大模型应用:大模型算力优化方案:识别突破隐性瓶颈达到效能最大化.65
大模型算力优化实战:从隐性瓶颈到效能最大化 本文深入探讨了大模型落地实践中常见的算力浪费问题,提出从系统、模型、数据三个维度进行全链路优化的方法论。系统级瓶颈包括CUDA版本、驱动适配和操作系统调度;模型级优化涉及注意力头裁剪、激活函数选择和权重稀疏化;数据级瓶颈则需优化批量加载、Tokenizer速度和数据格式。针对不同场景(个人开发、企业推理、边缘部署)给出了量化适配方案,强调通过动态批处理、
一、引言
在大模型落地实践中,我们都会面临一个共性困惑:明明显卡算力达标、模型量化适配,实际运行时却始终跑不满算力,甚至出现卡顿、显存溢出等问题。前文我们已详解算力指标(TFLOPS/PFLOPS)、模型和硬件匹配逻辑及基础优化技巧,今天我们也深度的聊聊在我们配了好的显卡,也满心欢喜的优选了适合的模型,可在实践应过程中,可能还是会遇到各种奇奇怪怪的问题,在平常我们可能普遍将算力问题归咎于显卡性能不足,但实战中很多实际情况的算力浪费源于隐性瓶颈。
接下来我们就好好分析分析这些算力浪费的隐性痛点,从系统、模型、数据三维度拆解全链路优化逻辑,通过经验诊断进行优化达到用好算力的结果,实现效能最大化。

二、隐性算力瓶颈
1. 核心回顾
- 基础单位:TFLOPS(每秒万亿次浮点运算,1 TFLOPS=10¹²次/秒)、PFLOPS(每秒千万亿次浮点运算,1 PFLOPS=1000 TFLOPS),消费级显卡用TFLOPS计量,数据中心显卡用PFLOPS。
- 精度算力:同一显卡算力随精度递减而倍增,如RTX 4090 FP32算力83 TFLOPS、FP16 166 TFLOPS、INT8 332 TFLOPS,核心逻辑是数据字节数越少,单位时间运算次数越多。
- 显存带宽:算力释放的“生命线”,RTX 4090 1008 GB/s带宽可充分匹配INT8算力,而带宽不足会导致“GPU等数据”的算力闲置。
2. 算力瓶颈体现
2.1 系统级瓶颈
系统级瓶颈就像底层适配的隐形枷锁,操作系统、驱动、CUDA版本的适配直接决定算力是否能完全释放,而非单纯依赖硬件参数:
2.1.1 CUDA版本:
RTX 4090搭配CUDA 12.1比11.8的INT4算力释放提升12%,低版本CUDA会屏蔽第4代张量核心的INT4优化功能;
- CUDA 版本太低,导致张量核心没有完全发货
- RTX 4090 等新卡依赖第 4 代张量核心来加速 INT4/FP8 计算。
- 但这个功能只在 CUDA 12.1 及以上才启用。如果你还在用 CUDA 11.8,系统会直接屏蔽它,从而导致INT4 推理吞吐白白损失 10%~15%。
2.1.2 驱动版本:
NVIDIA驱动需更新至530以上才能支持RTX 40系列的完整算力,旧驱动会导致算力利用率上限降至70%;
- 通俗的说就是驱动版本太旧,GPU 被限速
- NVIDIA 驱动低于 530(如常见的 515 系列),无法完整支持 Ada 架构的新特性(如 Shader Execution Reordering)。
- 实测显示:算力利用率上限被卡在 70% 左右,哪怕你满载跑,也永远到不了 100%。
2.1.3 系统调度:
Windows系统后台进程占用GPU资源,Linux系统对GPU调度更高效,同配置下Linux算力利用率比Windows高15%-20%。
- 用 Windows,后台程序偷偷抢资源,并且Windows 后台常有杀毒软件、更新服务等占用 GPU 显存或带宽。
- 而 Linux(尤其是 Ubuntu 22.04 + 新内核)对 GPU 调度更干净高效。
- 同一套代码、同一张卡,Linux 下 GPU 利用率通常比 Windows 高 15%~20%。
2.1.4 优化建议:
- 升级 CUDA ≥ 12.1 + 驱动 ≥ 530(推荐 Studio 驱动 535+)
- 生产环境优先使用 Linux
- 定期用 nvidia-smi 和 nvcc --version 核对CUDA版本是否匹配官方兼容矩阵
2.2 模型级瓶颈
模型级瓶颈体现在冗余计算的无声消耗之中,模型架构与参数设计中的冗余计算,会让算力在无效运算中流失:
2.2.1 QKV注意力冗余:
默认注意力机制中,部分QKV矩阵维度存在无效运算,通过“注意力头裁剪”可减少20%算力消耗,效果损耗仅3%;
- 注意力头太多会导致大量无效运算
- 大模型常用多头注意力机制,但实际应用中30%~50% 的注意力头对结果几乎没贡献。
- 基于敏感度分析,通过“注意力头裁剪”,可安全去掉 20% 的头,使计算量减少 20%,效果仅下降 2%~3%。
2.2.2 激活函数选择:
Swish激活函数比ReLU更适配大模型效果,但算力消耗高30%,实战中可根据场景取舍;
- 激活函数如果选择的不合适会拖慢推理
- Swish、GELU 效果好,但涉及指数、除法等复杂运算,在无专用加速的设备上开销大,比 ReLU 多消耗 25%~30% 的算力。
- 可以两者结合,训练用 Swish,推理阶段换成 ReLU再配合微调或校准,速度明显提升。
2.2.3 模型权重冗余:
部分权重参数对输出影响极小,通过“稀疏化训练”将权重稀疏度提升至40%,算力需求同步降低35%。
- 权重冗余严重会导致存储和计算都浪费
- 很多参数接近零,对输出影响微乎其微。通过“稀疏化训练”,可让 40% 的权重变为 0。
- 若配合 NVIDIA Ampere 架构以上的 Sparse Tensor Core,实际推理速度提升近 2 倍,同时模型体积缩小 40%。
2.2.4 优化建议:
- 使用 HuggingFace optimum、torch.nn.utils.prune 等工具进行结构化剪枝
- 推理时评估是否可用轻量激活函数替代
- 对部署模型做稀疏化 + 量化联合优化,如 TensorRT-LLM、vLLM 支持
2.3 数据级瓶颈
数据级瓶颈使得在预处理环节时导致算力空转,输入数据的加载与预处理速度,往往成为算力闲置的致命短板:
2.3.1 批量加载效率:
未使用PyTorch Dataloader异步加载数据时,GPU需等待CPU处理完数据才能运算,算力利用率骤降40%;
- 使用同步加载数据会导致GPU大量空闲
- 如果用简单 for 循环读文件,GPU 每次都要等 CPU 处理完一批数据才能开工。
- GPU 利用率可能从 85% 暴跌到 40%,一半时间在闲置状态。
2.3.2 Tokenizer速度:
普通Tokenizer处理批量文本时速度较慢,采用FastTokenizer可提升3倍处理速度,减少GPU等待时间;
- Tokenizer 太慢导致文本处理成瓶颈,Python 原生 Tokenizer(如 BERT 默认版)单线程处理慢。
- 换成 HuggingFace 的 FastTokenizer(Rust 实现,多线程),文本分词速度提升 3 倍,GPU等待时间大幅缩短。
2.3.3 数据格式:
JSON格式数据加载效率低于二进制格式,转换为LMDB格式后,数据读取速度提升50%,间接提升算力利用率。
- 数据格式低效使得I/O成为短板,JSON、CSV 等文本格式需逐行解析,I/O 带宽利用率低。
- 转为二进制格式(如 LMDB、Arrow、TFRecord),数据读取速度提升 50%+,epoch 时间缩短 15%~20%。
2.3.4 优化建议:
- 必用 torch.utils.data.DataLoader,设置 num_workers=4~8 + pin_memory=True
- 所有 NLP 任务默认开启 use_fast=True
- 预处理后将大规模数据集转为二进制格式存储,避免运行时解析开销
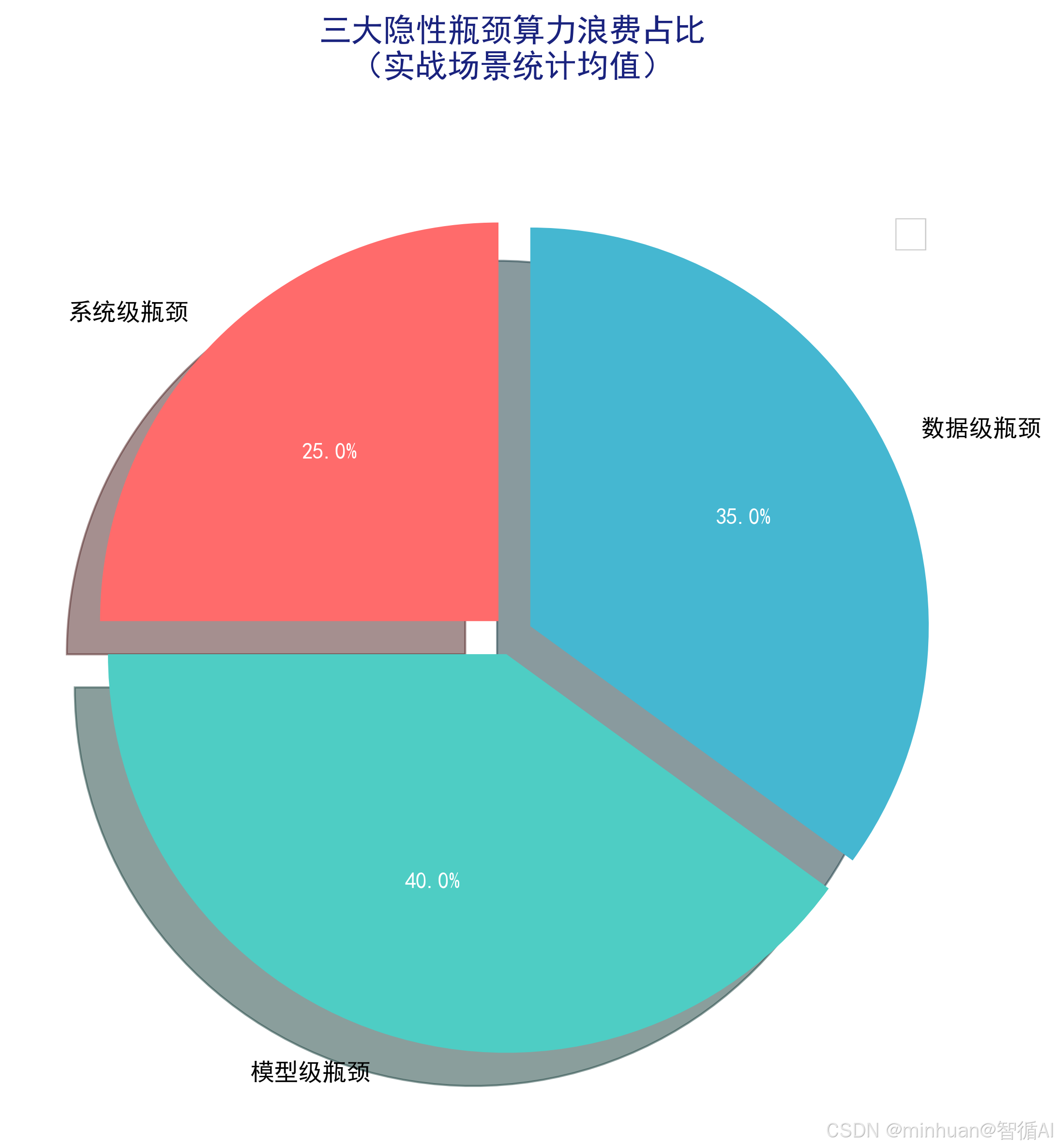
三、算力动态适配方案
1. 个人开发者
1.1 低成本场景:用技巧换算力
- 量化优化:采用INT4量化(NF4格式),搭配BitsAndBytes库,将13B模型显存占用从40GB降至10GB以内;
- 模型裁剪:裁剪注意力头从16个至12个,减少25%算力消耗,同时关闭重复惩罚、降低temperature至0.5,进一步减少计算量;
- 显存优化:开启梯度检查点(Gradient Checkpointing),牺牲20%速度换30%显存节省,避免显存溢出导致算力中断。
1.2 示例:16GB显卡运行13B INT4模型
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
# 适配16GB显存,开启INT4量化与显存优化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NF4格式降低效果损耗
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_device_map="auto"
)
# 加载模型,开启梯度检查点优化显存
model = AutoModelForCausalLM.from_pretrained(
"Qwen-13B-Chat",
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
gradient_checkpointing=True # 显存换速度,适配16GB显卡
)
tokenizer = AutoTokenizer.from_pretrained("Qwen-13B-Chat", trust_remote_code=True)
# 测试运行效果
inputs = tokenizer("用16GB显卡运行13B模型的算力优化技巧", return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.5)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))运行效果:
- RTX 4070(12GB显存)可稳定运行,生成速度约5-8字/秒,算力利用率75%,效果与FP16精度差异小于5%。
2. 企业推理
2.1 高并发场景:算力调度最大化
核心目标:在有限显卡集群中支撑多用户并发访问,避免单用户占用全量算力,提升集群整体算力利用率。
适配方案:动态批处理+模型缓存+负载均衡
- 动态批处理:根据用户请求量调整batch_size,空闲时用大批次提升算力利用率,高并发时用小批次降低延迟;
- 模型缓存:缓存高频请求的模型输出(如常见问题回答),减少重复运算,算力消耗降低40%;
- 负载均衡:采用NVIDIA Triton推理服务器,将请求均匀分配至各显卡,避免单卡过载、多卡闲置,算力利用率从60%提升至85%。
3. 边缘部署
3.1 低功耗场景:平衡算力与功耗
核心目标:在嵌入式GPU(如Jetson Orin、NVIDIA AGX Xavier)上部署大模型,适配边缘设备低功耗、低延迟需求。
适配方案:量化+蒸馏+轻量化架构
- 深度量化:采用INT4量化+模型蒸馏,将7B模型蒸馏为3B轻量化版本,算力需求降低60%,功耗控制在15W以内;
- 架构适配:选用MobileLLM等边缘优化模型,替换原生Transformer架构,减少30%算力消耗;
- 延迟优化:限制max_new_tokens为50以内,关闭冗余计算模块,确保推理延迟低于500ms,适配边缘实时场景。
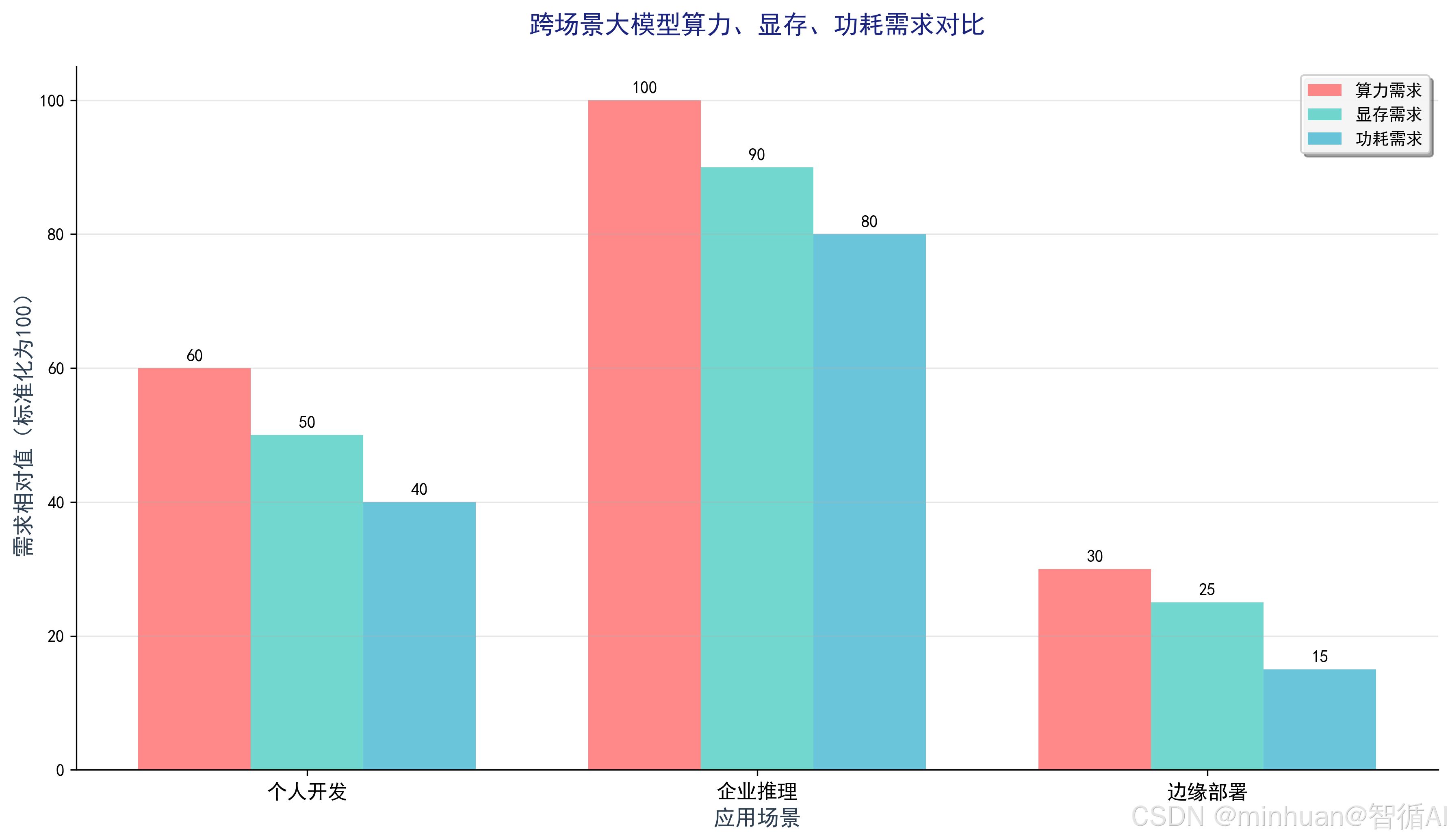
四、效能评估
量化算力利用率的核心方法,优化效果不能凭感觉,需建立量化评估体系,精准定位瓶颈、验证优化价值。
1. 核心评估指标
|
指标名称 |
定义与计算方式 |
合理范围 |
核心价值 |
|
算力利用率 |
GPU实际运算量/理论算力 × 100% |
75%-90% |
判断GPU是否充分利用,低于60%说明存在瓶颈 |
|
显存周转率 |
每秒显存读写量/显存总容量 × 100% |
30%-50% |
判断显存带宽是否瓶颈,过高说明数据读写频繁 |
|
Token算力成本 |
生成1个Token消耗的TFLOPS = 总算力需求/生成Token数 |
越低越好 |
量化优化效果的核心指标,INT4比FP16低50% |
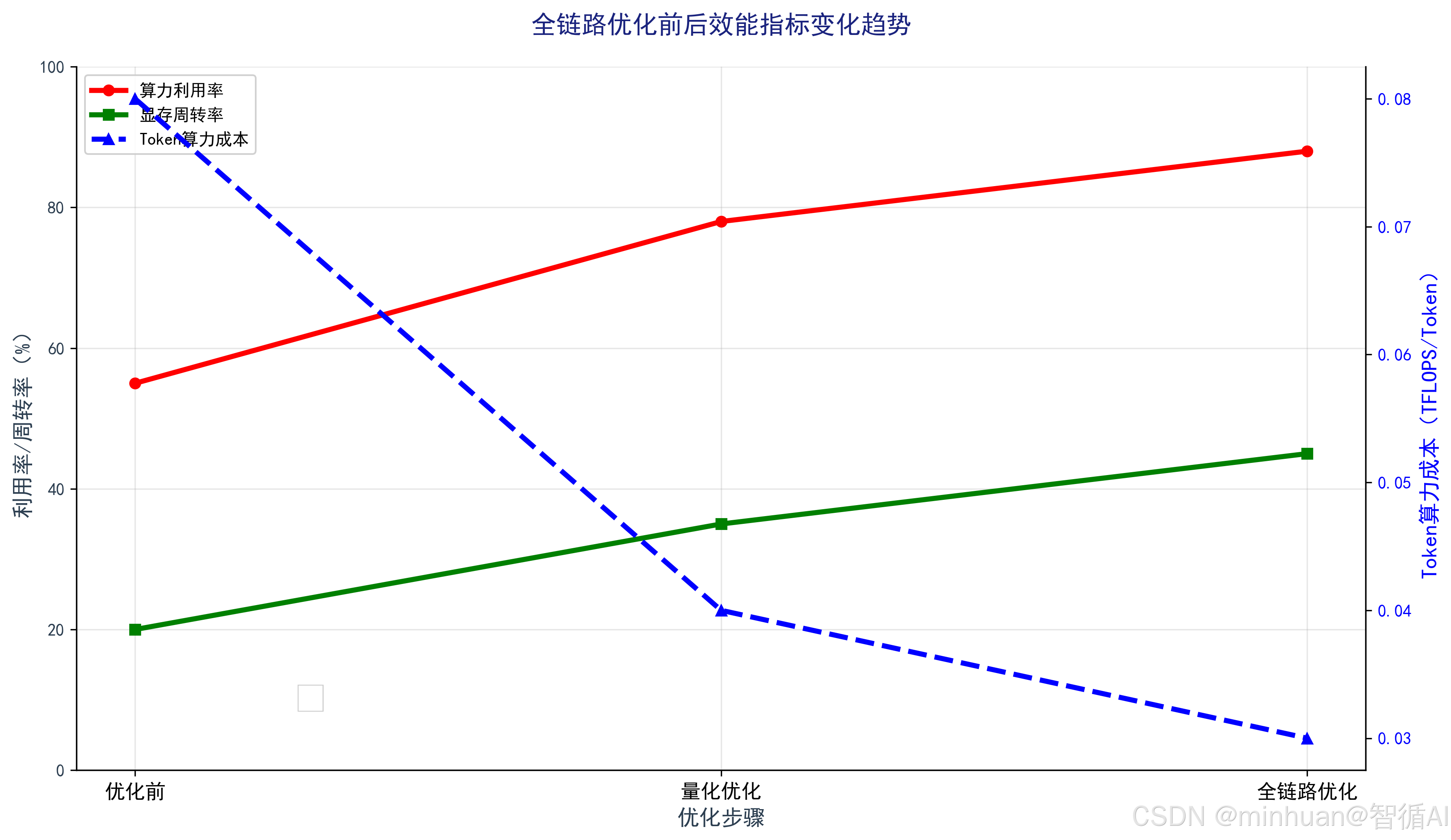
2. 优化前后效能指标趋势
3. 评估工具与代码示例
3.1 NVIDIA-smi进阶用法:监控张量核心利用率
普通监控仅看GPU利用率,进阶用法可精准定位张量核心是否生效:
3.1.1 实时监控 GPU 基础资源(每秒刷新)
# 实时监控GPU算力、显存、张量核心利用率(每秒刷新一次)
nvidia-smi --query-gpu=timestamp,name,utilization.gpu,utilization.memory,compute_mode --format=csv -l 1体现价值:判断 GPU 是否“真忙”并监控多卡任务是否均衡,比如利用率长期低于 30%,可能数据加载或模型有瓶颈
主要作用:
每秒输出一次 GPU 的关键运行状态,包括:
- 时间戳(timestamp)
- 显卡型号(name)
- GPU 计算利用率(utilization.gpu):核心算力使用百分比(0%~100%)
- 显存带宽利用率(utilization.memory):不是显存占用量,而是显存读写繁忙程度
- 计算模式(compute_mode):是否被设为独占/共享等
注意细节:
- 这个“显存利用率”≠ 显存占用多少 GB,而是反映显存总线是否繁忙。要看实际显存占用,要加傻上 memory.used,memory.total。
- 最后的“-l 1” 表示每 1 秒刷新一次,适合长时间观察训练/推理过程中的资源波动。
3.1.2 查看张量核心(Tensor Core)的实际使用情况
# 查看张量核心使用状态(需CUDA 12.0以上)
nvprof --profile-api-trace none --metrics tensor_precision_fu_utilization python your_script.py体现价值:
- 验证你的 INT4/FP16 模型是否真的启用了 Tensor Core
- 如果 GPU 利用率高但 Tensor Core 利用率低,说明可能没用对数据类型或算子(比如用了不支持 Tensor Core 的卷积)
主要作用:
- 通过 NVIDIA 的性能分析工具
nvprof,统计程序运行期间 张量核心的利用率(即 Tensor Core 实际参与计算的比例)。
细节说明:
- tensor_precision_fu_utilization 是一个硬件指标,表示张量功能单元(Tensor FU)的活跃时间占比,值越高说明越充分地利用了 Tensor Core 加速(如 FP16、INT4 等混合精度计算)。
- 要求 CUDA ≥ 12.0,且你的 GPU 支持 Tensor Core(如 Volta 架构及以上:V100、T4、A100、RTX 30/40 系列等)。
- nvprof 在较新 CUDA 版本中已被 nsight systems / nsight compute 取代,结合实际也可应用以下方法:
- nsys profile --stats=true -o report python your_script.py # 推荐替代命令(CUDA 12+)
- ncu --metrics sm__inst_executed_pipe_tensor_op_hmma.sum python your_script.py # 或查看具体指标
3.2 PyTorch Profiler:拆解每步运算的算力消耗
精准定位哪一步运算导致算力浪费,针对性优化:
import torch
from torch.profiler import profile, record_function, ProfilerActivity
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen-7B-Chat", device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("Qwen-7B-Chat")
inputs = tokenizer("测试算力消耗", return_tensors="pt").to("cuda")
# profiling每步运算的算力与时间消耗
with profile(activities=[ProfilerActivity.CUDA], record_shapes=True) as prof:
with record_function("model_generate"):
model.generate(**inputs, max_new_tokens=50)
# 打印分析结果,定位算力消耗大户
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))输出分析:
- 通过结果可查看“QKV矩阵运算”“激活函数运算”等步骤的CUDA时间占比,若某步骤占比过高,可针对性优化,如裁剪注意力头
五、算力优化逻辑
1. 执行流程
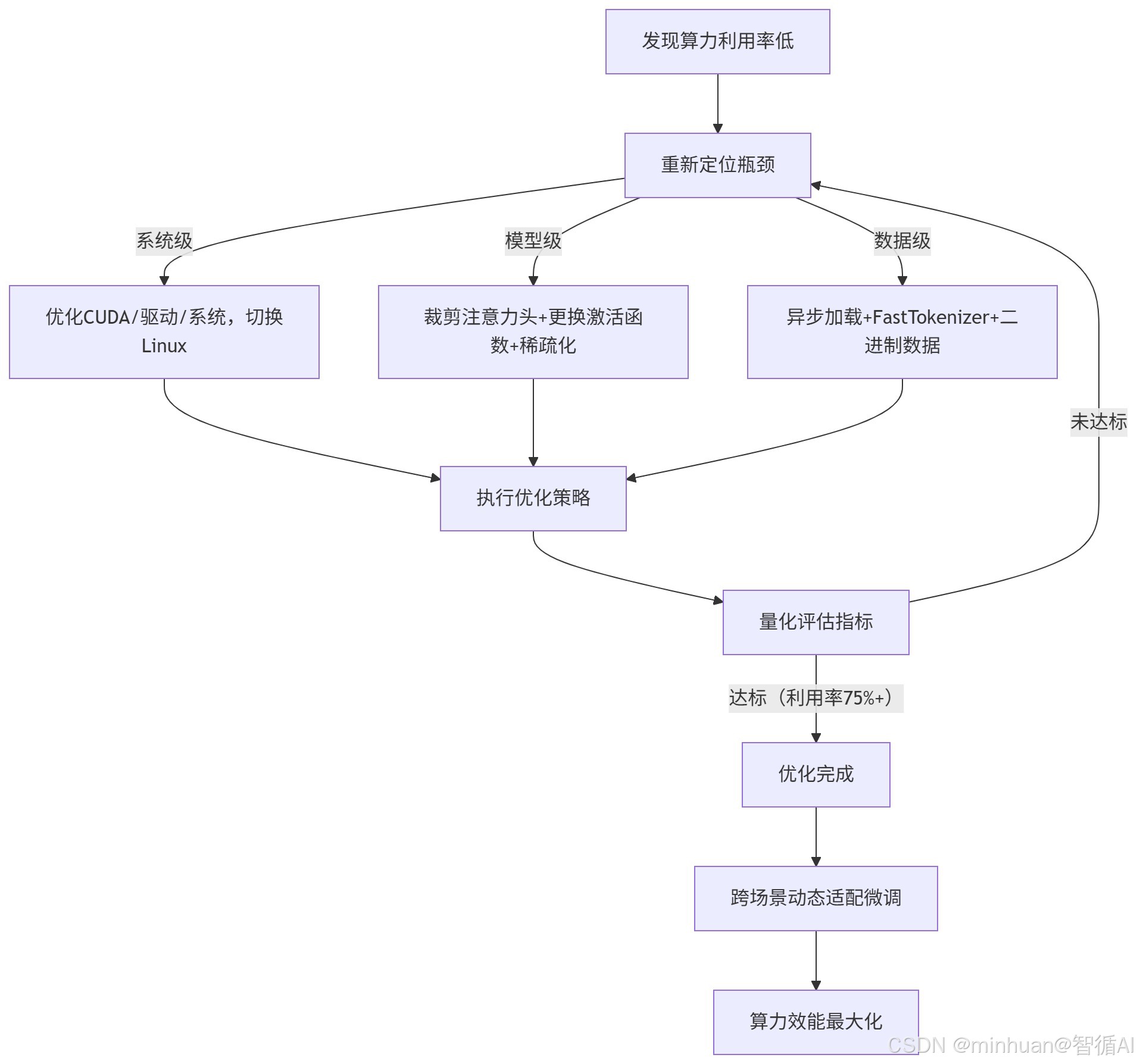
优化步骤说明:
- 1. 问题发现:监测到GPU算力利用率低于预期(如<30%)
- 2. 瓶颈定位:诊断问题根源的三个层级:
- 系统级:CUDA、驱动、操作系统层面问题
- 模型级:模型架构设计导致的效率问题
- 数据级:数据加载和处理流程的瓶颈
- 3. 针对性优化:根据定位结果执行具体优化措施
- 4. 效果评估:检查算力利用率是否达到目标(75%+)
- 5. 迭代优化:未达标则重新诊断,达标后进一步微调
- 6. 效能最大化:实现跨场景的最佳性能表现
优化策略详解:
- 系统级优化:基础环境调优,如切换Linux系统获得更好的CUDA支持
- 模型级优化:调整模型结构,如减少注意力头数、使用更高效的激活函数
- 数据级优化:改进数据流水线,如异步数据加载、使用快速分词器
2. 优化工具
2.1 瓶颈定位工具
2.1.1 nvidia-smi:算力体温计,看整体是否发烧或低烧
- 实时查看 GPU 的宏观运行状态,包括:
- GPU 利用率(utilization.gpu):核心计算单元忙不忙?
- 显存使用量(memory.used):占了多少显存?
- 显存带宽利用率(utilization.memory):数据搬运是否成瓶颈?
- 功耗、温度、进程占用等。
- 特点:
- 轻量、无侵入、秒级刷新(如 nvidia-smi -l 1)
- 无法告诉你“为什么”利用率低——只能看到结果,不能定位原因。
- 典型用途:
- 快速判断 GPU 是否“真在干活”(比如利用率长期 <30%,说明有瓶颈)
- 监控多卡任务是否均衡
- 排查是否有其他进程偷偷占用 GPU
一句话总结:它是你每天必看的“健康仪表盘”,但不是“诊断医生”。
2.1.2 PyTorch Profiler:模型“CT 扫描仪”,看清每一层花了多少时间
- 精细记录 PyTorch 模型每个算子(op)、每层网络、每次 forward/backward 的耗时与内存占用,支持:
- CPU 与 GPU 时间对齐
- 内存分配追踪
- 算子调用栈可视化(通过 TensorBoard)
- 特点:
- 与 PyTorch 原生集成,无需改模型结构
- 可直接定位“哪一层最慢”,如注意力计算、LayerNorm、Embedding 查找
- 有一定性能开销(建议只 profiling 几个 step)
- 典型用途:
- 发现模型中的“慢操作”(如未融合的 attention、频繁 host-device 数据拷贝)
- 验证优化是否生效(如开启 torch.compile 后提速多少)
- 分析内存峰值来源
一句话总结:当你怀疑“模型本身有问题”,就用它做一次深度体检。
2.1.3 nvprof / ncu(Nsight Compute):CUDA“显微镜”,深入硬件指令层
- 从 CUDA 内核(kernel)级别分析程序执行效率,可查看:
- Tensor Core 利用率(如 tensor_precision_fu_utilization)
- SM(流多处理器)占用率、指令吞吐、内存事务效率
- 是否存在 warp divergence、bank conflict 等底层问题
- 特点:
- 能回答“为什么张量核心没跑满?”、“FP16 是否真正生效?”
- 适用于验证 CUDA 版本、驱动、算子库(cuBLAS/cuDNN)是否适配
- 使用复杂、性能开销大,仅用于调试,不可用于生产监控
- nvprof 有版本差异,新版本请用 ncu(Nsight Compute)或 nsys(Nsight Systems)
- 典型用途:
- 验证 INT4/FP8 是否真正触发 Tensor Core 加速
- 对比不同 CUDA 版本下 kernel 性能差异
- 诊断“GPU 利用率高但吞吐低”的微架构级原因
一句话总结:这是给“硬核调优者”用的终极武器,用于确认底层硬件是否被充分利用。
最佳实践:先用 nvidia-smi 发现异常;再用 PyTorch Profiler 定位模型瓶颈;最后用 ncu 验证底层硬件是否被高效利用。三层联动,才能实现“从现象到根因”的完整诊断闭环。
2.2 量化优化工具
2.2.1 BitsAndBytes:“开箱即用”的轻量量化利器
- 核心能力:
- 提供 INT8 和 INT4 量化,特别适合在消费级 GPU(如 RTX 30/40 系列)上快速运行大模型(如 Llama、Mistral)。
- 优势:
- 集成简单:只需一行代码(load_in_4bit=True)即可加载 4-bit 模型
- 内存节省显著:7B 模型从 ~14GB 显存降至 ~6GB,普通显卡也能跑
- 兼容 Hugging Face Transformers,支持大多数开源模型
- 局限性:
- 推理速度提升有限(主要省显存,未深度优化计算路径)
- 不支持 TensorRT 或 CUDA kernel 定制,吞吐不如专用方案
- 适用场景:
- 个人开发者、研究者快速部署大模型;资源受限环境下的原型验证。
2.2.2 GPTQ:“高精度+加速”兼顾的量化方案
- 核心能力:
- 对模型进行逐层权重量化 + 误差补偿训练,实现 INT4 精度接近 FP16 效果,同时通过定制 CUDA kernel 加速推理。
- 优势:
- 量化后精度损失极小(通常 <1% 准确率下降)
- 推理速度明显快于 BitsAndBytes(因使用高效 kernel)
- 支持 AutoGPTQ、ExLlama 等高性能推理后端,QPS 更高
- 局限性:
- 量化过程耗时较长(需对整个数据集做校准)
- 主要适用于仅权重量化(激活仍为 FP16),不支持动态激活量化
- 适用场景:
- 需要在消费级 GPU 上兼顾低显存 + 高推理速度 + 高精度的生产部署(如本地 AI 助手、边缘服务)。
2.2.3 TensorRT:NVIDIA 企业级“终极加速器”
- 核心能力,NVIDIA 官方推理优化框架,支持:
- FP8 / INT8 / INT4 量化
- 算子融合(kernel fusion)
- 动态批处理、PagedAttention、多GPU并行
- 针对 LLM 的专用优化库 TensorRT-LLM
- 优势:
- 极致性能:在 A100/H100 上,比原生 PyTorch 快 3~8 倍
- 与 Triton Inference Server 无缝集成,支持高并发、低延迟企业部署
- 支持结构化稀疏、KV Cache 优化等高级特性
- 局限性:
- 仅支持 NVIDIA GPU(Ampere 架构及以上效果最佳)
- 配置复杂,需导出 ONNX → 构建 TRT 引擎,调试成本高
- 开源模型需适配 TensorRT-LLM 的模型定义
- 适用场景:
- 云服务商、大厂 AI 平台、高 QPS API 服务(如智能客服、搜索推荐)等企业级推理场景。
2.3 调度监控工具
- NVIDIA Triton:企业级推理服务器,支持动态批处理与负载均衡;
- Prometheus+Grafana:集群算力监控,可视化展示多卡运行状态
- Dataloader:PyTorch内置,优化数据加载效率,解决数据级瓶颈
六、总结
其实大模型算力优化,本质不是堆硬件,而是把现有硬件的潜力榨干,关键就抓三条:找对瓶颈、按需适配、量化验证,这也是从理论落地到实战的核心逻辑。很多人一遇到算力不够就想换显卡,殊不知80%的浪费都来自隐性瓶颈:系统级的CUDA、驱动适配不到位,会直接屏蔽显卡一半性能;模型里的QKV冗余运算、权重浪费,默默消耗着40%算力;就连数据加载慢,都能让GPU陷入等数据的空转状态。
优化的核心思路的是对症下药,不同场景有不同玩法。个人开发者不用硬追高端卡,靠INT4量化+模型裁剪,16GB显存也能稳跑13B模型,轻微牺牲效果换低成本落地;企业高并发场景,重点在调度,动态批处理+负载均衡能让集群算力利用率从60%拉满到85%;边缘部署则要平衡功耗与延迟,量化+蒸馏双管齐下,让大模型在嵌入式设备上高效运行。
还要记住,优化效果不能凭感觉,算力利用率、显存周转率、Token算力成本这三个指标,是检验优化价值的硬标准。用NVIDIA-smi、PyTorch Profiler这些工具定位瓶颈,再针对性优化,比盲目调参高效得多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)