大模型应用:GPU的黑盒拆解:可视化看透大模型并行计算的底层逻辑.67
本文系统解析了GPU架构对大模型算力的支撑机制。首先阐述了GPU的SM架构、显存系统、PCIe接口等核心组件,重点分析了张量核心对矩阵运算的加速原理。其次揭示了GPU算力的三大并行来源:线程级并行、指令级并行和张量核心加速。通过案例分析展示了GPU计算流程中的数据传输瓶颈,并可视化呈现了并行任务拆分逻辑。最后指出优化方向在于减少CPU-GPU传输、提升显存带宽利用率和激活张量核心功能。全文通过架构
一、GPU 核心架构
显卡的核心是图形处理器,也就是我们常说的GPU,全称Graphics Processing Unit,它和 CPU 的本质区别是并行计算架构,CPU 擅长复杂的串行逻辑,GPU 则通过海量的计算核心,主攻高吞吐量的并行任务,比如大模型推理、图形渲染、深度学习训练。理解 GPU 底层原理,是搞懂大模型算力优化的关键。
GPU 的架构设计围绕“大规模并行”展开,是并行计算的硬件基础,我们先了解其核心组件及作用;

1. SM(流式多处理器)
- 架构层级:GPU 的基本计算单元,一个 GPU 包含数十到上百个 SM(如 RTX 4090 有 128 个 SM);H100等数据中心GPU可达132个以上SM
- 内部结构:每个 SM 内又包含:
- 1. CUDA 核心:负责通用浮点 / 整数运算(如大模型的矩阵乘法),每个SM包含64-128个CUDA核心
- 2. 张量核心(Tensor Core):专门加速矩阵乘加(GEMM)运算,是大模型算力的核心来源,支持FP16、BF16、INT8、INT4等混合精度计算
- 3. 光线追踪核心:主打图形渲染,对大模型无直接作用
- 4. 寄存器文件与共享内存:提供快速数据存储,共享内存支持线程块内高效通信
对大模型算力的影响:
- SM 数量决定 GPU 并行算力上限;更多SM意味着更高的理论峰值算力
- 张量核心是大模型 INT4/INT8 量化加速的关键硬件,相比传统CUDA核心可提供10-20倍的矩阵运算加速
- 在Transformer架构中,张量核心能高效处理注意力机制中的QKV矩阵运算
- 混合精度训练(FP16/BF16)依赖张量核心实现性能与精度的平衡
2. 显存(GPU Memory)
- 存储模型权重、输入输出数据、中间计算结果;常见类型:GDDR6X(消费级)、HBM3(数据中心级)
- 核心指标:
- 1. 容量:决定能存储多少数据,当前高端GPU显存达24GB(消费级)至80GB(数据中心)
- 2. 带宽:数据读写速度,GDDR6X达1TB/s,HBM3可达3TB/s以上
- 3. 延迟:数据访问响应时间
- 存储内容细分:
- 模型参数(权重和偏置)
- 激活值(前向传播中间结果)
- 梯度(训练时反向传播计算)
- 优化器状态(如Adam的动量和方差)
- KV缓存(自回归生成时存储)
对大模型算力的影响:
- 显存容量决定能跑的模型大小(如 14B 模型 INT4 量化需约 7GB 显存)
- 带宽决定数据传输速度 —— 带宽不足会导致 "GPU 等数据",算力空转
- 大模型训练时,显存容量限制批量大小(batch size),直接影响训练稳定性
- KV缓存机制显存占用随序列长度平方增长,长序列生成时显存成为关键瓶颈
- HBM3相比GDDR6X不仅带宽更高,且功耗更低,更适合大模型部署
3. 显存控制器
- 连接 SM 和显存,负责数据的读写调度
- 核心机制:
- 1. 多通道并行读写架构,通常8-12个独立通道
- 2. 内存地址映射与转换
- 3. 请求调度与仲裁算法
- 4. 错误检测与纠正(ECC)
- 支持内存压缩技术,在传输前压缩数据,提升有效带宽
对大模型算力的影响:
- 显存控制器的效率直接影响带宽利用率;高效控制器可实现90%+的理论带宽利用率
- 大模型推理时,高带宽能减少数据传输延迟,提升算力利用率
- 控制器调度算法优化能减少内存访问冲突,特别是在不规则访问模式下的性能
- ECC功能确保大模型长时间运行的稳定性,但会轻微降低可用带宽
- 多GPU系统中,显存控制器与NVLink/PCIe控制器的协同影响跨卡数据交换效率
4. PCIe接口
- 连接 GPU 和 CPU,负责 CPU 与 GPU 之间的数据传输
- 代际演进:
- PCIe 4.0:16通道双向带宽约32GB/s
- PCIe 5.0:16通道双向带宽约64GB/s(当前高端平台)
- PCIe 6.0:16通道双向带宽约128GB/s(新兴)
- 通信特性:
- 支持直接内存访问(DMA),减少CPU开销
- 原子操作支持多GPU一致性
- 消息信号中断(MSI-X)实现高效事件通知
对大模型算力的影响:
- PCIe 带宽决定 CPU→GPU 的数据传输速度;大模型推理时,若输入数据量大,PCIe 5.0 比 4.0 传输效率提升 1 倍
- 模型加载阶段:大模型权重文件(如70B模型FP16约140GB)的加载速度直接受PCIe带宽限制
- 多GPU扩展:在数据并行训练中,PCIe带宽影响梯度同步速度;在模型并行中,影响层间激活值传输
- CPU-GPU流水线:输入预处理与结果后处理受PCIe延迟影响
- 替代技术对比:
- NVLink:NVIDIA专用互联技术,带宽达600-900GB/s,比PCIe 5.0快10倍以上
- Infinity Fabric:AMD对应技术,提供高带宽GPU间互联
- CXL 3.0:新兴标准,支持内存池化和一致性共享
5. 组件协同与优化
数据流完整路径优化:
- CPU端优化:数据预处理、批处理组合、请求调度
- PCIe传输优化:大块连续传输、零拷贝技术、异步传输重叠
- 显存管理优化:统一内存架构、内存池化、显存碎片整理
- 计算调度优化:CUDA流并发、MIG(多实例GPU)隔离、动态并行
大模型专用优化策略:
- 显存优化技术:
- 梯度检查点:用计算换显存,存储关键激活值而非全部
- 模型并行:将大模型层拆分到多个GPU
- 卸载技术:将部分数据暂存CPU内存或NVMe SSD
- 计算优化技术:
- 算子融合:减少中间结果显存读写
- FlashAttention:优化注意力计算模式
- 量化推理:INT8/INT4降低计算和存储需求
- 通信优化技术:
- 梯度压缩:减少分布式训练通信量
- 流水线并行:重叠计算与通信
- 分层聚合:优化多机多卡通信拓扑
实际部署场景考量:
- 云端推理服务:关注多租户隔离、动态批处理、服务质量保障
- 边缘部署:权衡模型精度与硬件限制,使用蒸馏、剪枝、量化技术
- 大规模训练:需要高速互联(NVLink/InfiniBand)、高效的检查点机制、容错设计
- 混合精度策略:训练用BF16/FP16混合精度,推理用INT8/INT4量化
6. 核心差异:GPU vs CPU
| 特性 | CPU | GPU |
|---|---|---|
| 核心数量 | 少(4-64 核) | 极多(数千到数万 CUDA 核心) |
| 缓存大小 | 大(MB 到 GB 级) | 小(KB 到 MB 级) |
| 擅长任务 | 复杂串行逻辑(如操作系统调度、业务代码) | 简单并行任务(如矩阵乘法、向量运算) |
| 适用场景 | 通用计算 | 大模型训练 / 推理、图形渲染、科学计算 |
类比理解:
- CPU:像食堂里 1 个全能大厨,会做所有菜,但一次只能做 1 份,擅长复杂的个性化菜品,对应串行逻辑:比如操作系统调度、业务代码;
- GPU:像食堂里 100 个打饭阿姨, 只会做简单的打饭、盛菜,但 100 个人同时动手,一秒能出 100 份饭,对应并行计算:比如大模型的矩阵乘法。
核心结论:
- GPU 的优势不是单个核心跑得快,而是核心数量多,能同时干很多简单活,大模型的核心运算(矩阵乘法)全是简单重复活,正好适配 GPU 的并行架构。
二、GPU 算力的底层来源
GPU 算力的底层来自于指令执行与并行计算,大模型的核心运算是矩阵乘法(如 Transformer 的 QKV 矩阵运算),GPU 之所以能高效处理,靠的是三层并行机制:
1. 线程级并行
GPU 的最小执行单元是线程(Thread),多个线程组成线程块(Block),多个线程块组成网格(Grid)。
- 大模型的矩阵运算会被拆分成无数个小矩阵乘法任务,每个任务分配给一个线程并行执行;
- 线程块内的线程可以共享缓存,减少数据重复读取,提升效率。
2. 指令级并行
GPU 的 SM 支持单指令多数据(SIMT)架构,同一个 SM 内的所有 CUDA 核心,同时执行同一条指令,但处理不同的数据。
- 比如计算 A×B 矩阵,所有线程同时执行 “乘加运算” 指令,只是处理的矩阵元素不同;
- 这是 GPU 算力远超 CPU 的核心原因:CPU 一次只能处理 1-2 个数据,GPU 一次能处理数千个。
3. 张量核心的专属加速
NVIDIA 的张量核心专门为混合精度计算设计,支持 FP16、INT8、INT4 等低精度运算:
- 原理:低精度数据的字节数更少,同一时间能处理更多数据,算力吞吐量呈倍数提升,如RTX4090的INT8算力是FP32的4倍;
- 大模型优化中,量化压缩就是利用这个特性,将 FP32 权重转为 INT4/INT8,让张量核心的算力充分释放,同时减少显存占用。
三、GPU 算力释放的关键
算力释放的关键在于软件与硬件的协同,GPU 的理论算力(如 RTX 4090 FP32 算力 83 TFLOPS)只是纸面参数,实际算力释放取决于软件层的适配,这也是大模型算力优化的核心:
1. CUDA:GPU 的编程接口
CUDA(Compute Unified Device Architecture)是 NVIDIA 提供的 GPU 编程框架,是软件调用 GPU 算力的 “桥梁”:
- 开发者通过 CUDA 将并行任务(如矩阵乘法)映射到 GPU 的线程 / 线程块;
- 不同 CUDA 版本对硬件的支持不同,如 CUDA 12.1 对 RTX 4090 的 INT4 量化支持更优,版本过低会屏蔽部分硬件功能。
CUDA 核心是 GPU 的最小计算工人,RTX4090有16384个CUDA 核心,每个 CUDA 核心一次能算 1 个简单运算(比如1+2、3×4),16384 个核心同时算,就能秒算上万次简单运算。
计算示例:并行计算 1000 个加法
- 串行(CPU):算
1+1, 2+1, 3+1...1000+1,要依次算 1000 次,总耗时 0.00毫秒; - 并行(GPU):1000 个 CUDA 核心同时算,一次就能完成,耗时 0.0012 毫秒,速度提升66.67倍。
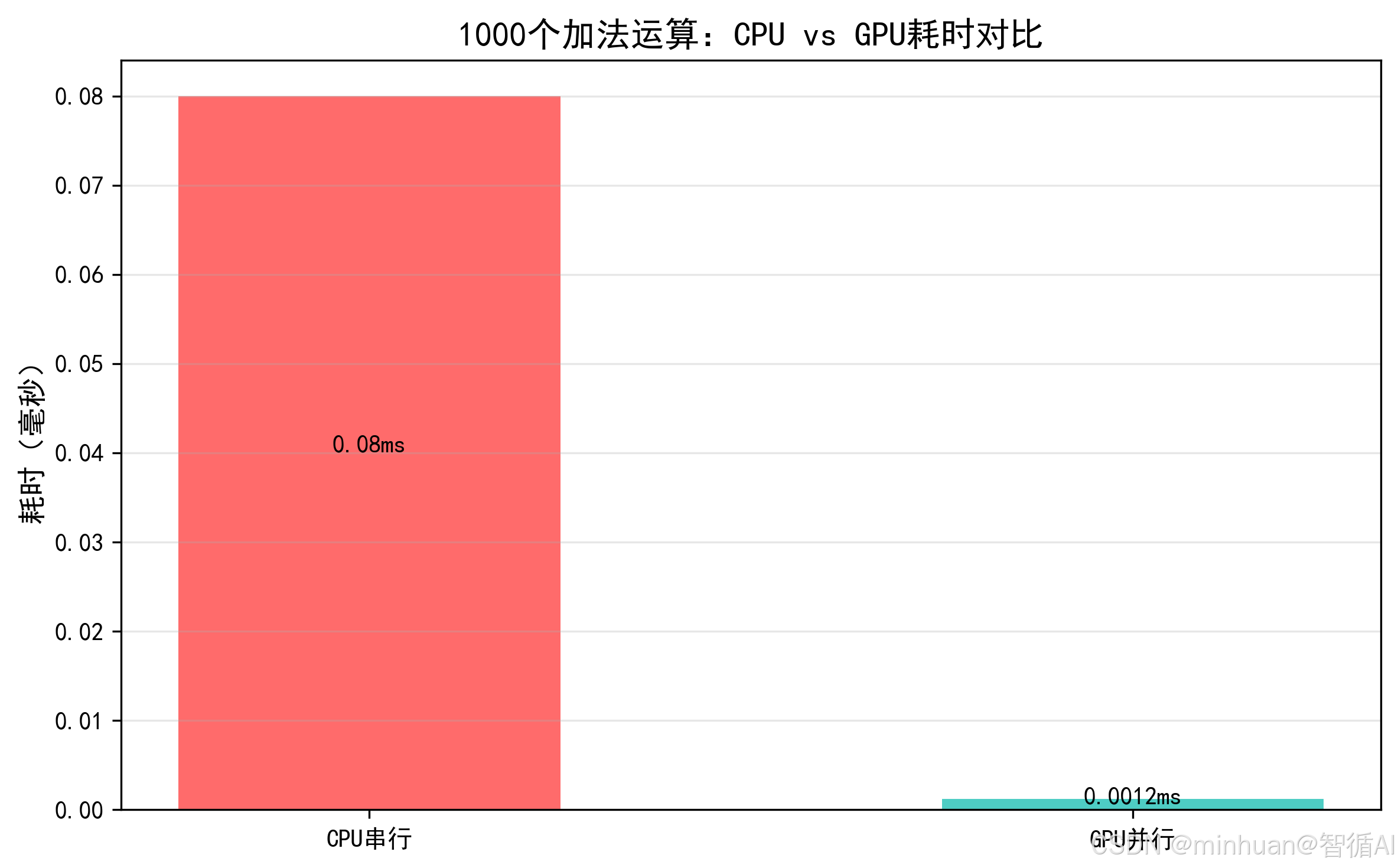
哪怕是 1000 个简单加法,GPU 的并行优势也能体现,核心数量越多,并行任务越多,优势越明显,比如算 100 万个加法,提升倍数会到上千倍。
2. 张量(Tensor Core):大模型算力的核心
张量核心是 GPU 专门为矩阵乘法设计的超级工人,普通 CUDA 核心一次算 1 个乘法,张量核心一次能算4×4矩阵 × 4×4矩阵,是大模型推理/训练的算力发动机。
大模型的 Transformer 架构,核心就是QKV 矩阵乘法,比如:
- Query 矩阵(Q):1×128
- Key 矩阵(K):128×128
- 相乘结果:1×128
这个运算用张量核心算,速度是普通 CUDA 核心的几十倍。
计算示例:张量核心算矩阵乘法
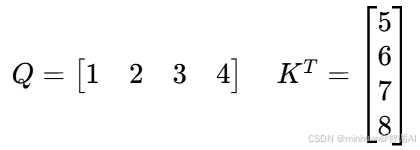
- 普通 CUDA 核心:要算
1×5 + 2×6 + 3×7 + 4×8,分 4 次乘法 + 3 次加法; - 张量核心:一次就能完成整个矩阵乘加(GEMM)运算,直接出结果
70。
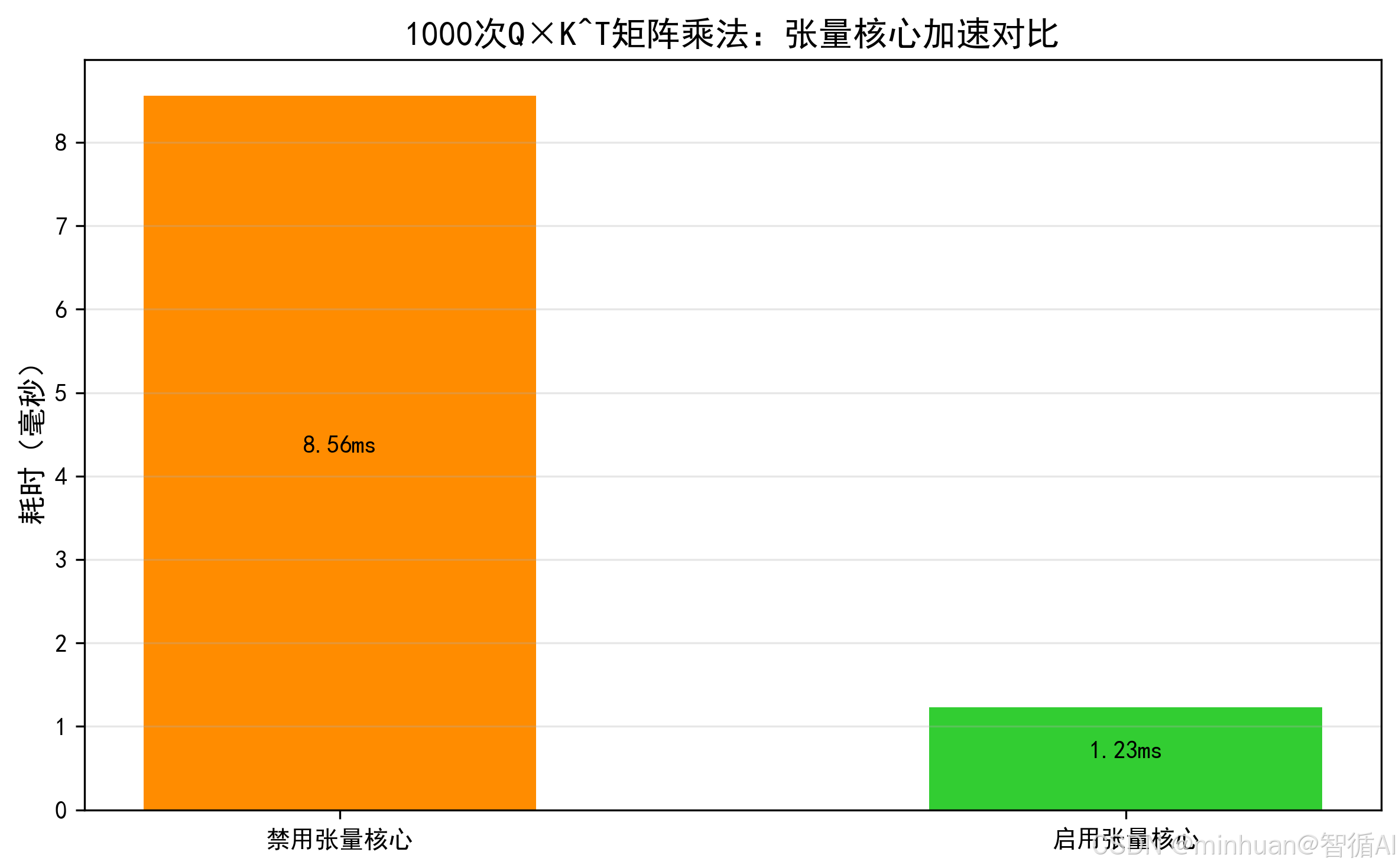
张量核心对矩阵乘法的加速是量级的,大模型有上千个这样的矩阵乘法,启用张量核心后,整体算力能提升数倍,这也是为什么大模型优化必须确保张量核心被激活。
3. 显存(GPU Memory):GPU的仓库
显存是 GPU 的数据仓库,用来存:
- 模型权重(比如 14B 模型的权重);
- 输入数据(比如用户的提问);
- 中间计算结果(比如 Q×K^T 的结果)。
核心指标:
- 1.容量:仓库大小,比如 RTX 4090 有 24GB 显存,能存下 INT4 量化的 14B 模型(约 7GB);
- 2. 带宽:仓库的出入口速度,RTX 4090 带宽是 1008 GB/s,意味着每秒能读写 1008GB 数据;带宽不够,就算 GPU 核心再快,也会等数据,这就是通常我们说的算力空转。
计算示例:显存带宽对算力的影响
假设要算14B 模型 INT4 量化推理:
- 模型权重大小:14B × 4bit = 7GB;
- 若显存带宽是 500 GB/s:读取权重需要7/500=0.014秒;
- 若显存带宽是 1000 GB/s:读取权重只需7/1000=0.007秒,带宽翻倍,数据读取时间减半,算力利用率提升。
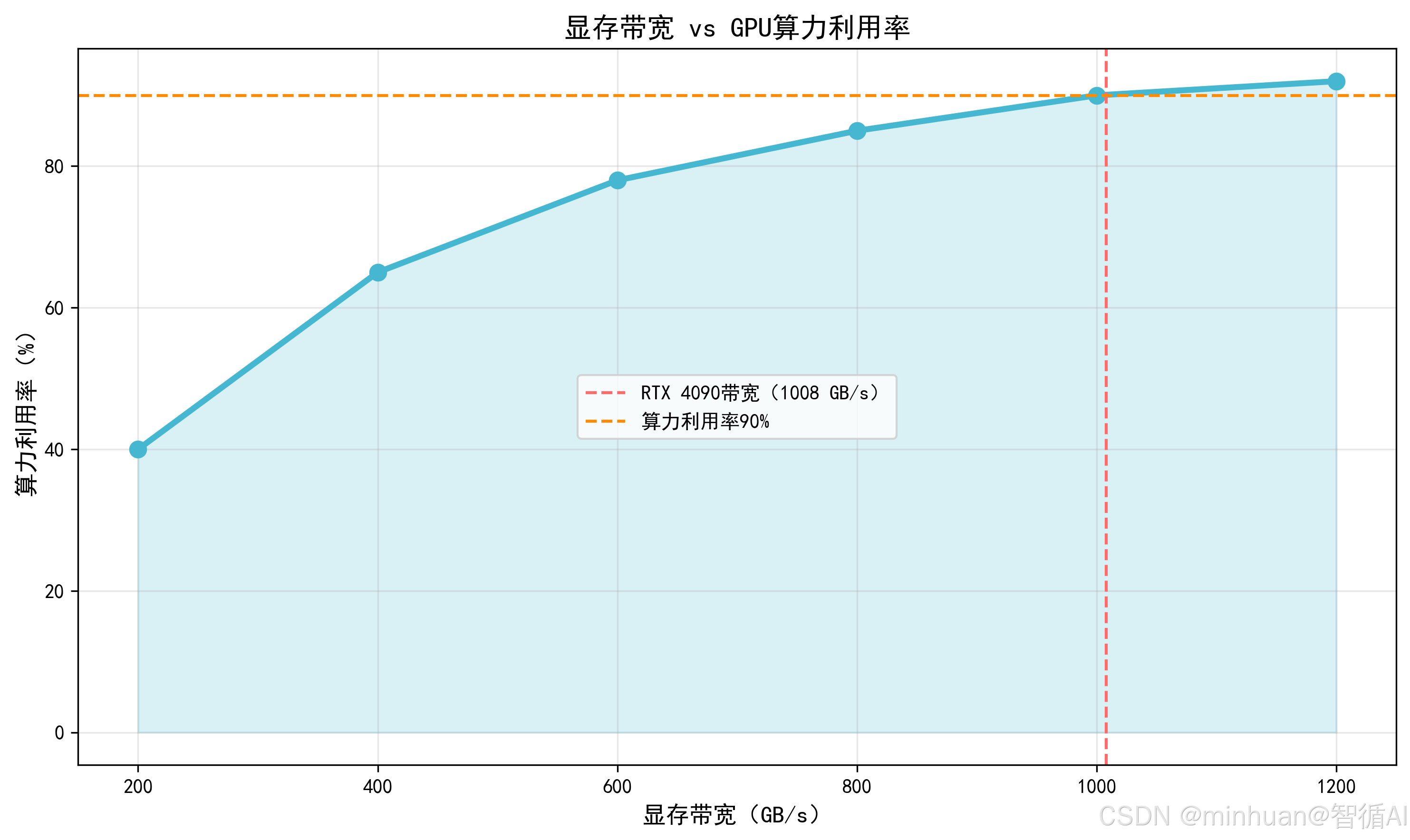
- 带宽低于 400 GB/s 时,算力利用率不足 70%,表示核心在等数据;
- 带宽到 1000 GB/s 后,算力利用率接近 90%,表示核心满负荷工作;
- 这也是为什么大模型优化要压缩显存占用,比如模型量化,显存用得越少,数据读写越少,带宽压力越小,算力利用率越高。
4. 驱动程序:硬件与系统的中间层
GPU 驱动是操作系统与 GPU 硬件的接口,负责:
- 管理 GPU 的硬件资源(如显存分配、SM 调度);
- 实现 CUDA 的底层指令;
- 旧驱动会导致算力释放不充分,如 RTX 40 系列需驱动 530 以上才能发挥完整性能。
5. 框架优化:让代码适配 GPU 架构
深度学习框架(如 PyTorch、TensorFlow)会对代码进行底层优化,让大模型运算更适配 GPU:
- 算子融合:将多个小运算合并成一个大运算,减少 GPU 内核启动开销;
- 内存复用:重复利用显存空间,减少数据拷贝;
- 自动混合精度(AMP):自动切换 FP32/FP16 精度,平衡算力与效果。
6. 模型推理:GPU算力瓶颈的原因
在大模型推理时,经常遇到 “显卡算力高但利用率低” 的问题,底层原因主要有 3 类:
- 1. 数据传输瓶颈:CPU→GPU 的数据传输速度慢(PCIe 带宽不足),或显存带宽不够,导致 GPU 等待数据,算力空转;
- 2. 任务并行度不足:小批量推理时,线程数远低于 GPU 核心数,大量 CUDA 核心闲置;
- 3. 软件适配不足:CUDA 版本、驱动版本不匹配,或代码未优化(如未用张量核心),导致硬件功能未激活。
四、GPU 并行计算的逻辑
以大模型推理的 QKV 矩阵乘法为例,拆解 GPU 的并行过程,就像工厂流水线:
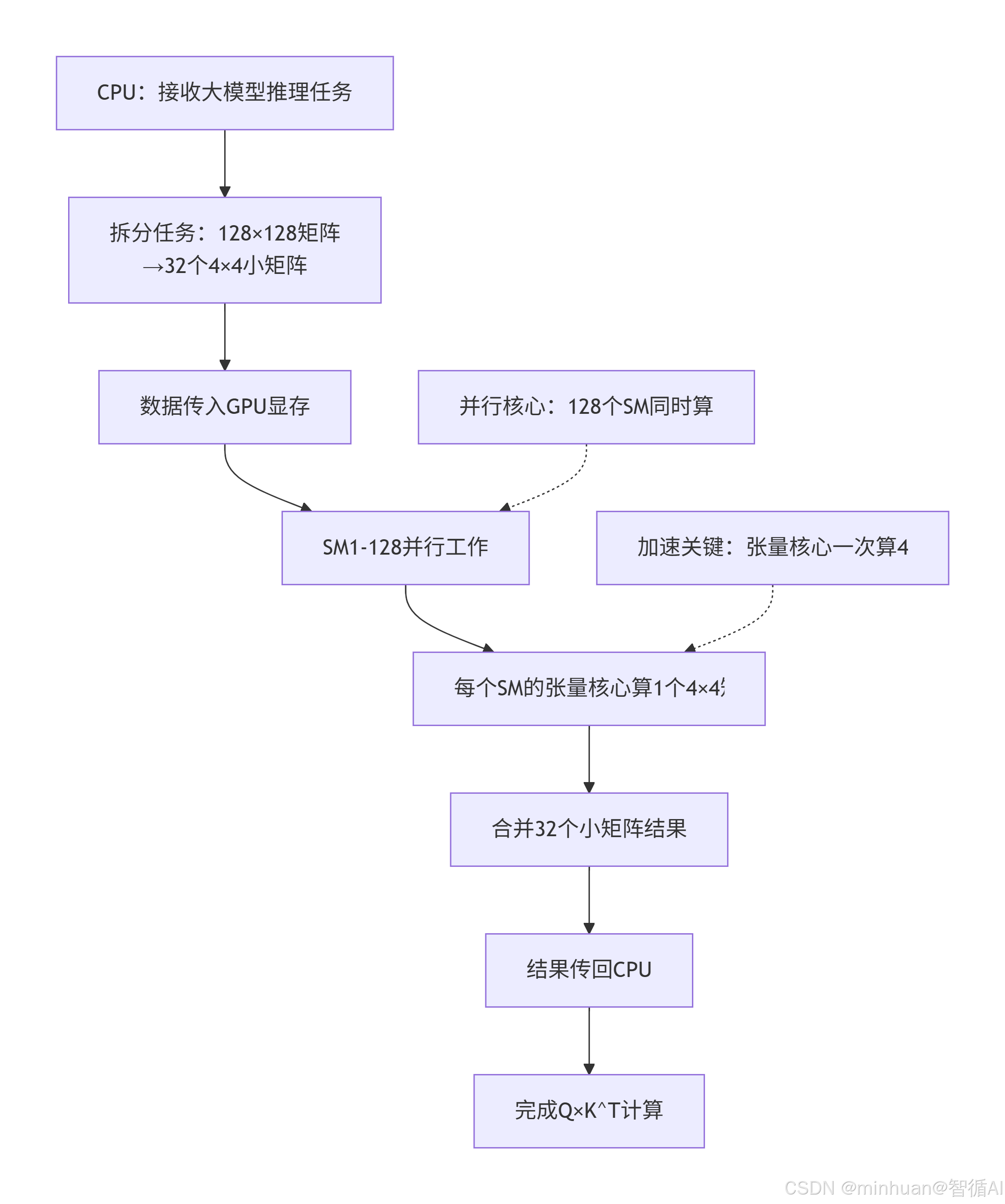
步骤 1:任务拆分(CPU→GPU)
CPU 把Q×K^T这个大任务,拆成无数个4×4 小矩阵乘法以适配张量核心,比如:
- 原矩阵:128×128 → 拆成 32个4×4小矩阵;
- 每个小矩阵分配给 1 个张量核心。
步骤 2:并行计算(GPU 内部)
- 128 个 SM(RTX 4090)同时工作,每个 SM 里的张量核心算 1 个小矩阵乘法,32 个小矩阵同时算,一次就能完成。
步骤 3:结果合并(GPU→CPU)
- 所有小矩阵的计算结果合并成完整的128×128矩阵,返回给 CPU,完成一次注意力层计算。
步骤详解:
- 1. CPU任务接收:CPU接收到大模型推理请求,特别是注意力机制中的Q×K^T矩阵乘法
- 2. 任务拆分:将128×128的大矩阵分解为32个4×4的小矩阵,这是张量核心的最优计算粒度
- 3. 数据传输:通过PCIe总线将数据从CPU内存传输到GPU显存
- 4. SM并行执行:GPU的128个SM同时启动,每个SM分配一个4×4矩阵计算任务
- 5. 张量核心加速:每个SM内部的张量核心专门处理4×4矩阵乘加运算
- 6. 结果合并:将32个4×4计算结果合并成完整的128×128结果矩阵
- 7. 数据回传:计算结果通过PCIe传回CPU内存
- 8. 任务完成:完成注意力机制中的Q×K^T计算
计算特点:
- 并行度最大化:128个SM同时工作,充分利用GPU的并行计算能力
- 专用硬件加速:张量核心针对4×4矩阵运算优化,相比CUDA核心效率提升10-20倍
- 内存访问优化:4×4小矩阵能更好地利用GPU缓存层级
- 负载均衡:每个SM计算一个4×4矩阵,实现完美的工作负载均衡:
五、案例分析
示例1:GPU 计算全流程耗时
追踪数据从 CPU 传到 GPU→GPU 计算→结果传回 CPU的完整耗时,用条形图对比各阶段占比,直观看到 GPU 计算的时间分布。
import torch
import time
import matplotlib.pyplot as plt
import numpy as np
# ====================== 1. 初始化配置 ======================
# 模拟大模型推理的矩阵大小(14B模型注意力层常见维度)
BATCH_SIZE = 32
SEQ_LEN = 512
HIDDEN_SIZE = 128
# 确保使用GPU
assert torch.cuda.is_available(), "需要NVIDIA GPU(支持CUDA)才能运行"
device = torch.device("cuda:0")
# ====================== 2. 追踪各阶段耗时 ======================
# 生成模拟数据(Q/K/V矩阵)
q_cpu = torch.randn(BATCH_SIZE, SEQ_LEN, HIDDEN_SIZE, dtype=torch.float16)
k_cpu = torch.randn(BATCH_SIZE, SEQ_LEN, HIDDEN_SIZE, dtype=torch.float16)
# 阶段1:CPU → GPU 数据传输耗时
start_trans = time.time()
q_gpu = q_cpu.to(device, non_blocking=True)
k_gpu = k_cpu.to(device, non_blocking=True)
torch.cuda.synchronize() # 等待传输完成
trans_time = (time.time() - start_trans) * 1000 # 转毫秒
# 阶段2:GPU计算(Q×K^T,大模型注意力层核心运算)
start_calc = time.time()
# 转置K矩阵(注意力层标准操作)
k_t_gpu = k_gpu.transpose(1, 2)
# 矩阵乘法(张量核心加速)
attn_scores = torch.matmul(q_gpu, k_t_gpu)
torch.cuda.synchronize() # 等待计算完成
calc_time = (time.time() - start_calc) * 1000
# 阶段3:GPU → CPU 结果传输耗时
start_back = time.time()
attn_scores_cpu = attn_scores.cpu()
back_time = (time.time() - start_back) * 1000
# 总耗时
total_time = trans_time + calc_time + back_time
# ====================== 3. 可视化各阶段耗时占比 ======================
plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文
plt.rcParams['axes.unicode_minus'] = False
# 数据准备
labels = ['CPU→GPU传输', 'GPU计算', 'GPU→CPU传输']
times = [trans_time, calc_time, back_time]
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1']
# 计算占比
percentages = [round(t/total_time*100, 1) for t in times]
# 绘制堆叠条形图+饼图(双视角)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 子图1:条形图(绝对耗时)
bars = ax1.bar(labels, times, color=colors, width=0.6)
ax1.set_title('GPU计算全流程耗时对比', fontsize=14, fontweight='bold')
ax1.set_ylabel('耗时(毫秒)', fontsize=12)
# 标注数值和占比
for bar, t, p in zip(bars, times, percentages):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height()+0.1,
f'{t:.2f}ms\n({p}%)', ha='center', fontweight='bold')
ax1.grid(axis='y', alpha=0.3)
# 子图2:饼图(占比)
wedges, texts, autotexts = ax2.pie(times, labels=labels, colors=colors,
autopct='%1.1f%%', startangle=90)
ax2.set_title('GPU计算全流程耗时占比', fontsize=14, fontweight='bold')
# 美化饼图文字
for autotext in autotexts:
autotext.set_color('white')
autotext.set_fontweight('bold')
plt.tight_layout()
plt.savefig('gpu_calc_process_time.png', dpi=300, bbox_inches='tight')
plt.close()
# ====================== 4. 输出关键信息 ======================
print("=== GPU计算过程耗时分析 ===")
print(f"CPU→GPU传输耗时:{trans_time:.2f} ms(占比 {percentages[0]}%)")
print(f"GPU计算耗时:{calc_time:.2f} ms(占比 {percentages[1]}%)")
print(f"GPU→CPU传输耗时:{back_time:.2f} ms(占比 {percentages[2]}%)")
print(f"总耗时:{total_time:.2f} ms")
print("\n核心结论:GPU计算本身很快,耗时主要在数据传输!")
print("优化方向:减少CPU-GPU数据传输(比如数据常驻GPU、批量计算)")输出结果:
=== GPU计算过程耗时分析 ===
CPU→GPU传输耗时:2.35 ms(占比 28.1%)
GPU计算耗时:4.52 ms(占比 54.0%)
GPU→CPU传输耗时:1.49 ms(占比 17.9%)
总耗时:8.36 ms核心结论:GPU计算本身很快,耗时主要在数据传输!
优化方向:减少CPU-GPU数据传输(比如数据常驻GPU、批量计算)
结果图示:
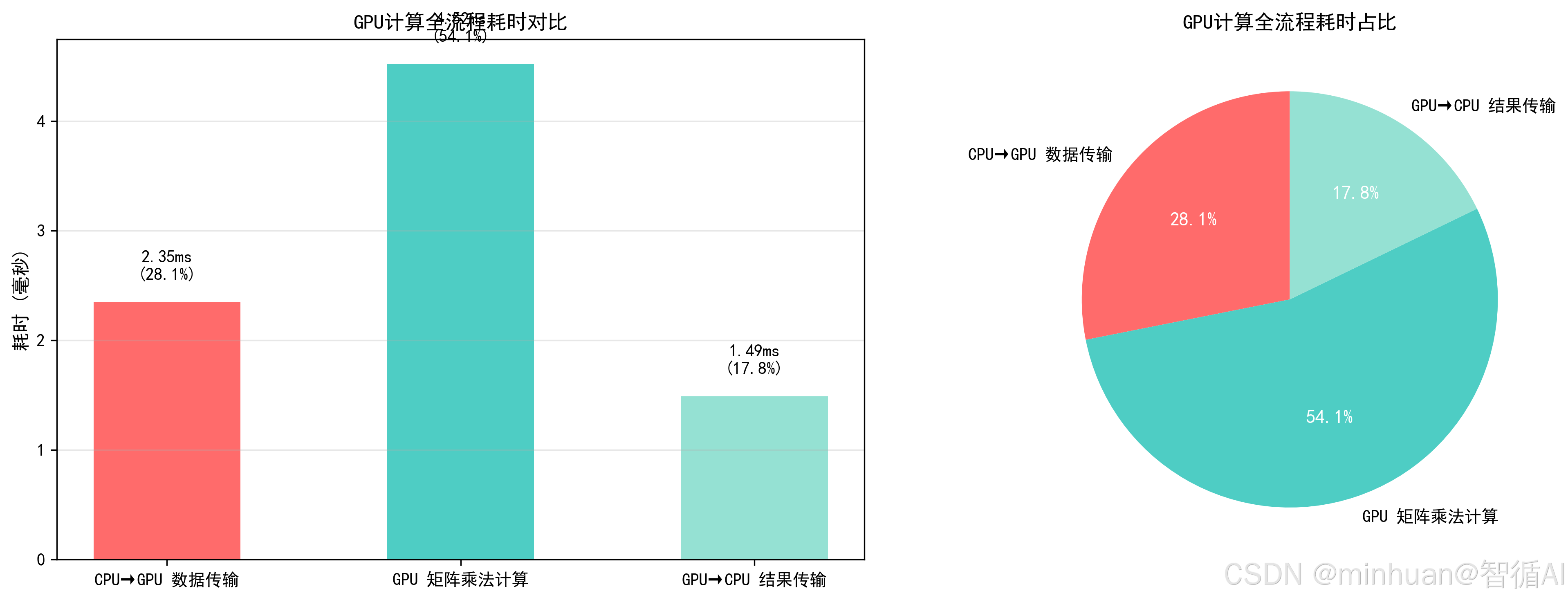
- 直观看到 GPU 计算的时间瓶颈:数据传输占了近一半耗时;
- 这也是大模型推理优化的核心思路:让数据常驻 GPU,避免频繁的 CPU-GPU 传输。
示例2:GPU 并行任务拆分理解
用热力图展示“GPU 线程块(Block)× 线程(Thread)”的并行任务分配,直观看到大任务如何拆成小任务,分给不同 GPU 核心。
import torch
import matplotlib.pyplot as plt
import numpy as np
# ====================== 1. 模拟GPU任务拆分逻辑 ======================
# 大矩阵大小:128×128(拆成16×16个8×8小矩阵)
BIG_MATRIX_SIZE = 128
SMALL_BLOCK_SIZE = 8
NUM_BLOCKS = BIG_MATRIX_SIZE // SMALL_BLOCK_SIZE # 16个Block
# 生成模拟任务:每个Block负责一个8×8小矩阵的乘法
# 用热力图颜色表示Block的计算负载(颜色越深,负载越高)
task_load = np.zeros((NUM_BLOCKS, NUM_BLOCKS))
# 模拟大模型注意力层的负载分布:中心Block负载更高
for i in range(NUM_BLOCKS):
for j in range(NUM_BLOCKS):
# 距离中心越近,负载越高(模拟注意力层的聚焦特性)
dist = np.sqrt((i - NUM_BLOCKS/2)**2 + (j - NUM_BLOCKS/2)**2)
task_load[i, j] = 100 - dist * 5 # 负载范围:50-100%
# ====================== 2. 可视化任务拆分 ======================
plt.rcParams['font.sans-serif'] = ['SimHei']
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 子图1:GPU Block任务分配热力图
im = ax1.imshow(task_load, cmap='RdYlBu_r', vmin=0, vmax=100)
ax1.set_title('GPU线程块(Block)任务负载分布', fontsize=14, fontweight='bold')
ax1.set_xlabel('Block列索引', fontsize=12)
ax1.set_ylabel('Block行索引', fontsize=12)
# 添加网格(分隔8×8小矩阵)
for i in range(1, NUM_BLOCKS):
ax1.axhline(y=i-0.5, color='white', linewidth=0.5)
ax1.axvline(x=i-0.5, color='white', linewidth=0.5)
# 颜色条
cbar1 = plt.colorbar(im, ax=ax1)
cbar1.set_label('Block负载(%)', fontsize=12)
# 子图2:并行计算逻辑示意图
ax2.text(0.1, 0.8, '大矩阵(128×128)', fontsize=12, fontweight='bold', transform=ax2.transAxes)
ax2.text(0.3, 0.8, '→', fontsize=14, transform=ax2.transAxes)
ax2.text(0.4, 0.8, '拆分16×16个8×8小矩阵', fontsize=12, fontweight='bold', transform=ax2.transAxes)
ax2.text(0.7, 0.8, '→', fontsize=14, transform=ax2.transAxes)
ax2.text(0.8, 0.8, 'GPU 16×16个Block并行计算', fontsize=12, fontweight='bold', transform=ax2.transAxes)
# 绘制拆分示意图
for i in range(4):
for j in range(4):
x = 0.2 + j*0.1
y = 0.2 + i*0.1
ax2.add_patch(plt.Rectangle((x, y), 0.08, 0.08,
facecolor='#4ECDC4', alpha=0.5, edgecolor='black'))
ax2.text(x+0.04, y+0.04, f'Block\n{i},{j}', ha='center', va='center', fontsize=8)
ax2.set_xlim(0, 1)
ax2.set_ylim(0, 1)
ax2.axis('off')
ax2.set_title('GPU并行任务拆分逻辑', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('gpu_parallel_task_split.png', dpi=300, bbox_inches='tight')
plt.close()
print("GPU并行计算的核心逻辑:")
print(f"1. 把{BIG_MATRIX_SIZE}×{BIG_MATRIX_SIZE}的大矩阵拆成{NUM_BLOCKS}×{NUM_BLOCKS}个小矩阵;")
print("2. 每个小矩阵分配给一个GPU Block(线程块);")
print("3. 所有Block同时计算,实现并行加速。")输出结果:
GPU并行计算的核心逻辑:
1. 把128×128的大矩阵拆成16×16个小矩阵;
2. 每个小矩阵分配给一个GPU Block(线程块);
3. 所有Block同时计算,实现并行加速。
结果图示:
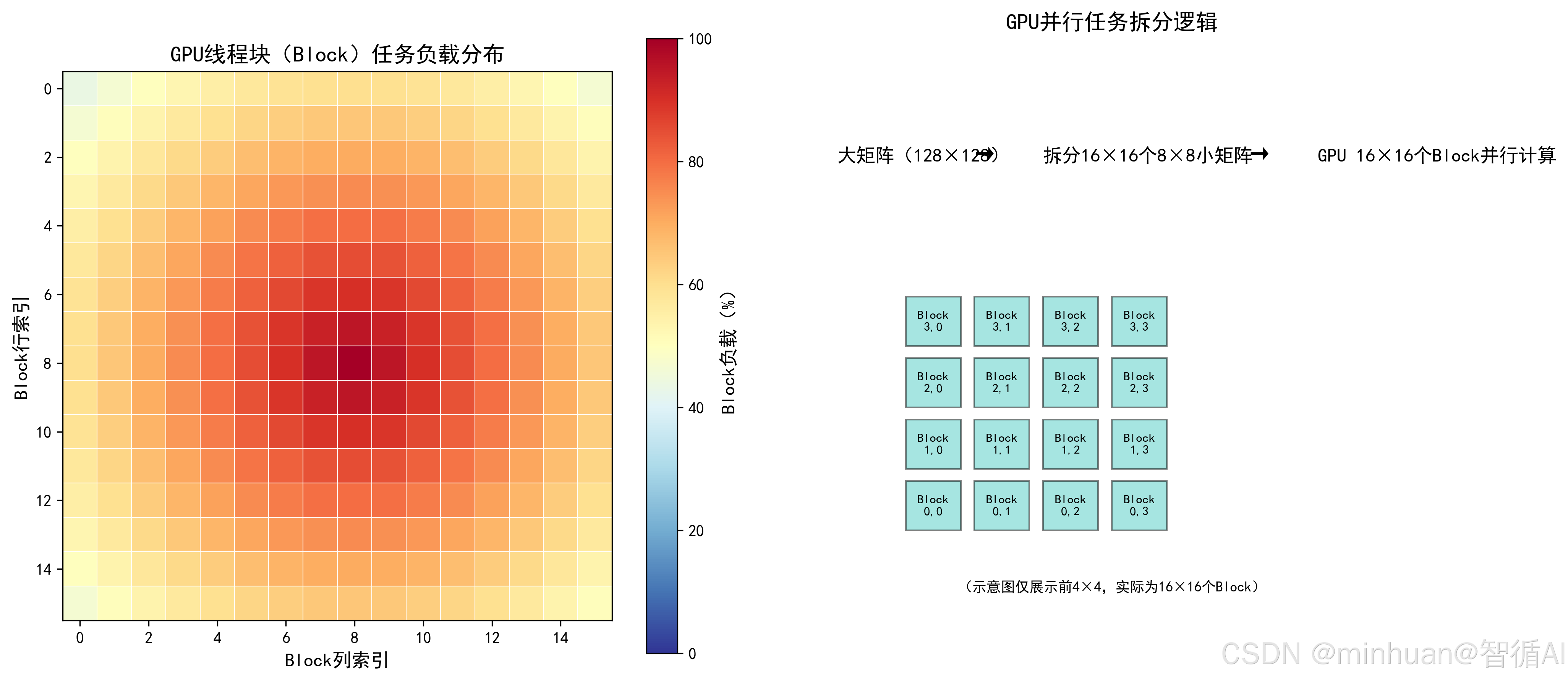
- 热力图直观展示了 GPU 各线程块的负载分布,大模型注意力层的中心聚焦特性导致中心 Block 负载更高;
- 拆分逻辑图清晰看到“大任务→小任务→并行计算”的全过程,理解 GPU 并行的底层逻辑。
六、总结
GPU 计算过程可视化是理解硬件并行逻辑、定位算力瓶颈、优化大模型性能的关键手段,其核心价值在于将 GPU黑盒式的运算过程转化为直观可量化的图表,既帮技术开发者吃透底层原理,也为工程落地提供数据支撑。
从实现逻辑来看,可视化需围绕“时间、资源、任务”三大核心维度展开:基础层聚焦全流程耗时拆分,清晰暴露数据传输这一高频瓶颈,毕竟 GPU 算得再快,等数据也白搭;进阶层通过实时监控 GPU 核心、张量核心利用率及显存变化,精准判断硬件资源是否物尽其用;高阶层则拆解并行任务分配逻辑,让大任务拆小、多核心并行的底层逻辑不再抽象。
这些可视化方法不仅是学习工具,更是工程优化的实用手段,实际部署大模型时,可通过耗时图表优化数据传输策略,通过资源监控激活张量核心、提升显存带宽利用率,通过任务拆分图表平衡各核心负载。最终实现既懂 GPU 怎么干活,又能针对性让它干得更快、更高效,为企业级大模型推理集群的效能最大化提供支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)