震惊!ChatGPT不是魔法而是科学!大模型小白必看:从预训练到后训练的完整指南,AI编程开发者的真香内幕!
本文解析大语言模型的两大核心阶段:预训练阶段让模型通过海量数据学习预测下一个词,掌握语言规律;后训练阶段通过监督微调、解决幻觉和强化学习,使模型从"学霸"转变为实用助手。同时提供四大实战技巧:触发内部思考、善用上下文学习、避开模型短板、按需选择合适模型,帮助开发者更高效地使用AI工具。
前言:前段深度学习了【安德烈·卡帕西:深入探索像ChatGPT这样的大语言模型】三个半小时的课程,受益匪浅(文末附课程链接)。希望通过每次学习后的分享,能让更多人了解大语言模型背后的底层原理,成为一个清醒、主动、高效的AI使用者。
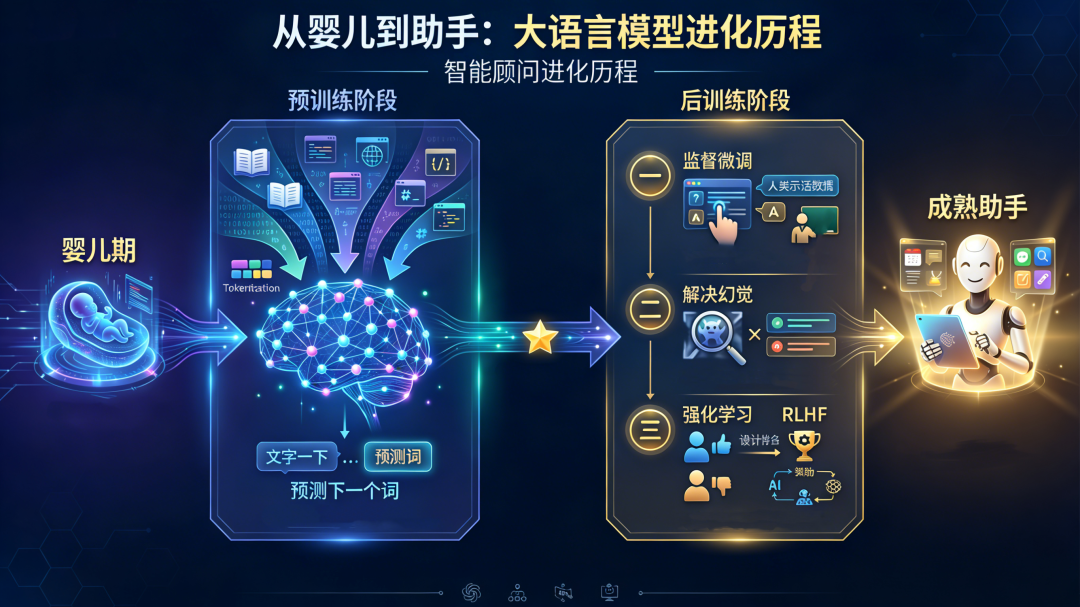
当你和ChatGPT对话时,偶尔会被它引经据典的深度分析惊艳到,下一秒又可能被它信誓旦旦的“胡言乱语”气笑。那它到底是个“通才学霸”还是个“随机忽悠大师”?背后的运行逻辑究竟是魔法还是科学?
今天,我们就掀开这层神秘面纱,带你走通大语言模型的“一生”——从诞生于海量数据的“婴儿”,到成为能与你侃侃而谈的“助手”。理解了这个流程,你将不再把它当作一个“黑箱”,而是能像老司机一样,预判它的反应,更高效地“驾驭”它。
本文将从两大核心阶段(预训练+后训练)展开,为你呈现一个由数据、算法和人类智慧共同编织的现代AI故事。
一、预训练:给AI塞下整个互联网的“填鸭式”教育
想象一下,要让一个婴儿学会人类的语言和知识,你会怎么做?最直接的办法,就是把他丢进一座由全世界所有书籍、网页、代码构成的巨型图书馆,让他没日没夜地读。
大模型的“预训练”阶段,干的就是这件事。 它的目标极其纯粹:让模型学会“预测下一个词”。
这个过程,并非让AI理解每个单词的含义,而是让它掌握语言中无比复杂的统计规律。工程师们会从互联网上抓取PB级别(1PB=1000TB)的文本数据,经过清洗、去重、过滤有害信息后,形成一个如 FineWeb 这样的优质数据集。
接下来是关键一步:分词(Tokenization)。模型“眼中”的世界,并非我们看到的“苹果”、“美丽”这些词,而是一个个被称为“词元(Token)”的数字编码。一个词可能被拆成多个词元(例如“ChatGPT”可能被拆成“Chat”、“G”、“PT”),标点符号、甚至空格也都是独立的词元。这种编码方式,是模型处理语言的基础砖块。
然后,巨大的神经网络(比如拥有1750亿参数的GPT-3)登场了。它像一张极其复杂的网,每次“吃”进一段文本(如前512个词元),它的唯一任务就是:预测下一个词元是什么。
-
输入:“今天天气真……”
-
模型计算后输出:概率最高的下一个词元可能是“好”,其次是“不错”、“糟糕”……
通过在海量文本上无数次进行“输入-预测-比对答案-调整网络参数”的循环,模型内部逐渐形成了对语言模式的深刻记忆。它学会了语法、事实关联(比如“巴黎是法国的首都”)、甚至一定的逻辑推理能力。这时诞生的,叫做 “基础模型(Base Model)”。
你可以把它看作一个接受了超量通识教育的“天文地理无所不知的学霸”,但它还远不是一个有用的“助手”。它可能会续写任何文本,包括不安全的、有偏见的内容,而且你问它问题,它很可能只会继续“续写”问题,而不是回答问题。
核心金句:预训练,本质上是让模型“熟读唐诗三百首”,但它还不会“作诗”,更不懂你要它作一首“关于离别的七言绝句”。
二、后训练:从“书呆子学霸”到“贴心助手”的塑形
一个满腹经纶但不懂社交的学霸,如何变成能帮你解决问题、语气得体的助手?这就需要 “后训练(Post-training)” ,也叫对齐(Alignment)。这是模型“社会化”的关键一步,通常分为三个循序渐进的环节。
第一步:监督微调——教它“说人话”
这是第一次明确的“教学”。研究人员会精心编写数以万计的“问答对”示例:
-
人类指令:“请用一句话解释光合作用。”
-
助理回答:“光合作用是植物利用阳光、水和二氧化碳制造氧气和葡萄糖的过程。”
让基础模型在这些优质对话数据上进行训练,教会它最基本的格式:看到人类指令,应该生成助理风格的回复。这一步后,模型初步学会了“对话”这个任务,变成了 “指令微调模型(Instruct-tuned Model)”。
第二步:解决“幻觉”——教它承认“我不知道”
模型“胡言乱语”(即产生“幻觉”)的根源在于:它在预训练时“看过”的文本中,错误、虚构、矛盾的信息本就大量存在。而它的设计目标是“让生成的文本看起来合理”,而非“说真话”。
要治这个病,目前有两个主流“药方”:
-
知识检索:当模型被问到特定事实时,不去依赖自己可能出错的内部记忆,而是先自动去外部的知识库(如维基百科、专业数据库)里搜索,然后基于查到的真实信息来组织答案。这相当于给它配了一个随时可查的“外部大脑”。
-
诚实性训练:在监督微调数据中,特意加入一些模型回答“我不知道”、“根据我的知识库,这个问题尚无定论”的示例。强化它“知之为知之,不知为不知”的习惯。
第三步:强化学习——让它“更讨人喜欢”
这是让ChatGPT脱颖而出的“点睛之笔”。光会正确回答问题还不够,我们还想让它的回答更有用、诚实、无害。
研究人员会准备大量问题,让模型生成多个不同的答案。然后,人类标注员或另一个AI模型,对这些答案进行排序(A比B好,B比C好)。这个“偏好排序”数据,被用来训练一个“奖励模型”,让它学会评判什么样的回答更符合人类喜好。
最后,让指令微调模型进入一个“自我进化”的游戏:它不断生成回答,奖励模型则像教练一样给它打分(更好的回答获得更高奖励)。通过基于人类反馈的强化学习(RLHF),模型被持续微调,最终其输出与人类偏好高度对齐。
至此,一个能对话、有帮助、且相对安全的AI助手,才真正诞生。
核心金句:后训练是一个“规训”与“引导”的过程,将一本“百科全书”打磨成一个“有问必答、措辞得体的智能顾问”。
三、实战宝典:如何像专家一样与AI对话?
理解了上述原理,你就能掌握与AI高效沟通的“心法”。这时提供给你四个立马能用的技巧:
- 技巧一:触发它的“内部思考”——用“逐步思考”
你问:“张三有5个苹果,吃了2个又买了3个,李四给了他4个,现在有几个?”模型可能直接答错。 但如果你说:“请逐步推理:张三有5个苹果,吃了2个又买了3个,李四给了他4个,现在有几个?”模型会更倾向于在“内心”先演算步骤,再给出最终答案,正确率飙升。这复现了【思维链(Chain-of-Thought)】提示的精髓。
- 技巧二:善用“上下文学习”——给它看例子
大模型有个神奇能力:在对话上下文中学习新任务。你无需解释什么是“提取情绪和主题”,只需先给它一两个示例: “例句:‘这电影太烂了,浪费时间。’ -> 情绪:负面;主题:电影评价” 然后你再给新的句子,它就能完美模仿。这比用文字描述任务规则要有效得多。
- 技巧三:避开它的“天生短板”——拼写、计数、精确信息
记住,模型的强项是语言的概率分布和模式生成,弱项是精确的字符操作和复杂计算。让它写首诗很棒,但让它倒着拼写单词或者统计长文中“的”字出现的次数,它很容易出错。对于这类任务,明确要求它“调用计算功能”或提醒它“仔细核对”会更有效。
- 技巧四:按需选择模型——创造 PK 实用
如果你需要天马行空的创意、写故事、头脑风暴,一个更“原始”的基础模型(或对其创意进行最小微调的版本)可能更有料,因为它受到的“规训”更少。如果你需要安全、可靠、格式规范的答案(如写邮件、总结、问答),那么经过严格对齐的指令模型(如ChatGPT)是你的最佳选择。
四、未来已来:AI领域的工具
大模型的世界日新月异。想保持前沿,你需要这张“资源地图”:
-
主流玩家:除了OpenAI的GPT系列,Google的Gemini,Meta开源的Llama系列,以及国内如深度求索(DeepSeek)等公司都在激烈竞逐。
-
模型竞技场:想直观对比哪个模型更强?可以关注 LMSys Chatbot Arena,那里有匿名、众投的模型排行榜。
-
本地运行:觉得联网服务有隐私顾虑?LM Studio这类工具让你能在自己的Mac或PC上,轻松下载和运行各种开源模型(如Llama),像使用一个本地软件一样与AI对话。
从预训练的“博览群书”,到后训练的“社会化规训”,大语言模型的成长路径,像极了人类专家的养成。理解它,不是为了成为技术专家,而是为了在这个AI无处不在的时代,成为一个清醒、主动、高效的使用者。下一次与ChatGPT对话时,你将知道,你面对的不仅是算法,更是一段凝结了人类数据、智慧与意图的复杂进化史。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献618条内容
已为社区贡献618条内容

所有评论(0)