Agent Memory(下):工作记忆折叠、会话档案化与记忆演化
在本篇中,我们转向长期一致性与多轮任务保持这类任务。通过 DeepAgent、Claude Agent SDK 和 MUSE 三条路径,我们看到现代记忆系统正在从“存储”演变为“面向行为链的组织与演化”。真正的 Agent Memory 是一种系统工程,而非单一模块。它牵涉信息表达、结构化组织、检索策略、工具调用链管理、行为一致性维护以及跨会话的经验演化。如何让记忆不仅服务单一任务,还能在更大范围
TL;DR
在上一篇文章中,我们从基础机制视角讨论了 Agent Memory 的整体框架,包括记忆的形式、功能与动态生命周期,并分别展示了用于工作记忆压缩与长期记忆检索的两类代表性方案:QwenLong-L1.5 与 M3-Agent。
然而,在真实的系统级代理中,我们更期望 Agent 能够在长期一致性与多轮任务保持中稳定运行。本篇文章介绍三个面向“长期一致性与多轮任务保持”的工作:DeepAgent 的工作记忆折叠与 ToolPO 算法、Claude Agent SDK 的会话档案化与可追溯结构化记忆、以及 MUSE 提出的演化式长期记忆体系。通过对这些路径的拆解,我们将进一步理解现代智能体如何在长时序任务中保持稳定的行为策略、持续的上下文一致性与可增长的经验库。
一、DeepAgent —— 工作记忆折叠+ ToolPO
论文提出的DeepAgent 是一个端到端的通用推理智能体框架。文章通过引入记忆折叠机制,将历史交互压缩为结构化的情景、工作和工具记忆来解决Agent Memory的问题。为稳定高效地学习工具使用能力,提出了 ToolPO 强化学习方法,对工具调用 token 进行精细化奖励。
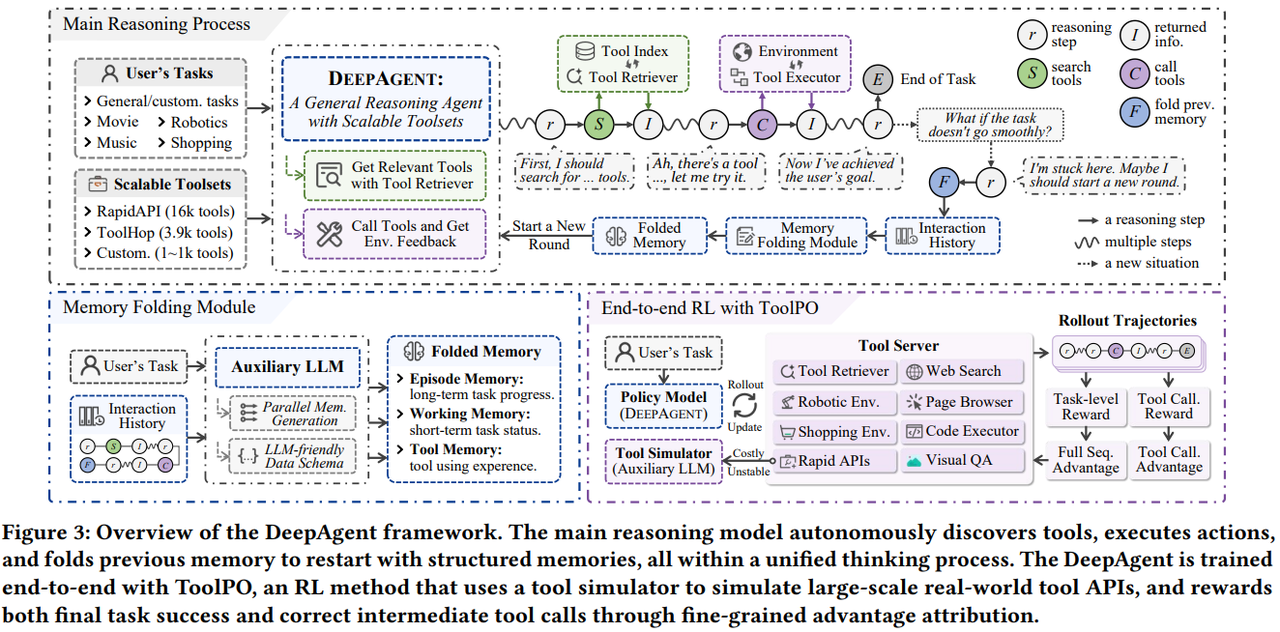
1. DeepAgent的动作空间

2. 面向长时序交互的 「自主记忆折叠机制」
DeepAgent 可以在推理过程中任意合适时机触发记忆折叠,将完整的历史交互压缩为结构化的三类记忆:
- 情景记忆:记录任务关键事件与阶段性成果,提供长期任务脉络
- 工作记忆:保存当前子目标、障碍和短期计划,保证推理连续性
- 工具记忆:总结工具使用方式与效果,用于改进后续工具选择
压缩后的记忆替代原始交互历史,使 Agent 能在保持关键信息的同时避免错误探索路径的累积。为提高稳定性和可解析性,折叠的记忆采用结构化 JSON 数据模式而非纯文本,从而在长时序任务中实现高效、可靠的上下文管理。
3. ToolPO:面向工具使用的强化学习算法
DeepAgent 采用 Tool Policy Optimization(ToolPO) 进行端到端强化学习,以学习通用工具使用能力。训练数据覆盖通用工具调用、真实交互、信息检索和数学推理等多类任务;为避免真实 API 带来的高成本与不稳定性,作者引入 LLM-based 工具模拟器,在训练阶段模拟真实工具的返回结果。

ToolPO 使用带裁剪的 PPO 目标函数进行优化,从而在保证训练稳定性的同时,使模型既学会正确完成任务,又学会高效、准确地使用工具与记忆机制。
二、Claude Agent SDK —— 像软件开发记录一样记忆会话
项目是从工程化的视角出发,关注长期运行 Agent 面临的核心挑战:它们必须在离散的会话中工作(像人类每天工作固定的时长后会休息),并且每个新会话开始时都没有之前的记忆。由于上下文窗口是有限的,且大多数复杂的项目无法在单个会话窗口内完成,Agent 需要一种方法来弥补会话之间的鸿沟。 为解决上述问题,研究提出了一套基于 Claude Agent SDK 的解决方案,方案由两种类型的Agent组成:
- 初始化Agent (Initializer agent):负责在首次运行时设置环境和规划任务。
- 编码Agent (Coding agent):负责在后续会话中进行增量开发,并为下一次会话留下清晰的记录。
1. 初始化 Agent:环境初始化 & 编写功能列表文件 & 初始 git 提交
第一个上下文窗口用于搭建整体框架(例如:编写测试、创建初始化脚本),随后在后续上下文窗口中围绕一个待办事项列表(todo-list)进行迭代开发。第一个上下文窗口使用专门的提示词,要求:
- 初始化 Agent 编写一个详尽的功能需求文件,这些功能最初都被标记为“failing”(未通过),编码 Agent 只能通过更改 passes 字段的状态来编辑此JSON文件。例如:
{
"category": "functional",
"description": "New chat button creates a fresh conversation",
"steps": [
"Navigate to main interface",
"Click the 'New Chat' button",
"Verify a new conversation is created",
"Check that chat area shows welcome state",
"Verify conversation appears in sidebar"
],
"passes": false
}- 创建初始化或辅助脚本(例如
init.sh),用于启动服务、运行测试套件以及执行代码检查工具。 这可以避免在每次从一个全新上下文窗口继续工作时重复执行相同的准备步骤。 - 一个记录 Agent 已完成工作的 JSON文件。例如:
Session 3 progress:
- 修复了认证 token 校验问题
- 更新了用户模型以处理边界情况
- 下一步:排查 user_management 测试失败(测试 #2)
- 注意:不要移除测试,否则可能导致功能缺失- 显示添加了哪些文件的初始 git 提交。
- 在跟踪结构化信息(如测试结果或任务状态)时,使用 JSON 或其他结构化格式,以帮助 Claude 理解数据模式和约束。创建结构化状态文件,例如:
{
"tests": [
{"id": 1, "name": "authentication_flow", "status": "passing"},
{"id": 2, "name": "user_management", "status": "failing"},
{"id": 3, "name": "api_endpoints", "status": "not_started"}
],
"total": 200,
"passing": 150,
"failing": 25,
"not_started": 25
}2. 编码Agent:依据需求文档等进行增量进展
编码 Agent 被要求一次只处理一个功能,取得增量进展,然后留下结构化的更新。每个编码 Agent 都会被提示运行一系列步骤(使用编码Agent提供的信息)来熟悉环境,会话通常以助手消息开始:
[Assistant] I'll start by getting my bearings and understanding the current state of the project.
[Tool Use] <bash - pwd>
[Tool Use] <read - claude-progress.txt>
[Tool Use] <read - feature_list.json>
[Assistant] Let me check the git log to see recent work.
[Tool Use] <bash - git log --oneline -20>
[Assistant] Now let me check if there's an init.sh script to restart the servers.
<Starts the development server>
[Assistant] Excellent! Now let me navigate to the application and verify that some fundamental features are still working.
<Tests basic functionality>
[Assistant] Based on my verification testing, I can see that the fundamental functionality is working well. The core chat features, theme switching, conversation loading, and error handling are all functioning correctly. Now let me review the tests.json file more comprehensively to understand what needs to be implemented next.
<Starts work on a new feature>三、MUSE —— 上海AI Lab:记忆演化与检索
MUSE 是一种无需微调大模型、面向生产力任务的智能体框架,通过在真实交互环境中进行测试时学习来完成复杂任务。系统由三个核心组件组成:记忆模块、规划-执行(PE)Agent 和 反思(Reflect)Agent。
1. MUSE的工作流程
MUSE 以 “Plan–Execute–Reflect–Memorize” 的循环方式运行:
- PE Agent 先对任务进行分解并执行子任务,在执行过程中仅使用最小化的基础工具集;
2. 每个子任务结束后,Reflect Agent 会自动评估执行结果,成功则将经验提炼为过程记忆,失败则生成诊断并触发重新规划。
3. 任务完成后,系统还会进行一次全局回顾,将执行经验升华为更高层次的战略记忆和工具记忆。
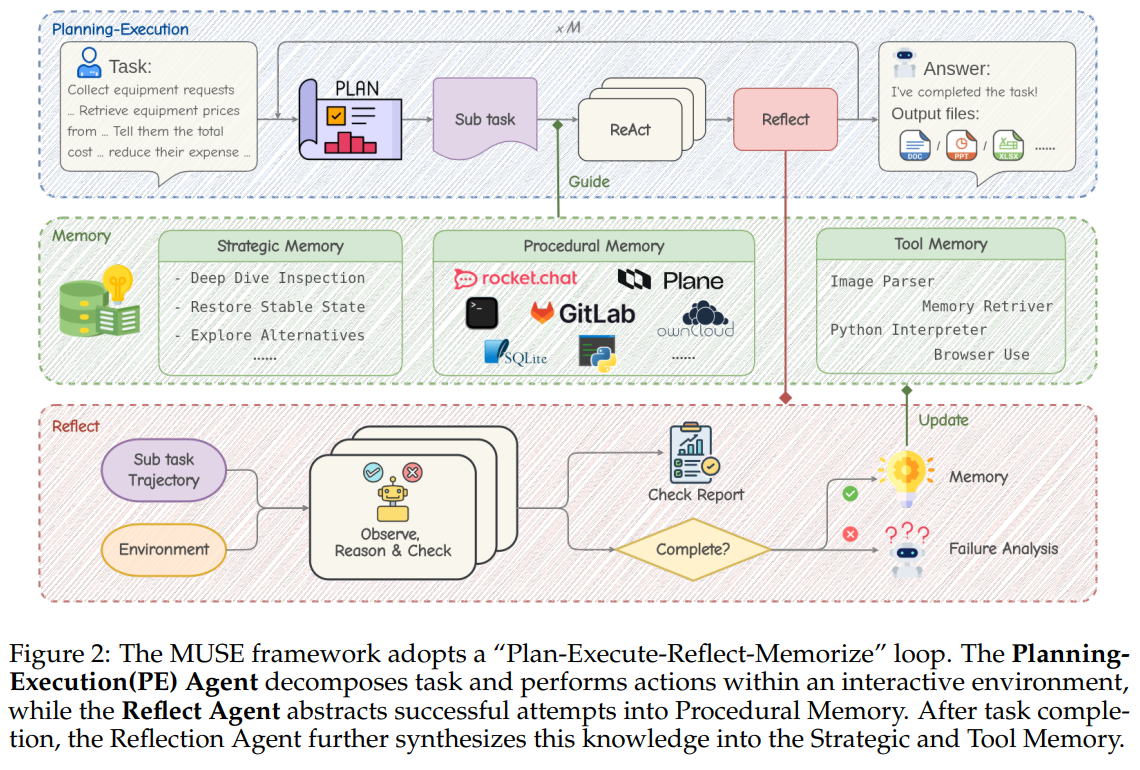
2. 记忆模块

3. Planning–Execution Agent
Planning-Execution(PE)Agent 负责将任务转化为可执行的长期行动序列,是 MUSE 中实现任务落地的核心执行单元。
- 在规划与重规划阶段,PE Agent 为每个子任务构建明确的决策描述与目标,用于后续的反思评估。
- 在执行与重试阶段,PE Agent 依次处理子任务,并采用记忆增强的 ReAct 循环进行执行:通过“思考–行动–观察”的迭代方式生成动作、执行操作并接收反馈。
- 在工具使用策略上,MUSE 采用最小可用工具集设计,仅提供少量通用基础工具(如浏览器、代码解释器、Shell、视觉解析与记忆检索),鼓励 Agent 通过组合基本能力完成复杂任务,而非依赖大量专用 API。
4. Reflect Agent Reflect
Agent的核心作用是在任务执行过程中独立评估、纠错与知识沉淀,以防止幻觉和错误累积。Reflect Agent 作为第三方监督者,在每个子任务完成或达到动作上限时被触发,基于子任务定义和 PE Agent 的执行轨迹进行系统化评估。
- 在子任务评估阶段,Reflect Agent 按照清单从三方面进行验证:真实性验证,交付物验证,数据保真性验证。
- 评估完成后,Reflect Agent 输出成功或失败标记及详细报告:若成功,则将有效执行流程提炼为新的标准操作流程写入过程记忆;若失败,则生成失败原因分析并触发 PE Agent 重新规划。
- 任务整体完成后,Reflect Agent 进一步对全流程进行回顾,提炼高层策略经验并强化工具使用知识,对战略记忆、过程记忆和工具记忆进行统一整合与精炼,从而持续提升系统的长期决策与执行能力。
四、总结
在本篇中,我们转向长期一致性与多轮任务保持这类任务。通过 DeepAgent、Claude Agent SDK 和 MUSE 三条路径,我们看到现代记忆系统正在从“存储”演变为“面向行为链的组织与演化”。这些路径共同说明:真正的 Agent Memory 是一种系统工程,而非单一模块。
它牵涉信息表达、结构化组织、检索策略、工具调用链管理、行为一致性维护以及跨会话的经验演化。 展望未来,仍有几个关键方向值得深入研究:
- 跨任务记忆迁移:如何让记忆不仅服务单一任务,还能在更大范围内形成可迁移的能力结构。
- 自适应记忆更新策略:基于信号质量、任务相关性和模型不确定性动态选择写入与遗忘。
- 与工具生态的深度融合:Task/Tool 调度逻辑与记忆结构如何实现闭环优化。 以上,围绕 Agent Memory 的背景、常见实现思路以及实际使用中容易被忽视的问题,梳理出了为什么 memory 在 Agent 系统中如此重要,又经常被误用。与其把 memory 当成“能力增强器”,不如把它放回到具体任务和交互流程中去理解,它解决的是连续性和效率问题,而不是智能本身。 如果你对 Agent Memory 有更多理解,或者在实际项目中有过相关实践和踩坑经验,欢迎在评论区交流,也欢迎补充你认为更合理的实现思路,共同讨论。
此外,DeepLink团队在小红书上新建了【DeepLink】账号(二维码如下),我们将会为大家分享核心技术的深度解析、AI 开放计算领域的行业动态研判,以及落地案例的细节拆解、技术踩坑经验。欢迎大家移步关注!

REFERENCE
[1] DeepAgent: A General Reasoning Agent with Scalable Toolsets
[2] 用于长期运行 Agent 的高效框架 • Anthropic
[3] 适用于长期运行智能体的有效工具
[4] https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/claude-4-best-practices#multi-context-window-workflows
[5] Effective harnesses for long-running agents
[6] Learning on the Job: An Experience-Driven, Self-Evolving Agent for Long-Horizon Tasks

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)