2. Ollama REST API - api/generate 接口详
摘要:本文介绍了Ollama服务的REST API端点及其使用方法,重点解析了/api/generate接口的参数配置和响应处理。文章详细说明了model、prompt等必需参数及format、stream等可选参数的设置方法,并提供了Python代码示例演示如何通过requests库调用API。同时探讨了num_ctx/num_predict参数对上下文长度和输出token数量的控制、流式输出功
Ollama 服务启动后会提供一系列原生 REST API 端点。通过这些Endpoints可以在代码环境下与ollama启动的大模型进行交互、管理模型和获取相关信息。其中两个endpoint 是最重要的,分别是:
- POST /api/generate
- POST /api/chat
其他端点情况:
- POST /api/create
- POST /api/tags
- POST /api/show
- POST /api/copy
- DELETE /api/delete
- POST /api/pull
- POST /api/push
- POST /api/embed
- GET /api/ps
1. /api/generate 接口参数概览
常规参数
|
参数名 |
类型 |
描述 |
|
model |
(必需) |
模型名称,必须遵循 |
|
prompt |
(必需) |
用于生成响应的提示。 |
|
suffix |
(可选) |
模型响应后的文本。 |
|
images |
(可选) |
base64 编码图像的列表(适用于多模态模型,如 llava)。 |
高级参数 (可选)
|
参数名 |
类型 |
描述 |
|
format |
(可选) |
返回响应的格式。格式可以是 |
|
options |
(可选) |
文档中列出的其他模型参数,例如 |
|
system |
(可选) |
系统消息,用于覆盖 Modelfile 中定义的内容。 |
|
template |
(可选) |
要使用的提示模板,覆盖 Modelfile 中定义的内容。 |
|
stream |
(可选) |
如果为 |
|
raw |
(可选) |
如果为 |
|
keep_alive |
(可选) |
控制模型在请求后保持加载的时间(默认:5分钟)。 |
|
context |
(可选) |
(已弃用) 从先前请求返回的上下文参数,用于保持简短的对话记忆。 |
对于endpoints来说,如果使用代码调用,常规的调用方式是通requests库进行调用。如下所示:
import requests # type: ignore
import json
# 设置 API 端点
generate_url = "http://192.168.110.131:11434/api/generate" # 这里需要根据实际情况进行修改
# 示例数据
generate_payload = {
"model": "deepseek-r1:7b", # 这里需要根据实际情况进行修改
"prompt": "请生成一个关于人工智能的简短介绍。", # 这里需要根据实际情况进行修改
"stream": False, # 默认使用的是True,如果设置为False,则返回的是一个完整的响应,而不是一个流式响应
}
# 调用生成接口
response_generate = requests.post(generate_url, json=generate_payload)
if response_generate.status_code == 200:
generate_response = response_generate.json()
print("生成响应:", json.dumps(generate_response, ensure_ascii=False, indent=2))
else:
print("生成请求失败:", response_generate.status_code, response_generate.text)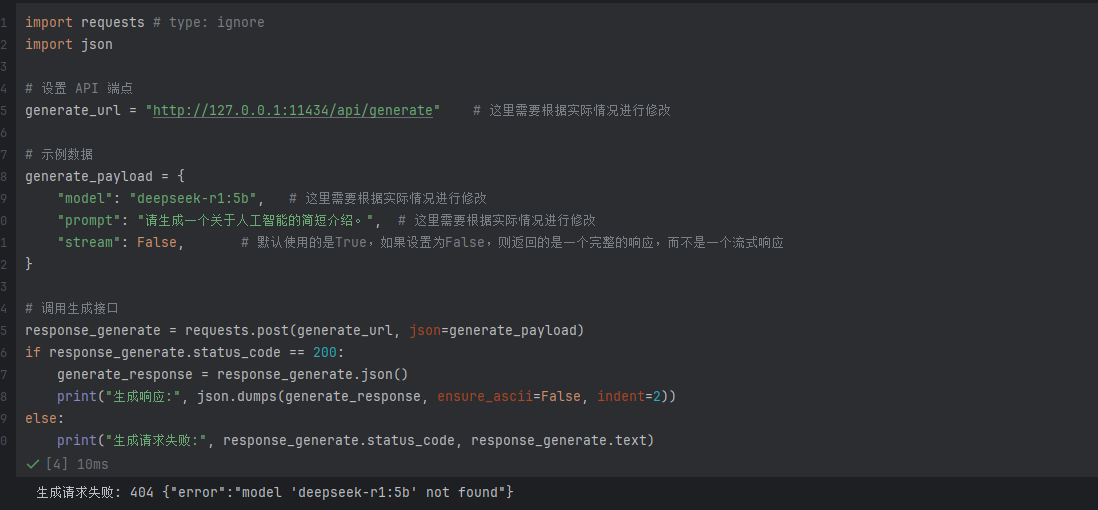
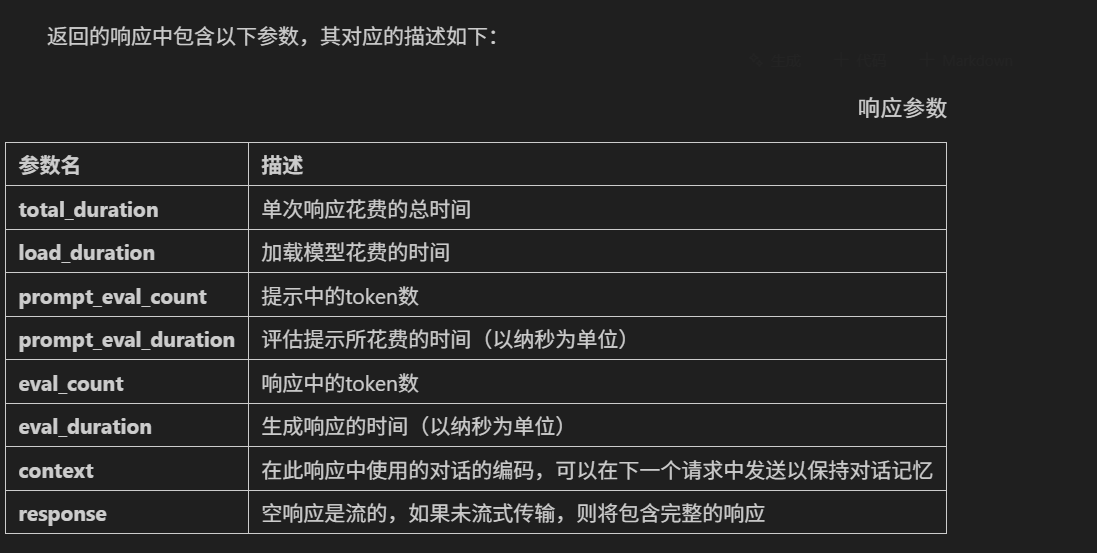
2. response 参数格式化解析
response 字段指的是模型生成的实际输出内容。对于 DeepSeek-R1 模型来说,response 字段中包含<think> 标签和正常文本,<think> 标签用于表示模型的思考过程或内部推理,而正常的文本则是模型生成的实际输出内容。注意:非推理类模型的返回结果中没有<think></think>标识。
3.num_ctx / num_predict 输入输出控制
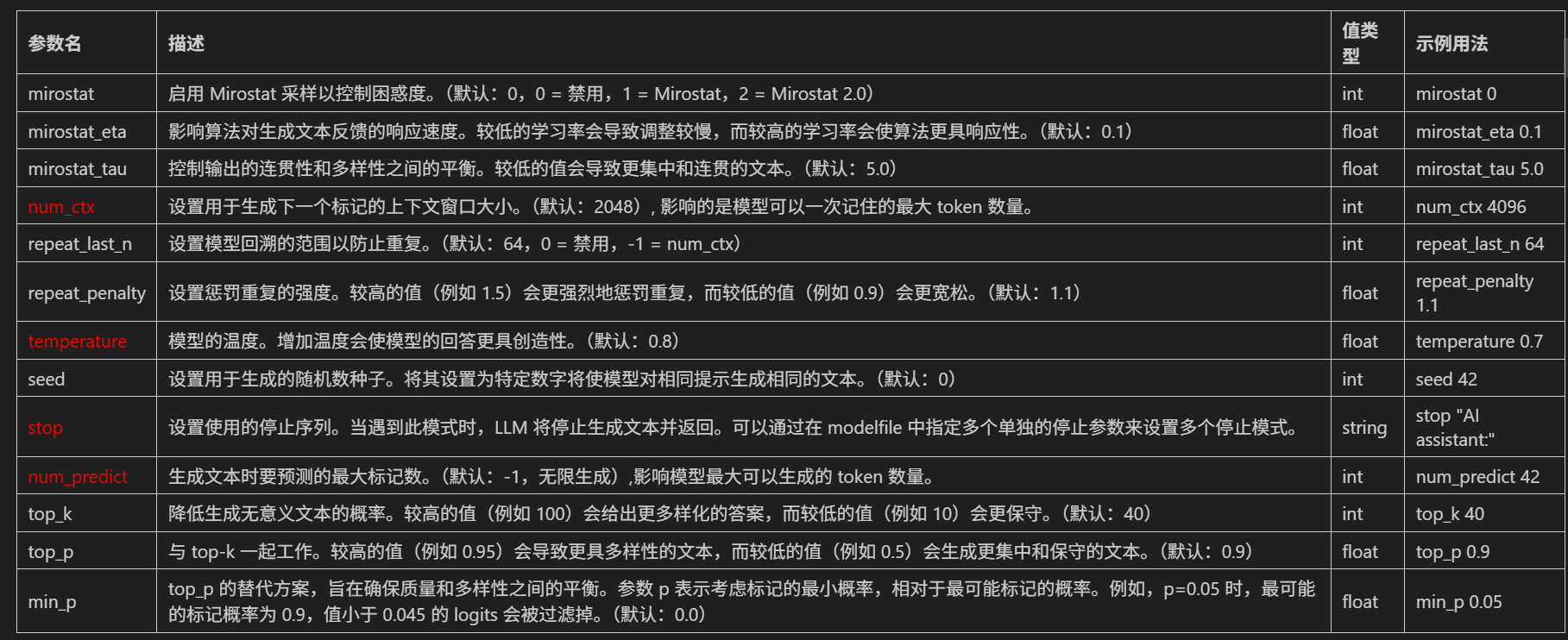
num_ctx 和 num_predict参数都是需要放置在 options 参数中的,其中:
num_ctx该参数指的是大模型在一次对话中能够"看到"和"记住"的最大上下文长度,默认配置 2048,相当于一次只能向模型输入 2ktoken,超过 2k 模型就无法记住。当prompt特别长时往往会出现问题。并且现在开源模型往往支持长上下文,默认配置会严重限制本地模型能力。num_predict参数指的是模型响应返回的最大 token 数据量。
我们可以这样测试:
import requests # type: ignore
import json
# 设置 API 端点
generate_url = "http://127.0.0.1:11434/api/generate" # 这里需要根据实际情况进行修改
# 示例数据
generate_payload = {
"model": "deepseek-r1:1.5b", # 这里需要根据实际情况进行修改
"prompt": "请生成一个关于人工智能的简短介绍。", # 这里需要根据实际情况进行修改
"stream": False, # 默认使用的是True,如果设置为False,则返回的是一个完整的响应,而不是一个流式响应
"options": {
# "num_ctx": 7, 慎用,可能会导致Ollama服务不稳定,建议选择 1024 及以上
"num_predict": 10
}
}
# 调用生成接口
response_generate = requests.post(generate_url, json=generate_payload)
if response_generate.status_code == 200:
generate_response = response_generate.json()
print("生成响应:", json.dumps(generate_response, ensure_ascii=False, indent=2))
else:
print("生成请求失败:", response_generate.status_code, response_generate.text)测试结果:
生成响应: {
"model": "deepseek-r1:1.5b",
"created_at": "2026-01-25T13:46:31.2225119Z",
"response": "<think>\n嗯,用户让我生成一个关于人工智能",
"done": true,
"done_reason": "length",
"context": [
151644,
14880,
43959,
46944,
101888,
104455,
9370,
98237,
99534,
100157,
1773,
151645,
151648,
198,
106287,
3837,
20002,
104029,
43959,
46944,
101888,
104455
],
"total_duration": 3521795400,
"load_duration": 3112872000,
"prompt_eval_count": 13,
"prompt_eval_duration": 321000000,
"eval_count": 10,
"eval_duration": 76000000
}4. 流式输出功能
接下来看流式输出输出,其参数和如上代码保持一致,只需要在 response_generate 中添加 stream=True,最后再通过流式的方式进行响应结果处理即可。代码如下所示:
import requests # type: ignore
import json
# 设置 API 端点
generate_url = "http://127.0.0.1:11434/api/generate"
# 示例数据
generate_payload = {
"model": "deepseek-r1:1.5b",
"prompt": "请生成一个关于人工智能的简短介绍。",
"options": {
"temperature": 0.6,
}
}
# 调用生成接口
response_generate = requests.post(generate_url, json=generate_payload, stream=True) # 在这里添加stream=True
if response_generate.status_code == 200:
# 处理流式响应
for line in response_generate.iter_lines():
if line:
try:
# 解码并解析每一行的 JSON
response_json = json.loads(line.decode('utf-8'))
if 'response' in response_json:
print(response_json['response'], end='', flush=True)
# 检查 response_json 字典中是否存在键 'done',并且其值是否为 True。如果这个条件成立,表示生成的响应已经完成。
if response_json.get('done', False):
print('\n\n完整响应:', json.dumps(response_json, ensure_ascii=False, indent=2))
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}")
else:
print("生成请求失败:", response_generate.status_code, response_generate.text)测试结果

5. Ollama 模型生命周期管理
默认情况下,通过Ollama run启动一个模型后,会将其在VRAM(显存)中保存5分钟。主要作用是为了做性能优化,通过保持模型在显存中,可以避免频繁的加载和卸载操作,从而提高响应速度,特别是在连续请求的情况下。
我们可以通过ollama stop 命令立即卸载某个模型。而在生成请求中,一种高效的方式是通过keep_alive参数来控制模型在请求完成后保持加载在内存中的时间。其可传入的参数规则如下:
|
参数类型 |
示例 |
描述 |
|
持续时间字符串 |
"10m" 或 "24h" |
表示保持模型在内存中的时间,单位可以是分钟(m)或小时(h)。 |
|
以秒为单位的数字 |
3600 |
表示保持模型在内存中的时间,单位为秒。 |
|
任何负数 |
-1 或 "-1m" |
表示保持模型在内存中,负数值将使模型持续加载。 |
|
'0' |
0 |
表示在生成响应后立即卸载模型。 |
import requests # type: ignore
import json
# 设置 API 端点
generate_url = "http://127.0.0.1:11434/api/generate"
# 示例数据
generate_payload = {
"model": "deepseek-r1:1.5b",
"prompt": "请生成一个关于人工智能的简短介绍。",
"stream": False,
"keep_alive": "10m", # 设置模型在请求后保持加载的时间
"options": {
"temperature": 0.6,
}
}
# 调用生成接口
response_generate = requests.post(generate_url, json=generate_payload)
if response_generate.status_code == 200:
generate_response = response_generate.json()
print("生成响应:", json.dumps(generate_response, ensure_ascii=False, indent=2))
else:
print("生成请求失败:", response_generate.status_code, response_generate.text)
if generate_response["eval_duration"] != 0:
tokens_per_second = generate_response["eval_count"] / generate_response["eval_duration"] * 10**9
print(f"Tokens per second: {tokens_per_second}")
else:
print("eval_duration is zero, cannot calculate tokens per second.")此时就可以在服务器控制台查看到:

keep_alive 在工程化的项目中,往往需要根据请求的频率来设置,如果请求不频繁,可以使用默认值或较短的时间,以便在不使用时释放内存。而如果应用程序需要频繁调用模型,可以设置较长的 keep_alive 时间,以减少加载时间。很关键,非常影响服务器的性能和应用程序的用户体验。大家一定要注意。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)