预训练实践 | 国内首个全国产化千亿参数细粒度开源MoE语义大模型TeleChat3-105B-A4.7B-Thinking
TeleChat3-105B-A4.7-Thinking是 TeleChat系列国内首个开源的全自主创新千亿参数细粒度MoE语义大模型,由中国电信人工智能研究院(TeleAI)研发训练,在问答、写作、数学、代码、Agent等多维度,与业内头部模型比肩,特别在代码能力、复杂任务通用问答、细粒度MoE等维度上有显著的效果提升,同时采用创新训练方式,加快模型在训练初期的收敛速度,增强模型在训练中的稳定性
TeleChat3-105B-A4.7-Thinking,国内首个开源的全自主创新训练的千亿参数细粒度MoE语义大模型,在问答、写作、数学、代码、Agent等多维度比肩业内头部。该模型基于昇腾与MindSpore AI框架完成训练,现已上线魔乐社区,欢迎广大开发者下载体验!
🔗https://modelers.cn/models/TeleAI/TeleChat3-105B-A4.7B-Thinking
以下为基于昇思MindSopre的手把手预训练实践教程。
01 模型介绍
TeleChat3-105B-A4.7-Thinking是 TeleChat系列国内首个开源的全自主创新千亿参数细粒度MoE语义大模型,由中国电信人工智能研究院(TeleAI)研发训练,在问答、写作、数学、代码、Agent等多维度,与业内头部模型比肩,特别在代码能力、复杂任务通用问答、细粒度MoE等维度上有显著的效果提升,同时采用创新训练方式,加快模型在训练初期的收敛速度,增强模型在训练中的稳定性。具体请参考 TeleChat3(https://github.com/Tele-AI/TeleChat3)。
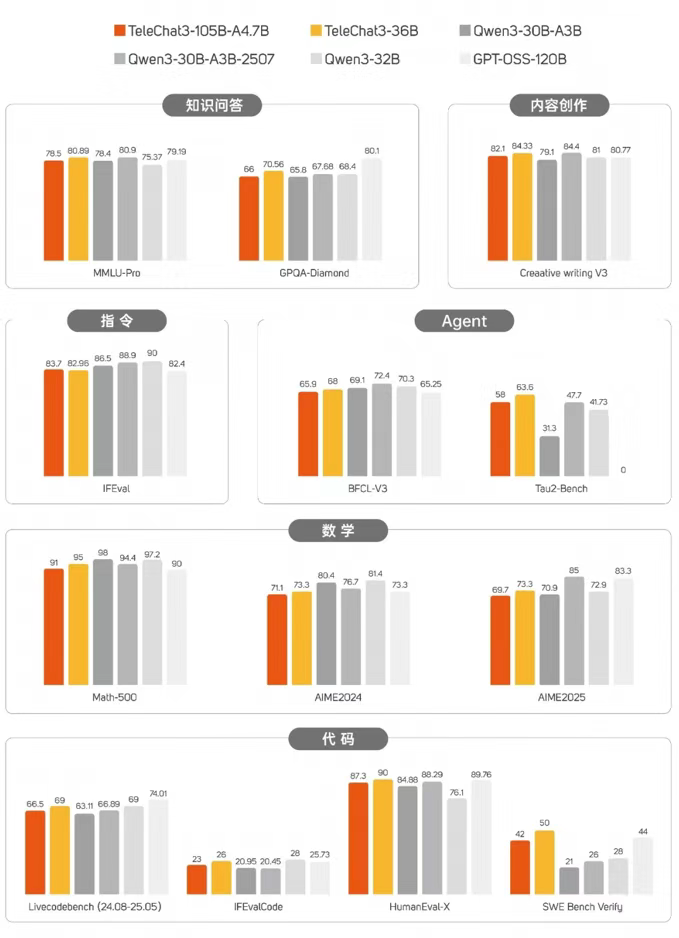
1、代码能力提升,复杂任务拿捏住了!
面对综合任务场景,TeleChat3-105B-A4.7-Thinking 高效拆解任务需求,整合多项代码能力,一次性交付出完整可运行的代码。
省去大量人工调试时间投入,运行流畅,审美在线!
2、细粒度MoE, 术业有专攻,协同更高效!
此前,中国电信人工智能研究院(TeleAI)与中电信人工智能科技有限公司已陆续开源原创打造的 TeleChat、TeleChat2 及TeleChat2.5系列模型,以传统稠密参数架构为主,模型尺寸覆盖十亿到千亿,构建了全尺寸大模型开源布局。
上半年,星辰语义大模型的首个MoE架构模型TeleChat2-39B-A12B也正式开源,采用粗粒度MoE架构,初步实现知识模块化存储,按需唤醒相关专家模块。

为了进一步提升MoE 大模型的效率与性能,让参数利用更充分,TeleAI团队基于昇腾与MindSpore训练框架完成了TeleChat3-105B-A4.7-Thinking 的全自主创新训练。该模型采用细粒度 MoE 架构,基础模型训练数据超15T,共包括1个共享专家和192个路由专家(每次激活4个专家),模型整体共105B参数量,实际激活参数为 4.7B,专家稀疏比处于业界前列。
面对不同的任务类型,更加细分的专家子模块实现了术业有专攻,模块之间也实现了更精准、更任务导向的协同。
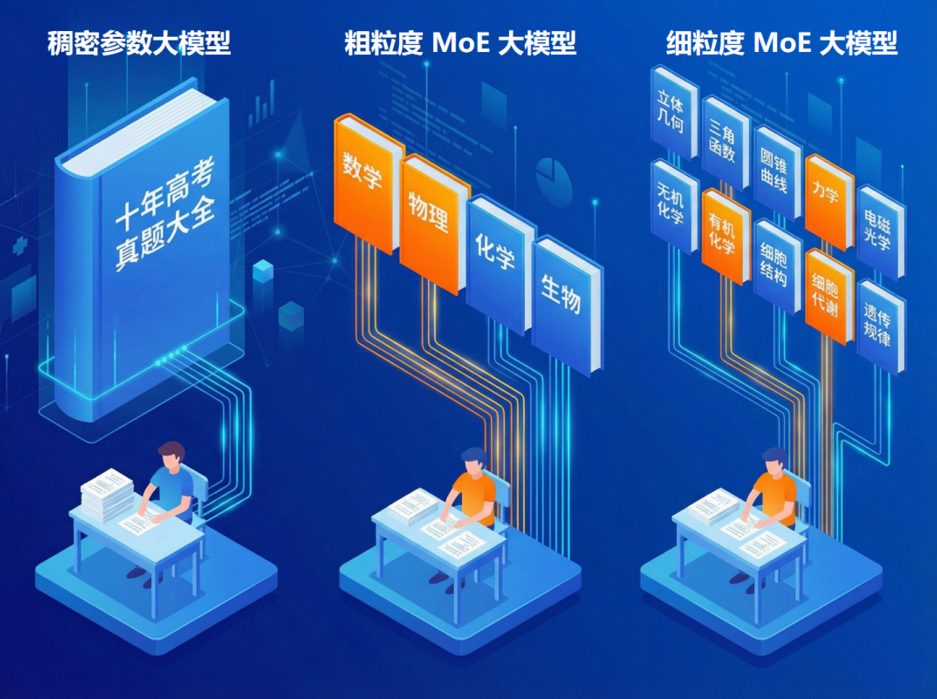
打个比方,假如大模型是个理综考生,稠密参数大模型就是从一本“十年高考真题大全”合订本里找思路,知识庞杂,效率低下。粗粒度模型,则实现了初步的学科分类和调用,减少了无效的知识调用。细粒度MoE,则是更进一步,特定的题目只调用特定的细分知识点组合,见招拆招,精准调配。
此外,TeleAI还同步开源了稠密参数模型TeleChat3-36B-Thinking模型,在知识、逻辑推理、智能体等维度实现了能力提升,并实现了文本创作、语义理解、角色扮演等任务的针对性优化。
3、训练方式创新:黑科技拉满,收敛稳、效率优
TeleAI 科研团队采用细粒度的模型初始化方式和学习率控制,对不同权重采用不同的初始化方式和学习率,加快模型在训练初期的收敛速度,增强模型在训练中的稳定性。
基础模型训练通过两个阶段预训练和一个阶段中训练完成,总计训练 15T tokens。
预训练第一阶段以通识数据(网页、书籍、多语言数据等)为主,主要提升模型知识能力;第二阶段增大 STEM 和代码相关数据占比,提升模型推理相关能力。
中训练阶段以合成数据为主,包含仓库级代码任务、高质量数理逻辑数据以及智能体任务数据,持续提升模型逻辑推理和智能体相关能力。
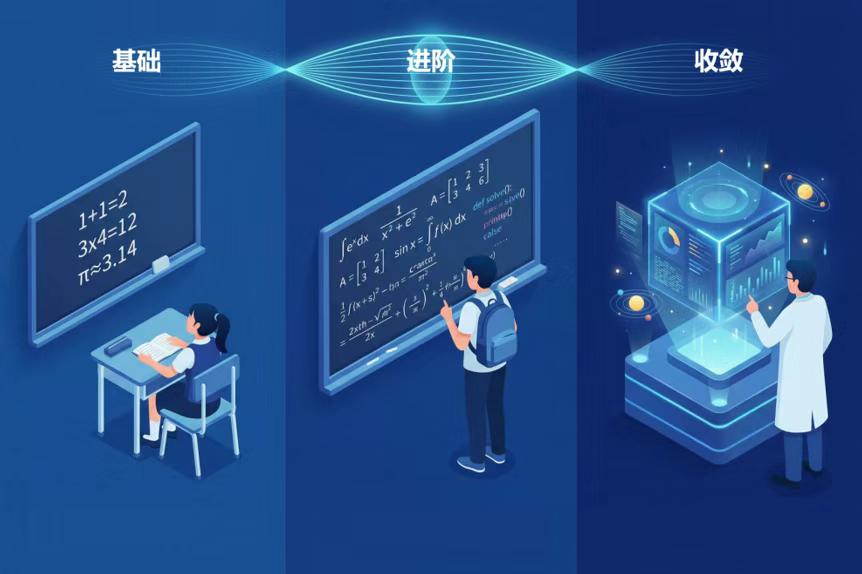
后训练也包含两个阶段:
第一阶段模型冷启动微调,为取得更好的冷启动效果,针对微调数据难度和多样性做了大量筛选工作,大幅提升模型多任务理解及指令遵从能力。
第二阶段强化学习,采用基于规则校验奖励和 RM 打分模型融合的方式。针对数理、代码、指令遵循等采用规则校验;针对文本创作、语义理解、角色扮演等任务采用专项训练 RM 模型进行打分。
02 基于昇思MindSpore的系列优化特性
TeleChat3-105B-A4.7-Thinking是基于昇思MindSpore AI框架训练的MoE类模型,通过昇思MindSpore提供的各种并行及加速特性,实现千亿级细粒度专家MoE模型高效训练,典型的优化特性如下:
- 核隔离+CPU绑核: 减少host侧进程抢占,提升算子下发性能。
- 断流优化:FFN使用异步拷贝,减少流同步耗时。
- DVM调优:Cube类算子Tiling在线调优、MM-AssignAdd融合、vector融合,提升算子性能。
- 计算通信掩盖优化:vpp 1f1b通信掩盖、dw反向通信掩盖等特性,模型并行通信掩盖率 > 60%。
- 策略优化&重计算调优:扩大BS增加Device算子执行开销,掩盖host的性能抖动;增大TP换取内存空间做重计算调优。
通过端到端的加速特性优化,实现MFU的绝对值提升近14%。
03 快速开始
1、环境安装
按照上述版本配套,参考环境安装指南(https://www.mindspore.cn/mindformers/docs/zh-CN/master/installation.html)安装运行环境。
2、模型下载
从魔乐社区下载所需的模型文件,包括模型权重、Tokenizer、配置等(从头预训练不需加载权重)。链接如下:
https://modelers.cn/models/TeleAI/TeleChat3-105B-A4.7B-Thinking
3、数据集下载
MindSpore Transformers 以下面的数据集为例提供了 TeleChat3 的预训练流程的使用案例,实际训练时可参考数据集(https://www.mindspore.cn/mindformers/docs/zh-CN/master/feature/dataset.html)章节制作数据集。请在执行任务前提前下载所需数据集。链接如下:
- 任务:预训练
- 数据集名称:WikiText-103
- 下载链接:https://dagshub.com/DagsHub/WIkiText-103/src/main/dataset/tokens/wiki.train.tokens
- 说明: 用于预训练的大规模文本数据集
4、预训练样例
预训练是指在大规模无标注数据上训练模型,使其能够全面捕捉语言的广泛特性。在MindSpore官网提供了详细的指导。(https://www.mindspore.cn/mindformers/docs/zh-CN/master/guide/pre_training.html)
1)数据预处理
MindSpore Transformers 预训练阶段当前已支持Megatron格式的数据集(https://www.mindspore.cn/mindformers/docs/zh-CN/master/feature/dataset.html#megatron%E6%95%B0%E6%8D%AE%E9%9B%86)。用户可以参考数据集章节,使用 MindSpore 提供的工具将原始数据集转换为 Megatron 格式。
制作Megatron格式数据集,需要经过两个步骤。首先将原始文本数据集转换为jsonl格式数据,然后使用MindSpore Transformers提供的脚本将jsonl格式数据转换为Megatron格式的.bin和.idx文件。
wiki.train.tokens 转为 jsonl 格式数据
用户需要自行将wiki.train.tokens数据集处理成jsonl格式的文件。作为参考,文档末尾的FAQ(https://gitee.com/mindspore/mindformers/tree/master/configs/telechat3#faq)部分提供了一个临时转换方案,用户需要根据实际需求自行开发和验证转换逻辑。
下面是jsonl格式文件的示例:
{"src": "www.nvidia.com", "text": "The quick brown fox", "type": "Eng", "id": "0", "title": "First Part"}
{"src": "The Internet", "text": "jumps over the lazy dog", "type": "Eng", "id": "42", "title": "Second Part"}
...
jsonl 格式数据 转为 bin 格式数据
MindSpore Transformers提供了数据预处理脚本toolkit/data_preprocess/megatron/preprocess_indexed_dataset.py用于将jsonl格式的原始文本预料转换成.bin或.idx文件。
这里需要提前下载TeleChat3-105B-A4.7B(https://huggingface.co/TeleChat/TeleChat3-105B-A4.7B)模型的tokenizer文件。
例如:
python toolkit/data_preprocess/megatron/preprocess_indexed_dataset.py \
--input /path/to/data.jsonl \
--output-prefix /path/to/wiki103-megatron \
--tokenizer-type HuggingFaceTokenizer \
--tokenizer-dir /path/to/TeleChat3-105B-A4.7B # 其他规格的模型可以调整为对应的tokenizer路径
运行完成后会生成/path/to/wiki103-megatron_text_document.bin和/path/to/wiki103-megatron_text_document.idx文件。 填写数据集路径时需要使用/path/to/wiki103-megatron_text_document,不需要带后缀名。
2)修改任务配置
MindSpore Transformers 提供了预训练任务的配置文件,用户可以根据实际情况修改配置文件。以下是一个示例配置文件片段,用户需要根据自己的数据集路径和其他参数进行相应修改。
数据集配置
# Dataset configuration
train_dataset: &train_dataset
data_loader:
...
sizes:
- 8000 # 数据集的大小,可以根据实际数据集大小进行调整
...
config:
...
data_path: # 采样比例和Megatron格式数据集路径
- '1'
- "/path/to/wiki103-megatron_text_document"# 替换为实际的Megatron格式数据集路径,此处不带后缀名
数据集路径需要替换为实际的Megatron格式数据集路径。
不同规格和序列长度的并行配置可参考并行配置建议。(https://gitee.com/mindspore/mindformers/tree/master/configs/telechat3#%E5%B9%B6%E8%A1%8C%E9%85%8D%E7%BD%AE%E5%BB%BA%E8%AE%AE)
3)启动预训练任务
通过指定模型路径和配置文件configs/telechat3/pretrain_telechat3_105b_a4b_4k.yaml(https://gitee.com/mindspore/mindformers/blob/master/configs/telechat3/pretrain_telechat3_105b_a4b_4k.yaml)以msrun的方式启动run_mindformer.py(https://gitee.com/mindspore/mindformers/blob/master/run_mindformer.py)脚本,进行16卡分布式训练。您可参考如下方式,拉起两台Atlas 800T A2(64G)训练。
在每台服务器上执行如下命令。设置master_ip为主节点IP地址,即Rank 0服务器的IP;node_rank为每个节点的序号;port为当前进程的端口号(可在50000~65536中选择)。
master_ip=192.168.1.1
node_rank=0
port=50001
bash scripts/msrun_launcher.sh "run_mindformer.py \
--config configs/telechat3/pretrain_telechat3_105b_a4b_4k.yaml \
--auto_trans_ckpt False \
--use_parallel True \
--run_mode train" \
48 8 $master_ip $port $node_rank output/msrun_log False 7200
此处样例代码假设主节点为192.168.1.1、当前Rank序号为0。实际执行时请将master_ip设置为实际的主节点IP地址;将node_rank设置为当前节点的Rank序号;将port设置为当前进程的端口号。
上述命令执行完毕后,训练任务将在后台执行,过程日志保存在./output/msrun_log下,使用以下命令可查看训练状态(由于开启了流水并行,真实loss只显示在最后一个pipeline stage的日志中,其余pipeline stage会显示loss为0)
tail -f ./output/msrun_log/worker_0.log
训练过程中的权重checkpoint将会保存在./output/checkpoint下。
04 结语
相关训练工作的介绍请参考《Training Report of TeleChat3-MoE》
https://arxiv.org/abs/2512.24157
更多详细的模型训练,请参考开源链接
https://gitee.com/mindspore/mindformers/tree/master/configs/telechat3#%E6%A8%A1%E5%9E%8B%E4%B8%8B%E8%BD%BD

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)