CC+GLM4.7调好了太爽了,入门焚诀分享给大家
本文分享了使用ClaudeCode与GLM-4.7组合进行AI辅助编程的优化方案。针对AI在编程中出现的"偷懒留TODO"和"捏造API"问题,作者提出了"MCP约束+Plan模式"的解决方法。方案包含四个核心工具:1) Shrimp Task Manager定义标准开发流程;2) Memory实现渐进式知识披露;3) Sequentia
最近一周,我一直在折腾 ClaudeCode + GLM-4.7 的组合。
有一说一,这个组合的文档阅读功底相当不错,但刚开始用的时候,编写文档体验尚可,但是coding能力堪忧,问题主要是下面两个:
-
偷懒:写代码老是给我留一堆
// TODO: 实现具体逻辑,让我自己去实现,或者他不确定的部分,不向我确认直接TODO。 -
造假:经常一本正经地捏造一些根本不存在的函数或 API(幻觉),写得跟真的一样,一运行全是红线。
经过这一周的调试和“磨合”,我用**“MCP 约束 + Plan 模式”**能基本解决上述问题。
今天就把这套方案分享给大家,保证小白也能看懂,希望能帮大家真正解放双手。
第一步:环境准备(小白必看)
如果你还没装过 ClaudeCode,先跟着我花 2 分钟把环境搭起来。
1. 安装 ClaudeCode
ClaudeCode 是 Anthropic 官方推出的命令行工具,咱们需要在终端(Terminal/CMD)里运行。
首先,确保你的电脑里安装了 Node.js(如果没有,去官网下个 LTS 版本)。然后在终端输入:
npm install -g @anthropic-ai/claude-code
2. 配置 GLM-4.7 模型
ClaudeCode 原生支持 Claude 模型,但为了性价比和中文语境优化,我用的是 GLM-4.7。因为最近的中转站确实太不稳定了,之前用的比较有名的中转站基本都开始涨价了,按我这个用法估计得花不少钱。
如果你还没有 API Key,可以用下面这个链接,立省10%:
👉 GLM-4.7 极速申请通道
拿到 Key 之后,在 ClaudeCode 的配置里把模型指向 GLM-4.7 即可。
第二步:核心解法——MCP 工具箱
之前 AI 容易出错,是因为它“太自由”了。我们需要给它装上MCP(Model Context Protocol),简单理解就是给 AI 戴上“紧箍咒”并配上“工具包”。
我主要用了这四个MCP来约束它:
1:Shrimp Task Manager(SOP 任务管理)
这是最关键的一环。我用 shrimp-task-manager 这个 MCP 工具定义了一套**“标准作业程序(SOP)”**。
以前我让它“接个 SSO 登录”,它可能瞎写。现在,我强制它必须按照我定义的模板一步步来。
我的配置模板如下(建议直接复制保存):
Shrimp Task Templates
本文件定义项目中常用的 Shrimp 任务模板。所有任务必须通过 shrimp-task-manager 创建并按模板步骤执行。所有执行过程必须遵守 memory 中定义的《核心开发指南》。
---
【模板 1:SSO / OIDC / JWT 改造任务】
触发关键词:SSO / 登录 / OIDC / JWT / 单点登录
目标:在不破坏现有链路的前提下,实现 SSO。
强制约束:
1. 禁止 TODO、禁止伪代码、禁止猜测 API。
2. 任何安全语义不明确的地方,必须先向我确认。
执行步骤:
1. [读取规范] read_file CLAUDE.md, SSO_CONTEXT.md
2. [读取目标] 读取涉及的 Controller/Filter 完整内容(含 import)
3. [影响面梳理] 必须输出修改清单,明确 Token 校验、用户上下文等影响。
4. [实施改造] 按规范实现,对无 Token 场景做兜底。
5. [安全检查] grep -r 检查全局引用,确保未破坏原有链路。
6. [DoD] 代码已评审,调用的方法都存在,无 TODO。
---
【模板 2:API(外部 API 对接 / Feign Client)】
触发关键词:API / 外部接口 / Feign / 对接
执行步骤:
1. [读取规范] read_file API_CONTEXT.md
2. [DTO 校验] Request/Response 字段必须与接口文档逐项对齐,禁止凭感觉增删。
3. [Feign 实现] 方法签名必须与 DTO 一致。
4. [Fallback] 必须 override 新增方法,使用统一降级策略。
5. [DoD] Feign 与 Fallback 完全同步,diff 中无任何 TODO/FIXME。
---
【模板 3:数据库 / SQL 开发】
触发关键词:SQL / 数据库 / 字段映射 / Mapper
执行步骤:
1. [读取规范] read_file 统一招采字段映射关系整理.md
2. [实现映射] 字段名/类型与 Entity 严格一致,注意 LocalDateTime 处理。
3. [引用检查] 删改字段必须 grep -r 检查全局引用。
这个模板的作用是:
一旦我提到“帮我接个 SSO”,AI 就会自动触发模板 1,被迫先读文档、再检查影响面、最后写代码,想偷懒都不行。
2:Memory(记忆体)
memory 类似于 AI 的长期技能树,我用它来实现渐进式披露。
比如,我会把《核心开发指南》或者项目里的《Commit Message Protocol》存进 Memory。AI 每次写完代码提交时,都会自动去查一下记忆:“哦,老板要求提交记录必须是这种格式”,从而保证风格统一。
神器 3:Sequential Thinking(深度思考)
遇到复杂逻辑(比如“把 Shiro 换成 OAuth2 且不影响旧业务”),我会强制 AI 开启 sequential-thinking。
这会让 AI 在写代码前,先进行多轮的逻辑推演:
-
思考第 1 步:分析现状…
-
思考第 2 步:识别风险…
-
思考第 3 步:设计回滚方案…
这比直接让它“一把梭”写代码要靠谱得多。
神器 4:Context7(防幻觉利器)
这是为了解决“瞎编 API”的问题。context7 允许 AI 查阅特定框架的真实 API 文档(比如 Spring Boot、MyBatis-Plus 的官方文档)。
当 AI 不确定某个类有没有 getxxx() 方法时,它不再靠猜,而是通过这个工具去查文档。这一招极大地减少了编译报错。
第三步:闭环验证(DoD + 编译即真理)
做好了上面这些,最后还有一道保险:通用结束规则(DoD)。
我在 Prompt 里写死了一条规则:
“编译即真理。DoD(完成标准)必须包含:代码已评审、调用的方法都存在、无 TODO。如果有错误,自行修改并生成测试类跑通。”
配合 ClaudeCode 的执行能力,现在的流程变成了:
-
AI 写代码。
-
AI 自己跑
mvn compile。 -
如果报错(比如方法找不到):AI 意识到“幻觉”了 -> 调用
context7查文档 -> 修正代码 -> 再次编译。 -
编译通过 -> 任务结束。
总结
作为 LLM 大模型,幻觉和生成不存在的 API 是不可避免的天性。但是,我们可以通过工程化手段来规避:
-
用 Shrimp Task Manager 把它框在标准的 SOP 流程里;
-
用 Context7 给它查阅真实文档的能力;
-
用 DoD + 编译检查 让它学会自我反思和修正。
最后,官方的Plan模式也很好用,会创建很多个task,然后挨个实现,类似于我们自己写代码,也是用这种分而治之的思路,一小块一小块的去完成,效果如下图: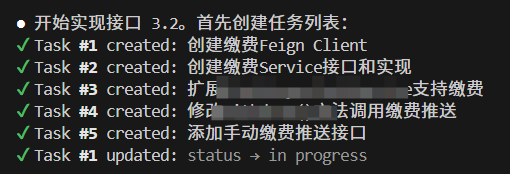

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)