【工具调用】数据集总结
本文汇总了多个关于工具增强型语言模型(LLM)的最新研究,重点介绍它们在API调用和多轮交互方面的创新。AgentBank提出了5万+轨迹调优数据集,FunReason-MT开发了多轮函数调用框架,Gorilla和ToolLLM分别连接了海量API(16,000+),API-Bank则提供了全面的评估基准(73个API)。这些研究通过数据合成、轨迹调优和专用训练集(如ToolDial的多轮对话集)
AgentBank: Towards Generalized LLM Agents via Fine-Tuning on 50000+ Interaction Trajectories
论文:https://arxiv.org/abs/2410.07706
数据:https://huggingface.co/datasets/Solaris99/AgentBank
简介:对代理环境交互轨迹数据的微调对于揭示开源大型语言模型(LLM)中通用代理能力具有重大潜力。本研究介绍了AgentBank,迄今为止规模最大的轨迹调优数据集,包含超过5万条多样化的高质量交互轨迹,涵盖涵盖五个不同代理技能维度(推理、数学、编程、Web、具身智能)的16个任务。利用新颖的注释流水线,我们能够扩展注释轨迹,生成难度偏置最小的轨迹数据集。此外,我们在AgentBank上微调LLM以获得一系列代理模型,如Samoyed。我们的比较实验展示了扩展交互轨迹数据以获得通用代理能力的有效性。其他研究还揭示了轨迹调优和代理技能泛化的一些关键观察。但数据内容以旧的ReAct格式输出,不含think模式标签。
FunReason-MT Technical Report: Overcoming the Complexity Barrier in Multi-Turn Function Calling
论文:https://arxiv.org/abs/2510.24645
代码:https://github.com/inclusionAI/AWorld-RL
简介:函数调用 (FC) 使大型语言模型 (LLM) 和自主代理能够与外部工具交互,这是解决复杂现实问题的关键功能。随着这种能力对于高级人工智能系统越来越重要,对高质量、多轮训练数据的需求来开发和完善它怎么强调都不为过。现有的数据合成方法,例如随机环境采样或多智能体角色扮演,不足以在现实环境中生成高质量的数据。实际挑战分为三个方面:有针对性的模型训练、工具架构的隔离和多轮逻辑依赖。为了解决这些结构缺陷,我们提出了 FunReason-MT,这是一种用于实际多圈工具使用的新型数据综合框架。
FunReason-MT :(1) 环境-API 图交互来收集各种高质量的轨迹,(2) 高级工具查询合成来简化硬查询构建,(3) 用于复杂 CoT 生成的引导迭代链,从而解决了多轮次 FC 数据中的复杂性障碍。对 BFCLv3 的评估证明了我们框架的强大功能:基于 FunReason-MT 生成的数据构建的 4B 模型在可比规模的模型中实现了最先进的性能,优于大多数近源模型。BFCLv4 上评估了Agentic能力,在OOD评测集上也进一步了改进性能。
基于BFCL-v3中的工具构建的数据集。
Gorilla: Large Language Model Connected with Massive APIs
论文:https://arxiv.org/abs/2305.15334
代码:https://github.com/ShishirPatil/gorilla
简介:OpenFunctions 旨在扩展大型语言模型 (LLM) 聊天完成功能,以制定可执行 API 调用给定的自然语言指令和 API 上下文。想象一下,如果 LLM 可以 填写各种服务的参数,从 Instagram 和 DoorDash 到 谷歌日历和条纹。即使是不太熟悉 API 调用过程的用户,以 编程可以使用该模型生成对所需函数的 API 调用。Gorilla OpenFunctions 是一个LLM我们使用一组精选的 API 文档进行训练,并生成问答对 从 API 文档中获取。
● 📚 数据集:gorilla-llm/OpenFunctions
● 💡 提供了:
○ 每个函数(API)的参数签名;
○ 文档描述;
○ 示例调用;
○ 部分函数在“gorilla”运行时中可直接执行。
● 🧰 函数来源:
○ HuggingFace Inference API;
○ OpenAI Completion/Image;
○ Google Translate;
○ Slack, Stripe, Twilio 等;
● 🧪 执行方式:
from gorilla import GorillaClient
client = GorillaClient()
result = client.call("huggingface.text_generation", text="hello world", model="gpt2")
print(result)
● ✅ 特点:
○ 所有 API 都带文档;
○ 大部分有对应真实 HTTP endpoint;
○ 可作为function-calling 训练 + 测试 + 验证闭环系统。
💡 用途建议:
你可以直接把 Gorilla 的函数调用器整合进训练框架(如 RLHF 环境),让模型调用真实 API 并基于返回结果计算 reward。
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
论文:https://arxiv.org/abs/2307.16789
代码:https://github.com/OpenBMB/ToolBench
简介:ToolBench仓库中提供了相关数据集、训练和评估脚本,以及在ToolBench上微调的功能模型ToolLLaMA,具体特点为:
- 支持单工具和多工具方案,其中单工具设置遵循LangChain提示风格,多工具设置遵循AutoGPT的提示风格。
- 模型回复不仅包括最终答案,还包含模型的思维链过程、工具执行和工具执行结果
- 支持真实世界级别的复杂性,支持多步工具调用
- 丰富的API,可用于现实世界中的场景,如天气信息、搜索、股票更新和PowerPoint自动化
- 所有的数据都是由OpenAI API自动生成并由开发团队进行过滤,数据的创建过程很容易扩展
不过需要注意的是,目前发布的数据还不是最终版本,研究人员仍然在对数据进行后处理来提高数据质量,并增加真实世界工具的覆盖范围。
● 💡 内容:
○ 工具(API)描述、参数定义;
○ 每个工具都是真实 Web API(如 weather, calculator, translation);
○ 官方提供 ToolServer,模型可通过 HTTP 实际调用工具。
● ⚙️ 官方调用接口:
from toolbench import ToolServer
server = ToolServer("configs/tool_config.json")
response = server.call_tool("WeatherAPI.get_forecast", {"location": "Tokyo", "date": "tomorrow"})
print(response)
● ✅ 特点:
○ 所有工具均可真实调用;
○ 工具通过 JSON-RPC 或 HTTP 请求执行;
○ 提供 docker 化部署;
○ 支持代理 / 无 key 模式(部分 API 模拟);
○ 非常适合做 RL 或在线验证。
💡 强烈推荐:ToolBench 是目前最完善的“可调用工具 + 训练数据”组合项目。
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
论文:https://arxiv.org/abs/2304.08244
代码:https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/api-bank
简介:最近的研究表明,大型语言模型 (LLM) 可以通过利用外部工具来增强其功能。然而,三个关键问题仍未得到解答:(1)当前的LLM在利用工具方面的效率如何?(2)如何提高LLM使用工具的能力?(3)使用工具需要克服哪些障碍?为了解决这些问题,我们推出了 API-Bank,这是一个突破性的基准,专为工具增强的 LLM 设计。对于第一个问题,我们开发了一个由 73 个 API 工具组成的可运行评估系统。我们用 753 个 API 调用注释 314 个工具使用对话,以评估现有 LLM 在规划、检索和调用 API 方面的能力。对于第二个问题,我们构建了一个全面的训练集,其中包含来自 1,000 个不同领域的 2,138 个 API 的 1,888 个工具使用对话。使用这个数据集,我们训练了 Lynx,这是一个从 Alpaca 初始化的工具增强型 LLM。实验结果表明,与 GPT-3 相比,GPT-3.5 表现出更高的工具利用率,而 GPT-4 在规划方面表现出色。然而,仍有巨大的进一步改进潜力。此外,Lynx 比 Alpaca 的工具利用性能高出 26 个百分点以上,接近 GPT-3.5 的有效性。通过误差分析,我们强调了该领域未来研究面临的主要挑战,以回答第三个问题。
● 💡 特点:
○ 汇集真实第三方 API;
○ 含约 300K 条指令;
○ 每个 API 提供调用样例;
○ 提供一个“mock API server”供本地调试;
○ 支持真实调用(需注册 API key)。
● ⚙️ 执行示例:
from apibank.client import APIClient
client = APIClient(api_key="YOUR_KEY")
response = client.call("weatherapi_get_forecast", location="Tokyo", date="tomorrow")
print(response)
● ⚠️ 注意:
○ 部分 API 需要外部 key;
○ 另一些提供 mock 返回;
○ 可选 “真实调用模式” vs “模拟模式”。
💡 用途建议:
可以用作「半真实环境」训练——模型发出调用,环境返回真实或模拟结果,用于计算 reward 或 correctness。
ToolDial: Multi-turn Dialogue Generation Method for Tool-Augmented Language Models
论文:https://arxiv.org/abs/2503.00564
代码:https://github.com/holi-lab/ToolDial
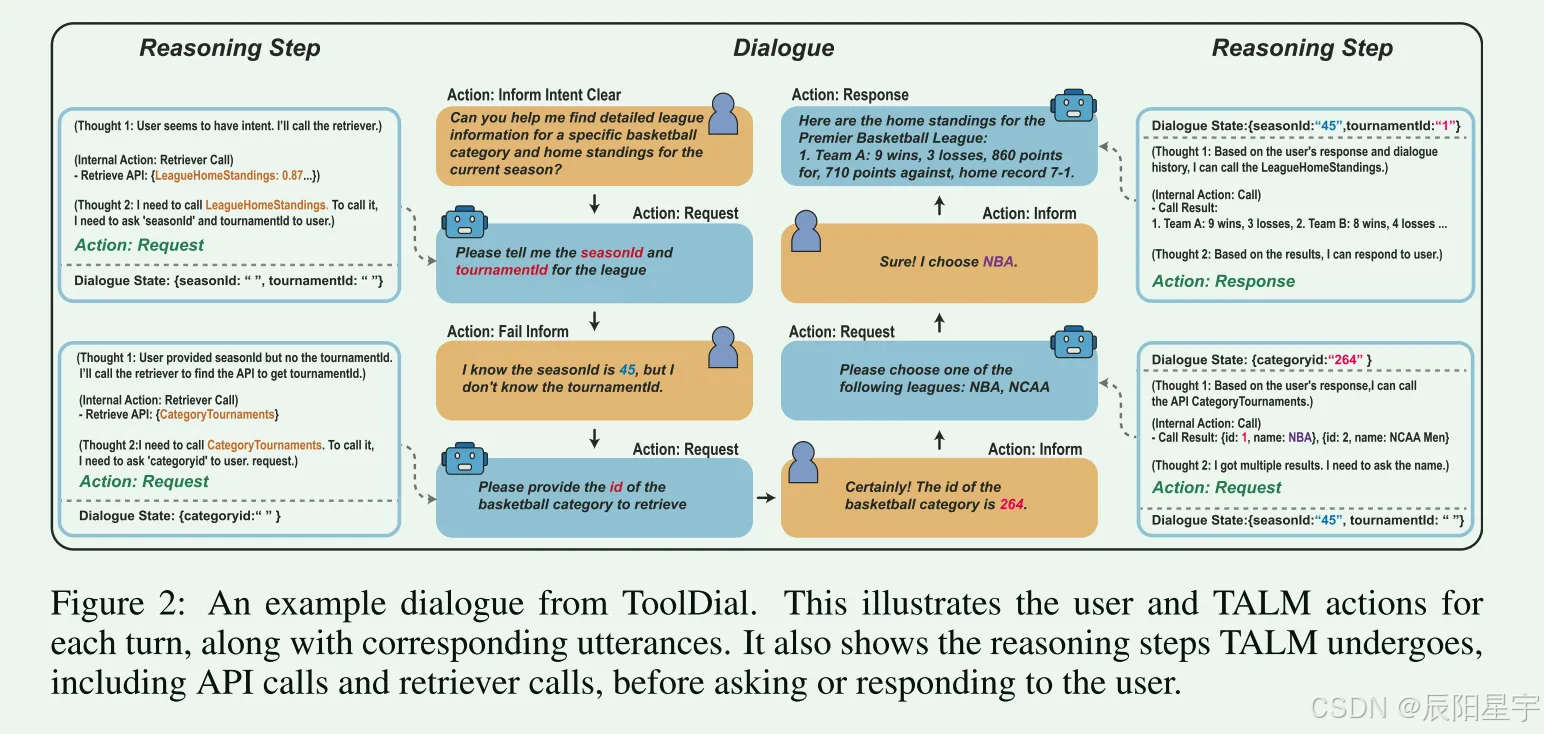
简介:多轮任务对话集,模拟用户与“工具增强型语言模型”(TALM)的互动。基于RapidAPI的真实API,包含11,111个对话(平均8.95轮/对话)。对话中引入了16种用户和系统动作(如Clarify、Request、Call等),系统在缺少信息时会主动询问或调用额外API。数据格式为多轮对话,其中对话状态包含待调用API及参数信息;每条对话包括用户询问、系统提问以获取参数、最后的API调用与回答。该数据集适用于评估LLM的多轮动作预测和对话状态跟踪能力。数据规模:共11,111条对话(8859训练、1086验证、1166测试);下载地址:GitHub仓库 holi-lab/ToolDial。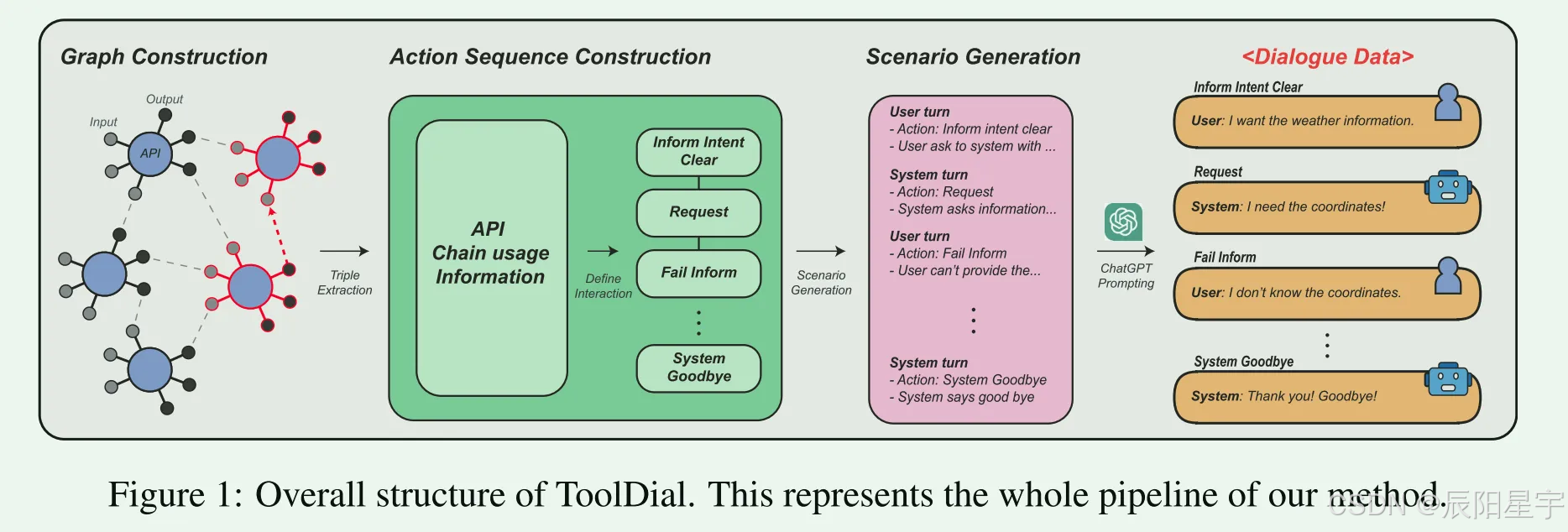
● 数据构建方法:
○ API图构建
■ 为了模拟应该按顺序调用API以满足用户需求的对话(例如,用户未能为API提供必要的参数,因此系统应该主动查找并运行可以提供它的另一个API),有必要确定哪个API的输出可以用作另一个API的输入(即,API链接)。如果一个API的输出可以用作另一个API的输入,则两个API通过一条边连接。最终,这个API图将用于对话生成,允许我们轻松地选择要按顺序调用的兼容API。StableToolBench可以生成类似于实际API调用的API输出,允许我们以类似于实际API调用的方式验证边缘。
○ 动作序列
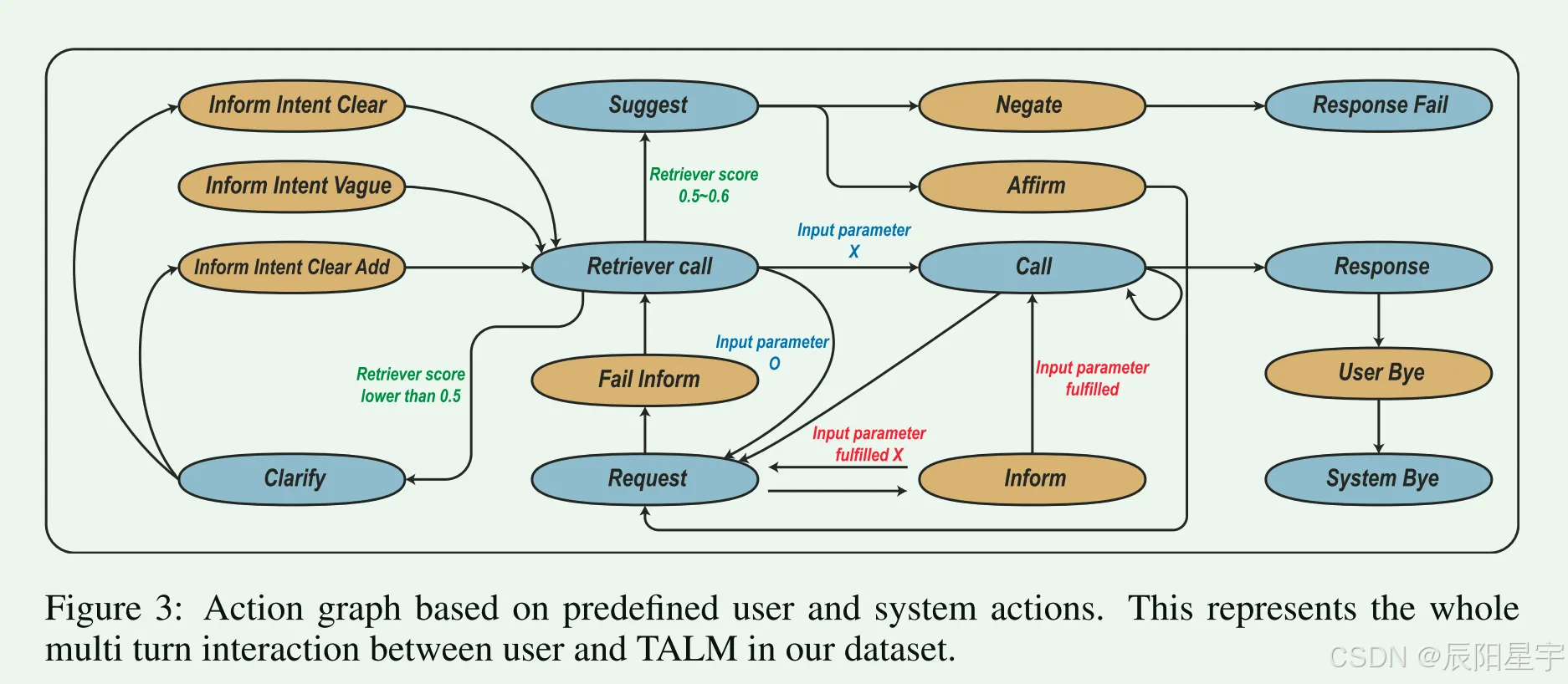
■ 定义了用户和系统可以执行的总共16个操作(8个用户动作和8个系统动作)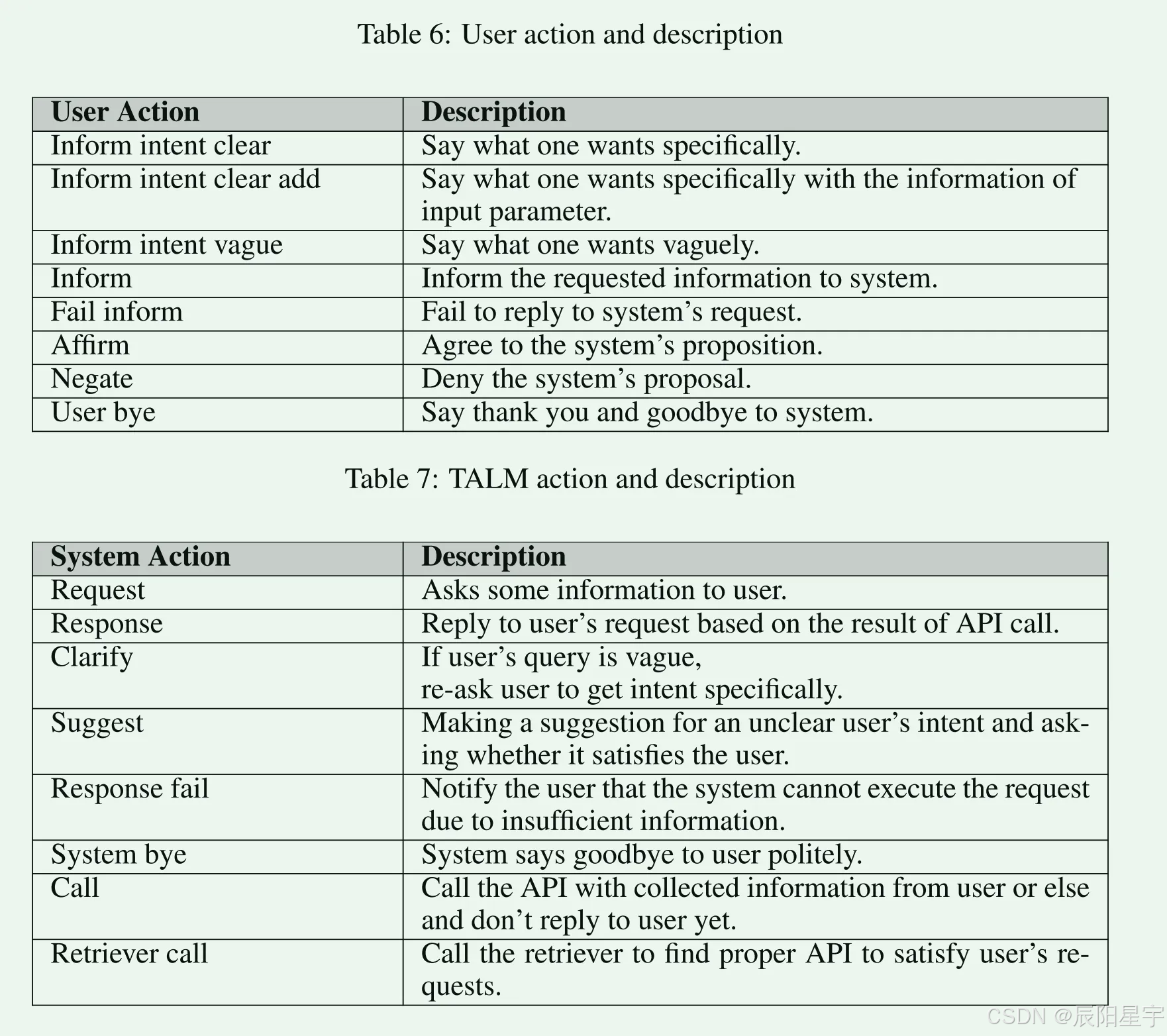
○ 场景指令生成
■ User Query:将API的描述文档给GPT-4o,让其生成与之相关的用户query。
■ 对话状态:GPT-4o模拟了具体和可信的工具调用参数值。(系统要调用的API名称、它的输入参数和用户提供的参数值)
■ 场景指令:基于对话状态,构建指令指导GPT-4o生成用户和系统对话。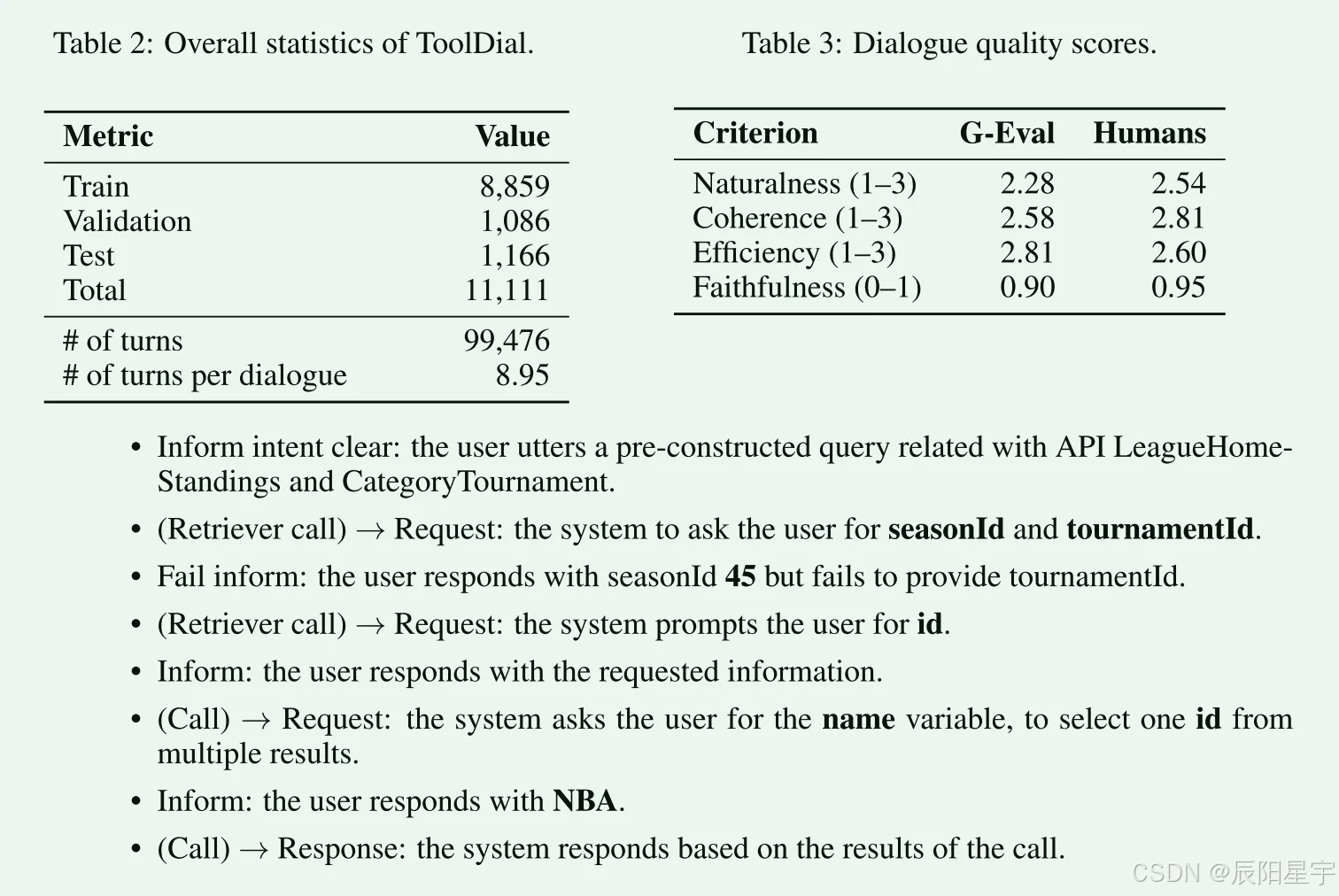
ToolACE: Winning the Points of LLM Function Calling
论文:https://arxiv.org/abs/2409.00920
代码:https://huggingface.co/datasets/Team-ACE/ToolACE
简介:提出了一种新的函数调用自动化数据管道——ToolACE,它包括一个工具自进化合成模块、一个自引导对话生成模块和一个双层验证模块。开发了一种自我引导的复杂性策略来生成具有适当复杂性的各种类型的函数调用对话框。利用给定的大型语言模型作为复杂性评估器来指导生成数据的复杂性级别。生成数据的质量是通过结合规则检查器和模型检查器的双层验证过程来保证的。
通过自动化流水线构造了一个包含26,507个API的工具库,生成了多轮对话,涵盖单步调用、并行调用、依赖调用等情形。数据示例为用户查询与助手返回函数调用列表(每次调用格式如[Func1(arg=…), Func2(arg=…)]),并附带工具执行结果。该数据集用于训练模型进行多轮工具调用(函数调用标记示例见“HuggingFace Team-ACE/ToolACE”),并在BFCL排行榜上测试模型性能。数据规模:API池26,507个,公开数据子集约1.13万条多轮对话(train);下载地址:HuggingFace Team-ACE/ToolACE。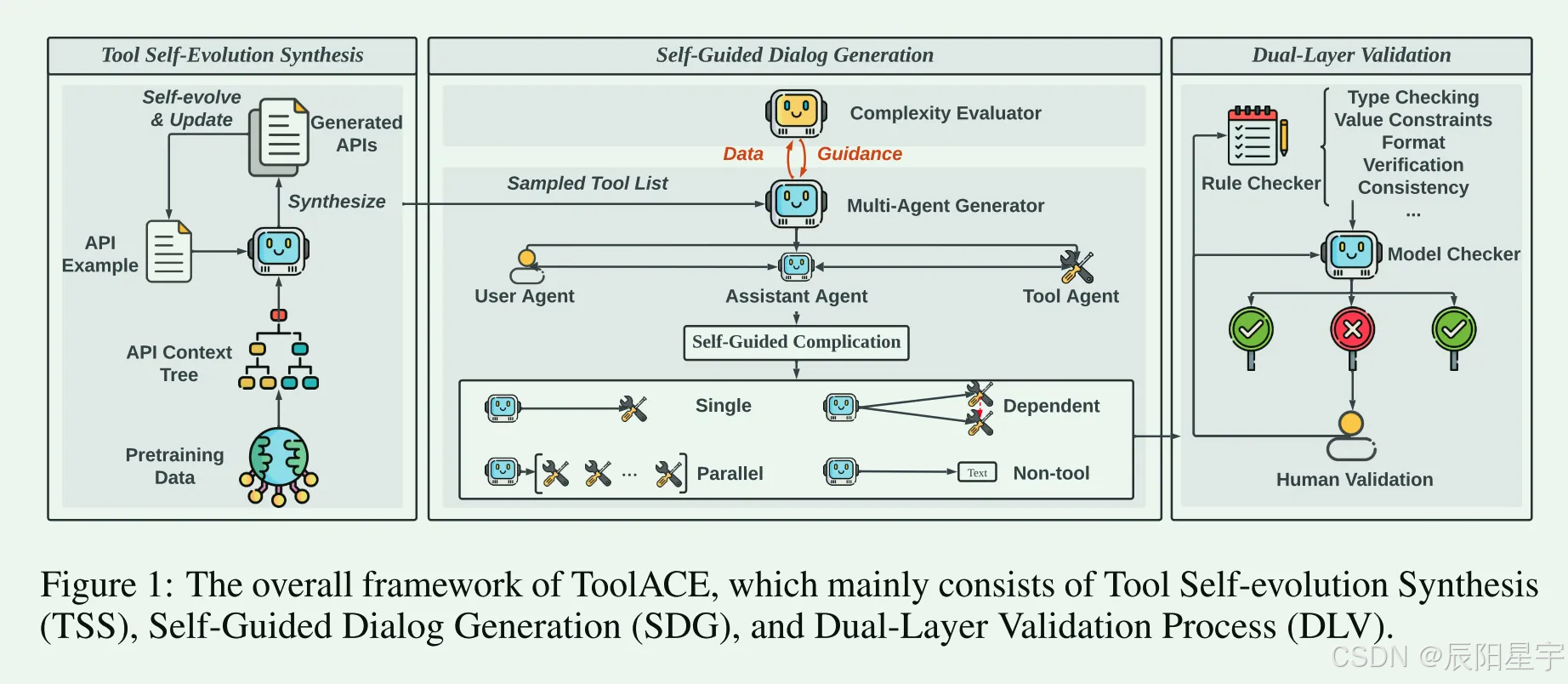
HammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios
论文:https://arxiv.org/abs/2412.16516
代码:https://huggingface.co/datasets/MadeAgents/HammerBench
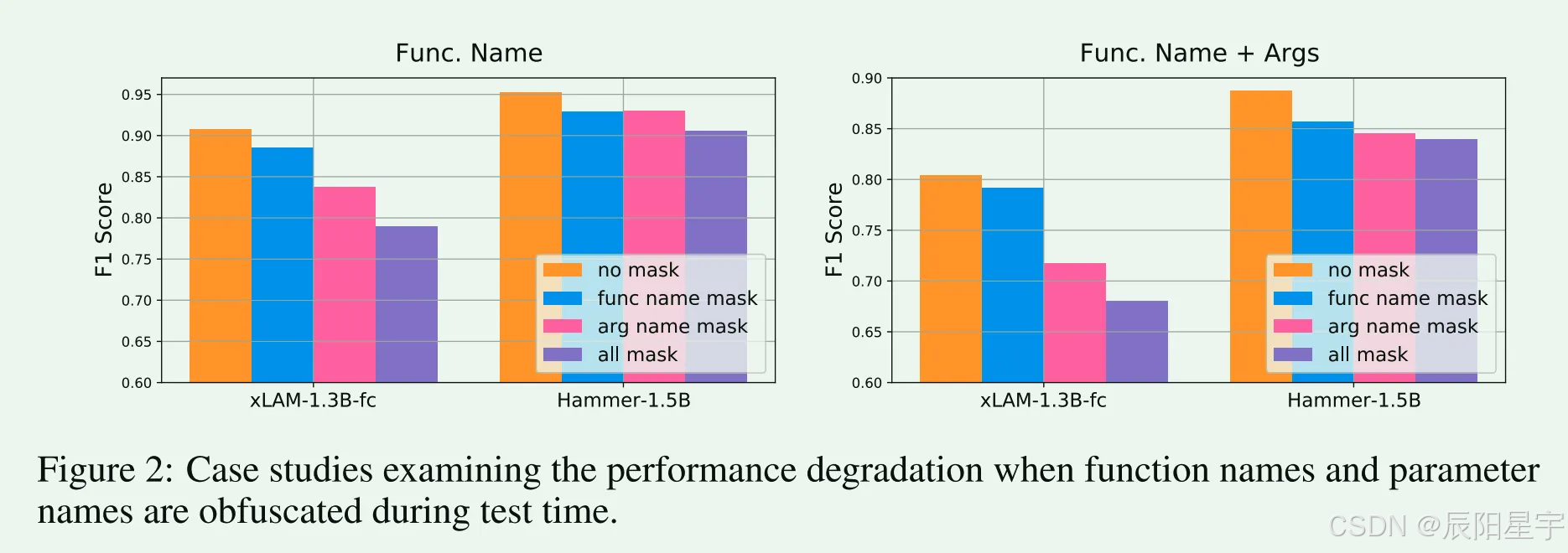
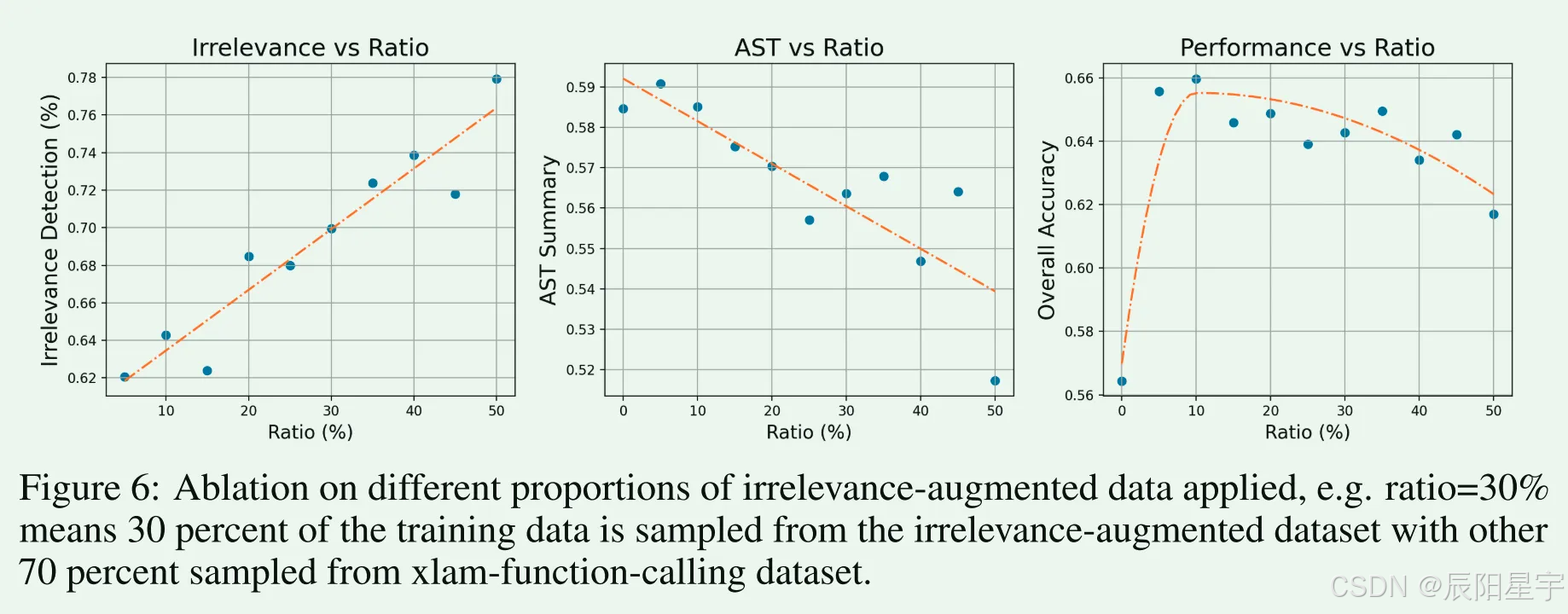
简介:增强了两种类型数据,一种是增强工具名的鲁邦性数据,一种是增强对不相关工具检测能力的数据。进行了消融实验,探索掩码比率、不相关性数据比率多少时候结果最优。
本文发现一个问题是当测试集中函数命名风格和训练集中函数命名风格不一致时候,会导致性能的下降,主要原因是模型不能很好的从函数描述中识别出差异,只靠函数命名而简单的理解。因此本文的重点就从函数名和参数转移到函数描述上。文中说明了函数名和参数名在训练集中和测试集中相似,但是功能不同时候,会出现的误导问题。
● 工具名鲁棒性问题:
○ 函数名误导:当用户意图与训练标签中出现的功能名称紧密一致时,模型可能会在测试期间错误地优先考虑候选列表中的功能,即使其功能与预期操作显著偏离。
○ 参数名误导:在测试环境中参数的功能和描述发生变化的情况下,模型经常会坚持其原始的参数使用模式,从而导致不正确的函数调用。
○ 命名偏好误导:训练集和测试集中命名约定不一致时候,鲁棒性会降低。
● 解决方式:
○ 函数名、参数名、默认值被随机替换,描述不变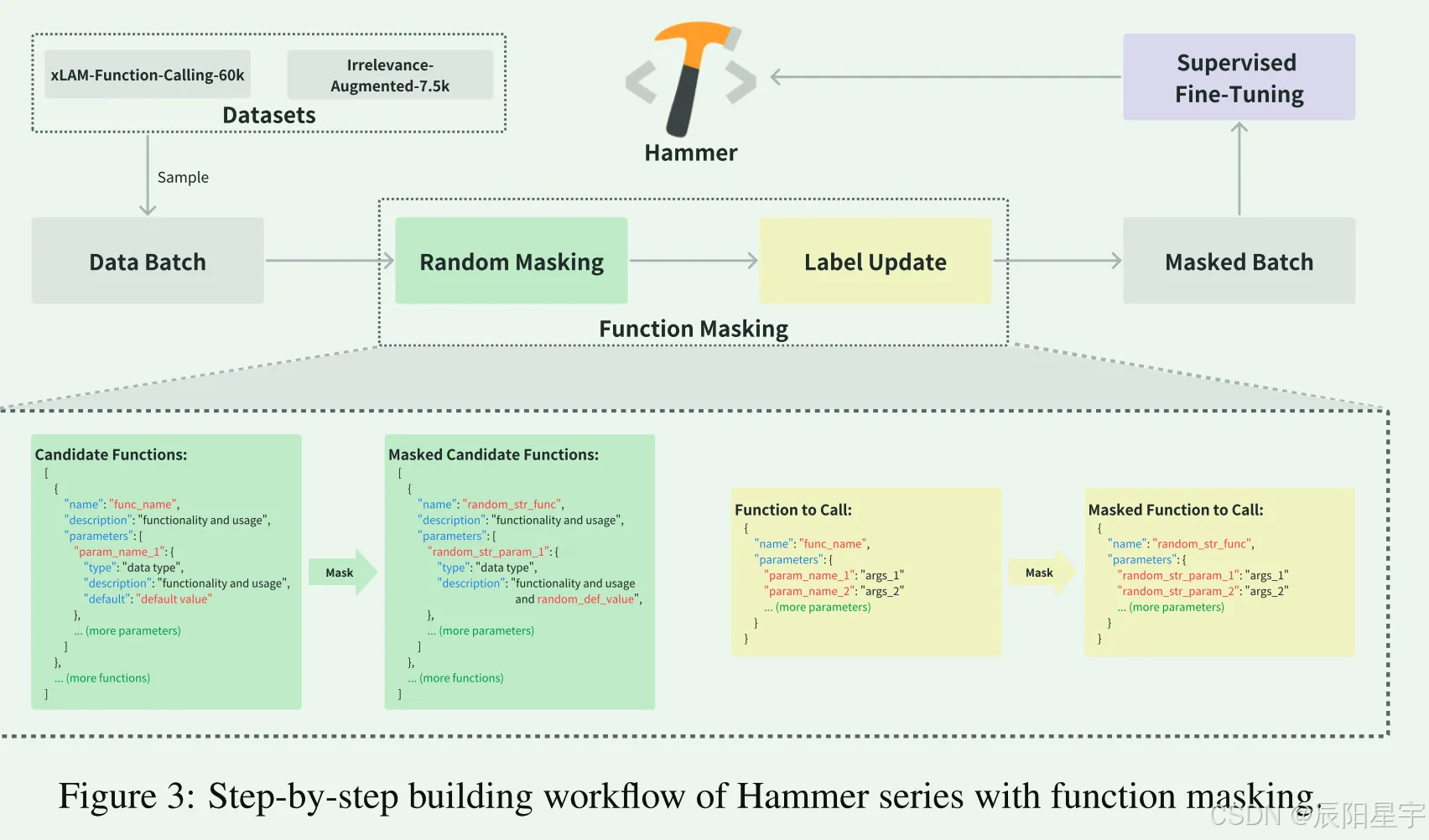
● 不相关性检测鲁棒性问题:
○ 模型准确执行函数调用的能力与其不相关检测能力之间的反比关系。通过在准用函数上微调增强选择能力的同时, 可能会损害检测不相关性工具的能力。
● 解决方式:
○ 从xlam-function- calls -60k数据集中采样的7500个示例,其中正确的函数被故意从候选列表中排除,并且标签被空列表替换。通过将模型暴露给更多需要不相关检测的实例,增强其辨别何时放弃进行函数调用的能力,从而促进更明智的函数选择。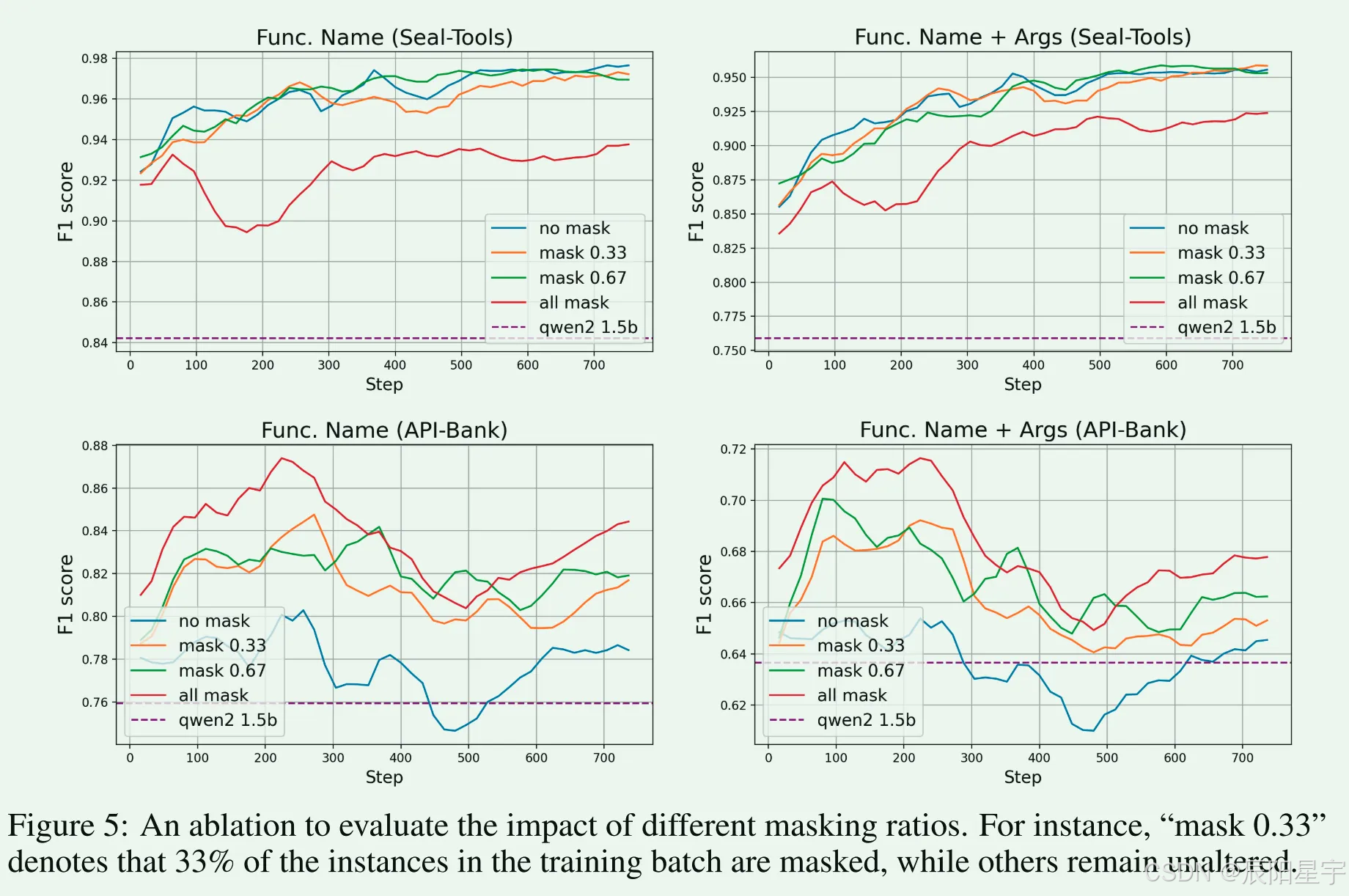
APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay
论文:https://arxiv.org/abs/2504.03601
代码:https://apigen-mt.github.io/
简介:介绍了APIGen-MT,这是一个两阶段框架,可以生成可验证的和多样化的多回合代理数据。在第一阶段,Agent pipline 利用大型语言模型评审委员会和迭代反馈循环,生成带有真实值行动的详细任务蓝图。然后,通过模拟人类相互作用,将这些蓝图转化为完整的相互作用轨迹。作者训练了一系列模型- xLAM-2-fc-r系列,尺寸范围从1B到70B个参数。源了5K合成数据轨迹和训练好的xLAM-2-fc-r模型。模型在τ-bench和BFCL基准测试中优于前沿模型,如gpt-4o和Claude 3.5,较小的模型优于较大的模型,特别是在多回合设置中,同时在多个试验中保持卓越的一致性。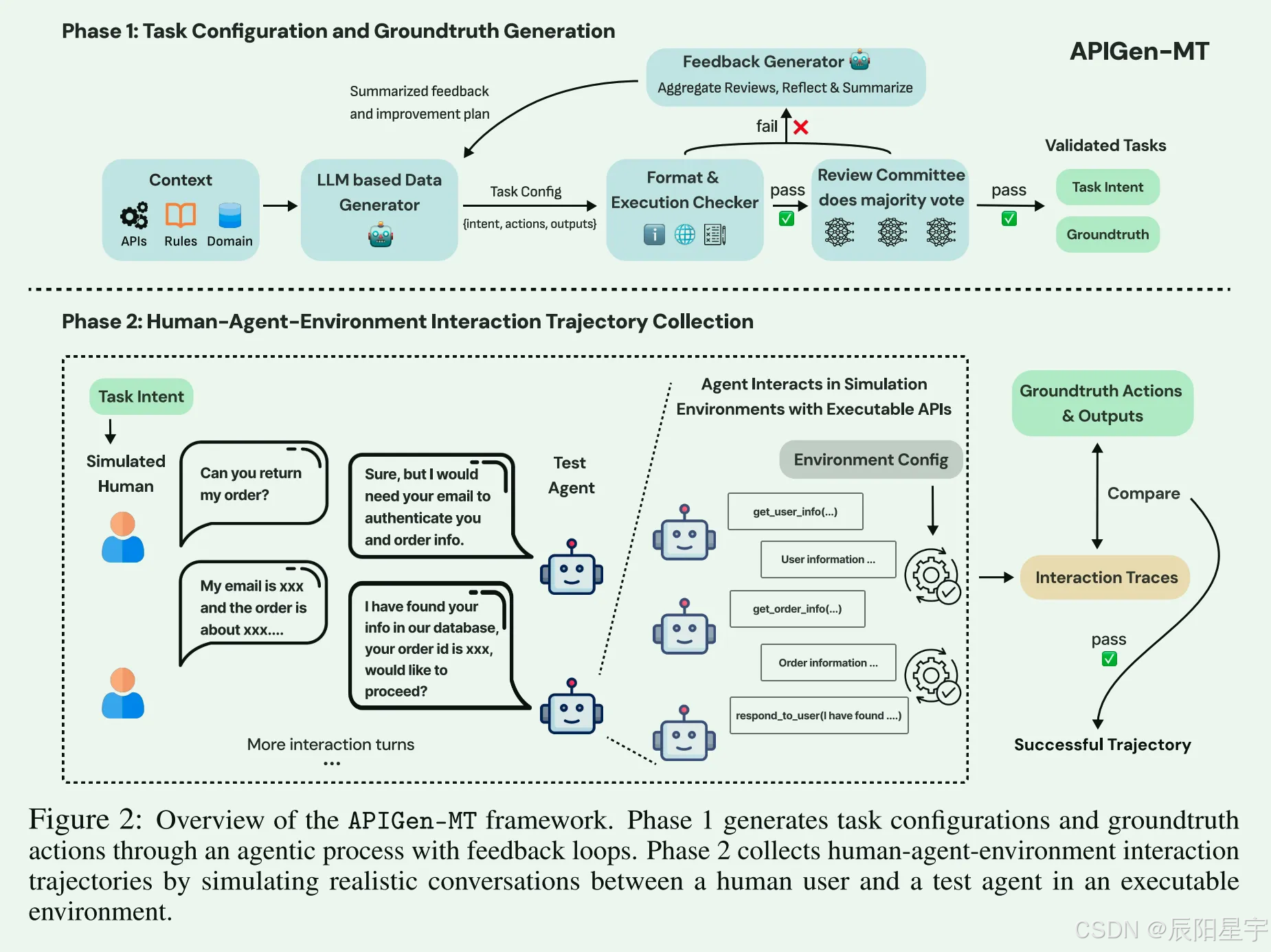
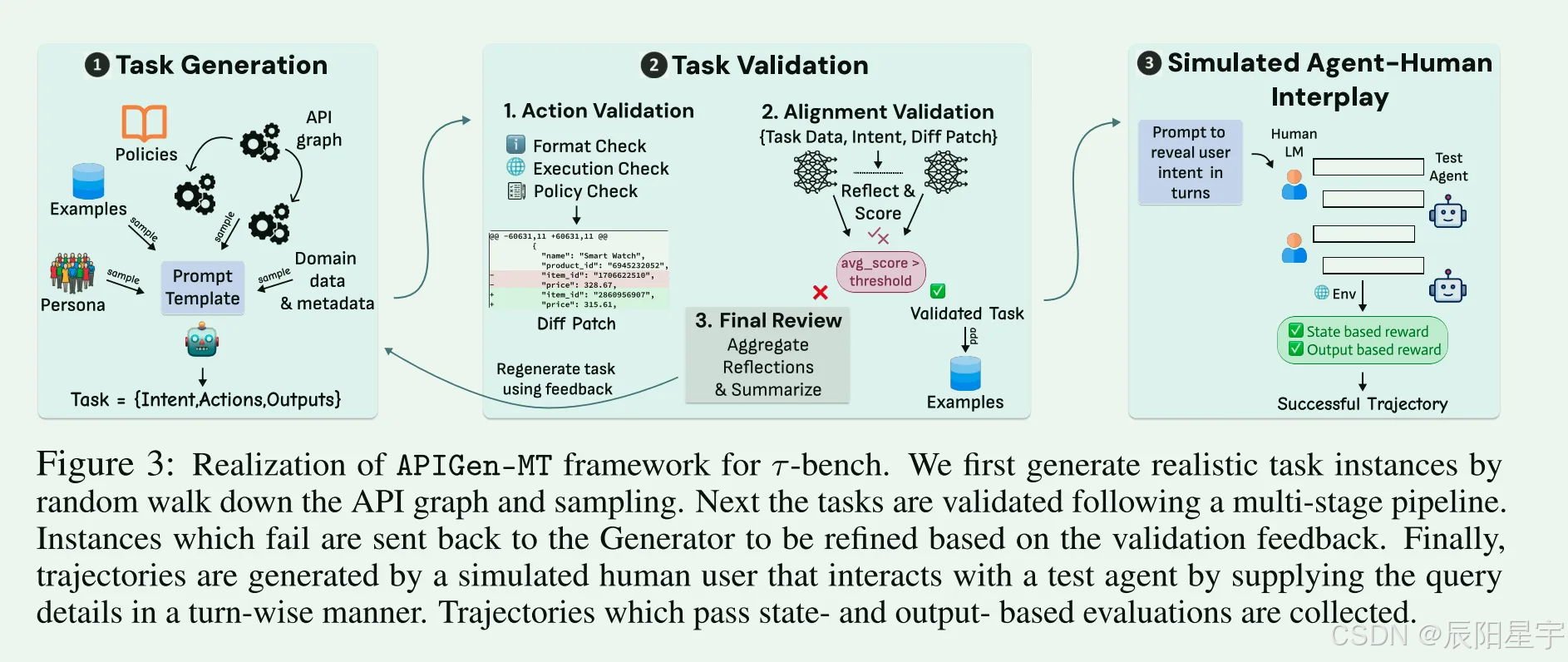
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
论文:https://arxiv.org/abs/2406.18518
代码:[https://huggingface.co/datasets/Salesforce/APIGen-MT-5k
https://huggingface.co/datasets/minpeter/xlam-function-calling-60k-parsed](https://huggingface.co/datasets/Salesforce/APIGen-MT-5k
https://huggingface.co/datasets/minpeter/xlam-function-calling-60k-parsed)
简介:函数调用智能体模型的进步需要多样化、可靠和高质量的数据集。本文介绍了APIGen,这是一种自动化数据生成管道,旨在为函数调用应用程序合成可验证的高质量数据集。我们利用 APIGen 收集 21 个不同类别的 3,673 个可执行 API,以可扩展和结构化的方式生成多样化的函数调用数据集。我们数据集中的每个数据都经过格式检查、实际函数执行和语义验证三个分层阶段进行验证,确保其可靠性和正确性。我们证明,使用我们精选的数据集训练的模型,即使只有 7B 参数,也可以在伯克利函数调用基准测试中实现最先进的性能,优于多个 GPT-4 模型。此外,我们的 1B 模型实现了卓越的性能,超越了 GPT-3.5-Turbo 和 Claude-3 Haiku。我们发布了一个包含 60,000 个高质量条目的数据集,旨在推进函数调用代理域领域。
When2Call: When (not) to Call Tools
论文:https://arxiv.org/abs/2504.18851
代码:https://github.com/NVIDIA/When2Call?utm_source=catalyzex.com
简介:聚焦“什么时候应该(或不应该)调用工具”的判断能力评测基准。包括工具是否调用、是否应追问、是否应拒绝的训练和评估数据。支持多选式训练方式,并提供评测脚本。核心亮点:使用 Self-Instruct 方法合成工具调用数据,包含大量工具实例与调用示例,强调复杂场景(如嵌套、多工具联合调用)。数据场景:既提供工具说明,也有工具调用实例,并设计了严格的格式与评测指标供训练和评估使用。用途:适用于 fine-tuning LLM 工具调用能力,尤其在复杂工具链调用场景下表现良好。
Seal-Tools: Self-Instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark
论文:https://arxiv.org/abs/2405.08355
代码:https://huggingface.co/datasets/casey-martin/Seal-Tools
简介:核心亮点:使用 Self-Instruct 方法合成工具调用数据,包含大量工具实例与调用示例,强调复杂场景(如嵌套、多工具联合调用)。数据场景:既提供工具说明,也有工具调用实例,并设计了严格的格式与评测指标供训练和评估使用。用途:适用于 fine-tuning LLM 工具调用能力,尤其在复杂工具链调用场景下表现良好。
FunReason: Enhancing Large Language Models’ Function Calling via Self-Refinement Multiscale Loss and Automated Data Refinement
论文:https://arxiv.org/abs/2505.20192
代码:https://github.com/inclusionAI/AgenticLearning
简介:来自“FunReason”框架的数据集,约 60,000 条样本,结合 Chain-of-Thought(CoT)推理与精确函数调用;使用自动数据精炼流程与多尺度损失优化训练样本质量。框架及数据集开源。
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
论文:https://arxiv.org/abs/2403.12881
代码:https://huggingface.co/datasets/internlm/Agent-FLAN
简介:复合数据集:整合了 AgentInstruct、ToolBench、ShareGPT 等,在“工具使用 + 函数调用”上下文中构建 34,400 条训练样本。用途:用于训练具备工具调用、指令理解及对话能力的模型。引用来源:GitHub 项目中列出该数据集的基本信息。
ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools
论文:https://arxiv.org/abs/2508.03284
代码:https://huggingface.co/datasets/DietCoke4671/ToolVQA
简介:将外部工具集成到大型基础模型 (LFM) 中已成为增强其解决问题的能力的一种有前途的方法。虽然现有研究在工具增强视觉问答 (VQA) 方面表现出色,但最近的基准测试显示,在现实世界的工具使用熟练程度方面存在显着差距,特别是在需要多步骤推理的功能多样化多模态环境中。在这项工作中,我们引入了 ToolVQA,这是一个包含 23K 实例的大规模多模态数据集,旨在弥合这一差距。与以前依赖合成场景和简化查询的数据集不同,ToolVQA 具有真实世界的视觉上下文和具有挑战性的隐式多步骤推理任务,更好地与真实用户交互保持一致。为了构建这个数据集,我们提出了 ToolEngine,这是一种新颖的数据生成管道,它采用深度优先搜索 (DFS) 和动态上下文示例匹配机制来模拟类人工具使用推理。ToolVQA 包含 7 个不同任务域的 10 个多模态工具,每个实例的平均推理长度为 2.78 个推理步骤。ToolVQA 上微调的 7B LFM 不仅在我们的测试集上取得了令人印象深刻的性能,而且在各种分布式外 (OOD) 数据集上超越了大型闭源模型 GPT-3.5-turbo,在现实世界的工具使用场景中表现出很强的通用性。
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
论文:https://arxiv.org/abs/2502.06589
代码:
简介:发布背景:作为新版训练语料库,专为提升语言模型的 API 函数调用、推理规划与环境反馈对齐能力而设计。内容规模:约 1030 亿 token 级别 agent 特定数据,涵盖 76,537 个 API;包括工具文档与函数调用轨迹,支持连续预训练。用途:用于提升 LLM 的工具调用能力、内在推理与规划能力,增强泛化到新任务的能力。
ADC: Enhancing Function Calling Via Adversarial Datasets and Code Line-Level Feedback
论文:https://arxiv.org/abs/2412.17754
代码:
简介:这篇文章主要介绍了一个工具集,该工具集旨在帮助用户更高效地处理和分析数据。工具集包含多种功能,如数据清洗、数据可视化、统计分析等,能够满足不同用户的需求。文章详细介绍了每个工具的功能和使用方法,并提供了实际应用的案例,帮助用户更好地理解和掌握这些工具。
工具集的核心功能:
- 数据清洗:帮助用户清理和整理数据,去除重复值、处理缺失值等。
- 数据可视化:提供多种图表类型,如柱状图、折线图、饼图等,帮助用户直观地展示数据。
- 统计分析:包括描述性统计、假设检验、回归分析等,帮助用户深入分析数据。
- 自动化处理:支持自动化脚本,减少重复性工作,提高效率。
FinAgentBench: A Benchmark Dataset for Agentic Retrieval in Financial Question Answering
论文:https://arxiv.org/abs/2508.14052
代码:
简介:准确的信息检索 (IR) 在金融领域至关重要,投资者必须从大量文档中识别相关信息。传统的 IR 方法——无论是稀疏的还是密集的——往往在检索准确性方面存在不足,因为它不仅需要捕获语义相似性,还需要对文档结构和特定领域的知识进行细粒度推理。大型语言模型 (LLM) 的最新进展为多步推理检索开辟了新的机会,其中模型通过迭代推理对段落进行排名,确定哪些信息与给定查询最相关。然而,金融领域还没有评估此类能力的基准。为了解决这一差距,我们推出了 FinAgentBench,这是第一个评估金融领域多步推理检索的大规模基准——我们称之为代理检索的设置。该基准由 3,429 个关于 S&P-100 上市公司的专家注释示例组成,评估 LLM 代理是否能够 (1) 识别候选者中最相关的文档类型,以及 (2) 查明所选文档中的关键段落。我们的评估框架明确地将这两个推理步骤分开,以解决上下文限制。这种设计能够为理解金融中以检索为中心的 LLM 行为提供定量基础。我们评估了一套最先进的模型,并进一步证明了有针对性的微调如何显着提高代理检索性能。我们的基准为研究以检索为中心的 LLM 行为在复杂的、特定领域的金融任务中提供了基础。我们将在论文被接受后公开发布数据集,并计划扩展和共享整个标准普尔 500 强及以后的数据集。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)