垂直领域SFT训练翻车实录:用Y-Trainer解决模型“复读+失忆“困境
本文探讨垂直领域SFT训练中的过拟合与灾难性遗忘问题,提出基于token级梯度调控的NLIRG算法解决方案。该算法通过动态调整不同难度token的训练强度,有效平衡专项与通用能力:对低损失token削减梯度防止过拟合,中等难度token增强梯度促进学习,高损失token梯度归零隔离噪声。相比传统方法,NLIRG无需精确控制数据比例,显著降低调参难度,同时提升训练稳定性和抗噪能力。文章详细介绍了算法
本文将探讨垂直领域SFT训练中常见的过拟合与灾难性遗忘问题,并介绍一种基于token级梯度调控的解决方案——Y-Trainer中的NLIRG算法。文末附实操指南与效果验证方法,助你摆脱训练调参噩梦。
一、垂直SFT的三大"翻车现场"
在垂直领域模型微调过程中,你是否也遇到过这些让人抓狂的场景?
-
模型变复读机:训练loss一路下降,上线后模型却开始机械复读同一种句式,丧失表达多样性
-
能力窄化严重:垂直SFT做得越深入,模型越"专一"——通用能力肉眼可见地下降,工具调用、常识问答等基础能力全面退化
-
数据质量敏感:训练数据稍有噪声(错标、幻觉、格式混乱),模型不仅学坏,还会把原有能力忘得一干二净
传统解法是不断掺入通用语料、反复调整数据比例、做复杂的平衡——结果是调参时间远超训练时间,且效果难以保证。
本文要介绍的Y-Trainer,其核心算法NLIRG(Gradient-driven Nonlinear Learning Intensity Regulation)提供了一种新思路:将训练强度从样本级细化到token级,并实现动态调控。下面详解其原理与实践。

二、为何会"复读/过拟合/灾难性遗忘"?梯度分配不合理是元凶
垂直SFT训练失败的本质,往往不是学习率设置问题,而是梯度分配不合理:
-
低损失token:模型已掌握的内容,若继续同等强度训练,会导致过拟合——模型死记硬背训练集细节,表达越来越模板化
-
极高损失token:通常来自噪声数据或超出模型当前能力范围的内容。若强行学习,梯度会非常"尖锐",轻则训练不稳定,重则破坏已有能力
-
中等难度token:才是真正该投入训练资源的部分——既能提升能力,又不会把模型带偏
NLIRG的核心思想正是基于此:用每个token的loss作为"难度信号",自动为梯度加权,实现精准训练。
三、NLIRG算法详解:为梯度装上智能"油门/刹车"
3.1 算法核心思想
NLIRG(基于梯度的非线性学习强度调节算法)像一位经验丰富的教练,能够:
-
智能识别每个token对模型的难度
-
动态调整训练强度
-
有效防止过拟合和灾难性遗忘
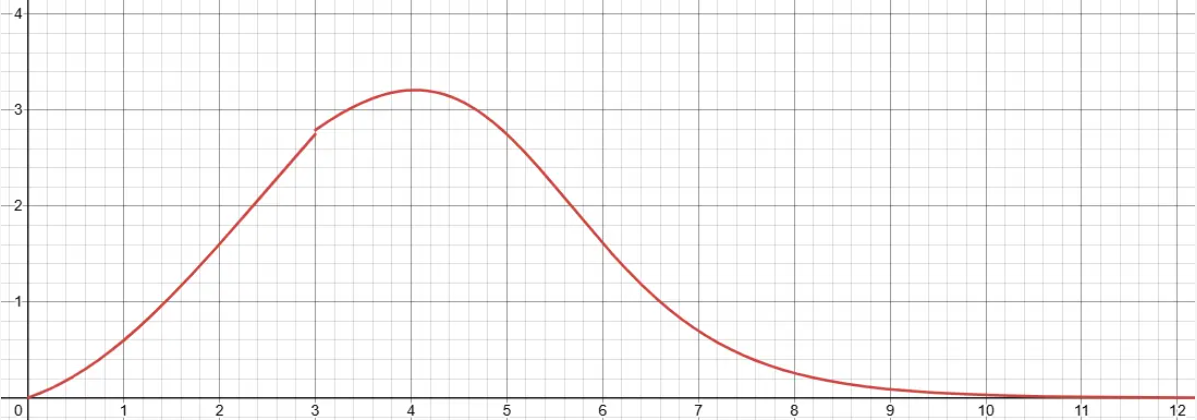
横坐标代表Loss值,纵坐标代表梯度计算权重
3.2 动态权重计算
def dynamic_sigmoid_batch(losses, max_lr=1.0, x0=1.2, min_lr=5e-8,
k=1.7, loss_threshold=3.0, loss_deadline=15.0):
"""
NLIRG核心算法:基于损失值的动态权重计算
参数说明:
- losses: 损失值张量
- max_lr: 最大学习率权重 (默认: 1.0)
- x0: 第一个sigmoid函数的中心点 (默认: 1.2)
- min_lr: 最小学习率权重 (默认: 5e-8)
- k: sigmoid函数的斜率 (默认: 1.7)
- loss_threshold: 损失阈值,区分不同区间 (默认: 3.0)
- loss_deadline: 损失上限,超过此值梯度归零 (默认: 15.0)
返回:权重张量,用于调整反向传播的梯度
"""NLIRG将loss分为四个区间,实施不同的梯度调控策略:
|
损失区间 |
策略 |
目的 |
实际效果 |
|
低损失区间 (loss ≤ 1.45) |
削减梯度 |
避免过拟合 |
防止模型过度记忆简单样本 |
|
中等损失区间 (1.45 < loss < 6.6) |
增强梯度 |
快速学习 |
重点训练对模型有挑战性的样本 |
|
中高损失区间 (6.6 < loss < 15) |
削减梯度 |
保持稳定性 |
防止模型被困难样本带偏 |
|
高损失区间 (loss ≥ 15.0) |
梯度归零 |
隔离噪声 |
忽略明显错误的训练样本 |
以下是动态权重W(L)W(L)的计算公式:
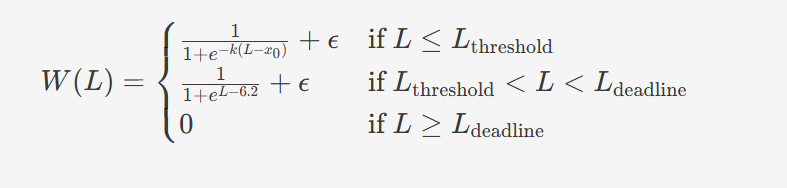
其中L是损失值,W(L)是对应的权重函数
3.3 为何对垂直SFT特别有效?
垂直领域SFT的核心矛盾在于:既要充分学习垂直知识,又要保留通用能力。NLIRG通过token级精细调控,解决了这一矛盾:
-
替代传统混合语料策略:无需依赖掺入通用语料来保护基础能力,通过动态梯度分配自然保留泛化性
-
降低数据平衡难度:无需精确控制数据比例,算法自动区分"该学/不该学/暂时学不动/明显有问题"的token
-
增强噪声抵抗能力:高损失token梯度归零,有效隔离脏数据对模型的污染
四、工程实践:不止是算法,更是训练全流程优化
4.1 Token级批处理技术
为保证token损失计算的准确性,Y-Trainer采用分批次token训练策略:
-
精度保证:小批次训练能更精确地计算每个token的损失
-
内存优化:避免一次性处理过多token导致显存溢出
-
梯度稳定:小批次训练有助于梯度计算的稳定性
实践中通过--token_batch参数控制每次反向传播的token数量,是SFT场景的关键调优参数。
4.2 语料质量评估与排序
Y-Trainer提供了一个实用功能:基于模型响应模式的语料质量评估。
算法原理:通过分析模型对每条语料的响应(损失值和熵的变化),计算语料难度评分
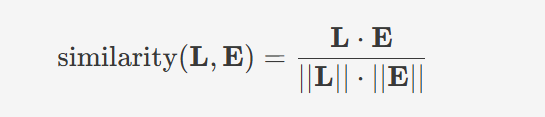
这带来两大实际价值:
-
训练前置质检:提前识别低分语料(通常包含格式错误、答案错误或噪声),优化数据质量
-
训练顺序优化:非简单"从易到难",而是采用难易混合策略,提升训练稳定性与效果
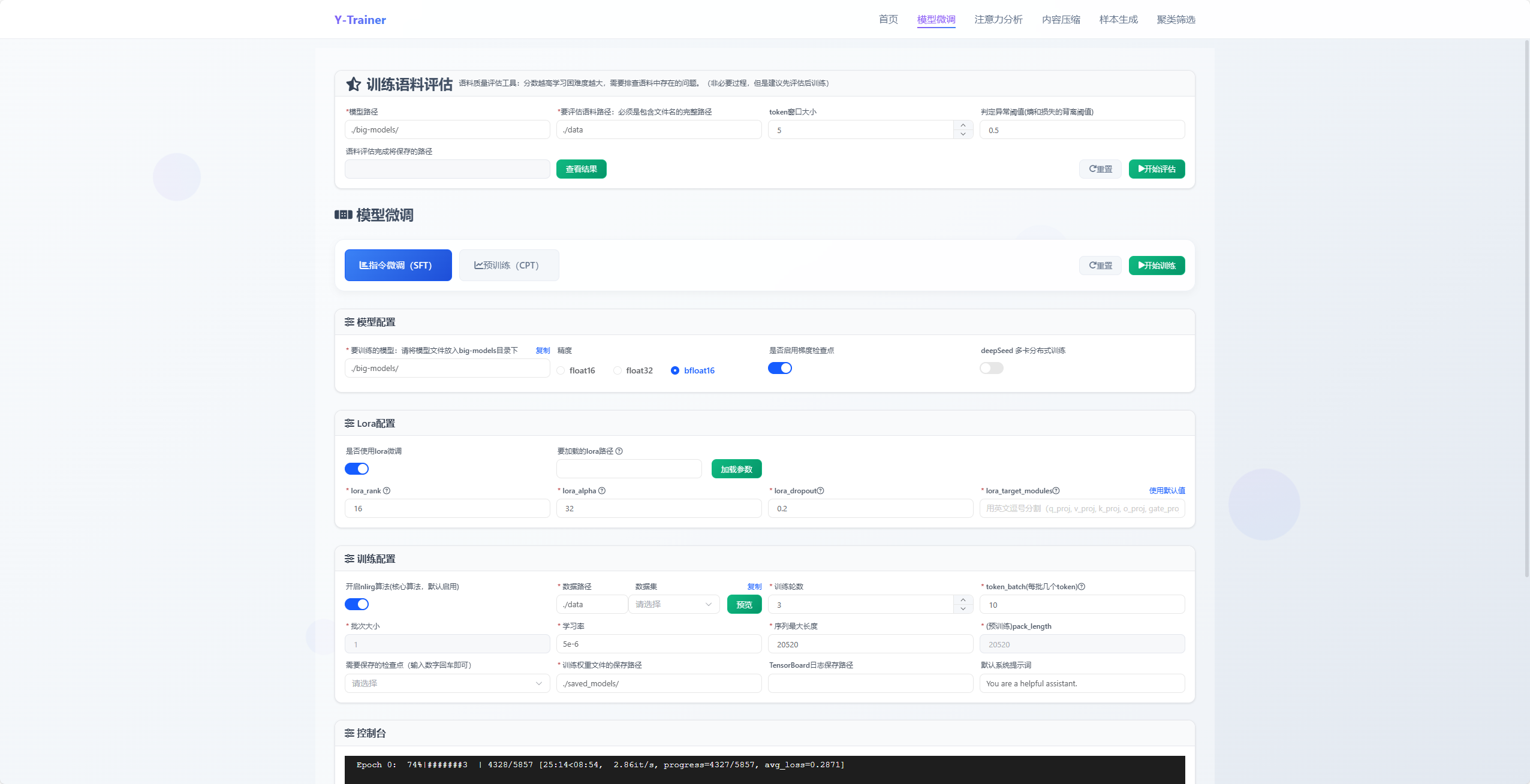
五、快速上手:两行命令解决垂直SFT难题
5.1 单卡LoRA垂直SFT示例
python -m training_code.start_training \
--training_type 'sft' \
--use_NLIRG 'true' \
--use_lora 'true' \
--batch_size 1 \
--token_batch 10 \
--data_path example_dataset/sft_example.json \
--output_dir outputdir
"""
参数说明:
--use_NLIRG: 核心功能,默认启用。启用智能训练优化算法
--model_path_to_load 加载的模型目录
--use_lora: 启用LoRA训练,降低显存需求
--token_batch 10: 每次反向传播处理的token数量,重要参数不建议更改
--checkpoint_epoch '0,1': 在第0轮和第1轮保存检查点
"""关键参数:--token_batch控制单次反向传播的token数,值越小训练更精确稳定,但速度较慢。
5.2 多卡全量CPT训练示例
deepspeed --module training_code.start_training \
--training_type 'cpt' \
--use_NLIRG 'true' \
--use_deepspeed 'true' \
--batch_size 2 \
--pack_length 2048 \
--data_path example_dataset/cpt_example.json \
--output_dir outputdir关键点:pack_length参数用于短文本打包,Deepspeed Stage3提供多卡支持。
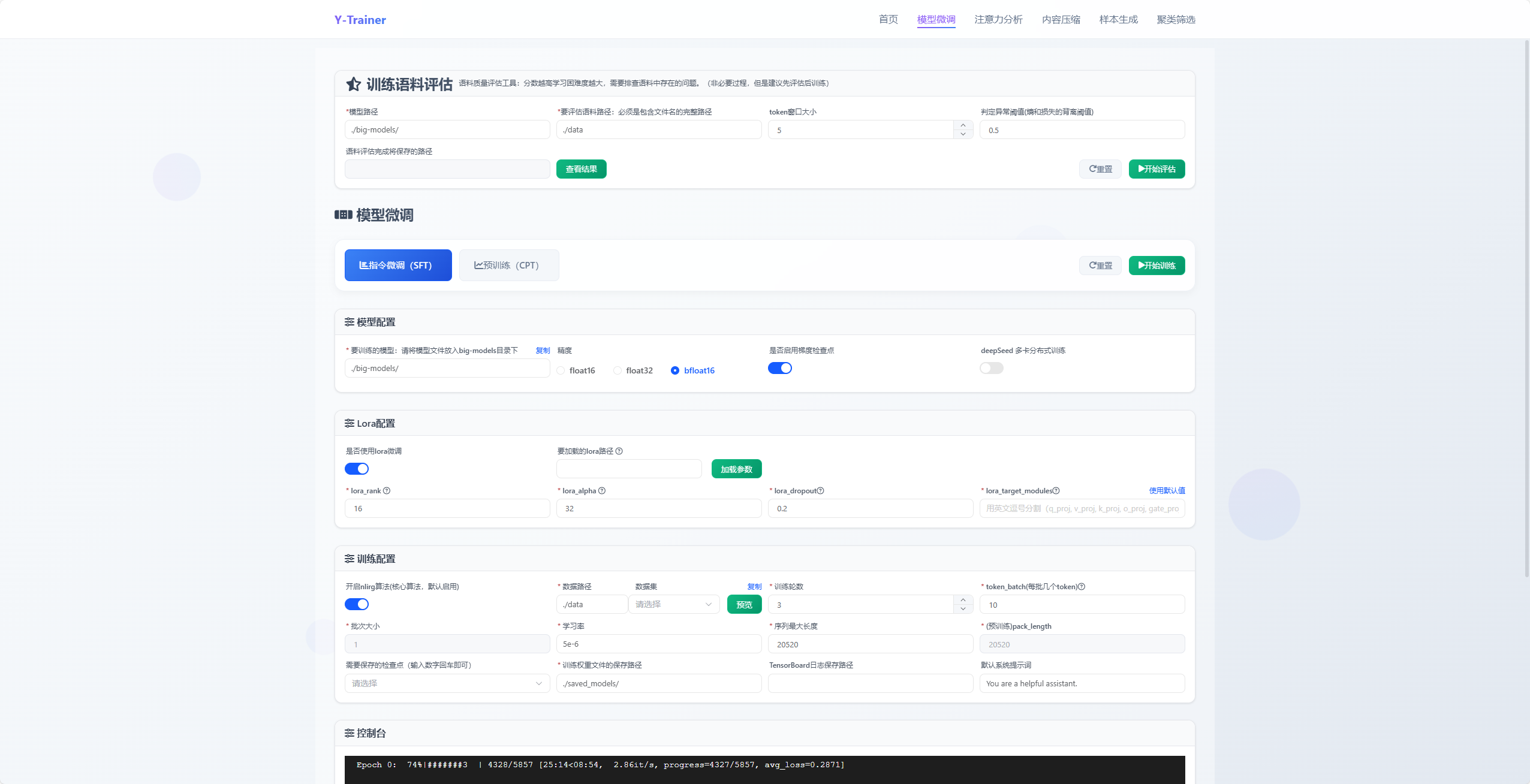
六、效果验证:三步A/B测试法
不要盲目相信理论,用数据说话:
-
建立基线:用同一份垂直数据,关闭NLIRG运行常规SFT作为baseline
-
启用NLIRG:相同配置下开启NLIRG,设置合理token_batch值
-
对比评估:
-
领域任务指标:核心业务指标是否提升
-
通用能力回归:多轮对话稳定性、工具调用、基础常识/代码能力是否保持
-
输出多样性:复读、模板化表达是否减少
-
如果NLIRG版本在保持领域性能的同时,显著减少了通用能力退化和表达单一化,就已证明其价值——你将节省大量后续调参和数据平衡的时间成本。
七、总结与建议
在垂直领域模型训练中,Y-Trainer的NLIRG算法提供了一种新的思考维度:不靠数据混合来保能力,而是通过梯度的精细分配来平衡专项与通用能力。
如果你正面临以下困境:
-
模型越训练越"窄",通用能力持续退化
-
训练结果不稳定,对数据质量过于敏感
-
花费大量时间在数据配比和平衡上
建议将Y-Trainer作为"训练风险控制器"尝试一次。只需调整几个关键参数,就能将训练从翻车边缘拉回正轨。
核心价值不是替代你的领域知识,而是让领域知识更高效、更稳定地注入模型,同时保留其原有的通用智能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)