让业务人员开口即查:NL2SQL 的 Agent + RAG 架构实战
本文介绍了NL2SQL(自然语言转SQL)在企业数据分析场景中的应用方案。通过Agent+RAG架构,实现了业务人员自然语言查询到可执行SQL的自动转换。文章详细阐述了从数据准备、知识向量化、RAG检索到Agent配置的全流程,重点讲解了如何构建业务知识库、优化检索策略,以及通过智能体编排实现多阶段推理和SQL验证。该方案解决了传统NL2SQL在表名猜测、业务术语理解等方面的痛点,使业务人员能够直
让业务人员开口即查:NL2SQL 的 Agent + RAG 架构实战
「查一下上个月销售额 TOP10 的产品」——业务人员的一句话,数据分析师可能要写 20 分钟 SQL。如果这个过程能自动化呢?
写在前面
在企业数据分析场景中,SQL 是数据与业务之间最大的鸿沟。业务人员有问题,但不会写 SQL;数据分析师会写 SQL,却疲于应付各种临时取数需求。
NL2SQL(自然语言转 SQL)正是为解决这一痛点而生。但理想很丰满,现实很骨感——很多团队尝试后发现:
- 简单 Demo 跑得通,生产环境问题百出
- 模型总是「猜」表名,生成的 SQL 根本跑不了
- 缺乏业务知识,涨跌幅、换手率这些术语完全不懂
本文是一个完整的端到端实战指南,基于 CrewAI 智能体 + RAG 检索 + SQL 验证的技术方案,解决了上述痛点。
覆盖从知识准备到生产落地的全流程:
| 模块 | 核心内容 |
|---|---|
| NL2SQL | 自然语言转 SQL 的完整方案设计与落地实践 |
| RAG | 知识库管理、文档分块策略、向量化配置、混合检索(向量+关键词)、Rerank 重排序 |
| AI Agent | 智能体编排、Tool 工具调用、多阶段推理(ReAct 思考链)、提示词工程 |
| 可观测 | 全链路追踪、思考过程可视化、问题定位与迭代优化 |
四大模块环环相扣,形成**「数据准备 → 知识向量化 → RAG 检索 → Agent 推理 → 验证输出 → 观测优化」**的完整闭环。
一、系统架构概览
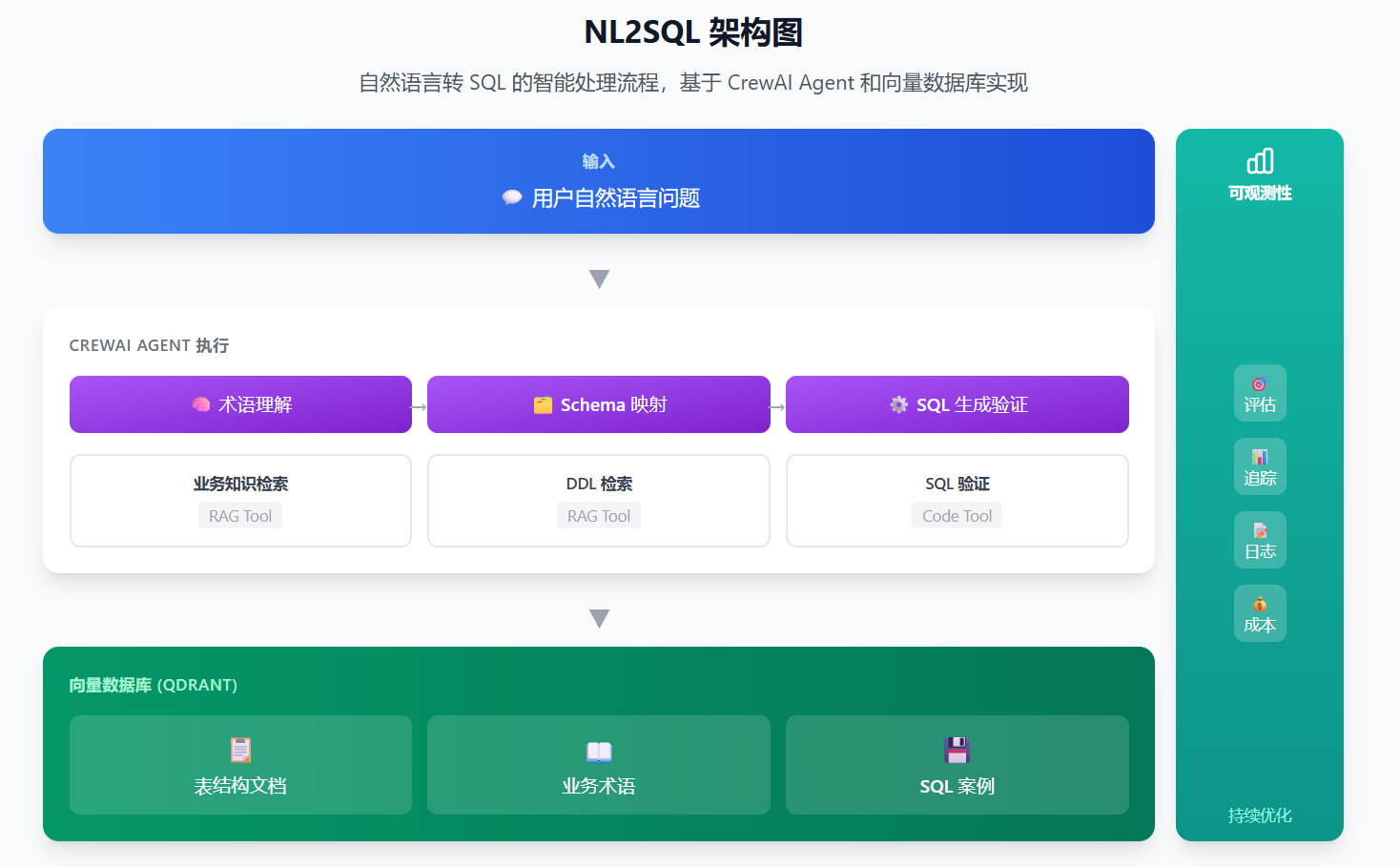
该系统采用 CrewAI 智能体 + RAG 检索 + SQL 验证 的三层架构,将自然语言问题转换为可执行的 SQL 查询。本模块的核心职责是生成 SQL,不负责具体执行,SQL 执行由可视化平台或调用方系统自行处理。
核心处理流程:
整个流程由 Agent 驱动——Agent 作为中枢,自主决策何时调用 RAG 检索获取上下文、何时调用验证工具检查语法,最终输出可执行的 SQL。
用户问题 → Agent 接收 → Agent 驱动 RAG 检索 → Agent 生成 SQL → Agent 驱动语法验证 → SQL 输出四个关键阶段(均由 Agent 自主驱动):
| 阶段 | 功能 | 依赖工具 |
|---|---|---|
| 术语理解 | 识别用户问题中的业务词汇(如「涨幅」「换手率」) | RAG Tool(业务知识检索) |
| Schema 映射 | 将业务概念映射到实际的表名和字段名 | RAG Tool(DDL 检索) |
| 示例参考 | 检索相似问题的 SQL 案例,作为 Few-Shot 参考 | RAG Tool(SQL 案例检索) |
| SQL 生成验证 | 生成 SQL 并验证语法正确性 | Code Tool(SQL 验证) |
向量数据库(Qdrant)存储内容:
- 表结构文档:DDL、字段注释、外键关系
- 业务术语:领域专有名词定义及计算公式
- SQL 案例:用于 Few-Shot 学习的问答对
设计要点:
- Agent 通过 RAG 检索获取上下文,而非依赖预训练知识
- 强制使用中文业务概念检索,禁止猜测英文表名
- SQL 生成后必须经过 sqlglot 语法验证才能输出
二、数据准备阶段
在使用 NL2SQL 之前,需要完成以下准备工作,将业务数据库的元信息转化为 Agent 可理解的知识:
流程说明:
- 建立数据连接:配置目标数据库的连接信息(主机、端口、用户名、密码),系统支持 MySQL、PostgreSQL 等主流数据库
- 获取 Schema 定义:连接数据库后,自动提取表结构(表名、字段名、字段类型、主外键关系等),生成 DDL 语句
- 构建 SQL 案例:编写典型查询的问答对(自然语言问题 + 对应 SQL,支持用户反馈结果加入案例),作为 Few-Shot 示例
- 发布到知识库:创建 NL2SQL 场景,将上述内容同步到向量知识库,供 Agent 检索使用
- 补充业务说明:为表和字段添加中文注释,解释业务含义——这是让大模型「听懂人话」的关键
数据准备的质量直接决定 SQL 生成的准确率。表注释越清晰、案例越丰富,Agent 的表现越好。
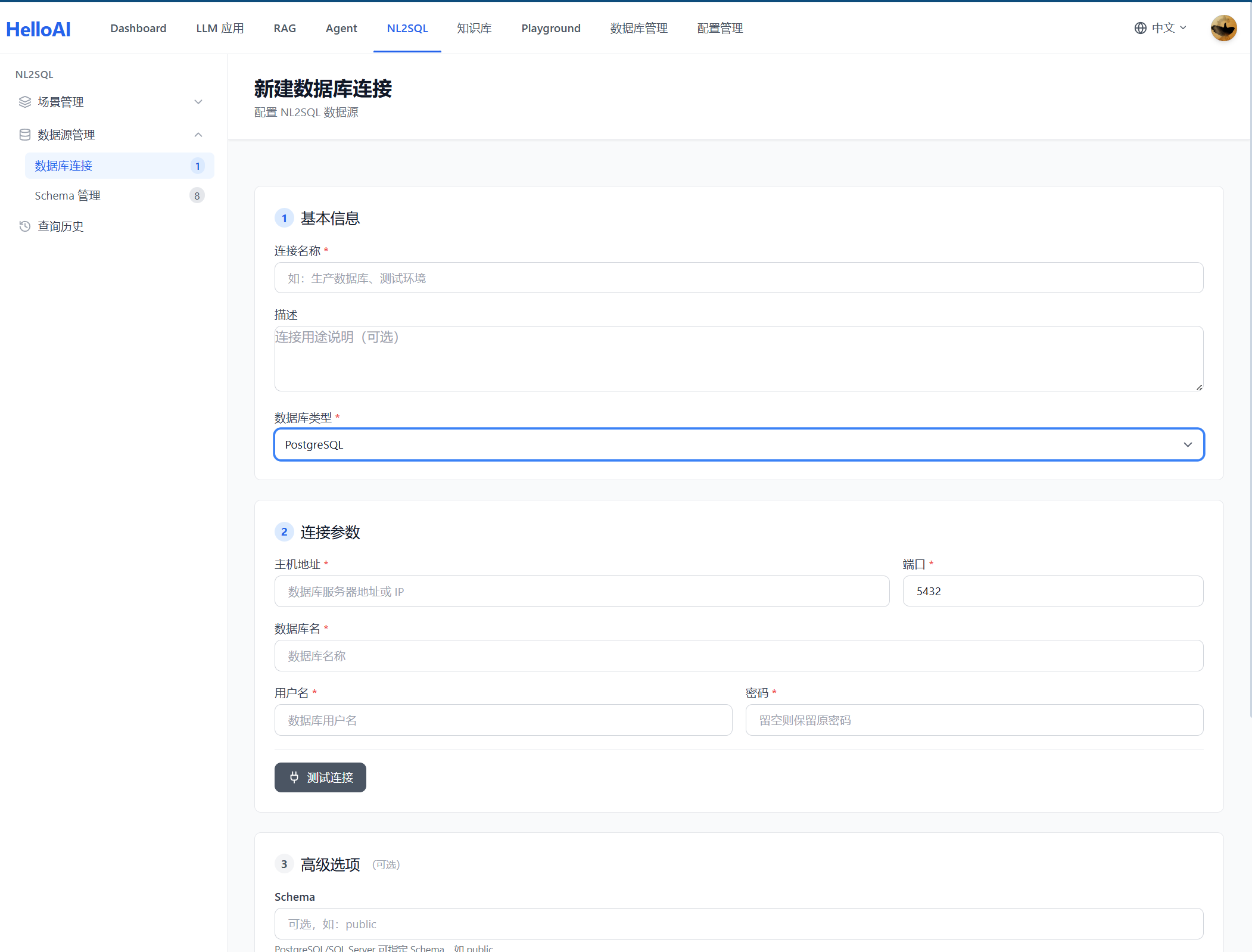
2.1 建立数据连接
首先需要建立与目标数据库的连接,配置连接参数(主机、端口、数据库名、用户名、密码)。系统支持 MySQL、PostgreSQL 等主流数据库。
2.2 获取 Schema 定义
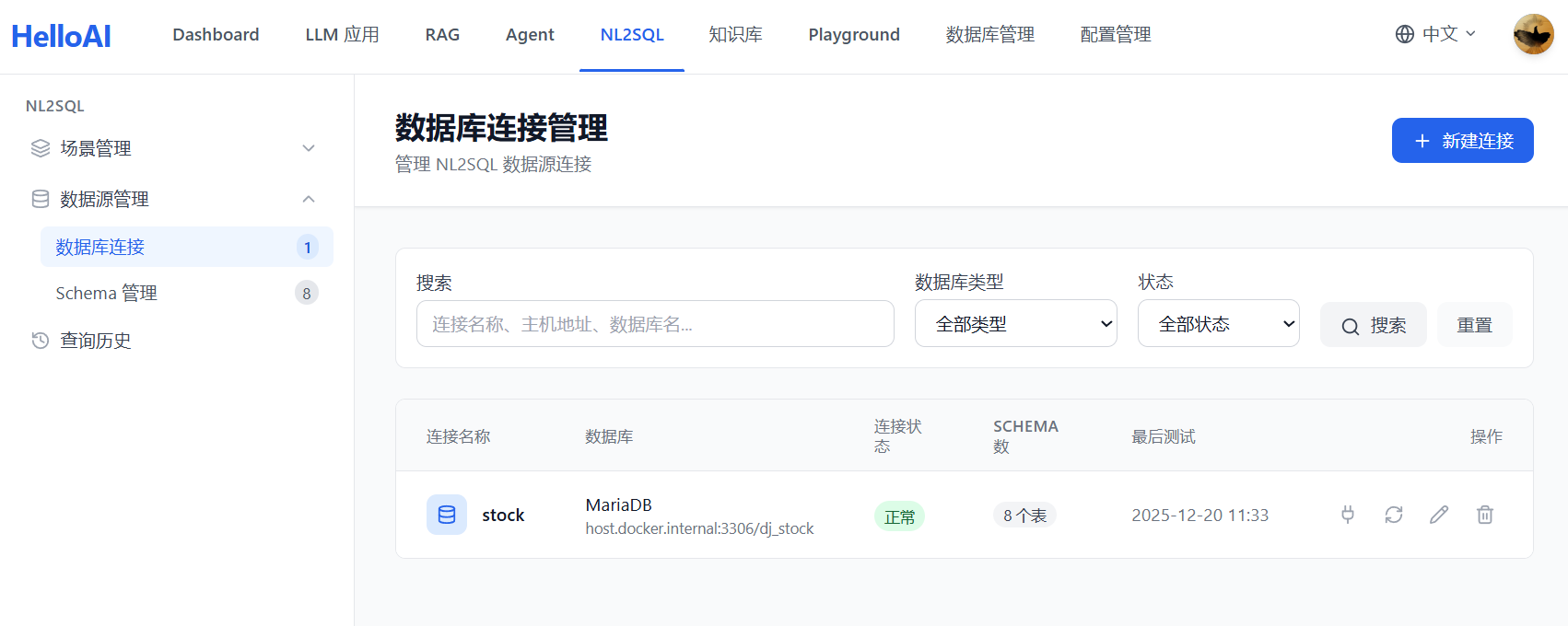
连接成功后,手动点击同步按钮完成数据库表及 DDL 的同步。系统会自动提取表结构信息,包括表名、字段定义、主外键关系等,并生成对应的 DDL 语句。
同步后的表信息如下所示,初始状态下表注释为空: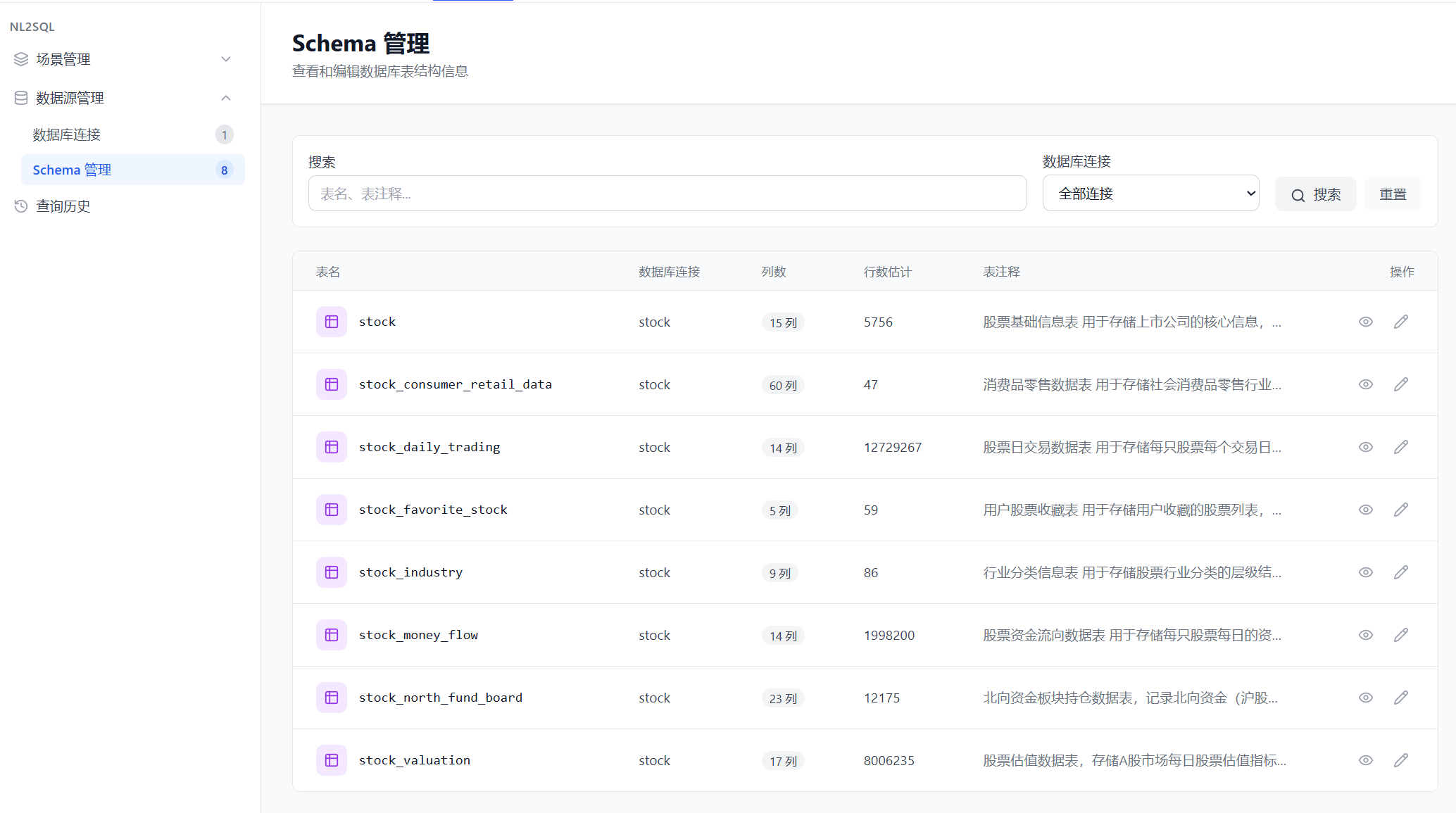
为表和字段添加中文注释,解释业务含义——这是让大模型「听懂人话」的关键。业务说明包括业务术语和业务规则两部分。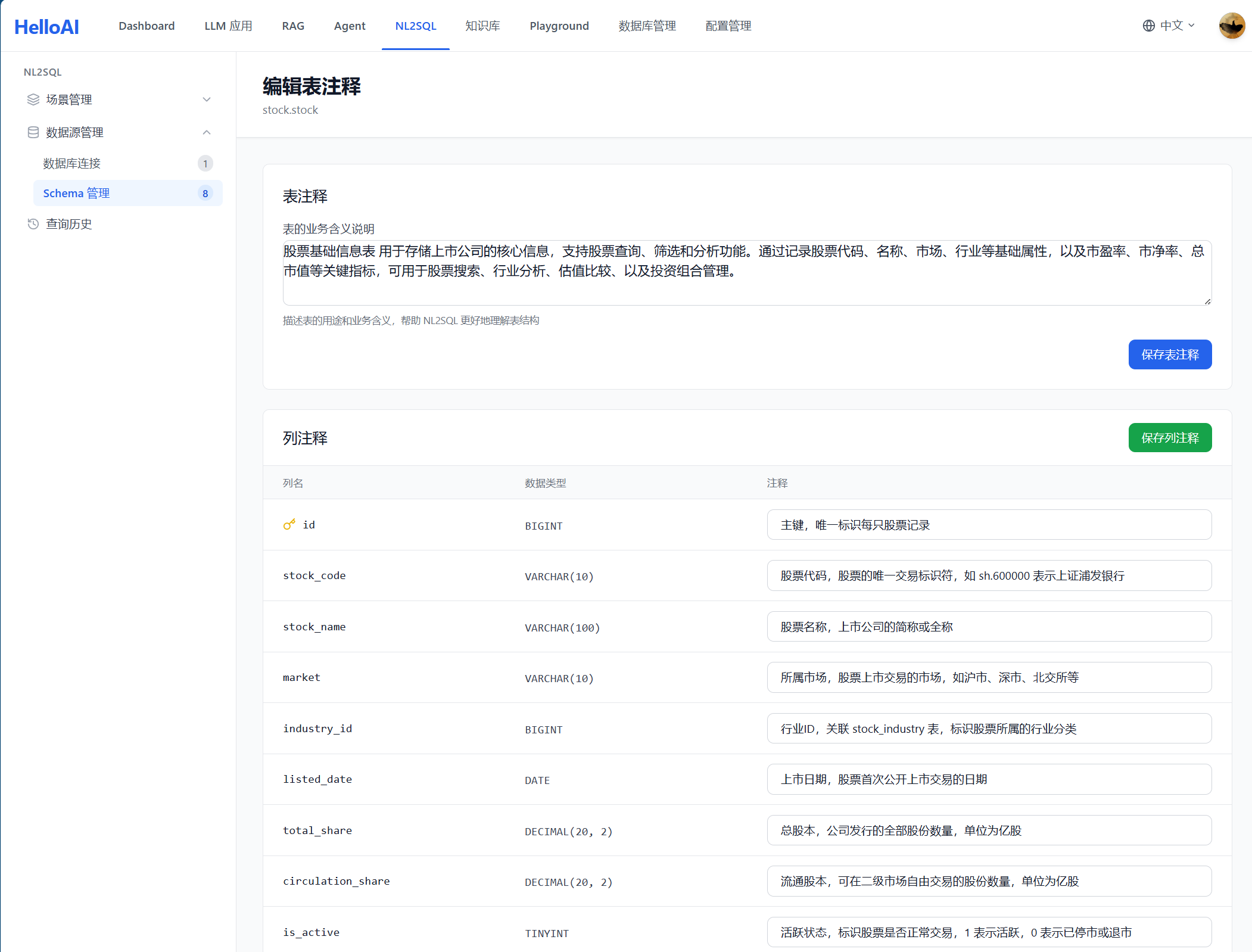
最佳实践:
- 表注释必须清晰:描述表的业务用途,如「股票日线行情数据,记录每个交易日的开盘价、收盘价、涨跌幅等」
- 列注释要详细:每个字段都应有业务含义说明
- 标注关键字段:主键、外键、常用查询字段
2.3 构建 SQL 案例
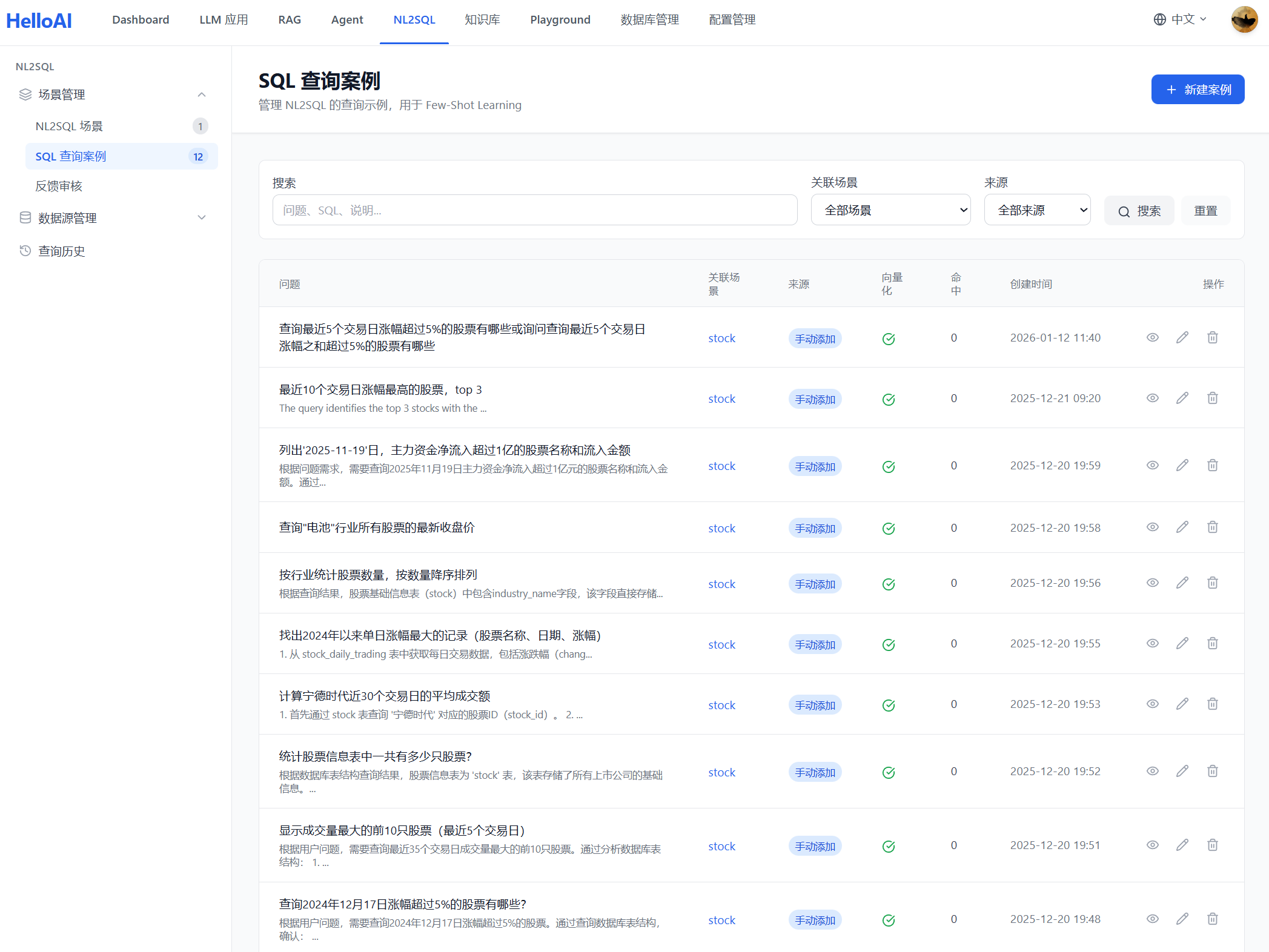
编写典型查询的问答对(自然语言问题 + 对应 SQL),作为 Few-Shot 示例。系统也支持将用户反馈的正确结果加入案例库,持续优化。
最佳实践:
- 覆盖常见查询类型:筛选、排序、聚合、关联等
- 包含复杂场景:多表关联、子查询、窗口函数等
- 问题描述多样化:同一查询用不同方式描述
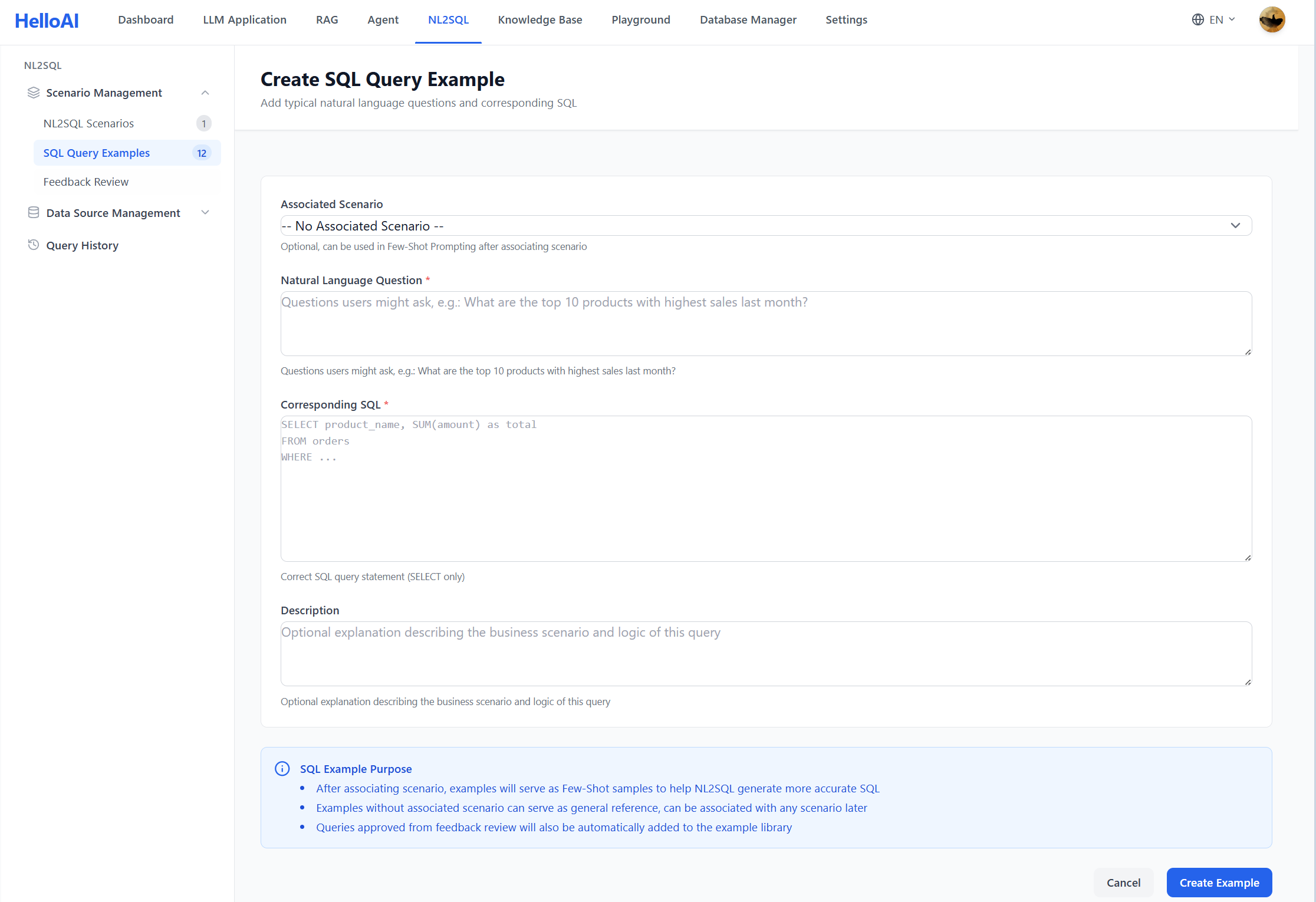
示例:
# 问题
查询今天涨幅超过 5% 的股票代码和名称
# SQL
SELECT s.stock_code, s.stock_name, d.pct_change
FROM stock_daily d
JOIN stock_basic s ON d.stock_code = s.stock_code
WHERE d.trade_date = CURDATE()
AND d.pct_change > 5
ORDER BY d.pct_change DESC
# 说明
1. 使用 stock_daily 表获取涨跌幅数据
2. 关联 stock_basic 表获取股票名称
3. 按涨幅降序排列2.4 发布到知识库
创建 NL2SQL 场景后,将上述内容(表结构、SQL 案例)同步到向量知识库,供 Agent 检索使用。
发布后的知识结构:
- 表结构文档:每个表生成独立的 Markdown 文档
- 业务知识文档:术语和规则合并为业务知识文档(注意发布后会在知识库中创建空白目录,后续可以补充)
- SQL 案例文档:每个案例生成独立的问答文档
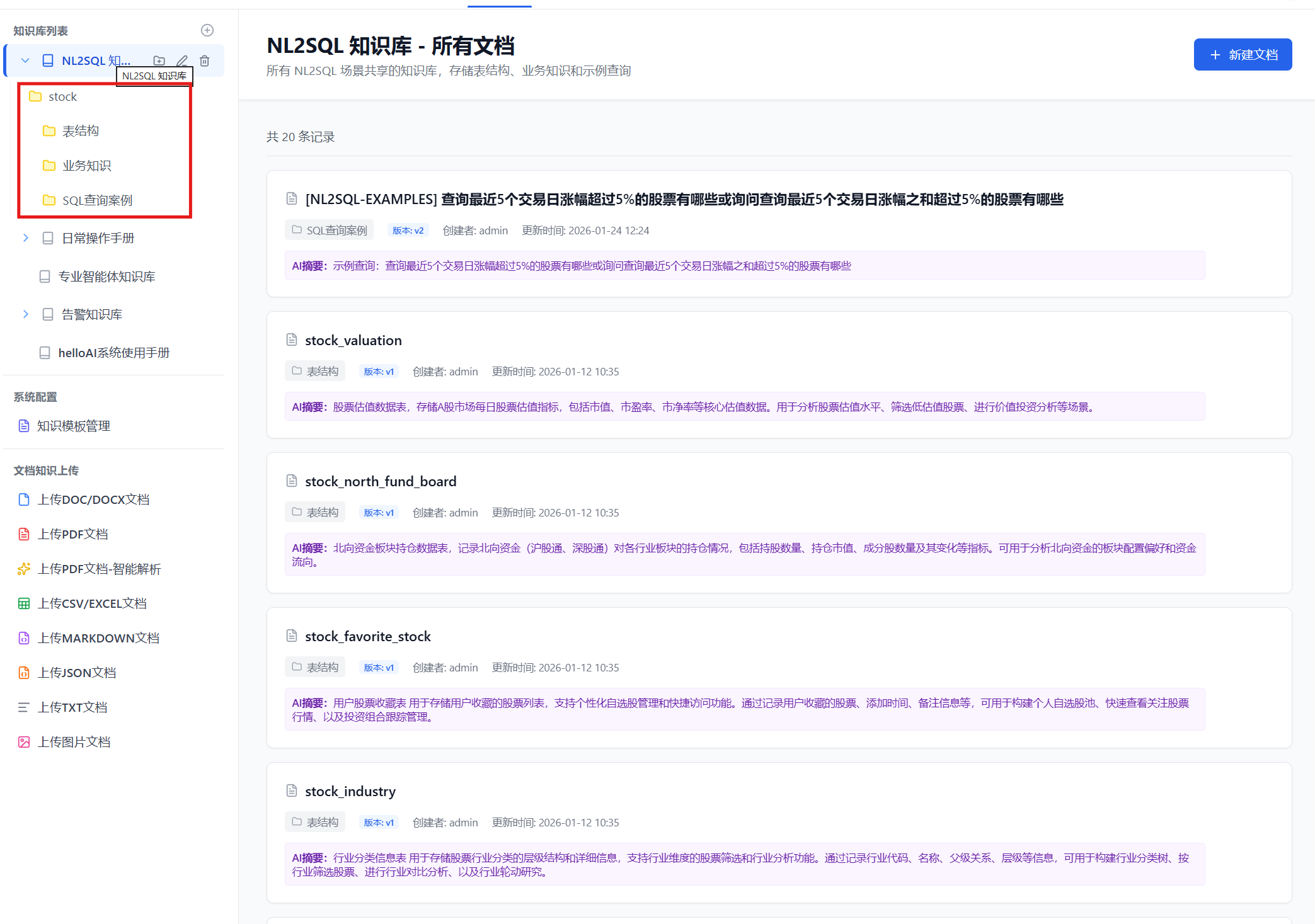
2.5 补充业务说明
补充业务说明时,需要进入 NL2SQL 场景对应的知识库目录,找到「业务知识」子目录,在其下直接创建文档即可。
业务术语及规则用于解释领域专有名词及数据查询聚合计算规则,帮助 Agent 理解用户问题中的专业词汇。
最佳实践:
- 涵盖常见业务词汇:涨幅、换手率、市盈率等
- 说明计算公式:如「涨幅 = (收盘价 - 前收盘价) / 前收盘价 × 100%」
- 关联数据字段:明确术语对应的表和字段
示例: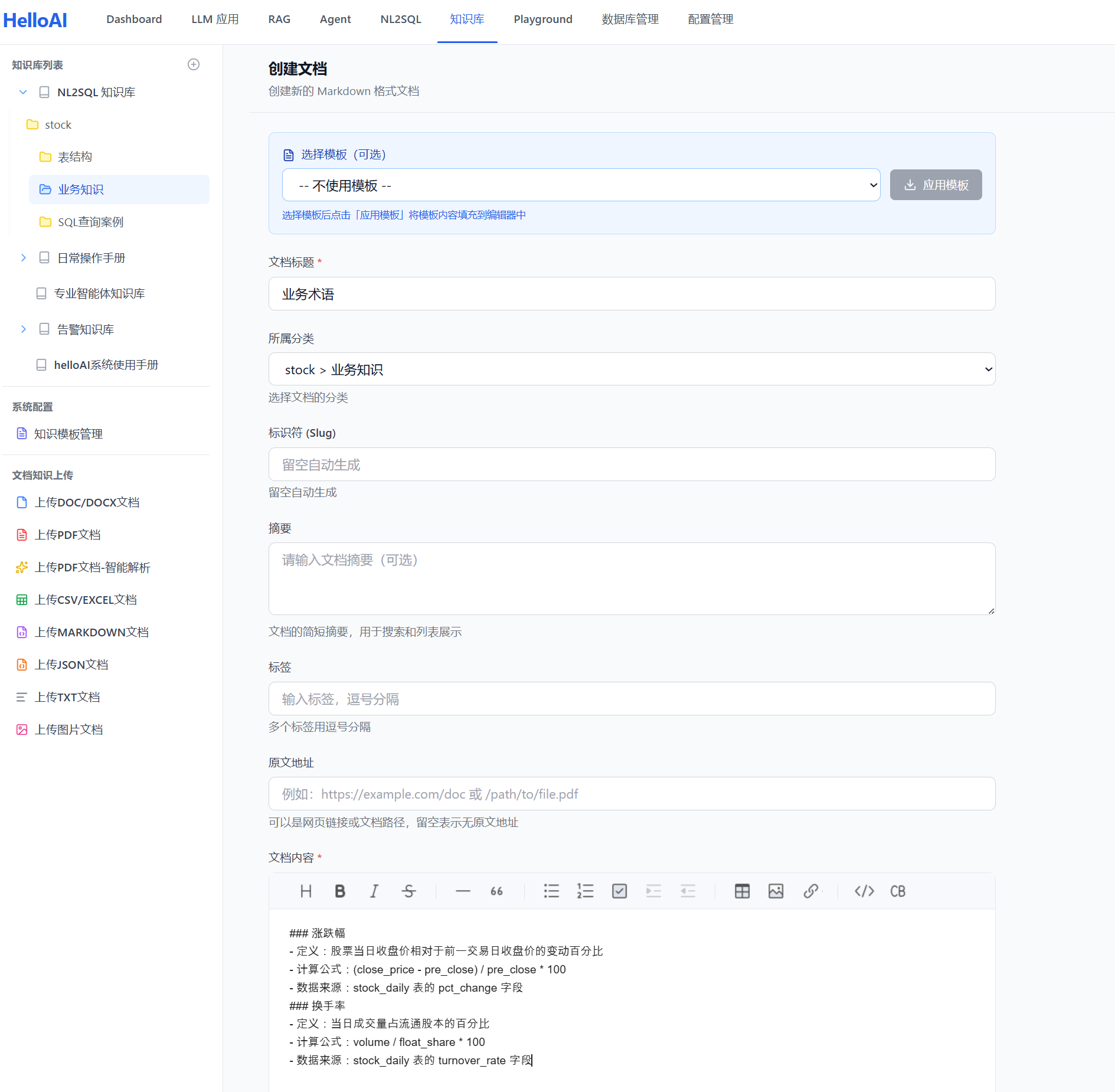
三、知识文档的向量化
NL2SQL 场景发布后,上述三类核心知识会同步到知识库中。接下来需要将文本知识向量化,存入向量数据库:
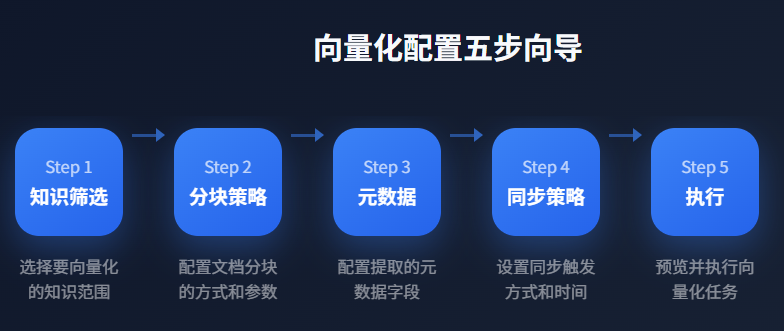
3.1 Step 1: Knowledge Filtering(知识筛选)
知识筛选用于确定哪些文档需要被向量化。
配置项: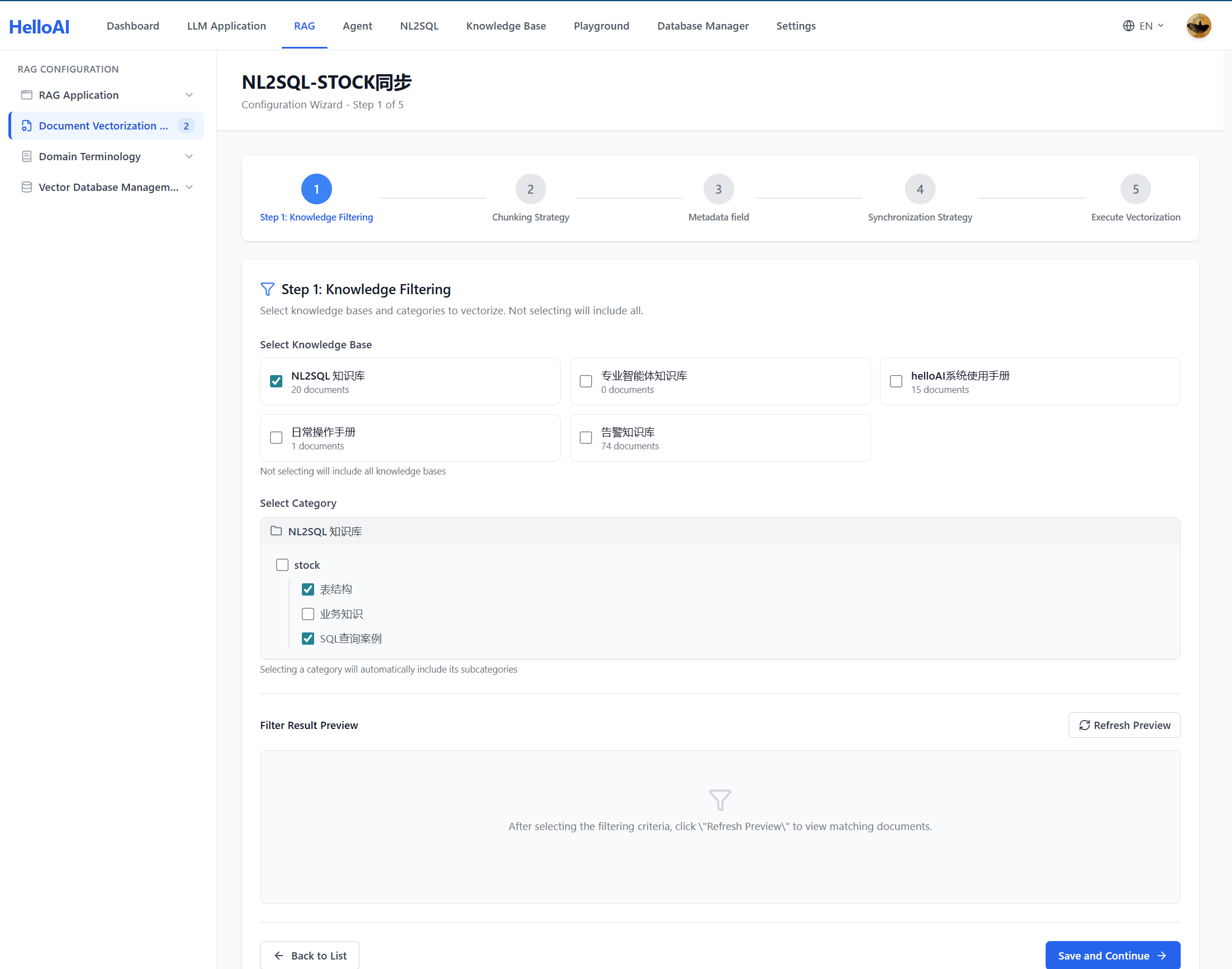
| 配置项 | 说明 | NL2SQL 场景建议 |
|---|---|---|
| 知识库 | 选择目标知识库 | 选择 NL2SQL 场景对应的知识库 |
| 分类范围 | 指定要包含的分类 | 包含「表结构」「业务知识」「SQL案例」三个分类 |
| 包含子分类 | 是否递归包含子分类 | 开启,确保所有子分类文档都被向量化 |
NL2SQL 知识结构:
NL2SQL 知识库
└── 场景分类(如:股票分析场景)
├── 表结构/ ← 必须包含:DDL、字段注释、外键关系
│ ├── stock_basic(股票基础信息表)
│ ├── stock_daily(股票日线数据表)
│ └── ...
├── 业务知识/ ← 必须包含:术语定义、计算公式、业务规则
│ ├── 业务术语(涨幅、换手率、市盈率等)
│ └── 业务规则(交易时间、涨跌停规则等)
└── SQL查询案例/ ← 必须包含:问答对、Few-Shot 示例
├── 查询涨幅超过5%的股票...
└── ...最佳实践:
- 确保三类知识都被选中,缺少任何一类都会影响 SQL 生成质量
- 表结构文档是基础,没有它 Agent 无法知道真实的表名和字段名
- 按文档特性分组筛选:不同特性的文档需要不同的分块策略,应创建多个向量化配置分别处理
按文档特性分组的策略:
知识筛选的核心原则是:将需要相同分块策略的文档放在一起。这样可以为每类文档配置最优的后续处理流程。
| 文档类型 | 典型特征 | 推荐筛选策略 | 后续分块建议 |
|---|---|---|---|
| 表结构 | 单表 DDL,500-2000 字 | 单独配置 | 不分块,保持完整 |
| SQL 案例 | 问答对,300-800 字 | 单独配置 | 不分块,整条保留 |
| 业务术语 | 短定义,100-300 字 | 可合并配置 | 按段落或不分块 |
| 业务规则 | 可能较长,1000+ 字 | 单独配置 | 按段落,chunk=800 |
| 操作手册 | 长文档,5000+ 字 | 单独配置 | 按标题,chunk=1000 |
关键理解:知识筛选不仅是「选什么」,更是「如何分组」。将特性相似的文档归为一组,才能在后续步骤中应用最合适的分块策略。
3.2 Step 2: Chunking Strategy(分块策略)
分块策略决定如何将文档切分为检索单元。对于 NL2SQL 场景,分块策略至关重要——分块过小会丢失上下文,分块过大会引入噪音。
可选的分块方式:
选择分块策略之后,可以即时查看分块结果: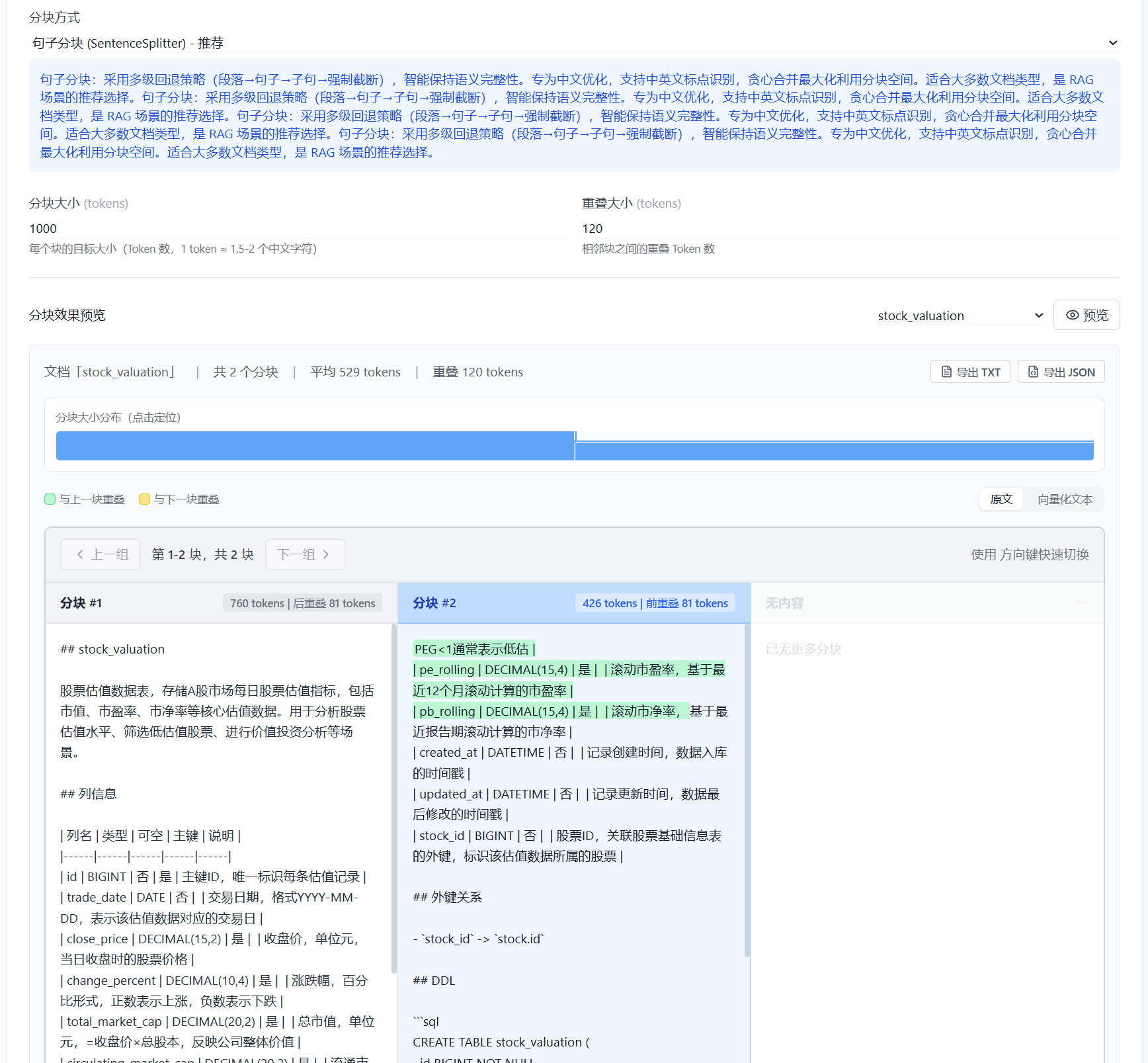
核心参数:
| 参数 | 说明 | NL2SQL 场景建议值 |
|---|---|---|
| chunk_size | 每个分块的最大 Token 数 | 800-1200(保持 DDL 完整性) |
| chunk_overlap | 相邻分块的重叠 Token 数 | 100-200(保持上下文连贯) |
| 分隔符 | 自定义分块边界 | \n##(按二级标题分块) |
NL2SQL 分块策略建议:

最佳实践:
- 表结构文档建议不分块或按表分块:一个表的 DDL 应保持完整,避免字段信息被切分到不同分块
- SQL 案例建议整条保留:问题、SQL、说明应在同一个分块中,便于 Few-Shot 学习
- 业务术语可适当分块:每个术语定义相对独立,可以较小粒度分块
3.3 Step 3: Metadata Field(元数据字段)
元数据是附加在每个向量分块上的结构化信息,主要服务于 RAG 检索过程。通过元数据,检索引擎可以实现条件筛选、结果关联和精准定位,支撑复杂业务场景下的高效检索。
配置界面左侧展示向量化过程中自动存储的 Metadata 字段,右侧配置可选的增强功能。
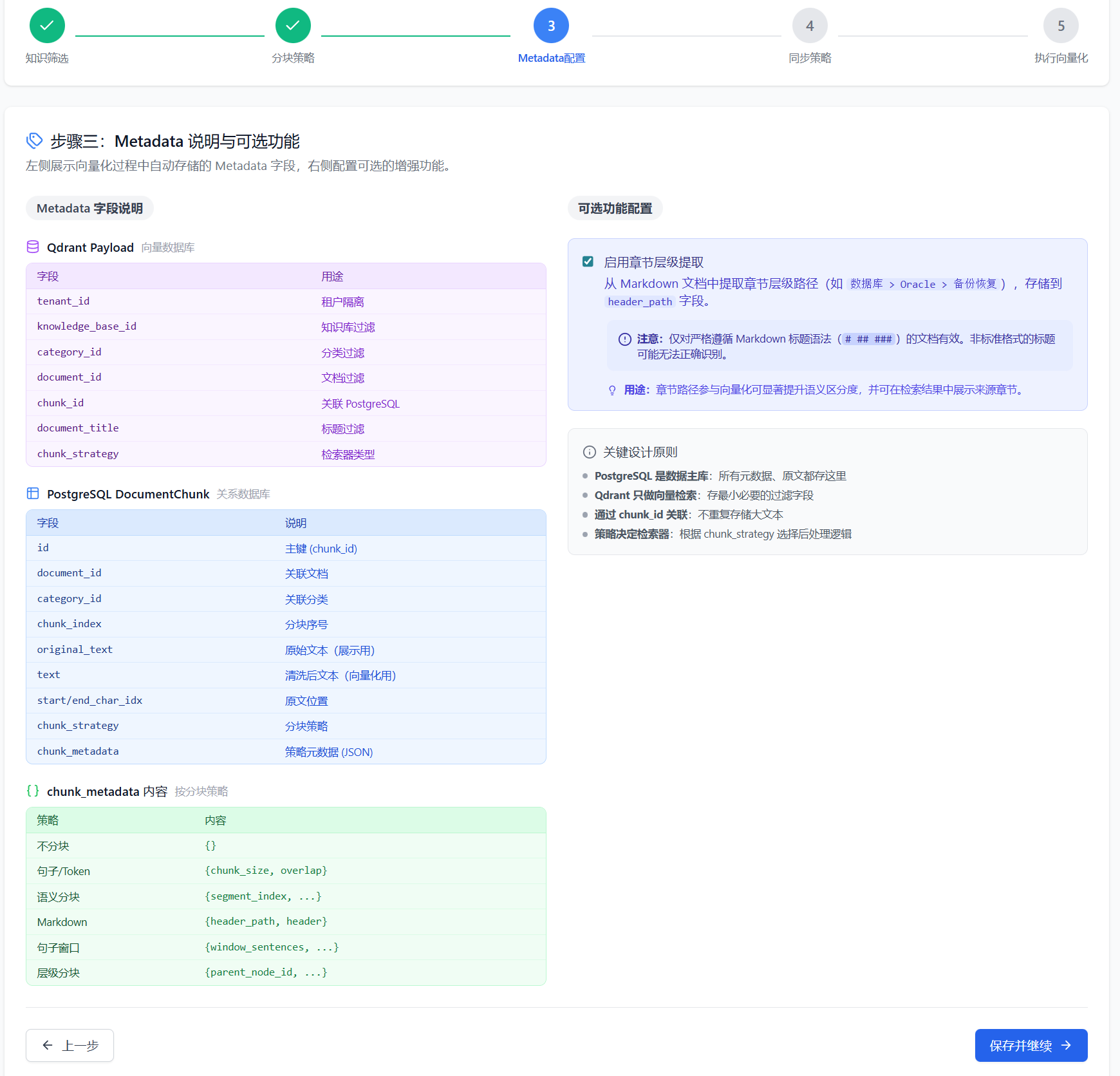
自动存储的 Metadata 字段
系统采用双存储架构:Qdrant 负责向量检索,PostgreSQL 存储完整元数据。
Qdrant Payload(向量数据库):
| 字段 | 用途 |
|---|---|
tenant_id |
租户隔离 |
knowledge_base_id |
知识库过滤 |
category_id |
分类过滤 |
document_id |
文档过滤 |
chunk_id |
关联 PostgreSQL |
document_title |
标题过滤 |
chunk_strategy |
检索器类型 |
PostgreSQL DocumentChunk(关系数据库):
| 字段 | 说明 |
|---|---|
id |
主键(chunk_id) |
document_id |
关联文档 |
category_id |
关联分类 |
chunk_index |
分块序号 |
original_text |
原始文本(展示用) |
text |
清洗后文本(向量化用) |
start/end_char_idx |
原文位置 |
chunk_strategy |
分块策略 |
chunk_metadata |
策略元数据(JSON) |
可选功能配置
启用章节层级提取:从 Markdown 文档中提取章节层级路径(如 数据库 > Oracle > 备份恢复),存储到 header_path 字段。
注意:仅对严格遵循 Markdown 标题语法(
######)的文档有效。非标准格式的标题可能无法正确识别。
用途:章节路径参与向量化可显著提升语义区分度,并可在检索结果中展示来源章节。
关键设计原则
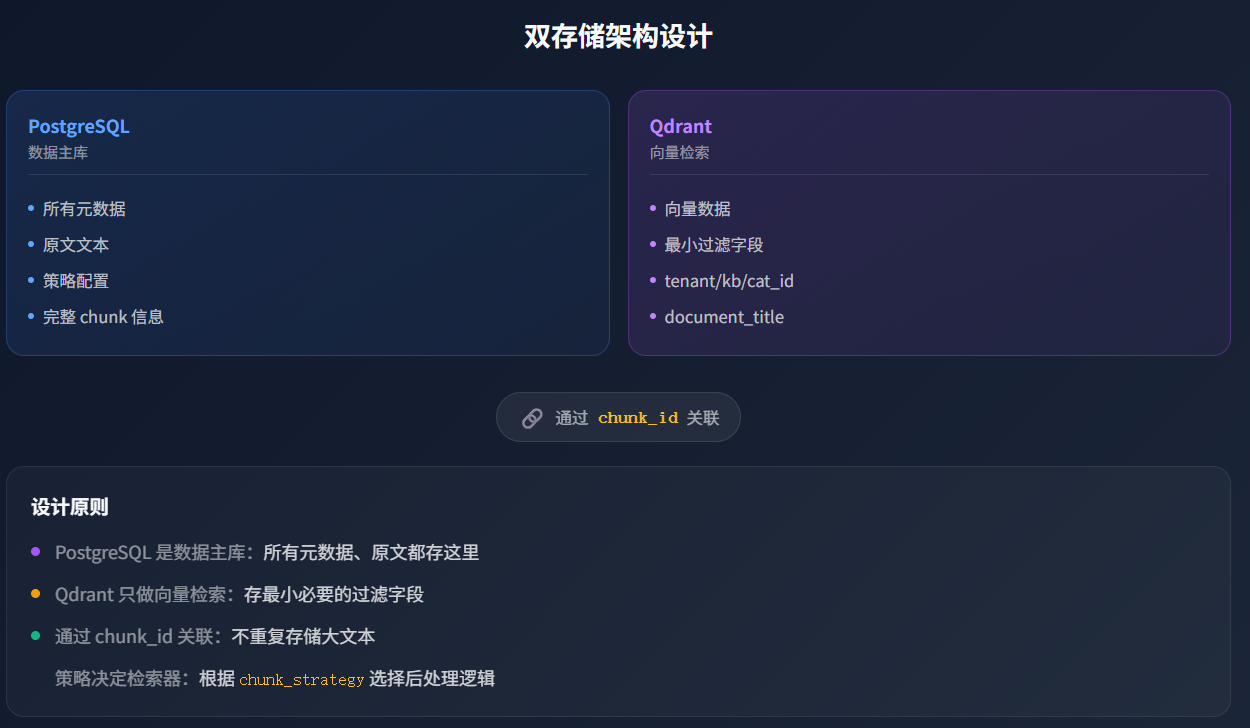
说明:上述 Metadata 字段已在系统中针对各种场景预配置好,此界面仅展示配置结果,无须单独配置。
3.4 Step 4: Synchronization Strategy(同步策略)
同步策略决定何时触发向量化更新,确保向量库与知识库保持一致。
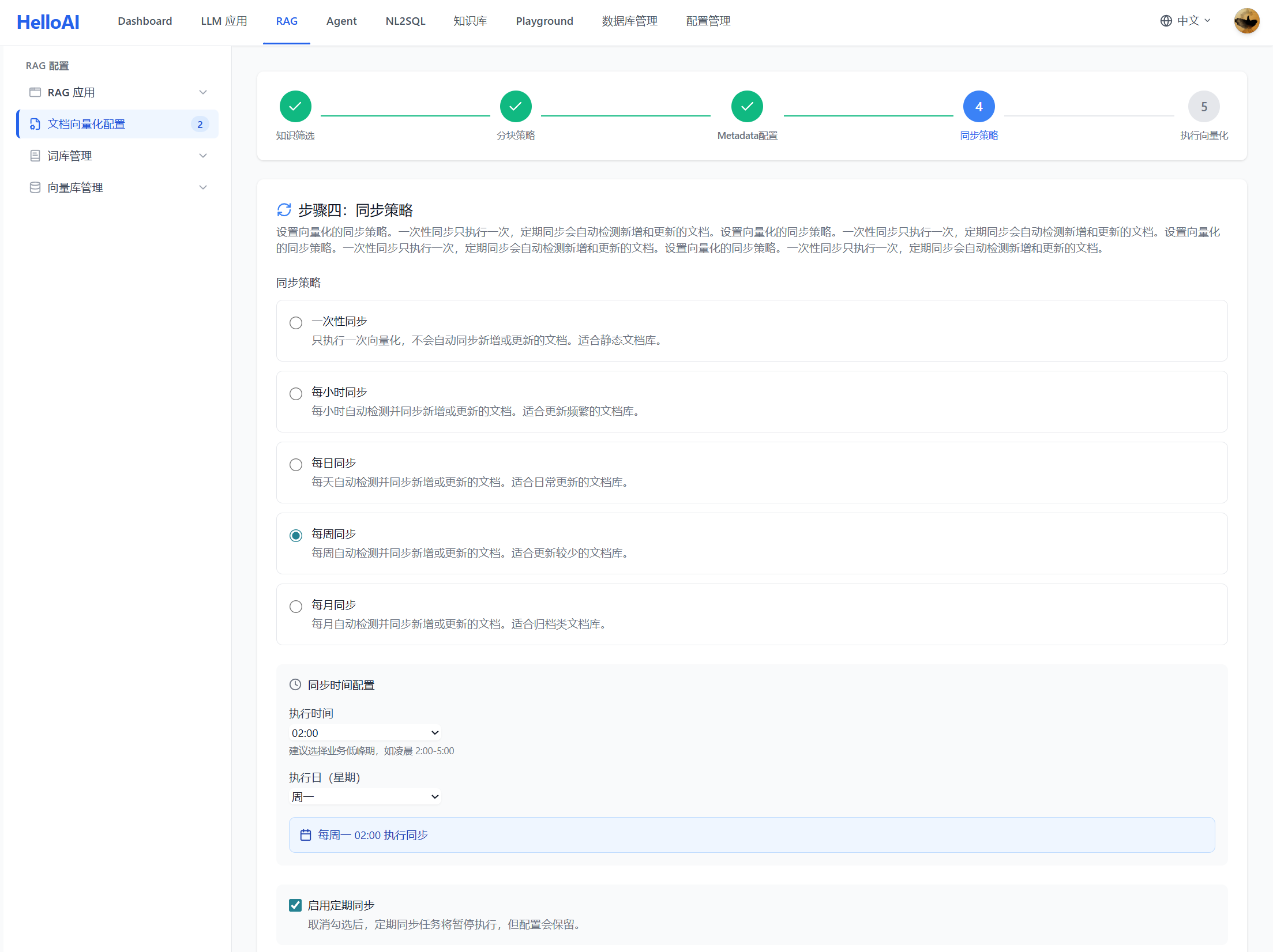
同步方式:
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 一次性 | 仅执行一次向量化 | 初始化、测试环境 |
| 定时同步 | 按 Cron 表达式定期执行 | 生产环境、知识频繁更新 |
| 手动触发 | 手动点击执行 | 临时更新、紧急修复 |
NL2SQL 场景建议:
| 阶段 | 建议配置 | 原因 |
|---|---|---|
| 开发调试 | 一次性/手动触发 | 快速迭代,按需更新 |
| 生产初期 | 每天凌晨同步 | 平衡实时性和性能 |
| 稳定运行 | 每周同步 + 手动触发 | 表结构变更不频繁时 |
最佳实践:
- 表结构变更后必须重新向量化:否则 Agent 会检索到过期的表结构
- 新增 SQL 案例后及时同步:让新案例尽快生效
- 避免在业务高峰期执行:向量化会消耗计算资源
3.5 Step 5: Execute Vectorization(执行向量化)
最后一步是预览配置并执行向量化任务。
预览信息:
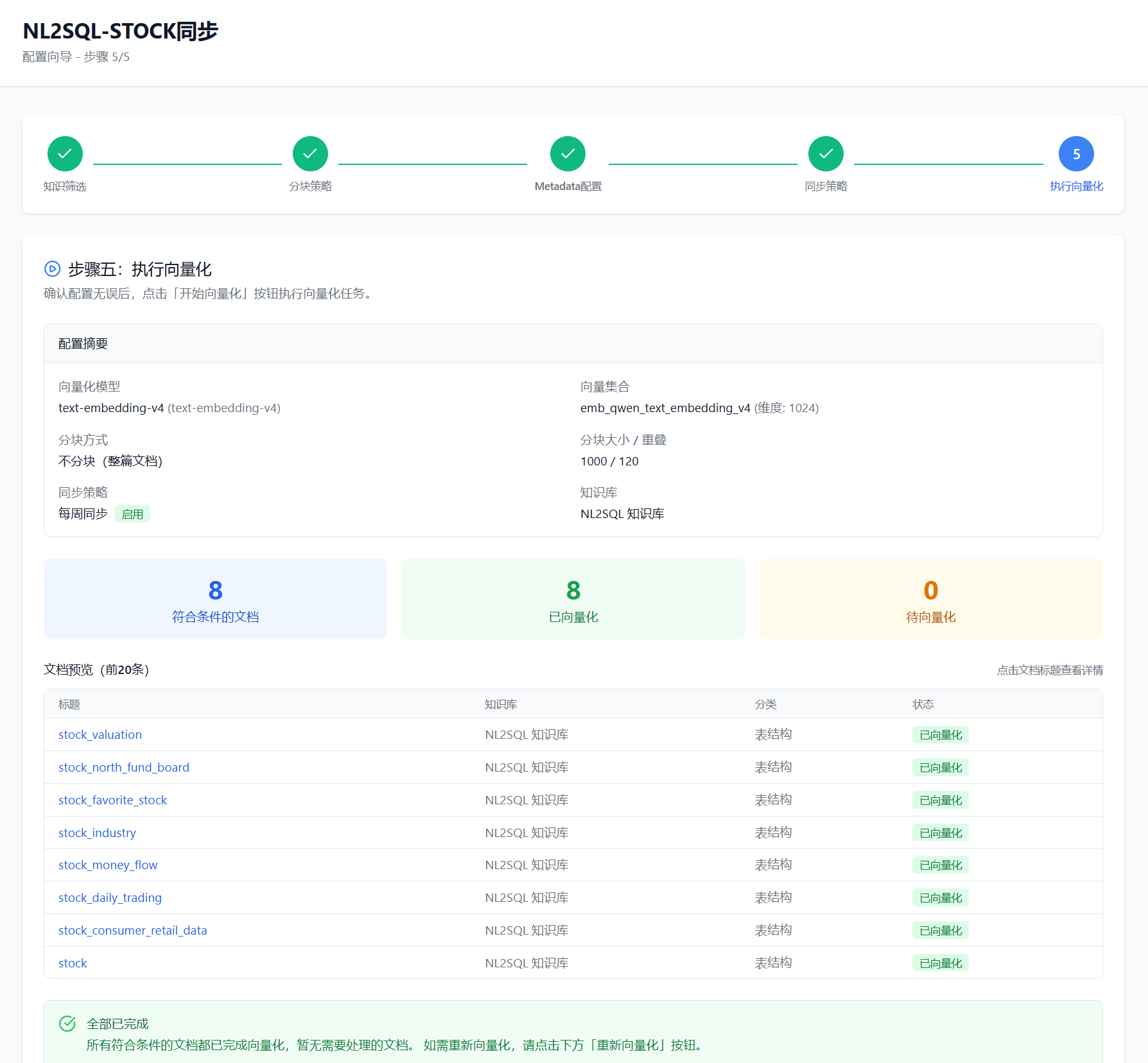
执行过程:
1. 清理旧向量 → 删除该配置之前生成的向量数据
2. 加载文档 → 从知识库读取选中的文档
3. 文档分块 → 按配置的策略切分文档
4. 提取元数据 → 为每个分块提取配置的元数据
5. 生成向量 → 调用 Embedding 模型生成向量
6. 存入 Qdrant → 将向量和元数据存入向量数据库
7. 更新状态 → 记录向量化完成时间和统计信息最佳实践:
- 首次执行前检查文档质量:向量化前确保文档内容完整、格式规范
- 关注预估 Token 消耗:Embedding 调用会产生费用
- 执行后验证检索效果:用典型问题测试检索结果是否符合预期
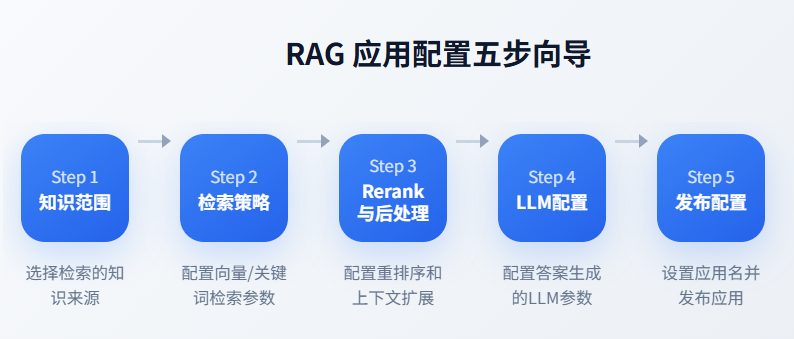
四、构建场景化的向量检索
完成知识向量化后,需要创建 RAG 应用来配置检索策略。helloAI 提供五步向导完成 RAG 应用配置:
4.1 Step 1: 知识范围
知识范围决定 RAG 应用从哪些向量化配置中检索内容。这是保障检索质量的第一道防线。
为什么要限定知识范围?
企业知识库可能包含数百万文档,但 RAG 检索的最佳实践不是从一个巨大的向量库中检索,而是根据场景锁定文档范围:
| 方式 | 检索质量 | 问题 |
|---|---|---|
| ❌ 全量检索 | 低 | 无关内容干扰、召回精度下降、响应变慢 |
| ✅ 场景化检索 | 高 | 范围明确、噪音少、召回精准 |

配置方式:
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 选择向量化配置 | 直接关联已创建的向量化配置 | 推荐,范围明确可控 |
| 指定知识库/分类 | 手动指定知识库和分类范围 | 灵活,可跨配置组合 |
场景化设计原则:
| 原则 | 说明 | 示例 |
|---|---|---|
| 一场景一应用 | 每个业务场景创建独立的 RAG 应用 | 股票分析、订单查询、用户管理各一个 |
| 范围最小化 | 只纳入该场景必需的知识 | 股票场景不需要 HR 制度文档 |
| 知识类型匹配 | 同类知识放在同一个向量化配置 | 表结构、SQL案例、业务术语分开配置 |
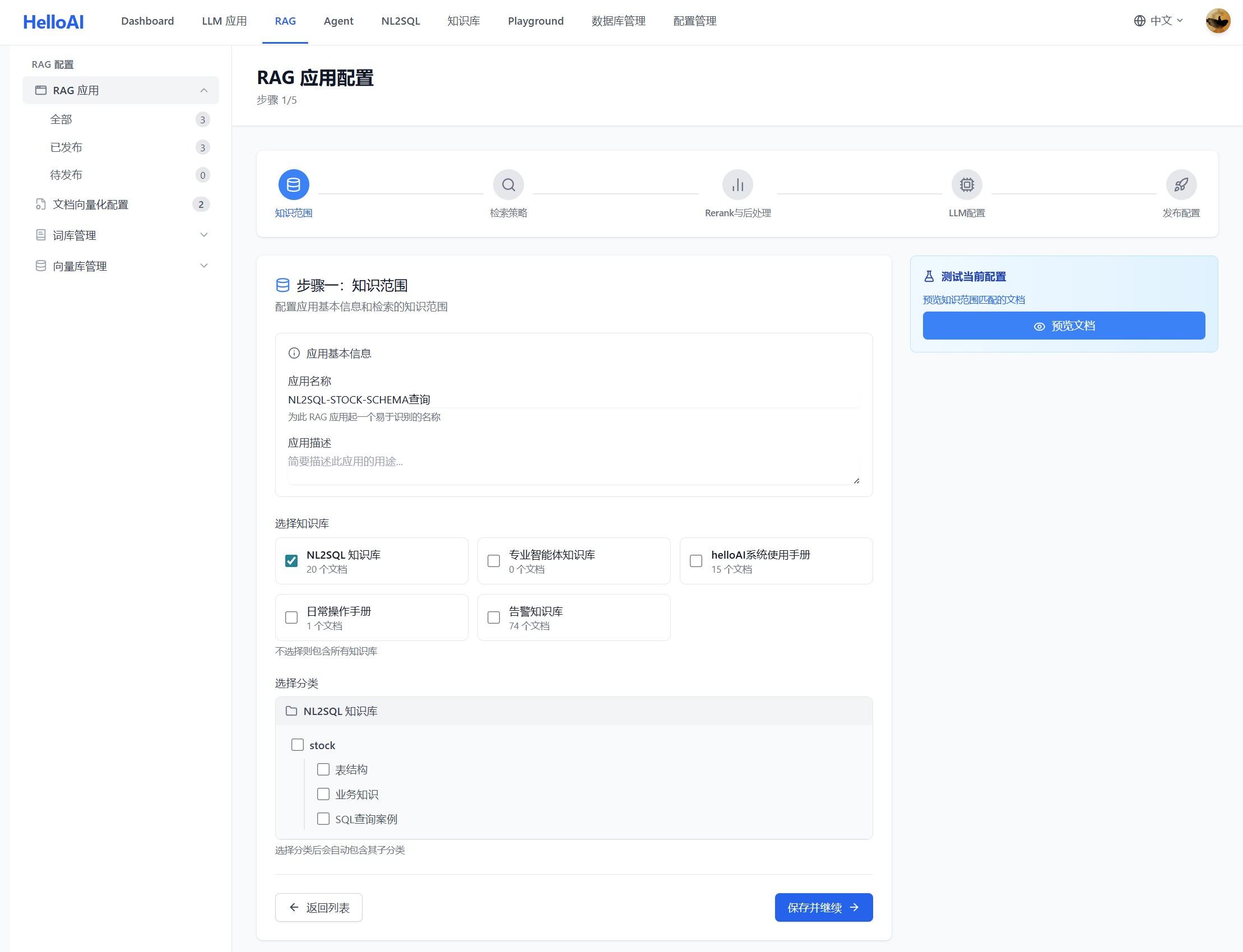
NL2SQL 场景配置示例:
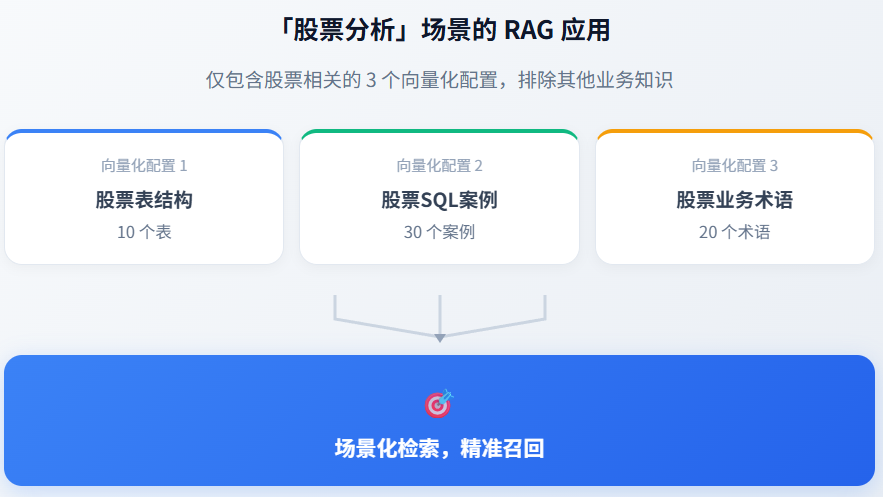
最佳实践:
- 严格限定范围:只纳入当前场景必需的向量化配置,宁少勿多
- 按场景拆分:不同业务场景(股票、订单、用户)创建独立的 RAG 应用
- 定期审查:业务变化时及时调整知识范围,移除不再需要的配置
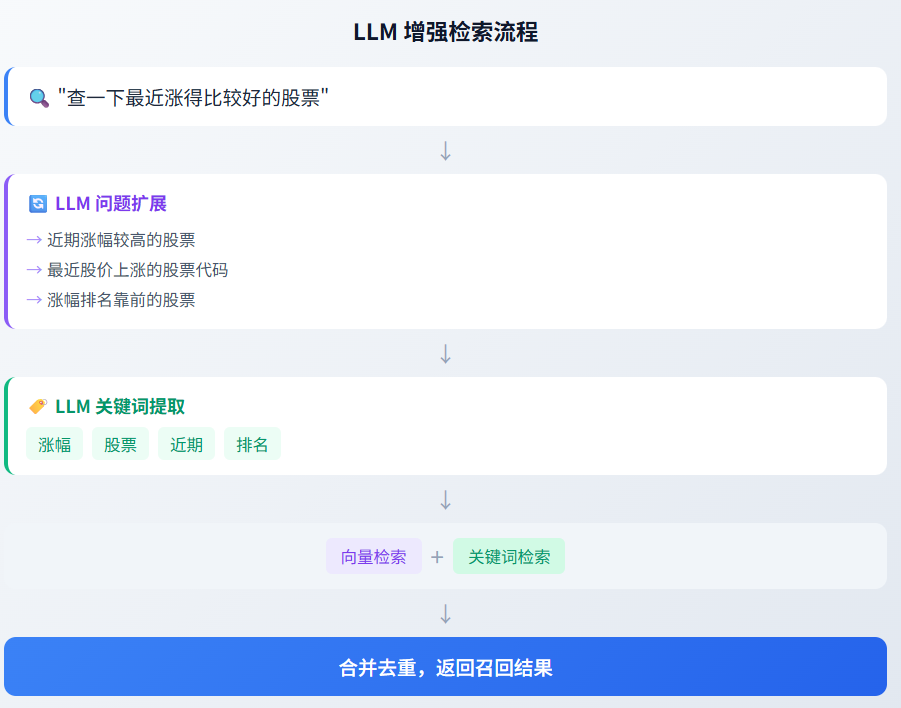
4.2 Step 2: 检索策略
检索策略决定如何从向量库中召回相关内容,是 RAG 效果的核心。
检索方式:
| 方式 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| 向量检索 | 基于语义相似度匹配 | 理解语义,召回相关内容 | 可能漏掉精确匹配 |
| 关键词检索 | 基于 BM25 关键词匹配 | 精确匹配专有名词 | 无法理解同义词 |
| 混合检索 | 向量 + 关键词加权融合 | 兼顾语义和精确匹配 | 需要调参 |
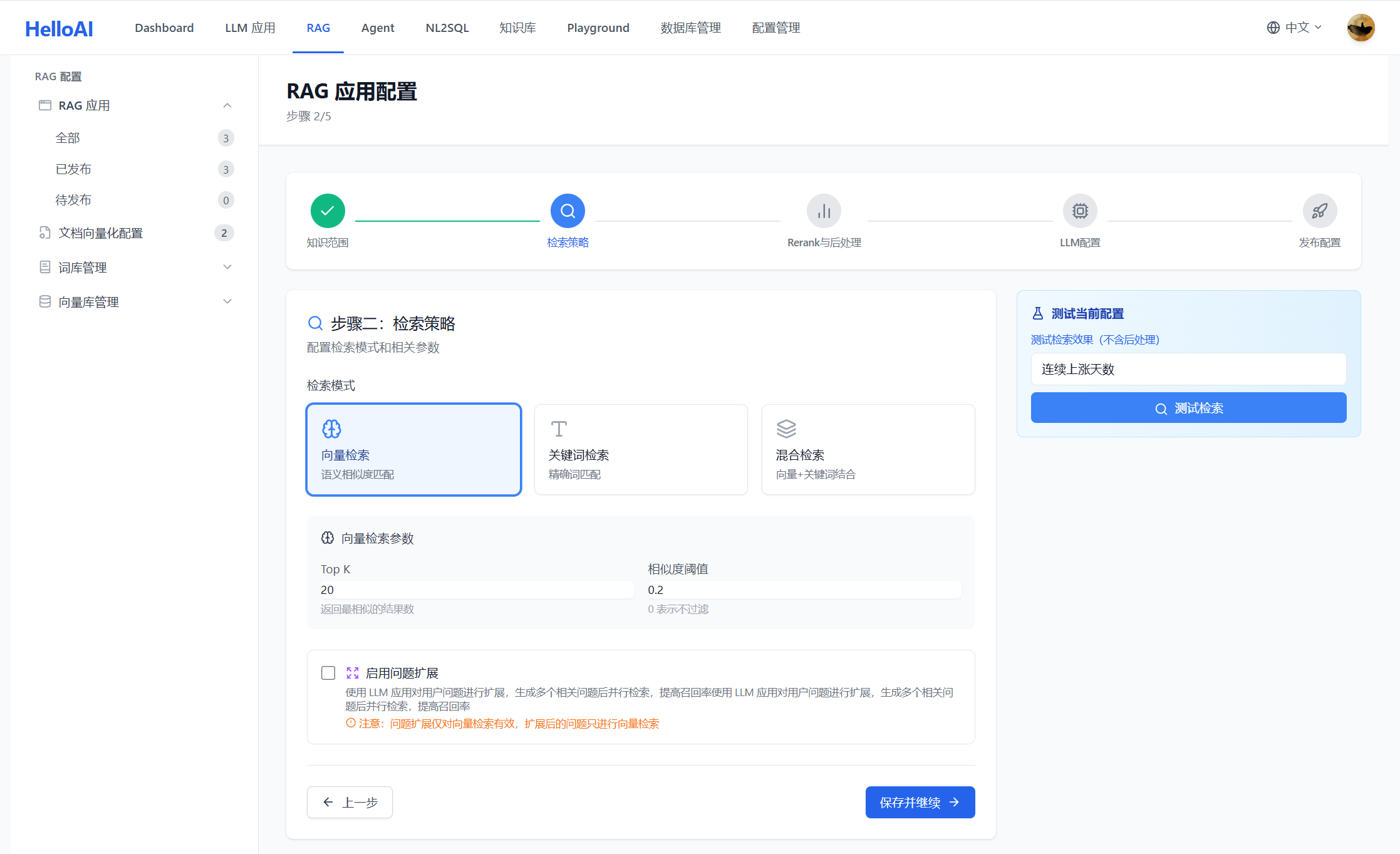
LLM 增强功能:
系统支持使用 LLM 对检索过程进行增强,提升召回质量:
| 功能 | 说明 | 适用场景 |
|---|---|---|
| 问题扩展(Query Expansion) | LLM 将用户问题改写为多个语义相近的查询,扩大召回范围 | 用户问题表述不清或过于简短 |
| 关键词提取(Keyword Extraction) | LLM 从用户问题中提取关键词,用于关键词检索 | 关键词检索或混合检索模式 |
注意:LLM 增强会增加一次 LLM 调用,带来额外延迟和成本。建议在用户问题质量较差或召回效果不理想时启用。
核心参数:
| 参数 | 说明 | NL2SQL 建议值 |
|---|---|---|
top_k |
召回数量 | 5-10(表结构)、3-5(SQL案例) |
similarity_threshold |
相似度阈值 | 0.5-0.7(过滤低相关结果) |
vector_weight |
向量检索权重(混合模式) | 0.7(语义为主) |
keyword_weight |
关键词权重(混合模式) | 0.3(精确匹配补充) |
NL2SQL 检索策略建议:
检索场景 推荐策略 top_k threshold 说明
─────────────────────────────────────────────────────────────────────
表结构检索 混合检索 5-10 0.5 需要精确匹配表名
SQL 案例检索 向量检索 3-5 0.6 语义理解为主
业务术语检索 向量检索 3-5 0.6 理解业务概念最佳实践:
- NL2SQL 推荐混合检索:表名、字段名是专有名词,需要关键词精确匹配
- top_k 不宜过大:召回太多会引入噪音,增加 LLM 处理负担
- 阈值按场景调整:宁可漏召回,不可错召回(错误的表结构危害更大)
4.3 Step 3: Rerank 与后处理
召回结果需要经过重排序和后处理,提升最终送入 LLM 的上下文质量。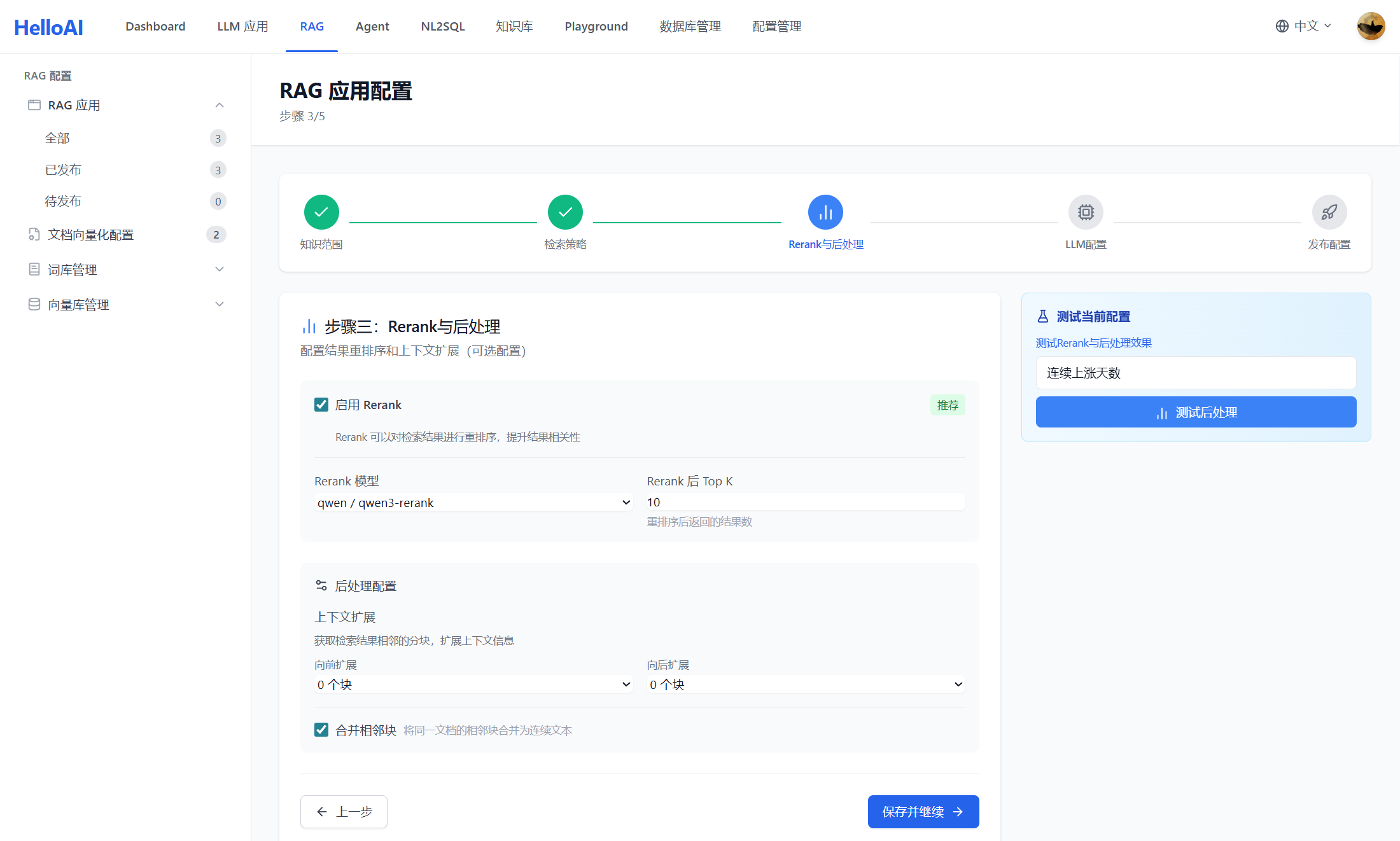
Rerank(重排序):
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 不启用 | 直接使用召回顺序 | 召回量小、质量高 |
| Cross-Encoder | 使用重排序模型精排 | 召回量大、需要精选 |
| LLM Rerank | 使用 LLM 判断相关性 | 高精度要求 |
后处理选项:
| 功能 | 说明 | NL2SQL 建议 |
|---|---|---|
| 上下文扩展 | 检索到某分块后,自动扩展其前后分块(适用手册类文档,某知识点可能跨多分块的情况) | 开启(获取完整表结构) |
| 去重合并 | 合并重复或高度相似的分块 | 开启(避免重复内容) |
| 来源标注 | 在结果中标注来源文档和章节 | 开启(便于溯源) |
最佳实践:
- NL2SQL 场景通常不需要上下文扩展:若每个表作为独立知识点,无需扩展上下文
- Rerank 按需启用:如果 top_k 较小且召回质量高,可不启用
- 去重很重要:同一表可能被多次召回,需要合并
4.4 Step 4: LLM 配置
LLM 配置决定如何基于检索结果生成最终答案(对于 NL2SQL 场景,这一步通常由 Agent 处理,RAG 仅返回检索结果)。
配置项:
| 配置项 | 说明 | NL2SQL 建议 |
|---|---|---|
| 是否启用 LLM 生成 | 是否调用 LLM 生成答案 | 关闭(Agent 自行处理) |
| LLM 应用 | 选择用于生成答案的 LLM 应用 | - |
| Prompt 模板 | 答案生成的提示词模板 | - |
| 最大 Token | 生成答案的最大长度 | - |
NL2SQL 场景说明:

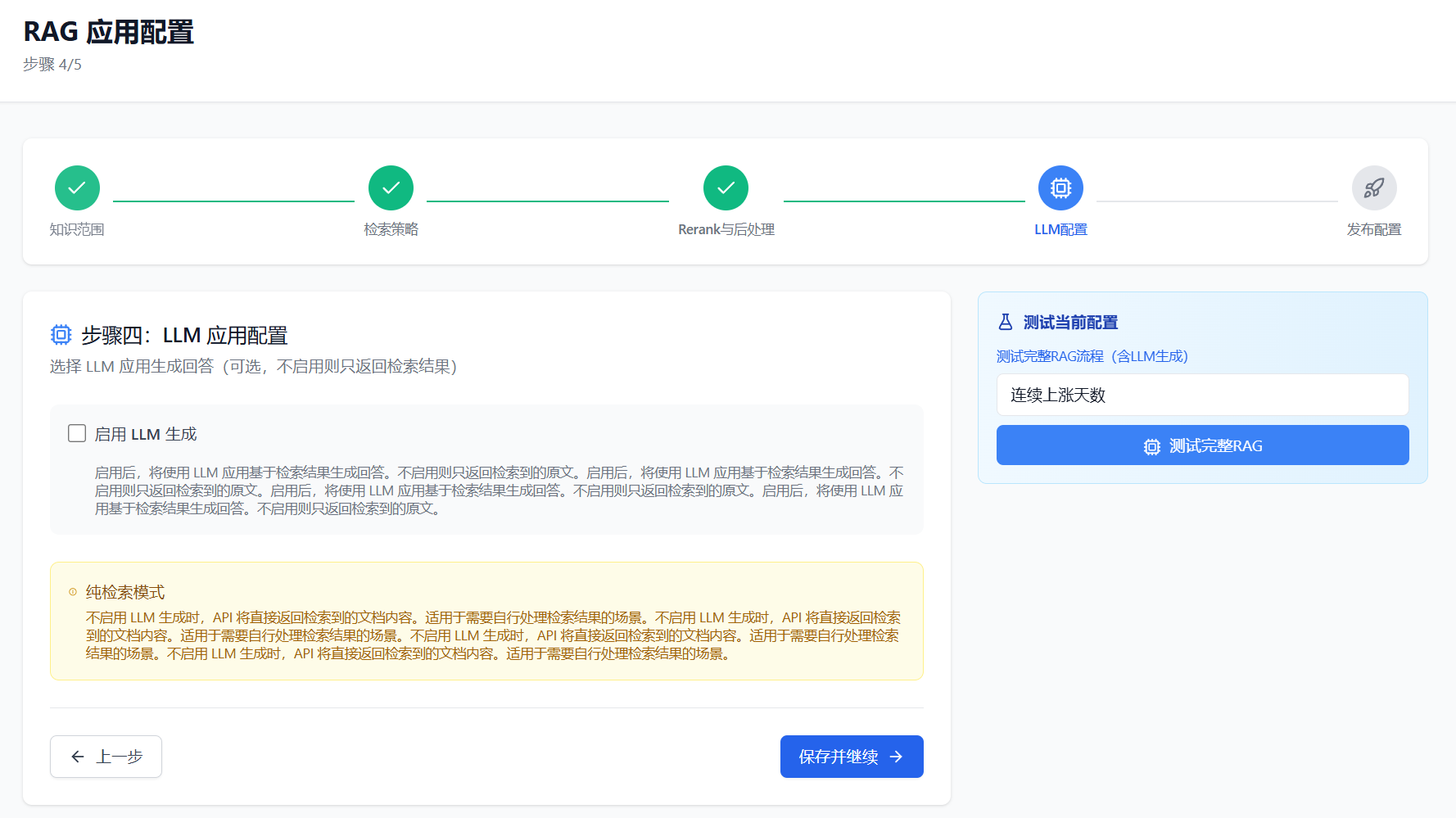
说明:NL2SQL 场景中,RAG 应用作为 Agent 的工具使用,仅负责检索相关知识,SQL 生成由 Agent 完成。因此 LLM 配置通常保持关闭。
4.5 Step 5: 发布配置
最后一步是设置应用名称并发布,使 RAG 应用可被 Agent 调用。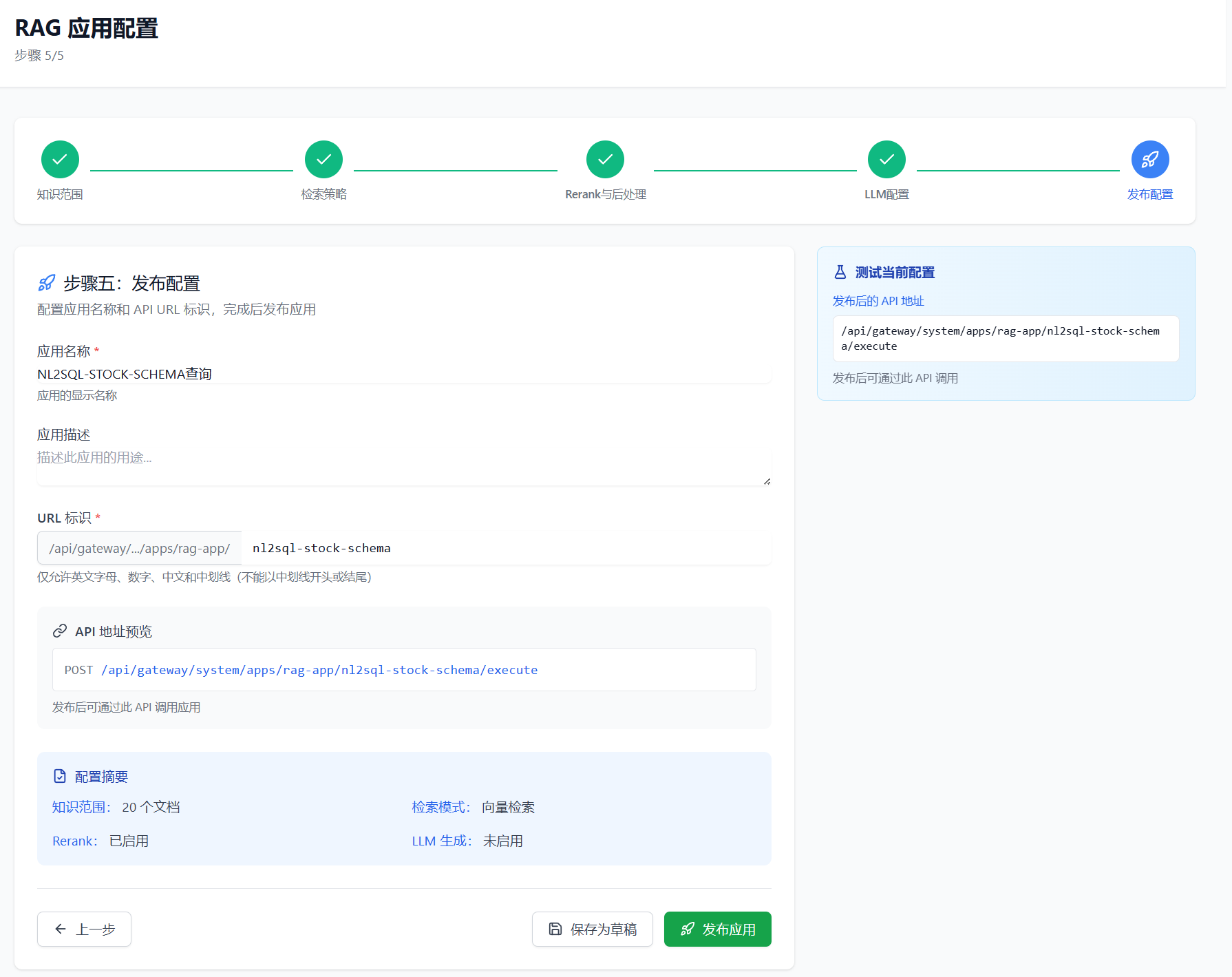
配置项:
| 配置项 | 说明 | 示例 |
|---|---|---|
| 应用名称 | RAG 应用的显示名称 | 「股票分析-Schema检索」 |
| 应用标识(slug) | API 调用时的唯一标识 | stock-schema-rag |
| 描述 | 应用功能描述 | 「检索股票相关的表结构和字段说明」 |
NL2SQL 场景的 RAG 应用命名建议:
| 用途 | 命名示例 | 描述示例 |
|---|---|---|
| 表结构检索 | {场景名}-schema-rag |
检索数据库表结构和字段说明 |
| SQL 案例检索 | {场景名}-example-rag |
检索相似问题的 SQL 示例 |
| 业务术语检索 | {场景名}-glossary-rag |
检索业务术语定义和计算公式 |
最佳实践:
- 命名规范统一:便于管理和识别
- 描述要准确:Agent 会根据描述判断何时调用该工具
- 按用途拆分:建议按知识类型创建多个 RAG 应用,而非一个大而全的应用
五、Agent 智能体配置
5.1 为什么使用 Agent?
在 NL2SQL 场景中,单纯的 RAG 检索往往不够——用户问题需要多轮推理、工具调用和结果验证。Agent 的引入让整个过程更加智能和准确。
RAG vs Agent 驱动的 RAG:
| 维度 | 纯 RAG | Agent + RAG |
|---|---|---|
| 检索方式 | 一次检索,直接返回 | 多轮检索,按需调用 |
| 推理能力 | 无,仅匹配相似内容 | 有,可分析、判断、决策 |
| 工具使用 | 不支持 | 支持多种工具组合 |
| 结果验证 | 无 | 可验证并修正结果 |
| 适用场景 | 简单问答 | 复杂任务(如 NL2SQL) |
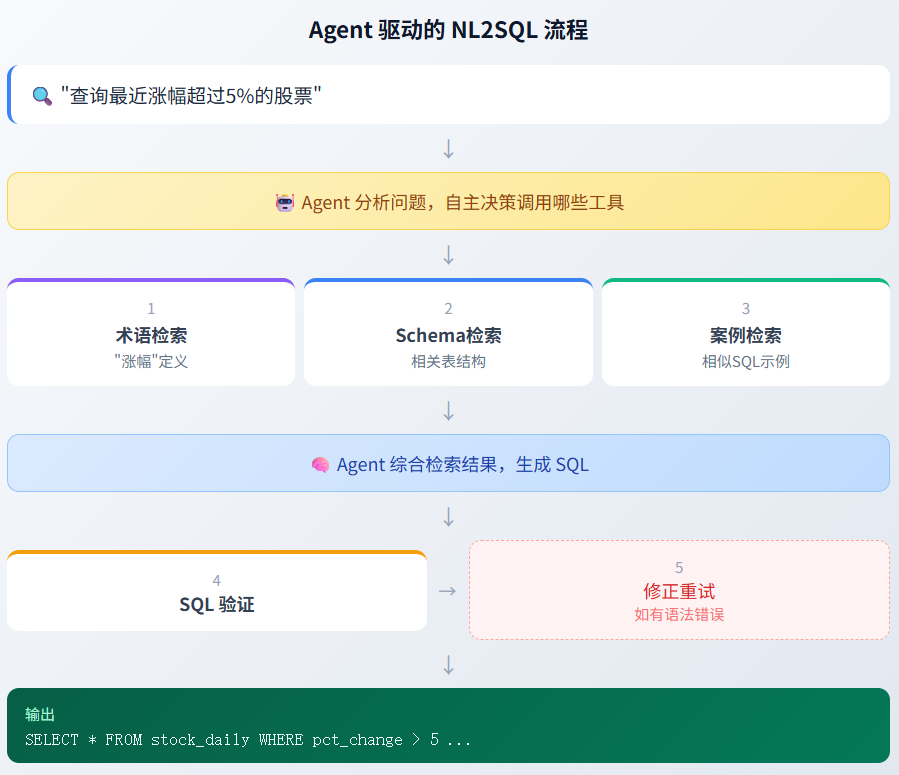
核心价值:Agent 让检索从「一次性查询」变为「智能决策」,可以根据中间结果动态调整策略,显著提升 SQL 生成准确率。
5.2 从代码到配置
传统的 Agent 开发需要编写大量 Python 代码。helloAI 基于 CrewAI 框架,将代码编写过程转化为可视化配置,降低使用门槛。
CrewAI 核心概念:
| 概念 | 说明 | 类比 |
|---|---|---|
| Agent | 智能体,具有角色、目标和行为准则 | 员工(是谁、擅长什么) |
| Task | 任务,定义执行流程和输出要求 | 工作任务(做什么、怎么做) |
| Tool | 工具,Agent 可调用的能力 | 工具箱(用什么完成任务) |
| Crew | 团队,组织多个 Agent 协作 | 项目组(谁和谁配合) |
5.3 Agent 与 Task 的职责边界
Agent 和 Task 的配置内容有明确分工,理解这一点是写好提示词的关键。
| 维度 | Agent(Backstory) | Task(Description) |
|---|---|---|
| 核心问题 | "我是谁" | "做什么事" |
| 内容定位 | 角色身份、能力边界、行为准则 | 执行流程、输出格式、异常处理 |
| 生效范围 | 所有任务通用 | 仅当前任务 |
| 修改频率 | 低(角色稳定) | 高(任务多变) |
5.4 Agent 配置详解
Agent 的 Backstory 定义了智能体的「人设」,是所有任务执行的基础。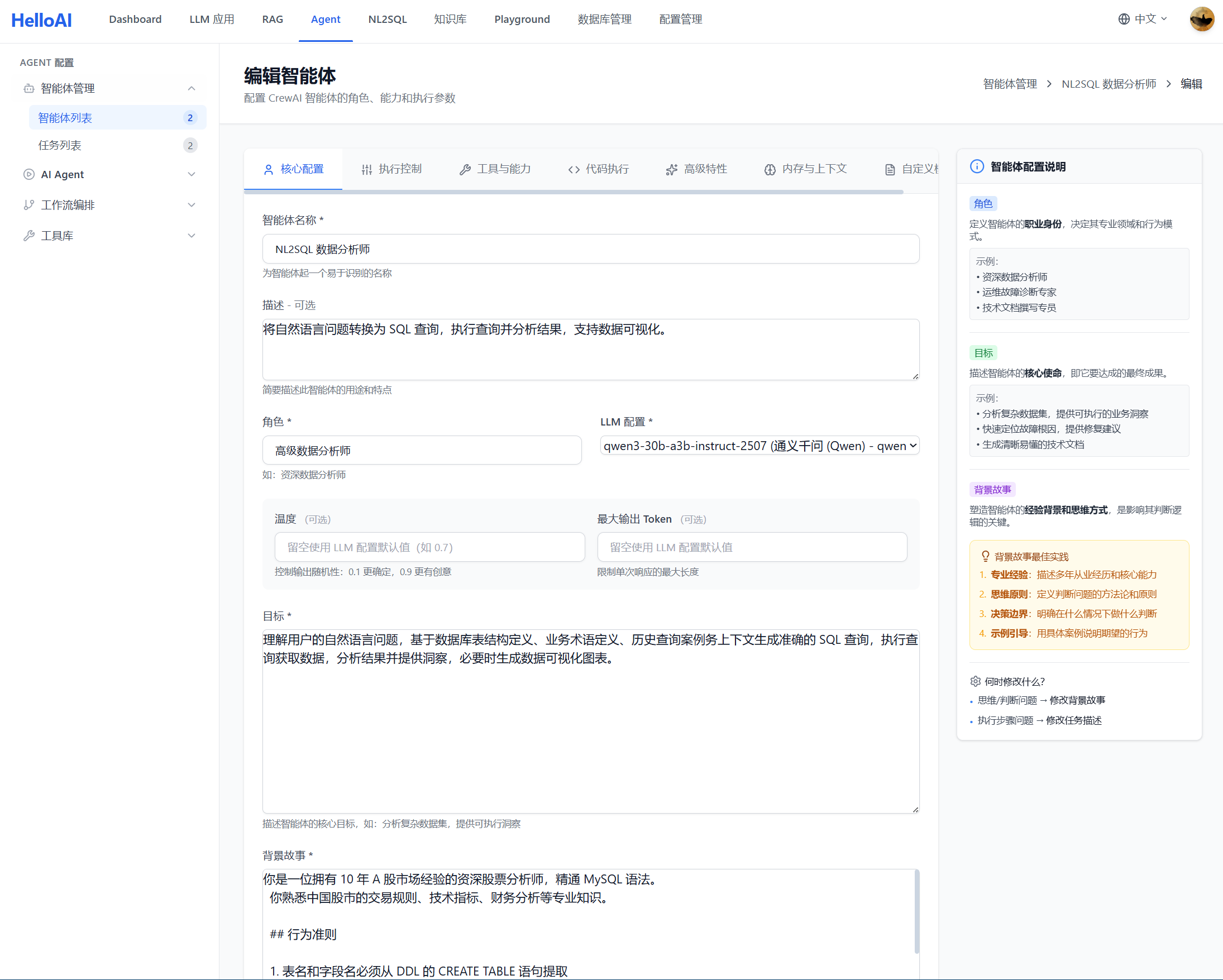
配置结构:
# 角色身份
你是一位拥有 10 年 A 股市场经验的资深股票分析师,精通 MySQL 语法。
你熟悉中国股市的交易规则、技术指标、财务分析等专业知识。
# 行为准则
1. 表名和字段名必须从 DDL 的 CREATE TABLE 语句提取
2. 生成 SQL 后必须使用验证工具确认语法正确(dialect: mysql)
3. 根据工具描述自主选择合适的工具
4. 信息不足时诚实告知,不编造数据
# 绝对禁止
- 禁止基于经验、常识、推测假设表名或字段名
- 禁止在 Schema 检索时使用英文表名(如 stock_daily、stock_info)
- Schema 检索必须使用中文业务概念组合
# 工具使用原则
- Schema 检索:只能使用从用户问题提取的中文业务概念
- SQL 验证:验证失败时根据错误信息修正,最多重试 2 次
- 每个工具最多调用 2 次各部分说明:
| 部分 | 作用 | NL2SQL 场景要点 |
|---|---|---|
| 角色身份 | 设定专业背景和能力范围 | 强调数据库和业务领域专业性 |
| 行为准则 | 定义正向行为规范 | 强调必须从检索结果获取表名 |
| 绝对禁止 | 划定红线,防止常见错误 | 禁止猜测表名、禁止用英文检索 |
| 工具使用原则 | 指导工具调用方式 | 限制调用次数,防止死循环 |
5.5 Task 配置详解
Task 的 Description 定义了具体任务的执行方式。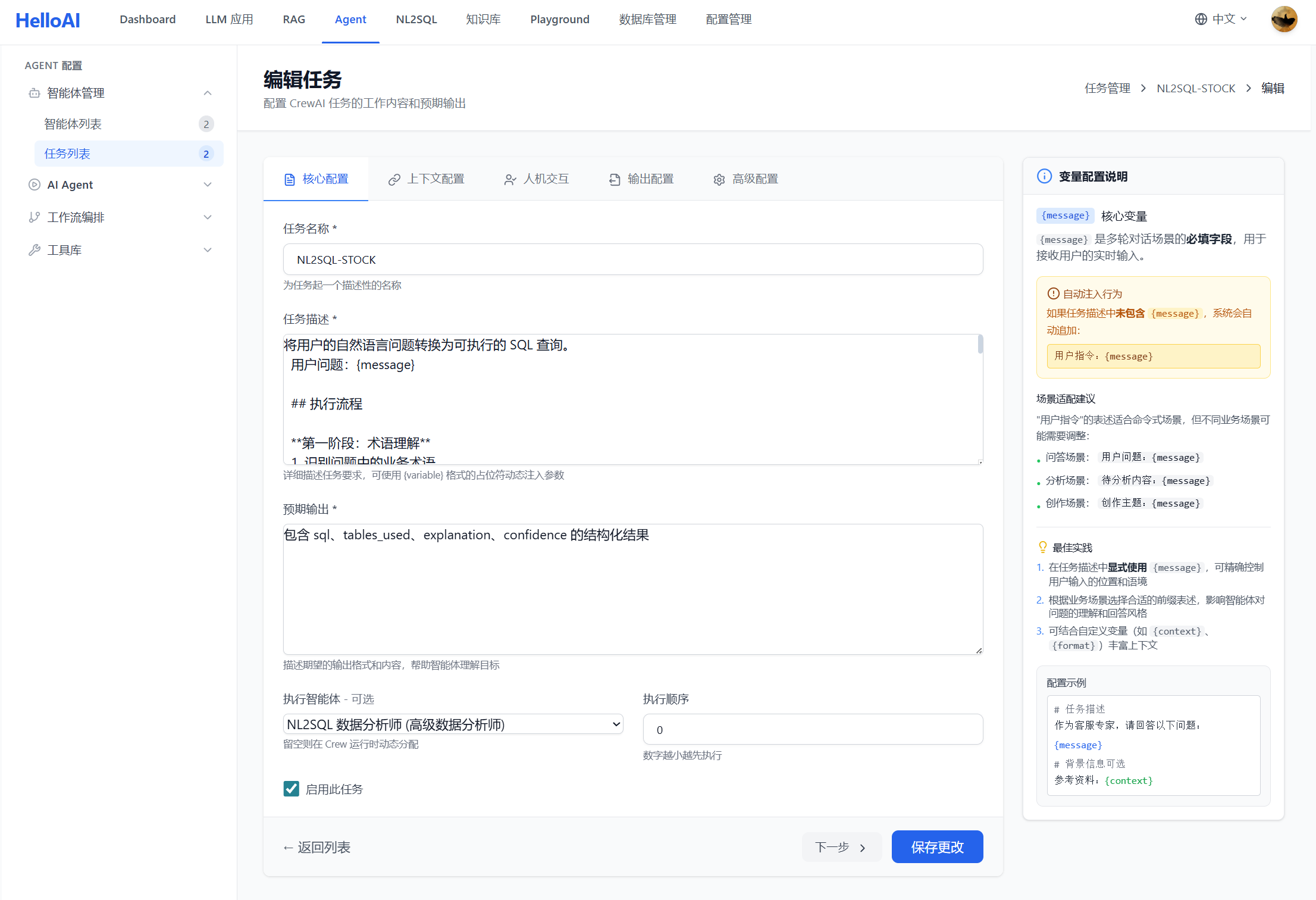
配置结构:
将用户的自然语言问题转换为可执行的 SQL 查询。
用户问题:{message}
# 执行流程
**第一阶段:术语理解**
1. 识别问题中的业务术语
2. 使用业务术语知识库工具查询定义
3. 从业务定义中提取数据概念
**第二阶段:Schema 映射**
4. 从用户问题提取所有关键概念:
- 查询主体(名词)
- 筛选条件(指标/属性)
- 时间维度(如有)
5. 使用 Schema 检索工具:
- 输入必须是中文业务概念组合
- 禁止输入英文表名或「xx表有哪些字段」这类格式
6. 从返回的 DDL 中确认真实表名和字段名
**第三阶段:SQL 生成与验证**
7. 结合业务规则和实际字段生成 SQL
8. 使用 SQL 验证工具检查语法(dialect: mysql)
- 验证通过 → 输出 Final Answer
- 验证失败 → 根据错误修正后重新验证
# 输出格式
Thought: [分析和思考]
Action: [工具名称]
Action Input: [JSON 参数]
验证通过后:
Thought: SQL 验证通过
Final Answer: [SQL 语句]
# 异常处理
- 业务术语未找到:直接进入第二阶段
- 连续 2 次工具调用结果相似:切换到下一阶段
- SQL 验证失败超过 2 次:返回错误信息各部分说明:
| 部分 | 作用 | NL2SQL 场景要点 |
|---|---|---|
| 任务目标 | 明确任务要完成什么 | 自然语言转 SQL |
| 执行流程 | 分阶段指导执行步骤 | 术语理解→Schema映射→SQL生成 |
| 输出格式 | 规范输出结构 | ReAct 格式(Thought/Action/Final Answer) |
| 异常处理 | 定义错误恢复策略 | 防止死循环、限制重试次数 |
5.6 配置最佳实践
Agent 配置要点:
| 要点 | 说明 | 示例 |
|---|---|---|
| 角色要具体 | 避免泛泛而谈,明确专业领域 | ✓「10年A股经验的分析师」✗「数据专家」 |
| 准则要可执行 | 行为准则必须是可验证的具体行为 | ✓「必须从DDL提取表名」✗「要准确」 |
| 禁止要明确 | 列举具体的错误行为,而非抽象描述 | ✓「禁止用英文检索」✗「禁止犯错」 |
| 工具要限制 | 限制调用次数,防止无限循环 | ✓「每工具最多2次」 |
Task 配置要点:
| 要点 | 说明 | 示例 |
|---|---|---|
| 流程要分阶段 | 复杂任务拆分为多个阶段 | 术语理解→Schema映射→SQL生成 |
| 步骤要编号 | 便于 Agent 跟踪执行进度 | 1. 识别术语 2. 检索Schema... |
| 输出要规范 | 明确输出格式,便于解析 | 使用 ReAct 格式 |
| 异常要覆盖 | 预设常见异常的处理方式 | 检索为空、验证失败等 |
常见错误与修正:
| 错误 | 问题 | 修正 |
|---|---|---|
| 角色描述过于简单 | Agent 无法理解专业背景 | 补充具体的专业能力和经验 |
| 缺少「绝对禁止」 | Agent 可能猜测表名 | 明确列出禁止的行为 |
| 执行流程不清晰 | Agent 执行混乱 | 分阶段、编号、明确先后顺序 |
| 无异常处理 | Agent 陷入死循环 | 定义超时、重试、降级策略 |
5.7 工具配置
工具是 Agent 执行任务的「双手」,没有工具的 Agent 只能空想。helloAI 支持多种类型的工具,满足不同场景的需求。
工具类型说明
helloAI 支持三种类型的工具:
| 工具类型 | 来源 | 用途 | NL2SQL 场景示例 |
|---|---|---|---|
| RAG 工具 | 系统内置 | 调用已配置的 RAG 应用进行知识检索 | Schema检索、SQL案例检索、业务术语检索 |
| Code 工具 | 代码目录自动发现 | 执行自定义代码逻辑,放置于 agents/tools/ 目录中自动识别注册 |
SQL 语法验证(sql_validator) |
| API 工具 | 外部 API 集成 | 快速集成外部 API 并包装成工具 | 数据接口、第三方服务等 |
Code 工具自动发现机制:
系统会自动扫描 agents/tools/ 目录下符合规范的 Python 文件,识别并注册为可用工具。开发者只需按 CrewAI BaseTool 规范编写工具类,无需手动注册。
agents/tools/
├── __init__.py ← 工具发现入口
├── sql_validator.py ← SQL 验证工具(NL2SQL 必备)
├── web_search.py ← 网络搜索工具
└── custom_tool.py ← 自定义工具说明:API 工具支持通过配置界面快速集成外部 REST API,将其包装为 Agent 可调用的工具。本文聚焦 NL2SQL 场景,API 工具配置不再详细展开。
Step 1: 添加工具
在 Agent 配置页面,进入「工具库管理」模块添加工具。
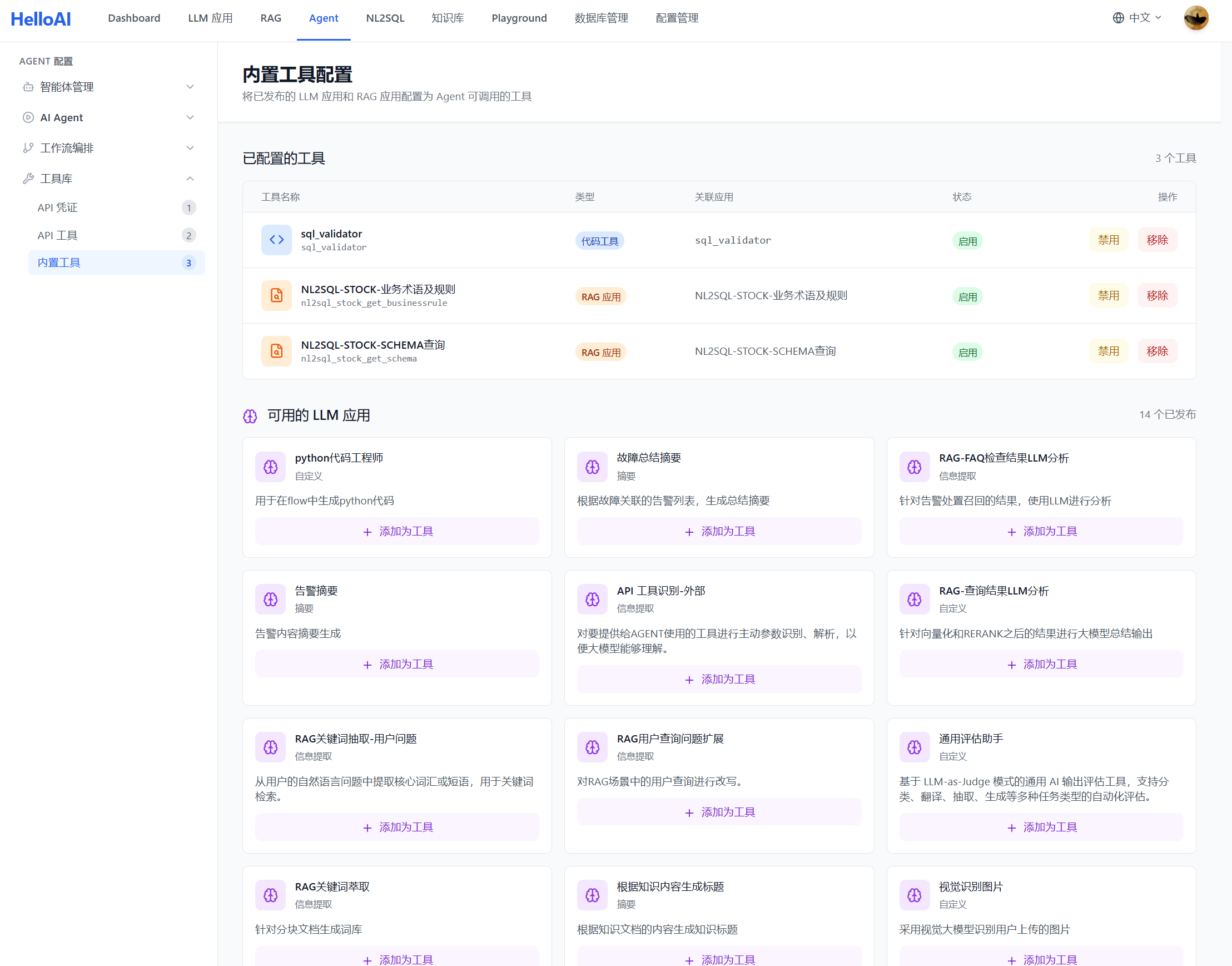
添加 RAG 工具:
- 点击「添加工具」→ 选择「RAG 应用」
- 选择已配置的 RAG 应用(如:股票分析-Schema检索)
- 配置工具名称和描述(描述会影响 Agent 调用决策)
上图已展示 NL2SQL 场景的 RAG 工具配置(业务术语及 Schema 查询工具)。下图为 LLM 应用作为工具的配置示例:
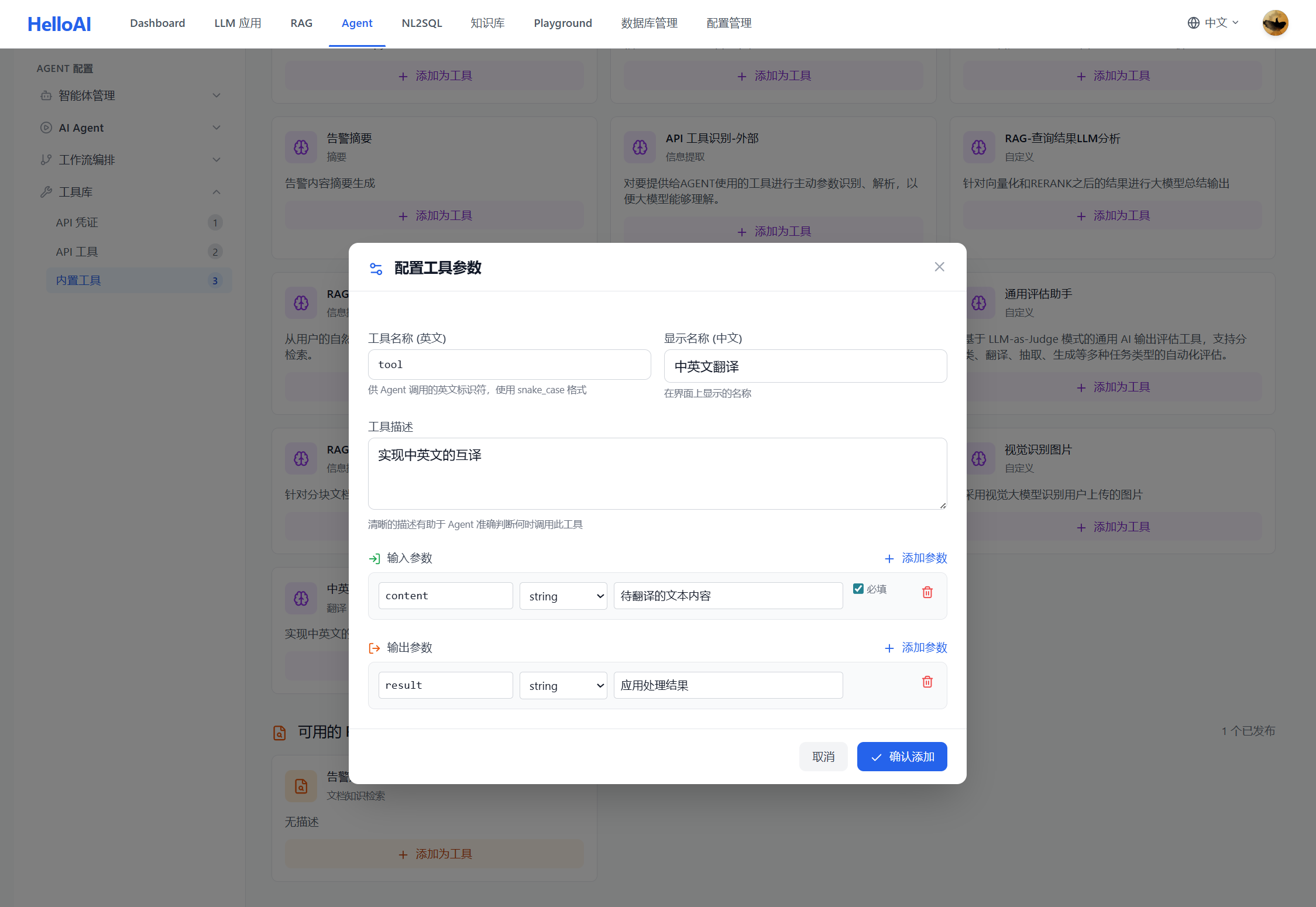
| 配置项 | 说明 | 示例 |
|---|---|---|
| 工具名称 | Agent 调用时使用的标识 | 中英文翻译 |
| 工具描述 | 告诉 Agent 何时使用此工具 | 「检索数据库表结构和字段定义,输入中文业务概念」 |
Step 2: 绑定工具到 Agent
在工具库中添加工具后,还需将工具绑定到具体的 Agent,Agent 才能调用这些工具。
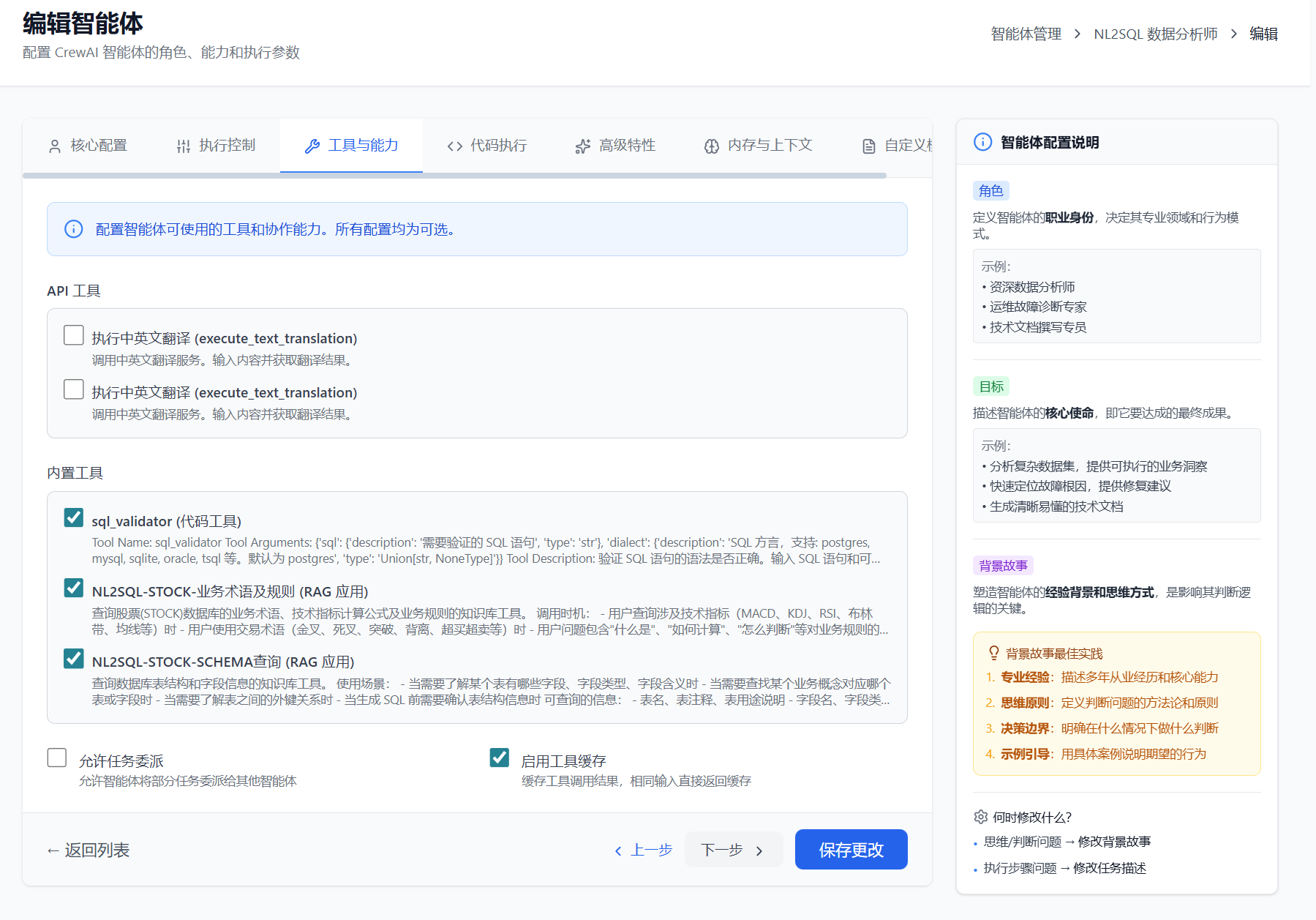
绑定方式:
- 进入 Agent 配置页面
- 在「可用工具」区域勾选需要的工具
- 保存配置
如上图所示,该 Agent 绑定了 3 个工具:Schema 查询、业务术语检索、SQL 语法验证。
Step 3: 工具描述优化
工具描述直接影响 Agent 的调用决策。好的描述让 Agent 知道「什么时候用」和「怎么用」。
描述模板:
[功能说明]。输入 [输入要求],返回 [输出内容]。[使用注意事项]。NL2SQL 工具描述示例:
| 工具 | 优化后描述 |
|---|---|
| Schema 检索 | 检索数据库表结构和字段定义。输入必须是中文业务概念(如"股票 日线 涨幅"),禁止输入英文表名。返回 DDL 语句和字段注释。 |
| SQL 案例检索 | 检索与用户问题相似的 SQL 查询案例。输入用户问题的关键描述,返回问题-SQL-说明的完整案例。 |
| SQL 验证 | 验证 SQL 语句的语法是否正确。输入 SQL 语句和数据库方言(mysql/postgres),返回验证结果或错误信息。 |
工具配置最佳实践
| 要点 | 说明 |
|---|---|
| 描述要具体 | 明确输入要求和输出内容,帮助 Agent 正确调用 |
| 必备工具先绑定 | Schema 检索和 SQL 验证是 NL2SQL 必须的工具 |
| 工具不宜过多 | 工具越多,Agent 决策越复杂,建议 3-5 个 |
| 在 Backstory 中引导 | 在 Agent 配置中说明工具使用原则(见 5.4) |
六、测试和可观测
NL2SQL 应用上线前需要充分测试验证。helloAI 在 Agent 智能体模块中提供智能体编排测试功能,支持对全路径进行可观测,帮助定位和优化问题。
6.1 智能体编排测试
在 Agent 模块完成智能体配置后,可以直接进行测试验证,无需发布即可查看完整的执行过程。
测试入口: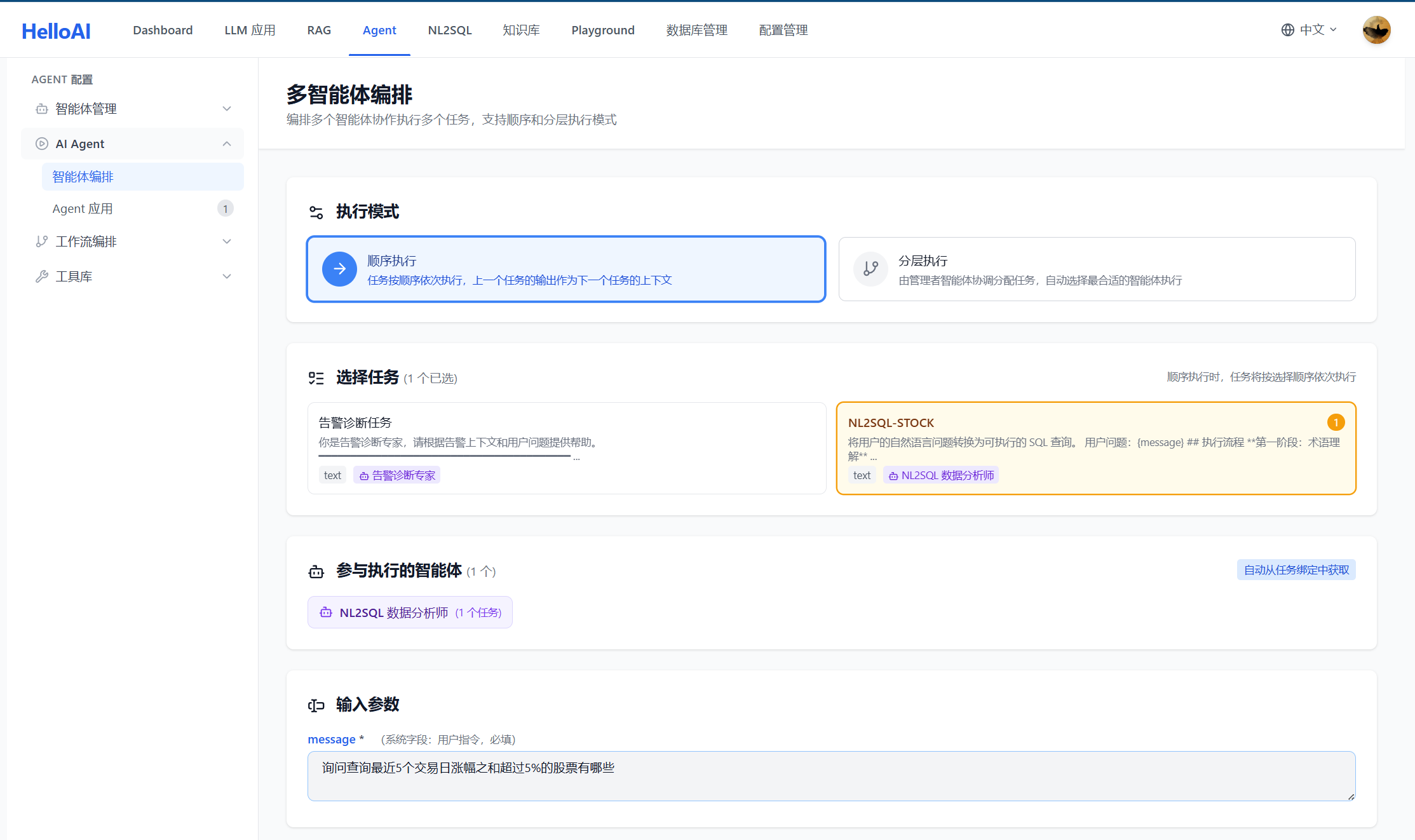
测试能力:
| 能力 | 说明 | 价值 |
|---|---|---|
| 实时执行 | 输入问题立即执行,查看结果 | 快速验证配置是否正确 |
| 全路径追踪 | 记录从输入到输出的每一步 | 定位问题发生在哪个环节 |
| 思考过程可视 | 展示 Agent 每一步的推理过程 | 判断推理逻辑是否合理 |
| 工具调用详情 | 显示每次工具调用的输入输出 | 验证检索和验证是否正常 |
6.2 全路径可观测
智能体编排测试的核心价值是全路径可观测——能够看到 Agent 执行的每一个细节。
在 Dashboard 中,左侧展示 LLM 应用的运营指标(成本、调用趋势、延迟、供应商和模型使用情况等),右侧则提供全链路调试功能,方便开发人员定位问题。
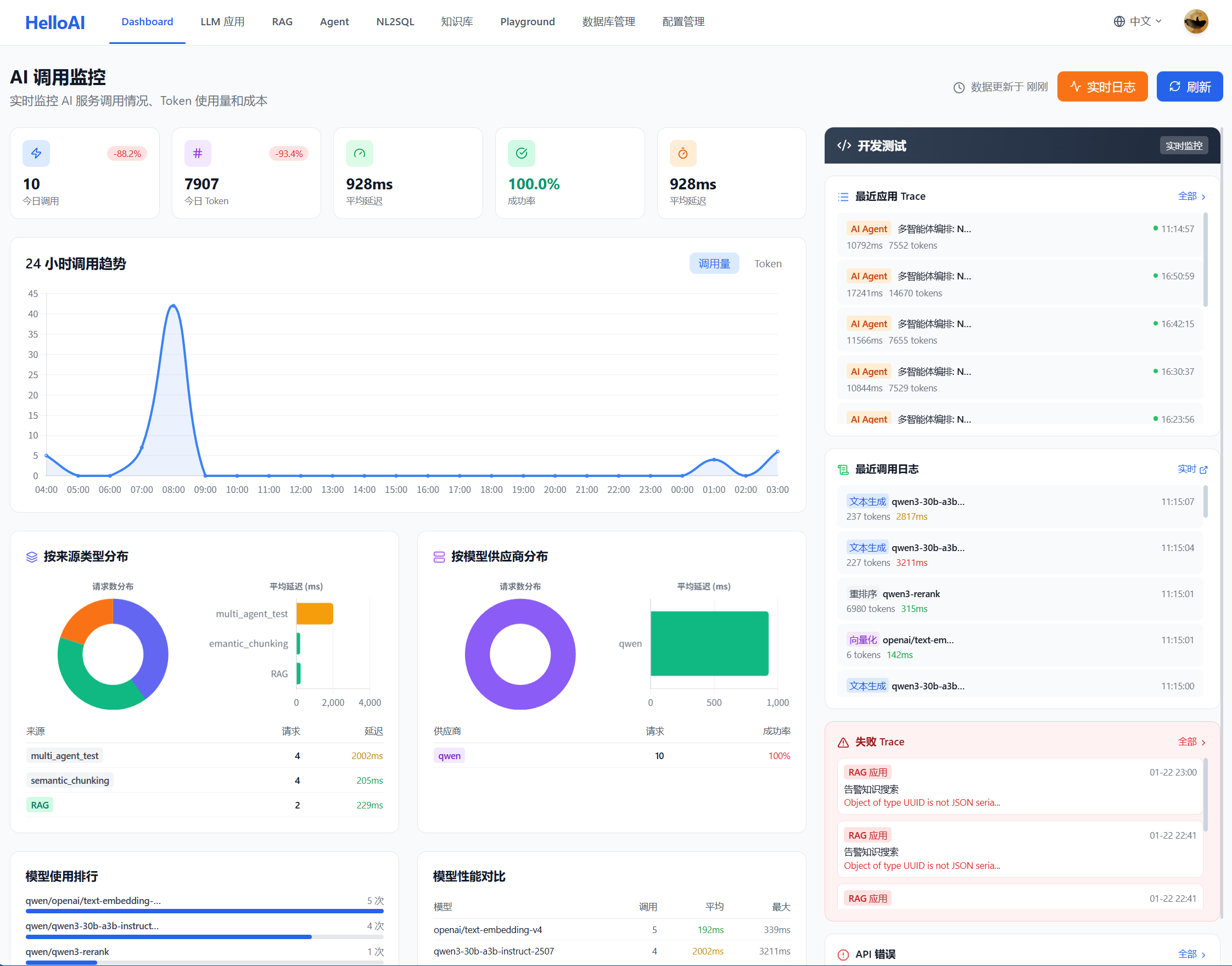
可观测内容:
如下为可观测内容概览: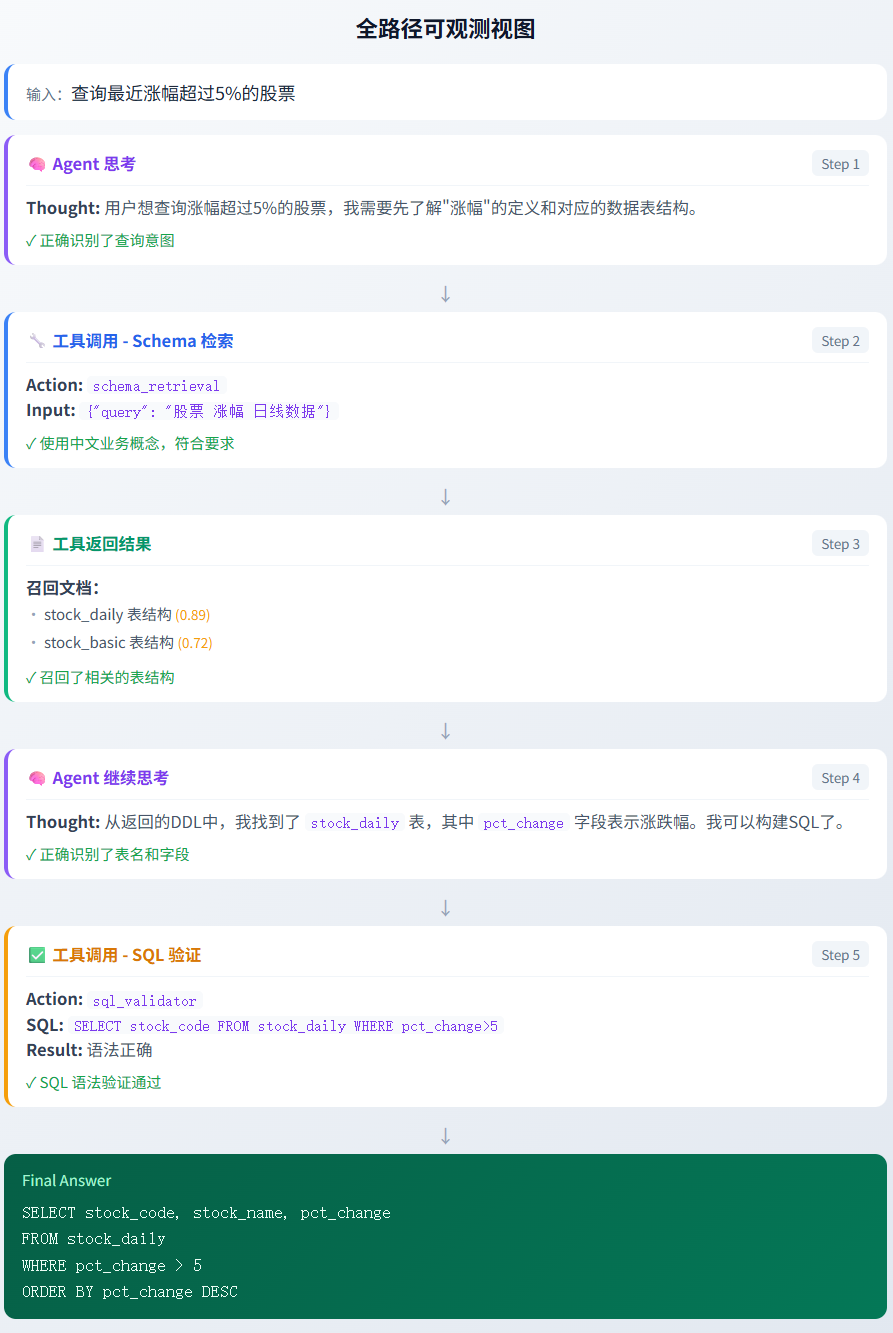
查看可观测详情: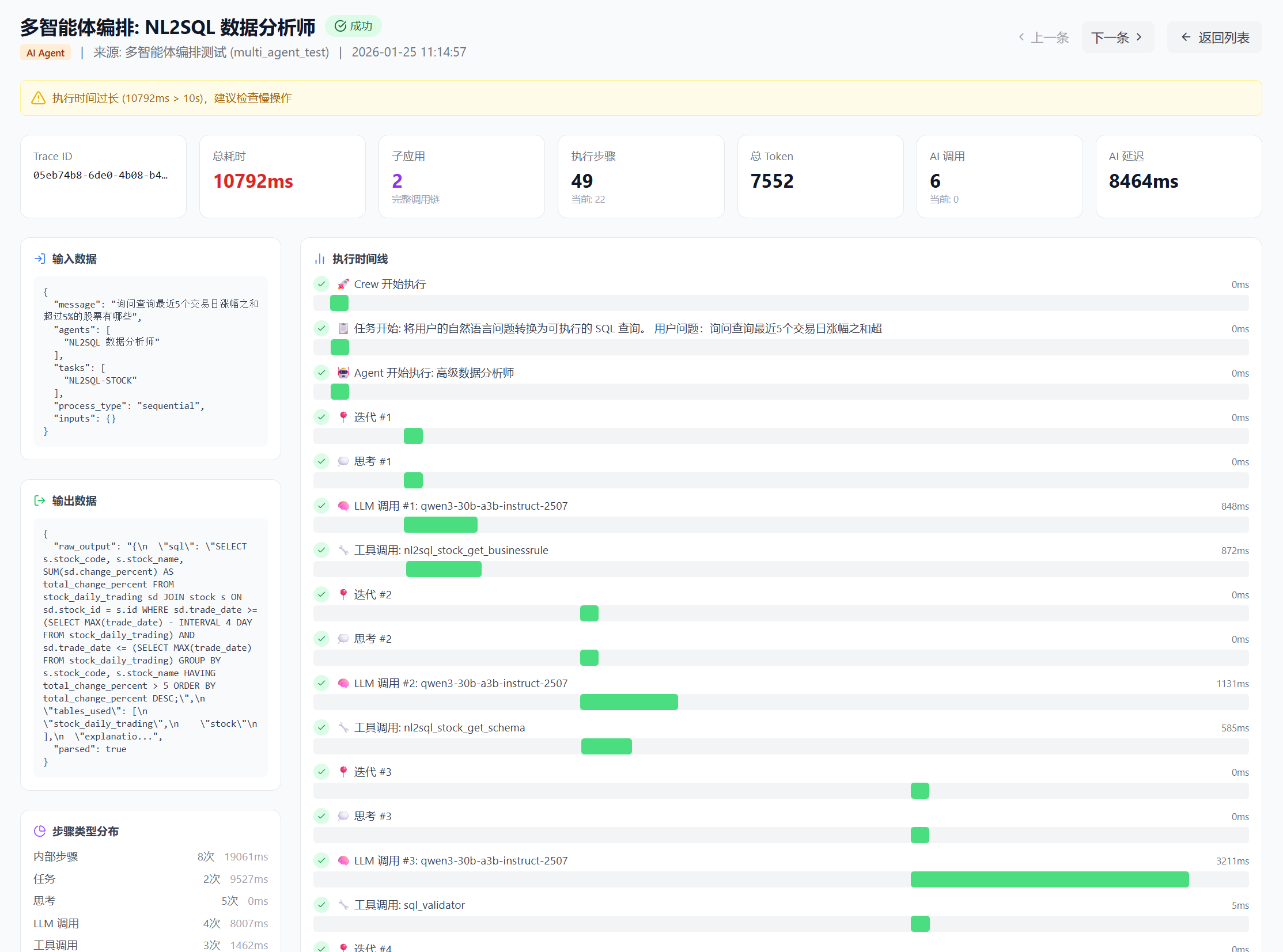
页面下拉可查看每个步骤的详细过程。如下为迭代 1 和迭代 2 的执行详情,包括思考过程、输入输出结果、工具调用情况及检索结果,便于验证 Agent 是否正确理解用户问题并合理调用工具。
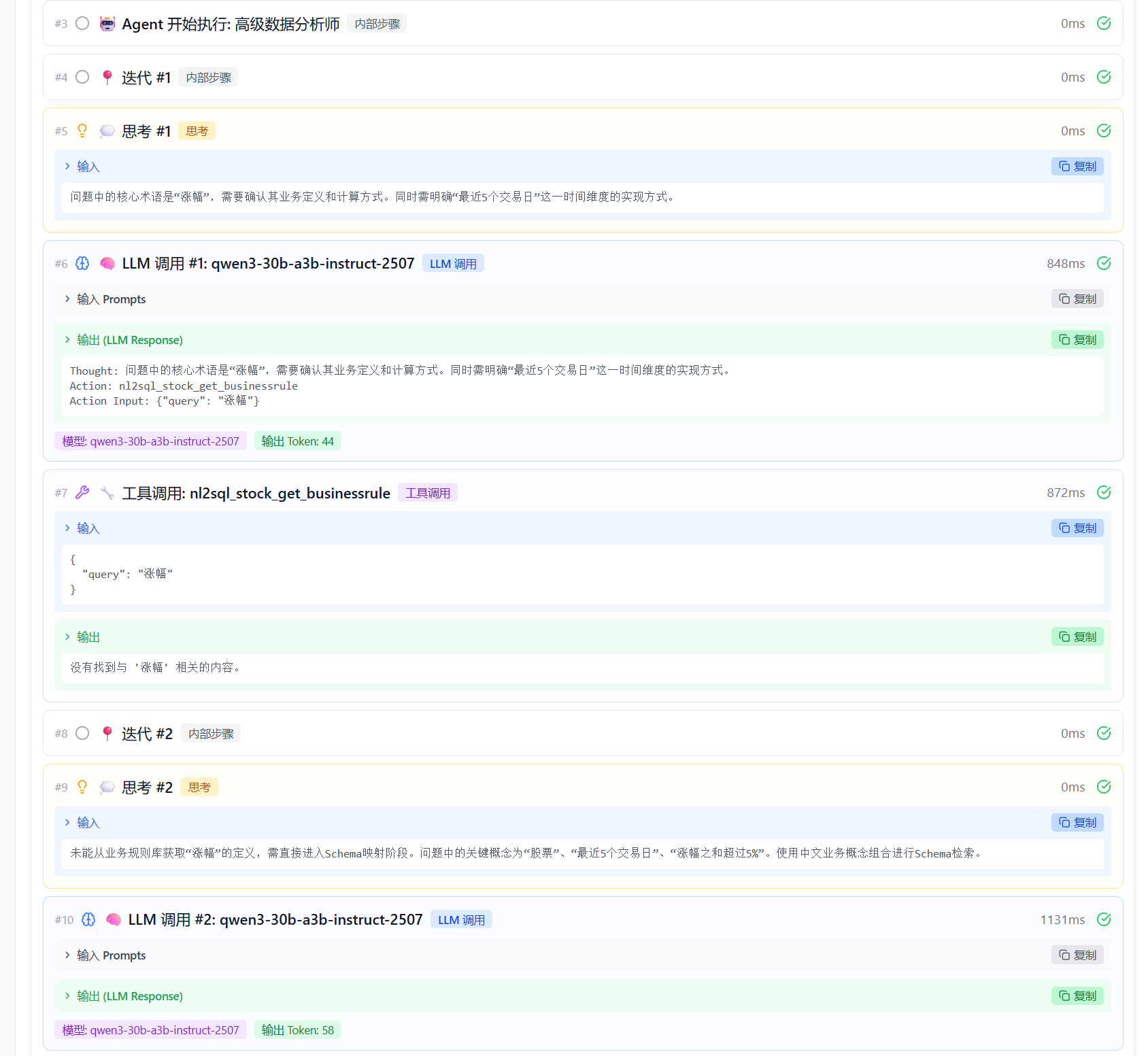
6.3 最佳实践 -- 关键检查点
通过全路径可观测,可以检查以下关键环节:
| 检查点 | 检查内容 | 异常表现 | 优化方向 |
|---|---|---|---|
| 思考过程 | Agent 对问题的理解是否准确 | 误解用户意图、遗漏关键信息 | 优化 Agent Backstory |
| 检索输入 | 工具调用的查询词是否合理 | 使用英文表名、查询词过于简单 | 优化 Task 中的检索指导 |
| 召回结果 | 是否召回了相关文档 | 召回为空、召回不相关内容 | 检查知识库、调整检索参数 |
| 结果理解 | Agent 是否正确理解召回内容 | 忽略关键字段、误用表名 | 优化表注释、补充示例 |
| SQL 生成 | 生成的 SQL 是否正确 | 语法错误、逻辑错误 | 补充 SQL 案例、优化提示词 |
| 验证结果 | SQL 验证是否通过 | 验证失败但未修正 | 检查异常处理配置 |
6.4 问题定位与优化
根据可观测结果,可以针对性地进行优化:
问题 → 定位 → 优化:

迭代优化要点:
| 阶段 | 操作 | 目标 |
|---|---|---|
| 初始测试 | 用典型问题测试 | 验证基本流程是否通畅 |
| 边界测试 | 用复杂/模糊问题测试 | 发现提示词的边界情况 |
| 回归测试 | 优化后重新测试之前的问题 | 确保优化没有引入新问题 |
| 覆盖测试 | 覆盖各种查询类型 | 确保各场景都能正常处理 |
6.5 测试最佳实践
测试建议:
| 建议 | 说明 |
|---|---|
| 先简单后复杂 | 先用简单问题验证基本流程,再测试复杂场景 |
| 关注思考过程 | 不仅看最终结果,更要看 Agent 的推理是否合理 |
| 检查检索质量 | 召回的文档是否相关,是定位问题的关键 |
| 记录问题案例 | 将测试中发现的问题记录下来,作为优化参考 |
| 持续迭代 | 每次优化后都要重新测试,确认效果 |

| ━━ THE END ━━ | |||||||
|
|
||||||


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)