AAAI2025、POF | 西湖大学冯浩东、范迪夏等:如何在不准确物理信息和部分观测下利用物理信息建模流体力学系统
在科学和工程领域,机器学习技术在流体力学系统建模方面取得了显著进展。将物理损失作为系统演化的约束能有效克服数据稀缺导致的泛化问题,提升模型预测能力,这在数据获取成本高昂的情况下尤为重要。然而,现实场景中,传感器限制导致我们往往只能获得部分观测数据,这使物理损失的计算变得不可行,因为物理损失计算通常依赖于高分辨率状态,使用部分观测数据计算的物理损失有很大的偏差。针对这一挑战,我们提出了在部分观测下重
How to Re-enable PDE Loss for Physical Systems Modeling Under Partial Observation
冯浩东,汪跃*,范迪夏*
Physics-informed Super-resolution and Forecasting Method based on Inaccurate Partial Differential Equations and Partial Observation
冯浩东,胡佩炎,汪跃*,范迪夏*,吴泰霖*,张羽中*

引用格式:
1.Feng, H., Hu, P., Wang, Y., Fan, D., Wu, T., & Zhang, Y. (2025). Physics-informed super-resolution and forecasting method based on inaccurate partial differential equations and partial observation. Physics of Fluids, 37(6).2. Feng, H., Wang, Y., & Fan, D. (2025, April). How to re-enable PDE loss for physical systems modeling under partial observation. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 39, No. 1, pp. 182-190).
摘要
在科学和工程领域,机器学习技术在流体力学系统建模方面取得了显著进展。将物理损失作为系统演化的约束能有效克服数据稀缺导致的泛化问题,提升模型预测能力,这在数据获取成本高昂的情况下尤为重要。然而,现实场景中,传感器限制导致我们往往只能获得部分观测数据,这使物理损失的计算变得不可行,因为物理损失计算通常依赖于高分辨率状态,使用部分观测数据计算的物理损失有很大的偏差。针对这一挑战,我们提出了在部分观测下重新启用物理损失的深度学习框架 (RPLPO)。其核心理念是:虽然单纯依靠部分观测无法直接利用物理损失来约束系统演化,但我们可以通过重建可学习的高分辨率状态,并同时利用这些状态约束系统演化,从而重新启用物理损失。具体而言,RPLPO整合了用于重建可学习高分辨率状态的编码模块和预测未来状态的演化模块,这两个模块通过数据损失和物理损失进行联合训练。此外,通过引入由物理损失优化的参数学习机制,我们进一步提出了PIPO,实现了在部分观测数据上利用不准确物理方程计算损失的能力。我们在多个流体力学系统的仿真数据上进行了广泛验证,包括Burgers方程、Navier-Stokes方程、波动方程、线性浅水波方程和非线性浅水波方程。实验结果表明,即使在观测稀疏、不规则或存在噪声的情况下,我们的算法仍能显著提升模型的泛化能力。同时,我们将方法应用于真实采集的中国长三角地区污染物浓度观测数据 (PM2.5)。污染物浓度的传输过程受风场影响,理论上遵循对流扩散方程,但扩散系数和源项未知,该场景具体十分稀疏和物理方程不准确的特征和挑战。实验证明,我们的方法能有效提高污染物浓度场的预测准确性,展示了该算法在实际应用中的优越性能。
背景与挑战
在科学和工程领域,物理系统的建模与预测一直是研究的核心问题。随着机器学习技术的快速发展,其在物理系统建模中的应用逐渐受到关注。传统的数值方法虽然能够精确求解物理系统的动态,但往往计算成本高昂,难以实时处理大规模数据。相比之下,机器学习方法具有高效性,能够从有限的数据中学习系统的动态规律,从而实现快速预测和分析。然而,在实际应用中,机器学习方法面临着诸多挑战,其中最为突出的是观测数据的不完整性和物理规律描述的不准确性。
首先,观测数据的不完整性是物理系统建模中的一个关键问题。在许多实际场景中,由于传感器分布有限或测量成本高昂,我们只能获取部分空间位置的观测数据,而无法获得完整的高分辨率状态。这种数据稀疏性不仅限制了模型的泛化能力,还可能导致模型在未观测区域的预测出现较大误差。例如,在大气污染监测中,监测站点的分布通常是不均匀的,城市中心区域监测站点密集,而偏远地区则几乎没有监测站点。这种不规则的部分观测使得传统的插值方法难以准确重建高分辨率的浓度场。另外,部分观测会影响PDE loss的准确性,从而带来误差。具体来说,PDE loss的计算依赖于高分辨率状态的导数信息,而部分观测数据的缺失会导致这些导数信息的不准确,进而影响模型的训练效果。例如,在计算浓度场的扩散项时,如果观测数据过于稀疏,模型可能无法准确捕捉到浓度梯度的变化,从而导致PDE loss的偏差。
其次,物理规律描述的不准确性也是建模中的一大挑战。物理系统的动态通常由偏微分方程(PDE)来描述,但在实际应用中,PDE的参数(如扩散系数、源项等)往往是未知的,或者由于外部因素的影响而存在偏差。例如,在空气污染物的传输过程中,污染物的扩散系数可能受到风场、温度层结等多种因素的影响,难以精确测量。此外,PDE中的源项也可能由于排放源的不确定性而难以准确描述。这些不准确性导致PDE本身存在偏差,进而影响模型的预测精度。
为了应对上述挑战,两篇文章分别提出了RPLPO(Re-enable PDE Loss under Partial Observation)和PIPO(Physics-Informed method based on Inaccurate PDEs and Partial Observation)两种算法。这两种算法都旨在通过结合机器学习和物理信息,提升模型在复杂物理系统中的泛化能力和预测精度。RPLPO首先解决了假设有准确的物理信息如何提高部分观测模型的泛化性,避免由于部分观测导致的PDE loss的误差。之后,在RPLPO的基础上,PIPO解决了不准确的物理信息如何在部分观测中使用。
1.RPLPO:
方法:
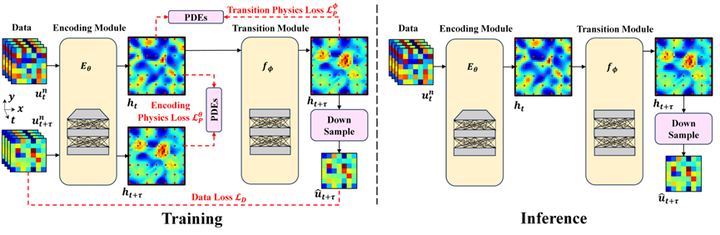
RPLPO框架的核心目标是通过重建高分辨率状态来重新利用PDE loss,从而提升模型在部分观测数据下的泛化能力。该框架通过结合编码模块和转换模块,有效地利用部分观测数据和物理规律,解决了部分观测导致的PDE loss误差问题。RPLPO框架包含两个主要模块:编码模块(Encoding Module)和转换模块(Transition Module)。这两个模块通过data loss和PDE loss联合训练,以充分利用部分观测数据和物理规律。具体来说,编码模块负责从部分观测数据中重建高分辨率状态,而转换模块则基于重建的高分辨率状态预测未来状态。RPLPO框架的训练分为两个阶段:
1.基础训练阶段(Base-training Period):编码模块通过PDE loss进行训练,而转换模块则通过数据损失和PDE loss联合训练。
2.两阶段微调阶段(Two-stage Fine-tuning Period):利用无标签数据进行半监督学习,进一步提升模型的泛化能力。
编码模块:编码模块的作用是从部分观测数据中重建高分辨率状态。具体来说,编码模块接收部分观测数据,并输出一个高分辨率的可学习状态,这一过程可以表示为:
其中,θ是编码模块的可训练参数。为了更好地利用时间信息,编码模块可以接收多个时间步的观测数据,从而更准确地重建高分辨率状态。这种多时间步的输入方式有助于模型捕捉时间序列中的动态变化,减少部分观测带来的信息缺失。
转换模块:转换模块的作用是基于重建的高分辨率状态预测未来的高分辨率状态
。这一过程可以表示为:
其中,ϕ是转换模块的可训练参数。转换模块通常是一个神经网络,能够学习高分辨率状态之间的动态关系。通过这种方式,模型可以预测未来的时间步的状态,从而实现对未来部分观测状态的预测。
Data Loss: 用于衡量预测值与真实值之间的差异。具体来说,数据损失可以表示为:
Data loss通过最小化预测值和真实值之间的相对误差,确保模型的预测结果尽可能接近真实数据。
PDE Loss: 用于约束模型的物理一致性。具体来说,它可以表示为:
其中,是PDE的微分算子。PDE loss通过最小化预测状态和真实状态之间的PDE残差,确保模型的预测结果符合物理规律。
在基础训练阶段,编码模块和转换模块通过data loss和PDE loss联合训练。具体来说,编码模块通过PDE loss进行训练,而转换模块则通过data loss和PDE loss联合训练。这一阶段的目标是通过联合优化data loss和PDE loss,提升模型的泛化能力。在基础训练阶段之后,RPLPO框架利用无标签数据进行半监督学习,进一步提升模型的泛化能力。这一阶段分为两个阶段。在第一阶段微调中,转换模块通过PDE loss独立进行微调。在第二阶段微调中,编码模块通过data loss进行微调,从而与第一阶段微调的转换模块对齐。
实验与结果
为了验证RPLPO框架的有效性,我们在多个物理系统上进行了实验,包括Burgers方程、波动方程、Navier-Stokes方程、线性浅水方程和非线性浅水方程。这些实验涵盖了单步预测和多步预测,结果表明RPLPO在泛化能力上显著优于现有的基线方法。
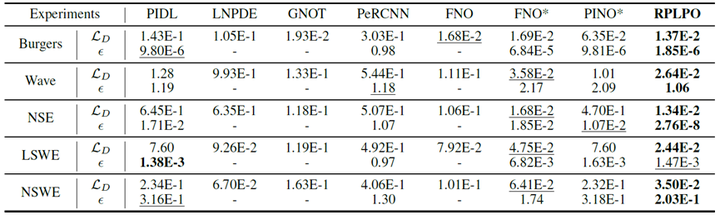
单步预测:表1显示了RPLPO与所有基线方法在五个基准测试上的相对损失和重建误差的结果。RPLPO在所有基准测试中均优于所有基线方法,平均性能提升超过25%。例如,在Navier-Stokes方程中,RPLPO的数据损失比第二好的方法FNO*低约60%,在波动方程中,RPLPO的重建误差ϵ比第二好的方法PINO*低约60%。
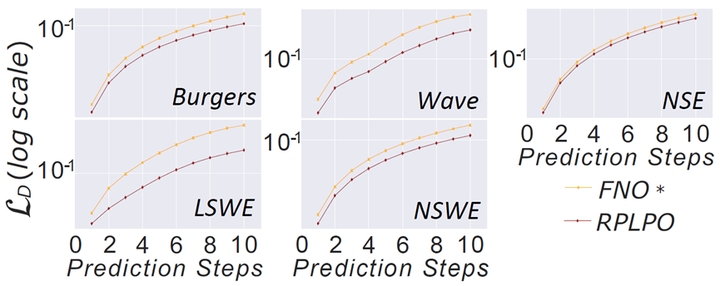
多步预测:图2展示了RPLPO与FNO*(基线方法中表现最好的)在所有基准测试中的多步预测结果。RPLPO在所有预测步数上均显著优于FNO*,随着预测步数的增加,性能差距逐渐增大。例如,在Navier-Stokes方程中,RPLPO在第10步预测时的误差比FNO*低约70%。这表明RPLPO能够更好地维持长期预测的精度。
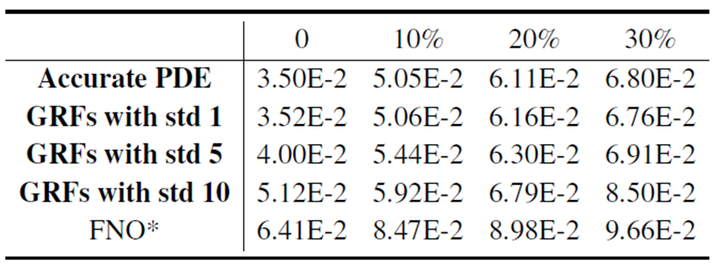

不规则观测和噪声数据:表2和表3展示了RPLPO在不规则观测和噪声数据下的性能。结果表明,RPLPO在不规则观测和噪声数据下仍然能够保持良好的性能,优于其他基线方法。例如,在非线性浅水方程中,RPLPO在不规则观测下的误差比第二好的方法低约40%。
2.PIPO:
除了部分观测的挑战,现实世界中的物理系统往往还面临着另一个挑战——PDE的不准确性。这些PDE可能由于未知的参数、外部因素的干扰或模型简化而存在偏差。为了解决这一问题,PIPO(Physics-Informed method based on Inaccurate PDEs and Partial Observation)方法应运而生。PIPO不仅继承了RPLPO在处理部分观测数据方面的优势,还进一步扩展了其能力,使其能够应对不准确的PDE。PIPO的核心在于利用不准确的PDE信息和部分观测数据,同时实现超分辨率重建和未来状态预测。这一方法通过引入插值器、编码器、预测器、解码器和参数学习器,构建了一个综合的框架,能够从部分观测数据中重建高分辨率状态,并基于这些状态进行未来状态的预测,同时通过参数学习器动态调整PDE中的未知参数,从而更好地适应实际物理系统的复杂性。
方法:PIPO利用不准确的PDE信息和部分观测数据,同时实现超分辨率重建和未来状态预测。PIPO框架包含五个主要模块:插值器(Interpolator)、编码器(Encoder)、预测器(Forecaster)、解码器(Decoder)和参数学习器(Parameters Learner)。这些模块通过data loss和PDE loss联合优化,实现从部分观测到高分辨率重建和未来预测的全流程建模。
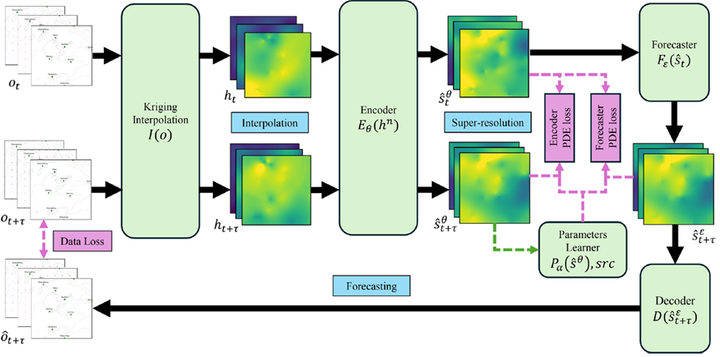
插值器(Interpolator):由于部分观测数据通常非常稀疏,直接使用这些数据作为输入可能会导致梯度消失和过拟合问题。因此,PIPO引入了一个插值器,使用插值方法(如Kriging插值)对部分观测数据进行预处理,增强模型的表达能力。插值器的输出可以表示为:
其中是部分观测数据,I是插值器。
编码器(Encoder):编码器的作用是从插值后的数据中重建高分辨率状态。为了更好地利用历史信息,编码器接收多个时间步的插值数据,并输出高分辨率状态
。这一过程可以表示为:
其中θ是编码器的可训练参数。
预测器(Forecaster):预测器的作用是基于重建的高分辨率状态预测未来的高分辨率状态。这一过程可以表示为:
其中,ε是预测器的可训练参数。预测器通常是一个神经网络,能够学习高分辨率状态之间的动态关系。
解码器(Decoder):解码器的作用是将预测的高分辨率状态下采样为部分观测数据
。这一过程可以表示为:
参数学习器(Parameters Learner):由于PDE中的参数(如扩散系数、源项等)通常是未知的,PIPO引入了一个参数学习器,用于学习这些参数。参数学习器的输出可以表示为:
其中,α是参数学习器的可训练参数,是学习到的扩散系数。PIPO通过data loss和PDE loss联合训练所有模块。Data loss 用于衡量预测值与真实值之间的差异,而PDE loss
和
则分别用于约束编码器和预测器的物理一致性。具体来说,PDE loss可以表示为:
通过联合优化data loss和PDE loss,PIPO能够有效地利用不准确的PDE信息和部分观测数据,提升模型的超分辨率重建和未来状态预测能力.
实验与结果:
为了验证PIPO方法的有效性,我们在真实测量的空气污染物浓度场(如PM2.5传输动态)和风场建模中进行了验证。这些场景具有典型的部分观测和不准确PDEs特征,结果表明PIPO在超分辨率重建和未来状态预测方面表现出色。
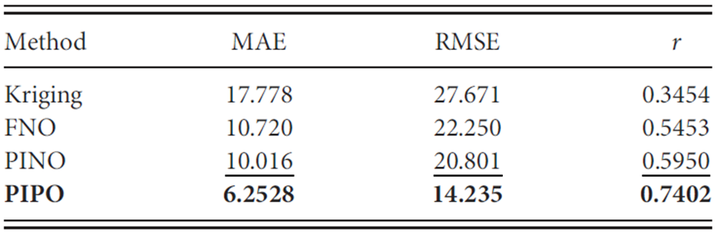
PIPO能够从稀疏的部分观测中准确重建高分辨率的浓度场,相比传统方法(如Kriging插值、U-Net等)显著提高了重建精度。例如,在表4中,PIPO在均方误差(MAE)、均方根误差(RMSE)和相关系数(r)三个评估指标上均优于所有基线方法。具体来说,PIPO相比最强的基线方法(PINO)在MAE、RMSE和相关系数(r)上分别提高了37.5%、31.5%和24.4%。当与传统的Kriging插值方法相比时,PIPO的性能提升更为显著,分别在三个指标上提高了81.5%、81.7%和270.6%。
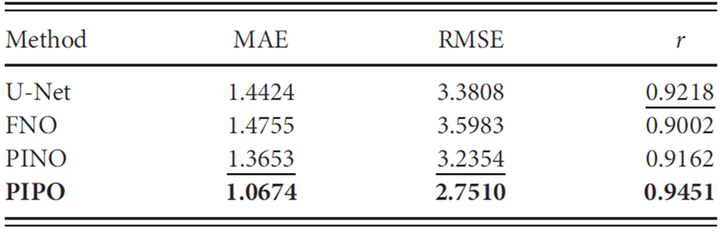
PIPO不仅能够重建当前状态,还能预测未来多个时间步的状态,且预测精度优于现有方法。例如,在表5中,PIPO在均方误差(MAE)、均方根误差(RMSE)和相关系数(r)三个评估指标上均优于所有基线方法。具体来说,PIPO相比最强的基线方法(PINO)在MAE、RMSE和相关系数(r)上分别降低了21.8%、15%和提高了3.2%。
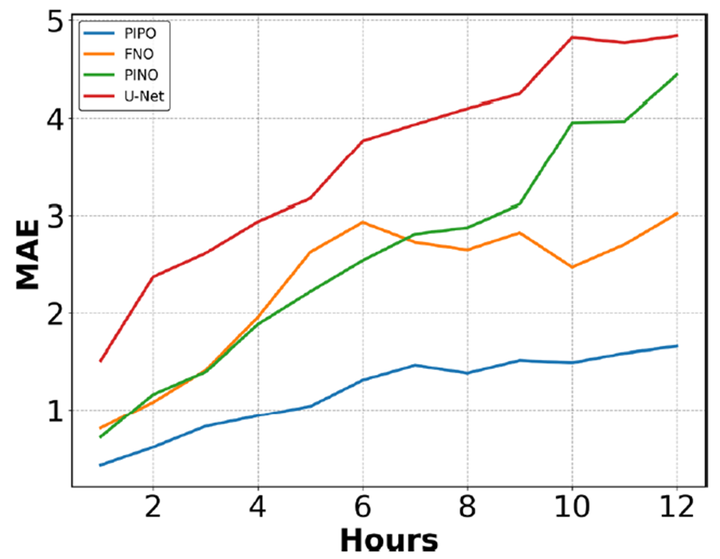
此外,PIPO在长达12小时的多小时预测中保持了较高的预测质量,展示了其在长期预测中的优势。如图6所示,PIPO在所有预测步数上均显著优于其他三种基线方法,且随着预测步数的增加,性能差距逐渐增大。
3.未来展望
RPLPO和PIPO方法在处理物理系统建模中的部分观测和不准确PDE问题上取得了显著进展。RPLPO通过引入编码模块和转换模块,有效地利用了部分观测数据和物理规律,显著提升了模型的泛化能力。PIPO则进一步扩展了这一思路,通过结合不准确的PDE信息和部分观测数据,同时实现超分辨率重建和未来状态预测。然而,尽管这些方法在理论和实验上都取得了成功,但物理系统建模领域仍有许多值得进一步探索的方向。
未来,我们将重点关注多物理场耦合和多尺度建模问题。许多实际物理系统涉及多个物理场的相互作用,如流体-结构相互作用和热-流耦合等,这些系统的物理规律复杂,且不同物理场之间的相互作用可能导致更显著的PDE不准确性。同时,许多物理系统还具有多尺度特征,例如大气污染传输中的微观扩散和宏观传输。我们将致力于开发能够同时处理多个物理场耦合的模型,并结合微观和宏观物理规律,实现从局部到全局的动态建模。通过动态调整不同物理场和不同尺度之间的信息传递,我们希望能够更全面地捕捉系统的动态行为,为解决实际物理系统建模中的复杂问题提供更全面和有效的解决方案。
此外,实时预测和反馈控制在许多实际应用中,如环境监测和工业过程控制,是关键需求。我们将开发能够实时处理观测数据并进行预测的模型,并结合反馈控制策略,实现对物理系统的动态调整。同时,我们也将探索如何在实时预测中引入不确定性量化,以提高反馈控制的可靠性。通过结合实时预测和反馈控制,我们希望能够为实际应用中的动态调整和优化提供支持,进一步推动物理系统建模领域的发展。
以上工作将于2025年中国力学大会,长沙,流体力学的人工智能方法专题研讨会中进行报告展示,编号为CSTAM-MS32-146-O,具体时间地点请参考会议日程。
公众号原文链接(文末附论文资源):
AAAI2025、POF | 西湖大学冯浩东、范迪夏等:如何在不准确物理信息和部分观测下利用物理信息建模流体力学系统
注:文章由作者原创供稿,并获得作者授权发布。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)