AI大模型原理概述
模型的训练通常包含三个关键阶段:预训练(无监督学习,奠定通用知识基础)、监督微调(SFT,教会模型遵循指令执行特定任务)以及基于人类反馈的强化学习(RLHF,使模型输出更安全、可靠且符合人类偏好)。文章还阐释了Token、向量嵌入、Transformer架构(特别是自注意力机制)等技术细节,说明了模型如何理解上下文、处理一词多义,并逐词生成文本。最后,文章也客观讨论了当前大模型可能产生“幻觉”(即
过去ai分析的思路
2021以前决策式ai:获取到过去历史的数据,然后基于历史的数据进行机器学习,得到一个模型,进行分析预测。
在企业侧用的比较多如智能推荐,风控等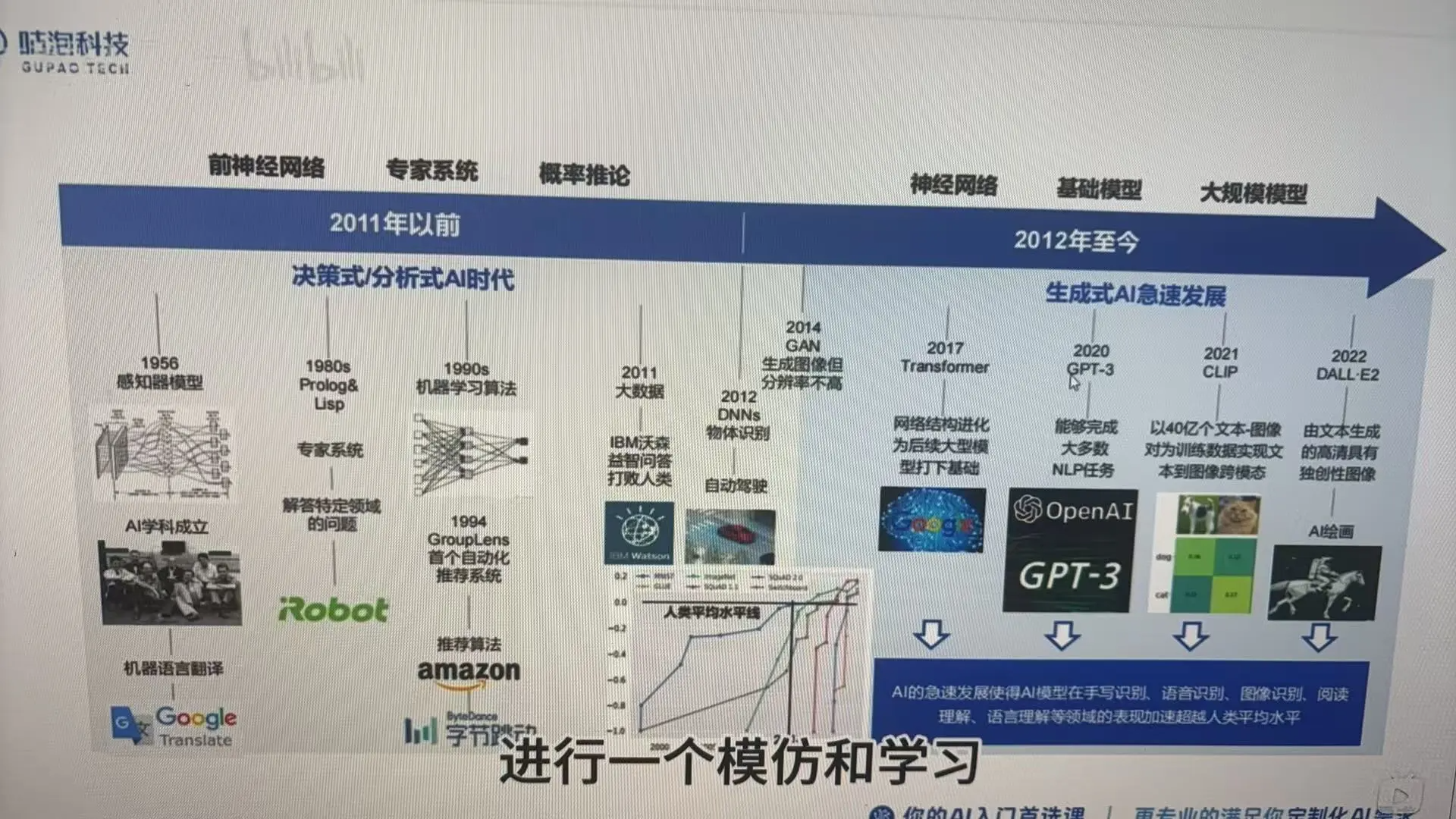
2012至今生成式ai:学习归纳已有数据后进行创造,有一个创造的过程,对历史的数据进行学习,然后通过缝合式的创作可以生成全新的内容,也能进行决策和判断,更符合人类对ai的定义。
生成式ai
大语言模型LLM
根据上下文来推理出下一个文字是什么,生成的下一个文字继续回到上下文语句,来生成更多的文字。
这就是ai大模型生成文本的一个基本原理。
需要三步:
- 预训练
a. 无监督学习:模型在大数据集中自主学习 - 微调
a. 非必要步骤
b. 有监督:通过在人工标注的数据集上训练优化模型,使其“有用”,“安全” - 推理
a. 与人在线、实时交互
b. 使用已经训练好的模型生成响应
无监督学习(预训练)
这是模型训练的起点。基于一些网络上的公开资料进行无监督学习,我理解是让ai熟悉这个世界。
比如gpt3无监督学习使用的是Common Crawl 网络爬虫公开数据集,WebText2: Reddit论文的网页文本,Books1,Book2 互联网书籍语料库,Wikipedia:整个英文维基百科知识库。
会去学习这些语料库里的token。
它的任务很纯粹:预测下一个词。通过这个简单的任务,模型在数十亿次的练习中,无监督地学会了词汇的搭配、语法结构、逻辑关系,甚至吸收了大量世界知识。这个过程就像让模型进行“博览群书”式的广泛阅读,为其打下了坚实的语言基础
token
token是模型处理和理解文本的基本单元。模型通过把用户输入的文本解析成token,然后在这些token的基础上进行计算和推理。token可以看成一个个小的单词(不一定是这样划分,大概差不多),可以去platform.openai.com/tokenizer上去试试如何划分的。
大模型不是直接对这些token进行计算和推理的,每个token都有自己的一个tokenId,基于tokenId去计算。
监督学习和无监督学习的区别
监督学习:经过预训练的模型虽然“学识渊博”,但还不会按要求做事,它只会自顾自地续写文本。为了让模型变得“有用”,就需要监督微调。在这个阶段,我们会使用高质量、小规模的“指令-答案”数据集(例如,人类编写的问答对、翻译对等)来训练模型。模型需要学习的不再是预测任意下一个词,而是根据给定的指令(如“将‘你好’翻译成英文”)生成符合要求的答案(“Hello”)。通过这种方式,模型被教会如何理解指令并输出有用的回应。
总而言之,监督学习提供的是从有标签数据(输入-输出对)中学习映射关系,目标是让生成的答案更“对”。
举例:Tom和Jerry的例子:假设我们想训练一个模型来识别Tom和Jerry。
准备教材(带标签的数据集):我们需要准备成千上万张图片,并且人为地给每张图片打上标签,明确告诉模型“这是Tom”、“这是Jerry”,或者“这是狗(Spike)”、“这是小鸭子”等其他角色。
学习过程:模型通过分析这些图片的像素、形状等特征,逐渐学习到Tom的特征(比如,体型较大、灰色皮毛),以及Jerry的特征(体型小巧、棕色皮毛)。
预测:训练完成后,当你给模型看一张它从未见过的Tom和Jerry追逐的截图时,它能够准确地指出“这里是Tom”,“那里是Jerry”。
本质:监督学习就像是有老师手把手教学,给出明确答案,目标是让模型学会精确判断。常见的应用包括图像分类、垃圾邮件过滤和房价预测等
无监督学习:无监督学习是一种机器学习范式,其核心在于模型从没有人工标注标签的数据中自行探索并发现其内在的隐藏结构或规律 。经过这种学习后,系统能够揭示数据特征之间的关系,例如将相似的数据点聚合在一起(聚类),或简化数据的复杂程度(降维)
以训练ChatGPT-3这样的模型为例,其初始的“预训练”阶段正是无监督学习的典型应用:
- 学习过程:模型接触海量互联网文本(无标签数据)。其训练任务是自监督的,具体表现为因果语言建模:给定一段文本序列,模型的任务是预测下一个最可能出现的词元(Token)。通过不断尝试和对比预测结果与真实文本,模型持续调整其内部参数(权重)。
- 学习成果:在这个过程中,模型并非简单地记忆,而是逐步掌握了人类语言的语法、句法、常见搭配乃至蕴含在文本中的部分常识和逻辑关系。最终产出的是一个具有强大语言理解和生成潜力的基座模型。
然而,这个基座模型确实与最终能进行高质量对话的模型存在巨大差距:
- 基座模型的能力局限:它更像一个强大的“文本补全引擎”。当输入“湖南的省会城市是”时,它能基于训练数据中的统计规律高概率地输出“长沙”。但它并不真正“理解”指令,也无法可靠地进行多轮对话、拒绝不当请求或生成符合特定格式的答案。
- 从“补全”到“对话”的飞跃:为了实现如ChatGPT一样的对话能力,必须对基座模型进行进一步的微调。这一阶段通常采用监督微调和基于人类反馈的强化学习等方法,使用大量精心编写的指令-回答对来教模型如何理解并遵循人类的指令,使其从一个知识渊博的“学者”转变为一个有用的“助手”。
监督微调(SFT)
所谓的微调就是在已有的基座模型上进一步的训练。 这个步骤也会去改变模型内部的参数,让模型更加适合特定的一个任务。比如如果你要训练出一个对话的模型,那就要让基座模型看到更多对话的数据。这个时候模型不需要从海量的无意义的数据中去学习,而是去人类提供的高质量的对话内容中去学习。
这个过程就是监督学习,相当于是给了模型数据以及答案,告诉模型这个猫是tom,老鼠是jerry。
强化学习(RL)
为了让模型的能力进一步的提升,还能对微调后的模型进行强化学习。强化学习就是让模型在环境中采取行动并获得结果反馈,从反馈中继续学习。从而能在特定的环境下采取最大的行动反馈。相当于"职场实战"。模型进入一个复杂的环境(与人类交互),需要自主尝试不同的回答(行动),然后根据反馈(奖励)来调整策略,目标是让自己的回答更符合人类偏好,从而获得更高的长期认可
到这里我们对模型灌入了大量的无监督学习的数据,也对其进行了特定任务的监督学习数据,以及对各种任务下的场景进行强化学习后,基本可以得到一个可以使用的大模型了。
比如对模型输入一个词语,他就会根据你给的词语一个token一个token的去根据历史训练的内容去填充。
这大概就是大模型文本生成的一个基本内容。
具体是怎么训练的呢
比如你输入一个句子,“I like _”,让模型去预测后续的token,那模型就只能根据你之前给他训练的数据,比如有“I like apple”, “I like banana”, “I like orange”, 那最后就是每个都是1/3的几率去使用。
但是这样会有问题,比如我们经常可以看到大模型在胡说八道,和你问的问题答的完全不一样,也就是幻觉的产生,实际上也是因为大模型其实无法去理解文本的意义,只能根据上下文的概率去生成。但是无法保证内容是符合我们的意思的。
随着数据集的正确量逐渐变大,一些很低级的幻觉问题基本也不会出现了。
向量嵌入
比如我问大模型,“我平时吃的水果有哪些”,这时候大模型应该要基于“水果”这个点去提供token,但是上文我们也知道大模型无法知道我们提供的token的一些真实语意。这个就涉及到一个向量嵌入的概念。
根据前文说的,大模型使用的是tokenId,而不是具体的文本,每个token都会是一个整数数字来表示。 我们需要把数据通过向量化嵌入,转化为向量结构数据。向量本质上也是数字,比如32176这个tokenId,是转换为了0.17,0.67,0.83这一串。为什么要这么做呢,是因为向量化表示的维度会更加丰富,一串数字能代表的东西肯定比一个数字更多,表示的也更方便。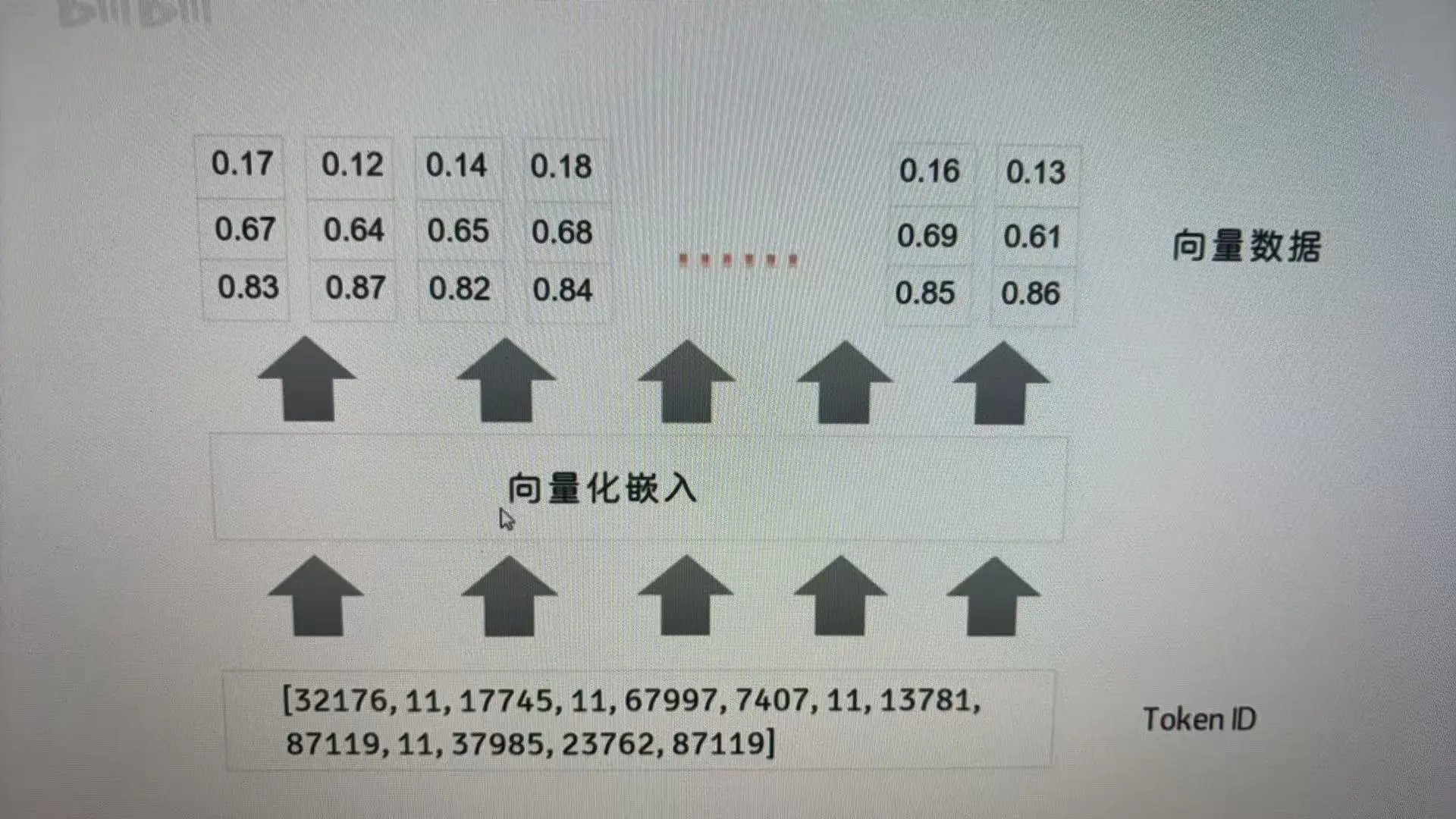
举例假设
我们就以苹果举例,对于苹果的tokenId进行向量化后假设得到了一组三个数字组成向量,每一个数字都代表这个词在某个特定“特征维度”上的强度或相关性得分。
| 向量维度 | 可能的语义特征 | “苹果” (水果) 的取值 | “苹果” (公司) 的取值 | 数值含义说明 |
|---|---|---|---|---|
| 第一维 | 事物类别 | 接近 1.0 (水果) | 接近 0.0 (非水果) | 正值越大,属于该类别的可能性越高 |
| 第二维 | 可食用性 | 接近 1.0 (可食用) | 接近 0.0 (不可食用) | 正值越大,可食用性越强 |
| 第三维 | 科技关联度 | 接近 0.0 (低科技感) | 接近 1.0 (高科技感) | 正值越大,与科技产品的关联越强 |
所以向量的长度越长,维度越高,代表的含义就越多,关联性也就这么来了。可以在空间中表示点或者与对象之间的关系。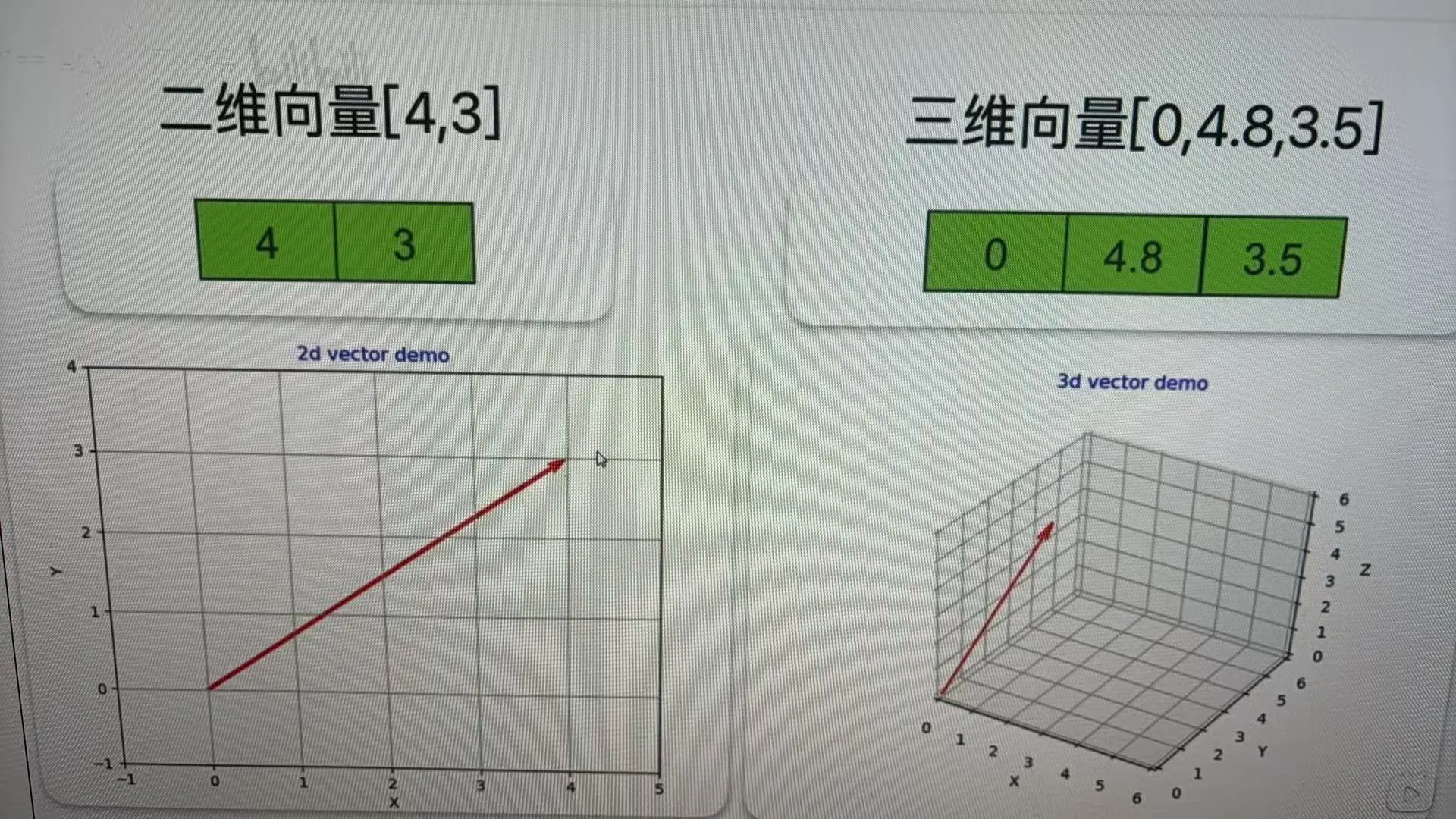
我们也可以通过计算向量之间的距离,来判断两个token之间在这个维度的语意相近度。
所以推理的时,基于输入的内容,会基于token向量归类成相似的内容,然后去相似的维度区间内区获取结果。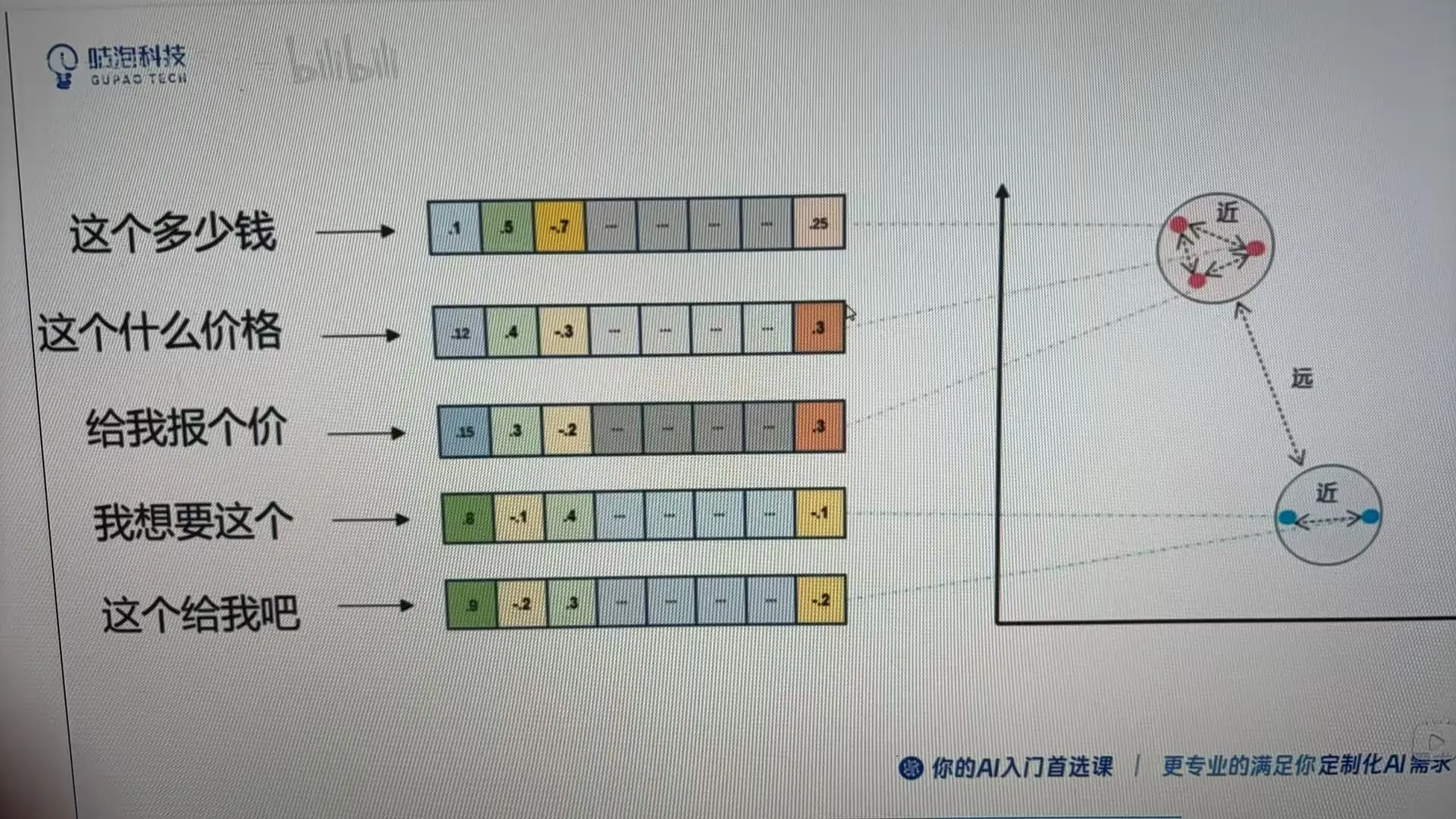
但是到这不禁有个疑问,相同的token对应的tokenId是一个,那如果一个token有多重语意,那最后转换出来的向量是什么呢,代表什么呢?
比如“我爱吃苹果”,和“苹果公司”,两句话里都有苹果这个token,那这个token对应的向量能是一样的吗?
很显然,如果单纯的通过tokenId进行查表得到静态的一串向量,那肯定是一样。但这里有最关键的一步是上下文建模,通过上下文建模,模型会分析整个句子,“吃” 这个动词作为强上下文信号,会告诉模型此处的“苹果”与“食物”高度相关。模型会增强向量中“水果”相关的特征,抑制“公司”相关的特征。而“公司” 这个名词作为强上下文信号,会引导模型增强向量中“科技企业”相关的特征,抑制“水果”相关的特征。
所以这个上下文建模,就需要一个注意力机制,可以并行处理所有的token,并计算每个token与其他所有token的关联权重,并根据上下文动态地更新每个token的向量表示。
transformer
transformer是2017年在论文里叫attention is all your need里面提出来的。提出来以后迅速成为了自然语言处理领域的一个主流架构,广泛用于各种任务,比如机器翻译,问答系统等等。
transformer模型的核心创新是自注意力机制,这使得模型能够在处理序列数据时,有效地捕捉序列内各元素之间的关系,无论他们在序列中的位置如何远近。
比如如下的一句话,其中的it可以指代animal也可以指代street,transformer基于注意力机制就会知道it指代的是animal。
会基于上下文中每个文字之间的关系和语意关系。
“it”指代“animal”的微观过程:当模型处理句子中的“it”时,它会生成一个Query向量。这个Query会去和句中所有词的Key向量进行匹配(计算点积)。由于“The animal didn’t cross the street because it was too tired”的语义逻辑,“it”的Key与“animal”的Key匹配度会最高,从而在计算“it”的新表示时,Value向量中包含的“动物”的语义信息会被赋予最大的权重。这样,“it”的向量表示就融入了“animal”的语义,成功完成指代。
因为语言关系是复杂的。一个词与其他词的关系可能同时包含语法、语义、指代等多种维度。Transformer通过“多头注意力”机制并行运行多个独立的注意力计算。这就好比有多组专家同时分析同一句话,一组专门关注语法结构,一组专门关注动词与宾语的搭配,另一组则关注指代关系。最后,将这些不同视角的洞察结果拼接起来,形成更全面、更丰富的词表示
比如当LLM去阅读短篇小说的时候,前几层transformer可能会去针对小说中的一些名词、主语等去处理,后面层次的transformer可能会针对段落去处理,从而实现对传入短片小说的一个深层次的理解。精准的去预测下一个词是什么。
详细解读: https://channels.weixin.qq.com/finder-preview/pages/feed?entry_card_type=48&comment_scene=39&appid=51&token=L%2FIS4ggBEAMaIAgEEhwxNzY5NDg3MzMwMzkyNjY0MzM3NERqWHBaM25SIhgIAxIUCAMSEA7HOcVkVv4FqMRaGvagnLw%3D&entry_scene=51&eid=export%2FUzFfAgtgekIEAQAAAAAAUTM2-EonhQAAAAstQy6ubaLX4KHWvLEZgBPEmacsTlAFUOOPzNPgMFkNAfkCNuEEwnow6rmMns4DkvXTCXxTRA
总结
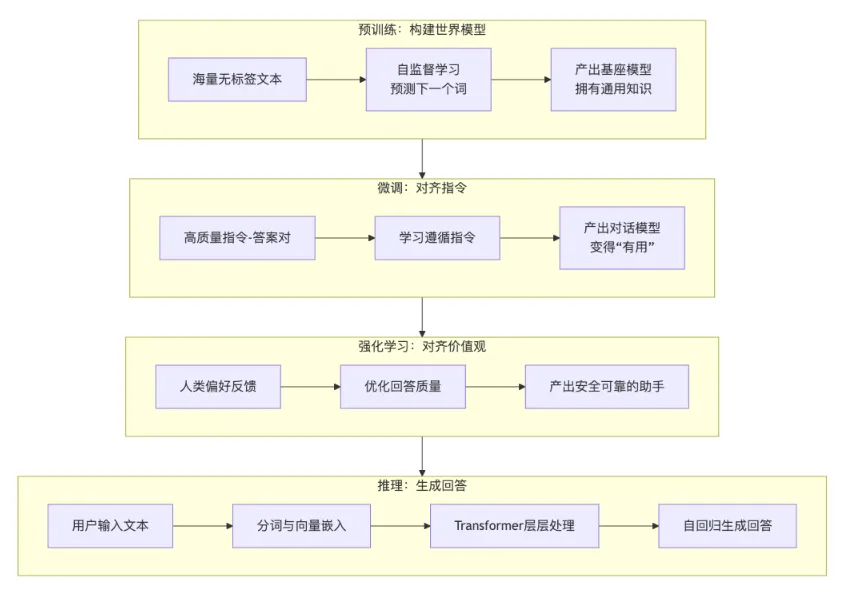
从“学习”到“对话”:模型训练的三个阶段
模型的能力并非与生俱来,而是通过三个关键训练阶段逐步获得的。
- 预训练:构建“世界模型”,打下知识根基这是模型的“博览群书”阶段。模型通过在海量无标注文本(如互联网数据、书籍、维基百科)上进行自监督学习,核心任务是预测下一个词(Next Token Prediction)。在这个过程中,模型逐步掌握了语法、逻辑和大量事实知识,最终形成一个基座模型。这可以类比于让学生通过广泛阅读来积累通识知识。
- 监督微调(SFT):学习遵循指令,变得“有用”基座模型知识渊博,但不懂如何与人类对话。监督微调阶段使用高质量、人工标注的“指令-答案”数据集来教学。模型学习的不再是随意预测下一个词,而是根据特定指令生成符合要求的回答。这如同“专项职业培训”,让模型变得“有用”,能完成问答、翻译等任务。
- 人类反馈的强化学习(RLHF):对齐人类偏好,变得“可靠”为使模型回答更安全、有用、符合人类价值观,会采用RLHF。人类评估员对模型的不同回答进行评分,训练出一个奖励模型来模拟人类偏好。随后利用强化学习算法优化模型,使其输出能获得更高奖励的回答。这一步是模型变得“可靠”的关键,能有效缓解“幻觉”(即胡说八道)问题。
从“问题”到“答案”:模型如何推理
当用户提问时,训练好的模型会经历一个复杂的内部处理流程来生成答案。
- 输入与理解:从文本到语义用户的输入文本首先被分词成模型认识的最小单元——Token。每个Token通过嵌入层转换为一个高维向量。这个向量不仅编码了Token的语义,其不同维度还代表了各种抽象特征,使得语义相近的词在向量空间中距离更近。
- 核心推理:Transformer与自注意力机制向量序列加上位置编码(提供词序信息)后,送入模型的核心——Transformer架构。其核心是自注意力机制,它让模型能够动态理解上下文。对于序列中的每个词,模型会计算它与句中所有其他词的关联度(注意力分数)。通过此机制,模型能根据上下文动态调整词的向量表示,解决一词多义问题。Transformer通常有数十甚至上百层,底层处理局部语法,高层则进行高级抽象和推理。
- 输出生成:从概率到文本模型通过线性层和Softmax函数将最终的语义向量映射到词汇表上,得到一个概率分布,表示下一个词的可能性。模型以自回归的方式,将当前生成的词作为新输入的一部分,循环预测下一个词,直到生成完整回答。
参考资料
总结来自原视频:https://www.bilibili.com/video/BV1bq9RYyEeW/?spm_id_from=333.1007.top_right_bar_window_history.content.click

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)