AI-深度学习-卷积神经网络-残差网络
目的
为避免一学就会、一用就废,这里做下笔记
说明
本文内容紧承前文-卷积神经网络CNN,欲渐进,请循序
一、是什么?—— 定义与核心思想
残差网络(ResNet)是一种通过引入 “快捷连接” 来构建极深卷积神经网络的架构。其核心思想是“残差学习”。
残差二字的由来:
- 在数学和统计学中,残差指的是观测值与预测值之间的差值。
- 在ResNet中,理想的"观测值"设为H(x)
- 基准预测值设为B(x)=x(即输入和输出相同,什么也不改变)
- 残差F(x)=H(x)-B(x)=H(x)-x
- 传统网络:让多层网络直接学习一个目标映射
H(x)。 - 残差网络:让多层网络学习一个残差映射
F(x) = H(x) - x,而最终的输出仍是H(x)=F(x) + x。这里的x就是通过快捷连接直接传递过来的输入。
简单比喻:
- 传统学习像是让你从零开始画一只猫。
- 残差学习则是:我先给你一张猫的草图
x,你只需要在上面修改(添加或删减几笔)F(x),就能得到更完美的猫H(x)。如果你的修改是零,那至少还有一张不错的草图保底。
关键技术:恒等快捷连接。它允许输入信号x跨层直接传递,与经过卷积层变换后的输出F(x)进行逐元素相加。
二、为什么?—— 解决的问题与动机
提出残差网络,是为了解决传统深度CNN在扩展时遇到的两个根本性难题:
-
梯度消失/爆炸:网络层数过深时,误差梯度在反向传播中会不断连乘,导致传到浅层时变得极其微小(消失)或巨大(爆炸),使得浅层参数无法有效更新。
-
网络退化:这是ResNet论文中更关键的一个发现。即使使用标准化等技术缓解了梯度问题,当网络深度增加时,训练集和测试集的准确率反而会下降。这并非过拟合(因为训练误差也升高),而是表明极深的普通网络难以被优化,它连在训练集上找到一个好的解都做不到。
根本原因:在深度网络中,让多个非线性层直接拟合一个复杂的恒等映射(即输入=输出)是非常困难的。而很多深层网络的有效部分,恰恰接近于一个恒等映射。
残差网络的解决方案:通过快捷连接,将“拟合恒等映射”这个困难任务,转变为“将残差推向0”的简单任务。如果恒等映射是最优的,那么将残差权重推为零即可;如果需要非恒等映射,也只需在恒等映射的基础上进行小幅调整。这极大地降低了优化难度。
三、怎么办?—— 实现方式与关键结构
残差网络通过构建残差块来实现其思想,下图是一个基础的残差块结构: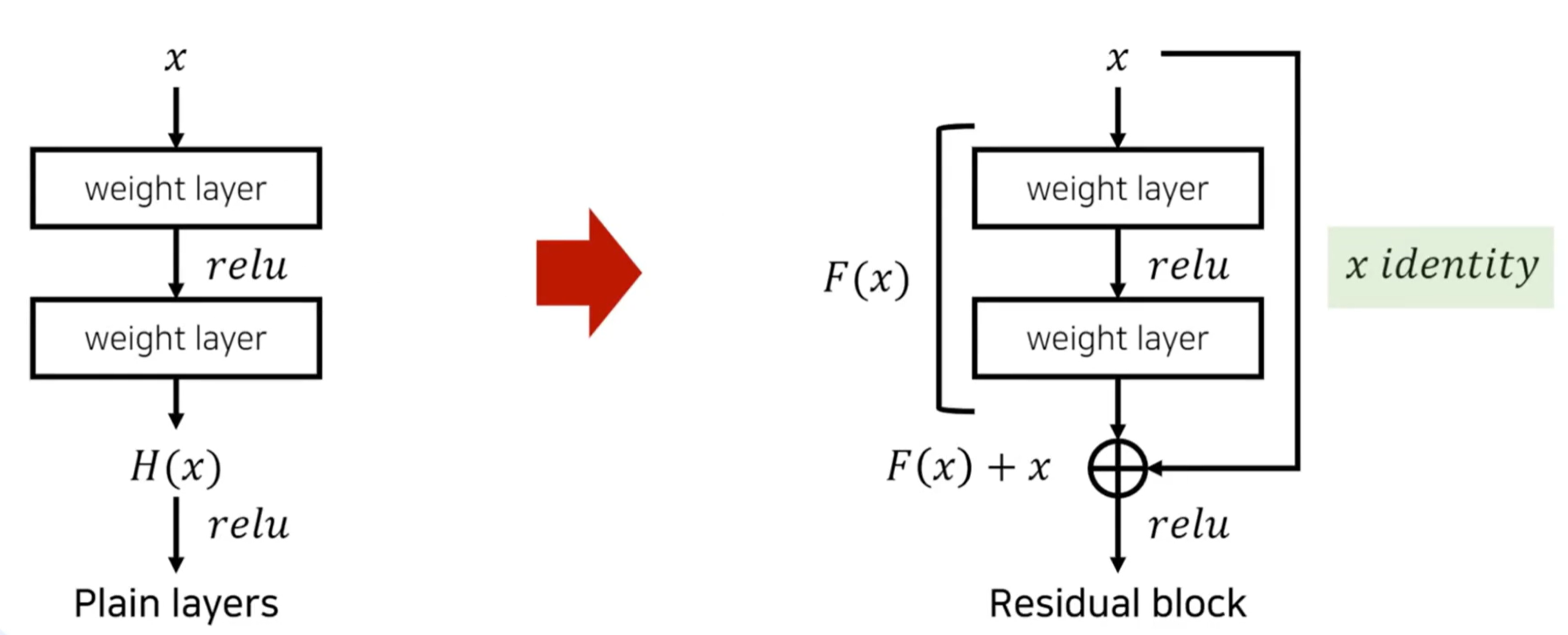
上图展示了一个包含两个卷积层的基本残差块的完整数据流。输入 x 可以“抄近路”直接跳到相加环节,这保证了即使在最坏情况下(所有卷积层权重无效),网络至少能保留输入信息,而不会被“损坏”。这使得信号可以跨越多个层直接传播,显著缓解了梯度消失问题。
在实际构建深层网络(如ResNet-34, ResNet-50)时,会采用两种关键设计:
- 瓶颈结构:在更深的残差块中,使用
1x1卷积先降维再升维,大幅减少计算量。 - 下采样调整:当需要缩小特征图尺寸(步长为2)或增加通道数时,快捷连接也需要进行相应调整(通常通过一个
1x1卷积,步长为2来完成),以确保F(x)和x的尺寸匹配,可以相加。
总结
- 是什么:一种通过 “快捷连接” 实现残差学习的深度CNN。
- 为什么:为了解决极深网络中的梯度消失和网络退化问题,降低优化难度。
- 怎么办:构建 “恒等快捷连接 + 逐元素相加” 的残差块作为基本单元,堆叠成深度网络,并在需要时用
1x1卷积进行维度匹配。
正是这个简洁而深刻的设计,使训练数百甚至上千层的网络成为可能,深刻影响了深度学习的发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)