SearchClaw:将 Elasticsearch 通过可组合技能引入 OpenClaw
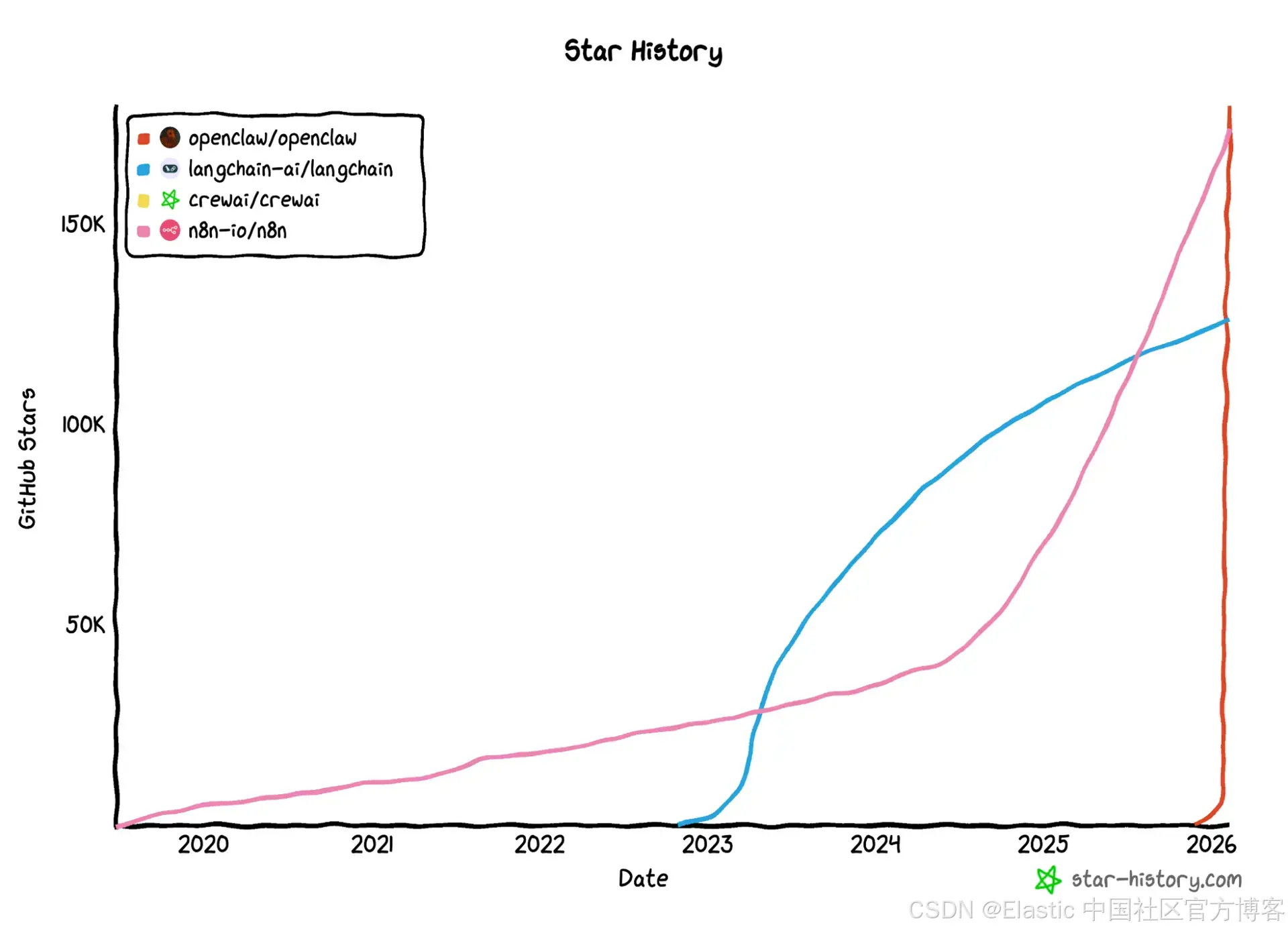
作者:来自 Elastic使用 OpenClaw、可组合技能和 agents,让你的本地 AI agent 访问 Elasticsearch 数据,无需编写自定义代码。Agent Builder 现已正式发布。你可以通过开始使用,并查看 Agent Builder 的文档。在最近几周,在 AI 社区讨论中频繁出现,特别是在关注 agents、自动化以及本地运行环境的开发者群体中。
作者:来自 Elastic Alex Salgado

使用 OpenClaw、可组合技能和 agents,让你的本地 AI agent 访问 Elasticsearch 数据,无需编写自定义代码。
Agent Builder 现已正式发布。你可以通过 Elastic Cloud Trial 开始使用,并在此查看 Agent Builder 的文档。
在最近几周,OpenClaw 在 AI 社区讨论中频繁出现,特别是在关注 agents、自动化以及本地运行环境的开发者群体中。该项目迅速获得关注,这自然引出了一个技术问题:
它为工程师解决了什么实际问题?
OpenClaw 是一个用于 AI agents 的自托管网关:一个统一的运行时,用于协调执行,将 agents 视为隔离的进程,并使用 skills(以 Markdown 文件形式编写的结构化指令)作为集成单元。从概念上讲,这与我们使用命令行接口(CLIs)和脚本的方式并没有完全不同,但现在它被正式化为以 agent 驱动的 workflows。
这也引发了在 Elastic Stack 中的一次实践探索:
如果我们将 OpenClaw 视为一个编排运行时,当 Elasticsearch 作为后端时它会如何表现?以及使用 OpenClaw skills 进行集成有多简单?
让我们使用 可组合技能(composable skills) 构建一个集成。
解决方案架构
在本教程中,我们将教 OpenClaw 通过一个自定义的只读技能访问并查询 Elasticsearch 数据,然后演示它如何将多个技能组合在一起;例如,将 Elasticsearch 查询与实时天气数据结合起来生成动态报告。
在进入实际操作步骤之前,先看看我们要构建的内容。该解决方案由三个集成层组成,它们通过 OpenClaw 编排协同工作。
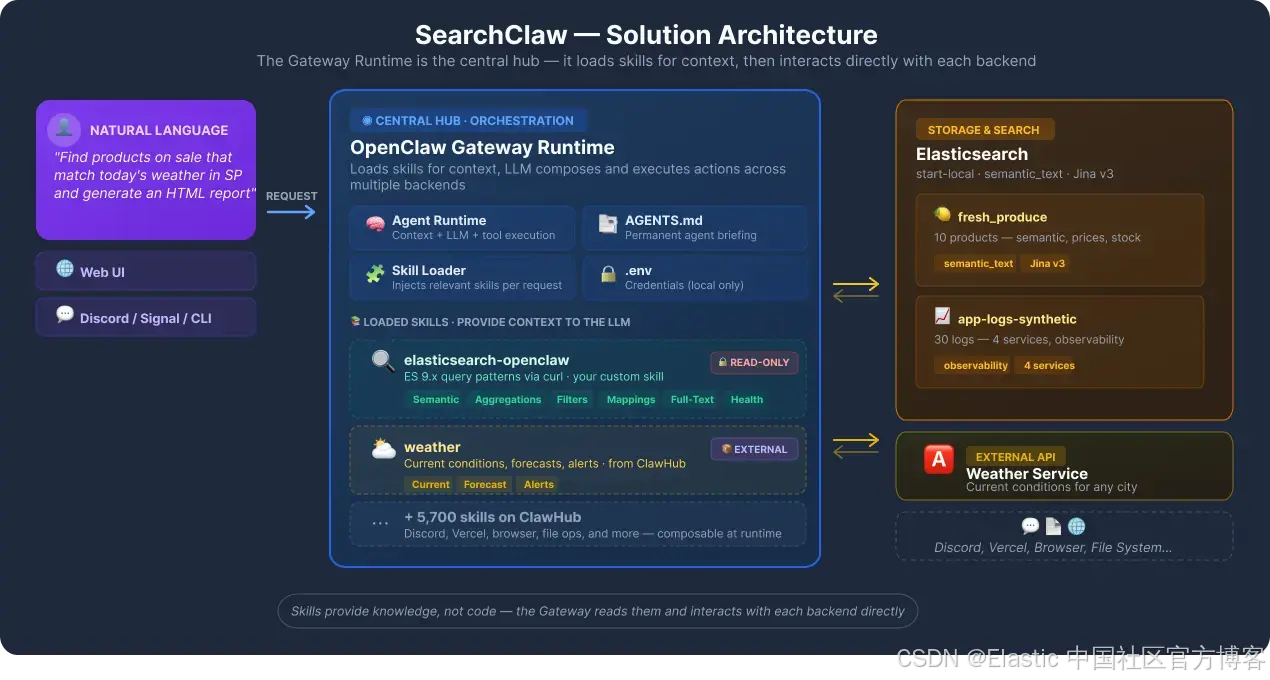
第 1 层:存储与搜索(Elasticsearch)
数据层运行在 Elasticsearch 上,通过 start-local 启动,只需一条命令即可使用 Docker 在本地启动 Elasticsearch 和 Kibana。
两个示例索引用于演示不同的使用场景:
同一个只读技能可以同时适用于这两个索引,无需任何重新配置;agent 会检查 mapping,并相应地调整查询。
第 2 层:编排(OpenClaw Gateway)
Gateway 接收自然语言请求并加载 Elasticsearch 技能,由大语言模型(LLM)决定需要构建哪些查询。该技能是一个纯 SKILL.md 文件,并包含参考文档,这意味着其操作无需任何自定义代码。
为了理解 Gateway 如何组织这一过程,需要了解 OpenClaw 的两个核心概念:
-
Agents:独立的 AI 实例,每个都有自己的配置、workspace 和技能集合。你可以为不同用途运行多个 agents。
-
Workspace:定义 agent 上下文的文件夹,包括 AGENTS.md(agent 的长期说明)、.env(凭证)以及 skills/ 目录。可以把它理解为 agent 的工作环境。
第 3 层:技能(可组合能力)
Skills 是写在 Markdown 文件(SKILL.md)中的结构化指令,用于教 agent 如何使用特定工具或 API。它们可以是全局的(所有 agents 可用)、workspace 专用的,或随 OpenClaw 一起提供的。agent 只会按需加载与当前请求相关的技能。
本教程使用两个技能:
-
Elasticsearch-openclaw(自定义,本教程构建):一个只读技能,教 agent 如何使用 curl 对 Elasticsearch 索引进行搜索、过滤、聚合和探索。
-
Weather(社区技能,用于组合演示):一个从外部 API 获取当前天气情况的技能。
在教程后续部分,我们将演示 OpenClaw 如何在一次请求中组合这两个技能,根据实时天气数据查询 Elasticsearch 中的产品,而无需任何自定义集成代码。
只读设计(Read-only by design)
elasticsearch-openclaw 技能在设计上是只读的。它提供用于搜索、过滤和聚合数据的模式,但从不执行写入、更新或删除操作。这可以在让 AI agents 访问 Elasticsearch 集群时,将安全风险降到最低。
即使 agent 环境被攻破,你的数据仍然不会被修改或删除。这通过以下方式进行保障:
-
技能设计:在 SKILL.md 或参考文件中不包含任何写操作模式。
-
API key 权限:本教程使用只读 API key,仅包含 read 和 view_index_metadata 权限。
-
Agent 指令:AGENTS.md 明确说明:“你可以 SEARCH、FILTER 和 AGGREGATE 数据,但绝不能写入、更新或删除。”
这种以安全为优先的设计也是为什么基础设施设置(如索引创建、数据加载)必须手动完成;从设计上来说,agent 无法替你执行这些操作。
先决条件(Prerequisites)
要完成本教程,你需要以下条件:
软件和工具:
-
安装并运行 Docker Desktop(Docker Engine 带 Compose V2)。
-
通过 start-local 在本地运行 Elasticsearch。(我们将在下一节进行设置)
-
Jina API key(免费):https://jina.ai/embeddings
-
安装 OpenClaw:https://openclaw.ai
环境设置
首先,克隆入门项目,该项目包含 skill、workspace 配置以及开发工具脚本(Dev Tools scripts):
git clone https://github.com/salgado/elasticsearch-openclaw-start-blog
cd elasticsearch-openclaw-start-blog该仓库包含:
elasticsearch-openclaw-start-blog/
├── devtools_fresh_produce.md ← Creates fresh_produce index (10 products)
├── devtools_app_logs_synthetic.md ← Creates app-logs-synthetic index (30 logs)
└── openclaw-workspace-elastic-blog/
├── AGENTS.md ← Agent briefing
├── .env.example ← Credentials template注意:devtools*.md 文件包含以参考文档格式编写的 Kibana Dev Tools 命令。
安装 OpenClaw
OpenClaw 是一个自托管的网关。这意味着你可以完全控制执行和数据,但你需要准备本地环境或服务器。
我在另一台机器上安装了 OpenClaw,因此附上以下免责声明。
** 安全与责任免责声明 **
由于 OpenClaw 是一个早期阶段、快速发展的开源项目,社区已经提出了关于潜在安全漏洞的重要讨论,尤其是在令牌处理和第三方脚本执行方面。
部署建议:
-
隔离环境:如果你不是高级基础设施安全用户,建议严格在隔离、可控的环境中安装 OpenClaw(例如专用虚拟机 [VM]、无 root 权限的 Docker 容器或测试机)。
-
避免生产环境使用:在项目达到更稳定、经过审计的版本之前,不要在包含敏感数据或对公司网络无限制访问的服务器上运行该网关。
-
最小权限原则:建议使用权限受限的 Elasticsearch API key(只读),以降低风险,即使环境遭到入侵。
-
网络隔离:Elasticsearch 和 OpenClaw 默认绑定到 localhost。除非有特殊原因,否则保持默认设置。
-
凭证轮换:定期更换 API key。OpenClaw 会在本地存储凭证,因此机器的安全性就是防护边界。
-
审计日志:启用 Elasticsearch 审计日志,以跟踪 OpenClaw 所做的所有 API 调用,记录代理访问了什么以及何时访问。
-
保持安装更新。
有关安全架构和部署选项的更深入分析,请查阅官方 OpenClaw 文档。
运行时安装
OpenClaw 通过 CLI 管理守护进程和技能隔离。由于这是一个近期项目,并且经历过命名变更,建议严格按照官方文档操作,以确保安装兼容性。
# Global gateway installation
curl -fsSL https://openclaw.ai/install.sh | bash准备 Elasticsearch 后端
在连接任何 agent 运行时之前,我们需要一个可用的 Elasticsearch 环境,包含可查询的数据以及安全的只读访问层。在接下来的两个部分中,我们将使用 start-local 在本地启动 Elasticsearch,创建一个包含 semantic_text 和 Jina v5 embeddings 的索引,加载示例数据,验证语义搜索功能,并生成只读 API key。一旦这个基础就绪,Elasticsearch 端就完成了,我们就可以专注于教 agent 如何使用它。
第 1 部分:在本地设置 Elasticsearch
使用单条命令启动本地 Elasticsearch 和 Kibana 实例:
curl -fsSL https://elastic.co/start-local | sh完成后:Elasticsearch 运行在 http://localhost:9200,Kibana 运行在 http://localhost:5601,凭据存放在 elastic-start-local/.env 中。
第 2 部分:在 Kibana Dev Tools 中配置索引
打开 http://localhost:5601 → Dev Tools,并按顺序运行 devtools_fresh_produce.md。
- 步骤 1:将 YOUR_JINA_API_KEY 替换为你实际的 Jina API key(免费)。
- 步骤 2:立即保存编码字段;之后无法再检索。
Dev Tools 文件中的关键命令包括:
创建 Jina 推理端点:
PUT _inference/text_embedding/jina-embeddings-v5
{
"service": "jinaai",
"service_settings": {
"api_key": "YOUR_JINA_API_KEY",
"model_id": "jina-embeddings-v5-text-small"
}
}使用 semantic_text 创建索引:
PUT /fresh_produce
{
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": { "keyword": { "type": "keyword" } }
},
"description": { "type": "text" },
"category": { "type": "keyword" },
"price": { "type": "float" },
"stock_kg": { "type": "float" },
"on_sale": { "type": "boolean" },
"image_url": { "type": "keyword" },
"semantic_content": {
"type": "semantic_text",
"inference_id": "jina-embeddings-v5"
}
}
}
}semantic_text 字段类型会在索引时自动处理 embedding 生成。
使用 bulk API 索引示例产品(完整 10 个产品数据请参见 devtools_fresh_produce.md)。
验证 semantic search:
GET /fresh_produce/_search
{
"query": {
"semantic": {
"field": "semantic_content",
"query": "healthy colorful meals"
}
},
"size": 3,
"_source": ["name", "description", "category"]
}semantic query 类型会在查询端自动处理推理;无需指定 model IDs 或 embedding 细节。
创建只读 API key:
POST /_security/api_key
{
"name": "openclaw-readonly",
"role_descriptors": {
"reader": {
"cluster": ["monitor"],
"indices": [
{
"names": ["fresh_produce", "app-logs-synthetic"],
"privileges": ["read", "view_index_metadata"]
}
]
}
}
}保存响应中的编码值。这是你用于 OpenClaw 配置的 API key。
连接到 OpenClaw
在 Elasticsearch 后端准备就绪后,我们现在可以将其接入 OpenClaw。生态系统中已经存在多种 Elasticsearch 集成,从 Elastic 自家的 Model Context Protocol (MCP) 服务器到社区构建的 MCP 服务器。然而,大多数都提供完整 CRUD 访问,或者为不同的 agent runtime 设计。鉴于这项技术仍处于早期阶段且安全仍是主要关注点,我选择构建一个专用 skill,简单、只读、为 OpenClaw 专门设计。这种方式确保 agent 可以搜索、过滤和聚合数据,但永远不会修改它,即使环境被攻破,也能将影响范围降到最低。
在接下来的章节中,我们将配置凭证、安装 skill、创建专用 agent,并探索 workspace 如何将一切联系起来。
安装 skill 并创建 agent
步骤 1:配置凭证
从克隆的仓库中,通过复制环境模板并填写你的 Elasticsearch URL 及只读 API key 来配置凭证:
cp openclaw-workspace-elastic-blog/.env.example
openclaw-workspace-elastic-blog/.env编辑 .env 文件,填写这两个值:
ELASTICSEARCH_URL: http://localhost:9200 (from start-local)
ELASTICSEARCH_API_KEY: The encoded value from the read-only API key you created in Part 2 (the POST /_security/api_key response)示例 .env 文件:
ELASTICSEARCH_URL=http://localhost:9200
ELASTICSEARCH_API_KEY=VnVaRmxLSDRCQxxxxxxxxbGVfa2V5步骤 2:从 ClawHub 安装 skill
ClawHub 是 OpenClaw 的公共 skill 注册中心,可以把它想象成 AI agent skill 的 npm。截止本文撰写时,ClawHub 已托管超过 3,200 个 skill,涵盖从 Slack 和 GitHub 集成到物联网(IoT)设备自动化的各种功能。在本教程中,我们创建了 elasticsearch-openclaw,这是一个专注于使用 semantic_text 进行只读查询、聚合和 Elasticsearch 9.x 可观测性的自定义 skill。它已发布在 ClawHub 上,可以直接安装。最佳实践:仅从可信来源安装 skill,确保来源可靠;像使用任何包管理器一样,在授予 agent 访问权限前,先审查内容。
elasticsearch-openclaw skill 已发布在 ClawHub。
建议:打开 OpenClaw Web UI(http://127.0.0.1:18789/)并尝试:
Install the elasticsearch-openclaw skill from https://clawhub.ai/salgado/elasticsearch-openclawOpenClaw 将会:
-
从 ClawHub 获取 skill。
-
安装到相应目录。
-
准备好后确认可用。
步骤 3:创建 agent
通过注册一个专用 agent 并为其创建独立 workspace,然后重启 gateway 以加载新配置:
openclaw agents add elasticsearch-agent \
--workspace ~/path/to/elasticsearch-openclaw-start-blog/openclaw-workspace-elastic-blog \
--non-interactive
openclaw gateway restart
理解 workspace
现在 agent 已经运行,让我们看看它是如何运作的。
AGENTS.md
AGENTS.md 文件是 agent 的永久简报。它定义了 agent 的身份、能力以及行为方式。对于我们的 Elasticsearch agent,这个文件会告诉 agent 可用的索引、只读约束,以及推荐的查询模式。
Skills:何时发挥作用
| 无 skill | 使用 elasticsearch-openclaw skill |
|---|---|
| Agent 不知道 Elasticsearch 查询语法 | Agent 知道语义搜索、全文、本地过滤和聚合模式 |
| Agent 可能尝试写操作 | Agent 被指示绝不写入、更新或删除 |
| Agent 猜测字段名称和类型 | Agent 先检查 mappings,再构建合适查询 |
| 使用通用 curl 命令并靠试错 | 使用针对 Elasticsearch 9.x 的结构化查询模板和最佳实践 |
与 agent 一起探索
配置好 Elasticsearch 后端并连接 OpenClaw agent,就可以看看 agent 实际能做什么了。在接下来的章节中,我们将测试自然语言查询、探索 observability 数据,并组合多个 skills。
在 OpenClaw 中测试
打开 OpenClaw Web UI,尝试一些自然语言查询。agent 会检查索引 mapping,选择合适的查询类型,并返回结果。
输入示例:
“Find products that would be good for a healthy summer salad.”
返回结果:
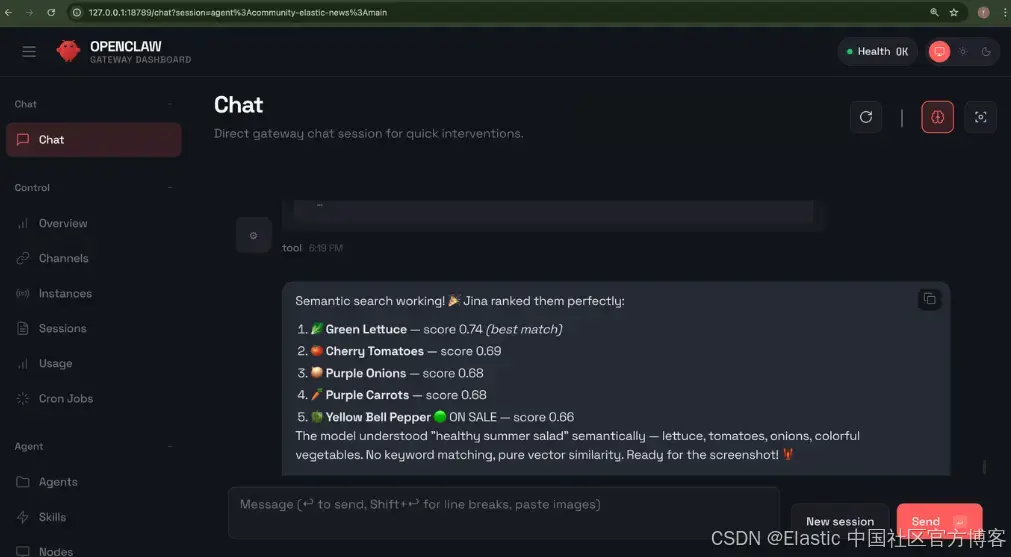
其他可探索的思路:
索引探索:
“What indices do I have in Elasticsearch? Show me the fields of fresh_produce.”
过滤搜索:
“Show me all products on sale under $15.”
聚合:
“What’s the average price by category?”
可观测性
为了展示 skill 在单一用例之外的功能,仓库中包含第二个索引:app-logs-synthetic,包含四个虚拟服务的 30 条合成日志条目,由 devtools_app_logs_synthetic.md 创建。
设置日志数据
由于 skill 是只读的,你需要先填充索引。devtools_app_logs_synthetic.md 文件包含五个命令(三个用于设置,两个用于验证):
-
创建 ingest pipeline:自动向日志条目添加
@timestamp。 -
创建索引 mapping:定义
app-logs-synthetic结构(仅经典字段,无semantic_text)。 -
批量插入日志:加载 30 条跨四个服务的合成日志条目。
-
Count 查询:验证已索引 30 条文档。
-
示例搜索:快速测试以确认数据可查询。
执行方法:
-
打开 Kibana Dev Tools:http://localhost:5601 → Dev Tools
-
从 .md 文件复制每个编号块
-
粘贴到 Dev Tools 控制台
-
按 Ctrl/Cmd+Enter 执行
-
等待成功响应再执行下一块
此操作会创建 app-logs-synthetic 索引并加载示例数据,可供查询使用。
在 OpenClaw Web UI 中尝试此查询:
Show me the distribution of HTTP status codes across all services.
返回结果:
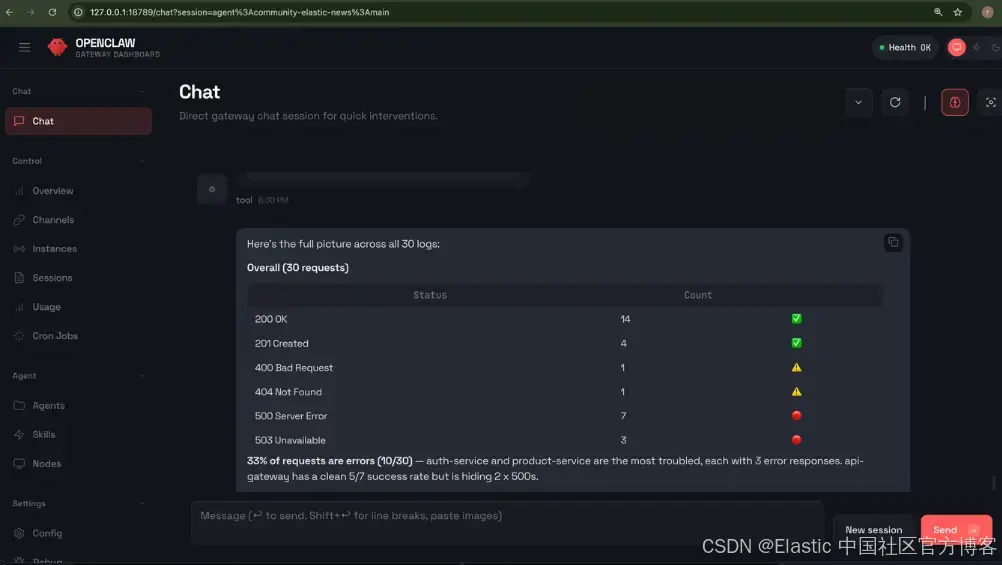
其他可探索的思路:
“How many 500 errors do I have in app-logs-synthetic? Which services are failing?”
“Which endpoints have the slowest response times?”
“What happened with the payment-service in the last 24 hours?”
这是相同的 skill、相同的 agent、相同的设置,只是指向不同的数据。Agent 会检查新的索引 mapping,调整查询,并返回相关结果,无需任何重新配置。
技能组合实战
这正是可组合 skills 的亮点。首先向 agent 提问:
Install the weather skill.OpenClaw 会搜索 weather skill,自动尝试安装,并引导你完成整个过程。只需按照屏幕上的说明操作;weather skill 不需要新的 API key。
完成后,尝试以下操作:
“Find the products on sale in the fresh_produce index that match today’s weather in São Paulo. Generate a nice HTML report with product cards using the image_url field from each document, price, description, and stock. Save it to ~/Desktop/report.html and open it in the browser.”
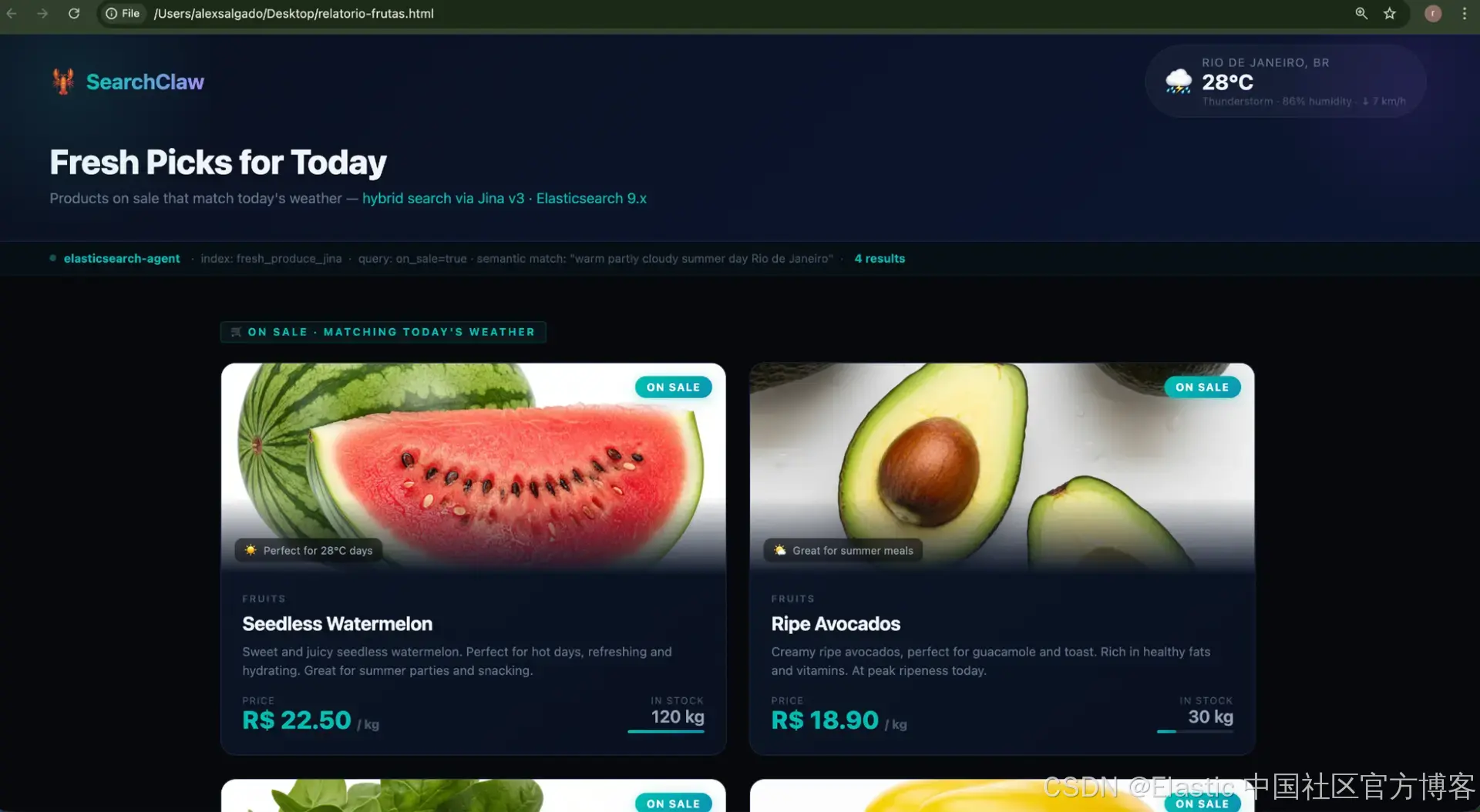
在单次请求中,Agent 会串联多个 skills:使用 weather skill 检查当前天气,使用 Elasticsearch skill 对匹配上下文的产品执行混合搜索,并利用内置的文件和浏览器工具生成 HTML 报告并打开它。无需自定义集成代码,无需 glue 脚本,所有操作均由 LLM 在运行时通过 skills 自动组合完成。
这就是 OpenClaw 与传统自动化框架的不同之处。你不需要预先编程工作流,只需描述期望结果,Agent 就会自动完成组合。
结论
SearchClaw 最初是一个简单实验,最终展示了可组合、LLM 驱动的集成在实践中的样子。关键 takeaway 并不是单个工具(它们都很熟悉),而是方法论。我们没有编写特定应用和硬编码查询,而是赋予 Agent 能力,让它动态组合解决方案。这就是 OpenClaw 的原生特点:可组合、LLM 驱动、本地优先。
像任何早期项目一样,OpenClaw 应谨慎使用,尤其是在安全性和环境隔离方面。本教程中展示的只读 skill 方法是限制风险,同时释放 Elasticsearch 数据价值的一种方式。
完整代码可在仓库获取,可作为自己集成的起点:https://github.com/salgado/elasticsearch-openclaw-start-blog。
原文:https://www.elastic.co/search-labs/blog/openclaw-elasticsearch-ai-agents#testing-in-openclaw

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)