AI安全:大模型微调中的数据安全风险及防护措施
《大模型微调数据安全风险与防护方案》 摘要:大语言模型微调在金融、医疗等领域广泛应用的同时,也面临严峻的数据安全挑战。本文系统分析了微调全流程中的四大核心风险:训练数据的合规瑕疵与污染攻击(占比62%)、训练过程的梯度反演(28%)、部署环节的传输泄露,以及存算协同的跨域风险。针对这些风险,提出全链路防护体系:通过数据脱敏和污染检测保障源头安全;采用差分隐私和加密技术防护训练过程;实施API加密和
随着大语言模型(LLMs)在金融、医疗、政务等关键领域的深度落地,微调技术已成为实现模型个性化适配的核心手段。通过微调,模型可基于行业专属数据、企业私有数据优化性能,精准匹配业务场景需求。但微调过程中的数据流转环节多、敏感信息密集,且面临合规监管与恶意攻击的双重压力,数据安全风险已成为制约大模型规模化落地的核心瓶颈。本文将系统拆解大模型微调中的核心数据安全风险,结合技术实践与合规要求,提出全链路防护方案,为开发者与企业提供实操指引。
一、大模型微调的数据安全核心风险
大模型微调的全流程涵盖数据采集、预处理、训练实施、模型部署四大环节,各环节均存在差异化安全风险,且风险可能沿数据流转链路传导扩散,形成连锁影响。结合OWASP Gen AI安全框架与行业实践,核心风险可归纳为四大类。
(一)训练数据源头风险:合规瑕疵与污染攻击
训练数据是微调的核心“燃料”,其来源合法性与内容完整性直接决定风险基数,此类风险占微调安全事故的62%以上。
在合规层面,核心风险表现为授权链条断裂与隐私泄露。一方面,部分企业为追求数据规模,通过非法爬虫、黑市采购等方式获取数据,或使用未获得明示授权的用户数据(如医疗病历、金融交易日志)进行微调,违反《数据安全法》《个人信息保护法》中“合法、正当、必要”的核心原则,可能面临最高5000万元罚款。另一方面,自有数据处理不当也会引发风险,如未对包含个人信息的客服对话、业务文档进行脱敏,导致身份证号、银行卡号等敏感信息被模型“记忆”,攻击者可通过提示词诱导模型输出隐私内容。
在数据质量层面,数据污染攻击已成为主流威胁。攻击者通过在训练数据中注入恶意内容、篡改样本标签等方式,可导致模型输出偏差、功能失效甚至植入后门。例如,在行业专属数据集的第三方采购环节,攻击者可能混入含隐藏触发条件的样本,使模型在特定指令下输出有害内容,且此类后门因隐蔽性强,难以通过常规测试检测。此外,开源语料库的滥用也会引入风险,部分开源数据存在版权纠纷或隐藏敏感信息,若未核查开源协议与数据合法性,可能引发侵权纠纷。
(二)训练过程风险:中间产物泄露与梯度反演
微调过程中产生的梯度数据、训练日志、模型快照等中间产物,是易被忽视的泄露突破口,此类风险占比达28%。
梯度反演攻击是典型威胁之一。梯度数据包含训练样本的核心特征,攻击者可通过分析梯度变化还原原始训练数据,即使采用联邦微调,若梯度未加密,中间节点也能窃取核心信息。
训练日志与模型快照的管控疏漏同样危险。训练日志若记录样本ID、损失值变化、参数更新细节,且未加密存储,攻击者可结合日志与模型输出反向推导数据分布;中间版本的模型快照可能包含中间层输出特征,一旦泄露,可通过特征匹配定位敏感数据。此外,训练过程中生成的缓存文件、数据分片备份若未及时清理,也会成为泄露隐患。
(三)部署链路风险:传输泄露与权限滥用
微调后的模型部署环节虽风险占比相对较低(10%),但直接关联业务场景,泄露后果更具破坏性。核心风险集中在传输安全与权限管控两大维度。
传输层面,API调用是主要风险点。若请求参数(输入文本)未加密传输,可能被中间人劫持;部分企业为简化部署流程,将模型部署在公网可访问的服务器,且未设置访问密钥,导致模型参数与推理数据被非法获取。推理日志的不当留存也会引发风险,若日志记录用户输入的敏感内容,且长期未清理,会形成隐私数据沉淀。
权限层面,最小权限原则落实不到位是核心问题。开发人员、运维人员、第三方服务商权限边界模糊,可能导致跨角色访问模型参数或推理数据;闲置权限未及时回收、密钥长期不轮换等问题,进一步放大了内部泄露风险。
(四)存算协同风险:跨域流转与算力依赖漏洞
当前企业多采用第三方云上智算资源进行微调,存算分离架构下的跨域数据流转风险日益突出。企业若自行搭建算力资源,成本压力过大;若依赖云端算力,原始数据跨域传输时易遭遇网络攻击、恶意篡改,且可能因算效下降间接增加成本。此外,部分企业在存算分离场景下未对数据进行分级分类存储,核心业务数据与普通数据混存,导致核心数据访问管控失效。
二、大模型微调数据安全全链路防护措施
针对上述风险,需构建“数据源头-训练过程-部署上线-存算协同”的全链路防护体系,兼顾技术防控、制度管控与合规适配,实现安全与性能的平衡。
(一)源头管控:构建合规、洁净的数据供给体系
1. 合规化数据采集。优先使用自有数据,对包含个人信息的自有数据,需通过用户协议明确告知使用目的、范围及留存期限,获得用户明示同意且保障同意可撤回,采集后立即通过掩码替换、字段删除等方式脱敏。第三方采购数据时,需对服务商进行全面尽调,核查资质与授权链条,签订规范协议明确侵权责任划分,要求服务商提供数据脱敏服务与合规报告。公开网络数据采集需遵循平台robots协议,规避恶意爬虫与版权侵权,开源语料库需核查协议类型,严格遵循署名、使用范围等要求。
2. 数据污染检测与清理。搭建数据校验流水线,采用异常检测技术过滤 adversarial 数据,通过哈希去重、语义校验剔除重复内容与恶意样本。引入ML-BOM工具追踪数据 origins 与 transformations,记录数据流转全链路,实现风险可追溯。对行业专属数据集,可通过与可信数据源交叉验证,检测标签篡改、后门注入等问题,必要时采用人工复核核心样本。
(二)训练过程防护:强化中间产物与梯度安全
1. 梯度与参数安全。采用差分隐私(DP)微调技术,在梯度中加入适量噪声掩盖单样本特征,ε值建议设置为1-5以平衡隐私与性能。可借助LLaMA-Factory等工具的内置模块,自动优化噪声系数与梯度裁剪阈值,降低实操成本。同时,采用AES-256加密算法对梯度数据、模型参数进行传输与存储,避免明文泄露。
2. 中间产物管控。训练日志需脱敏处理,移除样本ID、具体损失值等敏感信息,仅记录趋势数据,日志文件加密存储并设置访问白名单。模型快照仅保留最终版本,中间版本生成后立即删除,快照文件加密压缩存储并定期轮换密码。微调结束后,用shred命令彻底删除缓存文件、数据分片,避免文件被恢复。
附:梯度加密与日志脱敏实操代码片段
以下基于LLaMA-Factory实现差分隐私微调与日志脱敏,适配PyTorch框架,支持主流开源大模型(如Llama 3、Qwen)。
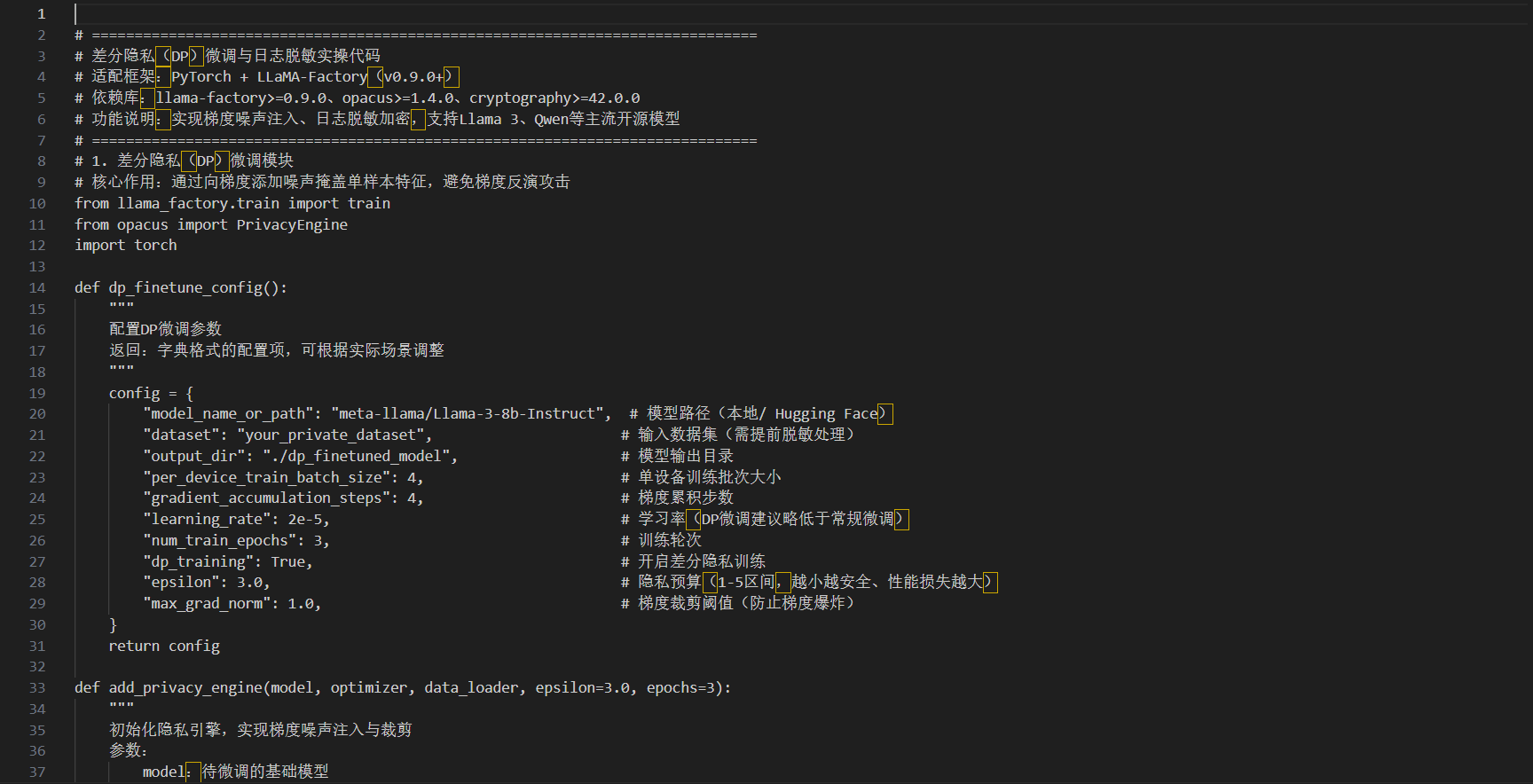
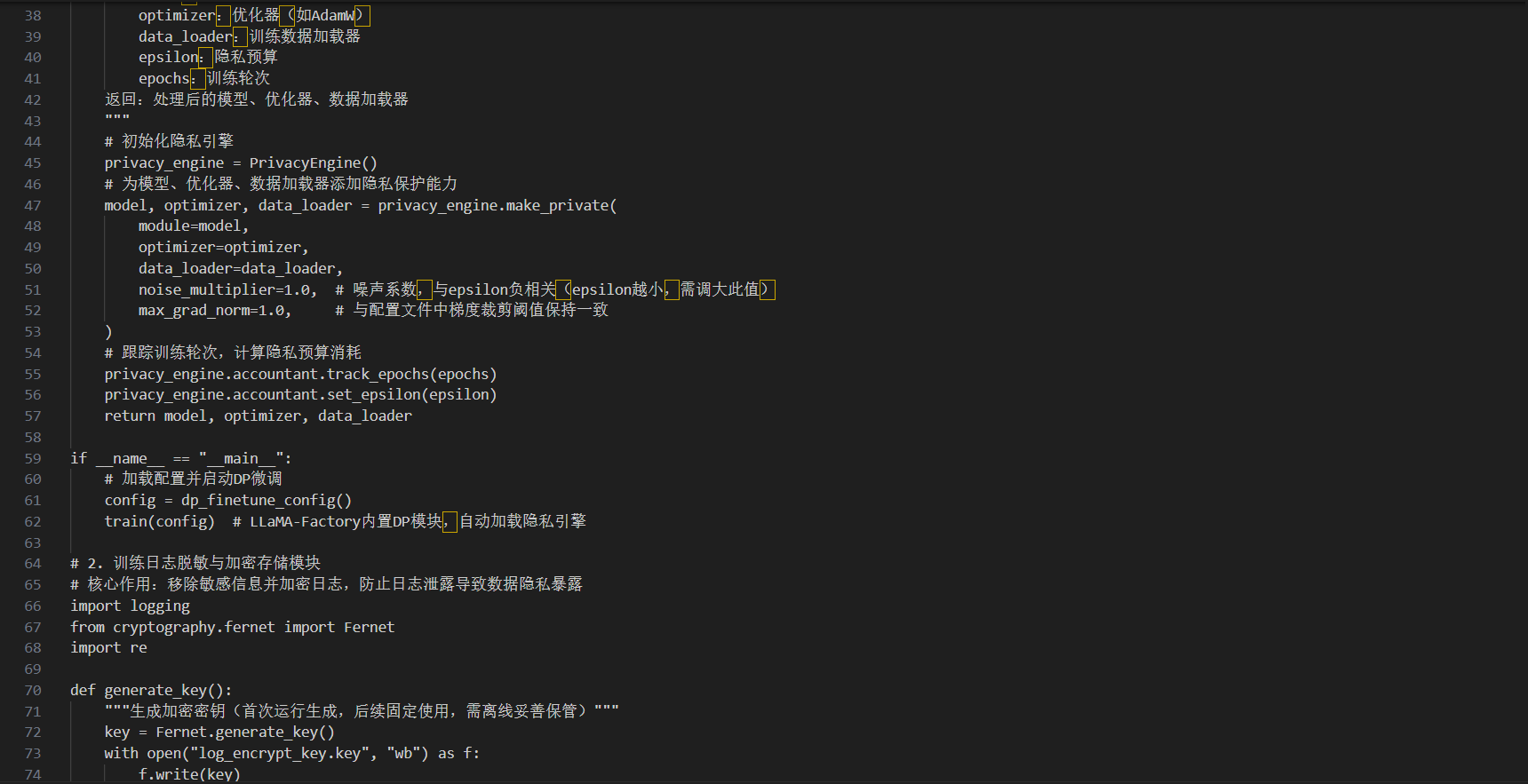
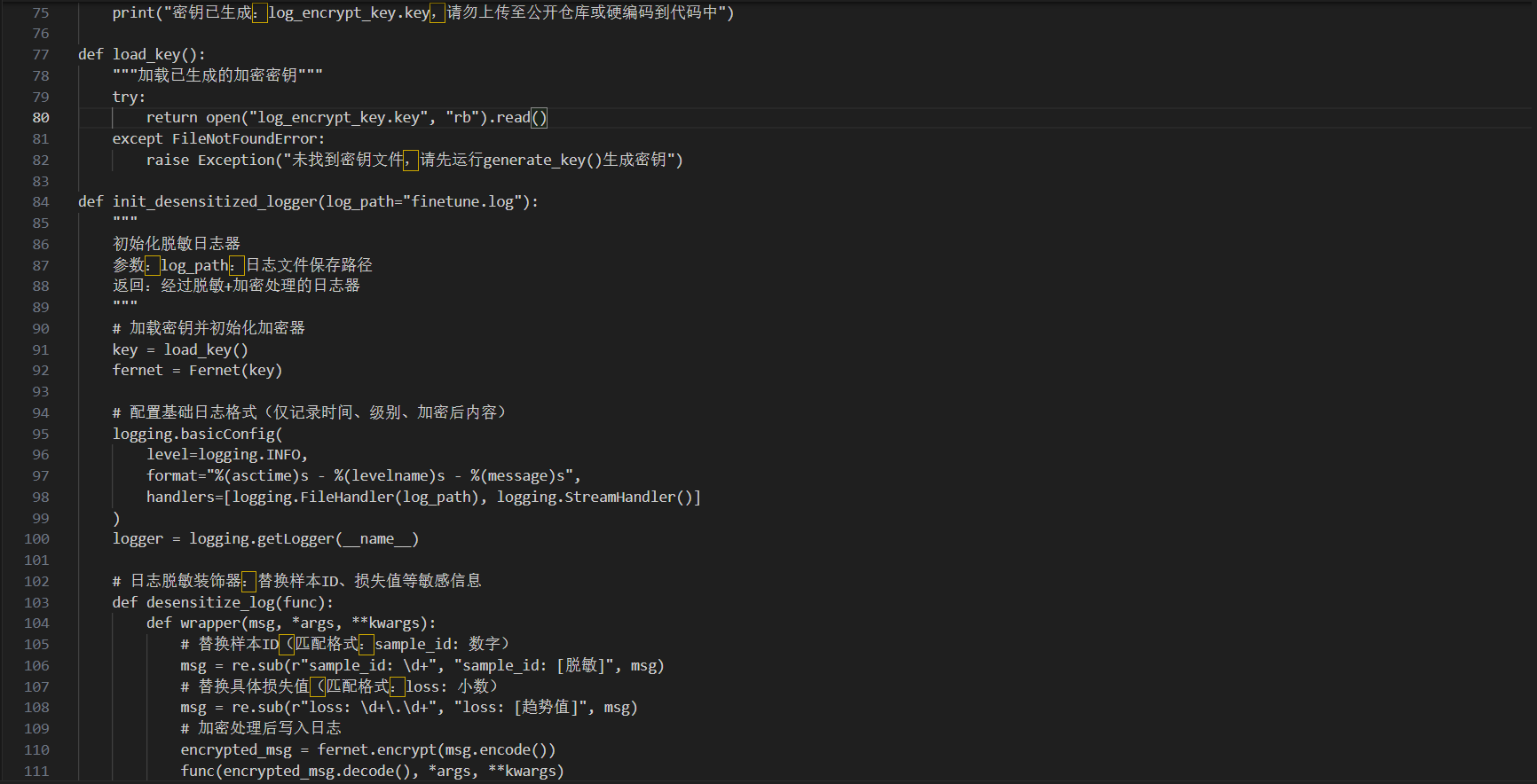
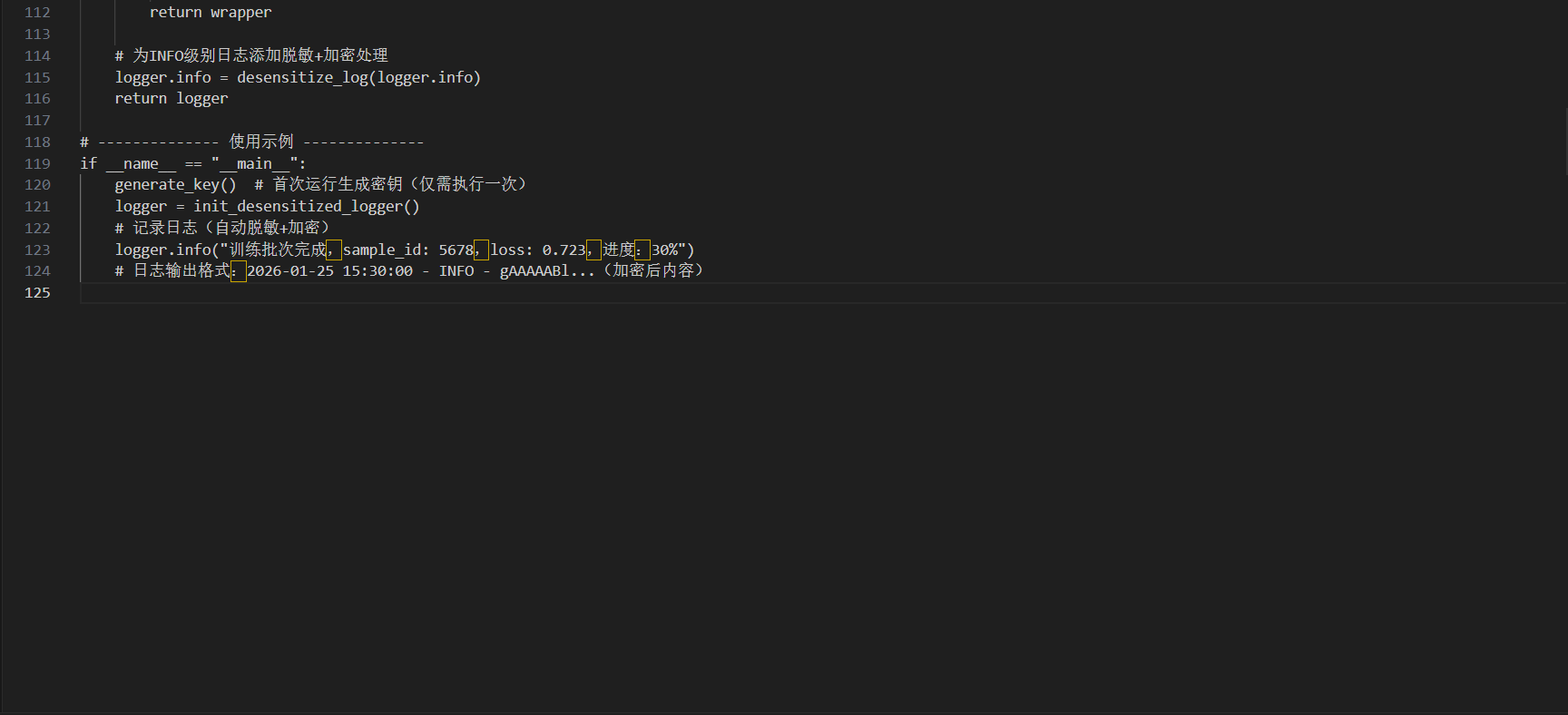
说明:代码中密钥需离线存储,避免硬编码;DP微调的epsilon值可根据数据敏感等级调整,金融、医疗数据建议取1-2,普通行业数据可取3-5。
(三)部署上线防护:筑牢传输与权限边界
1. 传输加密与API防护。采用HTTPS+JWT令牌双重防护,API请求参数与返回结果均进行AES加密,JWT令牌设置1小时有效期并支持动态吊销,每次调用均验证权限。部署服务器仅开放必要端口,禁用密码登录,采用SSH密钥登录并定期轮换密钥。
2. 精细化权限与日志管控。基于RBAC模型分配权限,实现开发、运维、业务人员角色分离,禁止跨角色访问核心数据,定期审计权限使用记录并回收闲置权限。推理日志瘦身处理,仅记录请求时间、状态码、调用方IP,不记录输入输出内容,每周自动清理备份,避免数据沉淀。
(四)存算协同防护:基于AI WAN的安全优化方案
针对存算分离场景的跨域风险,可采用智能IP广域网(AI WAN)的云边协同方案。通过模型拆分学习技术,将模型与数据按安全等级拆分部署,实现原始数据不出域,在100KM、400KM拉远场景下保障97%以上高算效。结合SRv6切片功能与精准流控技术,为微调业务分配专属网络切片,保障带宽与时延需求的同时实现逐级反压。通过自动流级调度技术优化路径规划,最大化网络运力,降低用算成本与安全风险。
(五)制度保障:建立全流程合规与审计体系
制定数据分级分类管理制度,对核心业务数据、敏感个人信息进行重点管控,建立内部数据采集审批流程。定期开展合规培训与安全演练,提升开发人员隐私保护意识与风险应对能力。引入第三方机构开展安全评估与合规审计,排查隐私泄露、版权侵权等隐患,确保符合法律法规与行业标准。
三、总结与展望
大模型微调的核心价值在于数据与模型的深度融合,而数据安全是这种融合的前提。当前,数据泄露、污染攻击、合规风险等问题仍制约着微调技术的落地,需摒弃“重性能、轻安全”的理念,通过技术手段构建防护屏障,同时依托制度建设与合规适配筑牢底线。
未来,随着存算分离、联邦学习、差分隐私等技术的持续迭代,以及行业监管体系的不断完善,大模型微调的数据安全能力将进一步提升。企业需主动适配技术与合规变化,将数据安全嵌入微调全流程,才能在享受AI技术红利的同时,守住安全与合规的底线。对于开发者而言,掌握数据脱敏、梯度加密等核心防护技术,既是职业能力的提升,也是应对行业风险的关键。
附:核心工具简易使用步骤
以下步骤适配主流开发环境(Linux/macOS),Windows环境可对应调整命令,确保工具快速上手:
1. 开源训练安全工具(LLaMA-Factory+Opacus)
1. 安装依赖:pip install llama-factory==0.9.5 opacus==1.4.1 torch==2.1.0,指定版本避免兼容性问题。
2. 配置微调:将上述代码中的数据集路径替换为实际路径,根据模型规模调整批次大小(如7B模型建议batch_size=2)。
3. 启动训练:直接运行脚本,DP模块自动加载,训练完成后模型将保存至配置的output_dir目录。
2. API部署防护工具(Kong Gateway)
1. 安装部署:通过Docker快速启动,命令:docker run -d --name kong -p 8000:8000 -p 8443:8443 kong:latest。
2. 配置加密:进入Kong管理界面,创建API路由,启用HTTPS与JWT插件,设置令牌有效期为1小时。
3. 权限管控:添加访问白名单,仅允许指定IP或角色调用模型API,定期在管理界面轮换访问密钥。
3. 密钥管理工具(HashiCorp Vault)
1. 安装启动:brew install vault(macOS)或 apt install vault(Linux),启动命令:vault server -dev。
2. 存储密钥:执行vault kv put secret/llm/log-key key=$(cat log_encrypt_key.key),将日志加密密钥存入Vault。
3. 动态调用:在微调脚本中集成Vault SDK,训练时动态获取密钥,避免密钥本地明文存储。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)