【Daily Report | 2026-01-25】
题单二总结DAY02。
题单二总结DAY02
复习内容
学习内容
1.B2113 输出亲朋字符串
2.P5329 [SNOI2019] 字符串
一、题目
B2113 输出亲朋字符串
题目描述
亲朋字符串定义如下:给定字符串 s s s 的第一个字符的 ASCII 值加第二个字符的 ASCII 值,得到第一个亲朋字符; s s s 的第二个字符加第三个字符得到第二个亲朋字符;依此类推。注意:亲朋字符串的最后一个字符由 s s s 的最后一个字符 ASCII 值加 s s s 的第一个字符的 ASCII 值。
输入格式
输入一行,一个长度大于等于 2 2 2,小于等于 100 100 100 的字符串。
输出格式
输出一行,为变换后的亲朋字符串。输入保证变换后的字符串只有一行。
输入输出样例 #1
输入 #1
1234
输出 #1
cege
Tips
返回值不同
| 写法 | 含义 |
|---|---|
s[i] |
char |
(int)s[i] |
ASCII |
s[i] - '0' |
数字值 |
printf("%c", s[i]) |
字符 |
printf("%d", s[i]) |
ASCII |
ans.push_back(char(result % 256));
char只能表示 0~255(1 字节) 的范围,
当计算结果result大于 255 时,直接转成 char 会溢出,结果不可控。因此需要对 256 取模,只保留 最低 8 位,
再安全地转成char输出。结论:使用
char时,要注意取值范围,必要时先%256。
完整代码
#include<bits/stdc++.h>
using namespace std;
string s="";
vector<char> ans;
int result=0;
int main(){
while(cin>>s){
ans.clear();
for(int i =0;i<s.size();i++){
if(i == s.size()-1){
result = int(s[i])+int(s[0]);
ans.push_back(char(result%256));
}else{
result = int(s[i])+int(s[i+1]);
ans.push_back(char(result%256));
}
}
for(int i =0;i<s.size();i++){
cout<<ans[i];
}
}
return 0;
}
P5329 [SNOI2019] 字符串
题目描述
给出一个长度为 n n n 的由小写字母组成的字符串 a a a,设其中第 i i i 个字符为 a i ( 1 ≤ i ≤ n ) a_i(1\le i\le n) ai(1≤i≤n)。
设删掉第 i i i 个字符之后得到的字符串为 s i s_i si,请按照字典序对 s 1 , s 2 , ⋯ , s n s_1,s_2,\cdots,s_n s1,s2,⋯,sn 从小到大排序。若两个字符串相等,则认为编号小的字符串字典序更小。
输入格式
第一行一个整数 n n n。
第二行一个长为 n n n 的由小写字母组成的字符串 a a a。
输出格式
输出一行 n n n 个整数 k 1 , k 2 , ⋯ , k n k_1,k_2,\cdots,k_n k1,k2,⋯,kn,用空格隔开。表示 s k 1 < s k 2 < ⋯ < s k n s_{k_1}<s_{k_2}<\cdots<s_{k_n} sk1<sk2<⋯<skn。
输入输出样例 #1
输入 #1
7
aabaaab
输出 #1
3 7 4 5 6 1 2
说明/提示
对于所有数据, 1 ≤ n ≤ 10 6 1\le n\le 10^6 1≤n≤106。
对于 10% 的数据, 1 ≤ n ≤ 2000 1\le n\le 2000 1≤n≤2000;
对于另外 20% 的数据, 1 ≤ n ≤ 10 5 1\le n\le 10^5 1≤n≤105 且任意两个相邻字符 a i , a i + 1 a_i,a_{i+1} ai,ai+1 不相等;
对于另外 30% 的数据, 1 ≤ n ≤ 10 5 1\le n\le 10^5 1≤n≤105;
对于余下 40% 的数据,无特殊限制。
Tips
字典序(Lexicographical Order)就是像查字典一样比较字符串的大小。
比较规则如下:
- 从左到右逐个字符比较;
- 在第一个不同的位置上,ASCII 值较小的字符所在字符串字典序更小;
- 如果所有字符都相同,则长度较短的字符串字典序更小。
示例:
"abc" < "abd"(因为c < d)"abc" < "abcd"(前缀相同,短的更小)"abZ" < "aba"('Z'(90) < 'a'(97))"10" < "2"(按字符比较,'1' < '2')在 C++ 中,字符串可以直接使用比较运算符进行字典序比较:
if (a < b) {// a 的字典序更小 }
字典序本质上就是按 ASCII 顺序从左到右比较字符:'0'~'9' < 'A'~'Z' < 'a'~'z'。一句话总结:字典序 = 从左到右,按 ASCII 值比较字符。
这题的核心在于 排序关系判断 + 双端构造。
如果出现 前小后大(
c[i] > c[i-1]),
说明当前位置会让字典序变大,
前面这一段下标应该往后放。如果出现 前大后小(
c[i] < c[i-1]),
说明当前位置可以让字典序变小,
前面这一段下标应该往前放。本质上是:
通过把下标从两端放入答案,
删除合适位置的元素,从而得到更小的字典序结果。
**样例示意图**
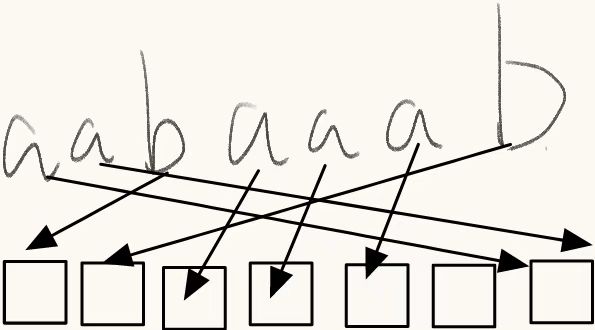
完整代码
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6+7;
int ans[N];
int id= 1 ;
char c[N];
int main(){
int n =0;
cin>>n>>c+1;
int l =1,r =n;
for(int i = 2;i<=n;i++){
if(c[i]>c[i-1]){
for(int j = i-1;j>=id;j--){
ans[r--]=j;
}
id = i;
}
if(c[i]<c[i-1]){
for(int j = id;j<i;j++){
ans[l++]=j;
}
id=i;
}
}
for(int i =id ;i<=n;i++){
ans[l++] = i;
}
for (int i = 1; i <= n; i++) {
cout << ans[i] << " ";
}
cout << endl;
return 0;
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)