智能体效率优化最新综述:从Token狂飙到成本可控的进化之路
论文链接:https://huggingface.co/papers/2601.14192大模型智能体(LLM-based Agents)正在成为AI领域的新焦点。但随着应用场景越来越复杂,一个残酷的现实摆在面前:这些智能体虽然功能强大,但实在太"费"了——费时间、费token、费算力。一个简单的任务,可能需要调用几百次API,消耗数万个token,等待数分钟才能得到结果。这种高昂的成本,让智能体
大模型智能体效率革命:从"能用"到"好用"的关键一跃

论文链接:https://huggingface.co/papers/2601.14192
大模型智能体(LLM-based Agents)正在成为AI领域的新焦点。但随着应用场景越来越复杂,一个残酷的现实摆在面前:这些智能体虽然功能强大,但实在太"费"了——费时间、费token、费算力。一个简单的任务,可能需要调用几百次API,消耗数万个token,等待数分钟才能得到结果。这种高昂的成本,让智能体离真正的大规模应用还有不小距离。
来自上海人工智能实验室等多家机构的研究团队,在2026年1月发布了一篇系统性综述论文,首次从效率这个关键维度,全面梳理了智能体领域的研究进展。论文明确提出:高效的智能体不是简单地用更小的模型,而是要在保证任务成功率的前提下,最大限度降低资源消耗。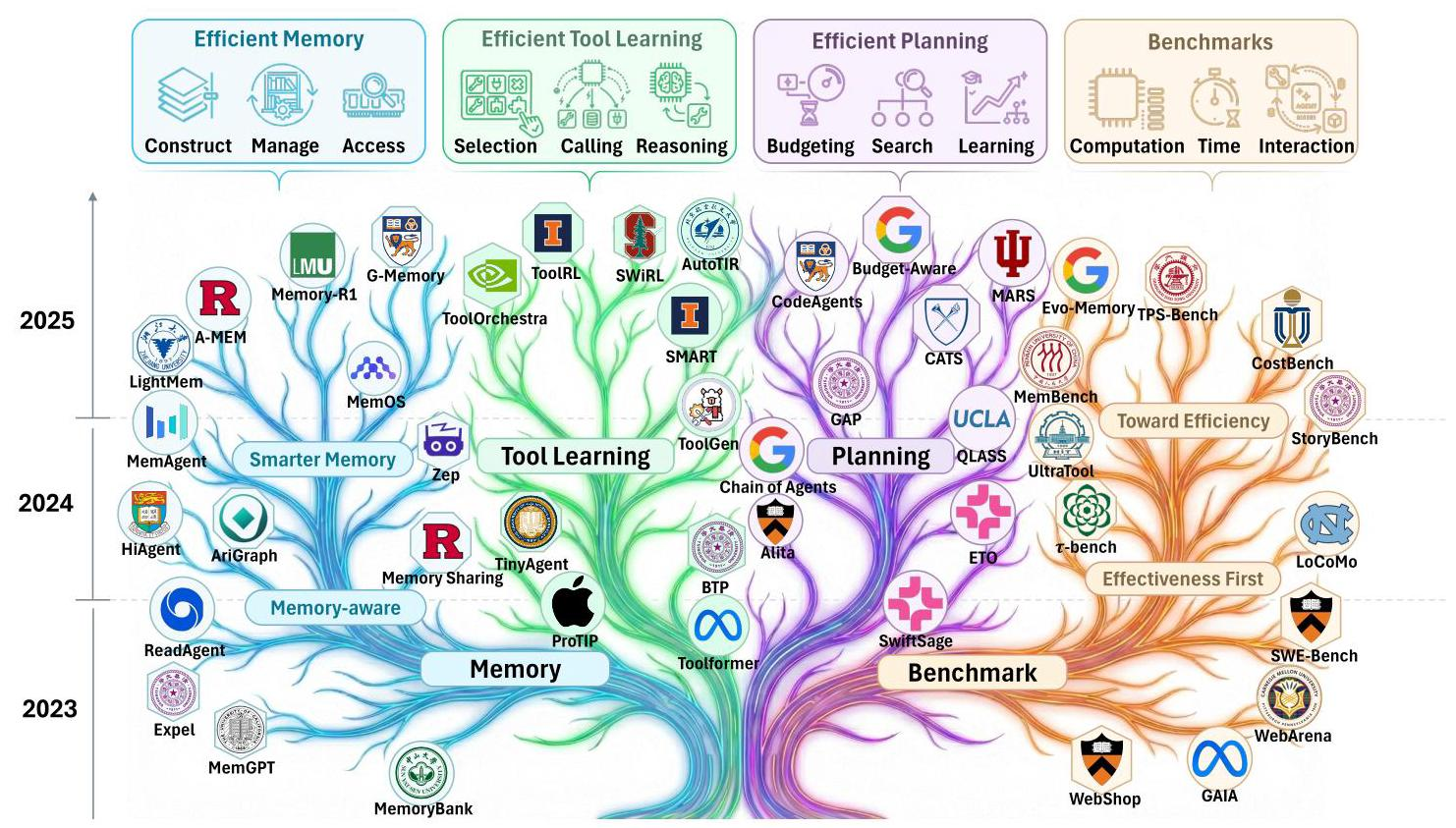
从LLM到智能体:效率为什么成了大问题?
要理解智能体的效率瓶颈,首先要搞清楚智能体和普通LLM的区别。普通LLM就像一个"一问一答"的对话机器,输入问题、输出答案,整个过程相对线性。但智能体完全不同——它会主动与外部环境交互,执行复杂的多步骤任务。
论文用一个公式形象地展示了智能体的工作流程:
输入 → [ 记忆 ⏟ 上下文 → 规划 ⏟ 决策 → 工具学习 ⏟ 行动 → 观察 ⏟ 反馈 ] n → 解决方案 \text{输入} \rightarrow [\underbrace{\text{记忆}}_{\text{上下文}} \rightarrow \underbrace{\text{规划}}_{\text{决策}} \rightarrow \underbrace{\text{工具学习}}_{\text{行动}} \rightarrow \underbrace{\text{观察}}_{\text{反馈}}]_n \rightarrow \text{解决方案} 输入→[上下文 记忆→决策 规划→行动 工具学习→反馈 观察]n→解决方案
这个循环会重复n次,每一轮都需要:从记忆中提取相关信息、制定行动计划、调用外部工具、处理返回结果。更要命的是,第n步的输出会成为第n+1步的输入,token像滚雪球一样越积越多。
论文给出了一个简化的成本对比:
- 普通LLM: 成本 ≈ α × 生成token数
- 智能体: 成本 ≈ α × 生成token数 + 工具调用成本 + 记忆访问成本 + 重试成本
这就是为什么智能体的效率优化,不能只盯着模型本身,而要从记忆、工具学习、规划这三大核心组件入手。
记忆模块:历史信息的"压缩与召回"艺术
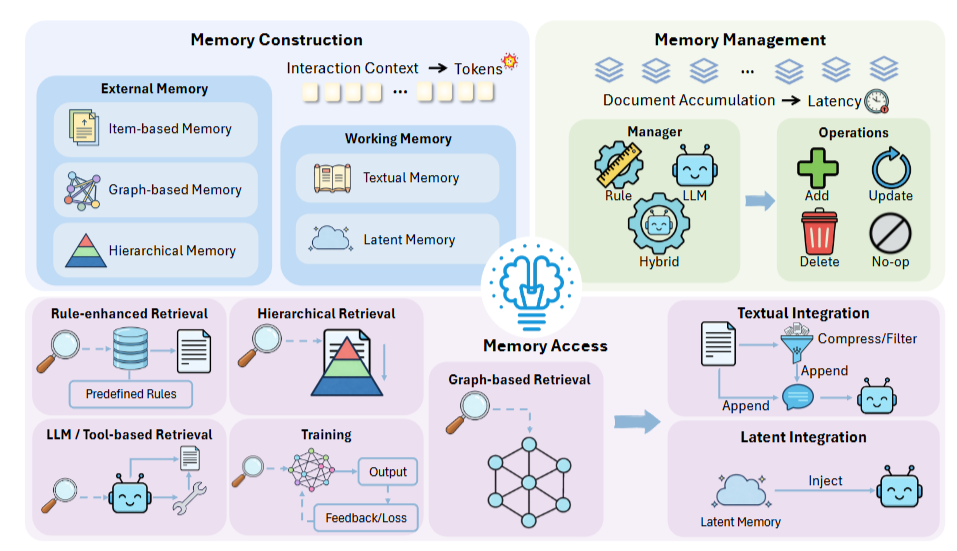
记忆是智能体的"大脑存储系统"。想象一个智能客服,需要记住几个月前和某个用户的所有对话历史——如果每次回复都要把这些历史全部塞进prompt,token开销会直接爆炸。
记忆的三大生命周期
论文将记忆管理分为三个阶段:
1. 记忆构建:从海量信息到精简表示
工作记忆分为两类:
- 文本记忆: COMEDY采用"两阶段蒸馏",先提取关键事件,再压缩成紧凑摘要;MemAgent更激进,直接用固定长度的记忆槽,每次更新就覆盖旧内容
- 隐式记忆: 将信息编码成KV缓存或隐藏状态。比如Activation Beacon把长文本压缩成少量"信标token",MemoRAG则构建全局记忆的KV表示
外部记忆则更加结构化:
- 基于项目的记忆: MemoryBank按日期存储对话,但会根据"遗忘曲线"定期淘汰不重要的内容;Expel提炼"经验洞察",把试错过程浓缩成可复用的知识
- 图结构记忆: AriGraph构建语义-情景双层图,Zep建立时序知识图谱,让多跳推理更高效
- 分层记忆: MemGPT模仿操作系统的虚拟内存,MemoryOS设计三层存储(短期/中期/长期),HiAgent用子目标作为索引
2. 记忆管理:防止"仓库爆仓"
记忆不能无限增长,否则检索速度会急剧下降。管理策略分三种:
- 基于规则: MemoryBank用遗忘曲线自动衰减记忆,MemGPT用FIFO队列淘汰旧内容。优点是快速可预测,缺点是可能误删关键信息
- 基于LLM: Memory-R1和Mem0让模型自己决定是添加、更新还是删除记忆。灵活但成本高
- 混合方案: MemoryOS用规则触发层间迁移,仅在必要时调用LLM;Agent KB先用相似度去重,再让LLM做最终筛选
3. 记忆访问:找到最相关的那根针
检索策略直接影响响应速度:
- 规则增强: Generative Agents结合"新近度、重要性、频率"三重评分;MemInsight给记忆打上属性标签,支持精准过滤
- 图检索: AriGraph从语义三元组入口,扩展相关子图;GraphReader从粗到细逐步探索
- 分层检索: H-MEM用多层索引递归查找;MemoryOS在短/中/长期存储中分别检索
- 训练优化: RMM用强化学习训练重排序器,Memento学习Q函数来选择最高价值的案例
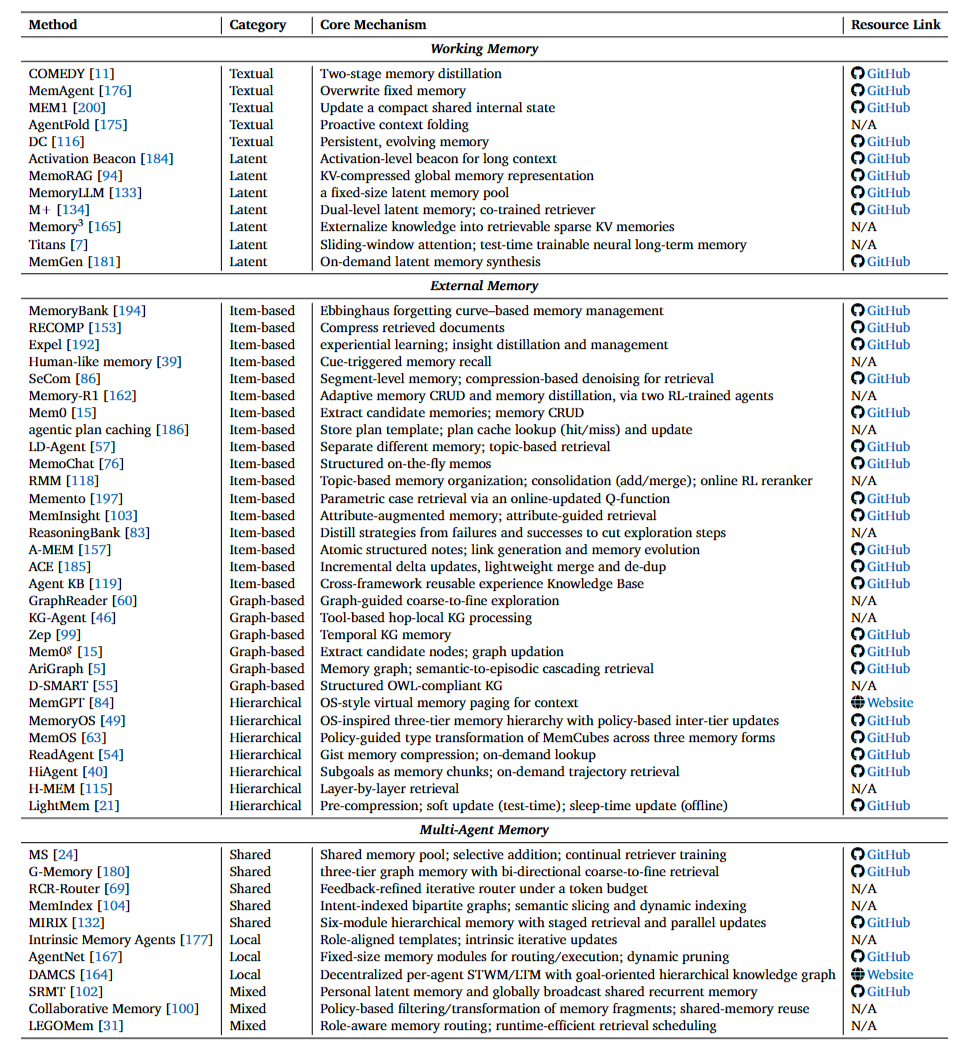
多智能体的记忆共享难题
当多个智能体协作时,记忆管理更复杂:
- 共享记忆: G-Memory构建三层图(洞察-查询-交互),双向检索高层抽象和底层细节;MemIndex用意图索引的二分图加速增删改查
- 本地记忆: AgentNet为每个智能体维护固定大小的记忆模块,用频率、新近度动态剪枝
- 混合方案: SRMT每个智能体有私有向量,同时共享循环记忆;LEGOMem按角色路由记忆访问
论文指出,记忆的核心取舍在于压缩率与性能的平衡。LightMem的实验清楚地表明:过度压缩会损失准确率,而轻度压缩能保持性能但成本更高。另一个关键选择是在线vs离线更新——在线更新响应快但增加延迟,离线更新节省推理时间但适应慢。
工具学习:从"疯狂调用"到"精准出击"
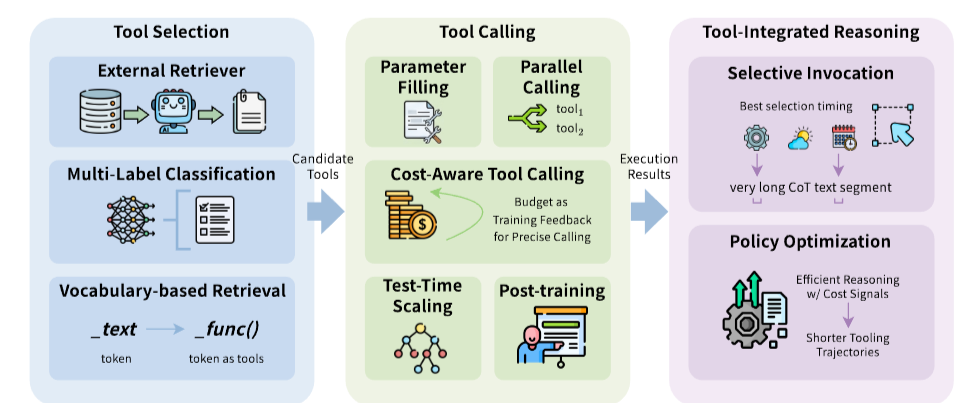
工具是智能体连接外部世界的桥梁。但问题在于:面对数千个API,如何快速找到需要的那几个?如何避免重复调用?如何在保证准确的前提下减少调用次数?
工具选择:从海量候选中快速定位
外部检索器方案最直接——用一个独立模型计算查询和工具描述的相似度。ProTIP用对比学习训练检索器,选中一个工具后,从查询中"减去"该工具的语义,再选下一个,避免显式任务分解。Toolshed更进一步,不仅优化检索器,还通过自我交互改进工具文档,双管齐下。
多标签分类把选择变成分类问题。TinyAgent在边缘设备上跑DeBERTa-v3小模型,概率超50%的工具就入选。这种方法极快,但添加新工具需要重新训练。Tool2Vec的解决方案是:不用静态描述,而是基于合成的使用示例生成工具嵌入,缩小查询和工具的语义鸿沟。
词汇表检索最激进——把工具编码成特殊token。ToolkenGPT冻结主模型,只训练工具嵌入,绕过上下文窗口限制。Toolken+加入重排序和拒绝机制,减少幻觉。但这类方法需要构造训练数据,对未见工具泛化较弱。
工具调用:并行化与成本感知
原地参数填充最简单——CoT生成过程中直接填参数。Toolformer开创了这一范式,CoA通过符号抽象替代中间结果,推理时间减少30%以上。
并行调用是效率提升的关键。获取一个省的天气,没必要逐个城市串行调用API。LLMCompiler借鉴编译器思想,生成执行计划并并行分发;LLM-Tool Compiler更进一步,运行时融合相似工具操作。CATP-LLM把成本约束融入规划,用离线强化学习训练策略。
成本感知调用把预算当硬约束。BTP将工具调用建模为背包问题,动态规划预算分配;Xu等人用一致性采样估计模型置信度,仅在"不确定且值得"时才调用;TROVE免训练地构建可复用函数库。
测试时扩展通过搜索提升质量。ToolChain用A搜索+学习的代价函数,提前剪枝错误分支,避免穷举搜索。
后训练优化让模型主动学会"少调用"。OTC-PO在强化学习目标中加入工具使用惩罚;ToolOrchestra训练专用编排器,用效率感知奖励;ToolRM用结果奖励模型引导高效轨迹。
工具集成推理:何时该用、何时该想
不是所有问题都需要工具。SMART构建CoT数据集,教模型判断"何时用参数化知识、何时调工具"。TableMind针对表格推理,设计计划-行动-反思循环,用监督微调预热后,再用RAPO强化学习优化排序。
ARTIST将智能体推理与基于结果的强化学习紧密耦合,无需步级监督就能学习最优策略。ReTool把代码解释器直接集成到推理循环,动态交织自然语言和可执行代码。ToolRL设计格式奖励+正确性奖励,匹配工具参数和真值。
为了减少不必要的调用,A²FM和IKEA都训练自适应路由器,优先用内部知识,必要时才搜索。AutoTIR显式惩罚冗余工具使用;SWiRL过滤并行轨迹中的冗余动作;PORTool用衰减因子γ强调接近最终结果的步骤。
论文总结道:工具学习的前沿正从"启用工具"转向"优化交互循环"。未来的智能体不再最大化工具使用来提升准确性,而是通过强化学习最小化冗余交互,实现帕累托最优的性能-成本权衡。
规划模块:从"无限搜索"到"预算控制"
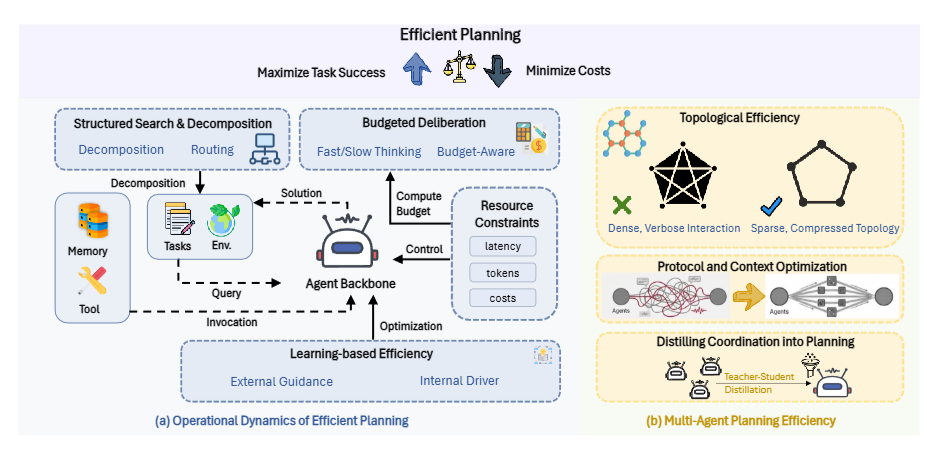
规划是智能体的"决策大脑"。传统规划假设算力无限,但现实中必须在严格的延迟、token和通信预算下做决策。论文将规划效率分为单智能体和多智能体两大类。
单智能体规划:深度优化
推理时策略在执行过程中动态优化:
- 自适应控制: SwiftSage设计"快慢双系统",简单任务用启发式,复杂任务才启动规划器;Budget-Aware根据预算约束动态调整工具策略;Reflexion从失败中学习,避免重复试错
- 结构化搜索: LATS把智能体展开建模为蒙特卡洛树搜索,自我反思引导探索;CATS在搜索树中集成成本感知,提前剪枝昂贵分支;ToolChain用A搜索导航动作空间
- 任务分解: ReWOO和Alita将规划与执行解耦,生成蓝图避免逐步token冗余;HuggingGPT将子任务路由到专用模型;BudgetMLAgent优化智能体路由成本
基于学习的演进通过训练内化规划逻辑:
- 策略优化: QLASS用Q值评论家指导搜索;ETO通过试错偏好学习(DPO)改进策略;RLTR和Planner-R1用过程级奖励反馈推理序列
- 记忆与技能: VOYAGER构建可复用技能库,避免重复规划;GraphReader和GAP用图表示支持并行化;Sibyl证明高效是涌现属性——更好的记忆结构直接降低未来规划负担
多智能体协作:广度优化
多智能体系统提升推理能力,但通信成本可能呈平方增长。优化重点是拓扑和协议:
拓扑稀疏化将通信从O(N²)降到O(N):
- Chain-of-Agents和MacNet用链式或DAG结构限制上下文增长
- GroupDebate在密集讨论和稀疏摘要间交替
- MARS和S²-MAD仅在观点分歧时触发辩论
- AgentPrune、AgentDropout动态学习剪枝低效边
协议压缩减少通信内容:
- CodeAgents用简洁伪代码编码推理
- Smurfs丢弃失败搜索分支防止上下文膨胀
- Free-MAD和ConsensAgent通过prompt工程加速收敛
- SMAS用监督器提前终止冗余循环
协作蒸馏把集体智慧内化到单模型:
- MAGDI和SMAGDi将交互图或苏格拉底式分解蒸馏到学生模型
- D&R用师生辩论生成偏好树做DPO
- 保留多样性视角的质量,同时降到单智能体的推理成本
论文总结:高效规划将推理从无界生成重构为预算感知控制问题。单智能体侧,从自适应预算到结构化搜索,再到策略改进和技能记忆;多智能体侧,从拓扑剪枝到协作蒸馏。统一趋势是:将计算从在线搜索迁移到离线学习或结构化检索,让智能体在严格资源约束下完成复杂目标。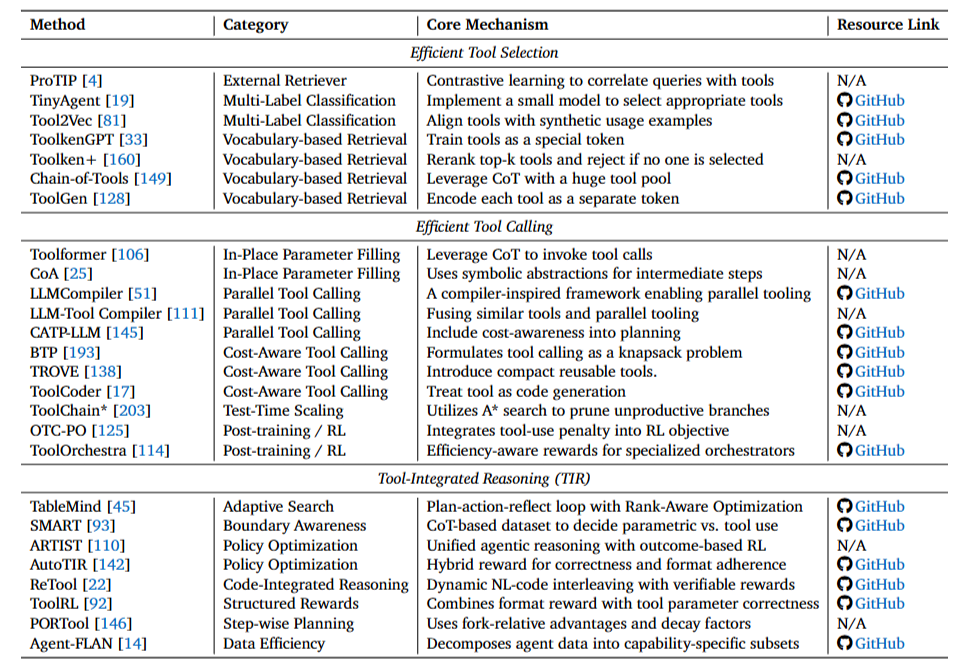
评估基准:效率到底怎么量化?
论文强调"效率优先但不牺牲效果"——便宜但无法完成任务的方法没有意义。效率的两种定义方式:
- 固定成本预算下比较效果
- 相同效果水平下比较成本
也可以看成效果-成本的帕累托前沿。
记忆评估
效果基准:
- 间接评估:用HotpotQA、Natural Questions等QA数据集,或GAIA等交互式智能体基准
- 直接评估:LoCoMo和LongMemEval专门测试记忆能力
效率基准:
- Evo-Memory引入"步骤效率",衡量到达目标需要的环境步数
- StoryBench报告运行时成本(总耗时)和token消耗
- MemBench显式包含读取时间和写入时间(每次操作的秒数)
方法层面指标分四类:
- Token消耗与API成本: 多数研究报告token用量,部分换算成美元成本
- 时间指标: HiAgent报告总运行时间,SeCom/Mem0/MemOS测量端到端延迟(不含构建时间),A-MEM/H-MEM/Agent KB测量检索时间,MemoRAG区分索引延迟和检索延迟
- 资源指标: A-MEM和MemoRAG报告GPU内存使用
- 交互指标: MemoryOS报告每次响应的平均LLM调用次数,ReasoningBank跟踪推理步数
工具学习评估
工具学习尚缺统一效率基准,多数评估优先看效果。主要基准家族包括:
选择与参数填充:
- Seal-Tools用LLM生成大规模工具和用例
- UltraTool从真实场景用户查询评估工具创建
- MetaTool专注"是否用工具"和"选哪个工具"的决策
- BFCL包含真实应用工具和多轮对话
- API-Bank提供73个手工标注工具
- NesTools分类嵌套工具调用,τ-Bench和τ²-Bench覆盖零售/航空/电信领域
- ToolBench收集16000+个RapidAPI,但稳定性有问题
- T-Eval将工具使用分解为六种能力(规划、推理、检索等)逐步评估
基于MCP协议:
- MCP-RADAR显式评估工具选择效率、计算资源效率和执行速度
- MCP-Bench用LLM-as-Judge评估并行性和效率
智能体工具学习:
- SimpleQA评估提供事实正确简短答案的能力
- BrowseComp让人类创建需要浏览能力的挑战性问题
- SealQA评估搜索增强LLM处理冲突/噪声/无用结果的能力
规划评估
效果基准: SWE-Bench、WebArena、WebShop等通过下游任务间接评估规划
效率基准:
- Jobs等提出基于Blocksworld的结构化基准,报告端到端执行时间、规划尝试次数、token消耗和货币成本
- TPS-Bench用token用量、端到端时间、工具调用轮数评估,并提出"通过成本"(每次成功完成的预期成本)
- CostBench在动态变化下评估成本最优规划,用成本差距和路径偏差衡量
方法层面指标:
- Token消耗和运行时间(SwiftSage、LATS、ReWOO等)
- 搜索深度/广度:时间步数(SwiftSage)、试验次数(Reflexion)、平均节点/状态数(LATS)、平均迭代次数(CATS)
- 通过成本类指标:TPS-Bench及后续工作普遍采用;常见做法是固定预算比较性能
未来方向:从理论到实践还有多远?
归根结底,这篇综述其实是给当下的 Agent 热潮提了个醒: 别光顾着堆功能,“跑得起”比“跑得通”更关键。
现在的痛点在于大家各玩各的,连个统一的效率评分标准都没有。未来的破局点,或许在于让 Agent 学会“心里默念”来省 Token(隐式推理),或者是搞定多模态任务里那些吞噬显存的视觉历史。一句话,Agent 的下半场不再是炫技,而是极致的“抠门”——只有在有限的预算和延迟里把活干漂亮,这玩意才能真正从实验室走进我们的生活。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)