垂直 SFT 常见翻车复盘:过拟合、复读、灾难性遗忘如何系统性处理?
一、写在前面:为什么要专门讨论垂直 SFT 的翻车问题
做垂直微调时,很多团队的诉求并不复杂:希望模型在特定业务场景里更稳定、更准确、更可控。但现实是,SFT 往往不是一次性工程:数据会迭代、任务会新增、模型会升级、线上反馈会推动你不断重训。
一旦进入高频迭代,训练过程中最耗时间的部分通常不是算力本身,而是排查和复现:
- 同样的训练配置,不同批次数据表现差异明显
- 训练 loss 下降,但线上效果变差
- 领域任务变强,但通用能力出现下滑
- 输出重复、模板化增强,长文本更明显
这些现象在垂直数据同质度高、样本质量不均、长尾难例存在的情况下更常见。Y-Trainer 的定位正是针对过拟合与灾难性遗忘提供训练侧的系统性处理方案。
本文目标是给出一套可复现、可对照的分析路径:先把问题拆清楚,再解释传统 SFT 的局限,最后提供基于 Y-Trainer 的落地流程,并重点解析 NLIRG 的机制与使用要点。
二、典型现象:它们经常同时出现
1. 垂直 SFT 过拟合
在指令微调中,过拟合不一定体现为训练 loss 极低,更常表现为模型对训练语料的表达方式过度贴合:格式、措辞、结构稳定,但换一种问法、换一组字段顺序、换一段更长的上下文,输出稳定性明显下降。Y-Trainer 文档将相似语料、模型已掌握知识列为过拟合相关因素,并提出通过 token 级动态调整缓解。
2. 复读与模板化增强
复读不仅与推理参数相关。当训练语料高度同质,模型会强化一组高概率的固定短语路径,导致生成时重复片段增多、套话增加、信息密度下降。
3. 灾难性遗忘
表现更为广泛:通用写作质量下降、指令遵循变差、结构化输出字段缺失率上升、常识性问题正确率下降等。Y-Trainer 文档明确将灾难性遗忘与过难语料关联,并作为核心解决目标。
实践中,这三类现象常相互耦合:同质语料带来的过拟合提高模板化概率;困难样本引发的激进更新可能导致遗忘;遗忘又进一步削弱输出结构稳定性。
三、问题根源:训练信号在 token 维度高度不均匀
理解问题需回归训练信号的最小粒度。SFT 的梯度更新最终来自 token,而非样本整体。哪些 token 提供更大 loss、贡献更强梯度,直接决定模型参数移动方向。
垂直 SFT 常见两类极端信号:
大量低损失 token 反复出现
垂直语料常含固定模板与字段(开头语、业务术语、格式符号等)。这类 token 早期即进入低损失区间。若训练过程对所有 token 一视同仁,模型会在已掌握模式上持续强化,加剧过拟合与模板化倾向。
少量高损失 token 带来过强更新
困难样本、长尾表达、标注不一致、截断错误等产生高损失 token。其对应梯度幅值更大,若不加区分参与反向传播,模型可能为拟合少量异常信号发生较大参数位移,引发训练不稳定与能力遗忘。
单纯降低学习率或减少 epoch 本质是削弱所有 token 的更新强度,会同步压制有效学习,非根本解法。
四、传统手段的局限
常见工程解法存在明显约束:
-
混合通用语料对冲遗忘
有效但面临现实挑战:语料合规性、治理成本、维护负担,且混合比例需随数据迭代持续调整。Y-Trainer 强调其优势之一是无需依赖通用语料即可保留泛化能力。 -
降低训练强度(小 lr、少 epoch、早停)
可降低翻车概率,但同步削弱领域能力提升幅度,难以满足专项能力稳定增强的需求。 -
数据清洗与去重
属必要前置工作,但无法解决低损失 token 过度参与更新的问题,亦难控制困难样本在训练中的影响权重。
更优思路是将优化点聚焦于训练信号本身:让不同难度 token 在反向传播中承担差异化权重,减少无效更新,提升有效学习比例。
五、Y-Trainer 的切入点:训练强度控制下沉至 token 级别
Y-Trainer 官方定位明确:对抗过拟合与灾难性遗忘,核心机制围绕 NLIRG 展开。对垂直微调团队而言,关键在于两点:
- NLIRG:基于 token loss 动态计算梯度权重,实现训练强度精细调控
- token_batch:分批次 token 训练,提升 token loss 的可靠性与稳定性
六、核心算法 NLIRG:用 token loss 作为难度信号,按区间动态调节梯度
NLIRG(Gradient-driven Nonlinear Learning Intensity Regulation)核心逻辑:对每个 token 计算 loss,将 loss 映射为权重,再用加权 loss 参与反向传播。
区间划分与策略
文档明确给出四段区间策略:
| 损失区间 | 梯度策略 | 作用目标 |
|---|---|---|
| loss ≤ 1.45 | 削减梯度 | 避免对简单样本过度训练,缓解过拟合 |
| 1.45 < loss < 6.6 | 增强梯度 | 聚焦有效学习区间,加速能力提升 |
| 6.6 < loss < 15 | 削减梯度 | 降低困难样本主导更新的概率 |
| loss ≥ 15 | 梯度归零 | 忽略明显异常训练信号,隔离噪声 |
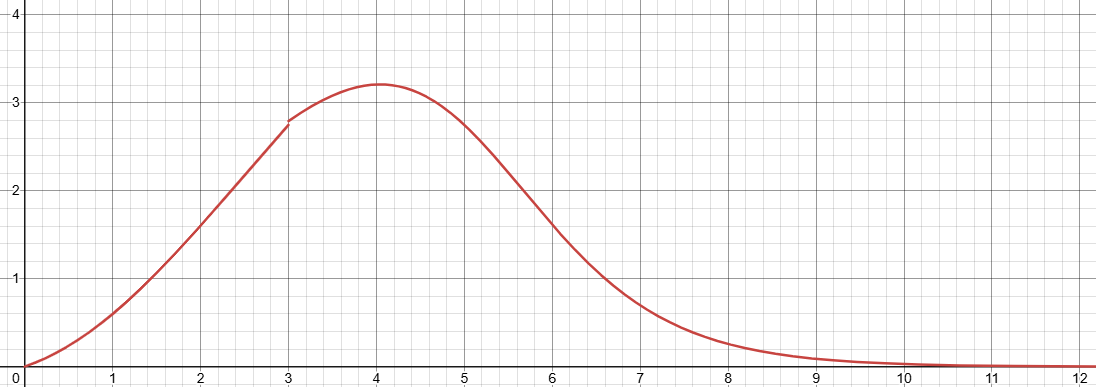
横轴为Loss值,纵轴为梯度权重
该策略的核心价值在于:将训练预算从低损失区间转移至中等损失区间,并对高损失区间建立隔离机制。目标并非单纯加速 loss 下降,而是使梯度更新更符合工程预期——减少无效更新,抑制噪声干扰,提升有效学习比例。
权重计算与参数
核心算法页提供了动态权重计算函数形式及相关参数(max_lr、x0、k、loss_threshold、loss_deadline 等),并明确 loss_deadline 后梯度归零机制。工程落地时,建议优先理解默认策略与区间含义,通过对照实验评估实际收益,而非初期即调整内部参数。
七、NLIRG 如何同步缓解过拟合与遗忘
在垂直 SFT 中,过拟合与遗忘并非矛盾,而是源于不同区间的训练信号:
- 过拟合主要来自低损失 token 的重复强化
- 遗忘与不稳定主要源于中高损失 token 的激进更新及高损失异常 token 的噪声影响
NLIRG 的四段策略针对性作用:
- 低损失区间降权 → 减少已掌握模式的重复强化,抑制过拟合
- 中等损失区间升权 → 保障领域能力有效提升
- 中高损失区间降权 + 高损失区间归零 → 降低困难/异常样本对更新方向的干扰,减少遗忘风险
八、为什么 SFT 强调 token_batch:提升 token loss 可靠性
NLIRG 的有效性依赖于 token loss 的准确性。Y-Trainer 在 SFT 中引入分批次 token 训练,通过 token_batch 控制单次反向传播的 token 数量。
参数说明明确:token_batch 在 SFT 时必填,默认值 10;数值越小训练越准确但速度越慢,该参数对结果影响显著,不建议随意调整。
对照实验关键点:若 token_batch 设置不一致,易将训练信号分辨率差异误判为算法收益,导致结论偏差。务必保持该参数在对照组中完全一致。
九、落地流程:从跑通到可对照,再到可迭代
步骤 1:跑通最小训练闭环
Quick Start 提供 SFT + LoRA 示例,建议单卡环境先验证基础流程:
- training_type=sft
- use_NLIRG=true
- token_batch=10
- batch_size=1
- use_tensorboard=true(便于后续复盘)
python -m training_code.start_training \
--model_path_to_load /path/to/base_model \
--training_type 'sft' \
--use_NLIRG 'true' \
--epoch 3 \
--data_path /path/to/sft.json \
--output_dir ./runs/nlirg \
--use_lora 'true' \
--batch_size 1 \
--token_batch 10 \
--use_tensorboard 'true'
步骤 2:严格对照实验
重要提示:use_NLIRG 默认值为 true。Baseline 必须显式设置为 false,否则对照失效。
Baseline(关闭 NLIRG):
python -m training_code.start_training \
--model_path_to_load /path/to/base_model \
--training_type 'sft' \
--use_NLIRG 'false' \
--epoch 3 \
--data_path /path/to/sft.json \
--output_dir ./runs/baseline \
--use_lora 'true' \
--batch_size 1 \
--token_batch 10 \
--use_tensorboard 'true'
实验组(启用 NLIRG):
python -m training_code.start_training \
--model_path_to_load /path/to/base_model \
--training_type 'sft' \
--use_NLIRG 'true' \
--epoch 3 \
--data_path /path/to/sft.json \
--output_dir ./runs/nlirg \
--use_lora 'true' \
--batch_size 1 \
--token_batch 10 \
--use_tensorboard 'true'
步骤 3:建立评测与回归体系
建议准备两套评估集合:
- 领域验证集:量化专项能力提升效果
- 通用回归集:监测灾难性遗忘与输出稳定性变化(50–200 条即可覆盖关键能力点:格式遵循、通用写作、摘要改写、常识问答、简单推理)
十、监控与复盘:TensorBoard 与训练日志固化流程
Y-Trainer 内置 TensorBoard 支持,建议每次训练固定记录:
- 训练与验证 loss 曲线
- 领域集关键指标(如有)
- 通用回归通过率与结构化输出校验通过率
- 复读相关指标(如 n-gram 重复率,可自行实现)
证据链优先级建议:对照实验的回归结果 > TensorBoard 曲线对比 > 单条 case 主观观感。
十一、附加能力:语料排序提升训练效率
Y-Trainer 提供语料排序工具,基于熵与交叉熵的时序差异评估语料难度,支持 similarity_rank 模式。适用于:
- 训练前排查异常样本,降低噪声干扰
- 优化训练顺序,提升收敛效率与稳定性
python -m training_code.utils.schedule.sort \
--data_path example_dataset/sft_example.json \
--output_path example_dataset/sft_example_out.json \
--model_path Qwen3/Qwen3-8B \
--mode "similarity_rank"
十二、适用场景判断(基于投入产出比)
优先尝试场景:
- 垂直专家模型(法律、医疗、金融、企业知识等),需专项能力提升同时抑制遗忘与过拟合
- 通用语料混合存在合规或维护成本障碍,且需高频迭代
- 数据质量不均,存在困难样本与噪声,需训练侧隔离机制
- 资源受限(单卡/小集群),需整合 LoRA、梯度检查点等策略于统一框架
暂不优先场景:
- 训练目标为通用聊天或超大规模混合语料预训练,问题焦点不集中于垂直 SFT 的典型痛点
- 已有高度定制化分布式训练体系且迁移成本极高,建议先小规模对照验证收益
十三、总结与建议
面对垂直 SFT 中的过拟合、复读、遗忘等问题,建议将排查视角从整体调参转向训练信号分配层面。Y-Trainer 的 NLIRG 机制通过 token loss 分区间计算梯度权重,配合 token_batch 提升信号可靠性,从原理上提供了一种可解释、易对照的训练控制方案。
落地建议:
- 严格对照:同一数据、同一超参,唯一变量为 use_NLIRG(baseline 显式 false,实验组 true)
- 固化 token_batch:SFT 场景下保持 10 不变,避免分辨率干扰
- 建立轻量回归集:聚焦关键能力点变化
- 将 TensorBoard 监控纳入标准流程
默认值细节(如 use_NLIRG 默认 true、token_batch 为 SFT 必填)务必在实验设计阶段明确写入命令行,避免因默认行为导致对照失真。最终价值判断应基于回归集与线上指标,而非单一 loss 曲线。
项目地址:https://github.com/yafo-ai/y-trainer
文档地址:https://www.y-agent.cn/docs/y-trainer/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)