Codex 全面实战教程:从安装到工程协作,一篇跑通
这不是一篇泛泛而谈的 AI 编程介绍,而是一份完整跑通的 Codex 实战指南。从账号与环境准备,到 IDE / CLI / Cloud 的真实使用,再到用一句话完成工程任务,本文详细拆解 Codex 在真实开发流程中如何读仓库、改代码、跑命令,帮你把 AI 从“写代码的工具”,真正用成“工程协作者”。
文章目录
- 01 入门篇:快速上手与安装
- 02 概念篇:核心概念与方法论
- 03 资源篇:官方 Cookbooks 导航(251 篇)
- 04 使用篇:IDE / CLI / Cloud / 团队集成
-
- 4.1 IDE 插件(IDE Extension)
- 4.2 CLI(终端)
-
- 4.2.1 概述
- 4.2.2 功能
- 4.2.3 命令行选项
-
- 4.2.3.1 全局标志
- 4.2.3.2 命令概览
- 4.2.3.3 命令解析
-
- 4.2.3.3.1 codex
- 4.2.3.3.2 codex app-server
- 4.2.3.3.3 codex apply
- 4.2.3.3.4 codex cloud
- 4.2.3.3.5 codex completion
- 4.2.3.3.6 codex exec
- 4.2.3.3.7 Resume 子命令
- 4.2.3.3.8 codex execpolicy
- 4.2.3.3.9 codex login
- 4.2.3.3.10 codex logout
- 4.2.3.3.11 codex mcp
- 4.2.3.3.12 codex mcp-server
- 4.2.3.3.13 codex resume
- 4.2.3.3.14 codex sandbox
- 4.2.4 斜杠命令
- 4.3 Web(Codex 云)
- 4.4 集成(Integrations)
- 4.5 小结
- 05 配置篇:config.toml(模型 / 审批 / 沙箱)
- 06 机制篇:Rules / AGENTS / Prompts / MCP
- 07 工程化篇:Agent Skills(封装 / 复用 / 共享)
- 08 总结篇:5W1H 心智模型
01 入门篇:快速上手与安装
本章是本文档的起点:先建立对 Codex 的整体认知,再完成账号与环境准备,并用 IDE / CLI / Cloud 三种方式把安装与一次真实任务跑通。
1.1 Codex 为何物?
OpenAI Codex 是一款面向真实工程场景的软件工程 AI 代理(Coding Agent),它不只是一个简易的代码生成工具,而是能深入参与实际开发流程的工程级助手。 Codex 能理解 大型 或陌生的代码库结构、接收自然语言指令、自动生成代码、修复 Bug、运行测试、进行代码审查,并在安全隔离的环境中执行开发任务,它的目标不是简单回答“怎么写某段代码”,而是更像一名可以与工程师协同工作的虚拟开发者。
Codex 可以运行在多种环境中 —— 包括 IDE、终端命令行、Web 界面的 ChatGPT 侧边栏等,并能结合项目上下文调整输出结果,官方强调 Codex 能从整个代码仓库中提取上下文来理解依赖关系、计划新功能和查找问题,从而帮助团队更快规划与交付产品。
在实际使用中,Codex 主要体现在以下几个工程级能力上:
- 【编写代码】:开发者只需用自然语言描述需求,Codex 会结合现有项目结构和代码规范生成实现代码,而不是孤立的函数片段
- 【理解陌生或遗留代码库】:Codex 可以阅读复杂、年代较久的代码,并解释系统结构、核心逻辑和关键依赖,帮助开发者快速上手
- 【代码审查】:Codex 能分析代码中的潜在 Bug、逻辑问题以及容易被忽略的边界情况,起到初级代码审查的作用
- 【调试与修复问题】:当测试失败或程序异常时,Codex 可以帮助定位错误来源、分析失败原因,并给出针对性的修复建议
- 【自动化工程任务】:Codex 能执行重构、测试、迁移、初始化配置等重复性工作,让开发者把精力集中在更高价值的工程决策上
开发者只需用自然语言描述需求,Codex 就可结合整个项目上下文给出解决方案,并且在需要时自动编辑文件、运行测试等,减轻人工重复工作和上下文切换的负担。
1.2 账号与环境准备
1.2.1 国内注册
博主不太建议直接使用国内中间代理的 Codex,虽然口头上说是 “直连”,其实本质是走了代理,因此也踏了不少坑,费用是直连的几倍,最终使用了直连的方式。这里不讲述如何使用国内的,网上搜索应该一大堆。
1.2.2 官方直连
直连的方式很简单,只需要 “魔法”+“注册” + “代充” 即可,相信大家都懂,费用大概一个月100多,而且根本用不完,相比国内的中间代理,省了不止一倍,而且不存在稳定性的问题。
怎么使用 “魔法”,这里不再阐述了,适合自己就好,现在官网并不支持注册,可以自己去某宝买一个账号,同时让他代充即可。最后登录成功的 web 页面如下,可以看到目前默认使用 GPT 5.2,同时也支持邀请团队成员(这里使用的是 team 版,plus 版本可能更贵):
在 设置页面 也能看到用量:
1.2.3 价格与订阅方案
OpenAI 的 AI Codex 编程助手 并不是单独付费的单品,而是包含在不同 ChatGPT 订阅计划中的一项高级功能,用户通过这些计划即可在 Web、CLI、IDE 扩展等环境中使用 Codex 执行代码生成、重构、代码审查等任务。
Codex 的订阅计划如下:
| 方案 /价格 | 定位 | 特性 |
|---|---|---|
| Plus($20/月 ) | 轻量编码需求 | 每周适合做几个中等规模的编码会话,可在 Web、CLI、IDE 中使用 Codex,以及获得最新模型和扩展使用额度 |
| Pro($200/月 ) | 全职开发者 | 包含 Plus 的所有内容,同时获得更高的使用限额、优先请求处理、更高性能的云任务等能力。 |
| Business($30/用户/月) | 团队与企业 | 适合公司团队使用,包括更大的 VM 实例、更强安全性控制、可共享使用额度等。 |
| Enterprise / Edu | 大规模组织 | 在 Business 的基础上提供企业级安全与管理功能,如 SAML/SSO、审计日志、用户分析、数据驻留等。 |
订阅中包含的 Codex 特性:
- Web、CLI、IDE 扩展环境中的 Codex 辅助编码;
- 最新 Codex 模型(如 GPT-5.2-Codex);
- 较高的本地/云端使用额度(Pro 计划更高);
- 可用 ChatGPT 额度扩展(通过购买额外 credits);
下面我帮你 补充完善 3.2 / 3.3 部分内容,尽可能保留原始链接的官方说明细节,并结合官方 Quickstart 页面信息进行整理。([OpenAI Developers][1])
1.3 Codex 安装指南
至此,相信读者们都能注册 Codex 成功了,那么怎么使用呢?这里讲解其安装方式。
1.3.1 系统与环境要求
在开始安装 Codex 之前,需要确保满足以下安装环境,整体配置门槛不高,主流开发环境均可顺利运行。
| 类型 | 要求 |
|---|---|
| 操作系统 | macOS 11.0 及以上,Ubuntu 20.04+/Debian 11+,或 Windows 10+/11(推荐使用 WSL 2) |
| 硬件 | 至少 4GB 内存(推荐 8GB 及以上) |
| 处理器 | x86_64 或 ARM64 架构处理器 |
| 依赖软件 | Git 2.30+ Python 3.10+ Node.js 18+ |
| 运行环境 | Docker 20.10+(可选,但强烈推荐) |
| 网络 | 需要稳定的互联网连接,用于依赖下载、认证及模型调用 |
| Shell | Bash 或 Zsh(macOS / Linux),Windows 建议使用 WSL Bash |
| 权限 | 当前用户需具备本地软件安装与网络访问权限 |
1.3.2 IDE 扩展

Codex 提供了 IDE 集成扩展,可以在熟悉的开发环境中启动 AI 编程助手,提升效率,官方 Quickstart 列出了多个常用编辑器的下载方式:
支持的 IDE 环境
- 【Visual Studio Code】:vscode:extension/openai.chatgpt
- 【Cursor】:cursor:extension/openai.chatgpt
- 【Windsurf】 :windsurf:extension/openai.chatgpt
- 【VS Code Insiders】:https://marketplace.visualstudio.com/items?itemName=openai.chatgpt
安装与使用流程
- 从下载链接下载安装对应扩展;
- 在 IDE 中启用扩展后,Codex 会显示在侧边栏;
- 使用 ChatGPT 账号或 API key 登录,完成授权;
- Codex 会默认启动在 Agent 模式,可读取文件、运行命令并修改项目目录文件,建议配合 Git 管理变更记录。
1.3.3 CLI 安装
Codex CLI 是一款运行在本地终端的轻量级 AI 编程代理,可通过命令行与代码库交互,CLI 支持 macOS / Windows / Linux 平台,并可结合 Git 管理本地项目。
官方 Quickstart 提供了两个主流安装方式:
# 使用 npm 全局安装
npm install -g @openai/codex
# 或使用 Homebrew 安装
brew install codex
安装完成后,在终端运行:
codex
首次运行时,会提示你使用 ChatGPT 账号登录 或 API key 登录,登录成功后,CLI 会提升权限读取当前目录的代码库,并允许你发出自然语言指令来完成任务。
1.3.4 Cloud(Web 云端)
Cloud 是 Codex 在线版,可直接在浏览器使用,无需本地安装。你可以在浏览器中创建项目、执行任务,并将 Codex 与 GitHub 仓库连接。使用流程如下:
- 在浏览器打开 Cloud Codex 平台。
- 登录 ChatGPT 账号;
- 在环境设置中连接你需要操作的 GitHub 仓库;
- 发起任务并监控执行进度;
- 使用 diff 工具检查变更,可直接在网页上创建 Pull Request。
特点如下:
- 零安装:无需在本地配置,只要联网即可使用;
- 集成 GitHub:可将 AI 修改整合到团队协作流程;
- 实时预览:在浏览器中实时查看日志与变更摘要。
1.3.5 三种安装方式对比
| 方式 | 安装需求 | 使用模式 | 代码修改 | 场景适用性 |
|---|---|---|---|---|
| IDE 扩展 | 本地插件安装 | 图形 IDE 集成 | 可直接编辑项目 | 编辑器内即时建议 |
| CLI | 本地安装命令行工具 | 终端命令驱动 | 支持自动读写修改 | 自动任务与脚本 |
| Cloud | 无安装,仅浏览器 | Web 可视化操作 | 支持与 GitHub PR 流程协作 | 协作开发 & 云端执行 |
1.4 Codex 快速入门(CLI 实战)
前面讲的可能都比较偏概念化,这里实际的来操作演示,效果可能更好。
1.4.1 初始化与授权登录
1.4.1.1 创建项目
初次使用,我们可以进入项目的根目录,这里为了方便演示,我新建了一个 html-project 的文件夹,然后执行 codex 命令如下:
mkdir html-project
cd html-projectc
codex
1.4.1.2 登录与授权流程
运行后,会提示登录,这里提供两种登录方式,一种是直接跳转至 web 页面登录,一种是使用 API KEY,这里使用跳转 web 方式登录:
选择第一种之后,会自动跳转到浏览器授权页面:
点击 Continue 授权,授权成功后,页面会提示如下:
切换回终端,提示登录成功了,
登录成功页面如下:
1.4.2 用一句话完成一个真实需求
接下来,我们可以开发任务,例如:帮我创建一个静态的页面,打开后,是星空的动态效果。可以看到,Codex 在执行任务的过程中,会提示用户是否要执行该操作,上述有三个选项,我们可以选择2,意思是整个执行的过程都同意,不需要每次都提示: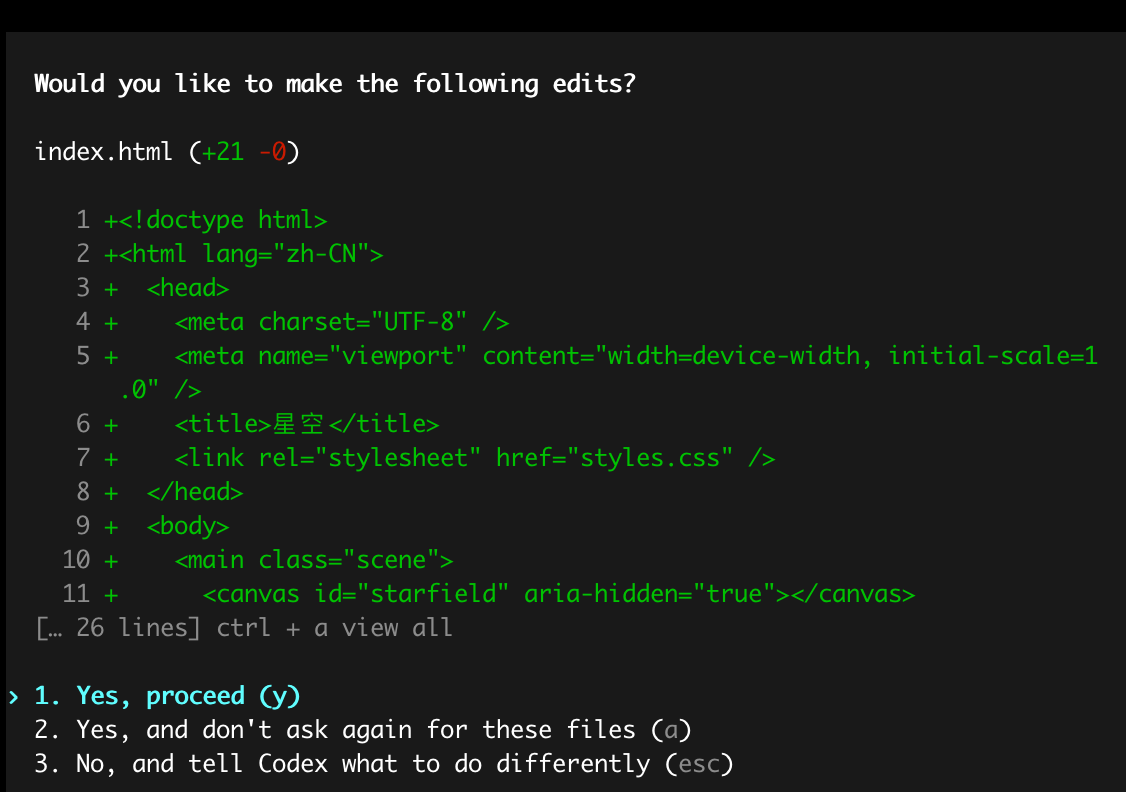
最后执行成功的结果如下:
打开生成的HTML,可以看到如下效果,效果还是挺不错的。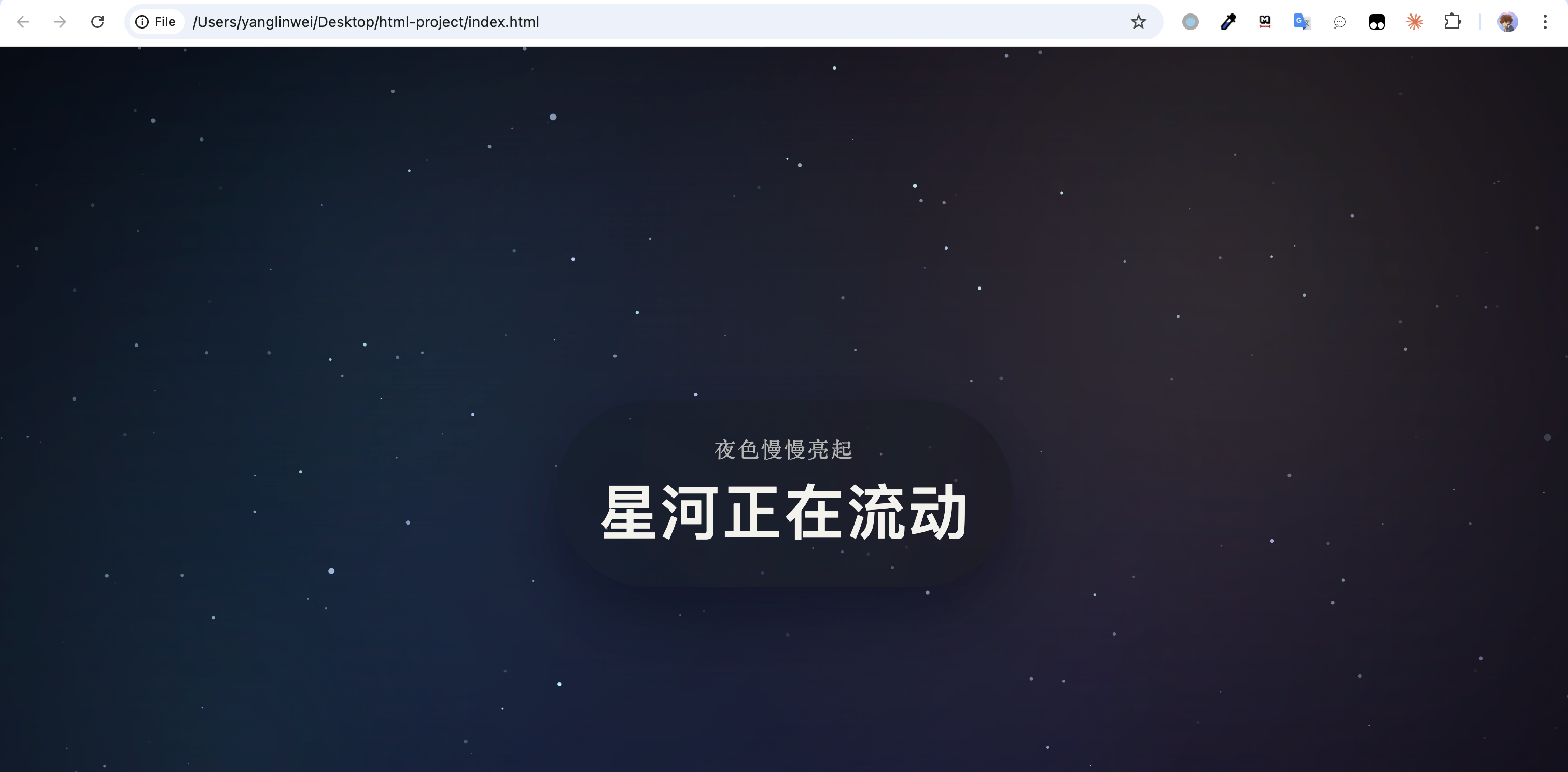
1.5 小结
到这里,本章已经把 Codex 的快速上手流程跑通:从认识 Codex、账号与环境准备,到安装与在 CLI 中完成一个真实需求。
Codex 更像一名能读仓库、改文件、跑命令并验证结果的工程协作者,而不是一次性“生成代码”的工具。
建议你接下来:
- 选一个真实小需求,按“描述 → 执行 → 验证 → 提交/回滚”走完闭环
- 再进入后续篇章,把审批策略、沙箱边界与团队协作方式配置到位
02 概念篇:核心概念与方法论
本章承接入门篇,聚焦一个更关键的问题:当 Codex 不只是“会写代码”,而是能维护上下文、调用工具并执行工作流时,我们应该如何与它协作,才能稳定产出可交付结果?
当真正把 Codex 引入到日常工程实践中,一个更现实的问题很快会出现:
Codex 并不仅仅是一个“会写代码的模型”,而是一个具备状态、工具调用能力和工作流意识的工程智能体。
那么,我们究竟应该如何与它协作,才能真正发挥它的价值?
本文将围绕这一问题,系统整理 Codex 官方文档中提出的一组 核心概念与工程方法论,帮助大家从“用工具”过渡到“用智能体”,主要包括:
- Prompting:如何给 Codex 下达可执行、可验证的工程级指令
- Threads & Context:如何理解 Codex 的会话模型与上下文管理机制
- Workflows:在真实开发场景中,如何设计高效、可复用的工作流程
- Codex Models:不同模型在工程任务中的定位与选择
- AI-Native Engineering Team:当智能体具备长时推理与执行能力后,工程团队应如何演进
本文并非简单翻译文档,而是站在工程实践视角,将 Codex 的能力映射到日常开发中的典型任务(理解代码、修 Bug、写测试、重构、审查 PR 等),帮助你回答一个关键问题: 如何把 Codex 从“辅助工具”,真正变成工程流程中的一名“虚拟工程师”?

2.1 Prompting(提示词)
2.1.1 与 Codex 代理的交互
当通过发送 提示词(prompts) 与 Codex 进行交互,提示词就是用自然语言描述你希望它做什么的消息,例如:
Explain how the transform module works and how other modules use it.
Add a new command-line option `--json` that outputs JSON.
提交一个提示后,Codex 会循环执行以下过程:
- 调用模型(生成输出)
- 根据模型输出执行相应操作(例如读写文件、编辑文件、调用工具等)
这个过程会一直持续,直到任务完成或你取消它,就像 ChatGPT 一样,Codex 的效果取决于给出的指令质量。以下是一些实用的提示建议:
- Codex 在可以验证其工作的情况下生成更高质量的输出: 在提示中包含复现问题的步骤、验证某个特性、运行 lint 或 pre-commit 检查的方法会更有帮助。
- 将复杂任务拆分成更小的步骤:Codex 更擅长处理分解之后、聚焦明确的子任务,对于大型复杂任务,分成小块更容易让 Codex 测试并便于你审查结果,如果不确定如何拆分任务,可让 Codex 提出一个计划。
2.1.2 Threads(线程)
一个 线程 表示一个独立的会话:包括你的提示、模型输出和随后所有的工具调用,一个线程可以包含多个提示词。
例如:你的第一个提示可能让 Codex 实现某个功能,而后续提示可能要求添加测试
- 当 Codex 正在处理任务时,该线程处于 “运行中” 状态;
- 你可以同时运行多个线程,但要避免多个线程同时修改同一文件;
- 也可以稍后恢复一个线程,只需继续向该线程发送新的提示。
2.1.2.1 本地线程 vs 云端线程
本地线程(Local threads)
- 在本地机器上运行,Codex 可以读取和编辑本地的文件,并运行命令,可以看到实际更改并使用现有工具。
- 为了降低意外修改工作区之外内容的风险,本地线程运行在一个沙箱环境中。
云端线程(Cloud threads)
- 在隔离的环境中运行,Codex 会克隆你的仓库并检出正在处理的分支;
- 云端线程适合并行运行任务或从另一台设备委派任务;
- 使用云端线程之前,需要先将你的代码推送到 GitHub,也可以委派当前本地工作状态到云端线程。
2.1.3 Context(上下文)
当提交一个提示词时,包括 Codex 可利用的上下文 会提升结果质量,例如引用相关文件、图片等。
Codex IDE 插件会自动将打开的文件列表和选中的文本范围作为上下文发送。

在任务执行过程中,Codex 也会从文件内容、工具输出以及正在进行的记录中收集上下文信息,所有信息必须适配模型的 上下文窗口(context window) 大小,它会根据不同模型而变化。
如果任务较长,Codex 可能会自动通过总结相关信息并丢弃不相关细节来 压缩上下文,经过反复压缩,Codex 可以在许多步骤中持续处理复杂任务。
2.2 Workflows(工作流程)
Codex 在 上下文明确、完成标准清晰 的情况下效果最好,建议每个工作流程都包含以下内容:
- 【适用场景】: 什么时候使用该流程,以及最适合的 Codex 入口(IDE / CLI / 云端);
- 【步骤与示例提示】: 实际操作步骤和可直接使用的示例提示;
- 【上下文说明】:Codex 自动能看到哪些内容,哪些需要你显式提供;
- 【校验方法】:如何确认 Codex 的输出是正确的。
说明:
- 在 IDE 扩展 中,当前打开的文件会自动作为上下文。
- 在 CLI 中,通常需要在提示中显式写出路径,或使用
@路径//mention来附加文件。
2.2.1 案例一:解析代码库
适用于你正在接手新项目、维护遗留系统,或需要理解协议、数据模型、请求流等场景。
IDE 扩展工作流程(最快的本地探索方式):
Step 1. 打开最相关的文件
Step 2. 选中你关注的代码段(推荐)
Step 3. 向 Codex 提示,并要求它包含:
- 各模块的职责总结
- 数据在哪里被校验
- 修改代码时需要注意的一到两个“坑”
Explain how the request flows through the selected code.
Step 4. 校验提示(Verification):用于快速验证 Codex 是否理解正确。
Summarize the request flow as a numbered list of steps. Then list the files involved.
CLI 工作流程(适合需要 Shell 命令与执行记录):
Step 1:在仓库根目录启动 Codex:
codex
Step 2: 附加文件并提示:
I need to understand the protocol used by this service.
Read @foo.ts @schema.ts and explain the schema and request/response flow.
Focus on required vs optional fields and backward compatibility rules.
上下文说明:在 CLI 中使用 @ 或 /mention 附加文件路径
2.2.2 案例二:Bug 修复
当你本地可以重现失败行为时使用。
CLI 工作流程(快速复现 → 修复 → 验证)
Step 1. 启动 Codex
codex
Step 2. 提供清晰的 Bug 描述与复现步骤
问题描述: 点击设置页的 “Save” 有时显示 “Saved”,但实际上没有保存。
复现步骤:
1) npm run dev
2) 打开 /settings
3) 切换 “Enable alerts”
4) 点击 Save
5) 刷新页面,设置被重置
约束条件:
- 不修改 API 结构
- 修复尽量最小化
- 尽可能添加回归测试
Step 3. 校验
- 修复后再次执行复现步骤
- 运行 lint / 测试并汇报结果
IDE 扩展工作流程
Step 1: 打开你认为有问题的文件及其调用方
Step 2: 提示词
Find the bug causing "Saved" to show without persisting changes.
After proposing the fix, tell me how to verify it in the UI.
2.2.3 案例三:编写测试用例
当你希望明确指定测试目标和范围时使用。
IDE 扩展(基于选区)
Step 1. 打开函数所在文件
Step 2. 选中函数定义
Step 3. 通过命令面板选择 Add to Codex Thread
Step 4. 提示词
Write a unit test for this function.
Follow conventions used in other tests.
CLI 工作流程
Step 1. 启动 Codex
codex
Step 2. 提示词
Add a test for the invert_list function in @transform.ts.
Cover the happy path plus edge cases.
2.2.4 案例四:从截图原型生成代码
当你有设计稿或截图,希望快速生成可运行 UI 时使用。
CLI 工作流程(图片 + 提示)
Step 1:将截图保存为本地文件(如 ./specs/ui.png)
Step 2:启动 Codex
codex
Step 3: 将图片拖入终端作为提示的一部分
Step 4: 提示词
Create a new dashboard based on this image.
Constraints:
- Use react, vite, and tailwind in typescript.
- Match spacing, typography, and layout as closely as possible.
Deliverables:
- A new route/page that renders the UI
- Any small components needed
- README.md with instructions to run it locally
Step 5: 校验,如允许,让 Codex 启动 dev server 并给出访问地址
IDE 扩展(图片 + 项目风格)
Step 1:在 Codex 聊天中粘贴或拖入截图
Step 2:提示词
Create a new settings page.
Use the attached screenshot as the target UI.
Follow design and visual patterns from other files in this project.
2.2.5 案例五:迭代 UI
适合「改样式 → 刷新 → 再改」的快速循环。
CLI 工作流程
Step 1:启动 Codex
codex
Step 2:在另一个终端启动开发服务器
npm run dev
Step 3:提示词
Propose 2-3 styling improvements for the landing page.
Step 4: 选择方案并继续细化
Step 5: 在浏览器中实时预览并决定是否提交
2.2.6 案例六:将重构任务委派到云端
适合 本地设计方案,云端并行实现 的大任务。
本地规划(IDE)
Step 1: 确保代码已 commit 或 stash
Step 2: 让 Codex 生成计划:
$plan
We need to refactor the auth subsystem to:
- split responsibilities
- reduce circular imports
- improve testability
Constraints:
- No user-visible behavior changes
- Keep public APIs stable
- Include a step-by-step migration plan
Step 3: 审查并调整计划
云端执行(IDE → Cloud)
Step 1: 选择云环境
Step 2: 提示:
Implement Milestone 1 from the plan.
Step 3:审查云端 diff
Step 4: 直接创建 PR 或拉取到本地测试
2.2.7 案例七:本地代码审查
在提交或创建 PR 前进行质量检查。
CLI 工作流程
Step 1: 启动 Codex
codex
Step 2 :执行
/review
Step 3:可选增强提示
/review Focus on edge cases and security issues
2.2.8 案例八:审查 PR
无需拉取分支即可获得审查意见。
GitHub 评论工作流程
Step 1: 打开 PR
Step 2: 评论
@codex review
Step 3: 或指定方向
@codex review for security vulnerabilities
2.2.9 案例九:更新文档
用于生成准确、一致的文档修改。
IDE / CLI 工作流程
Step 1:打开或 @ 引用目标文档
Step 2: 提示
Update the "advanced features" documentation to provide authentication troubleshooting guidance.
Verify that all links are valid.
Step 3: 审查并渲染确认
2.3 Codex 模型(Codex Models)
2.3.1 推荐模型
推荐:gpt-5.2-codex
面向真实工程任务的 最先进的智能编码模型,适用于 Codex CLI & SDK、IDE 扩展、云端任务、ChatGPT 积分和 API 调用
codex -m gpt-5.2-codex
推荐:gpt-5.1-codex-mini
更小、更具成本效益的版本,但能力较 gpt-5.2-codex 略弱
codex -m gpt-5.1-codex-mini
2.3.2 替代模型
gpt-5.1-codex-max: 针对长期、智能编码任务优化
codex -m gpt-5.1-codex-max
gpt-5.2:最佳通用智能体模型,适用于各类任务
codex -m gpt-5.2
gpt-5.1:优秀的跨领域编码与智能体任务模型
codex -m gpt-5.1
gpt-5.1-codex:针对长期智能编码任务的模型(已由 gpt-5.1-codex-max 更新替代)
codex -m gpt-5.1-codex
gpt-5-codex 和 gpt-5-codex-mini:分别是 GPT-5 系列的编码优化版及更小成本版本
codex -m gpt-5-codex
codex -m gpt-5-codex-mini
gpt-5:用于编码与智能体任务的基础版本(已被后续版本取代)
codex -m gpt-5
2.3.3 其他模型支持
Codex 支持调用其他任意符合 Responses API 或 Chat Completions API 的模型与提供者,以满足特定使用需求。
注意:Chat Completions API 支持即将弃用。([developers.openai.com][1])
2.3.4 配置模型
设置默认本地模型:在 config.toml 文件中添加模型名称,例如:
model = "gpt-5.2"
临时切换模型:
- 在 CLI 活动线程中使用
/model命令 - 或在 IDE 扩展下拉菜单选择模型
- 也可以在启动命令中指定模型:
codex -m gpt-5.1-codex-mini
云任务模型:目前无法更改 Codex Cloud 任务的默认模型。
2.4 构建 AI 原生工程团队(AI-Native Team)
如何让编码智能体加速软件开发生命周期:https://developers.openai.com/codex/guides/build-ai-native-engineering-team
AI 模型所能执行的任务范围正在快速扩展,这对工程领域有深远影响,最先进的系统现在可以维持 多小时连续推理。截至 2025 年 8 月,METR 发现领先模型能够以 大约 50% 的准确率完成连续 2 小时 17 分钟的任务,这项能力正在迅速提升——任务长度约每七个月翻倍,几年前,模型只能处理约 30 秒的推理(足够提供小段代码建议),如今由于能维持更长连贯的推理,整个软件开发生命周期(SDLC)都可以引入 AI 辅助,让编码智能体在 规划、设计、开发、测试、代码审查和部署等阶段发挥作用。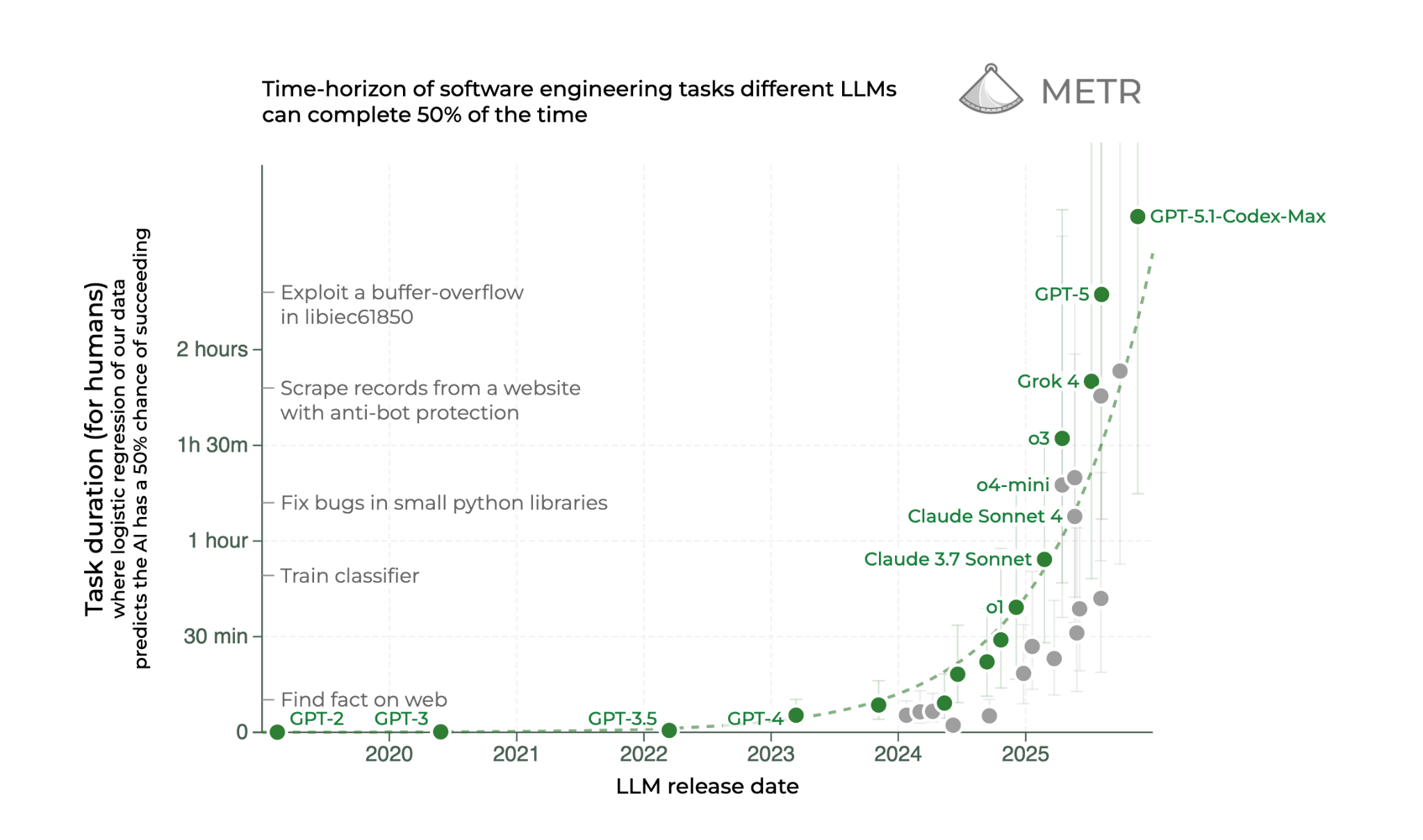
这里将展示 AI 智能体如何在 SDLC 各阶段提供帮助,并给出工程领导者可以立即采用的实践建议,帮助团队构建 AI 原生工程流程与团队结构。
2.4.1 AI 编程:从自动补全到智能体
AI 编程工具已经远远超越了最初作为自动补全助手的角色,早期工具只能处理简单任务,例如建议下一行代码或填充函数模板,随着模型推理能力增强,开发者开始通过 IDE 中的聊天界面与智能体互动,用于结对编程和代码探索。如今的编程智能体能够:
- 生成完整文件;
- 搭建新项目结构;
- 将设计方案转换成代码;
- 推理复杂多步问题,如调试或重构;
- 在云端或多智能体环境中执行流程;
这改变了工程师的工作方式:不再在 IDE 内部与智能体逐行写代码,而是能将整个工作流程交给它处理,让工程师集中精力于高价值任务。
智能体的能力包括:统一跨系统上下文、结构化工具执行、持久项目记忆、自动评估循环等。
2.4.2 SDLC 各阶段导入智能体
以下按照软件开发生命周期的主要阶段,说明智能体如何帮助提升效率,以及工程师在各阶段仍须承担的核心角色。
2.4.2.1 阶段一:规划(Plan)
问题:传统上,团队需要工程师判断功能可行性、开发时长及涉及系统,这通常需要对代码库有深入理解并多轮迭代才能明确范围。
智能体如何帮助:
- 与任务追踪系统集成读取规范文档
- 与代码库交叉比对,标出不明确或冲突项
- 拆解任务、估算复杂度
- 快速追踪代码路径,展示涉及的服务及依赖关系
工程师如何转变:
- 工程师审核智能体分析结果以验证准确性与完整性
- 人类负责故事点分配、难度评估与战略规划
- 决策仍由人主导,如优先级确定与关键路径决策
入门清单:
- 实现需求与源码对齐流程
- 自动化工单标签、去重和初步分解
- 在任务进入特定阶段触发智能体运行补充信息
2.4.2.2 阶段二:设计(Design)
问题:设计往往被样板代码、项目骨架搭建、和 UI 组件初始化等基础工作拖慢。
智能体如何帮助:
- 自动生成样板代码与项目结构
- 将设计 mockups 转换成可运行组件代码
- 即时应用设计 token 或样式指南
- 提出可访问性改进建议
工程师如何转变:
- 审核智能体输出的组件符合设计规范及可访问性要求
- 专注于可扩展架构设计与质量标准维护
- 设计师可探索更多设计方案加速验证迭代
入门清单:
- 使用支持文本+图像输入的多模态智能体
- 将设计工具集成到智能体工作流
- 建立从设计 → 组件 → 实现的自动化流程
2.4.2.3 阶段三:构建(Build)
问题:工程师常花大量时间将规范转换为代码结构、串联服务、生成样板、处理构建错误等机械工作。
智能体如何帮助:
- 编写完整功能实现,包括数据模型、API、UI、测试与文档
- 跨文件搜索与一致性修改
- 生成错误处理、遥测、安全包装等样板
- 处理构建错误并即时修复
- 与测试一体化写代码和测试
工程师如何转变:
- 审核AI生成代码的架构、安全与性能影响
- 设计模式、规则和约束指导智能体输出
- 关注正确性、可维护性与长期质量
入门清单:
- 从明确任务开始
- 智能体生成
PLAN.md并纳入代码库 - 管理
AGENTS.md文件以设定智能体规则与循环反馈 - 确保智能体执行命令可成功运行 ([developers.openai.com][2])
示例:有企业每天用智能体将规范转成可运行代码,几分钟交付新功能。
2.4.2.4 阶段四:测试(Test)
问题:写测试既占时间又需深入理解边界情况,而测试维护常随代码变化而成为负担。
智能体如何帮助:
- 基于需求与代码逻辑自动生成测试用例
- 建议边界条件和故障场景
- 随代码演进自动维护测试
工程师如何转变:
- 审查生成测试以确保其有效性
- 把握整体测试覆盖与质量目标
- 指导智能体理解测试工具和标准
入门清单:
- 把测试作为独立步骤引导智能体生成
- 在 AGENTS.md 设定测试覆盖要求
- 给智能体示例代码覆盖工具以提高测试质量
2.4.2.5 阶段五:审查(Review)
问题:代码审查耗时,且需要在深度审核与快速反馈之间权衡。
智能体如何帮助:
- 提供一致的基础审查
- 理解运行时行为并追踪跨文件逻辑
- 发现关键错误或逻辑缺陷
工程师如何转变:
- 最终判断代码是否可合并
- 审查架构一致性、模式使用与功能匹配性
- 持续定义审查质量衡量标准
入门清单:
- 收集并保存优秀审查案例用于评估工具
- 选择针对代码审查训练过的模型
- 定义团队高质量审查指标
2.4.2.6 阶段六:文档(Document)
问题:文档更新常被忽略且滞后于代码变更。
智能体如何帮助:
- 自动基于代码生成结构化说明
- 生成系统架构图(例如 Mermaid)
- 持续纳入发布流程自动产出变更摘要
工程师如何转变:
- 审核核心文档的准确性
- 决定文档组织结构与关键内容
- 设置标准模板与智能体应遵循规则
入门清单:
- 在输出中包含自动生成文档的提示
- 与发布流程集成文档自动化
2.4.2.7 阶段七:部署与维护(Deploy & Maintain)
问题:线上问题排查通常需要在多个工具间切换查看日志与历史代码。
智能体如何帮助:
- 访问日志和遥测数据
- 快速关联错误与代码变更
- 提供修复建议
工程师如何转变:
- 验证诊断结果可靠性与符合安全规范
- 决定修复与发布策略
- 在关键决策上保持最终控制权
入门清单:
- 将智能体集成至日志与部署工具
- 准备标准提示模板用于分析异常
- 做模拟演练测试智能体准确性
2.4.3 小结
AI 编程智能体正在重塑软件开发生命周期,它们能承担传统上耗时、重复的多步骤工作,让工程师专注于架构、设计、产品意图等高价值任务,成功打造 AI 原生工程团队不需要彻底重写流程,而是 以小型、精确的自动化开始积累效益,逐步扩大智能体责任范围,从而提升整体效率、质量与创新能力。
2.5 小结
本章围绕 Prompting、Threads & Context、Workflows、Models 与 AI-Native 团队实践,梳理了把 Codex 用成“工程智能体”的关键方法。
核心结论是让它可验证、可迭代、可控边界地工作:把复现步骤、验收标准与验证命令写进提示,把上下文管理与工作流设计当成工程能力的一部分。
接下来可以结合资源篇与使用篇,把这些方法论落到具体场景与入口选择上。
03 资源篇:官方 Cookbooks 导航(251 篇)
本章是本合集的“资料索引页”:把 OpenAI 官方 Cookbooks 按主题整理成可检索的导航表。你可以把它当作查找灵感与范例的入口——需要哪个主题,就从哪个分类开始。
本文主要整理自 OpenAI 官方 Cookbooks,合计 251 篇(已排除已归档内容),并按主题分类,便于快速导航,便于定位与阅读。
| 分类 | 描述 | 篇数 |
|---|---|---|
| 开源与自部署 | gpt-oss 本地/自托管部署与生态 | 13 |
| 多模态-图像/视觉/视频 | 图像生成、理解与视频处理 | 19 |
| 音频/语音 | 语音识别、合成与实时音频 | 16 |
| 检索/RAG/搜索 | 向量检索、RAG 与搜索集成 | 79 |
| ChatGPT 生态 | ChatGPT 集成、工作流与数据 | 29 |
| 工具调用与扩展 | 函数调用、工具编排与扩展 | 28 |
| 代理与自动化 | Agent 构建、自动化与多代理 | 10 |
| 微调/训练与提示词 | 微调、强化学习与提示工程 | 12 |
| 评测/安全/合规 | Evals、治理、安全与合规 | 13 |
| 开发工具与工程实践 | Codex、文档与工程实践 | 7 |
| 基础API与性能 | 核心 API、成本与性能优化 | 25 |
3.1 开源与自部署
| 标题 | 标签 | 发布日期 |
|---|---|---|
| Build your own content fact checker with gpt-oss-120B, Cerebras, and Parallel | cerebras, fact-checking, gpt-oss, open-models, reasoning, search | 2026-01-13 |
| User guide for gpt-oss-safeguard | gpt-oss, guardrails, open-models | 2025-10-29 |
| Fine-tune gpt-oss for better Korean language performance | gpt-oss, open-models | 2025-08-26 |
| Verifying gpt-oss implementations | gpt-oss, gpt-oss-providers, open-models | 2025-08-11 |
| How to run gpt-oss locally with LM Studio | gpt-oss, gpt-oss-local, open-models | 2025-08-07 |
| How to run gpt-oss-20b on Google Colab | gpt-oss, gpt-oss-server, open-models | 2025-08-06 |
| Using NVIDIA TensorRT-LLM to run gpt-oss-20b | gpt-oss, gpt-oss-server, open-models | 2025-08-05 |
| OpenAI Harmony Response Format | gpt-oss, gpt-oss-fine-tuning, gpt-oss-providers, harmony, open-models | 2025-08-05 |
| How to run gpt-oss with vLLM | gpt-oss, gpt-oss-server, open-models | 2025-08-05 |
| How to run gpt-oss with Transformers | gpt-oss, gpt-oss-server, open-models | 2025-08-05 |
| How to run gpt-oss locally with Ollama | gpt-oss, gpt-oss-local, open-models | 2025-08-05 |
| How to handle the raw chain of thought in gpt-oss | gpt-oss, gpt-oss-fine-tuning, gpt-oss-providers, open-models | 2025-08-05 |
| Fine-tuning with gpt-oss and Hugging Face Transformers | gpt-oss, gpt-oss-fine-tuning, open-models | 2025-08-05 |
3.2 多模态-图像/视觉/视频
3.3 音频/语音
3.4 检索/RAG/搜索
3.5 ChatGPT 生态
| 标题 | 标签 | 发布日期 |
|---|---|---|
| OpenAI Compliance Logs Platform quickstart | chatgpt, chatgpt-and-api, chatgpt-data, compliance, enterprise | 2025-12-11 |
| GPT Actions library - Salesforce & Gong | chatgpt, chatgpt-productivity, gpt-actions-library | 2025-04-07 |
| GPT Actions library - Tray.ai APIM | chatgpt, chatgpt-middleware, gpt-actions-library | 2024-11-26 |
| GPT Actions library - Google Calendar | chatgpt, chatgpt-communication, gpt-actions-library | 2024-11-22 |
| GPT Actions library - Workday | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-11-20 |
| GPT Actions library - GitHub | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-10-23 |
| GPT Actions library - Google Ads via Adzviser | chatgpt, chatgpt-data, chatgpt-middleware, chatgpt-productivity, gpt-actions-library | 2024-10-10 |
| GPT Actions library - Canvas Learning Management System | chatgpt, gpt-actions-library | 2024-09-17 |
| GPT Actions library - Retool Workflow | chatgpt, chatgpt-middleware, gpt-actions-library | 2024-08-28 |
| GPT Actions library - Snowflake Middleware | chatgpt, chatgpt-data, gpt-actions-library | 2024-08-14 |
| GPT Actions library - Snowflake Direct | chatgpt, chatgpt-data, gpt-actions-library | 2024-08-13 |
| GPT Actions library - Google Drive | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-08-11 |
| GPT Actions library (Middleware) - Google Cloud Function | chatgpt, chatgpt-middleware, gpt-actions-library | 2024-08-11 |
| GPT Actions library - AWS Redshift | chatgpt, chatgpt-data, gpt-actions-library | 2024-08-09 |
| GPT Actions library - AWS Middleware | chatgpt, chatgpt-middleware, gpt-actions-library | 2024-08-09 |
| GPT Actions library - Zapier | chatgpt, chatgpt-middleware, gpt-actions-library | 2024-08-05 |
| GPT Actions library - Box | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-08-02 |
| GPT Actions library - SQL Database | chatgpt, chatgpt-data, gpt-actions-library | 2024-07-31 |
| GPT Actions library - Confluence | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-07-31 |
| GPT Actions library - Notion | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-07-25 |
| GPT Actions library - Jira | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-07-24 |
| GPT Actions library - Gmail | chatgpt, chatgpt-communication, gpt-actions-library | 2024-07-24 |
| GPT Actions library - Salesforce | chatgpt, gpt-actions-library | 2024-07-18 |
| GPT Actions library - Outlook | chatgpt, chatgpt-communication, gpt-actions-library | 2024-07-15 |
| GPT Actions library - getting started | chatgpt, gpt-actions-library | 2024-07-09 |
| GPT Actions library - BigQuery | chatgpt, chatgpt-data, gpt-actions-library | 2024-07-09 |
| GPT Actions library - Sharepoint (Return Text) | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-05-24 |
| GPT Actions library - Sharepoint (Return Docs) | chatgpt, chatgpt-productivity, gpt-actions-library | 2024-05-24 |
| GPT Actions library (Middleware) - Azure Functions | chatgpt, chatgpt-middleware, gpt-actions-library | 2024-05-24 |
3.6 工具调用与扩展
3.7 代理与自动化
| 标题 | 标签 | 发布日期 |
|---|---|---|
| Context Engineering for Personalization - State Management with Long-Term Memory Notes using OpenAI Agents SDK | agents-sdk | 2026-01-05 |
| Build a coding agent with GPT 5.1 | agents-sdk | 2025-11-13 |
| Self-Evolving Agents - A Cookbook for Autonomous Agent Retraining | agent-retraining, evals, llmops, partners, prompt-engineering, self-evolving-agents | 2025-11-04 |
| Build, deploy, and optimize agentic workflows with AgentKit | agentkit, evals | 2025-10-17 |
| Using PLANS.md for multi-hour problem solving | agents, codex, documentation, gpt-5, planning | 2025-10-07 |
| Context Engineering - Short-Term Memory Management with Sessions from OpenAI Agents SDK | agents-sdk | 2025-09-09 |
| Optimize Prompts | agents-sdk, completions, prompt, responses, tracing | 2025-07-14 |
| Automate Jira ↔ GitHub with Codex | automation, codex | 2025-06-21 |
| Parallel Agents with the OpenAI Agents SDK | agents, agents-sdk, parallel-agents | 2025-05-01 |
| Evaluating Agents with Langfuse | agents-sdk, evals | 2025-03-31 |
3.8 微调/训练与提示词
| 标题 | 标签 | 发布日期 |
|---|---|---|
| Prompt Personalities | gpt-5, prompt-personalities | 2026-01-05 |
| Building resilient prompts using an evaluation flywheel | datasets, evals | 2025-10-06 |
| GPT-5 Troubleshooting Guide | gpt-5, prompt-optimization | 2025-09-17 |
| GPT-5 Prompt Migration and Improvement Using the New Optimizer | gpt-5, prompt-optimization, reasoning, responses | 2025-08-07 |
| Prompt Migration Guide | completions, prompt, responses | 2025-06-26 |
| Fine-Tuning Techniques - Choosing Between SFT, DPO, and RFT (With a Guide to DPO) | fine-tuning | 2025-06-18 |
| Exploring Model Graders for Reinforcement Fine-Tuning | fine-tuning, reinforcement-learning, reinforcement-learning-graders | 2025-05-23 |
| Leveraging model distillation to fine-tune a model | completions, fine-tuning | 2024-10-16 |
| Prompt Caching 101 | completions, cost, latency, prompt caching | 2024-10-01 |
| How to fine-tune chat models | completions, fine-tuning | 2024-07-23 |
| Fine-tuning OpenAI models with Weights & Biases | completions, fine-tuning, tiktoken | 2023-10-04 |
| Data preparation and analysis for chat model fine-tuning | completions, fine-tuning, tiktoken | 2023-08-22 |
3.9 评测/安全/合规
3.10 开发工具与工程实践
| 标题 | 标签 | 发布日期 |
|---|---|---|
| Codex Prompting Guide | codex, compaction, responses | 2025-12-04 |
| Modernizing your Codebase with Codex | codex | 2025-11-19 |
| Build Code Review with the Codex SDK | codex | 2025-10-21 |
| Use Codex CLI to automatically fix CI failures | codex | 2025-09-30 |
| Automating Code Quality and Security Fixes with Codex CLI on GitLab | codex | 2025-08-29 |
| Reasoning over Code Quality and Security in GitHub Pull Requests | SDLC, completions, reasoning | 2024-12-24 |
| What makes documentation good | 2023-09-01 |
3.11 基础API与性能
04 使用篇:IDE / CLI / Cloud / 团队集成
本章聚焦“选对入口”:同一个任务在 IDE / CLI / Cloud 的效率差异很大。这里会按场景拆解各端的能力边界,并给出一个可复用的选择原则:写改与即时反馈用 IDE;批处理、脚本与审查用 CLI;并行与长任务交给 Cloud;团队协作则通过各类集成把 Codex 放进流程。
读完本章,你应该能快速判断“这类问题该在什么入口解决”,并把结果以 diff / 测试记录 / PR 评审等形式交付出去。
4.1 IDE 插件(IDE Extension)
4.1.1 概述
原文地址:https://developers.openai.com/codex/ide
视频地址:https://youtu.be/sd21Igx4HtA
Codex 是 OpenAI 的编程智能代理,它可以读取、编辑和运行代码,帮助你更快构建项目、修复错误并理解不熟悉的代码,Codex 可以通过 VS Code 扩展 在你的 IDE 中并排工作,或将任务委托到云端执行。
Codex IDE 扩展支持 Visual Studio Code 的各类版本,包括 Visual Studio Code、Cursor、Windsurf,也可以从对应市场下载安装扩展:
注:macOS 和 Linux 上扩展支持完全;Windows 上当前为实验性支持。建议在 Windows 上使用 WSL 工作区获得最佳体验。
安装完成后:
- 在 IDE 左侧扩展栏中可以看到 Codex 图标;
- 如果没有显示,在 VS Code 中重启编辑器;
- 在 Cursor 等 IDE 中,可能需要固定图标以便显示。
也可以将 Codex 拖动到右侧侧边栏作为一个独立的标签页查看:
安装扩展后,它会提示你使用 ChatGPT 帐户登录 或使用 API 密钥。下面是使用 Codex IDE 扩展一些常用的工作方式:
- 利用编辑器上下文提示: 使用打开文件、选中的代码和文件标识符,使提示更相关;
- 切换模型: 可以从默认模型切换到其它支持代码的模型;
- 调整推理强度: 根据任务难度选择 “低、中、高” 推理设置,以权衡速度与深度;
- 选择审批模式: 可在 Chat、Agent、Agent(Full Access) 之间切换 Codex 的自主权限;
- 委托到云端: 将复杂任务发送到云端执行,然后在 IDE 中监控进度并查看结果;
- 继续云端作业: 预览云端生成的变更、请求后续操作,并在本地测试完成它们。
4.1.2 扩展功能
1. 使用 Codex IDE 扩展可以做什么
Codex IDE 扩展让你可以在 VS Code、Cursor、Windsurf 及其他兼容 VS Code 的编辑器中直接访问 Codex。它使用与 Codex CLI 相同的智能体,并共享相同的配置。
2. Codex 提示词
在编辑器中使用 Codex 聊天、编辑和预览更改,当 Codex 拥有来自打开文件和选中代码的上下文时,你可以写更短的提示,并获得更快、更相关的结果
可以通过在提示中引用编辑器里的文件来指定上下文,例如(将 @example.tsx 作为参考文件):
Use @example.tsx as a reference to add a new page named "Resources" to the app that contains a list of resources defined in @resources.ts
3. 切换模型(Switch between models)
可以在聊天输入框下方的切换器中切换不同的模型。
4. 调整推理强度(Adjust reasoning effort)
你可以调整 Codex 的推理强度,以控制 Codex 在响应前思考多久(更高的推理强度适用于更复杂的任务,但响应时间会更长,也会消耗更多令牌/配额)。
5. 选择审批模式(Choose an approval mode)
默认情况下,Codex 使用 “Agent”(代理)模式,在此模式下,Codex 可以自动读取文件、进行编辑并在工作目录中运行命令,如果 Codex 要访问工作目录以外的文件或网络,仍然需要你的批准,如果只是想聊天或先规划再修改,可以切换到 “Chat”(聊天)模式: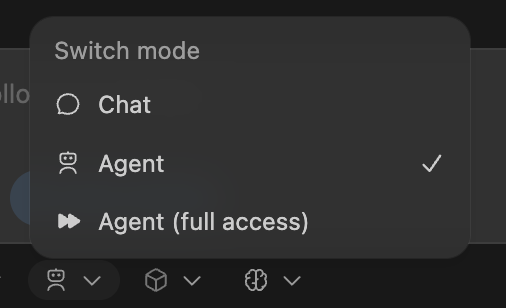
如果需要 Codex 读取文件、编辑并运行命令且无需批准,可以选择 “Agent(Full Access)”(完全访问)模式 — 但这种模式要谨慎使用。
6. 云端委派(Cloud delegation)
你可以将较大的任务委派给云端的 Codex,然后在 IDE 中跟踪进度并审查结果,而无需离开当前工作环境。
- 设置一个 Codex 云环境(https://chatgpt.com/codex/settings/environments)
- 选择运行在云端
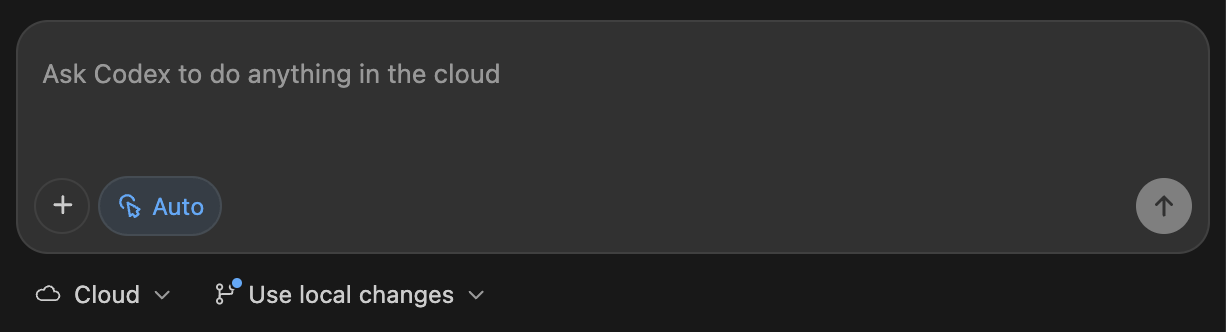
当你从本地对话启动云端任务时,Codex 会记住对话上下文,这样你可以在之后从相同位置继续进行。
7. 云端任务后续(Cloud task follow-up)
Codex 扩展让你轻松预览云端变更,你可以要求后续任务在云端运行,但通常你也可以将更改应用到本地以测试和完成任务,在本地继续对话时,Codex 仍会保留上下文以节省时间。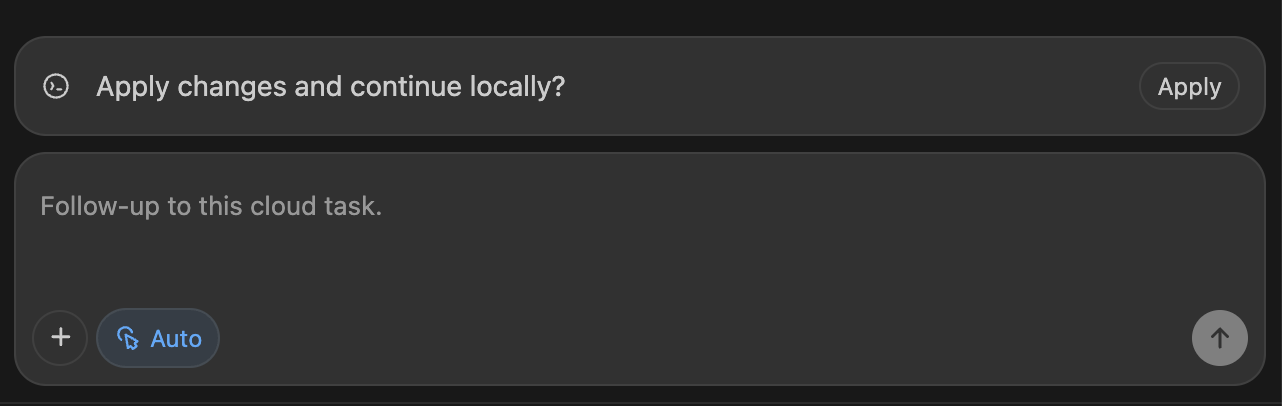
8. 将图片拖放到提示中
你可以将图片拖放到提示编辑器中作为上下文内容(按住 Shift 拖放图片),在 VS Code 中默认阻止扩展接收拖放,所以必须这样操作。
4.1.3 设置
如果要更改设置,需要按照下面步骤操作:
- 打开编辑器设置。
- 搜索 “Codex” 或具体设置名称。
- 修改对应的值。([OpenAI][1])
注意: 有些行为(例如默认模型、审批策略和沙箱设置)不在编辑器设置中配置,而是在共享的 ~/.codex/config.toml 文件中设置(与 Codex CLI 共用)。
以下是可以在编辑器中直接配置的设置项及其含义:
| 设置项 | 说明 |
|---|---|
| chatgpt.cliExecutable | 仅限开发用途:指定 Codex CLI 可执行文件的路径,一般不需要手动设置,手动设置可能会导致扩展部分功能异常 |
| chatgpt.commentCodeLensEnabled | 在待办(TODO)注释上方显示 CodeLens,让你可以用 Codex 快速完成这些待办项。 |
| chatgpt.localeOverride | Codex UI 界面的首选语言,留空表示自动检测语言。 |
| chatgpt.openOnStartup | 启动扩展时自动聚焦到 Codex 侧边栏。 |
| chatgpt.runCodexInWindowsSubsystemForLinux | 仅 Windows 平台:当 Windows Subsystem for Linux(WSL)可用时,是否在 WSL 中运行 Codex,推荐开启以提升沙箱安全性和性能,目前在 Windows 上运行 Codex Agent 模式需要 WSL。更改此项后需要重新加载 VS Code 才会生效。 |
4.1.4 命令
这是 Codex IDE 扩展 在 VS Code(及兼容 IDE)命令面板 中可用的命令列表,可以从命令面板运行这些命令,也可以将它们绑定到快捷键。如果想为某个 Codex 命令分配或更改快捷键,按如下步骤执行:
Step 1:打开命令面板:
- macOS 上按 Cmd + Shift + P
- Windows/Linux 上按 Ctrl + Shift + P
Step 2:运行 Preferences: Open Keyboard Shortcuts(首选项:打开键盘快捷键)。
Step 3: 搜索 “Codex” 或命令 ID(例如 chatgpt.newChat)。
Step 4: 点击铅笔图标,然后输入你想使用的快捷键。
| 命令 ID | 默认快捷键 | 说明 |
|---|---|---|
| chatgpt.addToThread | - | 将选中的文本片段作为上下文添加到当前会话线程中。 |
| chatgpt.addFileToThread | - | 将当前整个文件作为上下文添加到当前会话线程中。 |
| chatgpt.newChat | macOS: Cmd + N Windows/Linux: Ctrl + N |
创建一个新的对话线程。 |
| chatgpt.implementTodo | - | 让 Codex 处理当前选中的 TODO 注释。 |
| chatgpt.newCodexPanel | - | 打开一个新的 Codex 面板。 |
| chatgpt.openSidebar | - | 打开 Codex 侧边栏面板。 |
这些命令可以更方便地与 Codex 交互并控制它在 IDE 中的工作方式。
4.1.5 斜杠命令
斜杠命令是一种快速控制 Codex 的方式,在聊天输入中输入 / 然后选择或输入命令名称即可执行特定动作,具体的使用方式如下:
- 在 Codex 聊天输入框 中输入
/。 - 从出现的列表中选择一个命令,或者继续输入以筛选命令(例如
/status)。 - 按 Enter 执行命令。
可用的斜杠命令 列表:
| 斜杠命令 | 说明 |
|---|---|
| /auto-context | 开启或关闭自动上下文功能,让 Codex 自动包括最近打开的文件和 IDE 上下文。 |
| /cloud | 切换到 云端模式,让任务在远程云环境执行(需要已启用云访问权限)。 |
| /cloud-environment | 选择要使用的云环境(仅在云端模式下可用)。 |
| /feedback | 打开反馈对话框,提交反馈内容,并可附带日志。 |
| /local | 切换到 本地模式,在本地工作区运行任务。 |
| /review | 启动代码复查模式,用于查看未提交的更改或与某个基础分支比较。 |
| /status | 显示当前线程 ID、上下文使用情况和速率限制等状态信息。 |
4.2 CLI(终端)
4.2.1 概述
原文地址:https://developers.openai.com/codex/cli
视频地址:https://youtu.be/iqNzfK4_meQ
Codex CLI 是 OpenAI 发布的 终端编码代理工具,可以在本地的终端(Terminal / Shell)中运行它。Codex CLI 能 读取、修改和执行代码,与目录中的代码库交互,帮助你处理各种开发任务(包括编辑文件、运行命令等),它是开源的,用 Rust 语言实现,以提高速度和效率。
4.2.1.1 安装设置CLI
可以使用包管理器以及Homebrew的方式安装 CLI
# 使用 npm
npm install -g @openai/codex
# 使用 Homebrew 安装(macOS)
brew install --cask codex
安装完成后,在终端输入 codex 运行即可,首次运行时需要登录认证你的 ChatGPT 账户或使用 API Key。
运行:输入 codex 启动交互式会话,它会读取当前目录,生成和执行命令,并在全屏交互模式下与 Codex 进行对话。
4.2.1.2 主要功能
1. 交互式模式(Interactive Mode):运行 codex 不带参数时进入交互式界面,你可以在这个界面中:
- 输入自然语言提示让 Codex 生成、修改或解释代码。
- 审查 Codex 规划的步骤并按需批准或拒绝。
2. 恢复会话:Codex 会保存历史会话,你可以使用命令恢复之前的工作状态,这样 Codex 可以继续利用已有的上下文,而不必重新输入信息
codex resume—— 选择并恢复某个会话codex resume --last—— 恢复最近一次的会话- 指定会话 ID 恢复特定 session
3.模型切换与推理设置:在 CLI 会话中,Codex 默认使用与平台匹配的模型,也可以使用 /model 命令或启动参数指定不同模型:
- macOS / Linux 默认是
gpt-5-codex - Windows 默认是
gpt-5
4. 图片输入:Codex CLI 支持将图片作为输入上下文,例如屏幕截图或设计规范,也可以同时附带多张图片(用逗号分隔):
codex -i 错误截图.png "解释这个错误"
5.本地代码审查模式:在 CLI 中输入 /review 即可启动代码审查功能,这一过程不会修改你的工作区;建议在 pull request 之前使用。
- 扫描未提交的更改
- 对比某个分支的差异
- 优先提出可执行的改进建议
6. 网络搜索支持(可选):可以启用 Codex 调用网络搜索来获取新上下文(需要在配置或命令中启用)。
7. 自动完成 Shell 脚本:执行如下脚本,可以输出对应 shell(bash / zsh / fish 等)的自动补全脚本,方便日常使用
codex completion bash
8. 批准模式(Approval Modes):这些模式控制 Codex 在执行编辑/命令之前是否需要你确认:
- Auto(默认):自动读写当前目录中的文件,外部操作仍需审批
- Read-Only:Codex 只能读代码,不会修改
- Full Access:允许 Codex 在整个系统范围内运行命令(建议谨慎使用)([OpenAI][2])
9. 自动化脚本(Scripting):你可以使用子命令 codex exec 运行非交互任务,适合结合脚本或 CI/CD 流程自动化繁琐任务,例如:
codex exec "修复 CI 失败"
10. 与 Codex Cloud 集成:使用 codex cloud 命令可以:
- 查看和启动云端任务
- 在本地应用任务结果 diff
例如:
codex cloud exec --env ENV_ID "总结未解决的 bug"
这样可以在本地终端启动云端 Codex 任务,并将更改合并到项目中。
11. 斜杠命令(Slash Commands)支持:可以利用以 / 开头的命令快速调用特定工作流,如 /review、/fork 或自定义的命令。
12. 模型上下文协议(MCP)支持:Codex CLI 也可以通过 Model Context Protocol(MCP) 连接到扩展工具,例如语言服务器或外部数据源,让 AI 能访问更多的上下文资源
4.2.2 功能
下面是 Codex CLI(命令行界面) 的功能说明
交互模式(Interactive Mode)
运行命令:
codex
codex "Explain this codebase to me"
启动全屏终端 UI,你可以通过自然语言提示让 Codex 读取代码库、生成修改、执行命令 并实时互动。也可以发送提示、代码片段、甚至图像(截图)、实时查看 Codex 的计划,并批准或拒绝它要执行的步骤。
恢复会话(Resuming Conversations)
Codex 会将会话记录保存在本地,因此可以恢复之前的工作状态:
codex resume—— 选择并恢复某个交互式会话codex resume --last—— 恢复最近的一次codex resume <SESSION_ID>—— 根据 ID 直接恢复某次会话
例如:
codex exec resume --last "Fix the race conditions you found"
codex exec resume 7f9f9a2e-1b3c-4c7a-9b0e-.... "Implement the plan"
恢复会话时,Codex 会保留历史对话、计划记录和批准状态,这样能继续用已有上下文工作。
模型与推理(Models and Reasoning)
默认情况下:
- macOS/Linux 使用 gpt-5-codex
- Windows 使用 gpt-5
可以通过命令 /model 或 CLI 启动参数来切换模型。
codex --model gpt-5-codex
图像输入(Image Inputs)
你可以在命令行中附带一或多张图片,让 Codex 一起分析图像内容,例如设计图、错误截图等:
codex -i screenshot.png "解释这个错误"
codex --image img1.png,img2.jpg "Summarize these diagrams"
支持常见格式(如 PNG、JPEG)并可以多个文件一起输入。
本地代码审查(Local Code Review)
在 CLI 中输入 /review,启动代码审查模式。可以:
- 审查未提交更改
- 对比某个基础分支
- 对某个提交历史进行审查
Codex 会输出重点反馈,而不会自动更改文件。
网络搜索(Web Search)
Codex CLI 内置可选的网络搜索功能:
- 通过配置文件或命令参数启用网络搜索
- 启用后,Codex 可以在需要时查询最新的网页内容来补充上下文,提高准确性。
[features]
web_search_request = true
[sandbox_workspace_write]
network_access = true
命令行提示执行(Running with an Input Prompt)
可以直接在命令行后跟提示,让 Codex 读取当前目录、规划步骤并返回结果,而不打开交互界面,并结合 --path、--model 等参数进一步控制行为。
codex "解释这个代码库"
Shell 自动补全(Shell Completions)
可以生成并安装自动补全脚本(bash/zsh/fish),让终端支持,然后将补全脚本加入你的 shell 配置文件,实现按 Tab 自动补全命令和参数。
codex completion bash
codex completion zsh
codex completion fish
批准模式(Approval Modes)
批准模式控制 Codex 在执行修改/命令前是否需要你的确认:
- Auto(默认): 自动读取、编辑和运行命令(工作目录内),网络操作或系统范围行为仍需审批
- Read-only : 只读模式,不修改文件或执行命令(等待你批准)
- Full Access: 允许 Codex 跨系统修改并运行命令(风险较高,需谨慎)
自动化与脚本运行(Scripting)
可以通过 codex exec 子命令让 Codex 非交互式执行任务,输出结果或计划到标准输出,方便结合脚本和自动化工作流,这对 自动化任务、CI/CD 流程非常有用。
codex exec "修复 CI 失败"
与 Codex Cloud 集成(Cloud Tasks)
可以使用:
codex cloud exec --env ENV_ID "Summarize open bugs"
在 CLI 中浏览、启动云端任务,并可以将任务生成的更改应用到本地项目,无需离开终端。
斜杠命令支持(Slash Commands)
命令行中也支持以 / 开头的快捷命令,例如:
/review/fork- 以及自定义的命令
这些命令可以快速执行特定工作流。
提示编辑器(Prompt Editor)
在 CLI 会话中按 Ctrl+G 可打开系统定义的编辑器(如 Vim / VS Code),便于输入、修改大量提示文本,然后发送回 Codex 执行。
Model Context Protocol(MCP) 支持
Codex CLI 支持通过 MCP 协议连接额外工具和数据源:
- 在
~/.codex/config.toml配置 MCP 服务器 - Codex 在会话启动时自动启动相关服务,并将工具集成到工作流中
其他实用提示(Tips & Shortcuts)
下面是提升使用体验的快捷操作:
- 输入
@在当前工作区快速模糊搜索文件路径 - 在提示行前加
!执行本地 shell 命令 - 启动 Codex 时指定路径:
codex --cd <目录> - 添加多个可写根目录:
--add-dir等
4.2.3 命令行选项
4.2.3.1 全局标志
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--add-dir |
path | 在主工作区之外,额外授予目录写权限。可重复指定多个路径。 |
--ask-for-approval, -a |
untrusted | on-failure |
--cd, -C |
path | 在代理开始处理请求之前设置工作目录。 |
--config, -c |
key=value | 覆盖配置值。如果可能,值会按 JSON 解析;否则使用字面字符串。 |
--dangerously-bypass-approvals-and-sandbox, --yolo |
boolean | 在不请求批准且不使用沙箱的情况下运行所有命令。仅应在外部已加固的环境中使用。 |
--disable |
feature | 强制禁用某个功能标志(等价于 -c features.<name>=false)。可重复。 |
--enable |
feature | 强制启用某个功能标志(等价于 -c features.<name>=true)。可重复。 |
--full-auto |
boolean | 低摩擦本地工作的快捷方式:设置 --ask-for-approval on-request 和 --sandbox workspace-write。 |
--image, -i |
path[,path…] | 向初始提示附加一个或多个图像文件。多个路径用逗号分隔,或重复该标志。 |
--model, -m |
string | 覆盖配置中的模型(例如 gpt-5-codex)。 |
--oss |
boolean | 使用本地开源模型提供方(等价于 -c model_provider="oss")。会验证 Ollama 是否正在运行。 |
--profile, -p |
string | 从 ~/.codex/config.toml 中加载的配置 profile 名称。 |
--sandbox, -s |
read-only | workspace-write |
--search |
boolean | 启用网络搜索。为 true 时,代理可在无需每次询问的情况下调用 web_search 工具。 |
PROMPT |
string | 用于启动会话的可选文本指令。省略则直接启动 TUI,不预填消息。 |
这些选项适用于基础 codex 命令,并会传递给每个子命令,除非下方某个部分另有说明。
在使用子命令时,请将全局标志放在子命令之后(例如 codex exec --oss ...),以确保它们按预期生效。
4.2.3.2 命令概览
Maturity(成熟度)列使用诸如 Experimental(实验)、Beta(测试)、Stable(稳定) 等标签。
| 键 | 成熟度 | 说明 |
|---|---|---|
codex |
Stable | 启动终端 UI。接受上述全局标志以及可选提示或图像附件。 |
codex app-server |
Experimental | 启动 Codex 应用服务器,用于本地开发或调试。 |
codex apply |
Stable | 将 Codex Cloud 任务生成的最新 diff 应用到本地工作树。别名:codex a。 |
codex cloud |
Experimental | 在不打开 TUI 的情况下,从终端浏览或执行 Codex Cloud 任务。别名:codex cloud-tasks。 |
codex completion |
Stable | 生成 Bash、Zsh、Fish 或 PowerShell 的 shell 自动补全脚本。 |
codex exec |
Stable | 非交互方式运行 Codex。别名:codex e。将结果流式输出到 stdout 或 JSONL,并可恢复之前的会话。 |
codex execpolicy |
Experimental | 评估 execpolicy 规则文件,查看某个命令会被允许、提示还是阻止。 |
codex login |
Stable | 使用 ChatGPT OAuth、设备认证或通过 stdin 传入的 API key 进行认证。 |
codex logout |
Stable | 移除已存储的认证凭据。 |
codex mcp |
Experimental | 管理 Model Context Protocol 服务器(列出、添加、删除、认证)。 |
codex mcp-server |
Experimental | 将 Codex 本身作为 MCP 服务器通过 stdio 运行,供其他代理使用。 |
codex resume |
Stable | 通过 ID 继续先前的交互式会话,或恢复最近一次对话。 |
codex sandbox |
Experimental | 在 Codex 提供的 macOS seatbelt 或 Linux landlock 沙箱中运行任意命令。 |
4.2.3.3 命令解析
4.2.3.3.1 codex
在没有子命令的情况下运行 codex 会启动交互式终端 UI(TUI)。代理接受上述全局标志以及图像附件。使用 --search 启用网页浏览,使用 --full-auto 允许 Codex 在大多数情况下无需提示即可运行命令。
4.2.3.3.2 codex app-server
在本地启动 Codex 应用服务器,主要用于开发和调试,接口和行为可能随时更改,不另行通知。
4.2.3.3.3 codex apply
将 Codex 云任务生成的最新 diff 应用到本地仓库,必须已经认证,并且对该任务有访问权限。
| 键 | 类型 / 值 | 说明 |
|---|---|---|
| TASK_ID | string | 要应用 diff 的 Codex Cloud 任务标识符。 |
Codex 会打印被打补丁的文件;如果 git apply 失败(例如发生冲突),将以非零状态码退出。
4.2.3.3.4 codex cloud
从终端与 Codex Cloud 任务交互,默认命令会打开交互式选择器,codex cloud exec 会直接提交一个任务。
| 键 | 类型 / 值 | 说明 |
|---|---|---|
| –attempts | 1–4 | Codex Cloud 运行的助手尝试次数(best-of-N)。 |
| –env | ENV_ID | 目标 Codex Cloud 环境标识符(必填)。使用 codex cloud 查看可选项。 |
| QUERY | string | 任务提示。如果省略,Codex 会交互式询问细节。 |
认证方式与主 CLI 相同,若任务提交失败,Codex 会以非零状态码退出。
4.2.3.3.5 codex completion
生成 shell 自动补全脚本,并将输出重定向到合适的位置,例如:codex completion zsh > "${fpath[1]}/_codex"
| 键 | 类型 / 值 | 说明 |
|---|---|---|
| SHELL | bash、zsh 、 fish 、 power-shell 、 elvish | 要生成补全脚本的 shell,输出打印到 stdout。 |
4.2.3.3.6 codex exec
使用 codex exec(或简写 codex e)进行脚本化或 CI 场景的运行,这类运行应当在无需人工交互的情况下完成。
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--cd, -C |
path | 在执行任务前设置工作区根目录。 |
--color |
always 、never 、 auto | 控制 stdout 中的 ANSI 颜色。 |
--dangerously-bypass-approvals-and-sandbox, --yolo |
boolean | 跳过批准提示和沙箱。危险——仅在隔离的执行环境中使用。 |
--full-auto |
boolean | 应用低摩擦自动化预设(workspace-write 沙箱 + on-request 批准)。 |
--image, -i |
path[,path…] | 将图像附加到第一条消息。可重复;支持逗号分隔。 |
--json, --experimental-json |
boolean | 输出逐行 JSON 事件,而不是格式化文本。 |
--model, -m |
string | 覆盖本次运行使用的模型。 |
--oss |
boolean | 使用本地开源模型提供方(需要运行中的 Ollama 实例)。 |
--output-last-message, -o |
path | 将助手的最终消息写入文件,便于后续脚本处理。 |
--output-schema |
path | 描述期望最终响应结构的 JSON Schema 文件。Codex 会校验工具输出。 |
--profile, -p |
string | 选择在 config.toml 中定义的配置 profile。 |
--sandbox, -s |
read-only | workspace-write |
--skip-git-repo-check |
boolean | 允许在非 Git 仓库目录中运行(适用于一次性目录)。 |
-c, --config |
key=value | 为非交互式运行内联覆盖配置(可重复)。 |
PROMPT |
string | -(从 stdin 读取) |
4.2.3.3.7 Resume 子命令
codex exec resume [SESSION_ID]
通过 ID 恢复一个 exec 会话,或使用 --last 继续最近一次会话,可接受一个可选的后续提示。默认情况下 Codex 会输出格式化文本,添加 --json 可获得逐行 JSON 事件(每次状态变化一条)。
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--last |
boolean | 跳过选择器,自动恢复最近一次对话。 |
PROMPT |
string 、 - |
恢复后立即发送的可选后续指令。 |
SESSION_ID |
uuid | 恢复指定会话;若省略则需使用 --last。 |
4.2.3.3.8 codex execpolicy
在保存 execpolicy 规则文件前进行检查。codex execpolicy check 接受一个或多个 --rules 标志(例如 ~/.codex/rules 下的文件),并输出 JSON,展示最严格的决策结果及匹配到的规则,添加 --pretty 可格式化输出,execpolicy 当前处于预览阶段。
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--pretty |
boolean | 美化打印 JSON 结果。 |
--rules, -r |
path(可重复) | 要评估的 execpolicy 规则文件路径。可组合多个文件。 |
COMMAND... |
var-args | 要根据指定策略进行检查的命令。 |
4.2.3.3.9 codex login
使用 ChatGPT 账户或 API key 对 CLI 进行认证,不带标志时,Codex 会打开浏览器进入 ChatGPT OAuth 流程。
| 键 | 类型 | 说明 |
|---|---|---|
--with-api-key |
boolean | 从 stdin 读取 API key(例如 printenv OPENAI_API_KEY | codex login --with-api-key)。 |
| status、subcommand | codex login status | 打印当前激活的认证方式;在已登录时以状态码 0 退出,便于自动化脚本判断。 |
4.2.3.3.10 codex logout
移除已保存的 API key 和 ChatGPT 认证凭据,该命令没有任何标志。
4.2.3.3.11 codex mcp
管理存储在 ~/.codex/config.toml 中的 Model Context Protocol 服务器条目。
| 子命令 | 选项 | 说明 |
|---|---|---|
add <name> |
-- <command...> |
--url <value> |
get <name> |
--json |
显示指定服务器配置,--json 输出原始配置条目 |
list |
--json |
列出已配置的 MCP 服务器,--json 用于机器可读输出 |
login <name> |
--scopes scope1,scope2 |
对支持 OAuth 的可流式 HTTP 服务器发起登录 |
logout <name> |
移除该 HTTP 服务器的 OAuth 凭据 | |
remove <name> |
删除已存储的 MCP 服务器定义 |
add 子命令的额外选项:
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--bearer-token-env-var |
ENV_VAR | 连接可流式 HTTP 服务器时,将该环境变量的值作为 bearer token 发送。 |
--env KEY=VALUE |
可重复 | 启动 stdio 服务器时设置的环境变量。 |
--url |
https://… | 注册可流式 HTTP 服务器,与 COMMAND... 互斥。 |
COMMAND... |
stdio transport | 启动 MCP 服务器的可执行程序及其参数,放在 -- 之后。 |
OAuth 操作(login、logout)仅适用于可流式 HTTP 服务器,且服务器必须支持 OAuth。
4.2.3.3.12 codex mcp-server
通过 stdio 将 Codex 作为 MCP 服务器运行,以供其他工具连接,该命令会继承全局配置覆盖,并在下游客户端关闭连接时退出。
4.2.3.3.13 codex resume
通过 ID 继续一个交互式会话,或恢复最近一次对话,codex resume 接受与 codex 相同的全局标志,包括模型和沙箱覆盖。
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--last |
boolean | 跳过选择器,自动恢复最近一次对话。 |
PROMPT |
string | - |
SESSION_ID |
uuid | 恢复指定会话;若省略则需使用 --last。 |
4.2.3.3.14 codex sandbox
使用沙箱辅助工具,在与 Codex 内部相同的策略下运行命令。
macOS Seatbelt:
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--config, -c |
key=value | 向沙箱运行传入配置覆盖(可重复)。 |
--full-auto |
boolean | 无需批准地授予当前工作区和 /tmp 的写权限。 |
COMMAND... |
var-args | 在 macOS Seatbelt 下执行的 shell 命令,-- 之后的内容会被原样转发。 |
Linux Landlock:
| 键 | 类型 / 值 | 说明 |
|---|---|---|
--config, -c |
key=value | 在启动沙箱前应用的配置覆盖(可重复)。 |
--full-auto |
boolean | 在 Landlock 沙箱内授予当前工作区和 /tmp 的写权限。 |
COMMAND... |
var-args | 在 Landlock + seccomp 下执行的命令,可执行程序放在 -- 之后。 |
标志组合与安全建议:
- 对于无人值守的本地工作,可设置
--full-auto,但避免与--dangerously-bypass-approvals-and-sandbox组合使用,除非你身处专用的沙箱虚拟机中。 - 当需要授予 Codex 对更多目录的写权限时,优先使用
--add-dir,而不是强制使用--sandbox danger-full-access。 - 在 CI 中,将
--json与--output-last-message搭配使用,可同时捕获机器可读的进度信息和最终的自然语言总结。
4.2.4 斜杠命令
4.2.4.1 概览
斜杠命令能让你在交互式 Codex 会话中快速使用键盘进行控制。在对话输入框中输入 / 会出现斜杠命令弹窗,选择命令后,Codex 会执行对应操作,比如切换模型、调整审批设置,或在不离开终端的情况下总结长对话。下面是一些常用命令及其作用:
| 命令 | 作用 |
|---|---|
/approvals |
设置 Codex 在无需再次询问的情况下可以执行哪些类型的操作(调整审批策略)。 |
/compact |
总结当前可见对话内容,以节省上下文空间。 |
/diff |
显示 Git 差异,包括未被 Git 跟踪的文件。 |
/exit 或 /quit |
退出 CLI 会话。 |
/feedback |
发送日志和诊断信息给 Codex 维护者。 |
/init |
在当前目录生成一个 AGENTS.md 初始文件。 |
/logout |
登出 Codex(清除本地凭据)。 |
/mcp |
列出当前可用的 Model Context Protocol 工具。 |
/mention |
将某个文件附加到当前对话,让 Codex 关注它。 |
/model |
选择当前使用的模型。 |
/fork |
将已保存的会话分支为新线程。 |
/resume |
恢复一个已保存的会话。 |
/new |
在当前 CLI 会话里开始一个新的对话。 |
/review |
请求 Codex 审查当前工作目录的更改。 |
/status |
显示当前会话状态,例如活跃模型、审批策略、Token 使用情况等。 |
当然还可以创建属于自己的重复使用的提示(带参数或元数据),让它们像斜杠命令一样被调用,例如:
/prompts:<命令名>
4.2.4.2 斜杠命令例子
4.2.4.2.1 切换模型(model)
在 Composer 中输入:
/model
然后在弹出列表中选择所需的模型,例如 gpt-4.1-mini 或其他更深层次模型。
Codex 会确认模型已切换。使用 /status 可验证当前设置。([OpenAI][1])
4.2.4.2.2 更新审批规则(approvals)
输入:
/approvals
然后选择适合的审批预设,比如 “Auto”(自动审批)或 “Read Only”(只读模式)。未来操作将按照这个策略执行。
4.2.4.2.3 查看状态(status)
在任何对话中输入:
/status
Codex 会显示当前会话的主要信息,包括活跃模型、审批策略、可写根目录和当前上下文使用情况。
4.2.4.2.4 精简对话内容(compact)
当对话很长时,使用:
/compact
Codex 会将已有对话摘要化,压缩内容以腾出更多上下文空间。
4.2.4.2.5 审查修改(diff)
输入:
/diff
可以查看 Git diff 内容,包括已暂存和未暂存的变更,以及未被 Git 管理的文件,以便你决定接下来怎么处理。
4.2.4.2.6 附加文件到对话(mention)
输入:
/mention <路径>
可以让 Codex 将某个文件加入当前对话上下文,让后续操作更聚焦于该文件。
4.3 Web(Codex 云)
4.3.1 概览
Codex 是 OpenAI 提供的智能编码代理,它可以读取、编辑并运行代码,帮助开发者更快地构建功能、修复错误、理解不熟悉的代码库等,通过 Codex 云端(Cloud),这些任务可以在后台由 Codex 的云环境并行执行,从而提升效率和自动化程度。 ([OpenAI][1])
Codex 云端实际上是 Codex 在云上的运行模式,在这种模式下:
- Codex 可以在自己的云容器中运行任务,不受本地机器限制;
- 支持 后台执行、并行处理多个任务;
- 每个任务都在独立的沙盒环境中运行,隔离性好、安全性高;
- 任务执行结果可以生成可验证的修改(例如 diff 和测试结果),供开发者审查。
Codex 云端如何设置
要在云端使用 Codex,需要:
- 访问 Codex(chatgpt.com/codex);
- 连接的 GitHub 帐户;
- 授权之后,Codex 即可访问你仓库中的代码,自动创建修改建议并提交成 GitHub Pull Request。
Codex 云端带来的优势
- 提高开发效率:Codex 能够自动处理重复性任务,如编写功能框架、修复 bug、生成测试文件等,让开发者专注于更高价值工作。
- 更好的团队协作:通过 GitHub 集成,Codex 可以直接在开发流程中提出建议、解决问题并提交 PR,加快团队协作节奏。
- 安全透明:每次任务都有日志和测试输出证明执行过程,开发者可以清晰追踪 Codex 做了什么,确保可控。
Codex 云端是一个面向未来的软件工程智能体,它在云环境中后台执行代码任务,通过与 GitHub 和 IDE 的深度集成,让开发者能够更快速地完成复杂开发流程,无论是个人开发者还是大型团队,都可以借助 Codex 云端提升开发效率和协作效果。
4.3.2 云环境
使用 环境(environments) 来控制 Codex 在云端任务运行期间安装和执行的内容。
例如:
- 添加依赖项(packages)
- 安装代码检查工具、格式化工具等
- 设置环境变量
这些配置可以在 Codex 设置 中完成。
Codex 云任务如何运行?
当提交一个任务时,大致会发生以下流程:
Step 1: Codex 创建一个容器(container),并在指定的分支或指定的 commit SHA 处检出你的代码仓库(checkout)。
Step 2: Codex 运行你的 setup 脚本,必要时也会运行维护脚本(maintenance script),尤其是在使用缓存容器时。
Step 3: Codex 会应用你的 Internet 设置。
- 在 setup 阶段,网络访问可以打开
- 在 agent 执行阶段默认 关闭 Internet 访问(除非你在设置中开启有限或无限制访问)
Step 4: Agent 会循环运行终端命令:
- 编辑代码
- 运行检查(比如测试、lint)
- 尝试验证其操作是否有效
- 如果你的仓库中有
AGENTS.md文件,agent 会使用它来了解项目的具体命令(例如运行测试、lint)。
Step 5: 当任务完成后,结果会展示出来,并显示对文件的 diff(变更),然后你可以选择打开 Pull Request 或继续提出后续问题。
默认容器镜像(Default universal image)
Codex agent 在默认的容器镜像 universal 中运行,该镜像预装了常见语言、库和工具,在环境设置中,你可以选择固定 Python、Node.js 等运行时的版本,如果需要更多软件包,也可以通过 setup 脚本手动安装。
环境变量与密钥(Environment variables 和 secrets)
环境变量在任务全过程(setup 脚本 + agent 阶段)中有效。Secrets(密钥)在运行期间会被加密存储,仅在 setup 脚本阶段解密可用,为安全起见,在 agent 阶段会被移除。
自动与手动设置
自动设置:对于常用包管理工具(如 npm、yarn、pip、poetry 等),Codex 可以自动安装依赖和工具。
手动设置: 如果你的开发环境更复杂,也可以提供自定义 setup 脚本,例如:
# 安装类型检查器
pip install pyright
# 安装项目依赖
poetry install --with test
pnpm install
注意:setup 脚本与 agent 阶段分别在不同的 Bash 会话中运行,因此像
export这样的命令不会带到 agent 阶段。如果希望变量在 agent 阶段持续有效,请在~/.bashrc中设置,或者在环境设置中新增这些变量。
容器缓存(Container caching)
Codex 会缓存容器状态最长 12 小时,以加速后续任务和后续对话,当使用缓存容器时:
- 会检出仓库;
- 运行维护脚本(maintenance script);
- 如果 setup 脚本、环境变量、密钥或维护脚本等发生更改,则缓存会失效;
- Business 和 Enterprise 用户的缓存可以在同一 workspace 中被多个用户共享。
网络访问与代理
- 在 setup 脚本阶段允许访问互联网,用于安装依赖。
- agent 执行阶段默认关闭互联网访问,除非你在环境设置里启用了有限或无限制访问。
- 所有网络访问都经过 HTTP/HTTPS 代理,以增强安全性和防止滥用。
4.3.3 网络访问
原文地址:https://developers.openai.com/codex/cloud/internet-access
默认情况下,在 agent 执行阶段,Codex 不允许访问互联网,但可以在环境设置中为特定环境开启访问,并精细控制访问范围。
网络访问默认行为
- 默认关闭:在 agent 执行阶段,Codex 的互联网访问是 完全禁止的,以降低安全风险。
- Setup 阶段允许访问:只有在 setup 脚本阶段才允许访问互联网,用于安装依赖等操作。
启用互联网访问的风险
在 agent 执行阶段开启互联网访问可能带来安全问题,包括:
- 提示注入(Prompt Injection):代理从不可信网站读取内容并按照内容执行,可能导致信息泄露或执行不安全的操作。
- 敏感信息泄露:代码、密钥或最后的提交信息可能被发送到受控服务器。
- 恶意依赖或恶意资源下载:从不安全源下载代码或包可能包含恶意内容。
- 版权/许可证问题:从外部拉取的代码可能存在版权或许可限制。建议只允许访问可信域名,并严格审查日志与输出。
配置互联网访问(按环境设置)
Off(关闭):完全阻止 agent 在执行阶段访问互联网,这是默认设置。
On(开启) + 自定义控制:开启后你可以进一步控制域名允许列表(Domain Allowlist),可以选择:
- None → 空列表:从零开始自行添加可信域名。
- Common dependencies → 常见依赖域名列表:使用官方预设的一些常见依赖下载域名(如 npm、pypi 等)。
- All(无限制):允许访问所有域名。
之后还能手动添加或移除特定域名。
允许的 HTTP 方法
为了安全起见,你可以限定 agent 仅允许某些 HTTP 方法,例如:GET、HEAD、OPTIONS 等安全方法,禁止危险方法如 POST、PUT、DELETE 等,减少意外行为风险。
域名允许列表示例
官方提供了一个 常见依赖域名列表(Common dependencies),包括:
alpinelinux.org
anaconda.com
apache.org
apt.llvm.org
archlinux.org
azure.com
bitbucket.org
bower.io
centos.org
cocoapods.org
continuum.io
cpan.org
crates.io
debian.org
docker.com
docker.io
dot.net
dotnet.microsoft.com
eclipse.org
fedoraproject.org
gcr.io
ghcr.io
github.com
githubusercontent.com
gitlab.com
golang.org
google.com
goproxy.io
gradle.org
hashicorp.com
haskell.org
hex.pm
java.com
java.net
jcenter.bintray.com
json-schema.org
json.schemastore.org
k8s.io
launchpad.net
maven.org
mcr.microsoft.com
metacpan.org
microsoft.com
nodejs.org
npmjs.com
npmjs.org
nuget.org
oracle.com
packagecloud.io
packages.microsoft.com
packagist.org
pkg.go.dev
ppa.launchpad.net
pub.dev
pypa.io
pypi.org
pypi.python.org
pythonhosted.org
quay.io
ruby-lang.org
rubyforge.org
rubygems.org
rubyonrails.org
rustup.rs
rvm.io
sourceforge.net
spring.io
swift.org
ubuntu.com
visualstudio.com
yarnpkg.com
…
这些域名通常用于下载包、获取源代码、构建依赖等。
4.4 集成(Integrations)
4.4.1 Github
原文地址:https://developers.openai.com/codex/integrations/github
视频教程:https://youtu.be/HwbSWVg5Ln4
可以使用 Codex 在 GitHub 的 Pull Request(拉取请求)中执行代码审查,而无需离开 GitHub 界面。具体做法是在 Pull Request 的评论里写下@codex review,然后 Codex 会自动回复一个标准的 GitHub 代码审查。
4.4.1.1 设置代码审查
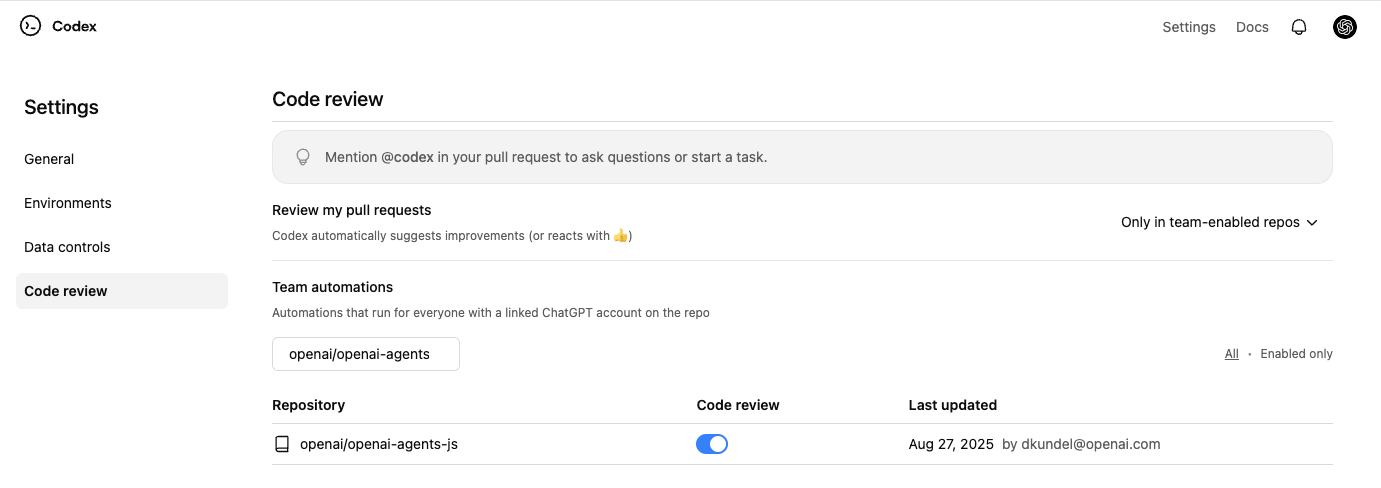
- 配置 Codex Cloud。
- 打开你的仓库设置,找到 Codex 设置 并为该仓库开启 代码审查(Code review) 功能,(界面里会有一个切换开关来启用代码审查。
在某个 Pull Request 里发表评论,写上@codex review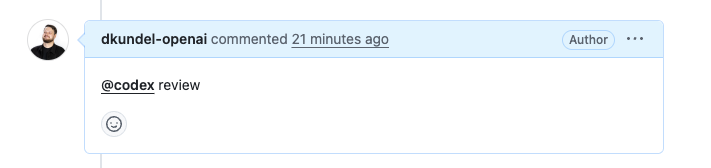
然后等待 Codex 处理并发布审查结果,就像一个团队成员那样发表评论。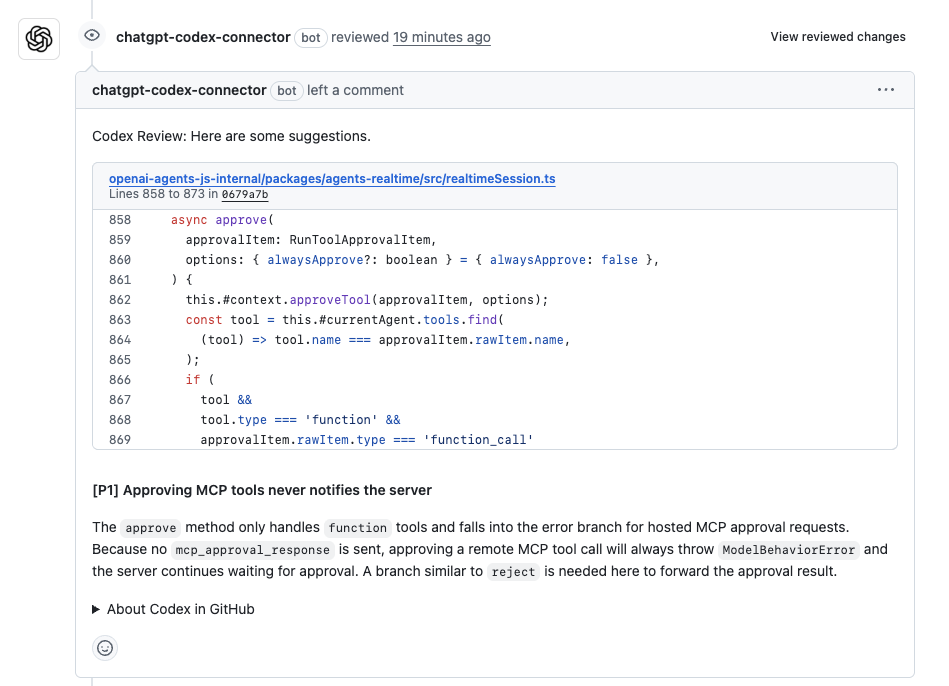
4.4.1.2 自定义 Codex 审查规则
默认情况下,Codex 会根据你的代码库中的 AGENTS.md 文件应用一些审查指南。你可以在仓库顶层添加或更新 AGENTS.md,写下自定义的审核规则。例如:
## Review guidelines
- 不要打印敏感个人信息(PII)。
- 确保每个路由都被身份验证中间件包裹。
这样,Codex 会按照这些规则执行审查,如果你在 Pull Request 评论里写类似:
@codex review for security regressions
Codex 会根据语义做更具体的审查。
4.4.1.3 给 Codex 指派其他任务
当你在评论里提到 @codex 并跟随其他指令(不是 review),Codex 会在云端将这个 Pull Request 作为上下文来创建一个新任务。例如:
@codex fix the CI failures
Codex 会尝试定位并修复 CI(持续集成)失败的问题。
4.4.2 Slack
可以在 Slack 的频道或线程里调用 Codex 来执行编码任务。只需在消息中提及 @Codex 并附上提示,Codex 会创建一个 云任务 并回复结果。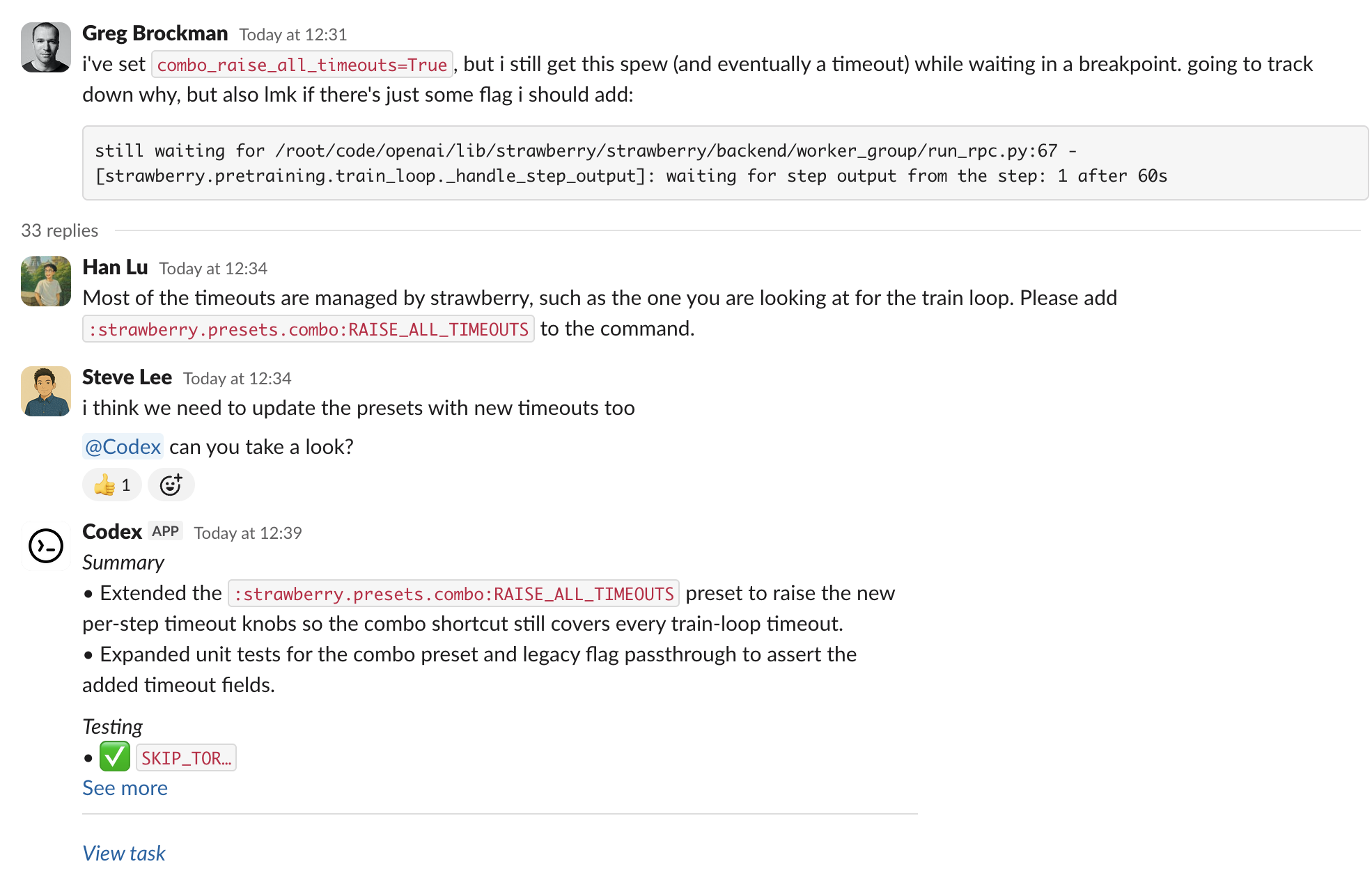
4.4.2.1 设置 Slack 应用
- 配置 Codex 云任务(Codex cloud tasks):需要一个 Plus、Pro、Business、Enterprise 或 Edu 计划,还需连接一个 GitHub 帐户 并至少有一个环境(environment)。
- 前往 Codex 设置 并为你的工作区安装 Slack 应用:根据 Slack 的策略,可能需要管理员批准安装。
- 在一个频道里添加
@Codex:如果还没添加,Slack 会在你提及时提示。
4.4.2.2 发起任务
在 Slack 的某个频道或线程内,提及 @Codex 并写出你的提示。Codex 能引用线程内早先的消息,因此通常不需要重复背景上下文。可以在提示里指定环境或仓库,这样能明确 Codex 使用哪个环境或代码仓库,例如:
@Codex 修复上面的内容 在 openai/codex
等待 Codex 做出反应并回复一个任务链接,任务完成后,Codex 会将结果发布在该线程中(视设置而定)。
4.4.2.3 Codex 如何选择环境和仓库
- Codex 会查看你有访问权限的环境,并从中选择最匹配你请求的一个。
- 如果请求不明确,它会回退到你最近使用过的环境。
- 任务会在该环境所列第一个仓库的默认分支上运行。你可以在 Codex 里更新仓库映射,以更改默认仓库或添加更多仓库。
- 如果没有适合的环境或仓库,Codex 会在 Slack 中回复说明,提示你如何修复问题再重试。
4.4.2.4 企业数据控制
默认情况下,Codex 会在线程中发布结果,这可能包括它所运行环境的信息。如果你希望 Codex 只发送任务链接而不包含答案,企业管理员可以在 ChatGPT 工作区设置中关闭 “允许 Codex Slack 应用在任务完成时发布答案” 选项。
4.4.2.5 数据使用、隐私与安全
当提及 @Codex 时,Slack 的消息内容和线程历史会被发送给 Codex 以理解请求并创建任务。数据处理遵循 OpenAI 隐私政策、使用条款 以及其他适用政策。
注意:Codex 使用大型语言模型生成回答,它可能会犯错。请始终自行复查结果和 diff。
4.4.2.6 提示与故障排查
常见问题及解决方法:
- 连接丢失:如果 Codex 无法确认你的 Slack 或 GitHub 连接,它会回复一个重新连接的链接。
- 环境选择错误:你可以在线程中用自然语言指出希望使用的环境(例如
请在 openai/openai 环境运行),然后再次 mention@Codex。 - 长线程或复杂上下文:把关键信息摘要写在最新消息里,以免上下文被埋没。
- 工作区发布限制:某些企业工作区可能限制发布最终答案,这种情况下可以点击任务链接查看进度和结果。
4.4.3 Linear
原文地址:https://developers.openai.com/codex/integrations/linear
如果在 Linear 任务中运行 Codex,可以:
- 使用 Linear 中的 Codex 可以 从 issue(问题/任务)中委派工作。
- 可以 将某个 issue 分配给 Codex,或者在评论中提到
@Codex,Codex 会创建一个云端任务并回复进度与结果。
4.4.3.1 设置 Linear
按照下面步骤配置 Linear 与 Codex 的联动:
- 先通过在 Codex 中连接 GitHub 并为要让 Codex 工作的仓库创建环境 来设置 Codex Cloud Tasks。
- 进入 Codex 设置 并 为你的工作区安装 Linear 的 Codex 集成。
- 通过在 Linear issue 的评论线程中提到
@Codex来 链接你的 Linear 账户。
4.4.3.2 如何将工作委派给 Codex?
你可以通过下面两种方式委派任务:
1) 将 issue 分配给 Codex:安装并启用集成后,你可以像将任务分配给团队成员一样,将 issue 分配给 Codex。 Codex 会开始处理任务,并在 issue 中发布进度更新。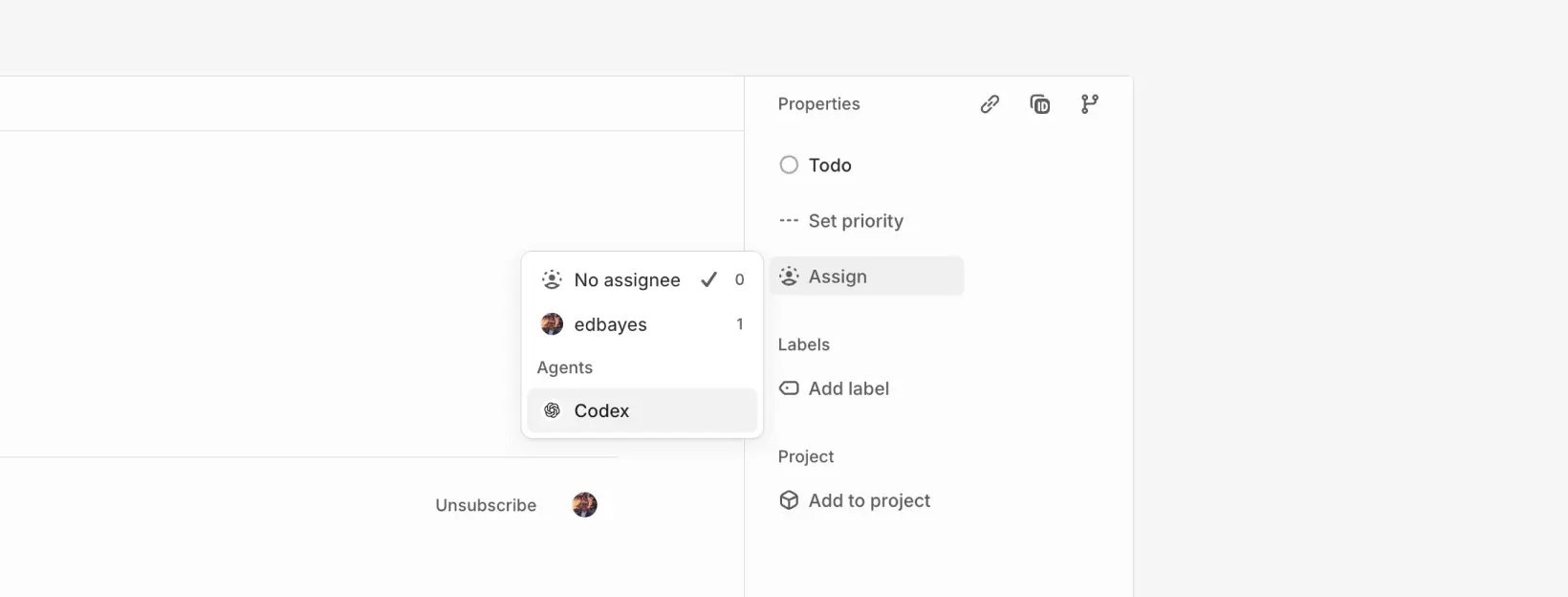
2) 在评论中提及 @Codex:也可以在评论中写 @Codex 来委派任务或提问。Codex 回复后,你可以在同一个评论线程中继续提问或增加说明以延续当前会话。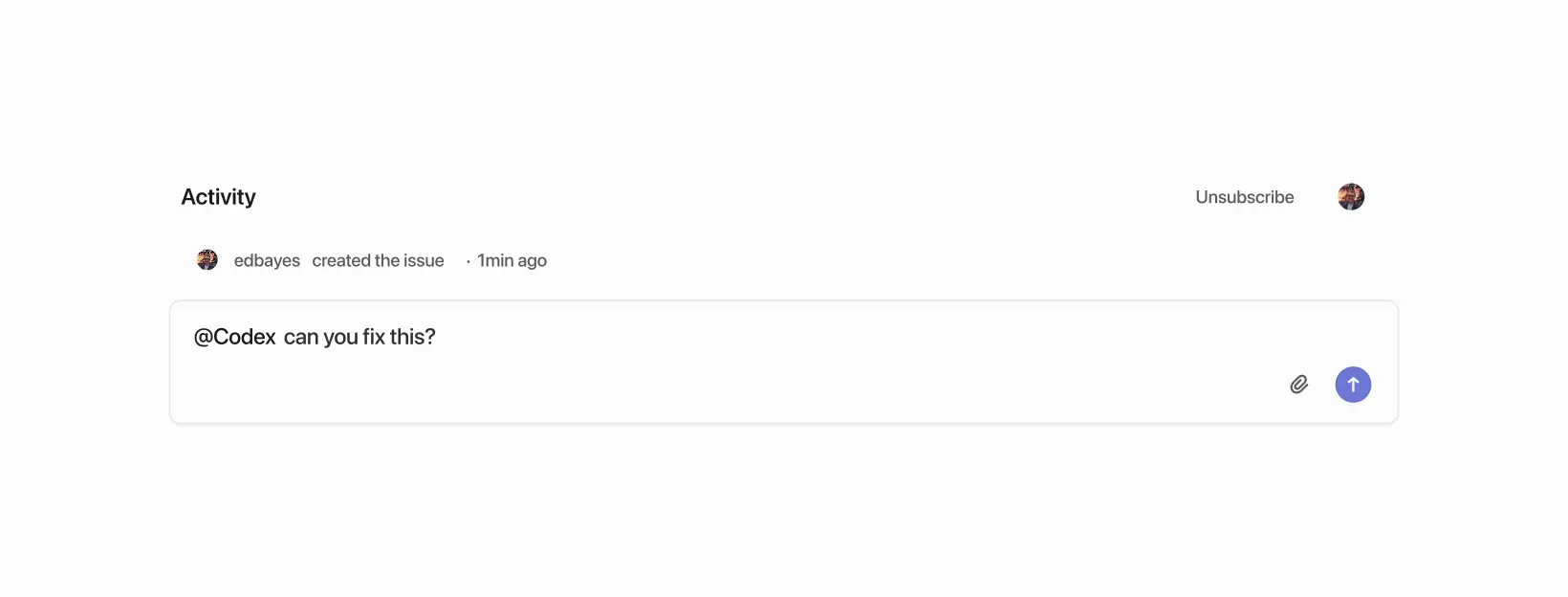
4.4.3.3 环境与仓库如何被 Codex 选中
Codex 开始工作后,会根据 issue 内容选择 合适的环境和仓库,如果你想指定固定仓库,可以在评论中写清楚,例如:
@Codex fix this in openai/codex
如果建议不明确,Codex 会采用最近一次使用的环境。任务默认运行在该环境仓库列表中第一个仓库的默认分支上。如需更改默认仓库或加入更多仓库,你可以在 Codex 配置中更新环境的仓库映射。
4.4.3.4 查看 Codex 的进展
可以 在 issue 的 Activity(活动)视图 中查看更新,点击任务链接查看更详细的进度,当任务完成后,Codex 会发布摘要并附上完成任务的链接,你可以据此创建 Pull Request(PR)。
4.4.3.5 自动将 Issue 指派给 Codex
可以通过设置 triage rules(初筛规则)自动将新 issue 分派给 Codex:
- 在 Linear 侧边栏进入 Settings(设置)。
- 在 Your teams(你的团队) 下选择你想要设置的团队。
- 打开 Workflow(工作流) → Triage(初筛)。
- 新建规则并设置将符合条件的 issue 委派给 Codex。
- 新任务符合规则后将自动分配给 Codex 执行。
当使用 triage 规则自动委派时,Codex 会使用 issue 创建者的账户 来运行任务。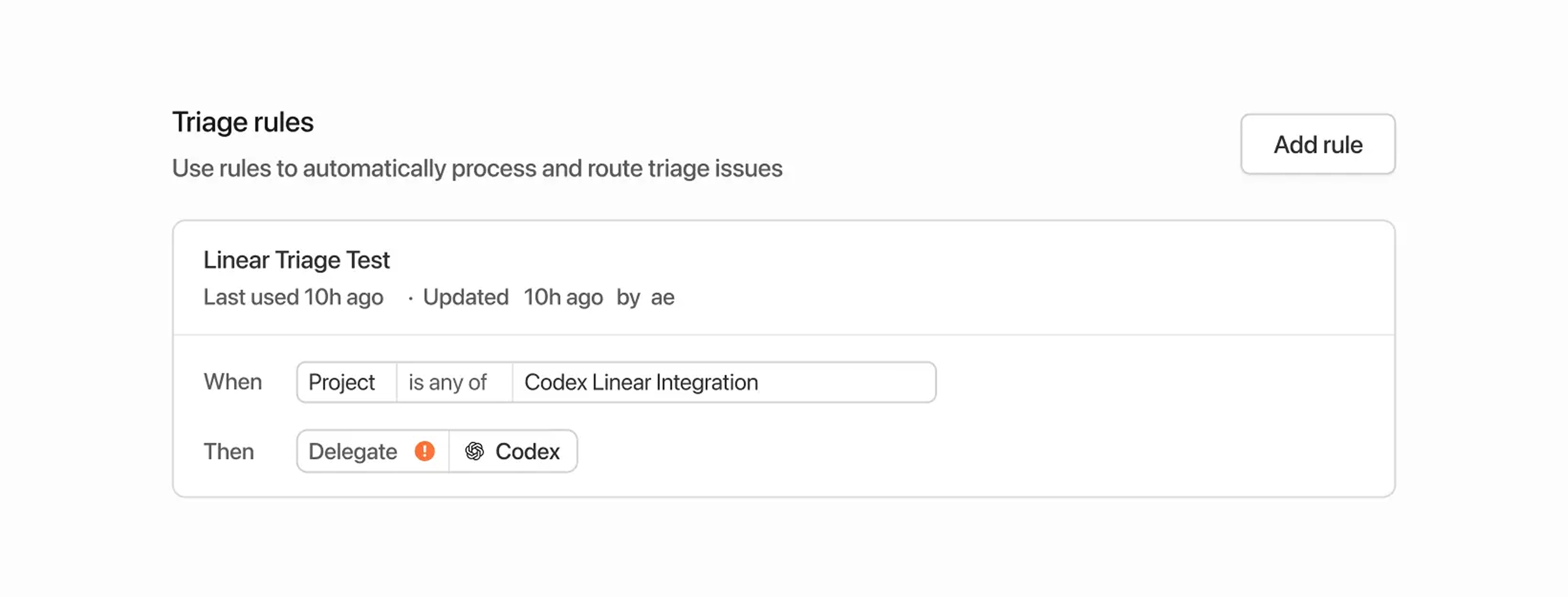
4.4.3.6 数据使用、隐私与安全
当你 mention 尽量写清楚你想让 Codex 做什么,因为 Codex 会读取这段内容来理解请求并生成任务。数据处理遵循 OpenAI 的隐私政策与使用条款;详见官方文档。 Codex 生成的内容可能不总是正确,你仍需手动审核其回答和 diffs(变更差异)。
4.4.3.7 常见提示与故障排查
连接失败:如果 Codex 无法确认链接,它会在 issue 中回复一个连接账户的链接。
环境被选错了:在评论中补充你想要的环境,这样可指导 Codex 选择正确环境执行任务,例如:
@Codex please run this in openai/codex
代码上下文不准确或不完整:提供更多上下文或明确指令,有助于 Codex 更准确完成任务。
查看更多帮助:可以查阅 OpenAI 的帮助中心获取更完整的说明。
4.4.3.8 在本地通过 MCC 使用 Linear
如果你想让 Codex 在本地访问 Linear issue(如通过 CLI 或 IDE 扩展),可以使用 Codex 的 MCP(Model Context Protocol)服务器,推荐方法(CLI)
codex mcp add linear --url https://mcp.linear.app/mcp
执行后系统会提示登录 Linear,完成账户连接。也可以使用手动方法,在 ~/.codex/config.toml 文件中添加:
[mcp_servers.linear]
url = "https://mcp.linear.app/mcp"
然后运行,即可手动连接 Linear:
codex mcp login linear
好,这里给你一版第一人称(博主视角)+ 精简概括型的整篇博客小结,偏“收束观点 + 给读者方向”,不铺细节、不啰嗦:
4.5 小结
本章对比了 IDE、CLI、Cloud(Web)以及 GitHub / Slack / Linear 等集成入口的定位与适用场景。
一个实用的选择原则是:写改与即时反馈用 IDE;批处理、脚本与审查用 CLI;并行/长任务用 Cloud;团队协作则把 Codex 放进现有流程。
建议你先固定一套自己最常用场景的“输入 → 执行 → 验证 → 交付”模板,后续再通过 config、rules 与 skills 逐步工程化。
05 配置篇:config.toml(模型 / 审批 / 沙箱)
本章是本合集的配置篇,聚焦 Codex 本地运行的“控制面板”——~/.codex/config.toml。如果你已经能跑通一次基本会话,本章将帮助你把模型选择、审批策略与沙箱边界调整到适合自己的工作流。
Codex 会在本地执行命令、读写文件、请求审批,其行为几乎完全由 ~/.codex/config.toml 决定。默认配置虽然安全,但在真实工程场景下往往限制较多。
本文将围绕 Codex 的配置体系展开,从基础配置到高级用法,重点说明每个关键配置项的作用与影响范围,帮助大家快速搭建一套符合自己工作流的 Codex 运行环境。
5.1 基础配置
Codex 会从 ~/.codex/config.toml 读取本地设置,你可以使用这个文件来更改默认值(比如模型)、设置审批与沙箱行为,以及配置 MCP 服务器。
5.1.1 配置文件
Codex 将其配置存储在:~/.codex/config.toml,要从 Codex IDE 扩展打开该配置文件:
- 点击右上角的齿轮图标;
- 选择 Codex 设置(Codex Settings);
- 然后选择 打开 config.toml(Open config.toml)
CLI 与 IDE 扩展共用同一个 config.toml 文件。你可以使用它来:
- 设置默认模型与提供商
- 配置审批策略与沙箱设置
- 配置 MCP 服务器
5.1.2 配置优先级
Codex 在解析值时遵循以下顺序:
- CLI 标志(例如
--model); - 通过
--profile <名称>指定的配置文件值(Profile); config.toml顶层值;- 内置默认值 。
使用这种优先级意味着你可以在顶层设置共享默认值,将可变的值保持在 Profile 中,要进行单次覆盖(包括 TOML 引号规则),请参阅高级配置(Advanced Config):https://developers.openai.com/codex/config-advanced#one-off-overrides-from-the-cli
备注:在受管理的机器上,你的组织也可能通过
requirements.toml强制执行约束,例如不允许approval_policy = "never"或sandbox_mode = "danger-full-access"。
5.1.3 常见配置选项
以下是最常修改的一些配置,所有示例都在 config.toml 顶层配置中设置。
① 默认模型:选择 CLI 和 IDE 中 Codex 默认使用的模型
model = "gpt-5.2"
② 审批提示: 控制 Codex 在执行生成命令之前何时暂停询问
approval_policy = "on-request"
③ 沙箱级别:调整 Codex 在执行命令时对文件系统和网络访问的程度
sandbox_mode = "workspace-write"
④ 推理强度:调整在模型支持时 Codex 使用多少推理能力
model_reasoning_effort = "high"
⑤ 命令环境:限制或扩展哪些环境变量会被传递给被启动的命令:
[shell_environment_policy]
include_only = ["PATH", "HOME"]
5.1.4 功能开关
可选的实验性功能可以通过 config.toml 中的 [features] 表来切换:
[features]
shell_snapshot = true # 加快重复命令的速度
web_search_request = true # 允许模型请求网页搜索
支持的功能(成熟度标签表示该功能的稳定性与实验性质,可以根据需要选择开启或保持默认):
| 键 | 默认值 | 成熟度 | 描述 |
|---|---|---|---|
| apply_patch_freeform | false | Experimental | 包含自由形式的 apply_patch 工具 |
| elevated_windows_sandbox | false | Experimental | 使用提升权限的 Windows 沙箱 |
| exec_policy | true | Experimental | 对 shell / unified_exec 强制策略检查 |
| experimental_windows_sandbox | false | Experimental | 使用 Windows 限制令牌沙箱 |
| remote_compaction | true | Experimental | 启用远程压缩(仅限 ChatGPT 授权) |
| remote_models | false | Experimental | 刷新远程模型列表以显示可用性 |
| shell_snapshot | false | Beta | 快速完成重复命令 |
| shell_tool | true | Stable | 启用默认的 shell 工具 |
| unified_exec | false | Beta | 使用统一的 PTY 执行工具 |
| undo | true | Stable | 支持通过每次操作的 git 快照进行撤销 |
| web_search_request | false | Stable | 允许模型发起网页搜索请求 |
如果要快速启用某个功能,可以 在 config.toml 的 [features] 部分添加:
feature_name = true
或者从命令行运行:
codex --enable feature_name
如果要同时启用多个功能:
codex --enable feature_a --enable feature_b
要停用某个功能,将其设置为:
feature_name = false
这样就可以灵活控制 Codex 的实验性与高级功能。
5.2 高级配置
5.2.1 Profiles
Profiles 允许你保存一组具名的配置集合,并在 CLI 中快速切换。
Profiles 目前仍处于实验阶段,未来版本中可能会变更或移除;
Codex IDE 扩展目前 不支持 Profiles。
在 config.toml 中通过 [profiles.<name>] 定义profiles,然后运行:
codex --profile <name>
示例:
model = "gpt-5-codex"
approval_policy = "on-request"
[profiles.deep-review]
model = "gpt-5-pro"
model_reasoning_effort = "high"
approval_policy = "never"
[profiles.lightweight]
model = "gpt-4.1"
approval_policy = "untrusted"
如果你想让某个 profile 成为默认值,可在 config.toml 顶层添加:
profile = "deep-review"
除非在命令行中显式覆盖,否则 Codex 会自动加载该 profile。
5.2.2 通过 CLI 进行单次覆盖
除了编辑 ~/.codex/config.toml 之外,你还可以在 单次运行时 通过 CLI 覆盖配置:
- 优先使用已有的专用参数(例如
--model) - 如需覆盖任意键,使用
-c / --config
示例:
# 专用参数
codex --model gpt-5.2
# 通用键值覆盖(值是 TOML,而不是 JSON)
codex --config model='"gpt-5.2"'
codex --config sandbox_workspace_write.network_access=true
codex --config 'shell_environment_policy.include_only=["PATH","HOME"]'
注意事项:
- 配置键支持 点号语法 来设置嵌套值(例如:
mcp_servers.context7.enabled=false); --config的值会按 TOML 解析;- 如有疑问,请加引号以避免
shell按空格拆分,如果无法解析为 TOML,Codex 会将其当作字符串处理。
5.2.3 配置与状态文件位置
Codex 会将本地状态存储在 CODEX_HOME 目录下(默认是 ~/.codex),你可能会看到的常见文件包括:
config.toml:本地配置;auth.json:使用文件方式存储凭据时或系统的 keychain / keyring;history.jsonl:启用历史记录持久化时,其他每用户状态,例如日志和缓存。
关于认证(包括凭据存储方式)的更多细节,请参见 Authentication,完整配置键列表请参见 Configuration Reference。
5.2.4 项目根目录检测
Codex 会从当前工作目录向上查找项目配置(例如 .codex/ 层级和 AGENTS.md),直到找到“项目根目录”,默认情况下,只要目录中包含 .git,就会被视为项目根目录,可以在 config.toml 中自定义该行为:
# 当目录中包含以下任意标记时,将其视为项目根目录
project_root_markers = [".git", ".hg", ".sl"]
如果设置为空数组:
project_root_markers = []
则 Codex 不再向上搜索父目录,而是将当前工作目录视为项目根目录。
5.2.5 自定义模型提供方
模型提供方定义了 Codex 如何连接模型(基础 URL、API 协议、可选 HTTP 头),你可以定义额外的提供方,并通过 model_provider 指向它们:
model = "gpt-5.1"
model_provider = "proxy"
[model_providers.proxy]
name = "OpenAI using LLM proxy"
base_url = "http://proxy.example.com"
env_key = "OPENAI_API_KEY"
[model_providers.ollama]
name = "Ollama"
base_url = "http://localhost:11434/v1"
[model_providers.mistral]
name = "Mistral"
base_url = "https://api.mistral.ai/v1"
env_key = "MISTRAL_API_KEY"
如有需要,可添加请求头:
[model_providers.example]
http_headers = { "X-Example-Header" = "example-value" }
env_http_headers = { "X-Example-Features" = "EXAMPLE_FEATURES" }
5.2.6 OpenAI 基础 URL 覆盖
如果你只是想让内置 OpenAI 提供方指向一个 LLM 代理或路由器,可以直接设置 OPENAI_BASE_URL,无需修改 config.toml:
export OPENAI_BASE_URL="https://api.openai.com/v1"
codex
5.2.7 OSS 模式(本地模型提供方)
当你使用 --oss 参数时,Codex 可以运行在本地“开源”模型提供方之上(例如 Ollama 或 LM Studio),如果使用 --oss 但未指定提供方,Codex 会使用 oss_provider 作为默认值:
# 使用 --oss 时的默认本地提供方
oss_provider = "ollama" # 或 "lmstudio"
5.2.8 Azure 提供方及单独调优
[model_providers.azure]
name = "Azure"
base_url = "https://YOUR_PROJECT_NAME.openai.azure.com/openai"
env_key = "AZURE_OPENAI_API_KEY"
query_params = { api-version = "2025-04-01-preview" }
wire_api = "responses"
[model_providers.openai]
request_max_retries = 4
stream_max_retries = 10
stream_idle_timeout_ms = 300000
5.2.9 模型推理、输出冗长度与限制
model_reasoning_summary = "none" # 禁用推理摘要
model_verbosity = "low" # 缩短回复
model_supports_reasoning_summaries = true # 强制启用推理
model_context_window = 128000 # 上下文窗口大小
model_verbosity仅对使用 Responses API 的提供方生效。 Chat Completions 提供方会忽略该设置。
5.2.10 审批策略与沙箱模式
选择审批严格度(影响 Codex 何时暂停)以及沙箱级别(影响文件 / 网络访问)。更深入的示例请参见 Sandbox & approvals。
approval_policy = "untrusted" # 其他选项:on-request, on-failure, never
sandbox_mode = "workspace-write"
[sandbox_workspace_write]
exclude_tmpdir_env_var = false # 允许 $TMPDIR
exclude_slash_tmp = false # 允许 /tmp
writable_roots = ["/Users/YOU/.pyenv/shims"]
network_access = false # 是否允许外部网络访问
在
workspace-write模式下,某些环境仍会将.git/和.codex/设为只读。因此,即使工作区可写,git commit等命令仍可能需要审批,如果你希望 Codex 跳过特定命令(例如阻止沙箱外的git commit),请使用 rules。
完全禁用沙箱(⚠️仅在你的环境已自行隔离进程时使用):
sandbox_mode = "danger-full-access"
5.2.11 Shell 环境变量策略
shell_environment_policy 控制 Codex 启动子进程时传递哪些环境变量(例如执行模型提出的工具命令时)。可以从一个干净环境(inherit = "none")或精简环境(inherit = "core")开始,再叠加排除、包含和覆盖规则,避免泄露密钥,同时仍保留必要路径或标志。
[shell_environment_policy]
inherit = "none"
set = { PATH = "/usr/bin", MY_FLAG = "1" }
ignore_default_excludes = false
exclude = ["AWS_*", "AZURE_*"]
include_only = ["PATH", "HOME"]
匹配规则为不区分大小写的 glob 模式(*, ?, [A-Z])。当 ignore_default_excludes = false 时,会在你自定义规则前自动过滤 KEY/SECRET/TOKEN。
5.2.12 可观测性与遥测
你可以启用 OpenTelemetry(OTel)日志导出,用于跟踪 Codex 运行情况(API 请求、SSE 事件、提示词、工具审批 / 结果等)。默认关闭,需要在 [otel] 中显式启用:
[otel]
environment = "staging" # 默认为 "dev"
exporter = "none" # 可设为 otlp-http 或 otlp-grpc
log_user_prompt = false # 默认不记录用户提示内容
选择导出器:
[otel]
exporter = { otlp-http = {
endpoint = "https://otel.example.com/v1/logs",
protocol = "binary",
headers = { "x-otlp-api-key" = "${OTLP_TOKEN}" }
}}
[otel]
exporter = { otlp-grpc = {
endpoint = "https://otel.example.com:4317",
headers = { "x-otlp-meta" = "abc123" }
}}
当 exporter = "none" 时,Codex 会记录事件但不会发送,导出器会异步批量发送,并在退出时刷新。
会发送哪些事件?
Codex 会为运行和工具使用发送结构化日志事件,示例包括:
codex.conversation_starts(model, reasoning settings, sandbox/approval policy)codex.api_requestandcodex.sse_event(durations, status, token counts)codex.user_prompt(length; content redacted unless explicitly enabled)codex.tool_decision(approved/denied and whether the decision came from config vs user)codex.tool_result(duration, success, output snippet)
更详细的安全与隐私说明请参见 Security。
指标(Metrics)
默认情况下,Codex 会周期性地向 OpenAI 发送少量匿名使用与健康数据,用于检测故障并了解功能使用情况。这些数据 不包含任何 PII(个人可识别信息),如需完全关闭指标收集:
[analytics]
enabled = false
默认上下文字段(适用于所有事件 / 指标)
surfaceversionauth_modemodel
指标目录
| Metric | Type | Fields | Description |
|---|---|---|---|
features.state |
counter | key, value |
Feature values that differ from defaults (emit one row per non-default). |
thread.started |
counter | is_git |
New thread created. |
task.compact |
counter | type |
Number of compactions per type (remote or local), including manual and auto. |
task.user_shell |
counter | Number of user shell actions (! in the TUI for example). |
|
task.review |
counter | Number of reviews triggered. | |
approval.requested |
counter | tool, approved |
Tool approval request result (approved: yes or no). |
conversation.turn.count |
counter | User/assistant turns per thread, recorded at the end of the thread. | |
mcp.call |
counter | status |
MCP tool invocation result (ok or error string). |
model.call.duration_ms |
histogram | status, attempt |
Model API request duration. |
tool.call |
counter | tool, status |
Tool invocation result (ok or error string). |
tool.call.duration_ms |
histogram | tool, success |
Tool execution time. |
user.feedback.submitted |
counter | category, include_logs, success |
Feedback submission via /feedback. |
反馈控制
默认支持通过 /feedback 提交反馈,如需禁用:
[feedback]
enabled = false
隐藏或显示推理事件
hide_agent_reasoning = true
show_raw_agent_reasoning = true
仅在你的工作流允许的情况下启用原始推理内容。
通知
使用 notify 在 Codex 触发事件时调用外部程序(目前支持 agent-turn-complete)。
notify = ["python3", "/path/to/notify.py"]
示例脚本:
#!/usr/bin/env python3
import json, subprocess, sys
def main() -> int:
notification = json.loads(sys.argv[1])
if notification.get("type") != "agent-turn-complete":
return 0
title = f"Codex: {notification.get('last-assistant-message', 'Turn Complete!')}"
message = " ".join(notification.get("input-messages", []))
subprocess.check_output([
"terminal-notifier",
"-title", title,
"-message", message,
"-group", "codex-" + notification.get("thread-id", ""),
"-activate", "com.googlecode.iterm2",
])
return 0
if __name__ == "__main__":
sys.exit(main())
历史记录持久化
默认情况下,Codex 会将会话记录保存在 CODEX_HOME 下:
[history]
persistence = "none"
限制历史文件大小:
[history]
max_bytes = 104857600 # 100 MiB
可点击的文件引用
file_opener = "vscode" # 或 cursor, windsurf, vscode-insiders, none
5.2.13 项目指令发现
Codex 会读取 AGENTS.md 并在会话首轮中注入项目指引,相关配置:
project_doc_max_bytesproject_doc_fallback_filenames
详见 Custom instructions with AGENTS.md。
5.2.14 TUI options
TUI(终端界面)选项
直接运行 codex 会启动交互式 TUI,专属配置位于 [tui] 下,包括:
tui.notificationstui.animationstui.scroll_*
5.3 完整配置参考
以下是 Codex 的 config.toml 和 requirements.toml 的完整参考文档。
5.3.1 config.toml
用户级别的配置位于:~/.codex/config.toml
| Key | Type / Values | Details |
|---|---|---|
| approval_policy | untrusted | on-failure |
| chatgpt_base_url | string | 覆盖 ChatGPT 登录流程中使用的基础 URL。 |
| check_for_update_on_startup | boolean | 在启动时检查 Codex 更新(仅在更新由集中管理时才设置为 false)。 |
| cli_auth_credentials_store | file | keyring |
| compact_prompt | string | 内联覆盖用于历史压缩的提示词。 |
| developer_instructions | string | 注入到会话中的额外开发者指令(可选)。 |
| disable_paste_burst | boolean | 在 TUI 中禁用批量粘贴检测。 |
| experimental_compact_prompt_file | string (path) | 从文件加载历史压缩提示词的覆盖版本(实验性)。 |
| experimental_instructions_file | string (path) | 实验性:使用该文件替代内置指令,而不是 AGENTS.md。 |
| experimental_use_freeform_apply_patch | boolean | 启用自由格式 apply_patch 的旧名称;推荐使用 [features].apply_patch_freeform 或 codex --enable apply_patch_freeform。 |
| experimental_use_unified_exec_tool | boolean | 启用 unified exec 的旧名称;推荐使用 [features].unified_exec 或 codex --enable unified_exec。 |
| features.apply_patch_freeform | boolean | 暴露自由格式的 apply_patch 工具(实验性)。 |
| features.elevated_windows_sandbox | boolean | 启用提升权限的 Windows 沙箱管道(实验性)。 |
| features.exec_policy | boolean | 对 shell / unified_exec 强制执行规则检查(实验性;默认开启)。 |
| features.experimental_windows_sandbox | boolean | 运行 Windows 受限令牌沙箱(实验性)。 |
| features.powershell_utf8 | boolean | 强制 PowerShell 使用 UTF-8 输出(默认 true)。 |
| features.remote_compaction | boolean | 启用远程历史压缩(仅 ChatGPT 登录;实验性;默认开启)。 |
| features.remote_models | boolean | 在显示就绪状态前刷新远程模型列表(实验性)。 |
| features.shell_snapshot | boolean | 对 shell 环境进行快照以加速重复命令(beta)。 |
| features.shell_tool | boolean | 启用默认的 shell 工具以运行命令(稳定版;默认开启)。 |
| features.tui2 | boolean | 启用 TUI2 界面(实验性)。 |
| features.unified_exec | boolean | 使用统一的、基于 PTY 的 exec 工具(beta)。 |
| features.web_search_request | boolean | 允许模型发起 Web 搜索请求(稳定)。 |
| feedback.enabled | boolean | 通过 /feedback 启用跨 Codex 界面的反馈提交(默认 true)。 |
| file_opener | vscode | vscode-insiders |
| forced_chatgpt_workspace_id | string (uuid) | 将 ChatGPT 登录限制到指定的工作区标识符。 |
| forced_login_method | chatgpt | api |
| hide_agent_reasoning | boolean | 在 TUI 和 codex exec 输出中隐藏推理事件。 |
| history.max_bytes | number | 如果设置,将通过丢弃最旧条目来限制历史文件大小(字节)。 |
| history.persistence | save-all | none |
| include_apply_patch_tool | boolean | 启用自由格式 apply_patch 的旧名称;推荐使用 [features].apply_patch_freeform。 |
| instructions | string | 保留供未来使用;推荐使用 experimental_instructions_file 或 AGENTS.md。 |
| mcp_oauth_credentials_store | auto | file |
| mcp_servers..args | array | 传递给 MCP stdio server 命令的参数。 |
| mcp_servers..bearer_token_env_var | string | 为 MCP HTTP server 提供 bearer token 的环境变量。 |
| mcp_servers..command | string | MCP stdio server 的启动命令。 |
| mcp_servers..cwd | string | MCP stdio server 进程的工作目录。 |
| mcp_servers..disabled_tools | array | 在 enabled_tools 之后应用的工具拒绝列表。 |
| mcp_servers..enabled | boolean | 在不移除配置的情况下禁用 MCP server。 |
| mcp_servers..enabled_tools | array | MCP server 暴露的工具名称白名单。 |
| mcp_servers..env | map<string,string> | 转发给 MCP stdio server 的环境变量。 |
| mcp_servers..env_http_headers | map<string,string> | 从环境变量填充的 HTTP Header(用于 MCP HTTP server)。 |
| mcp_servers..env_vars | array | 额外允许的 MCP stdio server 环境变量白名单。 |
| mcp_servers..http_headers | map<string,string> | 每次 MCP HTTP 请求都会包含的静态 Header。 |
| mcp_servers..startup_timeout_ms | number | startup_timeout_sec 的毫秒别名。 |
| mcp_servers..startup_timeout_sec | number | 覆盖 MCP server 默认 10 秒的启动超时。 |
| mcp_servers..tool_timeout_sec | number | 覆盖 MCP server 默认 60 秒的单工具超时。 |
| mcp_servers..url | string | MCP 可流式 HTTP server 的端点。 |
| model | string | 使用的模型(例如 gpt-5-codex)。 |
| model_auto_compact_token_limit | number | 触发自动历史压缩的 token 阈值(未设置则使用模型默认值)。 |
| model_context_window | number | 当前模型可用的上下文窗口 token 数。 |
| model_provider | string | 来自 model_providers 的 provider id(默认:openai)。 |
| model_providers..base_url | string | 模型提供方的 API 基础 URL。 |
| model_providers..env_http_headers | map<string,string> | 从环境变量填充的 HTTP Header。 |
| model_providers..env_key | string | 提供方 API Key 所在的环境变量。 |
| model_providers..env_key_instructions | string | 可选的 API Key 配置说明。 |
| model_providers..experimental_bearer_token | string | 直接提供 bearer token(不推荐;请使用 env_key)。 |
| model_providers..http_headers | map<string,string> | 添加到提供方请求中的静态 HTTP Header。 |
| model_providers..name | string | 自定义模型提供方的显示名称。 |
| model_providers..query_params | map<string,string> | 附加到请求中的额外查询参数。 |
| model_providers..request_max_retries | number | 提供方 HTTP 请求的最大重试次数(默认 4)。 |
| model_providers..requires_openai_auth | boolean | 提供方是否使用 OpenAI 认证(默认 false)。 |
| model_providers..stream_idle_timeout_ms | number | SSE 流的空闲超时(毫秒,默认 300000)。 |
| model_providers..stream_max_retries | number | SSE 流中断的最大重试次数(默认 5)。 |
| model_providers..wire_api | chat | responses |
| model_reasoning_effort | minimal | low |
| model_reasoning_summary | auto | concise |
| model_supports_reasoning_summaries | boolean | 即使是未知模型也强制 Codex 发送推理元数据。 |
| model_verbosity | low | medium |
| notice.hide_full_access_warning | boolean | 记录是否确认“完全访问权限”警告。 |
| notice.hide_gpt-5.1-codex-max_migration_prompt | boolean | 记录是否确认 gpt-5.1-codex-max 迁移提示。 |
| notice.hide_gpt5_1_migration_prompt | boolean | 记录是否确认 GPT-5.1 迁移提示。 |
| notice.hide_rate_limit_model_nudge | boolean | 记录是否选择退出速率限制模型切换提示。 |
| notice.hide_world_writable_warning | boolean | 记录是否确认 Windows 全局可写目录警告。 |
| notice.model_migrations | map<string,string> | 记录已确认的模型迁移映射(旧 → 新)。 |
| notify | array | 用于通知的命令;会接收来自 Codex 的 JSON 负载。 |
| oss_provider | lmstudio | ollama |
| otel.environment | string | 应用于 OpenTelemetry 事件的环境标签(默认 dev)。 |
| otel.exporter | none | otlp-http |
| otel.exporter..endpoint | string | OTEL 日志导出端点。 |
| otel.exporter..headers | map<string,string> | OTEL 导出请求中包含的静态 Header。 |
| otel.exporter..protocol | binary | json |
| otel.exporter..tls.ca-certificate | string | OTEL 导出器 TLS 的 CA 证书路径。 |
| otel.exporter..tls.client-certificate | string | OTEL 导出器 TLS 的客户端证书路径。 |
| otel.exporter..tls.client-private-key | string | OTEL 导出器 TLS 的客户端私钥路径。 |
| otel.log_user_prompt | boolean | 选择是否在 OpenTelemetry 日志中导出原始用户提示词。 |
| otel.trace_exporter | none | otlp-http |
| otel.trace_exporter..endpoint | string | Trace 导出端点。 |
| otel.trace_exporter..headers | map<string,string> | Trace 导出请求的静态 Header。 |
| otel.trace_exporter..protocol | binary | json |
| otel.trace_exporter..tls.ca-certificate | string | Trace 导出器 TLS 的 CA 证书路径。 |
| otel.trace_exporter..tls.client-certificate | string | Trace 导出器 TLS 的客户端证书路径。 |
| otel.trace_exporter..tls.client-private-key | string | Trace 导出器 TLS 的客户端私钥路径。 |
| profile | string | 启动时应用的默认 profile(等价于 --profile)。 |
| profiles..* | various | 对任意支持配置项的 profile 级别覆盖。 |
| profiles..experimental_use_freeform_apply_patch | boolean | 启用自由格式 apply_patch 的旧名称。 |
| profiles..experimental_use_unified_exec_tool | boolean | 启用 unified exec 的旧名称。 |
| profiles..include_apply_patch_tool | boolean | 启用自由格式 apply_patch 的旧名称。 |
| profiles..oss_provider | lmstudio | ollama |
| project_doc_fallback_filenames | array | 当 AGENTS.md 缺失时尝试的额外文件名。 |
| project_doc_max_bytes | number | 构建项目指令时从 AGENTS.md 读取的最大字节数。 |
| project_root_markers | array | 用于查找项目根目录的标记文件名列表。 |
| projects. |
string | 将项目或 worktree 标记为受信任或不受信任("trusted" |
| review_model | string | /review 使用的模型覆盖。 |
| sandbox_mode | read-only | workspace-write |
| sandbox_workspace_write.exclude_slash_tmp | boolean | 在 workspace-write 模式下排除 /tmp。 |
| sandbox_workspace_write.exclude_tmpdir_env_var | boolean | 在 workspace-write 模式下排除 $TMPDIR。 |
| sandbox_workspace_write.network_access | boolean | 允许 workspace-write 沙箱内的外部网络访问。 |
| sandbox_workspace_write.writable_roots | array | workspace-write 模式下额外的可写目录。 |
| shell_environment_policy.exclude | array | 默认处理后移除的环境变量 glob 模式。 |
| shell_environment_policy.experimental_use_profile | boolean | 生成子进程时使用用户 shell profile。 |
| shell_environment_policy.ignore_default_excludes | boolean | 在其他过滤前保留包含 KEY/SECRET/TOKEN 的变量。 |
| shell_environment_policy.include_only | array | 白名单模式,仅保留匹配的变量。 |
| shell_environment_policy.inherit | all | core |
| shell_environment_policy.set | map<string,string> | 注入到每个子进程的显式环境变量。 |
| show_raw_agent_reasoning | boolean | 当模型输出推理时展示原始推理内容。 |
| skills.config | array | 存储在 config.toml 中的技能级别启用配置。 |
| skills.config..enabled | boolean | 启用或禁用对应技能。 |
| skills.config..path | string (path) | 包含 SKILL.md 的技能目录路径。 |
| tool_output_token_limit | number | 单个工具/函数输出存入历史的 token 上限。 |
| tui | table | TUI 专用选项,例如启用桌面内联通知。 |
| tui.animations | boolean | 启用终端动画(欢迎页、闪光、加载器)(默认 true)。 |
| tui.notifications | boolean | array |
| tui.scroll_events_per_tick | number | TUI2 中用于标准化滚动的事件密度。 |
| tui.scroll_invert | boolean | 反转 TUI2 的鼠标滚动方向。 |
| tui.scroll_mode | auto | wheel |
| tui.scroll_trackpad_accel_events | number | 触发 +1x 加速所需的触控板事件数。 |
| tui.scroll_trackpad_accel_max | number | 触控板滚动的最大加速倍数。 |
| tui.scroll_trackpad_lines | number | TUI2 的触控板滚动基础灵敏度。 |
| tui.scroll_wheel_like_max_duration_ms | number | 自动模式下回退为滚轮的持续时间阈值(毫秒)。 |
| tui.scroll_wheel_lines | number | TUI2 中每次滚轮刻度滚动的行数。 |
| tui.scroll_wheel_tick_detect_max_ms | number | 自动模式下滚轮刻度检测阈值(毫秒)。 |
| tui.show_tooltips | boolean | 在 TUI 欢迎界面显示新手提示(默认 true)。 |
| windows_wsl_setup_acknowledged | boolean | 记录 Windows 引导流程的确认状态(仅 Windows)。 |
5.3.2 requirements.toml
requirements.toml 是由管理员强制执行的配置文件,用于限制用户无法覆盖的安全敏感设置。
有关详情、路径和示例,请参见 Admin-enforced requirements
| Key | Type / Values | Details |
|---|---|---|
| allowed_approval_policies | array<string> |
approval_policy 允许使用的取值。 |
| allowed_sandbox_modes | array<string> |
sandbox_mode 允许使用的取值。 |
5.4 示例配置
下面的代码片段可以作为参考使用,只需将配置项和配置段复制到 ~/.codex/config.toml 中,然后根据你的实际环境调整相应的值。
# Codex 示例配置(config.toml)
#
# 本文件列出了 Codex 会从 config.toml 读取的所有键、它们的默认值,
# 以及简要说明。这里的值与 CLI 编译进来的“实际默认值”一致。
# 可按需调整。
#
# 备注
# - 根级键必须出现在 TOML 的表(table)之前。
# - 默认值为 “未设置(unset)” 的可选键会以注释形式展示并附带说明。
# - MCP 服务器、profiles(配置文件)以及模型提供方都是示例;可删除或修改。
################################################################################
# 核心模型选择
################################################################################
# Codex 使用的主模型。默认:所有平台均为 "gpt-5.2-codex"。
model = "gpt-5.2-codex"
# /review 功能(代码审查)使用的模型。默认:"gpt-5.2-codex"。
review_model = "gpt-5.2-codex"
# 从 [model_providers] 中选择的提供方 id。默认:"openai"。
model_provider = "openai"
# 用于 --oss 会话的默认开源提供方。未设置时,Codex 会提示选择。默认:未设置。
# oss_provider = "ollama"
# 可选的手动模型元数据。未设置时,Codex 会根据 model 自动检测。
# 取消注释以强制指定这些值。
# model_context_window = 128000 # token 数;默认:按模型自动决定
# model_auto_compact_token_limit = 0 # token 数;未设置时使用模型默认值
# tool_output_token_limit = 10000 # 每个工具输出存储的 token 数;对 gpt-5.2-codex 默认是 10000
################################################################################
# 推理与详细度(支持 Responses API 的模型)
################################################################################
# 推理强度:minimal | low | medium | high | xhigh(默认:medium;在 gpt-5.2-codex 与 gpt-5.2 上为 xhigh)
model_reasoning_effort = "medium"
# 推理摘要:auto | concise | detailed | none(默认:auto)
model_reasoning_summary = "auto"
# GPT-5 系列(Responses API)的文本输出详细度:low | medium | high(默认:medium)
model_verbosity = "medium"
# 为当前模型强制启用推理摘要(默认:false)
model_supports_reasoning_summaries = false
################################################################################
# 指令覆盖
################################################################################
# 额外的用户指令会在 AGENTS.md 之前注入。默认:未设置。
# developer_instructions = ""
#(已忽略)可选的旧版基础指令覆盖(建议使用 AGENTS.md)。默认:未设置。
# instructions = ""
# 历史压缩提示词(compaction prompt)的内联覆盖。默认:未设置。
# compact_prompt = ""
# 用文件路径覆盖内置的基础指令。默认:未设置。
# experimental_instructions_file = "/absolute/or/relative/path/to/instructions.txt"
# 从文件加载历史压缩提示词覆盖。默认:未设置。
# experimental_compact_prompt_file = "/absolute/or/relative/path/to/compact_prompt.txt"
################################################################################
# 通知
################################################################################
# 外部通知程序(argv 数组)。未设置时:禁用。
# 示例:notify = ["notify-send", "Codex"]
notify = [ ]
################################################################################
# 审批与沙箱
################################################################################
# 何时请求命令审批:
# - untrusted:仅已知安全的只读命令自动执行;其余命令会提示确认
# - on-failure:在沙箱中自动执行;仅在失败时提示升级/放权
# - on-request:由模型决定何时询问(默认)
# - never:从不询问(风险较大)
approval_policy = "on-request"
# 工具调用的文件系统/网络沙箱策略:
# - read-only(默认)
# - workspace-write
# - danger-full-access(无沙箱;极其危险)
sandbox_mode = "read-only"
################################################################################
# 认证与登录
################################################################################
# CLI 登录凭据的持久化方式:file(默认) | keyring | auto
cli_auth_credentials_store = "file"
# ChatGPT 认证流程的基础 URL(不是 OpenAI API)。默认:
chatgpt_base_url = "https://chatgpt.com/backend-api/"
# 将 ChatGPT 登录限制到指定 workspace id。默认:未设置。
# forced_chatgpt_workspace_id = ""
# 当 Codex 通常会自动选择时,强制指定登录机制。默认:未设置。
# 可选值:chatgpt | api
# forced_login_method = "chatgpt"
# MCP OAuth 凭据的首选存储方式:auto(默认) | file | keyring
mcp_oauth_credentials_store = "auto"
################################################################################
# 项目文档控制
################################################################################
# 从 AGENTS.md 中最多嵌入到首轮指令的字节数。默认:32768
project_doc_max_bytes = 32768
# 当某一层目录缺少 AGENTS.md 时,按顺序尝试的备用文件名。默认:[]
project_doc_fallback_filenames = []
# 在向上查找父目录时,用来识别项目根目录的标记文件名。默认:[".git"]
# project_root_markers = [".git"]
################################################################################
# 历史与文件打开方式
################################################################################
# 可点击引用(citations)的 URI scheme:vscode(默认) | vscode-insiders | windsurf | cursor | none
file_opener = "vscode"
################################################################################
# UI、通知与杂项
################################################################################
# 抑制内部推理事件的输出。默认:false
hide_agent_reasoning = false
# 当可用时显示原始推理内容。默认:false
show_raw_agent_reasoning = false
# 禁用 TUI 中的“突发粘贴(burst-paste)”检测。默认:false
disable_paste_burst = false
# 记录 Windows 入门设置确认(仅 Windows)。默认:false
windows_wsl_setup_acknowledged = false
# 启动时检查更新。默认:true
check_for_update_on_startup = true
################################################################################
# Profiles(命名预设)
################################################################################
# 当前启用的 profile 名称。未设置时,不应用任何 profile。
# profile = "default"
################################################################################
# Skills(按技能覆盖)
################################################################################
# 在不删除技能的情况下禁用或重新启用某个技能。
[[skills.config]]
# path = "/path/to/skill"
# enabled = false
################################################################################
# 实验性开关(旧版;优先使用 [features])
################################################################################
experimental_use_unified_exec_tool = false
# 通过自由编辑路径包含 apply_patch(影响默认工具集)。默认:false
experimental_use_freeform_apply_patch = false
################################################################################
# 沙箱设置(表)
################################################################################
# 仅在 sandbox_mode = "workspace-write" 时使用的额外设置。
[sandbox_workspace_write]
# 除工作区(cwd)外额外允许写入的根目录。默认:[]
writable_roots = []
# 允许在沙箱内进行出站网络访问。默认:false
network_access = false
# 将 $TMPDIR 从可写根目录中排除。默认:false
exclude_tmpdir_env_var = false
# 将 /tmp 从可写根目录中排除。默认:false
exclude_slash_tmp = false
################################################################################
# 生成子进程的 Shell 环境策略(表)
################################################################################
[shell_environment_policy]
# inherit:all(默认) | core | none
inherit = "all"
# 对名称包含 KEY/SECRET/TOKEN(不区分大小写)的变量,跳过默认排除规则。默认:true
ignore_default_excludes = true
# 要移除的(不区分大小写)glob 模式(例如:"AWS_*", "AZURE_*")。默认:[]
exclude = []
# 显式 key/value 覆盖(始终优先)。默认:{}
set = {}
# 白名单;若非空,则只保留匹配的变量。默认:[]
include_only = []
# 实验性:通过用户 shell profile 运行。默认:false
experimental_use_profile = false
################################################################################
# 历史(表)
################################################################################
[history]
# save-all(默认) | none
persistence = "save-all"
# 历史文件最大字节数;超过后会裁剪最旧条目。示例:5242880
# max_bytes = 0
################################################################################
# UI、通知与杂项(表)
################################################################################
[tui]
# 来自 TUI 的桌面通知:布尔值或过滤列表。默认:true
# 示例:false | ["agent-turn-complete", "approval-requested"]
notifications = false
# 启用欢迎/状态/加载动画。默认:true
animations = true
# 在欢迎界面显示入门提示。默认:true
show_tooltips = true
# 可选的 TUI2 滚动调优(未设置则使用默认值)。
# scroll_events_per_tick = 0
# scroll_wheel_lines = 0
# scroll_trackpad_lines = 0
# scroll_trackpad_accel_events = 0
# scroll_trackpad_accel_max = 0
# scroll_mode = "auto" # auto | wheel | trackpad
# scroll_wheel_tick_detect_max_ms = 0
# scroll_wheel_like_max_duration_ms = 0
# scroll_invert = false
# 控制用户是否可以通过 `/feedback` 提交反馈。默认:true
[feedback]
enabled = true
# 产品内提示(多由 Codex 自动设置)。
[notice]
# hide_full_access_warning = true
# hide_world_writable_warning = true
# hide_rate_limit_model_nudge = true
# hide_gpt5_1_migration_prompt = true
# "hide_gpt-5.1-codex-max_migration_prompt" = true
# model_migrations = { "gpt-4.1" = "gpt-5.1" }
################################################################################
# 集中式功能开关(推荐)
################################################################################
[features]
# 将该表留空即可接受默认值。设置显式布尔值以选择加入/退出。
shell_tool = true
web_search_request = false
unified_exec = false
shell_snapshot = false
apply_patch_freeform = false
exec_policy = true
experimental_windows_sandbox = false
elevated_windows_sandbox = false
remote_compaction = true
remote_models = false
powershell_utf8 = true
tui2 = false
################################################################################
# 在此表下定义 MCP 服务器。留空则禁用。
################################################################################
[mcp_servers]
# --- 示例:STDIO 传输 ---
# [mcp_servers.docs]
# enabled = true # 可选;默认 true
# command = "docs-server" # 必填
# args = ["--port", "4000"] # 可选
# env = { "API_KEY" = "value" } # 可选:按原样复制的 key/value
# env_vars = ["ANOTHER_SECRET"] # 可选:从父进程环境转发这些变量
# cwd = "/path/to/server" # 可选:工作目录覆盖
# startup_timeout_sec = 10.0 # 可选;默认 10.0 秒
# # startup_timeout_ms = 10000 # 可选:启动超时(毫秒)的别名
# tool_timeout_sec = 60.0 # 可选;默认 60.0 秒
# enabled_tools = ["search", "summarize"] # 可选:允许列表
# disabled_tools = ["slow-tool"] # 可选:禁用列表(在允许列表之后生效)
# --- 示例:可流式 HTTP 传输 ---
# [mcp_servers.github]
# enabled = true # 可选;默认 true
# url = "https://github-mcp.example.com/mcp" # 必填
# bearer_token_env_var = "GITHUB_TOKEN" # 可选;Authorization: Bearer <token>
# http_headers = { "X-Example" = "value" } # 可选:静态请求头
# env_http_headers = { "X-Auth" = "AUTH_ENV" } # 可选:从环境变量填充的请求头
# startup_timeout_sec = 10.0 # 可选
# tool_timeout_sec = 60.0 # 可选
# enabled_tools = ["list_issues"] # 可选:允许列表
################################################################################
# 模型提供方(扩展/覆盖内置)
################################################################################
# 内置包括:
# - openai(Responses API;需要登录或通过认证流程提供 OPENAI_API_KEY)
# - oss(Chat Completions API;默认指向 http://localhost:11434/v1)
[model_providers]
# --- 示例:用显式 base URL 或 headers 覆盖 OpenAI ---
# [model_providers.openai]
# name = "OpenAI"
# base_url = "https://api.openai.com/v1" # 未设置时的默认值
# wire_api = "responses" # "responses" | "chat"(默认因情况而异)
# # requires_openai_auth = true # 内置 OpenAI 默认 true
# # request_max_retries = 4 # 默认 4;最大 100
# # stream_max_retries = 5 # 默认 5;最大 100
# # stream_idle_timeout_ms = 300000 # 默认 300_000(5 分钟)
# # experimental_bearer_token = "sk-example" # 可选:仅开发用途的直接 bearer token
# # http_headers = { "X-Example" = "value" }
# # env_http_headers = { "OpenAI-Organization" = "OPENAI_ORGANIZATION", "OpenAI-Project" = "OPENAI_PROJECT" }
# --- 示例:Azure(根据端点选择 Chat/Responses)---
# [model_providers.azure]
# name = "Azure"
# base_url = "https://YOUR_PROJECT_NAME.openai.azure.com/openai"
# wire_api = "responses" # 或按端点使用 "chat"
# query_params = { api-version = "2025-04-01-preview" }
# env_key = "AZURE_OPENAI_API_KEY"
# # env_key_instructions = "在环境变量中设置 AZURE_OPENAI_API_KEY"
# --- 示例:本地 OSS(例如 Ollama 兼容)---
# [model_providers.ollama]
# name = "Ollama"
# base_url = "http://localhost:11434/v1"
# wire_api = "chat"
################################################################################
# Profiles(命名预设)
################################################################################
[profiles]
# [profiles.default]
# model = "gpt-5.2-codex"
# model_provider = "openai"
# approval_policy = "on-request"
# sandbox_mode = "read-only"
# oss_provider = "ollama"
# model_reasoning_effort = "medium"
# model_reasoning_summary = "auto"
# model_verbosity = "medium"
# chatgpt_base_url = "https://chatgpt.com/backend-api/"
# experimental_compact_prompt_file = "./compact_prompt.txt"
# include_apply_patch_tool = false
# experimental_use_unified_exec_tool = false
# experimental_use_freeform_apply_patch = false
# tools_web_search = false
# features = { unified_exec = false }
################################################################################
# Projects(信任级别)
################################################################################
# 将特定 worktree 标记为可信或不可信。
[projects]
# [projects."/absolute/path/to/project"]
# trust_level = "trusted" # 或 "untrusted"
################################################################################
# OpenTelemetry(OTEL)- 默认禁用
################################################################################
[otel]
# 在日志中包含用户提示文本。默认:false
log_user_prompt = false
# 应用于遥测数据的环境标签。默认:"dev"
environment = "dev"
# 导出器:none(默认) | otlp-http | otlp-grpc
exporter = "none"
# Trace 导出器:none(默认) | otlp-http | otlp-grpc
trace_exporter = "none"
# 示例:OTLP/HTTP 导出器配置
# [otel.exporter."otlp-http"]
# endpoint = "https://otel.example.com/v1/logs"
# protocol = "binary" # "binary" | "json"
# [otel.exporter."otlp-http".headers]
# "x-otlp-api-key" = "${OTLP_TOKEN}"
# 示例:OTLP/gRPC 导出器配置
# [otel.exporter."otlp-grpc"]
# endpoint = "https://otel.example.com:4317",
# headers = { "x-otlp-meta" = "abc123" }
# 示例:带双向 TLS 的 OTLP 导出器
# [otel.exporter."otlp-http"]
# endpoint = "https://otel.example.com/v1/logs"
# protocol = "binary"
# [otel.exporter."otlp-http".headers]
# "x-otlp-api-key" = "${OTLP_TOKEN}"
# [otel.exporter."otlp-http".tls]
# ca-certificate = "certs/otel-ca.pem"
# client-certificate = "/etc/codex/certs/client.pem"
# client-private-key = "/etc/codex/certs/client-key.pem"
5.5 小结
本章从工程实践角度梳理了 config.toml 的核心项与高级用法,包括模型与 profiles、approval_policy、sandbox_mode 等关键配置。
配置的重点不是“全放开”,而是先画清边界:用审批策略和沙箱级别控制风险,再按需逐步放宽到命令、网络与工具链能力。
下一步可以继续阅读机制篇,把这些边界落实到 Rules、AGENTS 与可复用提示模板上。
06 机制篇:Rules / AGENTS / Prompts / MCP
本章把“边界与复用”落到机制层:用 Rules 控制高风险命令,用 AGENTS.md 做分层指令与团队约束,用自定义 Prompts 复用提示模板,用 MCP 把能力扩展到外部系统。
如果你希望 Codex 既能更自动化、又不失控,本章的目标是帮你把“可控、可查、可复用、可扩展”这四件事落到具体配置与写法上。
6.1 规则
描述:控制 Codex 在沙箱外可以运行哪些命令
原文地址:https://developers.openai.com/codex/rules
可以使用规则(Rules)来控制 Codex 在沙箱(sandbox)之外可以运行的命令。
6.1.1 创建规则文件
Step1:首先在 ~/.codex/rules 目录下创建一个 .rules 文件(例如:~/.codex/rules/default.rules)。
Step2:添加一条规则,下面这个示例会在 允许 gh pr view 在沙箱外运行之前进行提示确认。
# 在沙箱外运行以 `gh pr view` 为前缀的命令前进行提示。
prefix_rule(
# 要匹配的命令前缀。
pattern = ["gh", "pr", "view"],
# 当 Codex 请求运行匹配的命令时采取的动作。
decision = "prompt",
# 该规则存在的可选说明理由。
justification = "在获得批准的情况下允许查看 PR",
# `match` 和 `not_match` 是可选的“内联单元测试”,
# 用于提供应该(或不应该)匹配该规则的命令示例。
match = [
"gh pr view 7888",
"gh pr view --repo openai/codex",
"gh pr view 7888 --json title,body,comments",
],
not_match = [
# 不匹配,因为 `pattern` 必须是一个精确的前缀。
"gh pr --repo openai/codex view 7888",
],
)
Step3:重启,Codex在启动时加载 ~/.codex/rules 目录下的所有 *.rules 文件,当你在 TUI(终端交互界面)中将某个命令加入允许列表时,Codex 会自动把对应规则追加到~/.codex/rules/default.rules,这样以后运行时就可以跳过提示。
6.1.2 理解规则字段
prefix_rule() 支持以下字段:
pattern(必填):一个非空列表,用于定义要匹配的命令前缀,列表中的每个元素可以是:
- 一个字面量字符串(例如
"pr") - 一个字面量联合(例如
["view", "list"]),用于在该参数位置匹配多种可能
decision(默认值为 "allow"):当规则匹配时采取的动作,当有多条规则同时匹配时,Codex 会选择限制性最强的决策(forbidden > prompt > allow)。可选值包括:
- allow:无需提示,直接在沙箱外运行命令
- prompt:每次匹配时都进行提示确认
- forbidden:不提示,直接阻止该请求
justification(可选):一段非空的、对人类可读的规则说明,Codex 可能会在审批提示或拒绝信息中展示该内容。当你使用 forbidden 时,建议在说明中给出可替代方案,例如:“请使用 rg 代替 grep。”
match 和 not_match(默认值为 []):用于在加载规则时由 Codex 验证的示例命令,它们可以帮助你在规则生效前发现错误配置。
当 Codex 判断是否运行某条命令时,会将该命令的参数列表与
pattern进行比较。在内部,Codex 会把命令当作一个参数数组处理(类似execvp(3)接收到的形式)。
6.1.3 Shell 包装器与复合命令
有些工具会把多个 shell 命令包装成一次调用,例如:
["bash", "-lc", "git add . && rm -rf /"]
由于这种形式可能在一个字符串中隐藏多个操作,
Codex 会对 bash -lc、bash -c 以及它们在 zsh / sh 中的等价形式进行特殊处理。
① 当 Codex 拆分脚本
如果 shell 脚本是一个简单、线性的命令链,并且只包含:
- 普通单词(不包含变量展开、
VAR=...、$FOO、*等) - 使用安全操作符连接(
&&、||、;或|)
那么 Codex 会使用 tree-sitter 对脚本进行解析,并在应用规则之前将其拆分为多个独立命令。
例如,上面的脚本会被拆分为两个命令:
["git", "add", "."]
["rm", "-rf", "/"]
Codex 会分别对每个命令应用规则,并最终采用限制性最强的结果。因此,即使你允许了:
pattern = ["git", "add"]
Codex 也不会自动允许:
git add . && rm -rf /
因为 rm -rf / 会被单独评估,并阻止整个命令的自动执行。这种机制可以防止把危险命令“夹带”在安全命令中一起执行。
② 当Codex 不拆分脚本
如果脚本使用了更复杂的 shell 特性,例如:
- 重定向(
>、>>、<) - 命令替换(
$(...)、...) - 环境变量(
FOO=bar) - 通配符(
*、?) - 控制流(
if、for、带赋值的&&等)
那么 Codex 不会尝试解析或拆分脚本。在这种情况下,整个调用会被当作一个单独命令处理:
["bash", "-lc", "<完整脚本>"]
规则也只会应用在这一次调用上。通过这种特殊处理方式,在安全可解析时实现逐命令评估,在无法确定安全性时采取更保守的行为。
6.1.4 测试规则文件
可以使用以下命令来测试规则对某个命令的影响:
codex execpolicy check --pretty \
--rules ~/.codex/rules/default.rules \
-- gh pr view 7888 --json title,body,comments
该命令会输出 JSON,展示:
- 最严格的决策结果
- 所有匹配到的规则
- 以及规则中包含的
justification信息
可以使用多个 --rules 参数来组合多个规则文件,并使用 --pretty 让输出结果更易读。
6.1.5 理解规则语言
.rules 文件使用 Starlark 语言编写(可参考其语言规范)。它的语法类似 Python,但被设计为安全可执行,规则引擎可以运行它而不会产生副作用(例如访问或修改文件系统)。
6.2 AGENTS
描述:为你的项目向 Codex 提供额外的指令和上下文
原文链接:https://developers.openai.com/codex/guides/agents-md
Codex 在开始任何工作之前都会读取 AGENTS.md 文件,通过将全局指导与项目级别的覆盖规则分层组合,你可以在打开任何仓库时,都以一致的预期开始每一个任务。
6.2.1 Codex 如何发现指令
Codex 在启动时会构建一条指令链(每次运行一次,在 TUI 中通常意味着每次启动一个会话)。指令发现遵循以下优先级顺序:
全局作用域(Global scope):在你的 Codex 主目录中(默认为 ~/.codex,除非你设置了 CODEX_HOME),Codex 会:
- 如果存在
AGENTS.override.md,则读取它 - 否则读取
AGENTS.md - 在这一层级中,Codex 只会使用第一个非空文件
项目作用域(Project scope):从项目根目录(通常是 Git 根目录)开始,Codex 会向下遍历到你当前的工作目录:
-
如果 Codex 无法找到项目根目录,则只检查当前目录
-
在路径上的每一个目录中,依次检查:
AGENTS.override.mdAGENTS.mdproject_doc_fallback_filenames中配置的备用文件名
- 每个目录最多只会包含一个指令文件
合并顺序(Merge order):
- Codex 会从根目录向下拼接这些文件,并用空行连接
- 越靠近当前工作目录的文件优先级越高,因为它们在合并后的提示中出现得更晚
Codex 会跳过空文件,并在合并内容达到 project_doc_max_bytes 定义的大小上限时停止(默认是 32 KiB)。有关这些参数的详细说明,请参阅 Project instructions discovery。当你触及大小上限时,可以提高限制,或将指令拆分到更深层的子目录中。
6.2.2 创建全局指引
在 Codex 主目录中创建持久化的默认规则,让每一个仓库都能继承你的工作约定。
Step1:需要确保目录存在:
mkdir -p ~/.codex
Step2: 创建 ~/.codex/AGENTS.md,写入可复用的偏好设置:
# ~/.codex/AGENTS.md
## Working agreements
- Always run `npm test` after modifying JavaScript files.
- Prefer `pnpm` when installing dependencies.
- Ask for confirmation before adding new production dependencies.
Step3:在任意位置运行 Codex,确认它加载了该文件:
codex --ask-for-approval never "Summarize the current instructions."
预期结果:Codex 会在提出工作建议之前,引用
~/.codex/AGENTS.md中的条目。
当你需要临时的全局覆盖规则而又不想删除基础文件时,可以使用~/.codex/AGENTS.override.md,删除该 override 文件即可恢复共享指引。
6.2.3 分层设置项目指令
仓库级别的文件可以让 Codex 了解项目规范,同时仍然继承你的全局默认规则。
Step1:在仓库根目录中添加 AGENTS.md,用于基础设置:
# AGENTS.md
## Repository expectations
- Run `npm run lint` before opening a pull request.
- Document public utilities in `docs/` when you change behavior.
Step2:当特定团队需要不同规则时,在子目录中添加覆盖文件
例如,在 services/payments/ 目录下创建 AGENTS.override.md:
# services/payments/AGENTS.override.md
## Payments service rules
- Use `make test-payments` instead of `npm test`.
- Never rotate API keys without notifying the security channel.
Step3:从 payments 目录启动 Codex
codex --cd services/payments --ask-for-approval never "List the instruction sources you loaded."
预期结果:Codex 会依次报告 “全局指令文件” → “仓库根目录的
AGENTS.md” → “payments 目录下的 override 文件(最后加载)”
Codex 在到达当前工作目录后就会停止搜索,因此应尽量将 override 文件放在 最接近具体工作的目录中。添加了全局文件和 payments 专用 override 之后,一个示例仓库结构如下:
6.2.4 自定义备用文件名
如果你的仓库已经使用了不同的文件名(例如 TEAM_GUIDE.md),可以将它加入备用列表,让 Codex 将其视为指令文件。
可以编辑 Codex 配置:
# ~/.codex/config.toml
project_doc_fallback_filenames = ["TEAM_GUIDE.md", ".agents.md"]
project_doc_max_bytes = 65536
然后重启 Codex,或运行一条新命令,使更新后的配置生效,Codex 会按以下顺序检查每个目录:
AGENTS.override.md↓AGENTS.md↓TEAM_GUIDE.md↓.agents.md↓
不在该列表中的文件名将被忽略,更大的字节限制允许在被截断之前合并更多指引内容。在配置了 fallback 列表后,Codex 会将这些替代文件当作指令文件处理: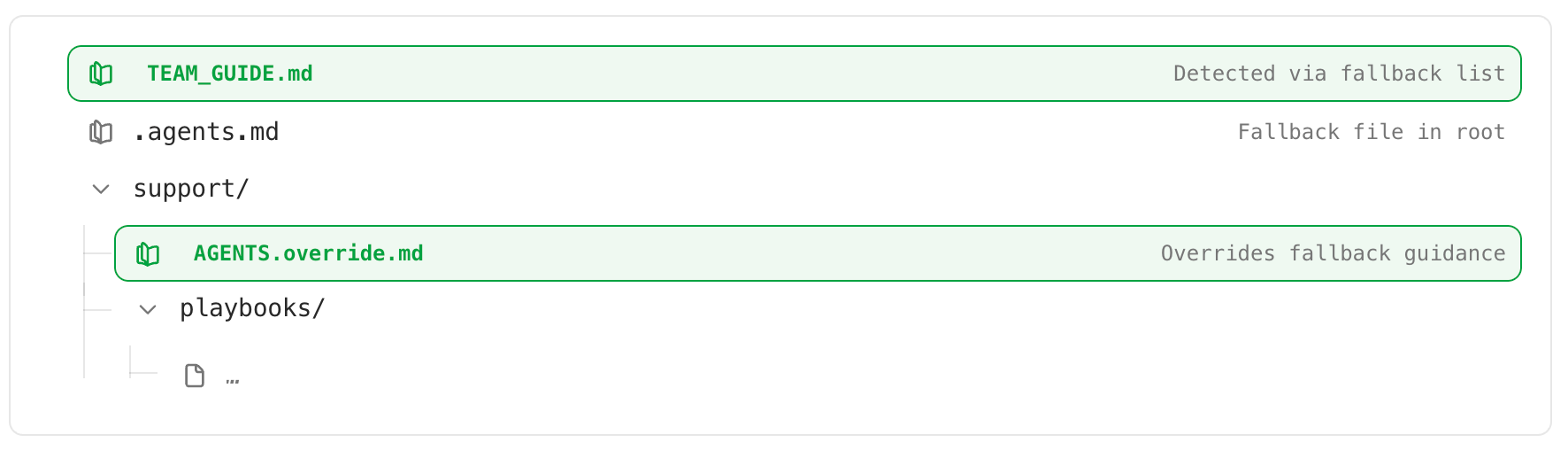
如果需要使用不同的配置(例如:项目专用的自动化用户)时,可以设置 CODEX_HOME 环境变量:
CODEX_HOME=$(pwd)/.codex codex exec "List active instruction sources"
预期结果:输出会列出相对于自定义 .codex 目录的指令文件。
6.2.5 验证配置
可以在仓库根目录运行如下命令,Codex 应按优先级顺序回显全局和项目指令:
codex --ask-for-approval never "Summarize the current instructions."
使用子目录验证覆盖规则:
codex --cd subdir --ask-for-approval never "Show which instruction files are active."
如果需要审计 Codex 加载了哪些指令文件:
- 查看
~/.codex/log/codex-tui.log - 或(如果启用了会话日志)查看最新的
session-*.jsonl文件
如果指令看起来是旧的:
- 在目标目录中重启 Codex
- Codex 会在每次运行时(以及每个 TUI 会话开始时)重建指令链,因此无需手动清缓存
6.2.6 问题排查
① 什么都没加载
- 确认你在正确的仓库中
- 检查
codex status是否显示了你期望的工作区根目录 - 确保指令文件中有内容(空文件会被忽略)
② 出现了错误的指引
- 检查目录树中更高层是否存在
AGENTS.override.md(包括 Codex 主目录) - 重命名或删除 override 文件即可回退到普通文件
③ Codex 忽略了 fallback 文件名
- 确认你已正确配置
project_doc_fallback_filenames,且无拼写错误 - 重启 Codex 以使配置生效
④ 指令被截断
- 提高
project_doc_max_bytes - 或将大型文件拆分到嵌套目录中
⑤ 配置档案混乱(Profile confusion)
-
在启动 Codex 前运行:
echo $CODEX_HOME -
非默认值意味着 Codex 正在使用与你编辑的不同主目录
6.3 自定义提示词
描述:定义可复用的提示,使其像斜杠命令一样工作
原文地址:https://developers.openai.com/codex/custom-prompts
自定义提示允许你将 Markdown 文件 转换为可复用的提示,并且可以在 Codex CLI 和 Codex IDE 扩展中通过斜杠命令来调用。自定义提示需要 显式调用,并且存放在你本地的 Codex 主目录中(例如 ~/.codex),因此不会随着你的代码仓库共享,如果希望共享一个提示(或者希望 Codex 能够隐式调用它),请使用 skills。接下来看看如何自定义提示词。
6.3.1 创建文件
首先创建 prompts 目录:
mkdir -p ~/.codex/prompts
然后创建 ~/.codex/prompts/draftpr.md,并添加可复用的指导内容:
---
description: Prep a branch, commit, and open a draft PR
argument-hint: [FILES=<paths>] [PR_TITLE="<title>"]
---
Create a branch named `dev/<feature_name>` for this work.
If files are specified, stage them first: $FILES.
Commit the staged changes with a clear message.
Open a draft PR on the same branch. Use $PR_TITLE when supplied; otherwise write a concise summary yourself.
最后重启 Codex 以加载新的提示(重启 CLI 会话;如果你在使用 IDE 扩展,请重新加载扩展)。
预期效果:在斜杠命令菜单中输入
/prompts:draftpr,你会看到自定义命令,其描述来自 front matter,并提示文件和 PR 标题是可选参数。
6.3.2 添加元数据和参数
Codex 会在下次会话启动时读取提示元数据并解析占位符。
- Description:显示在弹出窗口中命令名称下方。通过 YAML front matter 中的
description:设置。 - Argument hint:使用
argument-hint: KEY=<value>来说明期望的参数。 - 位置占位符(Positional placeholders):
$1到$9会从你在命令后提供的、以空格分隔的参数中展开,$ARGUMENTS包含所有这些参数。 - 命名占位符(Named placeholders):使用大写名称(如
$FILE或$TICKET_ID),并通过KEY=value形式提供值,包含空格的值需要加引号(例如:FOCUS="loading state")。 - 字面量美元符号:使用
$$来输出一个单独的$。 - 在编辑提示文件后,重启 Codex 或打开一个新的聊天以加载更新,Codex 会忽略
prompts目录中非 Markdown 的文件。
6.3.3 调用和管理自定义命令
在 Codex(CLI 或 IDE 扩展)中,输入 / 打开斜杠命令菜单。输入 prompts: 或直接输入提示名称,例如:
/prompts:draftpr
提供所需参数:
/prompts:draftpr FILES="src/pages/index.astro src/lib/api.ts" PR_TITLE="Add hero animation"
按 Enter 发送展开后的指令(当不需要某个参数时,可以省略它)。
预期效果:Codex 会展开
draftpr.md的内容,用你提供的参数替换占位符,然后将结果作为一条消息发送。
可以通过编辑或删除 ~/.codex/prompts/ 目录下的文件来管理提示,Codex 只扫描该文件夹顶层的 Markdown 文件,因此请将每个自定义提示直接放在 ~/.codex/prompts/ 下,而不要放在子目录中。
6.4 MCP
描述:为 Codex 提供对第三方工具和上下文的访问能力
原文地址:https://developers.openai.com/codex/mcp
模型上下文协议(Model Context Protocol,简称 MCP)用于将模型连接到工具和上下文,你可以使用它让 Codex 访问第三方文档,或让它与开发者工具(如浏览器或 Figma)进行交互,Codex 在 CLI 和 IDE 扩展中都支持 MCP 服务器。
6.4.1 支持的 MCP 功能
-
STDIO 服务器:作为本地进程运行的服务器(通过命令启动)
-
可流式的 HTTP 服务器:通过地址访问的服务器
- Bearer Token 认证
- OAuth 认证(对于支持 OAuth 的服务器,运行
codex mcp login <server-name>)
6.4.2 连接 MCP 服务器
Codex 会将 MCP 配置存储在 ~/.codex/config.toml 中,与其他 Codex 配置项放在一起,CLI 与 IDE 扩展 共享同一份配置,一旦配置好了 MCP 服务器,就可以在两个 Codex 客户端之间切换,而无需重新设置。
要配置 MCP 服务器,可以选择以下方式之一:
- 使用 CLI:运行
codex mcp来添加和管理服务器。 - 编辑 config.toml:直接修改
~/.codex/config.toml。
6.4.2.1 CLI 配置 MCP
添加一个 MCP 服务器
codex mcp add <server-name> --env VAR1=VALUE1 --env VAR2=VALUE2 -- <stdio server-command>
例如,要添加 Context7(一个免费的开发者文档 MCP 服务器),可以运行以下命令:
codex mcp add context7 -- npx -y @upstash/context7-mcp
要查看所有可用的 MCP 命令,可以运行:
codex mcp --help
6.4.2.2 config.toml 配置 MCP
如果需要对 MCP 服务器选项进行更精细的控制,可以编辑 ~/.codex/config.toml,在 IDE 扩展中,可以通过齿轮菜单选择 MCP settings > Open config.toml 来打开该文件。
在配置文件中,为每个 MCP 服务器使用一个 [mcp_servers.<server-name>] 表进行配置。相关参数配置如下:
STDIO 服务器
- command(必填):启动服务器的命令。
- args(可选):传递给服务器的参数。
- env(可选):为服务器设置的环境变量。
- env_vars(可选):允许并转发的环境变量。
- cwd(可选):启动服务器时使用的工作目录。
可流式的 HTTP 服务器
- url(必填):服务器地址。
- bearer_token_env_var(可选):用于在
Authorization中发送 Bearer Token 的环境变量名。 - http_headers(可选):请求头名称到静态值的映射。
- env_http_headers(可选):请求头名称到环境变量名的映射(值从环境变量中读取)。
其他配置选项
- startup_timeout_sec(可选):服务器启动超时时间(秒),默认值:10;
- tool_timeout_sec(可选):服务器运行工具的超时时间(秒),默认值:60;
- enabled(可选):设置为
false可在不删除服务器的情况下禁用它; - enabled_tools(可选):允许使用的工具白名单;
- disabled_tools(可选):禁止使用的工具黑名单(在
enabled_tools之后生效)。
config.toml 示例
[mcp_servers.context7]
command = "npx"
args = ["-y", "@upstash/context7-mcp"]
[mcp_servers.context7.env]
MY_ENV_VAR = "MY_ENV_VALUE"
[mcp_servers.figma]
url = "https://mcp.figma.com/mcp"
bearer_token_env_var = "FIGMA_OAUTH_TOKEN"
http_headers = { "X-Figma-Region" = "us-east-1" }
[mcp_servers.chrome_devtools]
url = "http://localhost:3000/mcp"
enabled_tools = ["open", "screenshot"]
disabled_tools = ["screenshot"] # 在 enabled_tools 之后生效
startup_timeout_sec = 20
tool_timeout_sec = 45
enabled = true
6.4.3 常用的 MCP 服务器示例
MCP 服务器的列表仍在不断增长,以下是一些常见示例:
- OpenAI Docs MCP:搜索并阅读 OpenAI 开发者文档。
- Context7:连接到最新的开发者文档。
- Figma Local 和 Remote:访问你的 Figma 设计。
- Playwright:使用 Playwright 控制和检查浏览器。
- Chrome Developer Tools:控制和检查 Chrome。
- Sentry:访问 Sentry 日志。
- GitHub:管理 GitHub(超出 git 本身支持的能力,例如拉取请求和 Issue)。
6.5 小结
本章覆盖了 Rules(命令与审批控制)、AGENTS.md(分层指令)、自定义 Prompts(提示复用)与 MCP(工具扩展),对应的是 Codex 的可控性、可发现性、可复用性与可扩展性。
实践上建议先用 Rules 管住高风险命令,再用 AGENTS/Prompts 固化团队约束,最后按需接入 MCP 连接外部系统。
07 工程化篇:Agent Skills(封装 / 复用 / 共享)
本章进入“工程化复用”的阶段:把零散的提示与操作步骤,封装成可反复调用、可共享给团队的 Skills。你可以把 Skill 理解成一个“带说明书与资源的工作流包”,用于稳定复现某类任务的做法与验收标准。
Agent Skills(代理技能) 可以为 Codex 扩展面向特定任务的能力,一个技能会将指令、资源以及可选脚本打包在一起,使 Codex 能够可靠地遵循某一工作流,你可以在团队之间共享技能,或将其分享给社区,技能都是基于开放的 Agent Skills 标准构建。
7.1 Agent skill 定义
描述:为 Codex 赋予新的能力与专业知识
原文地址:https://developers.openai.com/codex/skills
一个技能通过位于 SKILL.md 文件中的 Markdown 指令 来表达某种能力,技能文件夹中还可以包含脚本、资源和素材,供 Codex 在执行特定任务时使用。
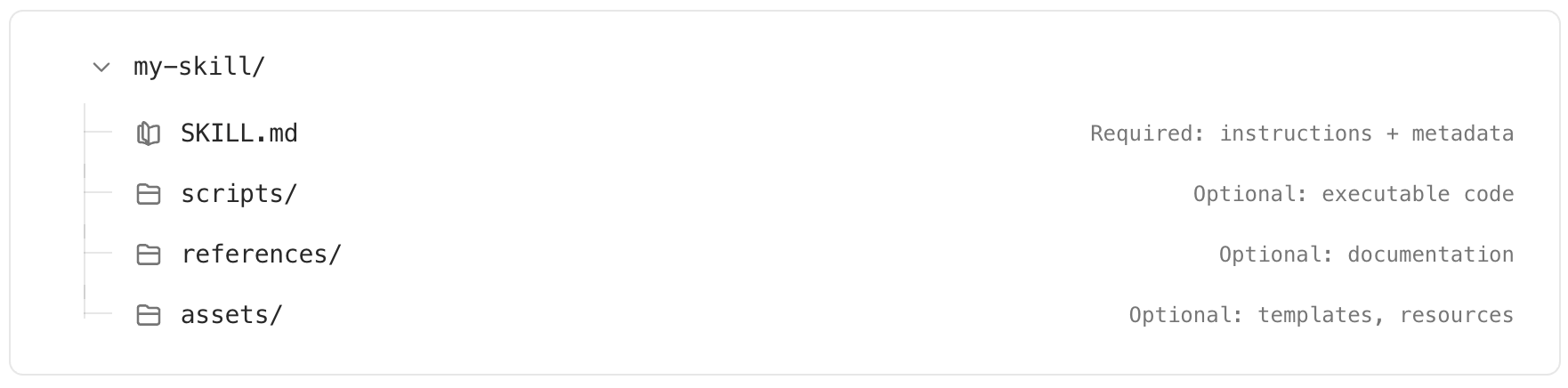
技能使用渐进式披露(progressive disclosure)来高效管理上下文,在启动时,Codex 只会加载每个可用技能的名称和描述。随后,Codex 可以通过以下两种方式激活并使用技能:
显式调用(Explicit invocation):可以在提示中直接包含技能。通过运行 /skills 斜杠命令来选择技能或输入 $ 来提及某个技能
 |
 |
|---|
隐式调用(Implicit invocation):当你的任务与某个技能的描述匹配时,Codex 可以自行决定使用该技能。无论采用哪种方式,一旦技能被调用,Codex 都会读取该技能的完整指令以及技能目录中包含的所有附加参考资料。
当 Codex 从这些位置加载技能时,如果存在同名技能,则会用优先级更高的作用域中的技能覆盖优先级较低的,下表按优先级从高到低列出了技能作用域及其位置:
| 作用域 | 位置 | 建议 |
|---|---|---|
| REPO | $CWD/.codex/skills启动 Codex 时的当前工作目录 |
如果你在某个仓库或代码环境中,团队可以提交仅与该工作目录相关的技能,例如只适用于某个微服务或模块的技能 |
| REPO | $CWD/../.codex/skills在 Git 仓库中启动 Codex 时,位于 CWD 上一级的目录 |
当仓库存在多级子目录时,组织可以在父目录中提交适用于共享区域的技能 |
| REPO | $REPO_ROOT/.codex/skills在 Git 仓库中启动 Codex 时的最顶层根目录 |
适用于整个仓库的通用技能。它们可被任何子目录中的技能覆盖 |
| USER | $CODEX_HOME/skills(macOS 和 Linux 默认: ~/.codex/skills) |
用户个人目录中的技能,适用于用户可能使用的任何仓库 |
| ADMIN | /etc/codex/skills |
机器或容器中的系统级共享技能,适用于 SDK 脚本、自动化以及默认的管理员技能 |
| SYSTEM | 随 Codex 一起打包 | 面向广泛用户的通用技能(如 skill-creator、plan 技能),对所有用户可用,可被上层作用域覆盖 |
Codex 支持 符号链接(symlink) 的技能文件夹,在扫描这些位置时会跟随符号链接的目标路径。
也可以在 ~/.codex/config.toml 中按技能粒度进行启用或禁用目前属于 实验性功能,未来可能会调整,你可以使用 [[skills.config]] 条目来禁用某个技能,而无需删除它,然后重启 Codex:
[[skills.config]]
path = "/path/to/skill"
enabled = false
7.2 创建技能
描述:使用 Codex 创建自定义工作流,并在项目之间强制执行最佳实践
原文地址:https://developers.openai.com/codex/skills/create-skill
技能(Skills)让团队能够沉淀组织内部知识,并将其转化为可复用、可共享的工作流,技能可以帮助 Codex 在不同用户、代码仓库和会话之间保持一致的行为,尤其适用于希望自动应用标准约定和检查的场景。
一个技能是一个小型的组合体,包含以下内容:
- 名称
- 描述(说明技能的作用以及何时使用)
- 可选的指令正文
Codex 在运行时上下文中只会注入技能的名称、描述和文件路径,指令正文不会被注入,除非该技能被明确调用。
7.2.1 什么时候需要创建技能
当你希望在团队中共享行为、强制统一工作流,或将最佳实践编码一次并在各处复用时,应使用技能。典型使用场景包括:
- 标准化代码审查清单和约定
- 强制执行安全或合规检查
- 自动化常见分析任务
- 提供 Codex 可自动发现的团队专属工具
不建议将技能用于一次性提示或探索性任务;应保持技能聚焦、单一职责,而不是试图建模大型多步骤系统。
7.2.2 创建技能
7.2.2.1 使用技能创建器
Codex 内置了一个用于创建新技能的技能,使用该方法可以获得引导,并对技能进行迭代优化。
可通过 Codex CLI 或 Codex IDE 扩展调用技能创建器:
$skill-creator
也可以添加你希望该技能实现功能的上下文说明。
$skill-creator
Create a skill that drafts a conventional commit message based on a short summary of changes.
创建器会询问:
- 技能的作用
- Codex 何时应自动触发该技能
- 运行类型(仅指令 / 脚本支持)
于是继续输入:
Example trigger requests:
1) 根据以下改动摘要帮我写一条 conventional commit message:<改动摘要>
2) 把这段改动说明转换成符合 Conventional Commits 的提交信息:<改动说明>
3) 生成一条 conventional commit:<一句话总结/要点列表>
Conventional Commit constraints: default (standard types feat/fix/docs/style/refactor/perf/test/build/ci/chore/revert; optional scope; use ! + BREAKING CHANGE footer when breaking; add Refs footer if issue id present)
shell
输出结果是一个 SKILL.md 文件,包含名称、描述和指令,目录在 skills/draft-conventional-commit/SKILL.md,内容如下: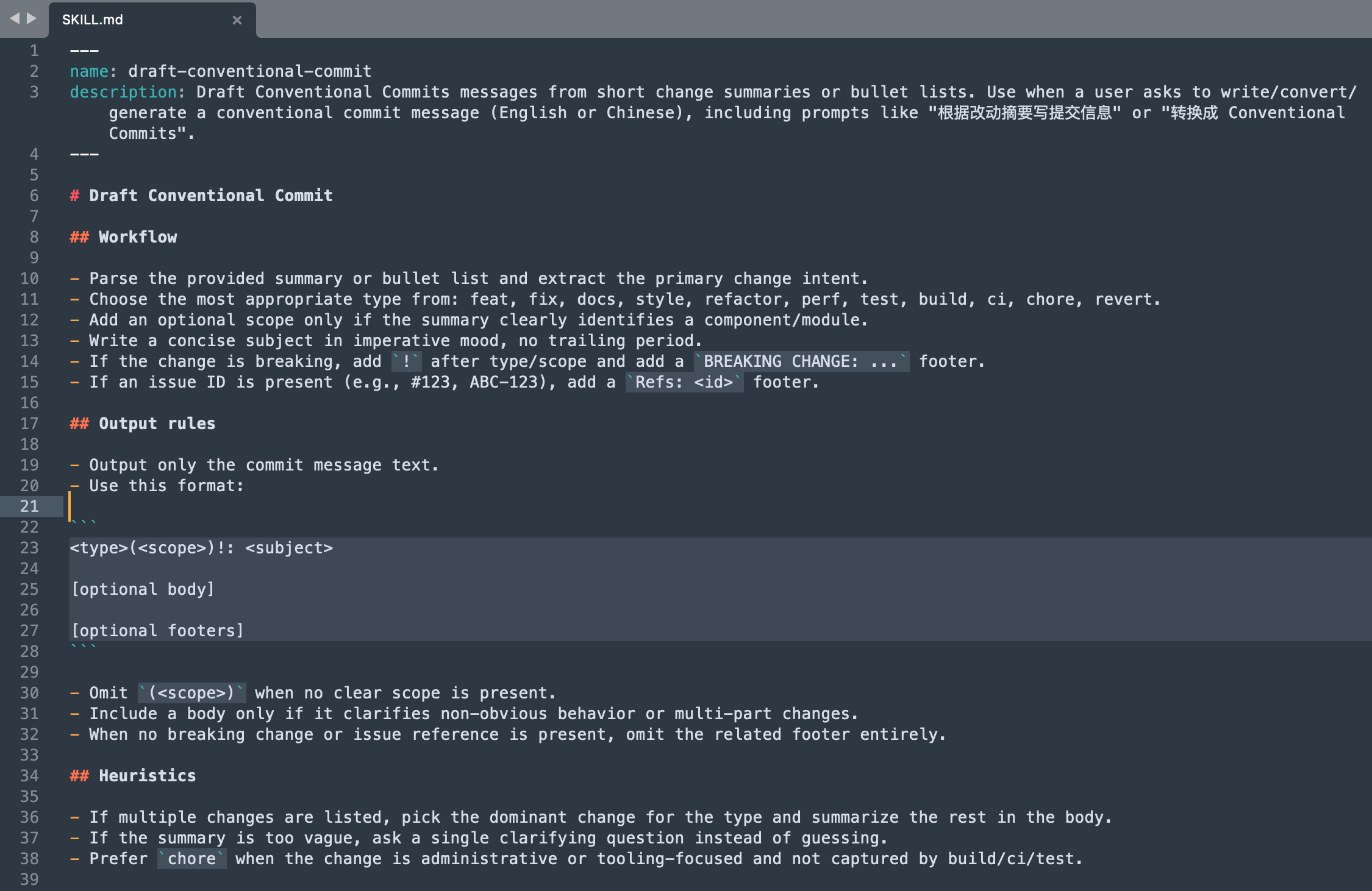
7.2.2.2 手动创建技能
当你需要完全控制,或直接在编辑器中操作时,可使用该方式。
Step1:选择存放位置(仓库级或用户级)
# 用户级技能(macOS/Linux 默认)
mkdir -p ~/.codex/skills/<skill-name>
# 仓库级技能(提交到代码仓库中)
mkdir -p .codex/skills/<skill-name>
Step2:创建 SKILL.md
---
name: <skill-name>
description: <功能说明及使用时机>
---
<指令、参考资料或示例>
重启 Codex 以加载该技能。
7.2.3 理解技能格式
技能使用 YAML front matter + 可选正文 的格式。必填字段:
name:非空,最多 100 个字符,单行description:非空,最多 500 个字符,单行
Codex 会忽略多余的键,正文部分可以包含任意 Markdown 内容,会保存在磁盘上,且不会注入运行时上下文,除非技能被明确调用。
除了内联指令外,技能目录通常还包含:
- 脚本(如 Python 文件):用于确定性处理、校验或调用外部工具
- 模板和结构定义:如报告模板、JSON/YAML Schema、配置默认值
- 参考数据:如查找表、提示语、固定示例
- 文档:说明假设条件、输入或预期输出
示例目录结构:
技能指令可以引用这些资源,但它们仍保留在磁盘上,从而使运行时上下文保持小且可预测。真实世界的模式和示例可参考 agentskills.io,以及 github.com/openai/skills 上的技能目录。
7.2.4 选择技能的保存位置
Codex 会从以下位置加载技能(仓库级、用户级、管理员级和系统级)。根据技能适用对象选择合适位置:
- 当技能应随代码库一起使用时,保存到仓库的
.codex/skills/ - 当技能应作用于本机所有仓库时,保存到用户技能目录
- 仅在受管环境中使用管理员/系统级位置(如共享机器)
完整的支持路径和优先级规则,请参阅 Skills 概览中的 “Where to save skills” 部分。
7.2.5 示例技能
示例技能如下:
---
name: draft-commit-message
description: Draft a conventional commit message when the user asks for help writing a commit message.
metadata:
short-description: Draft an informative commit message.
---
Draft a conventional commit message that matches the change summary provided by the user.
Requirements:
- Use the Conventional Commits format: `type(scope): summary`
- Use the imperative mood in the summary (for example, "Add", "Fix", "Refactor")
- Keep the summary under 72 characters
- If there are breaking changes, include a `BREAKING CHANGE:` footer
触发该技能的示例提示:
Help me write a commit message for these changes: I renamed `SkillCreator` to `SkillsCreator` and updated the sidebar.
更多示例技能和创意请参阅 github.com/openai/skills 仓库。
编写技能时,建议遵循原则:
- 明确触发条件:描述用于告诉 Codex 何时触发技能
- 保持技能小而精:优先使用窄范围、模块化技能
- 优先使用指令而非脚本:仅在需要确定性或外部数据时使用脚本
- 假设无上下文:指令应假定 Codex 只知道输入内容
- 避免歧义:使用祈使句、分步骤指令
- 测试触发条件:确认示例提示能按预期激活技能
7.2.6 引入技能方式
① 团队级技能(随代码走)
<repo>/
└── .codex/
└── skills/
└── <team-skill>/
└── SKILL.md
② 个人常用技能
~/.codex/skills/<skill-name>/
③ 使用符号链接共享技能
ln -s ~/company-skills/review-skill ~/.codex/skills/review-skill
7.2.7 问题排查
① 技能未显示(Skill doesn’t appear)
如果技能未出现在 Codex 中,请确认:
- 已启用技能并重启 Codex
- 文件名严格为
SKILL.md - 文件位于受支持路径(如
~/.codex/skills)
如果你在 ~/.codex/config.toml 中禁用了某技能,请移除或修改对应的 [[skills.config]] 条目并重启 Codex。
如使用符号链接目录,请确认目标路径存在且可读。Codex 也会跳过 YAML 格式错误 或 name/description 超出长度限制 的技能。
② 技能未触发(Skill doesn’t trigger)
若技能已加载但未自动运行,最常见原因是触发条件不明确。
- 确保 description 中明确说明何时使用该技能
- 使用与描述匹配的提示进行测试
若多个技能意图重叠,请缩小描述范围,以便 Codex 选择正确技能。
③ 启动校验错误(Startup validation errors)
如果 Codex 在启动时报校验错误,请根据提示修复 SKILL.md 中的问题,最常见原因是 多行 或 超长 的 name 或 description,修复后重启 Codex 以重新加载技能。
7.3 常见主流的 Skills 仓库
随着 Agent Skills 标准逐步统一,社区已经出现了一批可直接复用或作为模板的 Skills 仓库。下面列出目前较为主流、与 Codex 兼容度高的仓库,并说明推荐的引入方式。
7.3.1 openai/skills(官方推荐)
仓库地址: https://github.com/openai/skills
定位:
- OpenAI 官方维护
- 提供一组 可直接使用 / 可参考实现 的 Codex Skills
- 覆盖规划、写作、代码、流程类技能
- 非常适合作为团队技能模板
引入方式一:直接克隆到用户级技能目录
git clone https://github.com/openai/skills ~/.codex/skills/openai-skills
引入方式二:只引入单个技能
mkdir -p ~/.codex/skills
cp -r skills/<skill-name> ~/.codex/skills/
重启 Codex 后即可通过 /skills 或 $<skill-name> 使用。
7.3.2 agentskills/agentskills
仓库地址: https://github.com/agentskills/agentskills
定位:
- Agent Skills 规范仓库
- 定义
SKILL.md格式、字段约束、设计原则 - 包含示例与工具说明
- 更偏「写技能的人必看」
推荐用途
- 校对你写的技能是否符合规范
- 作为内部技能编写指南
- 不建议直接整体引入作为可执行技能
引入方式:不建议整体放入 .codex/skills,建议作为文档仓库单独 clone 阅读
git clone https://github.com/agentskills/agentskills
7.3.3 anthropics/skills(Claude 社区示例)
仓库地址: https://github.com/anthropics/skills
定位:
- Claude 社区公开 Skills 示例
- 包含较完整的目录组织、指令写法
- 对 Codex 高度可借鉴(SKILL.md 结构基本一致)
推荐用途
- 参考复杂技能如何拆分资源 / 模板 / 文档
- 借鉴 description 与 trigger 的写法
引入方式(选择性)
建议只复制单个技能目录,而不是整体引入。
git clone https://github.com/anthropics/skills
cp -r skills/<skill-name> ~/.codex/skills/
导入后重启内容如下:
7.3.4 agentskills.io(社区索引 / 市场)
定位
- 社区 Skills 聚合索引
- 可按类别搜索(写作 / 代码 / 分析 / DevOps 等)
- 指向 GitHub 仓库或可安装源
推荐用途
- 找灵感 / 找现成技能
- 快速定位某类工作流是否已有成熟实现
引入方式
- 在 agentskills.io 找到技能
- 跳转对应 GitHub 仓库
- 复制技能目录到:
~/.codex/skills/
7.4 小结
本章说明了 Agent Skills 的概念、目录结构与作用域优先级,并整理了常见社区资源。技能的目标是把零散 Prompt 升级为可复用、可共享的工作流包。
落地建议从一个高频任务开始(如 PR 审查、发布检查、迁移脚本),把输入、验收标准、脚本与模板收进一个 skill,再逐步扩展到团队共享。
08 总结篇:5W1H 心智模型
本章用于把前面各章的知识点串成一条主线。用 5W1H(What / Why / Who / When / Where / How)快速回答:Codex 到底是什么、为什么要用、团队里谁该参与、什么时候用哪些能力、它运行在哪里、以及如何从 0 到工程化落地。
你可以把本章当作复习提纲:需要对外解释 Codex、做团队共识、或回看关键边界与落地路径时,直接从这里查即可。
8.1 【WHAT】:Codex 是什么?
Codex 是面向真实工程场景的软件工程 AI 代理(Coding Agent):它不是“只会生成代码的聊天模型”,而是能在工程工作台里 读仓库、改文件、跑命令、做审查、产出可验证证据 的“工程级协作者”。
一、它的本质:一个“可执行”的工程智能体
- 输入:自然语言提示(Prompts)+ 代码上下文(文件/选区/截图)+ 工程约束(规范/安全/验证标准)。
- 过程:模型推理 → 调用工具(读写文件/运行命令/检索资源/连接外部系统)→ 根据结果迭代。
- 输出:不仅是文字解释,更包括 跨文件变更、测试/构建结果、diff、PR 审查意见 等“可交付物”。
二、四个核心抽象:Prompts / Threads / Context / Workflows
1)Prompting(提示词)
- 关键原则:Codex 在“可验证”时质量更高。复现步骤、验证命令、验收标准越明确,越容易形成闭环。
- 复杂任务最好拆分成更小步骤:可以先让 Codex 给计划(例如
$plan),由读者审查后再执行。
2)Threads(线程/会话)
- 一个 thread 包含:多轮提示 + 模型输出 + 期间的所有工具调用记录。
- 线程可以恢复继续;也可以并行跑多个线程,但应避免多个线程同时改同一文件。
- 本地线程(Local threads):在本地机器运行,可直接读写本地文件、运行本地命令,默认受沙箱保护。
- 云端线程(Cloud threads):在云端隔离环境运行,会克隆仓库并检出分支;适合并行任务、跨设备委派、或长任务执行。
3)Context(上下文)
- IDE 插件通常会自动带上“打开的文件 + 选中的代码”作为上下文;CLI 更依赖显式引用(如
@path或/mention)。 - 上下文需要适配模型的 context window;会话过长时 Codex 可能自动“压缩上下文”(summary + 丢弃无关细节),以便持续推进长任务。
4)Workflows(工作流程)
一个可复用的工程 workflow 通常应包含:
- 适用场景:什么时候用、用 IDE/CLI/Cloud 哪个入口更合适。
- 步骤与示例提示:能直接复制运行。
- 上下文说明:哪些自动可见、哪些需要显式提供。
- 校验方法:怎么证明“做对了”(测试/复现/对比/验收清单)。
三、它能“在哪些入口”工作:IDE / CLI / Web(Cloud) / 集成平台
IDE Extension(VS Code / Cursor / Windsurf 等兼容 VS Code 的编辑器)
- 优势:上下文天然就在编辑器里(打开文件、选区、符号定位),适合 边读边改边验证。
- 常见能力:切换模型、调整推理强度、选择审批模式、在本地/云端之间切换、
/review、/status、/auto-context、/cloud、/local等斜杠命令。
CLI(终端)
- 优势:天然与 shell/脚本/工具链结合,适合 批处理、跑测试、自动化执行、审查与记录。
- 支持:图像输入(如错误截图/设计稿)、恢复会话(
codex resume)、非交互执行(codex exec)、云任务(codex cloud ...)、/review、/diff、/compact、/model、/approvals、/mention等斜杠命令。
Web / Cloud(云端 Codex)
- 优势:后台并行执行、隔离容器、可直接产出 diff/PR,适合 复杂任务、并行执行、团队协作。
- 典型流程:创建容器 → checkout 仓库/分支 → 运行 setup/maintenance → agent 循环“编辑/运行检查/验证” → 输出 diff → 由读者审查并创建 PR 或继续迭代。
- 网络访问策略:setup 阶段可联网安装依赖;agent 阶段默认禁网(可按环境开启并细粒度限制)。
Integrations(集成)
- GitHub:PR/Issue 工作流中触发审查与任务委派(如评论
@codex review)。 - Slack:在团队 IM 中把任务委派给 Codex,获取进度与结果(适合“协作入口”)。
- Linear:可把 issue 分配给 Codex 或在评论里
@Codex,并可结合 MCP 在本地访问 Linear。
四、它如何“被工程化”:配置 + 安全边界 + 可复用资产
1)config.toml:Codex 的运行“总开关”
- 核心位置:
~/.codex/config.toml(CLI 与 IDE 共享)。 - 可控制:默认模型、推理强度、审批策略、沙箱模式、网络访问、环境变量传递、MCP 服务器、实验性功能开关等。
2)Approvals & Sandbox:把“能做事”变成“可控地做事”
- approval_policy:控制“什么时候需要确认”。
untrusted:仅安全只读命令自动执行,其余都要确认on-failure:沙箱内自动执行,失败时才提示升级/放权on-request:由模型决定何时询问(常见默认)never:从不询问(风险很高)
- sandbox_mode:控制文件系统/网络边界。
read-only(默认):只读workspace-write:允许写工作区(但某些目录仍可能只读)danger-full-access:无沙箱(极其危险,只建议在已有外部隔离时使用)
术语澄清:文章(尤其是 CLI/IDE 章节)里也会出现“批准模式/Approval Modes(如 Auto / Read-Only / Full Access)”的说法,它更像是产品界面上的一组预设;而
config.toml中的approval_policy/sandbox_mode是底层配置键。不同版本/不同入口可能在命名上略有差异,但本质都是在控制“是否需要确认”以及“可访问的文件/网络边界”。
3)Rules:控制“哪些命令可以在沙箱外跑”
~/.codex/rules/*.rules:通过规则语言定义允许/提示/禁止的命令前缀(如prefix_rule(pattern=["gh","pr","view"], decision="prompt", ...))。- 多规则匹配时选“限制性最强”的结果:
forbidden > prompt > allow。
4)AGENTS.md:让 Codex“默认懂项目与规范”
- Codex 会在启动时按路径分层发现并合并指令文件(全局 + 仓库根 + 子目录 override)。
- 典型用途:写清楚“怎么跑测试/怎么 lint/改动要注意什么/不能做什么”。
5)Custom Prompts vs Skills:提示复用的两条路
- 自定义提示词(Custom Prompts):存放在
~/.codex/prompts/*.md,显式调用(如/prompts:draftpr),更偏“个人复用”。 - Skills(Agent Skills):指令 + 资源 + 可选脚本打包,可显式或隐式调用,可仓库级共享,更适合“团队 SOP 固化与复用”。
6)MCP:把智能体连接到外部真实系统
- 在
config.toml中配置[mcp_servers.<name>],支持 STDIO 进程型与可流式 HTTP 服务器型。 - 可让 Codex 访问第三方文档、设计工具(Figma)、浏览器控制(Playwright/Chrome DevTools)、日志平台(Sentry)、项目管理(GitHub/Linear)等。
五、学习资源:251 篇官方 Cookbooks(索引型内容)
第三篇文章本质上是一个“官方实战指南导航”,把 251 篇 Cookbooks(去除归档)按主题整理,覆盖:
- 开源与自部署(gpt-oss 本地/自托管生态)
- 多模态(图像/视觉/视频)、音频/语音
- 检索/RAG/搜索(占比最大)
- ChatGPT 生态、工具调用与扩展、代理与自动化
- 微调/训练与提示词、评测/安全/合规
- 开发工具与工程实践、基础 API 与性能优化
8.2 【WHY】:为什么要用 Codex?
一、它解决的核心不是“会不会写代码”,而是“交付闭环效率”
真实工程里最耗时的往往不是敲代码,而是:
- 跨文件定位真正的改动点、理解依赖与数据流
- 改完后跑测试/构建/脚本 → 根据报错继续修 → 再验证(闭环)
- 代码审查、补测试、写变更说明与文档、整理证据
Codex 的价值在于:它能在同一工作台里,把“理解 → 修改 → 执行 → 验证 → 复盘”尽量跑完,让人把时间更多用在架构判断与需求决策上。
二、它把“工程经验”变成默认流程(团队价值)
当团队开始把 Codex 当“工程成员”使用时,效率之外更重要的是稳定性:
- 用
AGENTS.md把团队约束写出来(测试、lint、目录结构、禁忌操作、提交规范等)。 - 用
config.toml固化安全边界(审批策略、沙箱模式、网络访问、环境变量传递)。 - 用 Rules 把“沙箱外命令”做门禁(允许/提示/禁止),降低误操作风险。
- 用 Skills 把 SOP(比如“发版前检查”“迁移可回滚”“PR 必须附证据”)封装成可复用能力,让不同项目输出一致。
三、它让 SDLC 全阶段都能引入智能体(AI-Native Team)
第二篇文章把 SDLC 分成 Plan / Design / Build / Test / Review / Document / Deploy&Maintain,并给出“智能体能做什么、人类要做什么、入门清单”。核心结论是:
- 智能体越来越适合做“多步、重复、可验证”的工程任务;
- 人类更应聚焦:需求意图、架构取舍、安全与性能边界、上线决策与责任。
四、多端形态让 Codex“放在合适的位置”
第四篇文章强调:入口选对了,体验会从“能用”变成“顺手”:
- 写代码/改代码/读代码:IDE 最顺
- 批处理、跑脚本、审查、记录:CLI 更强
- 并行大任务、产出 PR、隔离执行:Cloud 更合适
- 团队协作委派入口:GitHub/Slack/Linear 集成更自然
8.3 【WHO】:谁适合用?团队如何协作?
一、个人开发者
- 快速理解陌生仓库、修 Bug、补测试、做本地审查、整理文档与变更摘要。
- 适合从 CLI/IDE 开始,用“可验证提示 + 小步迭代”建立正反馈。
二、Tech Lead / 架构与平台团队
- 更关心“把能力变成流程”:配置、权限、规范、复用模板、质量门禁。
- 典型抓手:
AGENTS.md(规则与约束)、Skills(SOP 固化)、Rules(沙箱外命令门禁)、Cloud/Integrations(接入团队系统)。
三、测试 / 质量工程
- 让 Codex 按项目约定补测试、跑测试并回传证据;把测试作为独立步骤纳入工作流。
- 典型抓手:在
AGENTS.md写清测试框架、覆盖要求、常用命令;用 workflow 指定“先写测试再修 bug”等策略。
四、运维 / 安全 / 合规
- 重点是边界与审计:审批策略、沙箱、网络访问风险、prompt injection 风险、密钥处理方式。
- 典型抓手:config.toml 的
sandbox_mode/approval_policy、Rules 的forbidden/prompt、Cloud 的网络访问策略与 secrets 生命周期、MCP 的工具白名单/黑名单。
五、协作场景的“入口角色”
- GitHub:PR/Review/Issue 让 Codex 成为协作者(例如评论触发 review)。
- Slack:更像“团队机器人”,适合问答、委派、进度同步。
- Linear:更像“任务执行者”,可分配 issue、自动更新进展、并能通过 MCP 在本地读取任务上下文。
8.4 【WHEN】:什么时候用哪些能力/入口?
这一部分把七篇内容里的“案例、能力与阶段”合并成一张“时间点地图”:读者可以按任务阶段(SDLC)或按任务类型来选入口与能力。
一、按 SDLC 阶段选 Codex 的用法(来自 AI-Native Team 章节)
- Plan(规划):读规范/工单/仓库,拆任务、估复杂度、标依赖与风险;人类负责优先级与关键路径决策。
- Design(设计):搭骨架、生成样板、从设计稿/截图生成组件、提出可访问性建议;人类审核设计一致性与可扩展性。
- Build(构建):跨文件实现功能、补错误处理/遥测/安全包装、修构建报错;人类把控架构、安全与性能边界。
- Test(测试):生成测试用例、补边界场景、随代码演进维护测试;人类审核测试有效性与覆盖目标。
- Review(审查):本地
/review或 PR review;人类做最终合并判断与架构一致性把关。 - Document(文档):更新 README/指南/排障文档,生成结构化说明与变更摘要;人类审核准确性与信息组织。
- Deploy & Maintain(部署运维):结合日志/遥测/工单系统做排障建议;人类决定修复与发布策略并保持最终控制。
二、按“任务类型”选入口:IDE / CLI / Cloud / 集成
| 任务类型 | 更推荐入口 | 原因(概括) |
|---|---|---|
| 理解代码、追数据流、解释模块职责 | IDE | 打开文件/选区天然就是上下文 |
| 修 Bug(可复现)、跑测试验证 | CLI / IDE | CLI 更擅长执行命令与记录;IDE 更适合定位与修改 |
| 写测试(对齐项目习惯) | IDE(选区)/ CLI | IDE 选中函数更快;CLI 便于明确文件路径与批量跑测 |
| 从截图/设计稿生成 UI | CLI / IDE | 支持图像输入;可要求可运行交付物 + README |
| UI 快速迭代(改样式→预览→再改) | CLI + 本地 dev server | 双终端循环更顺畅 |
| 大型重构(本地规划 + 云端并行实现) | IDE → Cloud | 本地审计划、云端跑实现与验证,最后拉 diff/PR |
| 提交前质量检查 | CLI /review |
不改文件,集中输出可执行建议 |
| 审查 PR(无需拉分支) | GitHub 集成 | 评论触发 review,适合团队协作 |
| 更新文档与变更说明 | IDE / CLI | 方便引用文档并做链接校验 |
三、Workflows 里的 9 个典型案例(可直接当“模板”)
第二篇文章给了 9 个 workflow 案例,读者可以把它们理解为“最常用的九种提问方式”:
- 解析代码库(模块职责、数据校验点、潜在坑)
- Bug 修复(复现步骤 + 约束 + 回归测试 + 验证)
- 编写测试(对齐项目约定、覆盖 happy path 与 edge cases)
- 从截图原型生成代码(约束技术栈 + 交付物 + 运行方式)
- 迭代 UI(提出多方案 → 选定 → 细化)
- 将重构任务委派到云端(先计划再执行里程碑)
- 本地代码审查(
/review,聚焦边界与安全) - 审查 PR(GitHub 评论
@codex review ...) - 更新文档(明确要更新的章节、验证链接与渲染)
8.5 【WHERE】:它运行在哪?配置/文件放哪?边界在哪里?
一、本地:读者需要记住的“Codex 工作目录体系”
1)主目录(CODEX_HOME,默认 ~/.codex)
~/.codex/config.toml:核心配置(模型/审批/沙箱/MCP/功能开关等)~/.codex/rules/*.rules:沙箱外命令规则(allow/prompt/forbidden)~/.codex/prompts/*.md:自定义提示(显式调用/prompts:<name>)~/.codex/skills/:用户级技能(可跨仓库复用)- 可能的状态文件:
auth.json、history.jsonl、日志与缓存等
2)项目/仓库内(随代码走的沉淀)
AGENTS.md/AGENTS.override.md:项目与子目录的指令(分层合并)<repo>/.codex/skills/:仓库级技能(团队共享、随仓库分发)- 其他项目资料:README、docs、团队指南(可通过 fallback 文件名让 Codex 识别)
二、云端:任务在隔离容器内如何跑?
Cloud 任务大致流程:
- 创建容器并 checkout 仓库/分支或指定 commit
- 运行 setup(必要时运行 maintenance;使用缓存容器会更常见)
- 应用网络策略:setup 阶段可联网;agent 阶段默认禁网(可按环境开启)
- agent 循环执行:编辑代码 → 运行检查(测试/lint 等)→ 根据结果迭代
- 输出结果:展示 diff/日志/验证信息 → 由读者审查并开 PR 或继续追问
三、Secrets 与网络访问:云端边界要特别注意
- 环境变量:可在任务全过程(setup + agent)可用。
- secrets:运行期加密存储,通常只在 setup 阶段可用,agent 阶段会移除(降低泄露风险)。
- 网络访问风险:agent 阶段开网会引入 prompt injection、敏感信息外泄、恶意依赖下载、许可证风险等;建议尽量限制可信域名并审查日志。
四、指令发现“在哪里发生”:AGENTS 的分层合并
Codex 启动时会构建指令链:
- 全局:
~/.codex/AGENTS.override.md(若存在)否则~/.codex/AGENTS.md - 项目:从项目根到当前工作目录逐层检查:
AGENTS.override.md→AGENTS.md→project_doc_fallback_filenames中的文件名
- 合并顺序:从根到叶拼接,越靠近当前目录优先级越高;默认最多嵌入
project_doc_max_bytes(32 KiB)
五、技能“在哪里加载”:Skills 的作用域优先级
同名技能会被“更高优先级作用域”覆盖(从高到低概括):
- REPO:当前目录或仓库根的
.codex/skills - USER:
$CODEX_HOME/skills(默认~/.codex/skills) - ADMIN:
/etc/codex/skills - SYSTEM:随 Codex 打包的系统技能
8.6 【HOW】:怎么从 0 到工程化落地(可直接照做)
这一章把七篇文章里所有“操作型内容”串成一条落地路径:先能用 → 再顺手 → 最后团队化与平台化。
Step 1:准备账号与入口(Web / CLI / IDE)
- 明确使用入口:IDE(编辑器内)、CLI(终端)、Cloud(Web)或团队集成(GitHub/Slack/Linear)。
- CLI 常见安装方式:
# npm
npm install -g @openai/codex
# Homebrew(macOS)
# 两种写法在文章中都出现过,按安装渠道选择其一:
brew install codex
brew install --cask codex
- 运行
codex,选择 ChatGPT 登录 或 API Key,完成授权。
Step 2:先把“安全边界”设好(配置 + 审批 + 沙箱)
在 ~/.codex/config.toml 里优先关注三件事:
- 默认模型(影响质量/成本/速度)
- approval_policy(影响“什么时候询问确认”)
- sandbox_mode(影响“它能改哪里、能不能联网”)
示例(偏稳妥、适合日常开发):
model = "gpt-5.2-codex"
approval_policy = "on-request"
sandbox_mode = "workspace-write"
如果需要让工作区之外某些路径可写(如特定工具链目录),可在 sandbox_workspace_write.writable_roots 精确放行;如果要开网络访问,尽量只在必要时按环境开启,并配合 Rules/日志审计。
Step 3:学会写“工程级提示词”(把任务变成可验证的闭环)
博主建议提示至少包含 5 个元素(顺序可调):
- 目标(Goal):需要交付什么结果
- 上下文(Context):相关文件、入口、运行环境(IDE 可少写,CLI 要写清)
- 约束(Constraints):不改 API、不引入依赖、最小 diff、性能/安全边界
- 交付物(Deliverables):需要哪些文件/改动/说明
- 验证(Verification):复现步骤、测试命令、lint、验收清单
示例(Bug 修复类):
- “问题是什么 + 复现步骤 + 不允许改什么 + 必须补什么测试 + 修完怎么验证”
示例(功能实现类):
- “按项目规范实现 X,要求跑通
npm test,并给出变更摘要与验证结果”
Step 4:把常用任务套进 Workflows(九大模板直接复用)
- 解析代码库:让它输出“请求流编号步骤 + 涉及文件列表 + 校验点 + 潜在坑”
- 修 Bug:让它先复现(或解释如何复现)→ 修复 → 跑测 → 回归测试
- 写测试:选中函数/引用文件 → 明确覆盖 edge cases → 对齐项目 conventions
- UI 从截图:给技术栈、路由/页面交付物、README 运行说明
- UI 迭代:先要 2-3 个方案,再逐步收敛
- 大重构:本地先计划(里程碑)→ 云端执行里程碑 → 拉 diff/PR
- 本地审查:
/review,加上安全/边界/性能关注点 - PR 审查:GitHub 评论
@codex review for ... - 文档更新:指定章节、要求校验链接与渲染
Step 5:选模型与推理强度(把“质量/成本/速度”调到合适)
文章给出的典型模型选择思路:
- 默认推荐:
gpt-5.2-codex(工程任务最强通用) - 成本敏感:
gpt-5.1-codex-mini(更省但能力略弱) - 长任务/更深推理:
gpt-5.1-codex-max(更适合长链路编码任务) - 通用智能体:
gpt-5.2/gpt-5.1(更泛化)
备注:在配置参考(config reference)片段中写明 “默认:所有平台均为
gpt-5.2-codex”。如果在某些地方看到 “macOS/Linux 默认gpt-5-codex、Windows 默认gpt-5” 之类描述,通常意味着它来自更早的版本/文档表述;以当前安装版本的/status与~/.codex/config.toml生效值为准。
CLI 可临时切换:
codex -m gpt-5.1-codex-mini
也可在会话中 /model 切换。
Step 6:用 Rules 给“沙箱外命令”上门禁(允许/提示/禁止)
- 在
~/.codex/rules/下创建*.rules。 - 用
prefix_rule()匹配命令前缀,指定decision:allow:直接放行prompt:每次提示确认forbidden:直接拒绝(建议写替代方案)
- 写
match/not_match当“内联单测”,避免误配。 - 注意
bash -lc这类包装器可能隐藏复合命令,Codex 会做特殊处理;能拆分时会拆分后再判定规则。
Step 7:用 AGENTS.md 让它“默认懂项目”(全局 + 仓库 + 子目录覆盖)
读者可以从两层开始:
1)全局 ~/.codex/AGENTS.md(个人工作约定)
- 常用测试命令、依赖管理偏好、是否允许加生产依赖、提交规范等。
2)仓库根 AGENTS.md(项目规范)
- 如何运行/测试/构建、目录结构、禁忌操作、安全要求、文档要求。
当某个子目录(如某个微服务)有特殊规则,用 AGENTS.override.md 放在子目录里覆盖。
验证是否生效:
codex --ask-for-approval never "Summarize the current instructions."
Step 8:把高频提示做成“自定义提示词”(个人复用)
- 创建
~/.codex/prompts/xxx.md,在 YAML front matter 写description与argument-hint。 - 在内容里使用占位符(如
$FILES、$PR_TITLE或$1..$9)。 - 重启 Codex 后用
/prompts:xxx调用。
适用:个人常用的“草稿 PR”“变更摘要”“统一 review 模板”等。
不适用:需要随仓库共享、希望隐式触发的 SOP(这更适合 Skills)。
Step 9:接入 MCP,让它能用“外部工具与真实系统”
两种方式:
- CLI:
codex mcp add ... - 直接改
~/.codex/config.toml的[mcp_servers.<name>]
读者需要重点理解的配置维度:
- STDIO(本地进程):
command/args/env/env_vars/cwd - HTTP(远程服务):
url、token 与 headers、OAuth(codex mcp login <name>) - 运行控制:
enabled、startup_timeout_sec、tool_timeout_sec、enabled_tools/disabled_tools
Step 10:用 Skills 把 SOP 封装成“团队可复用能力”
技能的核心是一个目录 + SKILL.md(可以附带脚本/资源/模板),Codex 采用“渐进式披露”:
- 启动时只加载 skills 的 name/description(省上下文)
- 显式调用:
/skills或在提示中$SkillName - 隐式调用:任务与 description 匹配时自动选择技能
保存位置的三种常用方式:
- 用户级:
~/.codex/skills/<skill>/SKILL.md(个人跨仓库复用) - 仓库级:
<repo>/.codex/skills/<skill>/SKILL.md(团队随仓库共享) - 符号链接:把“公司技能仓库”链接到
~/.codex/skills/(统一维护)
常见排查点:
- 文件名必须是
SKILL.md - YAML/name/description 需符合格式与长度限制
- 触发不明显:description 写得不够明确或多个技能意图重叠
社区/官方资源:
openai/skills(官方推荐,可直接用/可做模板)agentskills/agentskills(更偏规范与写技能指南)anthropics/skills(可借鉴复杂技能组织方式)agentskills.io(索引/市场)
8.7 小结
本章用 5W1H 把前面各篇串成一条主线:是什么、为什么、谁参与、何时用、在哪运行、以及如何工程化落地。
如果只记一条:用 config / approvals / sandbox 画边界,用 rules / agents / prompts / mcp / skills 做复用,让每次协作都能形成可验证的交付闭环。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)