取长补短,解锁推理性能1+1>2,DeepLink首发:生产级国产异构算力混合推理加速方案
DeepLink 团队打造首个国产异构算力 PD 分离混合推理方案,通过 PD 分离架构,实现了3款异构芯片的混合推理。此方案利用国产硬件的异构优势,实现 1+1 > 2 的推理效能,为 AI + 制造等场景的规模化落地提供可行路径。
近期,工信部联合 7 部门出台《“人工智能 + 制造” 专项行动实施意见》,明确将异构算力突破列为技术创新核心抓手,为人工智能高质量发展锚定了方向。在大模型与实体经济加速融合的当下,算力的效能发挥直接决定着 AI 技术落地的深度与广度。
而在大语言模型(LLM)推理的工程实践中,我们始终面临着一个经典的“二律背反”:极低的延迟(Latency)与极高的吞吐量(Throughput)往往难以兼得。随着 DeepSeek-V3/R1 等超大规模 MoE 模型的爆发,显存墙(Memory Wall)与计算墙(Compute Wall)的博弈愈发激烈。
上海 AI 实验室 DeepLink 团队打造首个国产异构算力 PD 分离混合推理方案,通过 PD 分离架构,实现了3款异构芯片的混合推理。此方案利用国产硬件的异构优势,实现 1+1 > 2 的推理效能,为 AI + 制造等场景的规模化落地提供可行路径。
一、 基础支撑:DLInfer +DLSlime,国产推理与高速互联并驾齐驱
DeepLink 团队推出的 DLInfer 与 DLSlime,分别构建起国产大模型推理的适配底座与高速通信桥梁,二者协同发力,实现了“推理效能优化”与“异构互联提速”双向突破,为国产硬件生态下的大模型混合推理提供核心支撑。
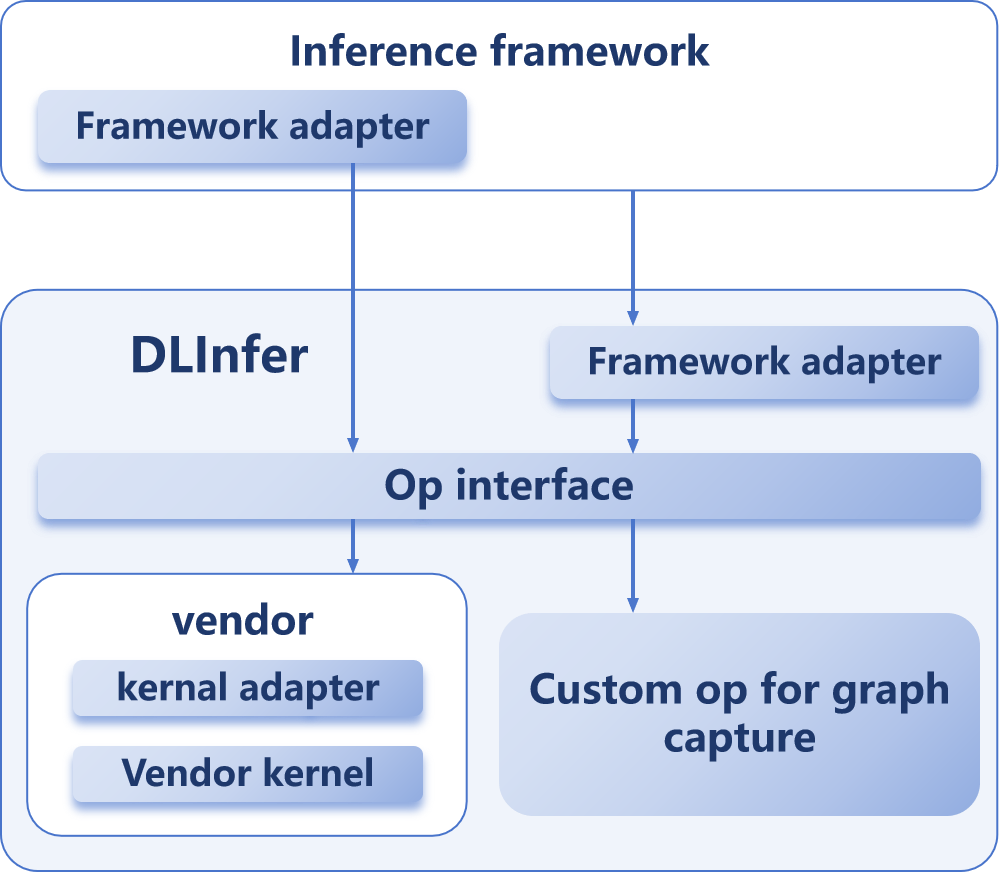
DLInfer 作为专为国产硬件适配的大模型推理中间件,以标准化融合算子接口为核心,打通上层推理框架与底层异构硬件的协同壁垒,实现软硬适配工程的高效解耦。目前 DLInfer 已兼容 InternLM、InternVL、Qwen、DeepSeek 等系列主流模型,支撑超 5 款主流国产硬件接入。其通过分层设计提供双执行模式:Eager 模式可直接调用厂商优化融合算子,满足快速调试需求;Graph 模式则对接硬件图编译引擎,凭借精准算子匹配实现端到端性能优化,大幅降低多平台开发成本。
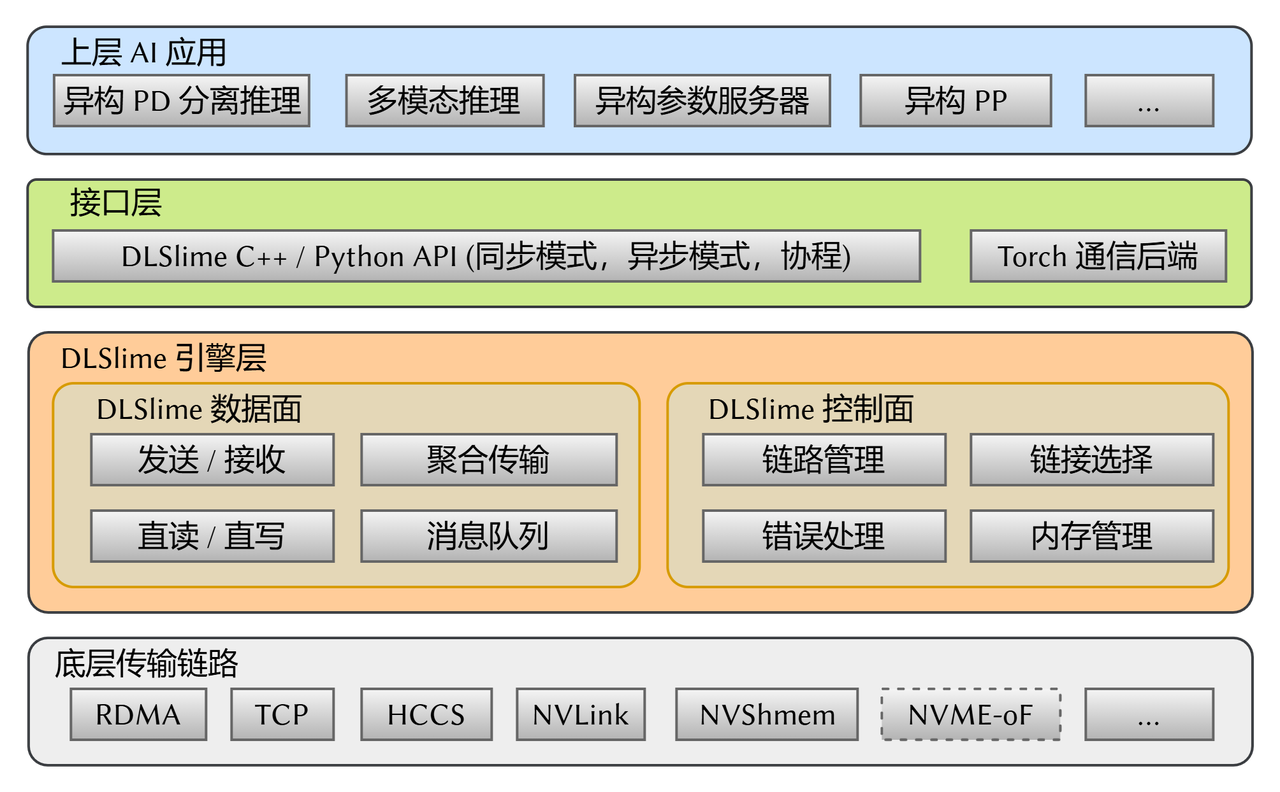
开源 AI 异构芯片高效通信库 DLSlime,是 PD 分离推理、异构跨域训练等方案的核心组件,为多设备、多链路数据传输搭建高效桥梁。其可实现跨架构设备高速互联,部分场景带宽利用率超 97%;并兼容 RDMA、NVShmem、NVLink、HCCS 等节点内及节点间高速通信链路,适配多元硬件环境;同时,DLSlime 支持 PD 分离、多模态推理、异构训练等多种通信范式,覆盖全场景需求。此外,通信性能表现优异,小消息时延接近 RDMA 理论下限,大 Batch 高并发场景下,吞吐量较 NIXL 提升近 1 倍、较 NCCL 提升 3 倍,异构互联带宽较 Torch 原生通信库高出一个数量级。
DLInfer 的推理适配能力与 DLSlime 的高速通信能力形成互补,前者解决“软硬协同效率”问题,后者突破“跨设备传输瓶颈”,共同为国产大模型异构算力、高并发推理等场景筑牢技术根基。
二、计算访存解耦:PD 分离与 SLO 的精准对齐
在传统的 Monolithic(单体)推理架构中,Prefill(预填充)阶段和 Decode(解码)阶段共享同一组计算资源。然而,这两个阶段的计算特性截然不同:
-
Prefill 阶段:Compute-bound(计算受限)。需要处理长 Prompt,是密集的矩阵乘法(GEMM),对 FLOPs 要求极高。
-
Decode 阶段:Memory-bound(访存受限)。逐 Token 生成,主要瓶颈在于 KV Cache 的读取,对 HBM 带宽敏感。
当两者混跑时,长 Prompt 的 Prefill 请求会抢占计算资源,导致正在 Decode 的请求出现明显的卡顿(Inter-token Latency 飙升),严重影响用户体验。因此,为了解决此类问题,便提出了 PD 分离的方式。
PD 分离(Disaggregated Prefill-Decode)将这两个过程拆分到不同的节点:Prefill 阶段只需专注于快速处理 Prompt,生成 KV Cache;而 Decode 阶段则接收 KV Cache,专注于高速生成 Token。

在单芯片场景中,PD 分离仅能实现逻辑层面的任务拆分,通过调度策略避免 Prefill 与 Decode 阶段的资源争抢,优化单芯片内资源利用率。例如可减少长 Prompt Prefill 任务对 Decode 任务的阻塞,降低 Inter-token Latency 波动,让单一芯片在兼顾 TTFT(首字生成时间)与 TPOT(每输出 token 时间)的同时,逼近硬件性能上限。但受限于单芯片算力与带宽的固有配比,无法突破 “算力强则带宽不足、带宽优则算力有限” 的瓶颈,性能提升存在天然边界。
而在多芯片场景中,PD 分离通过异构混推架构实现物理层面的资源适配,将特性差异转化为性能优势。一方面可构建异构资源池:将高算力芯片组成 Prefill 集群,通过全图下沉、子图融合最大化并行计算效能,快速完成 KV Cache 批量生成;将高带宽 / 大显存芯片组成 Decode 集群,通过 TP 互联与 PagedAttention 优化算子,低成本提升缓存访问效率。另一方面依托高速互联与中间件(如 DLInfer+DLSlime),实现 KV Cache 跨节点低延迟传输,配合智能调度让两集群高效协同。
DeepLink 混合推理方案优势在于 SLO(服务等级目标)的精细化管理,不再追求笼统的性能,而是针对 TTFT (Time to First Token) 优化 Prefill 节点,针对 TPOT (Time Per Output Token) 优化 Decode 节点。通过 LMDeploy 的流水线编排,可以确保 Decode 节点的显存几乎全部用于 KV Cache,从而支持极大的 Batch Size,显著提升系统整体吞吐。
三、 1+1 > 2:国产异构硬件的“田忌赛马”
在国产硬件生态中,芯片的规格往往各有侧重。有的芯片(如训练卡)算力极强但价格昂贵;有的芯片(如推理卡)显存带宽不错且成本低廉。DeepLink 混合推理方案通过 DLInfer 的硬件抽象层构建一个异构的推理集群,实现算力与显存的互补组合,将好钢用在刀刃上:
-
针对 Prefill 节点(算力型),部署高算力芯片。利用 DLInfer 提供的 Graph Mode,方案可以将整个 Prefill 计算图进行全图下沉或大范围子图融合。通过静态图优化,最大化利用 Cube 单元的矩阵运算能力,瞬间完成超长 Context 的编码。
-
针对 Decode 节点(显存型/带宽型),部署高带宽或大显存芯片(例如旧一代的高显存卡)。Decode 阶段计算量小,但需要频繁读取 KV。多张低算力但高带宽的卡通过 TP(Tensor Parallel)互联,可以低成本地提供海量的 KV Cache 吞吐。
DeepLink 混推方案可同步利用 LMDeploy 的 KV Cache Manager 机制,配合 DLInfer 优化的 Communication Kernels 和 DLSlime 针对 KV Cache 的高效传输,实现通过 RDMA 或片间高速互联,将 Prefill 节点生成的 KV Cache 快速“搬运”到 Decode 节点。随后,DLInfer 则可以发挥其算子特化的能力,在PD的两个阶段分别调用高算力版本的算子接口。比如:在 Prefill 端,DLInfer 调用 FlashAttention 的高算力版本;在 Decode 端,DLInfer 调用针对 PagedAttention 深度优化的 Kernel,甚至利用内联汇编优化特定芯片的访存指令。这种组合使得我们能够以更低的 TCO(总拥有成本) 构建出对比同规模单一旗舰芯片集群推理更高效的PD分离异构集群混合推理服务。
四、 架构演进:跨代次融合与微服务化
而随着模型架构的演进(如 MoE、长文本),DeepLink 混合推理方案的架构可以继续向以下方向深化:
1. 跨代次芯片混用
企业往往存有大量上一代算力卡。在 PD 分离架构下,老旧显卡可以专门作为 Decode 节点或 KV Cache 的“以存代算”节点,而将最新的高性能卡全部用于 Prefill。DLinfer 统一的接口屏蔽了代次差异,使得 V100 时代的国产对标卡能与 H100 时代的对标卡在同一服务中协作。
2. AF 分离 (Attention-Feedforward Disaggregation)
这是一种更激进的切分。由于 Attention 模块消耗了大部分显存(KV Cache),而 Feedforward Network (FFN) 消耗了大部分计算。 未来我们可以尝试将 FFN 层的计算卸载到算力极强但显存较小的节点,而将 Attention 保留在显存大户节点。这需要极高带宽的互联支持,是芯片设计与软件架构协同优化的下一个高地。
3. EP 微服务化 (Expert Parallelism as a Service)
针对 DeepSeek-V3/R1 这类巨型 MoE 模型,全量加载单机显存压力巨大。 DeepLink 混合推理方案可以将 Expert 层微服务化。比如,将不同的 Expert 组(Experts Group)放置在不同的异构节点上,主干网络(Router + Attention)则负责调度;再利用 DLInfer 的通信算子实现极其高效的 Expert Dispatch 和 Combine。 这使得我们能够利用碎片化的国产算力资源,拼凑出运行万亿参数模型的能力。
五、 落地探索:混合推理方案初步锚定多模态场景
技术架构的价值,终究要在真实产业场景中落地验证。而在 AI + 、科研文档处理等刚需场景中,多模态数据结构化是打通数据流转链路的关键一环,这一过程对推理性能的要求,恰恰成为检验混合推理方案价值的最佳试金石。
MinerU 作为上海 AI 实验室研发的一款开源的一站式文档解析工具,凭借高效的 PDF 转结构化 Markdown 能力,收获 GitHub 数近 50K 的星标,在文档解析领域有着重要的影响力。其核心任务是将 PDF 等复杂文档转换为结构化的 Markdown,是一个典型的多模态数据生成场景。其场景的资源需求特征与混合推理方案的 Prefill-Decode 分离架构高度契合,天然成为验证混合推理方案效能的理想场景。
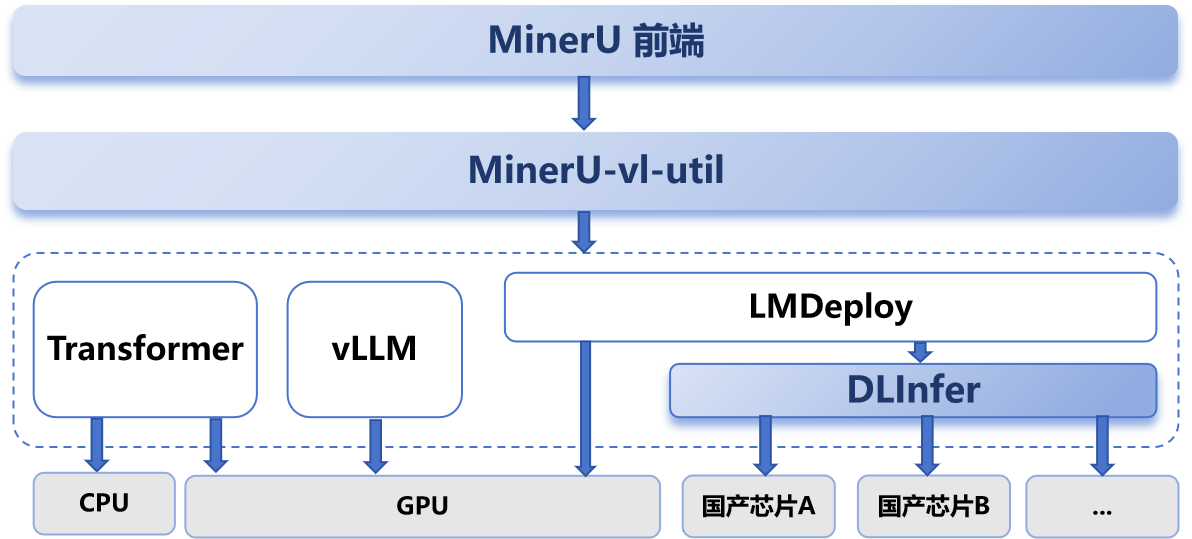
此前,DeepLink 已通过 Mineru-LMDeploy-DLInfer 的技术路线,将 MinerU 无缝运行在曦云 C500 上,并实现 Graph 模式性能相比 Eager 模式提升了 60%。通过多方技术优势的互补,实现了复杂垂类场景的性能加速突破。而 DeepLink 混合推理方案将逐步推进多款芯片在 MinerU 多模态数据生成场景的落地,实现 1+1 > 2 的推理效能。
结语
硬件决定了性能的上限,而软件栈决定了我们能多大程度逼近这个上限。DeepLink 混推方案通过 DLInfer 的底层算子优化和 DLSlime 的异构高速互联,让 PD 分离技术运用于异构算力混合推理不再是理论,而是国产算力降本增效的最佳实践。
更多DeepLink相关动态,可关注账号~
内容转自:取长补短,解锁推理性能1+1>2,DeepLink首发:生产级国产异构算力混合推理加速方案 - 浦算DeepLink的文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)