一看就懂!通过ChromaDB实现“个人知识库问答”场景的技术实现方案
本文提出一个基于RAG架构的个人知识库问答系统方案。系统包含知识库构建和智能问答两个阶段:在构建阶段,使用LangChain加载各类文档,通过文本分块(推荐500字符大小)和开源中文嵌入模型(如BAAI/bge-small-zh)将文档转化为向量存入ChromaDB;在问答阶段,结合语义检索和LLM生成答案,支持多路召回和结果重排序优化检索效果。文章强调合理设置分块大小、选择适配中文的嵌入模型以及
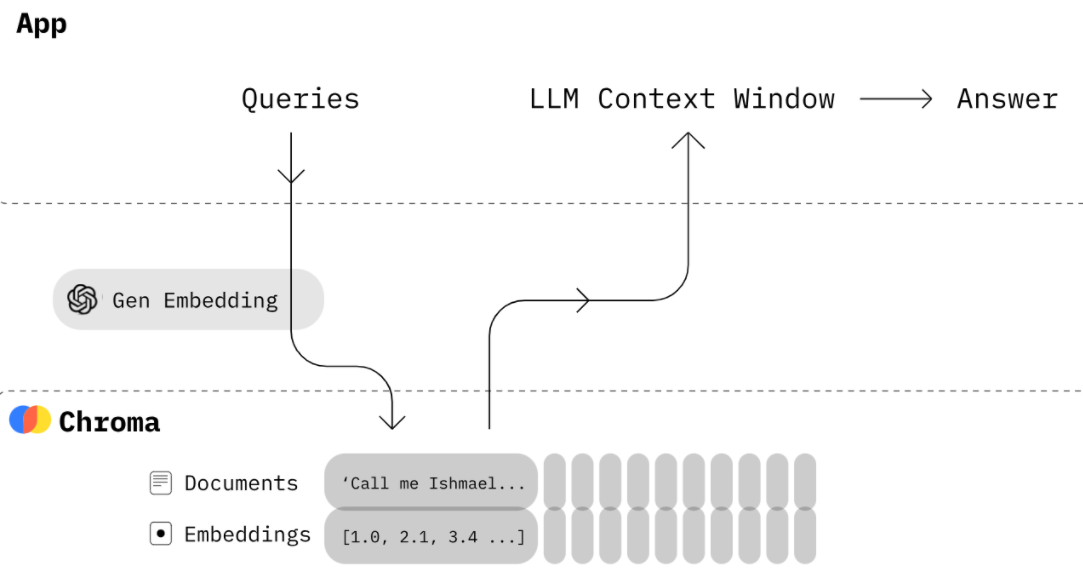
针对“个人知识库问答”场景,设计了一个基于RAG(检索增强生成)的架构方案。这个方案将文档、向量搜索与LLM结合,实现“从投喂的文档中学习并回答问题”的目标。
如果大家对chromadb的基础概念和操作还不是很清楚,可以参考文档:
https://blog.csdn.net/liwenxiang629/article/details/155980677
整体架构设计
下图清晰地展示了整个系统的核心流程和数据流转:
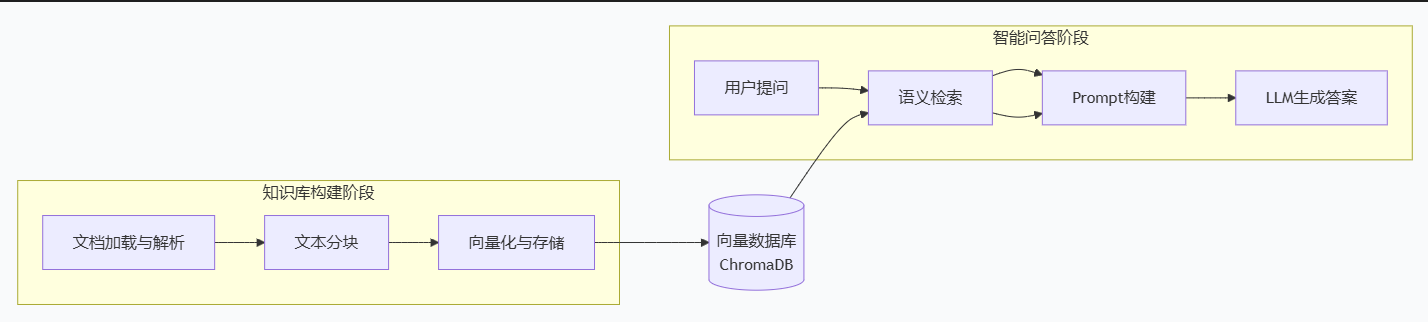
下面,我们分解来看每个环节的具体实现建议。
知识库构建阶段:从文档到向量
这是确保问答质量的基础,核心是将个人文档(如PDF、笔记、网页)转化为ChromaDB中富含语义的向量。
-
文档加载与解析
-
工具:推荐使用
LangChain或LlamaIndex的文档加载器。它们支持众多格式,能大幅简化工作。 -
覆盖类型:
-
Markdown / 纯文本:你的核心笔记。
-
PDF / Word:论文、报告、电子书。
-
网页:用
WebBaseLoader保存的博客、文章。 -
代码库:可用
TextLoader加载.py、.md文件。
-
-
-
文本分块策略
-
为什么分块:LLM有上下文长度限制,且过长的文档会包含噪声。
-
方法:使用
RecursiveCharacterTextSplitter。 -
关键参数:
-
chunk_size: 500:每个块约500字符,平衡信息完整性与精度。 -
chunk_overlap: 50:块间重叠50字符,避免语义被割裂。
-
-
-
向量化与存储
-
嵌入模型选型(关键!):由于是个人知识库,优先选择高质量且免费的开源模型。
-
中文优先:
text2vec-base-chinese、BAAI/bge-small-zh或moka-ai/m3e-base。它们在中文语义上表现更佳。 -
多语言:
paraphrase-multilingual-MiniLM-L12-v2。
-
-
元数据设计:为每个文本块添加元数据,便于后续过滤和溯源。这是高质量问答系统的关键。
# 添加数据时,丰富的元数据至关重要 collection.add( documents=[chunk_text1, chunk_text2, ...], metadatas=[ { "source": "我的机器学习笔记.md", # 文档来源 "page": 1, # 原始页码 "type": "concept", # 内容类型(概念/代码/总结) "category": "机器学习/深度学习" # 自定义分类 }, ... ], ids=[...] )
-
智能问答阶段:从问题到答案
当知识库构建完成后,就可以实现智能问答了。
-
语义检索
-
基础检索:直接使用
collection.query进行向量相似度搜索。 -
增强检索(推荐):
-
多路召回:除了向量搜索,可结合基于元数据(如
where={"category": "机器学习"})的过滤检索。 -
重排序:用更精细的模型(如
bge-reranker)对初步检索结果进行重排序,提升TOP结果的相关性。
-
-
-
Prompt构建与LLM集成
-
核心思想:将检索到的文档块作为“上下文”,和用户“问题”一起喂给LLM,让它基于上下文生成答案。
-
Prompt模板示例:
template = """ 请严格根据以下提供的上下文信息回答问题。如果上下文不包含答案,请直接说“根据我的知识库,无法回答此问题”。 上下文: {context} 问题:{question} 答案: """ -
LLM选型:
-
本地部署(隐私好):
ChatGLM3-6B、Qwen1.5-7B等,使用Ollama或LM Studio运行。 -
API调用(方便):OpenAI GPT、DeepSeek、千问等。
-
-
进阶优化建议
-
查询路由:系统可先判断用户问题是属于“知识库检索”类还是“通用聊天”类,再决定是否走检索流程。
-
记忆与历史:在对话应用中,可将历史对话的总结向量化后存入另一个Chroma集合,让AI记住之前的交流。
-
评估与迭代:准备一些“验证问题”,定期测试答案质量,据此调整分块大小、嵌入模型或检索策略。
快速开始:一个极简示例
这里是一个使用 LangChain 和 ChromaDB 的集成代码片段,帮你快速建立概念:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
# 1. 加载文档
loader = TextLoader("我的笔记.md")
documents = loader.load()
# 2. 分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# 3. 选择嵌入模型并创建向量库
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./my_knowledge_db" # 持久化目录
)
# 4. 检索(示例)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
docs = retriever.get_relevant_documents("什么是Transformer?")
print(docs[0].page_content)总结与核心建议
-
模型选择:中文知识库务必选择高质量的中文嵌入模型,这是效果的下限。
-
分块策略:分块大小是需要反复调试的最重要参数之一,直接影响检索精度。
-
元数据思维:在添加文档时,尽可能多地附加有意义的元数据,这是未来进行精细化检索和管理的基石。
-
低成本启动:先用本地开源模型(Embedding + LLM)搭建可运行的完整流程,验证效果后再考虑是否升级。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)