为什么你的Sentinel限流规则总是不生效?这6个“隐形杀手”没填过,上线就是P0事故!
这是新手村最常见的死法,也是很多初级开发者最容易忽视的“灯下黑”。现象核心病灶必杀技 (Solution)难度URL 配了没反应资源定义错位统一用 URL,或注解值精确匹配⭐OOM / 监控丢失动态 URL 爆炸UrlCleaner(归一化) +热点参数限流⭐⭐⭐异步方法限流失效ThreadLocal 丢失AsyncEntry或⭐⭐⭐⭐前端报 500异常被吞实现⭐⭐流量放大/限流不准集群限流退化独
最近有粉丝去面某大厂(核心链路全线 Sentinel),回来后跟我吐槽:
“Fox,面试官问我 Sentinel 规则不生效的原因,我答了阈值配错和资源名不对,结果他问我‘异步线程池里怎么算?集群模式下 Token Server 挂了怎么算?Sentinel 的 SlotChain 是怎么处理这些的?’,直接把我问哑火了。”
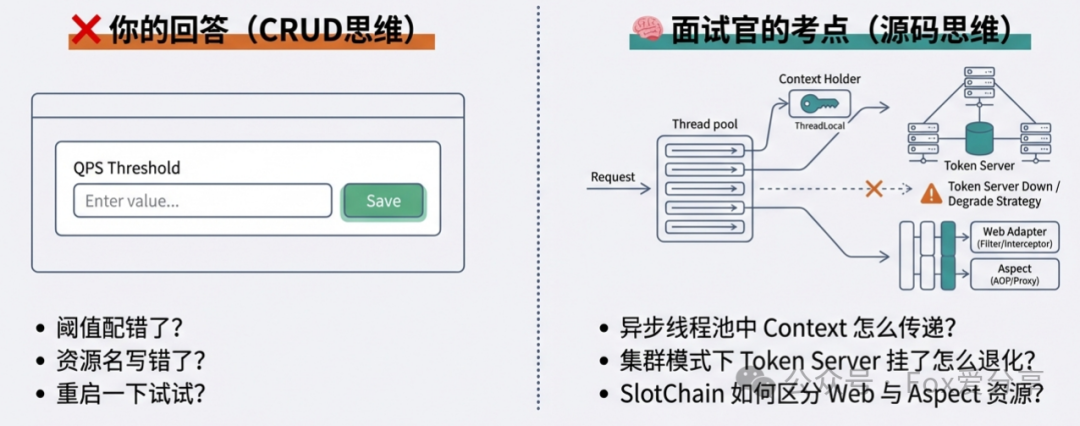
很多兄弟对 Sentinel 的理解还停留在“控制台配个 QPS,代码加个注解”的 CRUD 阶段。
Too Young! 在高并发生产环境中,Sentinel 的“失效”往往涉及线程上下文切换、集群通信故障、监控维度坍塌等底层原理。这不仅是配置问题,更是对 Spring 上下文、RPC 调用链、分布式一致性 的综合考量。
今天 Fox 就在之前的基础上,给大家暴力拆解这 6 大核心病灶。这次我们不只要解决问题,更要深入源码和架构,给出从入门到架构级的落地代码。文长干货多,建议先收藏再看!
⛔ 病灶一:资源定义错位 —— "你以为的资源,在 SlotChain 里查无此人"
这是新手村最常见的死法,也是很多初级开发者最容易忽视的“灯下黑”。
1. 现象复现
-
场景: 你在 Service 层的代码里写了
@SentinelResource(value="getOrder"),但在 Sentinel 控制台配置流控规则时,资源名却填了 Controller 层的接口路径/order/get。 -
结果: 压测时发现,配了规则的那个资源根本没触发限流,没配规则的那个反而因为默认规则被误杀了。
2. 深度解析:双轨制与 SlotChain
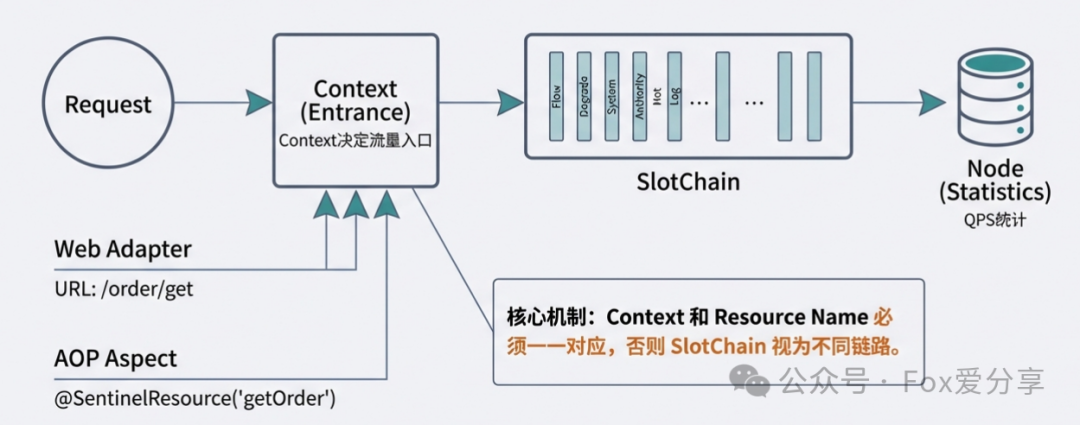
Sentinel 的核心是 Resource(资源),而底层是通过 Node(统计节点) 来记录 QPS 的。Spring Cloud Alibaba 在整合 Sentinel 时,其实有两套并行的机制:
-
Web 适配层(Interceptor): 引入
spring-cloud-starter-alibaba-sentinel后,会自动配置SentinelWebInterceptor。它会将所有的 HTTP 请求 URL(如/order/get)定义为一个资源,并创建一个对应的ClusterNode进行统计。 -
AOP 切面层(Aspect):
@SentinelResource注解是通过 AOP 切面实现的。当代码执行到这个注解时,它会通过SphU.entry("getOrder")定义另一个完全独立的资源。
本质原因:
在 Sentinel 的 SlotChain(功能插槽链) 中,Context(上下文)决定了流量的入口,而 Resource Name 决定了使用哪个 Node 进行统计。
你给“URL Node”配了锁,却指望它去锁住“注解 Node”。在 Sentinel 眼里,这完全是两个陌生的路人,当然不生效!
3. 💡 Fox 避坑指南
-
全司统一标准(推荐): 除非有特殊需求,否则优先使用 URL 路径 配置规则。这种方式对代码侵入性最小,运维人员看着 URL 也能直接配,沟通成本低。
-
精确匹配: 如果必须使用注解(比如内部 Service 方法级限流、不暴露 URL 的内部调用),务必保证控制台配置的资源名与注解
value值 字符级精确匹配。注意:/order/get和order/get是两个资源,少一个斜杠都不行! -
链路模式(Chain Mode): 如果你想限制某个 Service 方法的入口流量(比如限制从 Controller A 进来的流量,不限制从 Controller B 进来的),要搞懂 Context(调用链路入口)。
-
坑点: Spring Cloud Alibaba 默认会将所有 Web 入口的 ContextName 聚合为
sentinel_default_context,导致链路流控失效。 -
解法: 需要配置
spring.cloud.sentinel.web-context-unify: false关闭聚合(注意:这会增加内存消耗)。
-
⛔ 病灶二:RESTful 接口的“双重陷阱” —— "OOM 与 监控盲区"
这个问题能直接区分你是“Demo 玩家”还是“生产玩家”。面试中聊到这里,一定要把“归一化”和“热点参数”结合起来讲。
1. 现象复现
接口是标准的 RESTful 风格:/order/{id}。实际请求是 /order/1001、/order/1002...
-
陷阱 A(内存爆炸): Sentinel 默认把每个 URL 当作不同资源。百万级订单号 = 百万级 Node 对象。JVM 的 Old 区会被塞满,最终导致 OOM(内存溢出)。
-
陷阱 B(监控致盲): 你做了
UrlCleaner归一化,把 ID 转成了/order/{id}。限流生效了,但运营跑来问你:“我想封禁 ID 为 1001 的恶意用户,为什么在监控里看不到他的单独数据了?”
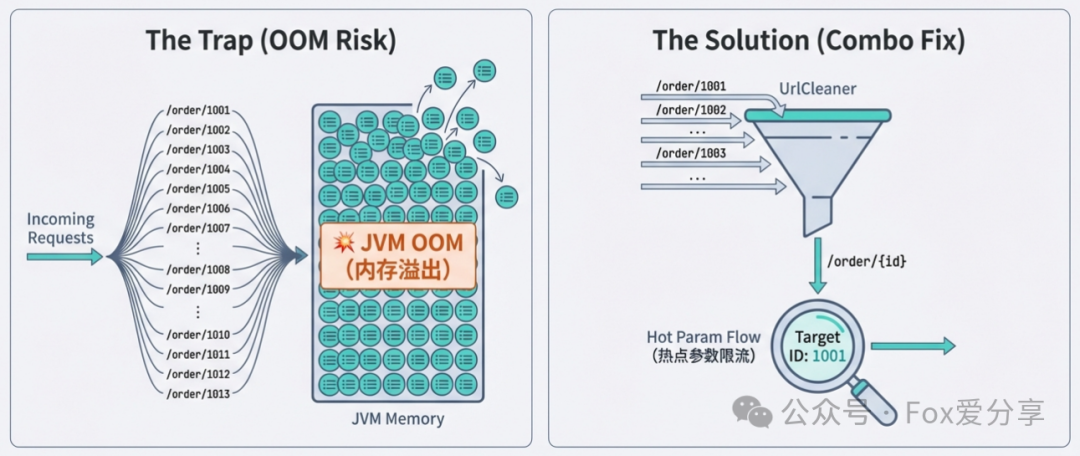
2. 💡 Fox 避坑指南:组合拳
第一步(保命):实现 UrlCleaner 接口
必须把 /order/1001 清洗为 /order/{id},防止内存爆炸。
@Component
public class CustomUrlBlockHandler implements UrlCleaner {
@Override
public String clean(String originUrl) {
// 正则匹配,把 /order/1001 变成 /order/{id}
// 注意:正则要写得严谨,避免误杀
if (originUrl.matches("/order/\\d+")) {
return "/order/{id}";
}
return originUrl;
}
}
第二步(高阶):配合热点参数限流
归一化后丢失了 ID 明细,怎么对特定用户限流?用热点参数限流(Hot Param Flow)!
-
原理: 它不创建海量 Node,而是使用 LRU 策略(Leaky Bucket 或 Token Bucket)统计 Top N 的热点参数。
-
配置实操:
-
在控制台“热点规则”中,资源名填归一化后的
/order/{id}。 -
参数索引填 0(假设 ID 是 URL 或方法参数的第一个)。
-
配置“参数例外项”:当参数值为
1001时,阈值设为 0(直接封禁);其他参数阈值设为 100。
-
-
效果: 既保护了 JVM 内存,又实现了对“刺头”用户的精准打击。
⛔ 病灶三:异步调用的“失忆症” —— "线程一换,Context 全断"
1. 现象复现
你在 Controller 里接收请求,为了提升吞吐量,你用 @Async 或者直接丢进一个 ThreadPoolExecutor 去异步处理下游逻辑。
你在异步执行的那个方法上加了限流规则,结果发现完全不生效,QPS 飙到天上去也没反应。
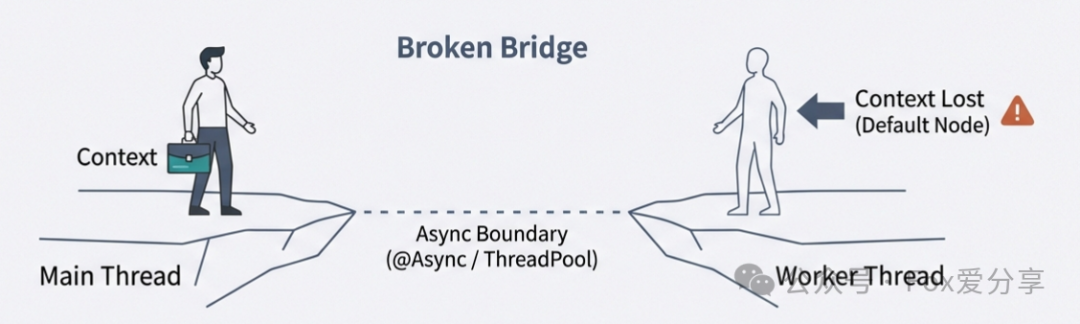
2. 深度解析:ThreadLocal 的局限性
Sentinel 的核心上下文 Context(包含了当前调用链的入口信息 EntranceNode、当前调用栈 CurNode 等)是基于 ThreadLocal 存储的。
-
断链: 一旦你切换了线程(异步调用),主线程里的
ThreadLocal变量是带不过去的! -
后果: 在新的子线程里,Sentinel 认为这是一个“无名氏”发起的全新调用(Context 为空),它会创建一个默认的 Context。这导致它找不到原本的入口,也关联不到原本的调用链路。
3. 💡 Fox 避坑指南
方案 A(推荐):使用包装类
Sentinel 提供了 SentinelRunnable 和 SentinelCallable,它们会在创建时自动“捕获”当前线程的 Context,并在执行时“重放”到子线程中。
// 错误写法:Context 丢失
threadPool.submit(() -> service.doSomething());
// 正确写法:Context 自动传递
threadPool.submit(new SentinelRunnable(() -> service.doSomething()));
方案 B(手动挡):AsyncEntry(高阶写法)
如果你无法使用包装类(比如用的是 @Async 或者复杂的 CompletableFuture 编排),你需要手动利用 AsyncEntry。这需要你对 Sentinel 的 API 非常熟悉。
// 1. 在主线程获取 Context 快照
final Context contextSnapshot = ContextUtil.getContext();
threadPool.submit(() -> {
// 2. 在子线程运行,手动切入 Context
ContextUtil.runOnContext(contextSnapshot, () -> {
try {
// 3. 显式定义资源,开启异步 Entry
// 注意:这里必须用 SphU.asyncEntry,而不是 SphU.entry
AsyncEntry entry = SphU.asyncEntry("asyncResource");
try {
// 4. 执行业务逻辑
service.doSomething();
} finally {
// 5. 必须退出!
entry.exit();
}
} catch (BlockException e) {
// 处理限流逻辑
}
});
});
注意: 如果不手动 runOnContext,虽然 asyncEntry 能创建资源,但它会丢失“调用链路”信息,导致链路流控失效。
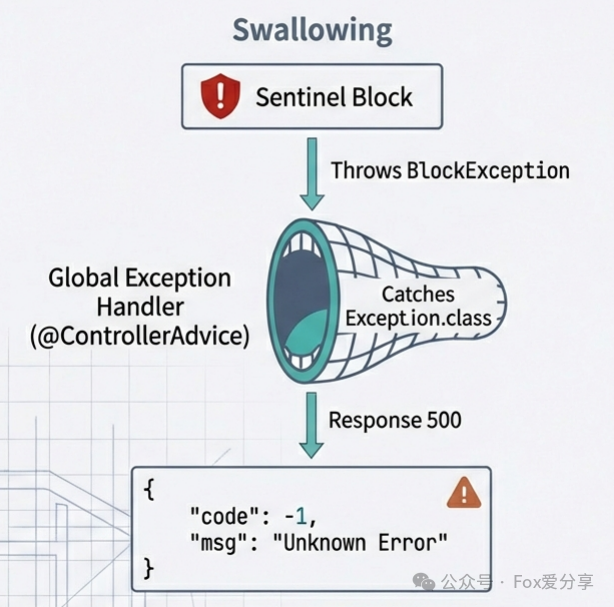
⛔ 病灶四:异常被吞 —— "流量防住了,前端却报错"
1. 现象复现
Sentinel 控制台显示已经限流(Blocked QPS 有值),但前端收到的不是 HTTP 429,而是 500 错误,或者业务层的通用异常 {"code": -1, "msg": "未知错误"}。
2. 深度解析
Sentinel 抛出的 BlockException 是一个受检异常(Checked Exception)或者是 RuntimeException(取决于具体实现)。
-
冲突点: 现在的 Spring Boot 项目通常都有全局异常处理器(
@ControllerAdvice)。 -
误杀: 如果你的全局异常处理器捕获了
Exception.class且优先级较高,它会把BlockException当作普通异常处理掉。Sentinel 预设的响应逻辑(返回 "Blocked by Sentinel")根本没机会执行。
3. 💡 Fox 避坑指南
你要夺回对 BlockException 的控制权!强烈建议实现 **BlockExceptionHandler** 接口。
/**
* Sentinel 适配 Spring MVC 的异常处理器
* 注意:如果是 Gateway 网关,需要实现 BlockRequestHandler 接口
*/
@Component
publicclass FoxBlockExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
// 1. 设置状态码为 429 (Too Many Requests)
response.setStatus(429);
response.setContentType("application/json;charset=utf-8");
// 2. 构建标准化的返回对象
Map<String, Object> data = new HashMap<>();
data.put("code", 429);
data.put("msg", "系统繁忙,请稍后再试");
// 3. 区分异常类型(可选)
if (e instanceof FlowException) {
data.put("detail", "触发限流");
} elseif (e instanceof DegradeException) {
data.put("detail", "触发降级");
}
// 4. 写回响应
response.getWriter().write(new ObjectMapper().writeValueAsString(data));
}
}
⛔ 病灶五:集群限流的“退化” —— "Token Server 去哪了?"
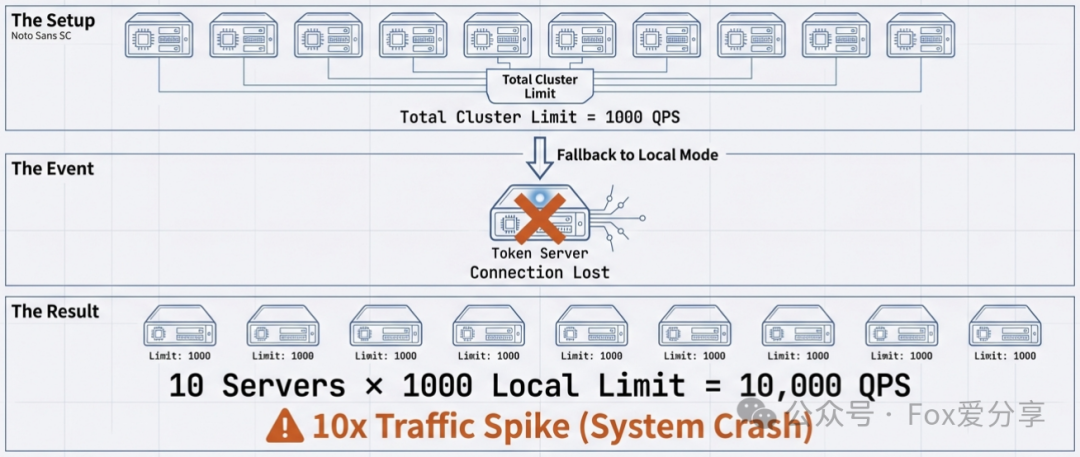
1. 现象复现
配置了集群限流总阈值 1000,集群有 10 台机器。预期总 QPS > 1000 限流。
压测时发现,实际通过的 QPS 飙到了 10000 还没拦住!或者有时候限流极不准。
2. 深度解析:Token Server 的单点与退化
集群限流的架构中,包含三个角色:**Nacos (配置)、Token Server (发牌员)、Sentinel Client (业务应用)**。
-
通信依赖: Client 必须通过 Netty 连接 Token Server 申请令牌。
-
Fail-over 机制: 当 Client 连不上 Server 时,默认策略是 自动退化为本地限流。
-
流量放大: 退化后,原本“10 台机器共用 1000 配额”,变成了“每台机器单独 1000 配额”。
-
实际总量 = 10 * 1000 = 10000 QPS。
-
后果: 下游服务原本只能抗 2000,现在放进来 10000,直接被打挂。
-
3. 💡 Fox 避坑指南
-
部署架构(Production Ready): 不要使用“嵌入式模式”(即让某个业务服务兼职当 Token Server)。生产环境建议使用 独立模式(Standalone) 部署 Token Server 集群,并配合 Nacos 进行动态选主。
-
退化策略(关键): 在
ClusterClientConfig中,根据业务容忍度设置fallbackToLocalWhenFail。
ClusterClientConfigManager.applyNewConfig(new ClusterClientConfig()
.setRequestTimeout(20) // 请求超时时间
// 如果是强依赖保护(如防止数据库被打死),建议设为 false(失败直接拒绝)
// 如果是弱依赖(如非核心日志),设为 true(退化本地,保可用性)
.setFallbackToLocalWhenFail(false)
);
⛔ 病灶六:配置“假”持久化 —— "Dashboard 的骗局"
1. 现象复现
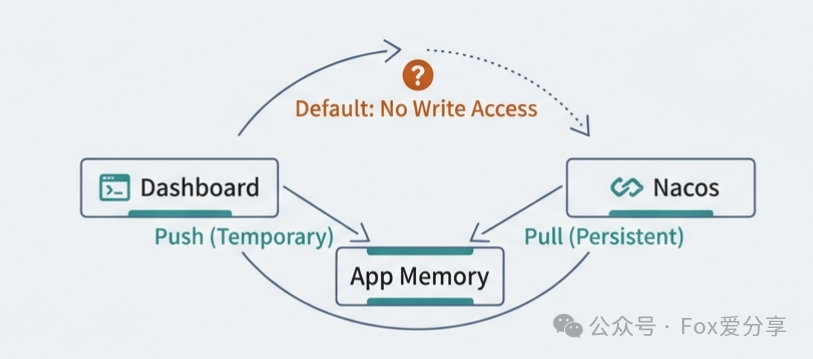
在 Dashboard 配好规则,重启服务后规则全丢。或者以为推到 Nacos 了,结果 Nacos 里根本没文件。
2. 深度解析:推拉模式之争
-
原生 Dashboard (Push模式): 默认是把规则直接推送到微服务内存。微服务重启即丢。
-
Nacos 数据源 (Pull模式): 微服务集成
sentinel-datasource-nacos后,启动时会从 Nacos 拉取配置。 -
矛盾点: 原生 Dashboard 不支持 往 Nacos 里写数据!它只是个内存查看器。你配了 Nacos 数据源,只是解决了“拉”的问题,没解决“推”的问题。
3. 💡 Fox 避坑指南
这里分两级,看你们团队的基建能力:
Level 1:标准解法(适合中小团队 - 极简)
-
思路:放弃在 Dashboard 上修改规则! Dashboard 只用来查看监控。所有规则修改,直接去 Nacos 控制台改 JSON 配置文件。
-
配置 (
application.yml):
spring:
cloud:
sentinel:
datasource:
flow:
nacos:
server-addr:127.0.0.1:8848
dataId:${spring.application.name}-flow-rules
groupId:SENTINEL_GROUP
rule-type:flow
data-type:json
-
优点: 零代码开发,官方原生支持,绝对持久化。
Level 2:进阶解法(适合大厂/强运维团队 - 体验好)
-
思路:改造 Dashboard 源码。
-
操作: 修改 Dashboard 的
FlowControllerV2等类,将“推送到客户端”的逻辑改为“调用 Nacos Open API 写入配置”。 -
优点: 实现了 双向同步。运维人员可以在 Dashboard 图形化界面改规则,自动落库 Nacos,服务自动拉取,体验完美。
⚡ 附赠:排查问题的“上帝视角”
如果以上 6 点都排除了,规则还是不生效,怎么办?
教你一招看日志,这是 P7 必须掌握的技能。
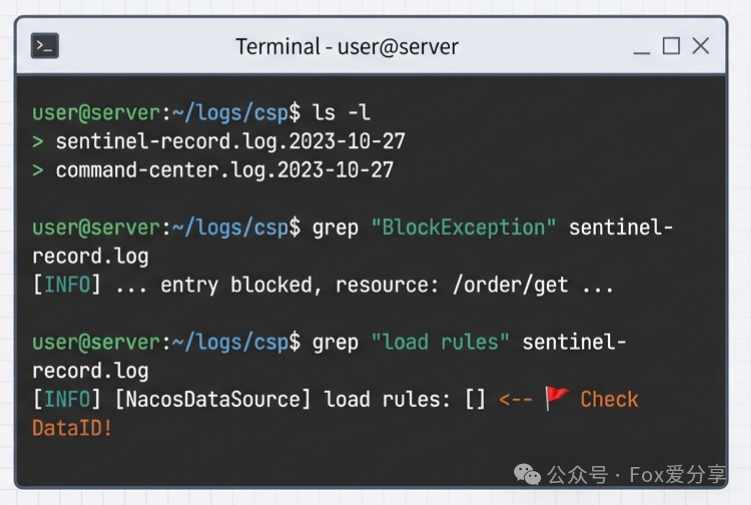
Sentinel 的日志默认位于 ~/logs/csp/ 目录下:
-
sentinel-record.log.xxx:这是核心日志。-
搜
[BlockException]:看是否有拦截记录。 -
搜
DataSource:看 Nacos 规则是否加载成功。 -
搜
Cluster:看集群 Token Server 连接是否正常。
-
-
command-center.log:看 Dashboard 推送的规则是否接收到了。
实战案例:
如果你在日志里看到 load rules: [],说明 Nacos 数据源配置错了,或者 DataId 对不上。
如果你看到 receive push rules: [...],说明 Dashboard 推送成功了,但可能被后续的 Nacos 拉取覆盖了(双向同步没做好)。
🎯 终极总结一张表(面试核武器)
| 现象 | 核心病灶 | 必杀技 (Solution) | 难度 |
|---|---|---|---|
| URL 配了没反应 |
资源定义错位 |
统一用 URL,或注解值精确匹配 |
⭐ |
| OOM / 监控丢失 |
动态 URL 爆炸 |
UrlCleaner
(归一化) + 热点参数限流 |
⭐⭐⭐ |
| 异步方法限流失效 |
ThreadLocal 丢失 |
AsyncEntry
或 SentinelRunnable |
⭐⭐⭐⭐ |
| 前端报 500 |
异常被吞 |
实现 BlockExceptionHandler |
⭐⭐ |
| 流量放大/限流不准 |
集群限流退化 |
独立部署 Token Server,配置 Fail-over 策略 |
⭐⭐⭐⭐⭐ |
| 重启规则丢失 |
持久化未闭环 |
标准版:
Nacos 数据源 + Nacos 改配置 |
⭐⭐⭐⭐ |
写在最后
兄弟们,Sentinel 的坑,往往不在于工具本身,而在于你对 Spring 上下文、线程模型、分布式一致性 的理解深度。
面试官问你“为什么不生效”,其实是在考你对微服务架构细节的掌控力。
把这 6 点吃透,面试时别光背八股文,结合代码、架构图和日志排查思路讲出来,面试官一定会被你的实战经验折服。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)