「Datawhale」RAG技术全栈指南 Task 3
向量嵌入与检索技术概述 向量嵌入(embedding)是将高维数据转换为低维稠密向量的技术,其核心在于使语义相似对象在向量空间中距离更近。衡量embedding质量的标准是相近词向量相似度是否更高。 相似度度量方法选择: 余弦相似度:适合文本检索、聚类/去重等场景 点积:L2归一化后等同于余弦相似度 欧式距离:适用于图像特征、度量学习等场景 向量检索技术: HNSW:多层近邻图结构,适合高召回+低
向量嵌入
概念
embedding是将真实世界中复杂、高维的数据对象转换为数学上易于处理的、低维、稠密的连续数值向量的技术。embedding的核心意义在于,它所构建的向量空间中,语义相似的对象得到的向量距离会更近,语义上不相关的对象向量距离会更远。
理解:
embedding是将文本/图像等人类能看懂的数据转换成计算中可量化的数据。
如何衡量一个embedding模型的好坏,是看相近词的向量相似度是否更高,无关词的向量相似度更低。
如何度量相似度?
- 余弦相似度/点积/欧氏距离
如何选择不同的度量方法?
- 余弦相似度(Cosine)
适合:语义相似、主题相近、同义表达匹配
○ 文本检索(FAQ/客服知识库/代码搜索/文档搜索)
○ 聚类/去重(同一语义不同写法)
○ 跨域长度差异大(短 query vs 长文档)
- 点积
○ 在做L2归一后,点积 = 余弦相似度
- 欧式距离
适合:向量在空间里的“位置差”有明确意义
○ 图像特征、度量学习(某些 triplet loss / contrastive loss 直接用 L2)
○ 下游算法天然基于距离(k-means 常用欧氏)
○ 在做异常检测/漂移检测,关心“偏离中心点有多远”
Embedding在RAG中的作用
- 语义检索的基础:所有需要和用户输入问题相关的查询/检索都是需要用embedding来进行表示和计算。
多模态embedding
- 多模态embedding表现形式是一致的,主要是将图片和文字的向量对齐在同一空间内。
向量数据库
解决的问题:如何快速、准确地从海量向量中找到与用户查询最相似的几个。
索引机制详解:
HNSW(Hierarchical Navigable Small World)
核心思想:把向量构造成多层的“近邻图”(小世界图)。查询时从顶层快速跳转到接近目标的区域,再在底层做更精细的图搜索。
适用场景:通用的向量检索,尤其是需要高召回 + 低延迟、数据规模中到大(百万级常见)。
优点
召回率高、延迟低,通常是工程上最“省心”的默认选择
支持多种距离(L2、inner product、cosine(通常通过归一化+IP))
增量插入相对友好(动态更新比 IVF 稳)
缺点
内存占用较大(图结构需要额外边)
构建时间可能较长;参数(如 M, efConstruction, efSearch)需要调优。
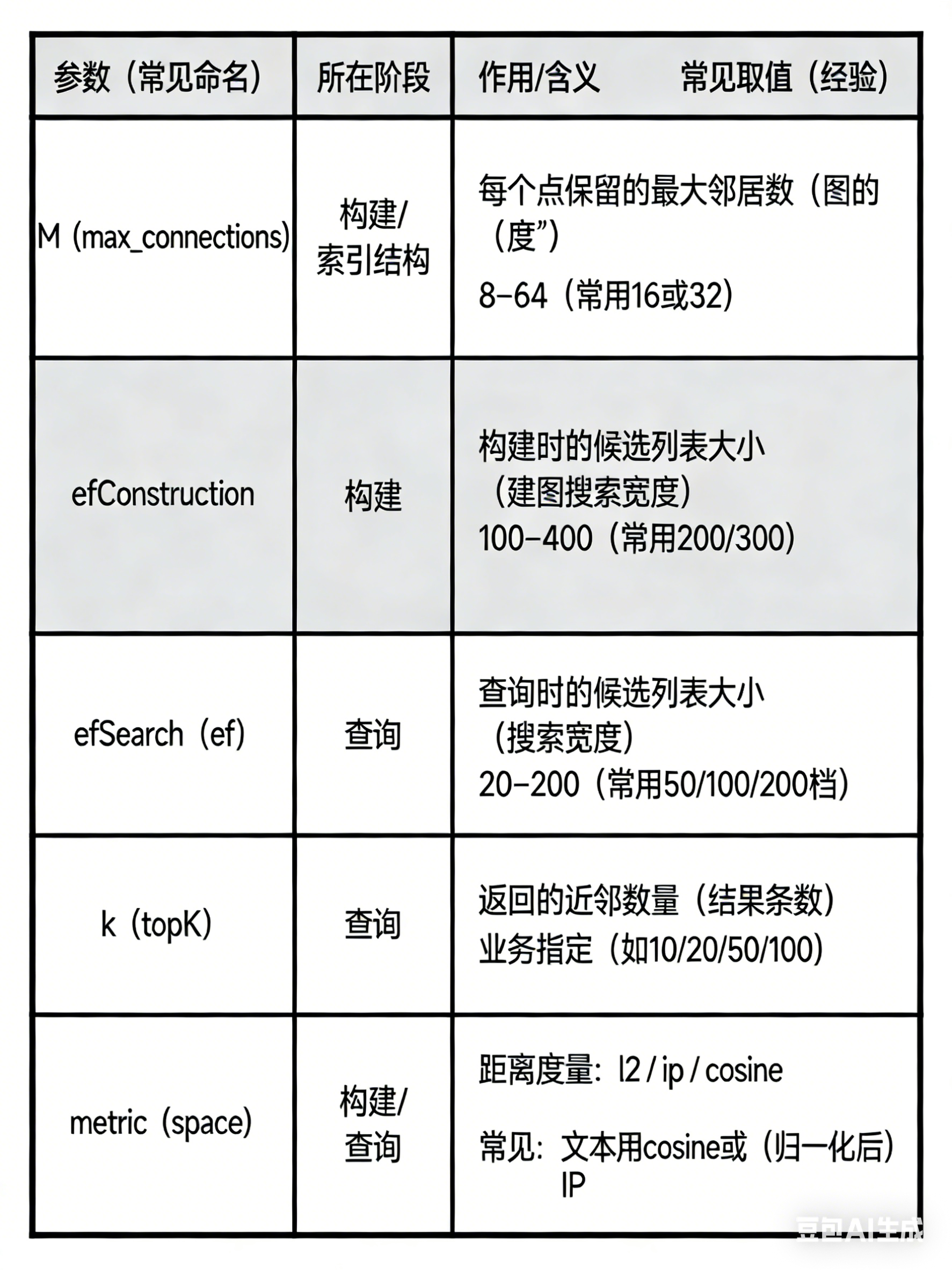
IVF(Inverted File Index,倒排文件/聚类分桶)
核心思想:先用 k-means 把向量分成很多“簇”(centroids),查询时先找离 query 最近的若干簇(nprobe),只在这些簇的候选集合里做精搜/重排。
适用场景:超大规模(百万到十亿级),希望用“先粗后细”控制计算量。
优点
可扩展性强,适合大数据量
通过 nlist(簇数)和 nprobe(探测簇数)在速度/召回之间做权衡
缺点
需要训练聚类中心(训练成本 + 数据分布变化会影响效果)
对动态更新/频繁插入不如 HNSW 友好(实现相关)
召回对 nprobe 很敏感:nprobe 小容易漏,nprobe 大延迟上升
练习:
1. LlamaIndex默认会将数据存储为透明可读的JSON格式,运行03_llamaindex_vector.py文件,查看保存的json文件内容。
• docstore.json
作用:保存内容本体。主要包括:
传入的 Document(text=...)
以及由 Document 转换/切分出来的 Node(例如 TextNode)
node_id → node 的映射(文本、metadata、关系)
理解:检索到候选 node_id 后,最终要用它来取回原文片段,作为上下文喂给 LLM。
• default__vector_store.json
作用:保存向量索引“真正用于相似度检索的数据”,通常包括:embedding 向量(浮点数组)和 node_id(向量对应哪个节点)
• index_store.json
作用:保存“索引的结构与配置”,例如:index_id、索引类型(VectorStoreIndex)索引里包含哪些 node_id,一些索引的组织结构信息(不同 Index 类型差异很大。
2. 新建一个代码文件实现对LlamaIndex存储数据的加载和相似性搜索。
API网址:https://llamaindex.readthedocs.io/zh/latest/reference/query/retrievers/vector_store.html
有两种写法:
retriever = index.as_retriever(similarity_top_k=3)
nodes = retriever.retrieve("张三是谁?")
for n in nodes:
print(n.score, n.node.text)直接写retriever用的是Llamaindex里面python实现的类似向量库查询的办法。
Faiss的写法:
from llama_index.core import VectorStoreIndex, StorageContext, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
texts = [
"张三是法外狂徒",
"FAISS是一个用于高效相似性搜索和密集向量聚类的库。",
"LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
]
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5")
dim = len(Settings.embed_model.get_text_embedding("测试"))
faiss_index = faiss.IndexFlatIP(dim)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(texts, storage_context=storage_context)
retriever = index.as_retriever(similarity_top_k=1)
nodes = retriever.retrieve("FAISS是做什么的?")
for n in nodes:
print(n.score, n.node.get_content())Milvus介绍及多模态检索实践
直接看对应章节,本章写的很好。
https://github.com/datawhalechina/all-in-rag/blob/main/docs/chapter3/09_milvus.md
注意事项⚠️:
现在docker启动Milvus后再运行代码,不然就会
索引优化
上下文扩展(句子窗口检索)
思路:为检索精确性而索引小块,为上下文丰富性而检索大块。
工作流程:
索引阶段:用句子作为索引,同时将句子的上下文窗口都存到元数据中,即该句子原文中的前N个和后N个句子。窗口文本不会作为索引,只是会作为元数据存储。
检索阶段:在单一句子节点上执行相似度搜索。
后处理阶段:用元数据,也就是包含检索句子的上下文数据来替换节点中原来单一的句子内容,传递给LLM。
我理解句子窗口检索的问题是根据位置来获取的上下文信息不一定是靠谱的,可以看一些其他论文看一下改进。
FreeChunker: A Cross-Granularity Chunking Framework https://arxiv.org/pdf/2510.20356
Reconstructing Context: Evaluating Advanced Chunking Strategies for Retrieval-Augmented Generation https://arxiv.org/abs/2504.19754
结构化索引
为了解决文档库中存在大量文档的情况,利用结构化索引。其原理是在索引文本块的同时,为其附加结构化的元数据(Metadata)
这些元数据可以是任何有助于筛选和定位信息的标签,例如:
• 文件名
• 文档创建日期
• 章节标题
• 作者
• 任何自定义的分类标签
重点就是先元数据过滤,再在过滤后的数据后做向量搜索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)