WoVR:世界模型作为可靠的模拟器,用于基于强化学习VLA策略后训练
26年2月来自清华、自动化所、中科院大学、中关村学院和无问芯穹(Infinigence AI)的论文“WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL”。强化学习 (RL) 有望为视觉-语言-动作 (VLA) 模型解锁超越模仿学习的能力,但其对大规模真实世界交互的需求阻碍了其在物理机器人
26年2月来自清华、自动化所、中科院大学、中关村学院和无问芯穹(Infinigence AI)的论文“WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL”。
强化学习 (RL) 有望为视觉-语言-动作 (VLA) 模型解锁超越模仿学习的能力,但其对大规模真实世界交互的需求阻碍了其在物理机器人上的直接部署。近期研究尝试将学习的世界模型用作策略优化的模拟器,但闭环的想象部署不可避免地会受到幻觉和长期误差累积的影响。这些误差不仅会降低视觉保真度,还会破坏优化信号,促使策略利用模型的不准确性而非真实的任务进展。WoVR,一个可靠的基于世界模型强化学习框架,用于后训练VLA 策略。WoVR 不假设一个忠实的世界模型,而是显式地规范 RL 如何与不完美的想象动态进行交互。它通过可控的动作条件视频世界模型提升展开稳定性,通过关键帧初始化的展开重塑想象交互以降低有效误差深度,并通过世界模型-策略协同演化维持策略与模拟器的一致性。在 LIBERO 基准测试和真实机器人操作上的大量实验表明,WoVR 能够实现稳定的长时程想象展开和有效的策略优化,将 LIBERO 平均成功率从 39.95% 提升至 69.2%(+29.3 分),将真实机器人成功率从 61.7% 提升至 91.7%(+30.0 分)。
近年来,大规模生成视频模型[18, 19, 20]的进步使得这一方向越来越可行。一些研究直接将预训练的视频生成器视为模拟器,并在想象中完全执行强化学习[21, 22, 23]。然而,学习的世界模型并非忠实的模拟器。本文将幻觉定义为闭环交互中想象结果与真实结果之间的系统性不匹配。世界模型可能生成视觉上合理的展开,但预测的物理状态转换却不正确,甚至在策略作用下产生虚假的成功信号(如图所示)。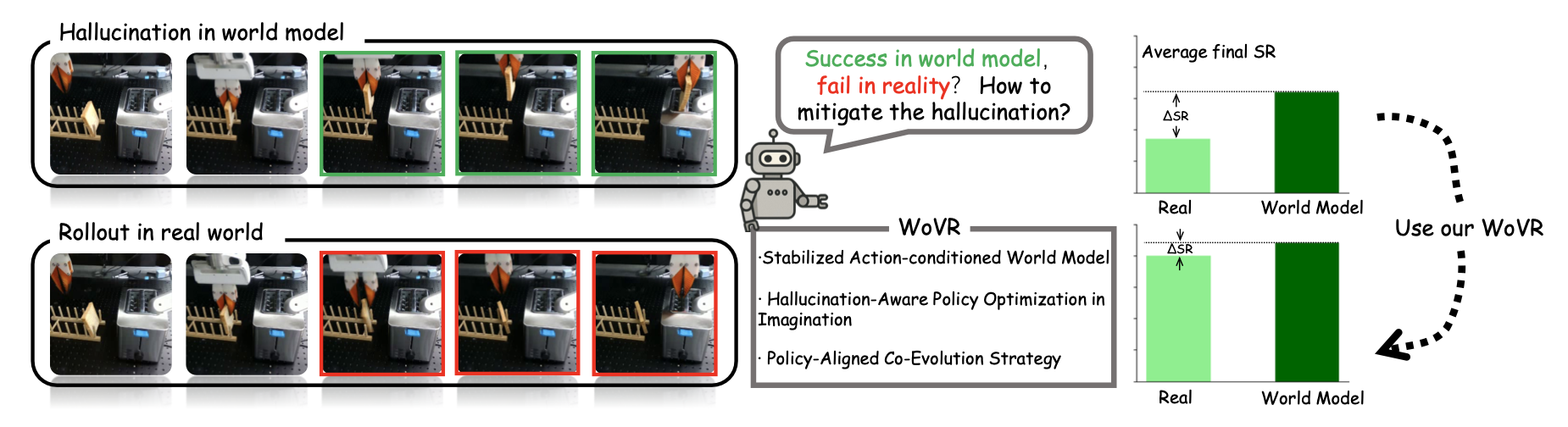
针对VLA模型的在线强化学习微调
基于策略的强化学习[5, 12]已被越来越多地用于微调VLA模型,超越了模仿学习[5, 6]。然而,将在线基于策略的微调直接应用于真实机器人仍然不切实际,因为此类方法需要大规模并行部署、重复的环境重置以及紧密耦合的策略-环境交互,这些在实际硬件中难以实现。为了缓解这一问题,一些离线策略方法[8, 25]引入离线数据重用或人工干预,但通常会面临可扩展性有限和在线更新期间性能下降的问题。另一种方法是构建大规模的真实机器人基础设施,但现有系统[26, 27]仍然无法在实际应用中大规模地支持完全基于策略的算法。这些局限性表明,VLA 在线强化学习的挑战是系统性的,而不是算法性的,这促使人们采用基于世界模型的方法,将策略优化与现实世界的交互解耦。
世界模型的幻觉问题
幻觉不仅仅是生成过程中产生的假象——它从根本上破坏强化学习。在闭环自回归展开中,预测误差会随着预测范围的延长而累积,原因如下:
自回归反馈:模型会根据自身生成的帧进行调整,从而放大早期的小误差;
分布偏移:随着策略的演变,其行动分布会偏离用于训练世界模型的数据,从而增加分布外预测失败的情况。
如果直接使用想象的轨迹进行策略优化,强化学习就会倾向于利用系统性的模型误差,而非真实的任务进展。这就引出了一个关键问题:
如果世界模型不可避免地会产生幻觉,强化学习如何在不完美的想象动态下保持可靠性?
WoVR
用世界模型进行强化学习主要不是一个建模问题,而是一个可靠性问题。为了使基于世界模型的强化学习切实可行,必须在三个相互关联的层面上控制幻觉:可控的模拟器设计、可靠的交互协议以及策略-模型对齐。为此,WoVR,一个基于世界模型的框架,用于后训练视觉-语言-动作策略的强化学习,它基于 RLinf [24] 构建。WoVR 并不假设学习的世界模型是一个忠实的模拟器,而是明确地规范强化学习如何与不完美的想象动态进行交互。
首先通过构建一个具有稳定自回归上下文建模的、可控动作的视频世界模型来增强模拟器本身,从而减少长期漂移和结构崩溃。然而,仅仅改进模拟器是不够的,因为预测误差不可避免地会在长时间的展开过程中累积。因此,通过关键帧初始化展开(KIR)来重塑想象交互,通过在任务关键状态附近初始化轨迹来缩短有效预测深度,从而限制学习过程中幻觉的累积。最后,由于策略优化会改变动作分布并导致策略与世界模型之间的分布不匹配,引入PACE,一种策略对齐的协同进化策略,它通过在不断演化的策略分布下迭代地优化世界模型来恢复对齐,而无需持续的在线监督。这些组件共同构成一个统一的、幻觉-觉察的强化学习框架,从而能够在想象中实现可靠的策略优化。
提出一种名为WoVR的基于世界模型可靠性驱动强化学习框架,用于后训练的视觉-语言-动作(VLA)策略,无需并行进行现实世界交互。如图所示,WoVR将学习的世界模型视为一个生成式模拟器,并围绕闭环想象中的幻觉控制构建整个强化学习流程。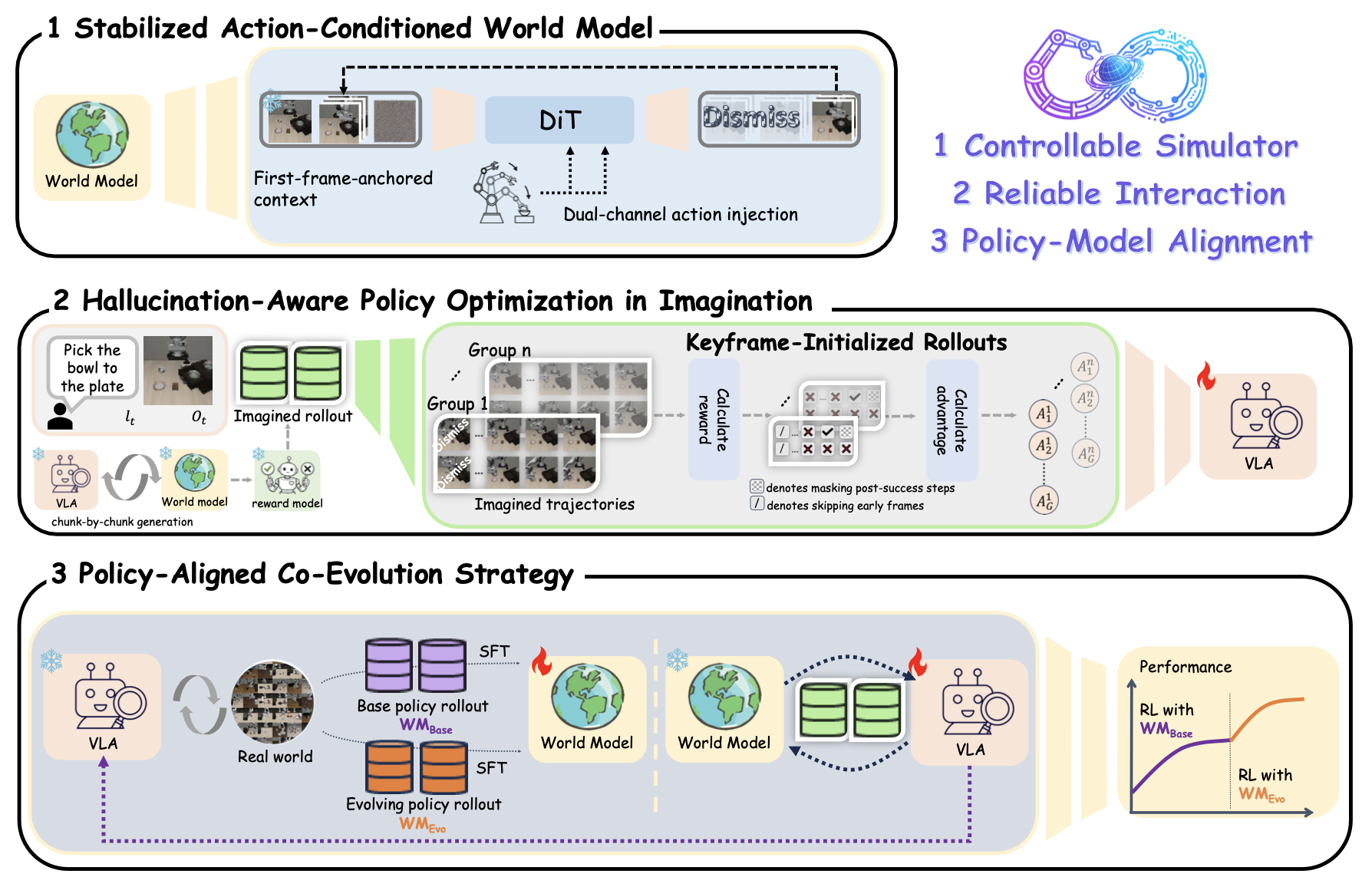
具体而言,WoVR在三个相互关联的层面上调节可靠性。(1) 模拟器层面的控制:构建一个动作可控、展开稳定的视频世界模型,该模型采用双通道动作注入和首帧锚定来抑制长时域漂移。(2) 交互层面的重塑:通过关键帧初始化展开(KIR)和掩码GRPO重新设计想象的交互,以减少有效误差深度并防止对幻觉成功的过度优化。 (3)对齐层面的调控:引入PACE,一种策略-模型协同演化策略,它通过定期将世界模型与演化策略对齐来缓解分布偏移。
这些组件共同实现完全在想象中可扩展且可靠的在线策略优化。
问题描述
虽然基于策略的强化学习为微调VLA策略提供一个原则性的框架,但由于交互成本高昂且环境并行性有限,将其直接应用于真实世界的机器人环境中往往不切实际。为了解决这一局限性,目标是用一个学习的世界模型来替代真实环境交互,该模型可以作为策略优化的模拟器。
稳定的动作条件世界模型
WoVR 依赖于学习的视频世界模型作为闭环想象交互的生成模拟器。然而,长时域展开容易出现幻觉,随着展开长度的增加,全局场景结构会逐渐漂移,背景也会坍塌。因此,设计的世界模型既可由动作控制又具有展开稳定性,从而确保模拟的动态在迭代的、策略驱动的生成过程中保持一致。
骨干网络和动作条件。世界模型构建于 Wan2.2-TI2V-5B 视频扩散骨干网络 [20] 之上。与传统的图像-到-视频生成不同,具身模拟需要显式的动作条件,以确保预测的状态转换能够因果地响应策略。为此,通过双通道动作注入设计(如图所示)将 Wan2.2-TI2V 重构为一个动作条件生成器,该设计在保留原始 DiT 结构的同时,实现帧级可控性。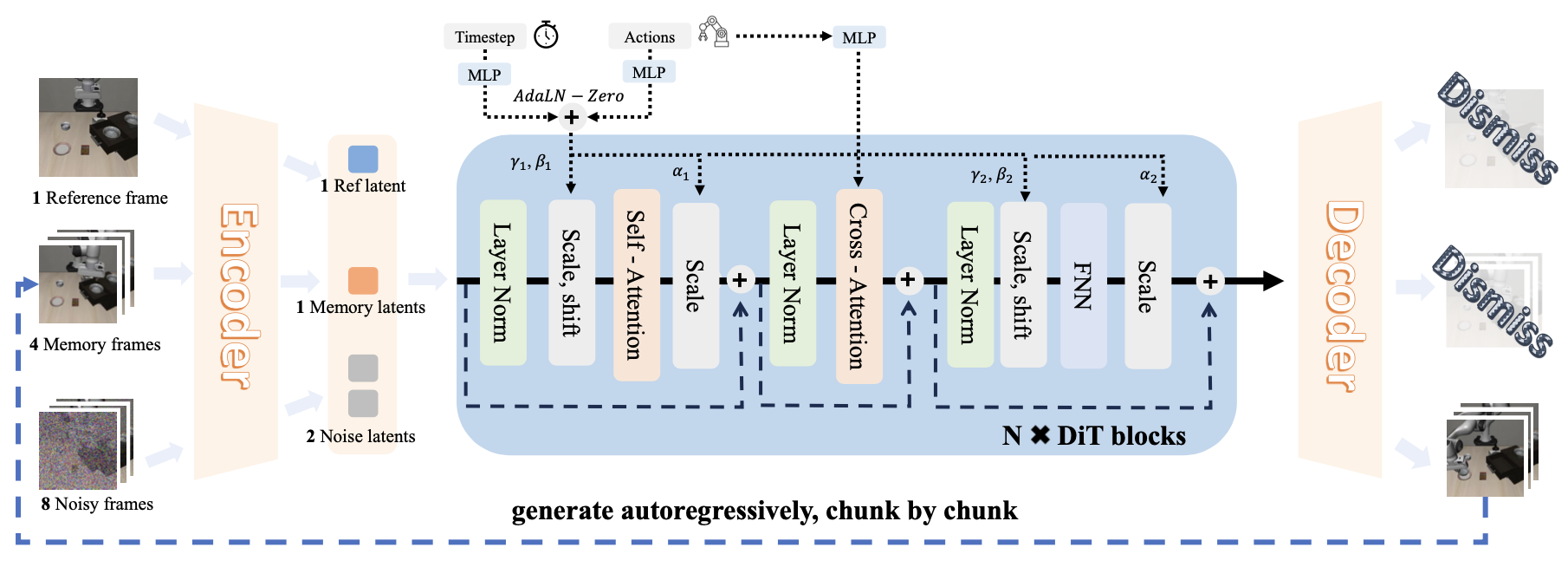
具体而言,在每个 DiT 模块中,动作嵌入通过两条互补的路径影响生成过程。首先,动作嵌入与扩散时间步嵌入融合,并通过 AdaLN-Zero 式调制应用,直接在特征层塑造去噪动态。其次,保留原有的交叉注意算子,但用动作嵌入替换文本嵌入,使得动作能够跨层全局地调控网络。这两条路径共同为动作调控的视频生成提供局部调制和全局上下文。
首帧锚定用于提升展开稳定性。即使动作调控作用很强,逐块自回归生成仍然会累积误差,导致空间漂移和背景逐渐塌陷。为了抑制这种长期退化,采用首帧锚定的推理上下文。在每个自回归步骤中,模型以 [o_0, o_t′−c′:t′] 为条件,该条件将当前片段的初始参考帧与前一个片段的最新记忆帧连接起来。这种持续的参考约束全局外观和场景布局,因为许多自注意头在去噪过程中自然会关注第一帧(如图所示自注意概率图),这与之前的研究结果一致 [50, 51, 31]。
通过双通道动作条件化和首帧锚定,获得一个展开稳定的世界模型,该模型可用作闭环交互的生成模拟器。从首帧锚定的上下文 [o_0, o_t′−c′:t′] 出发,首先使用 Wan 编码器将其编码为潜表示 [z_0, z_t−c:t]。然后,对下一个数据块采样高斯噪声潜变量 znoise_t+1:t+H ∼ N (0, I),并将拼接后的潜变量 [ z_0, z_t−c:t, znoise_t+1:t+H ] 输入到一系列动作条件化的 DiT 块中。模型预测未来的潜变量 zˆ_t+1:t+H,这些潜变量被解码成帧 oˆ_t′+1:t′+H′ 并添加到上下文中。通过迭代这种逐块处理的过程,世界模型在策略动作下生成长时程想象展开,同时保持全局场景一致性,这些展开随后被用作强化学习的模拟环境。
用精整的流目标函数 [52] 训练世界模型。令 x_1 = z_t+1:t+H 表示目标未来潜变量,x_0 ∼ N (0, I) 表示相同形状的噪声。给定采样时间 t ∈ [0, 1],得到中间潜变量 x_t,并训练模型 u(·; φ) 来预测速度 v_t。
为了减少闭环展开中的训练-推理差距,还通过在训练期间向非参考上下文潜变量 z_t−c:t 注入扩散噪声来应用噪声上下文。这可以抑制脆弱的视觉上下文复制,并在模型长期使用自生成帧时提高鲁棒性 [53, 46]。
当作为强化学习的模拟器时,世界模型还必须提供奖励信号。在现实世界的机器人操作中,设计密集奖励通常是不切实际的,训练通常依赖于稀疏的成功标注。因此,引入一个学习型奖励分类器,该分类器基于预测的下一个观测值生成二元成功信号。具体来说,给定世界模型生成的观测值 õ_t+1,奖励模型 R_ψ 预测任务成功的概率,得到稀疏奖励 r_t+1。
参照 HiL-SERL [16],奖励分类器被实现为一个轻量级网络,并使用二元交叉熵 (BCE) 损失函数在已标记的成功状态上进行训练。
想象中的幻觉-觉察策略优化
WoVR 通过与学习的世界模型交互来优化 VLA 策略,该世界模型充当闭环想象展开的生成模拟器。关键难点在于,在从初始状态开始的长时域展开中,世界模型误差会早期累积,并最终产生视觉上合理但物理上错误的转换,甚至产生虚假的成功信号。如果强化学习简单地信任此类展开,则策略会倾向于优化幻觉结果,而不是实际的任务进展。
为了降低想象交互的有效误差深度,引入关键帧初始化展开 (KIR)。如图所示,并非总是从episode起始点 o_0 开始初始化展开,而是从靠近任务关键中间状态(尤其是当前策略遇到的失败状态)的关键帧 o_k 开始初始化一部分展开。这样做的动机是,许多决定性的接触和修正都发生在这些状态附近,而从 o_0 开始则迫使世界模型在到达这些状态之前预测一个较长的前缀,在此期间,累积误差可能已经导致展开偏离轨道。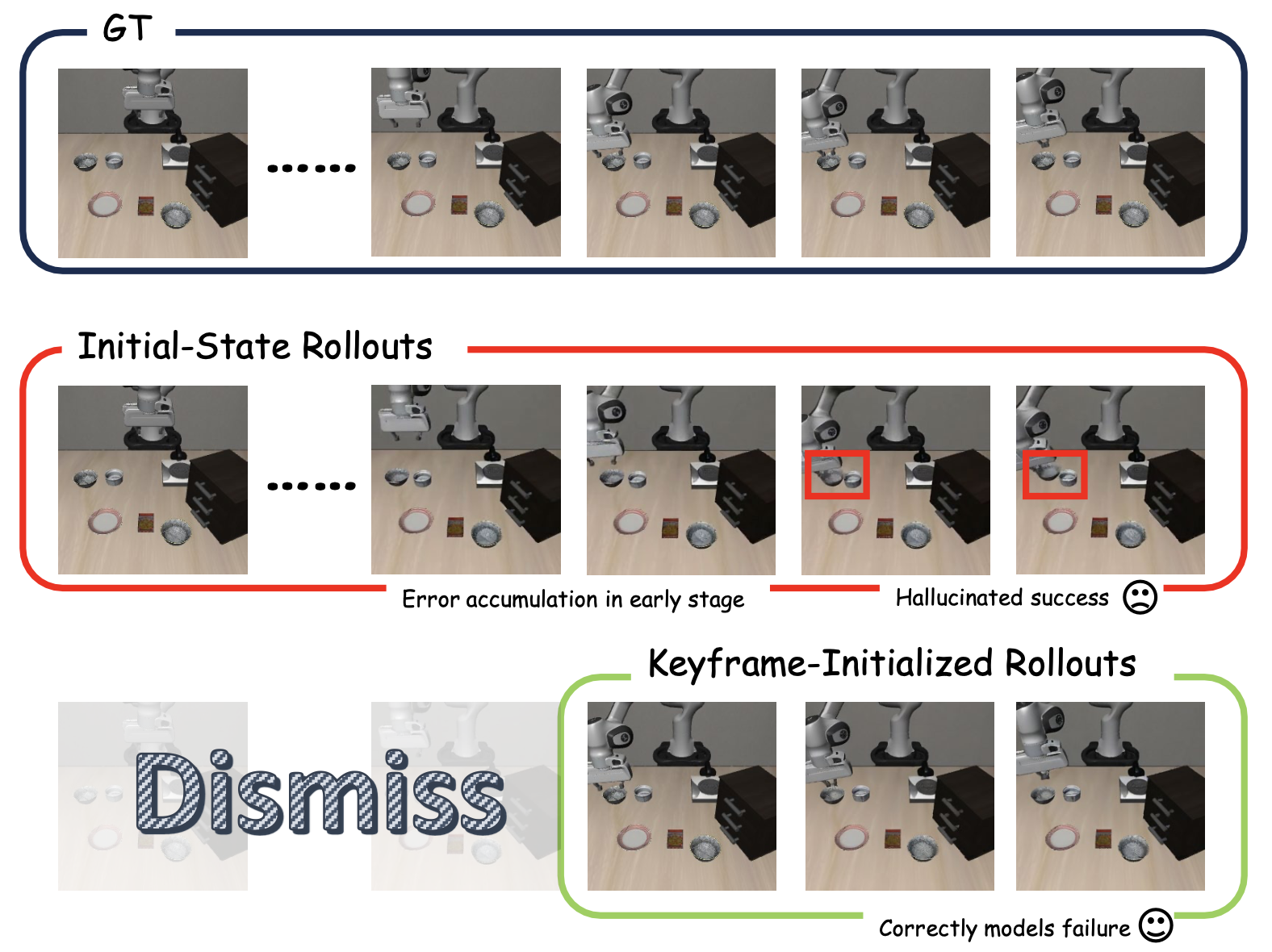
采用组相对策略优化 (GRPO) 来使用想象的展开更新策略。对于每次更新,采样一组想象的轨迹并计算组相对优势,然后优化一个裁剪后的 GRPO 目标函数。由于在想象中取得成功后,幻觉往往会占据主导地位,因此对成功后的步骤进行掩码,并将每条轨迹按其有效长度进行归一化。
这个GRPO目标函数互补KIR:关键帧初始化的展开往往能以较少的有效步骤达到任务分辨率,而轨迹长度归一化增加它们在每个时间步的贡献,因此梯度主要由短的、任务关键的片段构成,而不是由长的、容易漂移的连续部分构成。
PACE:策略协同演化
虽然策略优化完全在已学习的世界模型中进行,但策略的动作分布会不断演化,并逐渐偏离用于训练初始世界模型的数据。这种固有的分布偏移会导致模拟器与改进策略之间不断累积的不匹配,最终降低预期部署的可靠性。
为了解决这个问题,引入 PACE,一种世界模型-策略协同演化策略。PACE 不再将世界模型视为策略优化过程中固定的静态模拟器,而是允许世界模型和 VLA 策略在训练过程中协同演化。
具体来说,通过低频的、策略驱动的细化来实现这种协同演化:首先使用从基础 VLA 策略收集的轨迹训练一个初始世界模型,记为 WM_Base。在 WM_Base 中完成第一阶段的策略优化后,收集一组在演化后的策略下进行的额外部署,并用它们来进一步细化世界模型。改进后的模型被称为 WM_Evo。
重要的是,这种改进仅执行一次(或以极低的频率执行),这使得 PACE 与传统的基于模型强化学习方法区别开来。传统的基于模型强化学习方法在策略优化过程中会持续高频地更新动态模型。
这种低频改进提供两个关键优势。首先,与现实世界的在线强化学习不同,它不需要在策略训练期间持续进行人工监督或环境重置,从而显著降低操作开销。其次,通过将世界模型与不断演化的策略分布对齐,PACE 可以缓解模型误差的累积,并在不牺牲训练稳定性的前提下保持模拟器的可靠性。
系统实现。基于 RLinf [24] 构建 WoVR,以支持高效的分布式虚拟部署和训练。具体来说,将 RLinf 的环境后端替换为学习的世界模型,从而实现可扩展的闭环部署,而无需使用真实世界模拟器。
世界模型是否稳定、可控且有效?
首先研究提出的世界模型是否足够稳定、可控且高效,能够作为闭环强化学习的模拟器。具体而言,关注在分块自回归推理下,长时域、动作条件视频生成,因为建模误差可能会累积并严重影响下游策略优化。
实验设置。所有世界模型评估均在 LIBERO 环境 [59] 中进行。收集 3000 条 VLA 展开轨迹(每条轨迹长度为 512 帧)用于训练世界模型。此外,还专门使用 200 条相同长度的保留轨迹进行评估。将 WoVR 与 WMPO 中采用的三种代表性动作条件世界模型进行比较:EVAC、Cosmos-Predict2 和 OpenSora。其中,EVAC 基于末端执行器的绝对动作来生成视频,而 Cosmos-Predict2、OpenSora 和 WoVR 都使用残差动作表示。
在评估过程中,所有基线模型均遵循相同的分块自回归生成协议,以确保公平比较。具体而言,每个模型基于一个包含 4 帧视觉上下文和一个 8 步动作块的条件,预测未来的视频片段,并自回归生成后续的 8 帧。对于第一个动作块,由于仅有一个初始图像可用,因此会复制该初始帧以填充上下文窗口,从而使不同方法的推理过程保持一致。用标准视频生成指标(包括 LPIPS、FID、FVD 和 FloLPIPS)将预测视频与真实轨迹进行比较,从而对生成的展开视频进行定量评估。
WoVR能否有效提高VLA任务性能?
接下来,评估所提出的世界模型是否能够有效地支持强化学习,并提升 VLA 策略的任务性能。除了世界模型的保真度之外,本实验还直接评估 WoVR 作为策略优化模拟器的实际价值。
实验设置。在多个 LIBERO 任务套件上进行策略优化实验,包括空间、目标、目标和长任务套件 [59]。作为基础策略,遵循 SimpleVLA-RL [17] 的方法,从 OpenVLA-OFT 初始化,并进行单轨迹监督微调。
每个 LIBERO 套件包含 10 个任务。对于每个套件,分配 2500 条轨迹的真实环境部署预算。首先使用基础 VLA 策略收集 1500 条轨迹(每个任务 150 条),用于训练初始世界模型 WM_Base。在模拟环境中完成第一阶段的策略优化后,在更新后的策略下额外收集 1000 条轨迹,并用它们来优化世界模型 WM_Evo,使模拟器与不断演化的策略分布保持一致。为了平衡对齐质量和计算效率,在实践中仅执行一次协同进化步骤,从而实现从 WM_Base 到 WM_Evo 的一次精细化,而非多次迭代交替。
为了确保公平比较,所有方法均分配相同的真实环境部署预算,即每个测试套件 2500 条轨迹。对于基于世界模型的方法(包括 WMPO 和 WoVR),这些轨迹专门用于世界模型的训练和精细化,而策略优化则完全在已学习的世界模型中通过虚拟部署进行,无需与真实环境模拟器进行进一步交互。相比之下,GRPO 直接与真实环境模拟器交互,并消耗相同的 2500 条轨迹预算用于策略内优化。
使用 WoVR 优化的策略能否可靠地迁移到现实世界?
最后,评估使用 WoVR 优化的策略是否能够可靠地迁移到真实世界的机器人操作任务中。
实验设置:实验在 Franka Emika Panda 机器人上进行。考虑两个接触密集型操作任务:(i)拾取香蕉,需要拾取香蕉并将其放在盘子上;(ii)拾取面包,需要拾取面包并将其放在指定的面包标记(marker)上。对于每个任务,收集 10 个远程操作演示来预训练基础 VLA 策略,并额外收集 150 个基于基础策略的展开来训练世界模型。训练完成后,将得到的策略部署到物理机器人上,并在每个任务的 30 次独立试验中评估成功率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献226条内容
已为社区贡献226条内容

所有评论(0)