【Daily Report | 2026-01-24】
题单二总结DAY01
复习内容
学习内容
1.P1553 数字反转(升级版)
2.P3375 【模板】KMP
一、题目
P1553 数字反转(升级版)
题目背景
以下为原题面,仅供参考:
给定一个数,请将该数各个位上数字反转得到一个新数。
这次与 NOIp2011 普及组第一题不同的是:这个数可以是小数,分数,百分数,整数。整数反转是将所有数位对调;小数反转是把整数部分的数反转,再将小数部分的数反转,不交换整数部分与小数部分;分数反转是把分母的数反转,再把分子的数反转,不交换分子与分母;百分数的分子一定是整数,百分数只改变数字部分。整数新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零;小数新数的末尾不为 0 0 0(除非小数部分除了 0 0 0 没有别的数,那么只保留1个 0 0 0);分数不约分,分子和分母都不是小数(约分滴童鞋抱歉了,不能过哦。输入数据保证分母不为 0 0 0),本次没有负数。
题目描述
给定一个数,请将该数各个位上数字反转得到一个新数。
这次与 NOIp2011 普及组第一题不同的是:这个数可以是小数,分数,百分数,整数。
-
整数反转是将所有数位对调。
-
小数反转是把整数部分的数反转,再将小数部分的数反转,不交换整数部分与小数部分。
-
分数反转是把分母的数反转,再把分子的数反转,不交换分子与分母。
-
百分数的分子一定是整数,百分数只改变数字部分。
输入格式
一个实数 s s s
输出格式
一个实数,即 s s s 的反转数
输入输出样例 #1
输入 #1
5087462
输出 #1
2647805
输入输出样例 #2
输入 #2
600.084
输出 #2
6.48
输入输出样例 #3
输入 #3
700/27
输出 #3
7/72
输入输出样例 #4
输入 #4
8670%
输出 #4
768%
说明/提示
【数据范围】
- 对于 25 % 25\% 25% 的数据, s s s 是整数,不大于 20 20 20 位;
- 对于 25 % 25\% 25% 的数据, s s s 是小数,整数部分和小数部分均不大于 10 10 10 位;
- 对于 25 % 25\% 25% 的数据, s s s 是分数,分子和分母均不大于 10 10 10 位;
- 对于 25 % 25\% 25% 的数据, s s s 是百分数,分子不大于 19 19 19 位。
【数据保证】
-
对于整数翻转而言,整数原数和整数新数满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数和原来的数字的最高位数字不应为零。
-
对于小数翻转而言,其小数点前面部分同上,小数点后面部分的形式,保证满足小数的常见形式,也就是末尾没有多余的 0 0 0(小数部分除了 0 0 0 没有别的数,那么只保留 1 1 1 个 0 0 0。若反转之后末尾数字出现 0 0 0,请省略多余的 0 0 0)
-
对于分数翻转而言,分数不约分,分子和分母都不是小数。输入的分母不为 0 0 0。与整数翻转相关规定见上。
-
对于百分数翻转而言,见与整数翻转相关内容。
数据不存在负数。
Tips
string t.end()和t.back()的区别:t.end()返回的是迭代器,表示最后一个字符的后一个位置(不能当字符用)t.back()返回的是最后一个字符的具体值(char)
reverse(t.begin(), t.end())的含义: 将 string 的 [begin, end)
区间整体反转,也就是把字符串前后颠倒
s.substr(0, s.size() - 1)的含义:substr(pos, len)从下标pos开始,连续取len个字符
所以上面这句表示:从第 0 个字符开始,取到倒数第二个字符string 既支持下标也支持迭代器: 下标访问:s[i] 迭代器访问:s.begin(), s.end()
下标用于取值,迭代器用于算法(如 reverse、sort)
s.find('.') != string::npos的含义: find 用来查找字符或字符串 如果找不到,返回 string::npos
所以这个判断表示:字符串中存在字符 ‘.’
完整代码
#include<bits/stdc++.h>
using namespace std;
> 处理0在前面情况
string rev(string t){
reverse(t.begin(),t.end());
int i=0;
while(i+1<t.size() && t[i]=='0')i++;
return t.substr(i);
}
> 处理0在后面情况 小数
string rev_x(string t){
reverse(t.begin(),t.end());
int i =0;
while(t.size()>1 && t.back()=='0')t.pop_back();
return t;
}
string s;
int main(){
while(cin>>s){
if(s.find('%')!=string::npos){
string a = s.substr(0,s.size()-1);
cout<<rev(a)<<'%';
continue;
}
if(s.find('/')!=string::npos){
int p = s.find('/');
string a = s.substr(0,p);
string b = s.substr(p+1);
cout<<rev(a)<<'/'<<rev(b);
continue;
}
if(s.find('.') != string :: npos){
int p = s.find('.');
string a = s.substr(0,p);
string b = s.substr(p+1);
cout<<rev(a)<<'.'<<rev_x(b);
continue;
}
cout<<rev(s);
}
return 0;
}
P3375 【模板】KMP
题目描述
给出两个字符串 s 1 s_1 s1 和 s 2 s_2 s2,若 s 1 s_1 s1 的区间 [ l , r ] [l, r] [l,r] 子串与 s 2 s_2 s2 完全相同,则称 s 2 s_2 s2 在 s 1 s_1 s1 中出现了,其出现位置为 l l l。
现在请你求出 s 2 s_2 s2 在 s 1 s_1 s1 中所有出现的位置。
定义一个字符串 s s s 的 border 为 s s s 的一个非 s s s 本身的子串 t t t,满足 t t t 既是 s s s 的前缀,又是 s s s 的后缀。
对于 s 2 s_2 s2,你还需要求出对于其每个前缀 s ′ s' s′ 的最长 border t ′ t' t′ 的长度。
输入格式
第一行为一个字符串,即为 s 1 s_1 s1。
第二行为一个字符串,即为 s 2 s_2 s2。
输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 s 2 s_2 s2 在 s 1 s_1 s1 中出现的位置。
最后一行输出 ∣ s 2 ∣ |s_2| ∣s2∣ 个整数,第 i i i 个整数表示 s 2 s_2 s2 的长度为 i i i 的前缀的最长 border 长度。
输入输出样例 #1
输入 #1
ABABABC
ABA
输出 #1
1
3
0 0 1
说明/提示
样例 1 解释
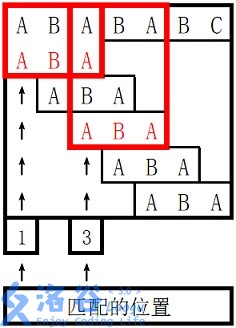 。
。
对于 s 2 s_2 s2 长度为 3 3 3 的前缀 ABA,字符串 A 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 1 1 1。
数据规模与约定
本题采用多测试点捆绑测试,共有 4 个子任务。
- Subtask 0(30 points): ∣ s 1 ∣ ≤ 15 |s_1| \leq 15 ∣s1∣≤15, ∣ s 2 ∣ ≤ 5 |s_2| \leq 5 ∣s2∣≤5。
- Subtask 1(40 points): ∣ s 1 ∣ ≤ 10 4 |s_1| \leq 10^4 ∣s1∣≤104, ∣ s 2 ∣ ≤ 10 2 |s_2| \leq 10^2 ∣s2∣≤102。
- Subtask 2(30 points):无特殊约定。
- Subtask 3(0 points):Hack。
对于全部的测试点,保证 1 ≤ ∣ s 1 ∣ , ∣ s 2 ∣ ≤ 10 6 1 \leq |s_1|,|s_2| \leq 10^6 1≤∣s1∣,∣s2∣≤106, s 1 , s 2 s_1, s_2 s1,s2 中均只含大写英文字母。
Tips
在 KMP 算法中,代码通常分为两个核心过程,但它们的本质是一样的,都是围绕
next数组展开的。第一个过程是构建 next 数组。它通过让模式串与自身进行比较,计算模式串每一个前缀的最长相等前后缀(border)长度,并将结果存入next 数组。这个过程只与模式串本身有关,目的是在发生失配时,为模式串提供一个可以快速回退的位置,从而避免重复比较。
第二个过程是 KMP 的匹配阶段。在这一阶段中,利用已经计算好的 next数组,让模式串在主串中进行匹配。主串指针始终向前移动,不会回退;而模式串指针在失配时,根据 next数组进行回退。当模式串指针到达末尾时,说明找到了一次完整匹配。匹配阶段并不会重新计算 next 数组,而是将其作为失配时的回退规则直接使用。
总体来说,KMP 算法的核心思想就是:先通过模式串自身构建 next 数组,再利用 next 数组指导模式串在主串中的高效匹配。
完整代码
#include<bits/stdc++.h>
using namespace std;
vector<int> getnext(string s2){
int m = s2.size();
vector<int>next(m+1,0);
int j = 0;
for(int i =1;i<m;i++){
while(s2[i]!=s2[j] && j>0){
j = next[j-1];
}
if(s2[i]==s2[j]){
j++;
}
next[i]=j;
}
return next;
}
vector<int>KMP(string s1,string s2){
int n =s1.size() , m =s2.size();
vector<int>next = getnext(s2);
vector<int>result;
int j = 0;
for(int i =0;i<n;i++){
while(j>0&&s1[i]!=s2[j]){
j = next[j-1];
}
if(s1[i]==s2[j]){
j++;
}
if(j==m){
result.push_back(i-m+2);
j = next[j-1];
}
}
return result;
}
int main(){
string s1="" ,s2 = "";
cin>>s1>>s2;
vector<int> positions = KMP(s1, s2);
for (int pos : positions) {
cout << pos << endl;
}
vector<int> next = getnext(s2);
for (int i = 0; i < s2.size(); i++) {
cout << next[i] << " ";
}
cout << endl;
return 0;
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)