基于SpringAI的在线考试系统-数据库设计核心业务方案(微调)
本文总结了修正后的数据流转链路,重点优化了阅卷质量管控模块的表结构设计。核心修正点在于将marking_quality_control表的外键关联从task_id改为marking_score_id,使其更准确地关联具体评分记录。全文包含完整的Mermaid流程图展示六个阶段的数据流转(从基础配置到结果沉淀),以及详细的外键关联表和修正后的质量管控表结构设计。该设计通过三重关联(评分记录、阅卷任务
·
更新后的核心数据流转链路总结(修正版)
应该是 marking_quality_control.marking_score_id → marking_score.id,这样更清晰准确。基于这个修正重新梳理核心数据流转链路。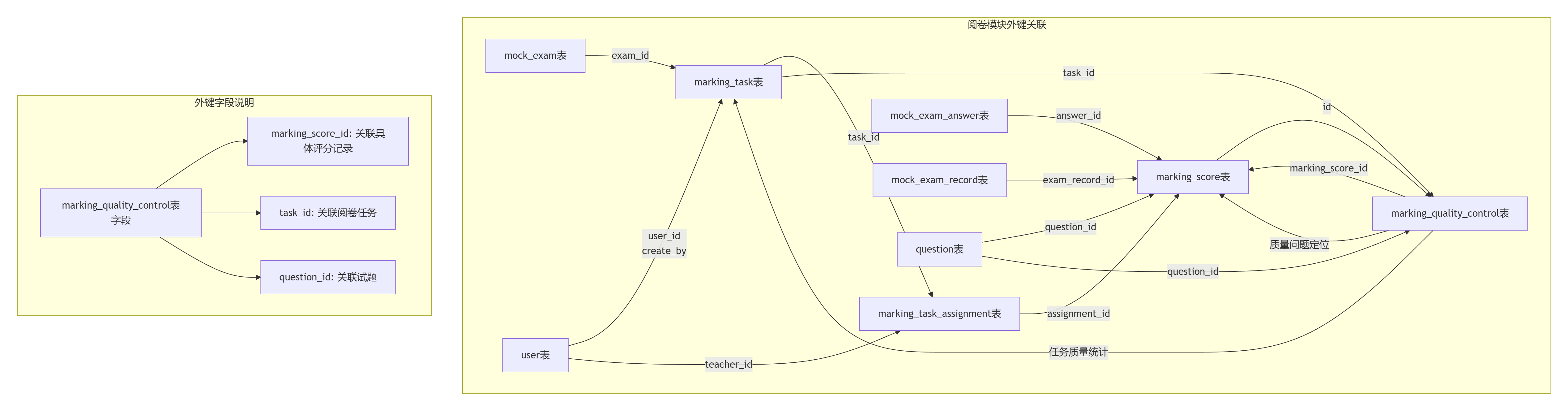
修正后的全流程数据流转图
修正后的阅卷表外键关系
关键外键修正说明
- 原设计:
marking_quality_control.task_id → marking_score.id - 修正后设计:
marking_quality_control.marking_score_id → marking_score.id
这样设计的好处:
- 语义更清晰:字段名明确表示关联到评分记录
- 避免混淆:与
marking_quality_control.task_id(关联阅卷任务)区分开 - 便于维护:代码和查询中更容易理解字段含义
修正后的阅卷表完整外键关联图
详细外键关联表
| 主表 | 主键 | 从表 | 外键字段 | 关联说明 |
|---|---|---|---|---|
mock_exam |
id |
marking_task |
exam_id |
阅卷任务关联考试 |
user |
id |
marking_task |
create_by |
阅卷任务创建人 |
marking_task |
id |
marking_task_assignment |
task_id |
任务分配关联阅卷任务 |
user |
id |
marking_task_assignment |
teacher_id |
任务分配关联阅卷教师 |
marking_task_assignment |
id |
marking_score |
assignment_id |
评分明细关联任务分配 |
mock_exam_answer |
id |
marking_score |
answer_id |
评分明细关联答题记录 |
mock_exam_record |
id |
marking_score |
exam_record_id |
评分明细关联考试记录 |
question |
id |
marking_score |
question_id |
评分明细关联试题 |
marking_score |
id |
marking_quality_control |
marking_score_id |
关键修正:质量管控关联具体评分记录 |
question |
id |
marking_quality_control |
question_id |
质量管控关联试题 |
marking_task |
id |
marking_quality_control |
task_id |
质量管控关联阅卷任务 |
修正后的质量管控表结构
marking_quality_control 表结构设计
CREATE TABLE marking_quality_control (
id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
-- 三重关联设计
marking_score_id BIGINT NOT NULL COMMENT '关联的评分记录ID',
task_id BIGINT NOT NULL COMMENT '关联的阅卷任务ID',
question_id BIGINT NOT NULL COMMENT '关联的试题ID',
-- 双评信息
first_teacher_id BIGINT COMMENT '第一位阅卷教师ID',
second_teacher_id BIGINT COMMENT '第二位阅卷教师ID',
first_score DECIMAL(5,2) COMMENT '第一位教师评分',
second_score DECIMAL(5,2) COMMENT '第二位教师评分',
score_diff DECIMAL(5,2) COMMENT '分差绝对值',
-- 仲裁信息
arbitration_teacher_id BIGINT COMMENT '仲裁教师ID',
arbitration_score DECIMAL(5,2) COMMENT '仲裁分数',
-- 状态控制
status TINYINT NOT NULL DEFAULT 0 COMMENT '状态:0-无需仲裁,1-待仲裁,2-已仲裁',
threshold DECIMAL(5,2) COMMENT '分差阈值',
-- 时间戳
created_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
arbitrated_time DATETIME COMMENT '仲裁时间',
-- 外键约束
FOREIGN KEY (marking_score_id) REFERENCES marking_score(id) ON DELETE CASCADE,
FOREIGN KEY (task_id) REFERENCES marking_task(id) ON DELETE CASCADE,
FOREIGN KEY (question_id) REFERENCES question(id) ON DELETE RESTRICT,
FOREIGN KEY (first_teacher_id) REFERENCES user(id) ON DELETE SET NULL,
FOREIGN KEY (second_teacher_id) REFERENCES user(id) ON DELETE SET NULL,
FOREIGN KEY (arbitration_teacher_id) REFERENCES user(id) ON DELETE SET NULL,
-- 索引优化
INDEX idx_marking_score_id (marking_score_id),
INDEX idx_task_id (task_id),
INDEX idx_question_id (question_id),
INDEX idx_status (status),
INDEX idx_created_time (created_time)
) COMMENT '质量管控表';
修正后的质量管控数据流转
优化后的核心流转链路
完整链路(修正后)
基础表(grade/classroom/subject/user)
→ 内容表(knowledge/question)
→ 试卷考试表(paper/paper_question/mock_exam)
→ 作答表(mock_exam_record/mock_exam_answer/exam_screen_record)
→ 阅卷表(marking_task → marking_task_assignment → marking_score → marking_quality_control)
→ 沉淀表(wrong_question_collection/wrong_question_item/operation_log)
精简链路(含双分配规则)
grade/class/subject/user
→ knowledge/question
→ paper/paper_question/mock_exam
→ mock_exam_record/mock_exam_answer
→ marking_task
→ 【基于题型/基于考生】marking_task_assignment
→ marking_score
→ marking_quality_control(marking_score_id→marking_score.id修正)
→ wrong_question_collection/wrong_question_item
修正后的质量管控查询示例
1. 直接定位具体问题的评分记录(修正后)
-- 查询有质量问题的评分记录详情
SELECT
mq.*,
ms.actual_score,
ms.marking_comment,
q.stem,
u.username as teacher_name
FROM marking_quality_control mq
JOIN marking_score ms ON mq.marking_score_id = ms.id -- 修正后的关联
JOIN question q ON mq.question_id = q.id
JOIN marking_task_assignment mta ON ms.assignment_id = mta.id
JOIN user u ON mta.teacher_id = u.id
WHERE mq.status = 1 -- 待仲裁
ORDER BY mq.score_diff DESC;
2. 向上统计阅卷任务整体质量(修正后)
-- 统计阅卷任务的整体质量情况
SELECT
mt.task_name,
COUNT(DISTINCT mta.id) as assignment_count,
COUNT(DISTINCT ms.id) as score_count,
SUM(CASE WHEN mq.status = 1 THEN 1 ELSE 0 END) as pending_arbitration,
SUM(CASE WHEN mq.status = 2 THEN 1 ELSE 0 END) as arbitrated,
AVG(mq.score_diff) as avg_score_diff
FROM marking_task mt
JOIN marking_task_assignment mta ON mt.id = mta.task_id
JOIN marking_score ms ON mta.id = ms.assignment_id
LEFT JOIN marking_quality_control mq ON ms.id = mq.marking_score_id -- 修正后的关联
GROUP BY mt.id
ORDER BY pending_arbitration DESC;
双分配规则下的质量管控查询
基于题型分配的质量统计(修正后)
-- 基于题型分配的质量统计
SELECT
mta.question_type,
COUNT(*) as total_scores,
SUM(CASE WHEN mq.id IS NOT NULL THEN 1 ELSE 0 END) as quality_issues,
AVG(CASE WHEN mq.score_diff IS NOT NULL THEN mq.score_diff ELSE 0 END) as avg_diff
FROM marking_task_assignment mta
JOIN marking_score ms ON mta.id = ms.assignment_id
LEFT JOIN marking_quality_control mq ON ms.id = mq.marking_score_id -- 修正后的关联
WHERE mta.assign_rule = 1 -- 基于题型分配
GROUP BY mta.question_type
ORDER BY quality_issues DESC;
基于考生分配的质量统计(修正后)
-- 基于考生分配的质量统计
SELECT
mer.user_id,
u.username as student_name,
COUNT(DISTINCT ms.id) as scored_questions,
SUM(CASE WHEN mq.status = 1 THEN 1 ELSE 0 END) as pending_arbitration,
SUM(CASE WHEN mq.status = 2 THEN 1 ELSE 0 END) as arbitrated
FROM mock_exam_record mer
JOIN marking_score ms ON mer.id = ms.exam_record_id
LEFT JOIN marking_quality_control mq ON ms.id = mq.marking_score_id -- 修正后的关联
JOIN user u ON mer.user_id = u.id
WHERE EXISTS (
SELECT 1 FROM marking_task_assignment mta
WHERE mta.id = ms.assignment_id
AND mta.assign_rule = 2 -- 基于考生分配
)
GROUP BY mer.user_id
ORDER BY pending_arbitration DESC;
业务优势总结
1. 精准定位与统计
marking_score_id:精准定位到具体的评分记录,便于快速处理质量问题task_id:向上统计整个阅卷任务的质量情况question_id:关联试题,便于分析特定题目的评分质量
2. 数据一致性保障
- 仲裁结果通过
marking_score_id直接同步到对应的评分记录 - 外键约束确保关联数据的完整性
- 乐观锁机制防止并发冲突
3. 灵活的查询支持
- 支持从评分记录到质量管控的直接查询
- 支持从阅卷任务到质量问题的聚合查询
- 支持按题型、按考生的多维度质量分析
4. 双规则分配适配
- 基于题型分配:便于统计同一题型的评分一致性
- 基于考生分配:便于分析特定考生的评分问题
- 两种分配规则下的质量管控都能有效支持
总结
通过修正 marking_quality_control.marking_score_id → marking_score.id 的外键关联,我们实现了:
- 语义清晰:字段名准确表达关联关系,避免混淆
- 精准定位:直接关联到具体评分记录,便于问题定位
- 统计灵活:通过三重关联(评分记录、阅卷任务、试题)支持多维度统计分析
- 业务适配:完美支持双分配规则下的质量管控需求
这样的设计既满足了教育考试系统阅卷模块的实际业务需求,又确保了数据模型的一致性和可维护性,为系统的长期稳定运行奠定了坚实基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)