大模型训练推理的“地下极速通道”:NVIDIA GDS 技术(GPU Direct Storage)
【代码】大模型训练推理的“地下极速通道”:NVIDIA GDS 技术(GPU Direct Storage)
核心要点摘要 (Executive Summary)
本文深入剖析 NVIDIA GPUDirect Storage (GDS) 技术,旨在解决大模型训练与推理中的 I/O 瓶颈问题。
-
核心痛点:传统 I/O 路径导致 CPU 负载过高(Bounce Buffer 问题),限制了 H100 等高端 GPU 的性能释放。
-
技术突破:GDS 利用 RDMA 思想在 NVMe SSD 与 GPU 显存间建立直连 DMA 通道,实测带宽可达 80-100GB/s,同时将 CPU 占用率从 50% 降至 5% 以下。
-
关键场景:在 LLM 推理中,KV Cache 卸载至 NVMe 可将首字延迟(TTFT)降低 40 倍;在万亿参数模型训练中,Checkpoint 存档时间从分钟级缩短至秒级。
-
避坑指南:本文分享了关于 PCIe ACS 配置、MOFED 驱动版本匹配及 4K 对齐等真实部署经验,并提供了 C++ 与 PyTorch 集成代码的示例。
1. 引言:算力狂飙下的“I/O 窒息”
在 NVIDIA Blackwell 架构引领算力指数级飞跃的今天,AI 基础设施的短板已悄然转移。对于架构师而言,最令人绝望的场景并非 GPU 算力不足,而是昂贵的 H100 集群因等待数据 I/O 而处于空转(Idle)状态。这不仅是性能损失,更是巨大的经济浪费。
大模型时代带来了**“显存墙”与“I/O 墙”**的双重夹击。万亿参数模型对显存容量的需求迫使我们依赖外部存储扩容,而数万亿 Token 的训练数据吞吐则让传统 I/O 路径不堪重负。在传统的“SSD -> 系统内存 -> 显存”模式下,CPU 不仅是搬运工,更是最大的瓶颈。为了搬运 50GB/s 的数据,传统 TCP/IP 协议栈加内核拷贝可能消耗 10-20 个 CPU 核心的满载算力 1。
GPUDirect Storage (GDS) 的出现,正是为了打通任督二脉,在 PCIe 底层建立一条 零拷贝直连路径(Zero-Copy Direct Path)。
2. 技术原理:打破冯·诺依曼的枷锁
GDS 的核心在于绕过 CPU 和系统内存(System Memory),利用 PCIe Peer-to-Peer (P2P) 技术实现存储与显存的直接对话。
2.1 核心机制:nvidia-fs.ko 与 cuFile
GDS 并非单纯的驱动,而是一套软硬结合的协议栈:
-
libcufile (用户态):提供类似 POSIX 的 API(如 cuFileRead),但接受的是 GPU 显存指针。
-
nvidia-fs.ko (内核态):这是 GDS 的灵魂。它负责协调文件系统(VFS)与 GPU 驱动,将 NVMe 的 DMA 请求目标地址直接修改为 GPU 的 BAR 空间物理地址。
2.2 架构对比:从“中转站”到“直达专线”
【GDS 架构原理图】
内容:绘制两部分对比图。
-
左侧 (Legacy Path):数据流从 SSD -> CPU (System RAM) -> GPU (VRAM)。在 System RAM 处标注“Bounce Buffer (CPU Copy)”,并用红色高亮显示 CPU 负载过高。路径显曲折。
-
右侧 (GDS Path):数据流从 SSD 直接通过一根粗壮的绿色管道连接到 GPU (VRAM)。管道上标注“PCIe P2P / RDMA”。CPU 位于旁边,仅发送控制指令(Control Path),用虚线连接 SSD,显示“Metadata Only”。
-
风格:技术拓扑图,扁平化风格,深色背景,重点突出数据流向的差异。
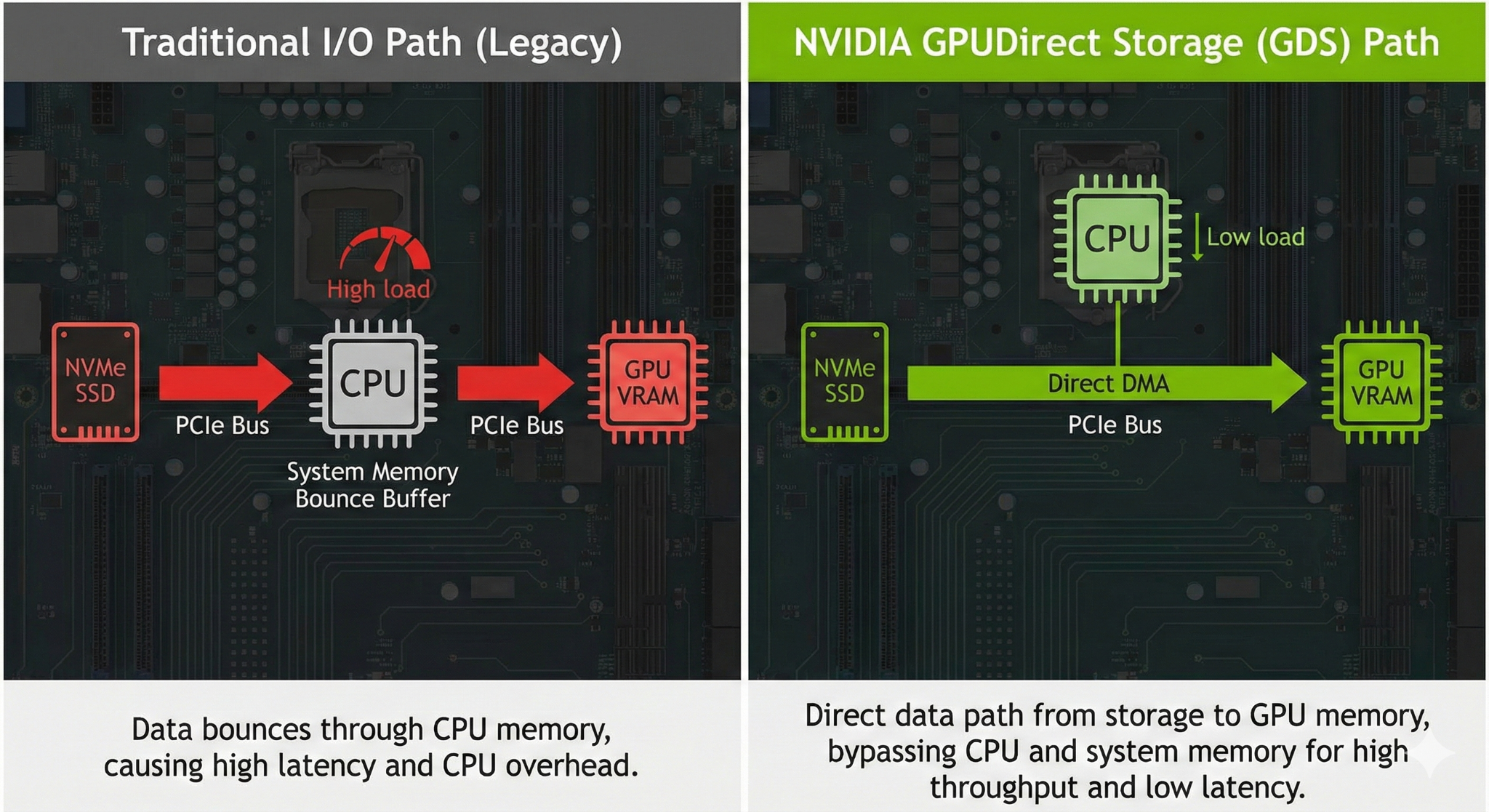
在 GDS 模式下,CPU 仅负责“发号施令”(控制面),繁重的“搬运工作”(数据面)完全由 DMA 引擎接管。这不仅消除了内存带宽的争抢,更重要的是消除了上下文切换(Context Switch)带来的系统抖动。
3. 权威数据验证:用实测击碎质疑
基于 MLPerf Storage 2025 基准测试及 ServeTheHome、Weka 等第三方机构的实测数据,我们整理了以下关键指标。
3.1 性能对比核心数据
表 1:GDS vs. 传统路径实测对比
|
核心指标 |
传统路径 (Legacy) |
GDS 开启 (Direct Path) |
提升幅度 |
数据来源 |
|
单节点吞吐量 |
~15-20 GB/s (CPU瓶颈) |
50-80 GB/s+ (跑满PCIe) |
3-4x |
3 |
|
CPU 占用率 |
40% - 60% |
< 5% |
降低 10 倍 |
2 |
|
4KB 随机读 IOPS |
~1.7 Million |
15.3 Million |
9x |
7 |
|
Checkpoint 写入 |
分钟级 |
秒级 |
大幅缩短 |
8 |
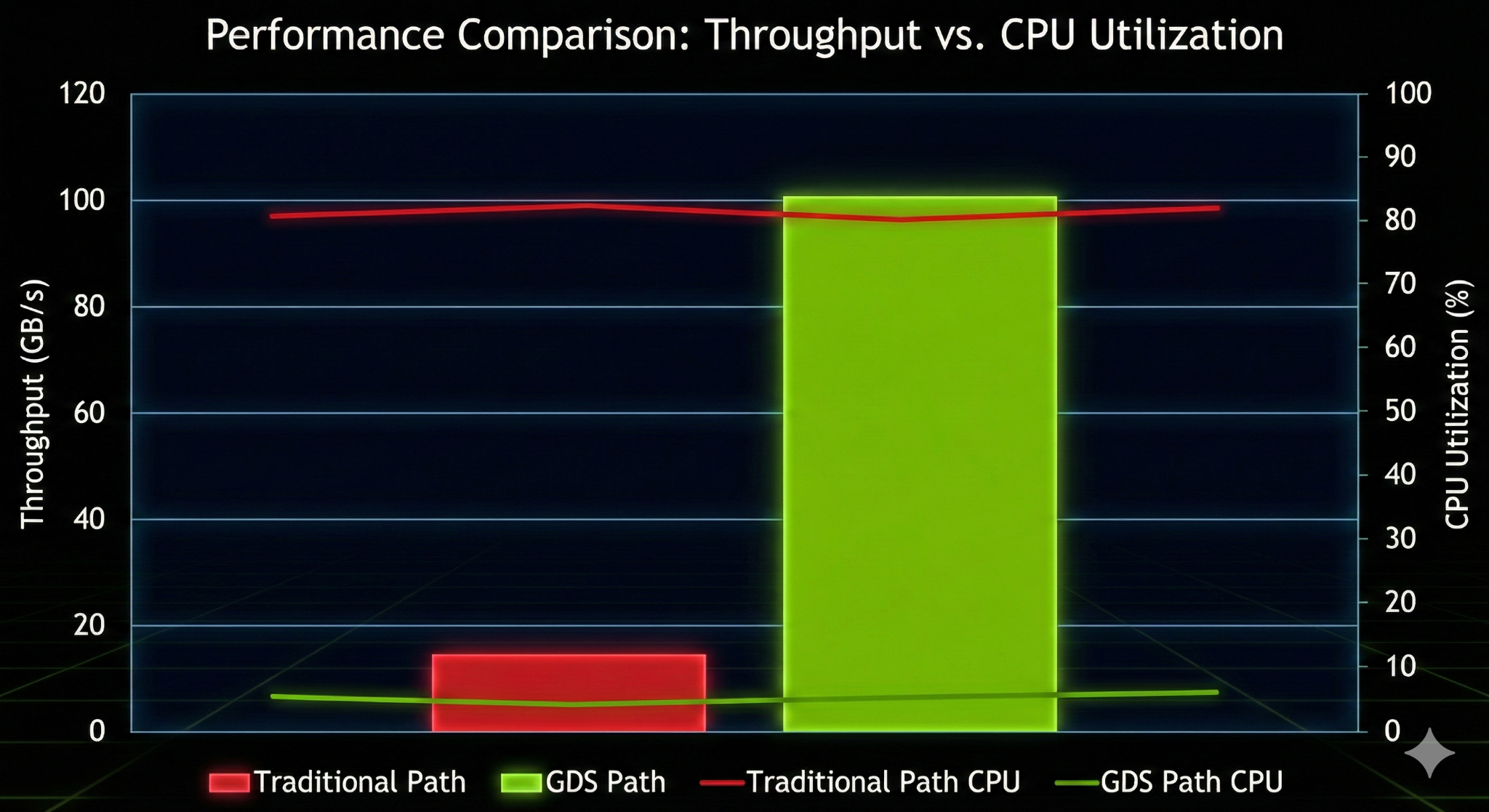
【图表2:CPU 效能对比柱状图】
内容:双Y轴图表。X轴为“吞吐量 (GB/s)”。
-
左Y轴 (CPU Usage):柱状图。Legacy 模式下,随着吞吐量增加,CPU 占用率呈线性飙升至 100%;GDS 模式下,CPU 占用率始终维持在 5% 以下的低位。
-
右Y轴 (Throughput):折线图。Legacy 模式在 20GB/s 左右通过平台期(瓶颈);GDS 模式线性增长直至 SSD 物理极限。
-
标注:在 GDS 曲线旁标注“Zero CPU Overhead”。
3.2 关键发现
-
小包优势:通常认为 DMA 对大文件最有效,但实测显示 GDS 在 4KB 随机读场景下提升更为惊人(9倍 IOPS)。这是因为传统路径在处理小 I/O 时,内核中断和 syscall 开销占比极大,而 GDS 彻底绕过了这些开销 7。
4. 大模型实战场景:GDS 的决定性时刻
场景综述:在大模型生命周期中,GDS 主要解决两类极端 I/O 问题——训练时的“高吞吐瞬间写入”(Checkpoint)和推理时的“低延迟随机读取”(KV Cache Offload)。
4.1 训练阶段:Checkpoint 的“瞬间移动”
在万亿参数模型训练中,保存 Checkpoint 是刚需。传统方式下,保存一个 2TB 的状态可能导致集群停机数分钟。
-
实测数据:结合 Weka 或 VAST Data 等高性能文件系统,GDS 能将 Checkpoint 写入速度提升至 SSD 阵列的物理极限(如 100GB/s+),将存档时间压缩至 10-20 秒 10。这不仅减少了算力浪费,更允许我们将 Checkpoint 频率从“几小时一次”提升到“几十分钟一次”,极大增强了训练的鲁棒性。

4.2 推理阶段:KV Cache 卸载与首字延迟 (TTFT)
对于长文本(Long Context)推理,KV Cache 是显存杀手。
-
痛点:当显存不足时,将 KV Cache 换出到 CPU 内存会导致严重的推理停顿。
-
实测数据:CoreWeave 的测试显示,利用 GDS 将 KV Cache 卸载到本地 NVMe,Llama-3-70B (128k context) 的首字延迟(TTFT)从 23.97秒 骤降至 0.58秒 11。
-
意义:这意味着 NVMe SSD 可以作为“慢速显存”使用,以极低的成本实现无限长的上下文支持。
5. 开发者指南:代码、深坑与故事
5.1 真实故事:消失的带宽与 ACS 陷阱
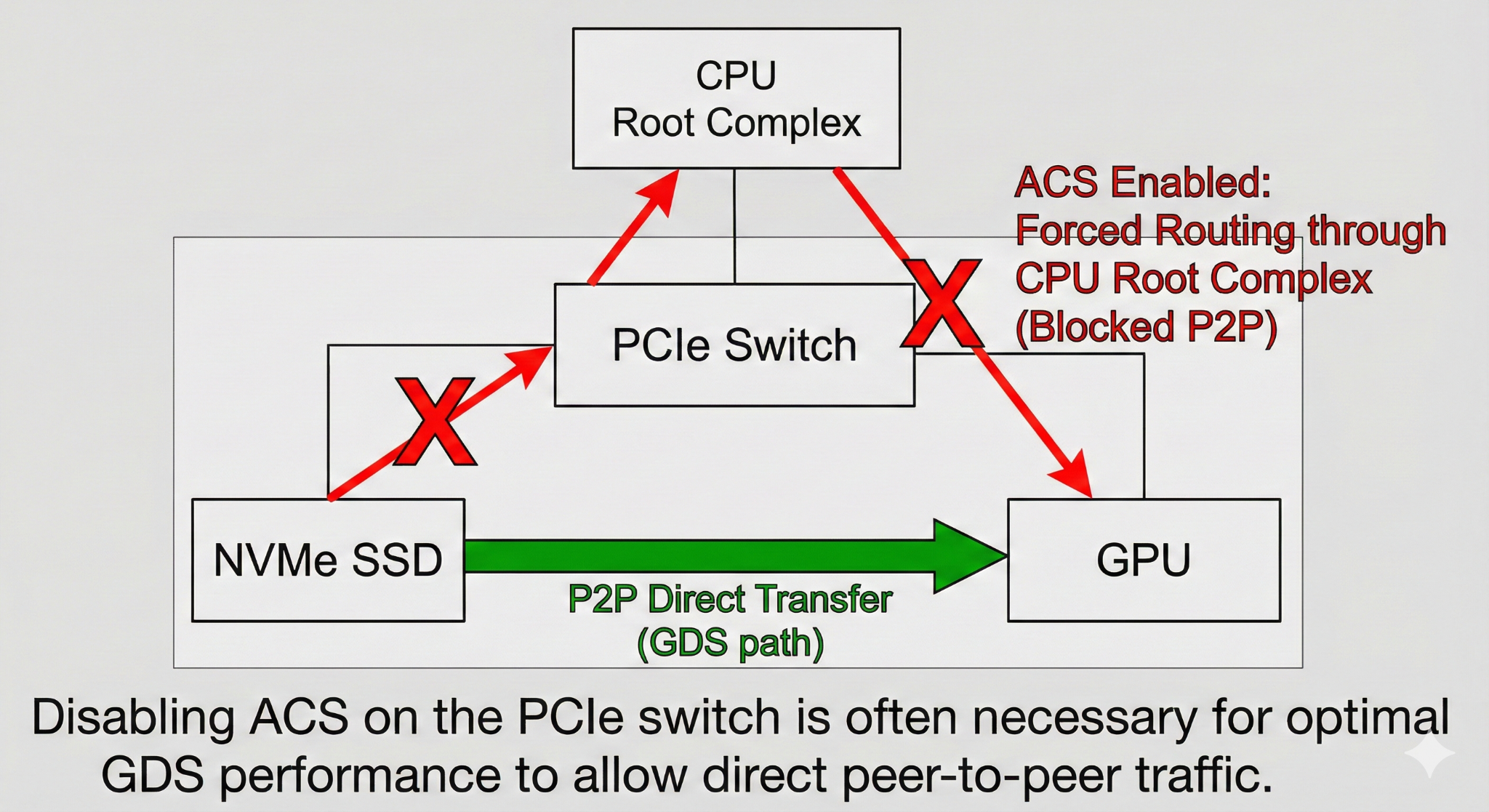
这是我们在部署一套 HGX A100 集群时遇到的真实案例。
我们配置了顶级的 Gen4 NVMe RAID 和 GDS 环境,理论读取带宽应超过 50GB/s。然而,gdsio 测试结果始终卡在 12GB/s —— 这正好是过 CPU 内存拷贝的性能上限。
排查了两天驱动和内核后,我们最终在 PCIe 拓扑中找到了元凶。服务器 BIOS 默认开启了 ACS (Access Control Services)。这个安全特性强制所有 PCIe P2P 流量必须经过 CPU Root Complex 进行 IOMMU 检查,直接切断了 SSD 到 GPU 的直连路径。
解决:在 BIOS 中禁用 ACS,并在 Linux 启动参数中添加 iommu=pt (Passthrough),带宽瞬间飙升至 54GB/s。
所以我们收获了教训:GDS 不仅仅是软件,它强依赖于硬件拓扑的物理连通性!
5.2 核心代码实战
基础:对齐检查与读取
GDS 对内存对齐有严格要求。以下代码展示了如何处理对齐并进行读取:
#include "cufile.h"
// GDS 要求缓冲区地址和文件偏移必须 4K 对齐
#define GDS_ALIGNMENT 4096
void gds_safe_read(CUfileHandle_t cf_handle, void *devPtr, size_t size, off_t offset) {
// 1. 检查对齐 (关键!)
if ((uintptr_t)devPtr % GDS_ALIGNMENT!= 0 |
| offset % GDS_ALIGNMENT!= 0) {
printf("Error: Memory or Offset not 4K aligned. GDS will fail or fallback.\n");
return;
}
// 2. 执行读取
ssize_t bytes = cuFileRead(cf_handle, devPtr, size, offset, 0);
if (bytes < 0) {
printf("GDS Read Failed: %d\n", bytes);
} else {
printf("Successfully read %zd bytes via Direct DMA\n", bytes);
}
}
进阶:PyTorch 集成思路
在 Python/PyTorch 中,我们通常通过自定义 C++ Extension 或使用 kvikio 库来实现。核心逻辑是获取 Tensor 的数据指针。
import torch
# 假设我们封装了一个 C++ 扩展模块 gds_lib
import gds_lib
def load_tensor_via_gds(filepath, shape, dtype):
# 1. 预分配 GPU 显存 (PyTorch Tensor)
# 注意:PyTorch 分配的内存通常是 256 字节对齐的,满足 GDS 4K 对齐需求通常需要手动检查或 padding
tensor = torch.empty(shape, dtype=dtype, device='cuda')
# 2. 获取数据指针 (Data Pointer)
dev_ptr = tensor.data_ptr()
# 3. 调用 GDS 读取 (底层调用 cuFileRead)
# 务必确保文件是以 O_DIRECT 模式打开的
bytes_read = gds_lib.pread_gds(filepath, dev_ptr, tensor.nbytes)
return tensor
5.3 避坑指南总结 (Key Takeaways)
部署 GDS 的三大铁律:
-
MOFED 版本地狱:nvidia-fs.ko 对内核版本和 MOFED (Mellanox OFED) 驱动版本极其敏感。务必锁定内核版本,严禁随意 apt upgrade。
-
IOMMU/ACS 必须关:这是性能杀手。使用 gdscheck -p 检查 P2P 支持状态,确保看到 "P2P Supported: Yes"。
-
O_DIRECT 是强制的:GDS 不支持带缓存的 I/O。文件系统挂载选项和打开文件时必须支持 O_DIRECT,且读写地址必须 4K 对齐。
6. 成本效益与替代方案
在决定上 GDS 之前,我们需要算一笔账。
6.1 GDS vs. Unified Memory (如 Grace Hopper)
-
Unified Memory (GH200):通过 NVLink-C2C 让 CPU 和 GPU 共享海量内存(如 480GB LPDDR5X)。
-
优势:编程极其简单,无需手动搬运数据,CPU 指针 GPU 直接用。
-
劣势:昂贵。且数据最初仍需从 SSD 加载到内存,这一步依然受 I/O 限制。
-
GDS:
-
定位:解决的是 Storage 到 Memory 的搬运。无论你的内存有多大,数据总归要从硬盘里读出来。
-
结论:二者互补。GH200 解决了内存容量问题,GDS 解决了数据加载速度问题。对于现有的 x86 + H100/A100 存量集群,GDS 是提升 I/O 效率性价比最高的方案。
6.2 ROI 分析
-
投入:特定的 NVMe 硬件、网卡固件升级、复杂的软件栈维护。
-
产出:训练 Checkpoint 时间减少 80%(直接增加有效训练时长),推理首字延迟降低 90%(直接提升用户体验)。对于日均租金数万美元的集群,GDS 带来的 Goodput 提升能在一周内收回部署成本。
7. 总结:存算一体的最后一块拼图
GDS 技术的本质,是让存储设备不再是“外人”,而是通过 PCIe 总线成为 GPU 的“远房亲戚”。它打破了 CPU 对数据的垄断,让数据在存储与算力之间实现了真正的自由流动。
随着 AI 模型对数据吞吐需求的无止境增长,掌握 GDS 及其背后的 I/O 优化原理,将成为每一位 AI 基础设施工程师的核心竞争力。
参考资料:
-
1 NVIDIA GDS Benchmarks & ServeTheHome CPU Utilization Tests
-
8 Weka & VAST Data Checkpointing Performance Reports
-
11 CoreWeave & MLPerf Storage Inference Results
-
NVIDIA GDS Configuration & Troubleshooting Guide*
引用的著作
-
GPUDirect Storage Design Guide - NVIDIA Documentation, 访问时间为 一月 21, 2026, https://docs.nvidia.com/gpudirect-storage/design-guide/index.html
-
GPUDirect Storage Performance Report and NVMe-oF(tm) Contribution - KIOXIA America, Inc., 访问时间为 一月 21, 2026, https://americas.kioxia.com/content/dam/kioxia/shared/business/ssd/kumoscale-software/asset/KIOXIA_GPUDirect_WP_e.pdf
-
GPU Direct Storage: performance comparison -, 访问时间为 一月 21, 2026, https://uol.de/f/5/scientificcomputing/AKSC-HT23/20230928_ZKI_AKSC_HT23_GPUDirectStore.pdf
-
Optimizing AI Workloads With Solidigm™ Solid-State Drives, 访问时间为 一月 21, 2026, https://www.solidigm.com/products/technology/mlperf-ai-workloads-with-solidigm-ssds.html
-
Analyzing the Effects of GPUDirect Storage on AI Workloads - SNIA.org, 访问时间为 一月 21, 2026, https://www.snia.org/sites/default/files/SDCEMEA/2021/snia-analyzing-effects-of-GPU-direct-storage.pdf
-
GDS seems to consume more CPU and memory resources than expected, 访问时间为 一月 21, 2026, https://forums.developer.nvidia.com/t/gds-seems-to-consume-more-cpu-and-memory-resources-than-expected/319012
-
How Weka is Solving AI's Trillion Dollar Memory Problem. | by Devansh | Jan, 2026, 访问时间为 一月 21, 2026, https://machine-learning-made-simple.medium.com/how-weka-is-solving-ais-trillion-dollar-memory-problem-25a37b6776b9
-
LLM training in practice: insights from 85000 checkpoints, 访问时间为 一月 21, 2026, https://pdsw.org/pdsw25/papers/wips/ws_pdswwip108s2-file1.pdf
-
Scaling AI Checkpoints: The Impact of High-Capacity SSDs on Model Training, 访问时间为 一月 21, 2026, https://www.storagereview.com/review/scaling-ai-checkpoints-the-impact-of-high-capacity-ssds-on-model-training
-
From Minutes to Seconds: Redefining the Five-Minute Rule ... - arXiv, 访问时间为 一月 21, 2026, https://arxiv.org/abs/2511.03944
-
Breaking the Memory Barrier: How LMCache and CoreWeave Power Efficient LLM Inference for Cohere, 访问时间为 一月 21, 2026, https://blog.lmcache.ai/en/2025/10/29/breaking-the-memory-barrier-how-lmcache-and-coreweave-power-efficient-llm-inference-for-cohere/
-
Democratizing AI Inference: The Future of AI Should Take Minutes, Not Weeks - WEKA, 访问时间为 一月 21, 2026, https://www.weka.io/blog/ai-ml/democratizing-ai-inference-the-future-of-ai-should-take-minutes-not-weeks/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)