2个月构建医学知识库:RAG技术实战全解析 | 程序员必看的大模型应用指南
本文记录了作者历时两个月构建医学知识库的完整历程,从最初的朴素RAG到多路召回RAG的三次迭代尝试,最终选择Dify平台结合硅基流动API服务实现。过程中解决了本地模型资源不足、API配置和延迟等技术难题,总结出文本预处理质量大于算法复杂度、混合检索优于纯向量检索、云端API更适合个人用户等关键经验。作者通过实践深入理解了RAG的核心技术,并强调在项目推进中要敢于放弃沉没成本。最终构建的知识库采用
本文记录了作者历时两个月构建医学知识库的完整历程,从朴素RAG到多路召回RAG的三次迭代尝试,最终选择Dify平台结合硅基流动API服务实现。过程中解决了本地模型资源不足、API配置和延迟等技术难题,总结出文本预处理质量大于算法花哨度、混合检索优于纯向量检索、云端API更适合个人用户等关键经验,强调敢于放弃沉没成本的重要性。

在构建医学知识库的海洋里, 粗略计算已经过了2个月。第一次发布记录我构建知识库的那篇[文章], 如今已经有了9000+的阅读量, 更有很多陌生读者给了我优化检索增强生成(RAG)的建议。那是我写公众号记录以来, 为数不多的具有建设性的意见。在不断的尝试和优化方法后, 我终于走到了要为这件事画上句号的阶段, 但我知道这只是另一个阶段的新起点。
在学医的这五年里, 我多了许多白发, 看着自己略带苍老的面容, 我内心不知道如何安慰自己。我没有成为专业第一, 而是在阅读、写作、编码、折腾这些事情上花了很多心血。我知道它们并不会为我的专业学习带来直接帮助,但我还是义无反顾地去做这些事情。
今年在看罗振宇2026跨年演讲的时候,他提到了一个词——逃离「一致性」。在AI已经成为我们重要合作伙伴的今天, 也许我们确实应该换一种路径走了。不是为了彰显自己的特立独行,而是为了让AI无法预测我们的行为, 成为一个真正意义上的人。
在实习的一年多时间里, 我越来越发现, 工作就是在别人设置好的规则和系统下生存。不论你想怎么逃离,只要你还在这个游戏里,规则永远存在,系统永远滞后,你永远是被愚弄的受害者。
可能像现在这种,坐在电脑旁,安心写作记录,是我逃离规则的一种方式吧!更重要的是,带着好奇和创意去构建自己的系统,也可以成为我对抗现有SB系统的有效手段。
不要试图去预测
现在回头去看2个月前我开始使用AnythingLLM来构建医学知识库的时候,完全没有想过,最后的呈现方式竟然是这样的。
在多次尝试使用RAG + AnythingLLM来做的知识库效果不理想,以及在尝试了文章评论区各位陌生前辈给的建议之后,我转向了自己使用AI tools来协助构建医学知识库。
技术深潜:从理论到实践
在Vibe Coding的过程中,我不仅学到了什么叫嵌入(Embedding)、重排(Rerank)、向量化···还知道了如何使用代码去实现它们。这应该是我第一次这么近距离地了解RAG的本质。
它们之前还只是一种可有可无的概念储存在我头脑里,可经过这次实践,我明白了:
为什么要重叠切分文本块(Chunk Overlap): 避免语义信息在chunk边界处被截断,通常设置10-20%的重叠率
语义切分的劣势: 虽然能保持语义完整性,但在医学教材这种结构化强的文本中,基于章节的切分反而更有效
向量化存储的好处: 通过余弦相似度快速检索语义相关内容,比传统关键词匹配准确率大幅提升
为什么要按置信度重排: 因为向量检索只考虑语义相似度,而rerank模型能综合考虑上下文相关性,过滤掉"看起来像但实际不相关"的结果
这些知识只通过阅读资料、文献是很难正确理解的,必须要在尝试的过程中不断微调、完善,才能看到这种结果优化的过程。
RAG演化之路:三次迭代的血泪史
第一版:朴素RAG(失败)
提问 → 检索向量库(仅做基础切分) → LLM分析 → 返回结果
问题: 检索召回率低,回答质量差,经常答非所问
第二版:优化RAG(略有改善)
提问 → LLM扩展关键词 → 检索向量库 → 置信度重排 → LLM分析 → 返回结果
改进:
- 使用Qwen2.5对用户query进行改写和扩展,例如"高血压怎么治"扩展为"高血压的药物治疗方案、非药物干预措施、并发症预防"
- 引入BGE-reranker-large对召回的top-20结果进行重排,最终选择top-5喂给LLM
问题: 原材料质量不行——PDF扫描版识别错误多,格式混乱
原材料优化:
- 文字版PDF → Markdown转换(自己编写脚本)
- Markdown多轮清洗:删除页眉页脚、修正表格格式、统一术语表达
- 这个过程交给OpenCode完成,倒也节省了我大量时间
第三版:多路召回RAG(性能瓶颈)
提问
↓
LLM(Qwen2.5)扩展关键词
↓
并行检索:
├─ 知识库检索(向量化)
├─ MedGemma1.5模型检索(医疗专业知识)
└─ 联网检索(最新指南)
↓
结果融合(RRF算法):余弦相似度(知识库),置信度(模型检索),网页排名(联网)
↓
LLM分析综合
↓
返回结果
改进:
- 多路召回提高覆盖率
- RRF(Reciprocal Rank Fusion)融合不同来源的结果
致命问题:
- 算力消耗巨大,Mac跑得巨慢
- 简单问题需要等3-5分钟
- MedGemma1.5在本地推理速度<5 tokens/s,完全不可用
- 联网检索基本没有返回有效医学文献
沉没成本
不知道从什么时候开始,做事考虑沉没成本成了我的一种习惯。在Vibe Coding上花了很多时间和精力后,放弃这条路真的舍得吗?
可能这个问题换做是谁都不好回答,但如果换成你花钱买票去看电影,看了一段时间后发现那是部无聊透的烂片,你还会接着看完吗?这个问题就好回答一些。也就是说,你花的钱、时间都成了过去,你无法改变,它们就成了沉没成本。你现在能做的要么是走出电影院,要么就是耐着性子看完,你会怎么选,答案也一目了然了是吧!
我纠结了很久之后,从GitHub上克隆了Dify的仓库,并使用Docker环境来运行。
Dify部署踩坑记录
环境准备:
git clone https://github.com/langgenius/dify.git
cd dify/docker
docker-compose up -d
第一个坑:本地Embedding模型不工作
- 问题: 使用Ollama的
bge-m3模型,Mac已经摸着烫手了,但切分进度条始终为0 - 排查: Docker日志显示模型加载成功,但请求超时
- 原因: 我的 Mac 物理内存为 16G,由于 Docker Desktop 采用了静态资源分配方案,划走了 8G 独立虚拟机内存给 Dify 平台。这导致宿主机环境在扣除系统开销后,留给原生 Ollama 运行 Embedding 和 Rerank 模型的有效物理内存极其有限,引发了频繁的内存交换(Swap)和请求超时。
- 解决: 放弃本地模型,转向云端API
第二个坑:硅基流动(SiliconFlow)API配置
根据Dify上模型提供商列表,我发现硅基流动这个平台提供的模型不错:
Embedding: BAAI/bge-large-zh-v1.5
Rerank: BAAI/bge-reranker-v2-m3
LLM: Qwen/Qwen2.5-72B-Instruct
在注册API key后,我充值了50元,回到Dify继续重试,但结果还是一样——进度条不动。
第三个坑:诡异的延迟问题
折腾了许久,我放弃了。第二天下班后,我抱着试试看的心态重新打开Dify,结果竟然成功了!Mac没有发烫,虽然等了10分钟,但看着召回测试结果不错(Hit Rate达到0.85+),也就不计较了。
事后分析: 可能是首次向量化时,硅基流动的并发限制导致请求排队,第二次重试时缓存生效,所以秒过。
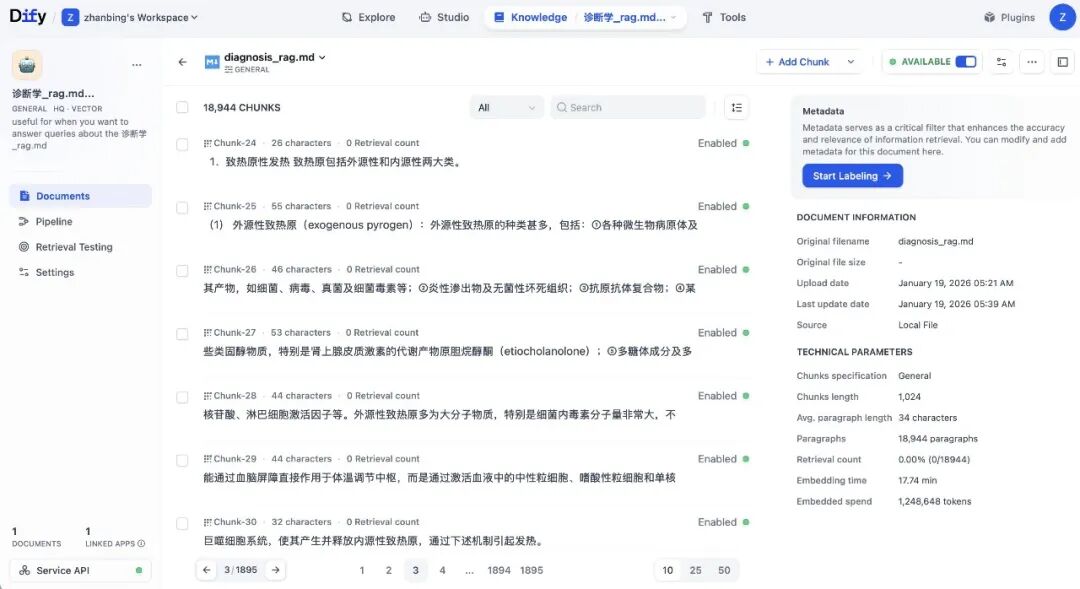
Dify最终配置
知识库设置:
分段模式: 自动分段(512 tokens,20% overlap)
Embedding模型: bge-large-zh-v1.5
检索设置: 混合检索(向量检索 + 全文检索,权重0.7:0.3)
Rerank: bge-reranker-v2-m3,TopK=3
工作流设计:
用户输入
↓
意图识别(判断是否医学相关)
↓
知识库检索
↓
置信度过滤(score > 0.7)
↓
结果整合提示词工程
↓
LLM生成回答(Qwen2.5-72B)
↓
输出(附带来源引用)
写在最后
2个月,从刚开始的害怕,到第一次成功运行的欣喜,再到优化过程中的崩溃,Dify部署成功的小惊喜,最后到现在的平常心。这个过程中,我逐渐明白:
遇到问题解决问题才是学习,反过来说:大部分人之所以不学习,是因为他们无法感知到问题,所以没有解决问题的冲动,更没有为了解决问题而去学习的欲望。
至此,我的医学知识库总算是在好奇中开始,在行动中节节败退,在Vibe Coding中优化、完善,最终被舍弃,然后在Dify中又迎来了新生。
这不是结束,而是新的开始。下一步,我打算:
- 继续优化提示词工程,提高回答的专业性
- 引入多模态能力,支持医学影像的检索
- 探索Agent模式,让它能主动查阅最新临床指南
如果你也在折腾RAG,欢迎交流踩坑经验。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献788条内容
已为社区贡献788条内容

所有评论(0)