PPO(Proximal Policy Optimization) 近端策略优化
本文深入解析近端策略优化(PPO)算法的核心原理与工程实现:从背景出发,对比策略梯度、TRPO 的局限性,阐明 PPO 通过带概率比截断的代理目标函数,在样本效率、实现复杂度与计算耗时间实现平衡;拆解 GAE 优势估计等关键模块,并给出 agent 代码架构。并以 Walker2d-v5 连续动作环境为例,提供基于 Stable Baselines3 的完整实现。
本文深入解析近端策略优化(PPO)算法的核心原理与工程实现:
从背景出发,对比策略梯度、TRPO 的局限性,阐明 PPO 通过带概率比截断的代理目标函数,
在样本效率、实现复杂度与计算耗时间实现平衡;
拆解 GAE 优势估计等关键模块,并给出 agent 代码架构。
并以 Walker2d-v5 连续动作环境为例,提供基于 Stable Baselines3 的完整实现。
目录
1. Background 策略优化 + TRPO + 自适应 KL
2. Clipped Surrogate Objective 带截断的代理目标函数
痛点:基础版策略梯度方法的数据效率与鲁棒性较差;
信任域策略优化(TRPO)则实现相对复杂,且无法与含噪声的网络架构(如丢弃法,dropout)或参数共享机制(策略与价值函数之间共享参数,或与辅助任务共享参数)兼容。
理想的强化学习:scalable,data efficient, and robust 可扩展性、数据高效性与鲁棒性
a novel objective with clipped probability ratios 通过使用带概率比截断的新型目标函数
PPO 在样本复杂度、实现简易性与计算耗时之间取得了良好的平衡。
此外 PPO 的适用场景更为通用(例如,可直接应用于策略与价值函数共享参数的联合网络架构)
1. Background 策略优化 + TRPO + 自适应 KL
先计算策略梯度的估计值(形式如下 g),再将其代入随机梯度上升算法中完成优化。
![]()
pytorch 这样可自动微分的,也可以写成 L 这样的目标函数。(L 的梯度 g 为策略梯度估计值)
![]()
尽管利用同一批轨迹数据对损失函数执行多轮优化的思路颇具吸引力,
但这种做法缺乏充分的理论依据,且在实验中往往会导致策略更新幅度过大,进而破坏原有策略性能。
硬约束的TRPO;代理目标函数 + 策略变化KL散度约束
共轭梯度算法求解(目标函数做线性近似,对约束条件做二次近似)
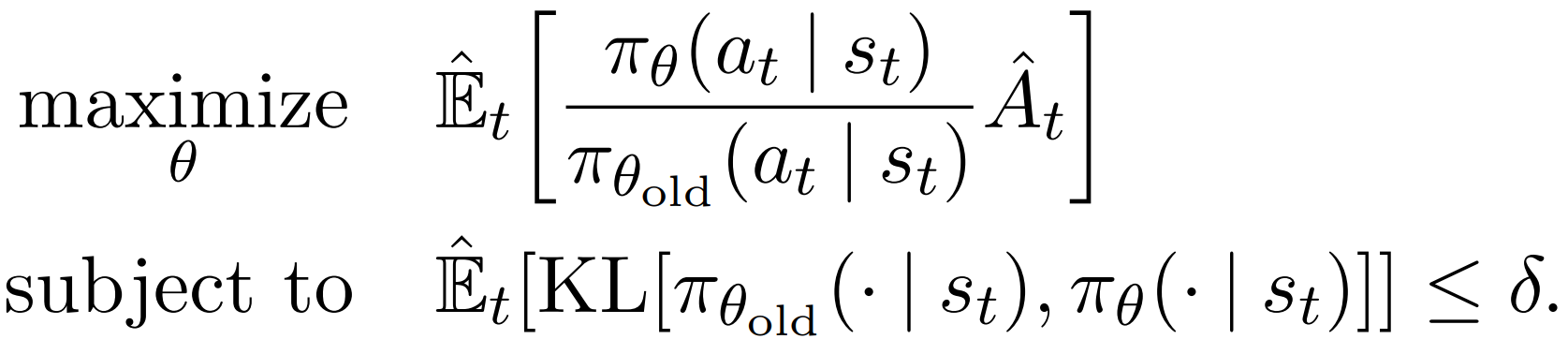
TRPO的理论实际上 更倾向于使用惩罚项而非约束条件,
但很难选取一个能在不同任务上都表现良好的固定惩罚系数。
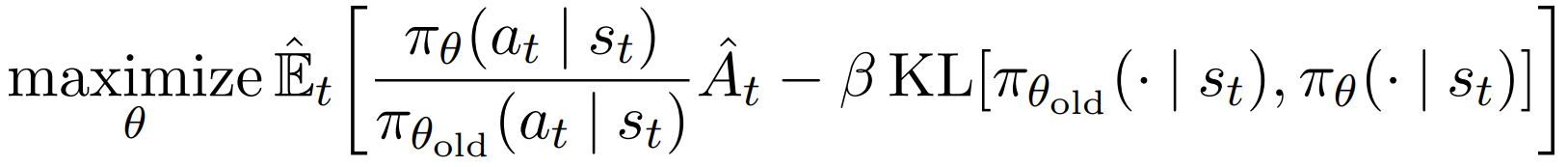
论文中提出的一个baseline:自适应KL惩罚系数
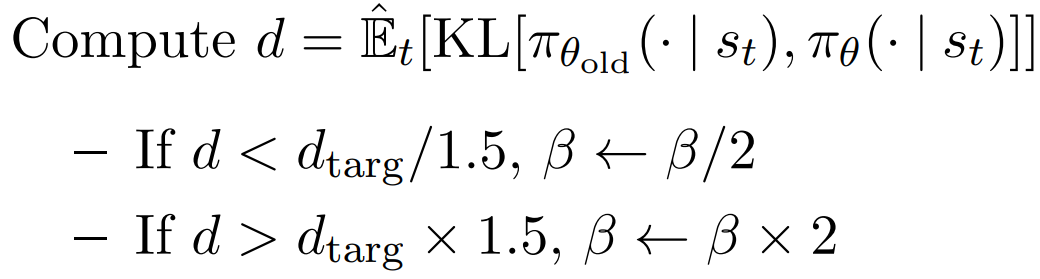
如果这次 KL 变化比较小,则下一次的惩罚系数减半 鼓励多变化;
如果这次 KL 变化比较大,则下一次的惩罚系数加倍 扼制变化过大;
但自适应KL惩罚 在实验中表现差于 clip,可能是因为:
-
调整 β 的过程引入了一定的滞后和不稳定性;
-
而 Clipped 方法通过直接的、非自适应的裁剪操作,能更稳定地控制更新幅度,实现更好的性能与样本效率。
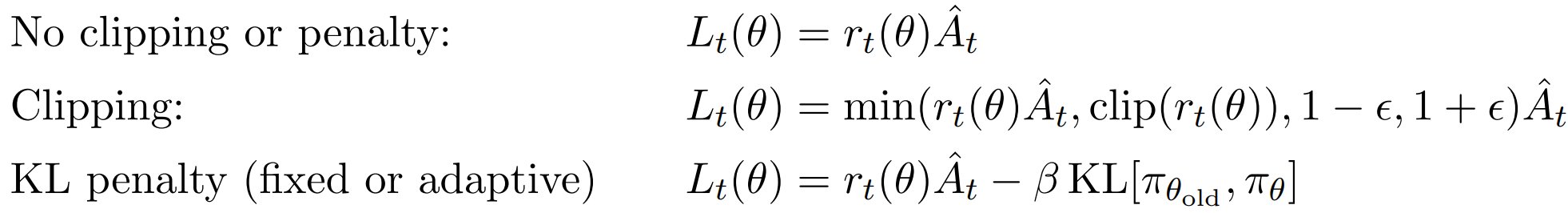
2. Clipped Surrogate Objective 带截断的代理目标函数
CPI 保守策略迭代的目标函数
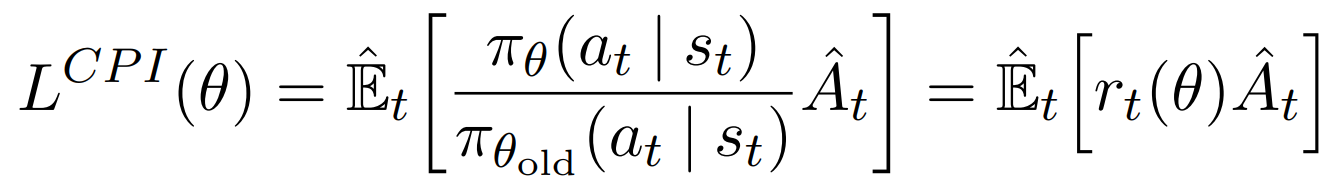
惩罚策略的改变(penalize changes to the policy that move rt(θ) away from 1)
CLIP 新目标函数:
![]()
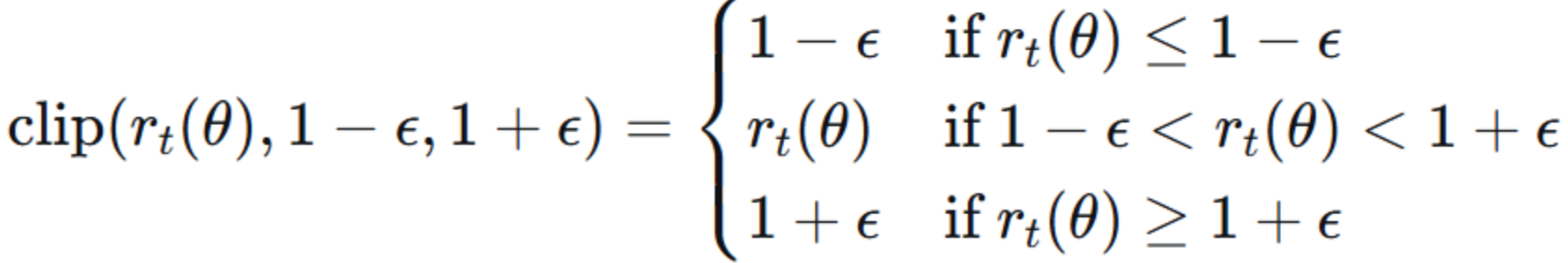

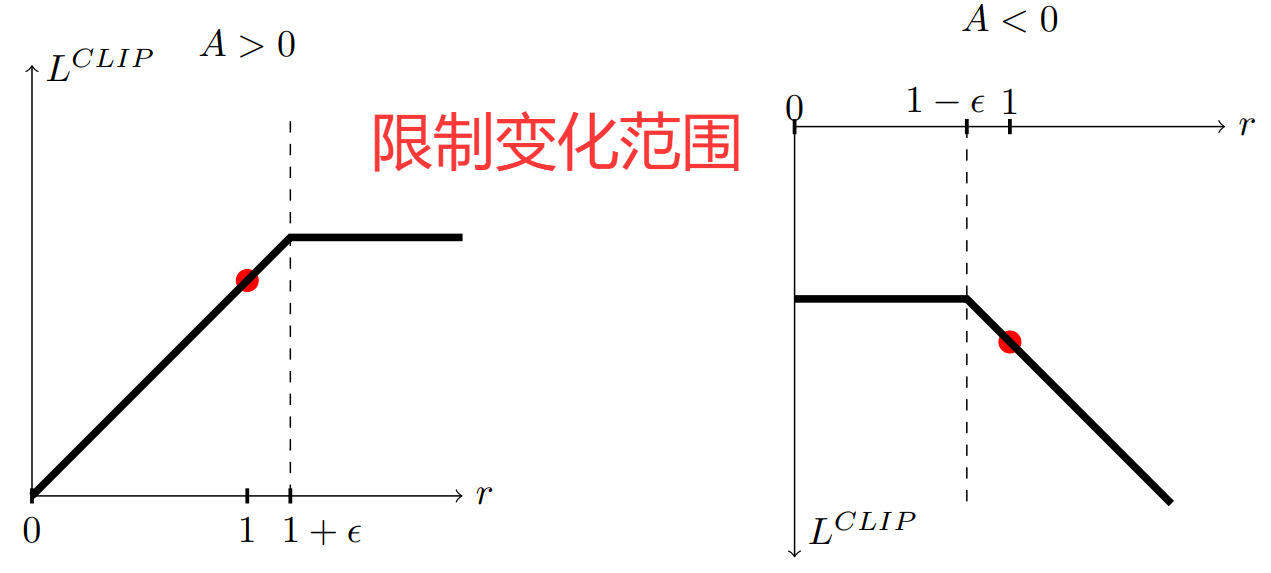
min 操作:在 clipped 目标与 unclipped 目标之间取最小,是为了形成悲观边界,
防止因策略变化过大而导致某些样本对更新产生破坏性影响。
3. 截断版 GAE
TD误差 ![]()
T步截断的 GAE(对TD 反向乘以系数求和)![]()
λ=0 时退化为纯TD方法,低方差但有偏;λ=1时 退化为蒙特卡洛方法,无偏但高方差。
λ 作为一个超参数通常取 0.9-0.99,论文实验中取 0.95。
def compute_advantage(gamma, lmbda, td_delta): # GAE
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
td_delta = td_target - self.critic(states)
advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)如果使用策略网络与价值网络共享参数的架构,
则必须用一个损失函数来结合策略替代项与价值函数误差项。

鼓励高熵策略 防止过早收敛到局部最优。
没有熵正则化: 一旦找到看似好的动作,会迅速将概率集中到该动作 可能错过更好的动作
有熵正则化:即使某个动作看起来好,也会保持一定概率尝试其他动作
4. PPO 实现
代码实现上 继承 TRPO,区别只有对 actor 网络的更新进行简化。
利用 clamp截断(无约束 无需共轭梯度)
也可看作Actor-Critic 的基础上,优化了 actor 的更新。
agent 初始化 + 动作概率选择:
class PPO:
''' PPO算法,采用截断方式 '''
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
lmbda, epochs, eps, gamma, device):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.lmbda = lmbda
self.epochs = epochs # 一条序列的数据用来训练轮数
self.eps = eps # PPO中截断范围的参数
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()先计算 td_target 和 优势函数;记录旧策略 (s,a) 概率 需要.detach() 从计算图分离
再多轮循环更新(critic 目标为 td_target ;actor 目标为截断代理目标函数)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to( self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
td_delta = td_target - self.critic(states)
advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)
old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()
for _ in range(self.epochs):
log_probs = torch.log(self.actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage # 截断
actor_loss = torch.mean(-torch.min(surr1, surr2)) # PPO损失函数
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
5. PPO Walker2d-v5
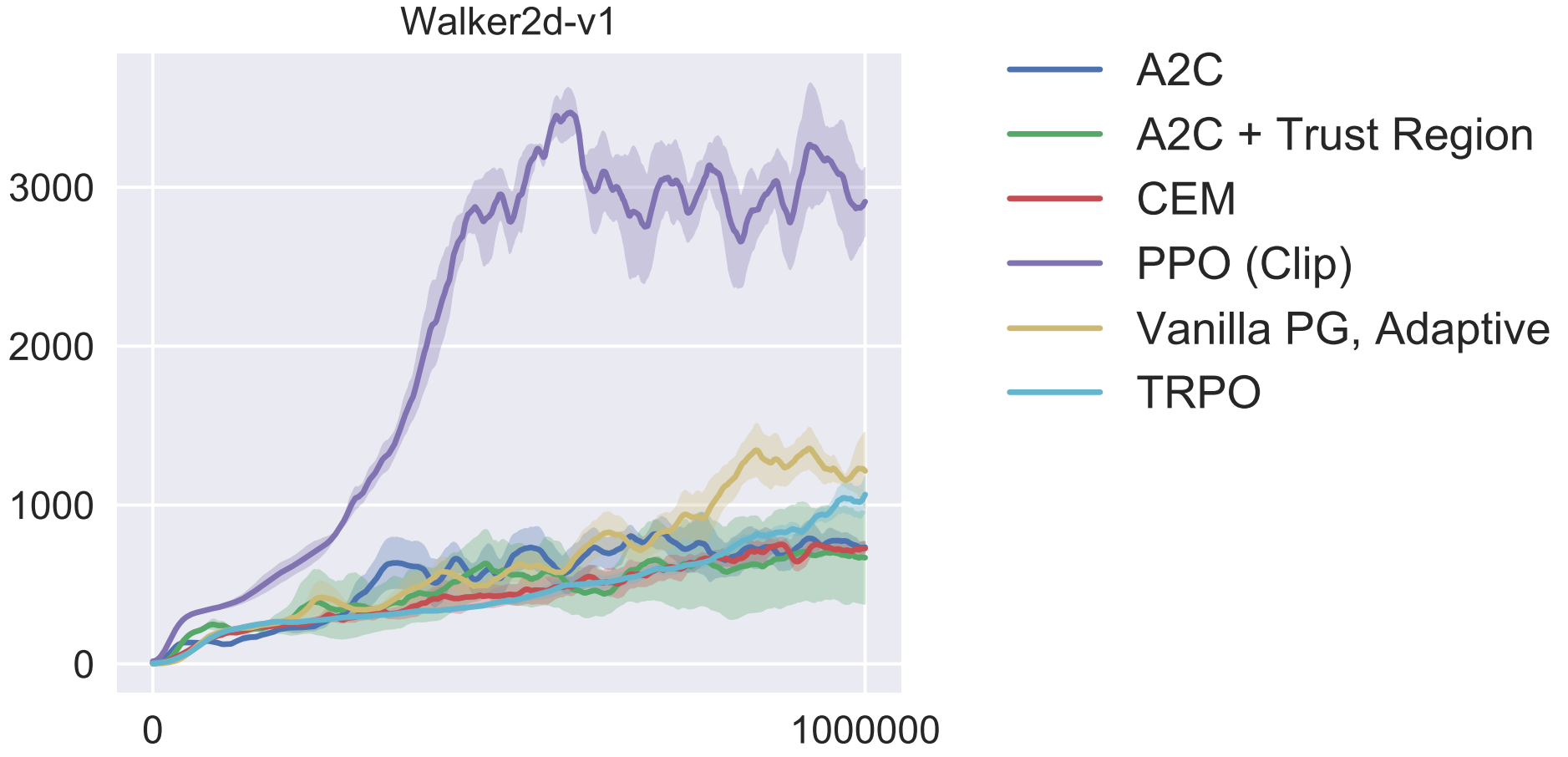
总共训练 50w 步,每 1w 步做10步 eval,保留分最高的参数。
OpenAI 的论文图(吊打其他)
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.evaluation import evaluate_policy
import numpy as np
class EvalAndSaveBestCallback(BaseCallback):
def __init__(self, eval_env, eval_freq=10000, n_eval_episodes=10, best_model_path="./best_walker2d_ppo.pth"):
super().__init__()
self.eval_env = eval_env # 评估用环境
self.eval_freq = eval_freq # 评估频率(每N步)
self.n_eval_episodes = n_eval_episodes # 每次评估的回合数
self.best_model_path = best_model_path # 最优模型保存路径
self.best_mean_reward = -np.inf # 初始化最优奖励为负无穷
def _on_step(self) -> bool:
# 每eval_freq步执行一次评估
if self.n_calls % self.eval_freq == 0:
# 评估模型:n_eval_episodes个回合,返回平均奖励和标准差
mean_reward, std_reward = evaluate_policy(
self.model,
self.eval_env,
n_eval_episodes=self.n_eval_episodes,
deterministic=True # 评估时用确定性策略
)
# 打印评估结果
print(f"\n===== 步数: {self.num_timesteps} =====")
print(f"当前平均奖励: {mean_reward:.2f} ± {std_reward:.2f}")
print(f"历史最优奖励: {self.best_mean_reward:.2f}")
# 如果当前奖励优于历史最优,保存模型
if mean_reward > self.best_mean_reward:
self.best_mean_reward = mean_reward
self.model.save(self.best_model_path)
print(f"✅ 保存最优模型到: {self.best_model_path} (奖励: {mean_reward:.2f})")
else:
print("❌ 未刷新最优奖励,不保存模型")
return True创建环境训练(带上上面的 callback)
env = gym.make(
"Walker2d-v5",
render_mode=None,
exclude_current_positions_from_observation=False
)
# 验证环境
print("状态空间维度:", env.observation_space.shape[0]) # 18
print("动作空间维度:", env.action_space.shape[0]) # 6
# PPO模型 超参数配置
model = PPO(
"MlpPolicy",
env,
learning_rate=3e-4,
n_steps=2048,
batch_size=64,
n_epochs=10,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
verbose=1
)
eval_callback = EvalAndSaveBestCallback(
eval_env=env,
eval_freq=10000,
n_eval_episodes=10,
best_model_path="./best_walker2d_ppo.pth"
)
model.learn(
total_timesteps=500000,
callback=eval_callback,
progress_bar=True # 显示训练进度条
)
env.close()训练完:test.py 导入保存的参数 按确定性策略测试
import gymnasium as gym
from stable_baselines3 import PPO
import numpy as np
BEST_MODEL_PATH = "./best_walker2d_ppo.pth" # 最优模型参数路径
N_TEST_EPISODES = 10 # 测试回合数
# 创建测试环境(启用可视化)
env = gym.make(
"Walker2d-v5",
exclude_current_positions_from_observation=False
)
model = PPO.load(BEST_MODEL_PATH)
test_rewards = []
for episode in range(N_TEST_EPISODES):
obs, info = env.reset()
episode_reward = 0.0
steps = 0
while True:
# 用确定性策略预测动作(测试时更稳定)
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
episode_reward += reward
steps += 1
if terminated or truncated:
break
test_rewards.append(episode_reward)
print(f" 回合 {episode + 1}/{N_TEST_EPISODES}:奖励 = {episode_reward:.2f},步数 = {steps}")
print("\n===== 测试结果统计 =====")
print(f"平均奖励:{np.mean(test_rewards):.2f} ± {np.std(test_rewards):.2f}")
print(f"最高奖励:{np.max(test_rewards):.2f}")
print(f"最低奖励:{np.min(test_rewards):.2f}")
# 关闭环境
env.close()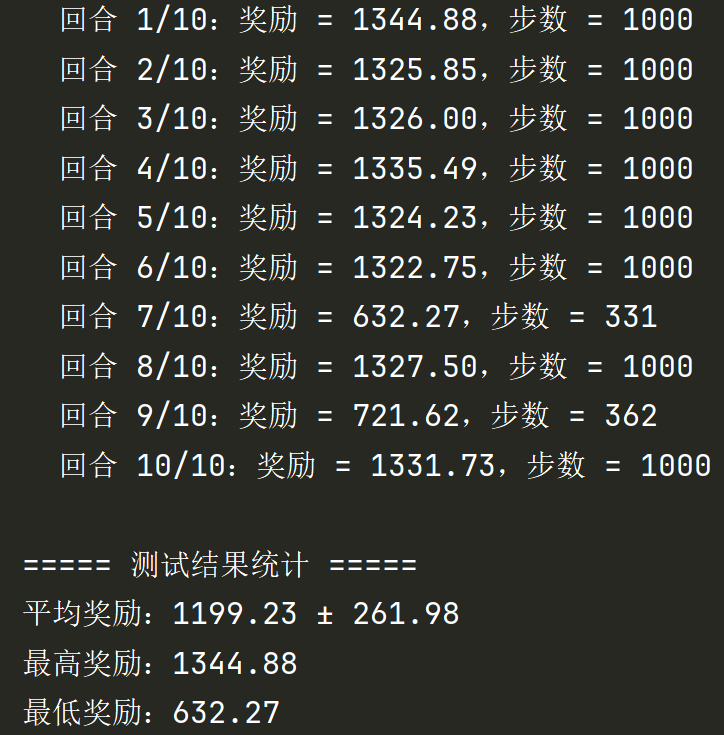

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)