让大模型“听话”的PPO强化学习:从ChatGPT原理到你的第一个微调实验
区正在探索更优方案,例如DPO等直接偏好优化算法,试图绕过复杂的强化学习过程。但无论如何,PPO作为大模型对齐技术的开拓者和现阶段事实上的标准,其思想将持续影响未来。
各位好,我是你们的技术朋友maoku。今天,我们来拆解一个让ChatGPT从“知识库”蜕变为“智能助手”的核心魔法——PPO强化学习微调。它并不遥远,看完本文,你不仅能懂,甚至能亲手尝试。
引言:从“有知识”到“有智慧”的关键一跃
你是否有过这样的疑惑:一个经过海量数据预训练和指令微调(SFT)的大模型,明明“学识渊博”,为何有时答非所问、废话连篇,甚至生成有害内容?
SFT如同填鸭式教育,它能教会模型遵循指令的格式,却无法教会它“分寸感”、“价值观”和“用户体验”。如何让模型生成的内容不仅正确,而且有用、诚实、无害?这需要引入更高维度的训练范式——强化学习(RL)。
想象模型是一个实习生(智能体),它每说一句话(动作),都需要收到来自老板(环境)的反馈(奖励)。通过不断试错,它学习如何说话才能让老板最满意。近端策略优化(PPO),正是目前最稳定、最有效的“实习生培训算法”。
从引爆全球的ChatGPT,到开源社区百花齐放的LLaMA衍生模型,PPO都是其实现“人类对齐”、提升对话质量与安全性的核心技术引擎。下表展示了它的广泛应用:
| 模型名称 | 核心目标 | PPO扮演的角色 | 关键成果 |
|---|---|---|---|
| ChatGPT | 优化对话质量,使其更符合人类偏好。 | 基于人类反馈强化学习(RLHF)的核心算法,利用奖励模型指导微调。 | 实现了流畅、连贯、有用的对话能力,成为现象级应用。 |
| InstructGPT | 使模型生成更“有用、诚实、无害”的文本。 | ChatGPT的前身,同样采用PPO进行RLHF微调,验证了该范式的有效性。 | 相比GPT-3,在指令遵循和安全性上显著提升。 |
| FLAN-T5 | 降低生成内容的毒性,提升安全性。 | 结合专门的“毒性奖励模型”,用PPO引导模型避免生成有害言论。 | 有效减少了模型输出的偏见和仇恨言论。 |
| 开源模型 (如Vicuna) | 优化开源模型的对话质量和相关性。 | 社区使用PPO,结合自定义奖励模型对LLaMA等基础模型进行微调。 | 催生了大量高性能开源对话模型,推动生态繁荣。 |
第一部分:技术原理 —— 拆解PPO微调的“四大天王”
与其钻研复杂公式,不如先理解PPO微调中四个核心角色的精妙协作。这是一个经典的“RLHF-PPO”架构。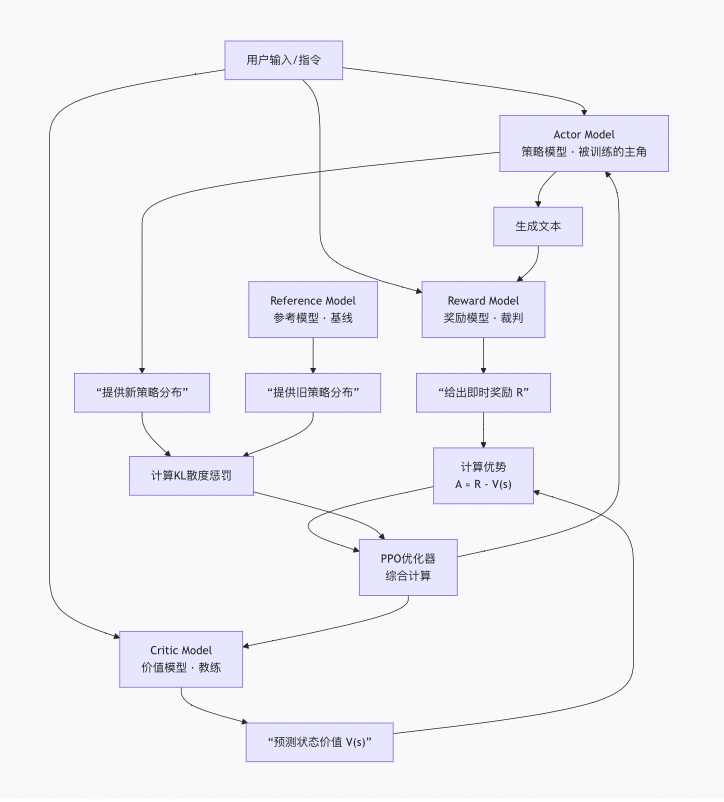
角色一:演员(Actor Model)
- 身份:我们要微调的目标大模型本身。
- 职责:根据用户的输入(剧本/指令),现场发挥,生成回复(表演)。
- 目标:通过学习,让自己的“表演”赢得更高的“票房”(奖励)。
角色二:裁判(Reward Model)
- 身份:一个独立训练的“人类偏好评估器”。
- 职责:对演员生成的每一段“表演”(文本)进行打分。分数高低代表该回复是否符合人类在有用性、真实性、无害性等方面的偏好。
- 特点:其参数在PPO训练中被冻结,是稳定不变的评分标准。
角色三:教练(Critic Model)
- 身份:一个策略价值评估者。
- 职责:它不直接评判表演好坏,而是预测:从当前这个对话状态开始,让演员按现在的水平演下去,整场戏预计能获得多少总奖励。这个预测值叫 “状态价值 V(s)”。
- 妙用:用裁判给的即时分(R) 减去教练的预测分(V(s)),就得到 “优势(Advantage)A”。如果A>0,说明这次表演超常发挥,值得加强;如果A<0,说明发挥失常,需要调整。这比只看单次得分更聪明、更稳定。
角色四:基线演员(Reference Model)
- 身份:演员的一个参数冻结的“旧版本”(通常是SFT后的模型)。
- 职责:代表演员原有的、安全的表演风格和语言能力。
- 核心作用:防止“奖励黑客”和“遗忘”。PPO训练时会计算当前演员和基线演员在表演风格(输出词的概率分布)上的差异(KL散度),并将此作为惩罚项。这意味着,演员在追求高奖励的同时,不能偏离自己原来的基本功太远,从而避免了为刷分而输出乱码或忘记原有知识。
一句话比喻:网球训练场
- 演员(Actor):正在训练的网球选手小吴,他想提高水平。
- 裁判(Reward):场边裁判,对小吴的每一次击球(回球质量、落点)给出即时分数。
- 教练(Critic):资深教练,他不仅看这一球,还预测小吴按当前打法,整场比赛的预期得分。
- 基线(Reference):小吴的训练用发球机/标准动作录像,代表他正确、规范的基础动作。
训练过程就是:小吴打一球 -> 裁判和教练分别给反馈 -> 系统综合“优势(这球比平均水平好多少)”和“动作变形度(和标准动作差多少)” -> 对小吴的肌肉记忆进行小幅、安全的调整。如此循环,水平稳步提升!
第二部分:实践步骤 —— 启动你的第一个PPO微调项目
理解了“四大天王”,我们来实战。这里以使用LLaMA-Factory这一优秀开源库为例,因为它极大简化了流程。
步骤一:环境与数据准备
- 环境:准备一个具有足够GPU内存(如至少24GB)的环境。云服务器(如AutoDL)是不错的选择。
- 基座模型(Actor初始化):选择一个已经过指令微调(Instruct-tuned) 的模型作为起点,例如
Qwen2.5-7B-Instruct或Llama-3-8B-Instruct。这比从纯预训练模型开始要高效得多。 - 奖励模型:这是关键。
- 选项A(推荐给初学者):直接使用社区训练好的奖励模型,例如
OpenAssistant/reward-model-deberta-v3-large-v2。 - 选项B(高阶):自己收集人类偏好数据,训练一个专属奖励模型。
- 选项A(推荐给初学者):直接使用社区训练好的奖励模型,例如
- 提示词数据:准备一个JSON文件,包含一系列指令或问题,用作训练时模拟的用户输入。例如:
json
[{"instruction": "解释什么是人工智能"}, {"instruction": "写一首关于春天的五言绝句"}, ...]
步骤二:关键配置详解
在LLaMA-Factory的配置文件中,以下参数至关重要:
yaml
# 模型设置 model_name_or_path: “Qwen2.5-7B-Instruct“ # Actor和Reference的起点 reward_model: “OpenAssistant/reward-model-deberta-v3-large-v2“ # 裁判模型 # 训练设置 stage: “ppo“ # 指明进行PPO训练 training_type: “full“ # 全参数微调,效果通常更好但更耗资源 # PPO核心参数 learning_rate: 1.0e-6 # PPO学习率通常非常小,防止更新过大 batch_size: 8 # 根据你的GPU调整 ppo_epochs: 4 # 每次采样数据后,内部优化的轮数 kl_penalty: “full“ # 启用完整的KL散度惩罚 # 资源相关 max_samples: 128 # 用于PPO训练的提示词数量,可从少开始关于奖励模型类型 (reward_model_type) 的重要提示:
- 如果你使用的是独立的、完整的大模型作为奖励模型(如
Qwen2.5-7B-RM),则上述配置即可。 - 如果你的奖励模型是通过 LoRA 微调得到的(即一个“小插件”),则需要额外指定LoRA权重路径,并将相关设置改为
lora。这能节省大量显存,因为**不需要同时加载多个完整大https://www.llamafactory.online/register?promoteID=undefined模型**。
步骤三:启动训练与监控
运行启动命令后,观察日志。健康的训练信号包括:
- 平均奖励(Reward):总体呈缓慢上升趋势。
- KL散度(KL Divergence):维持在一个相对较低且稳定的范围(例如3-10之间)。持续快速上升是危险信号。
- 优势(Advantage):均值在0附近波动。
对于想绕过复杂环境配置、快速验证想法的朋友,可以关注在线平台【LLaMA-Factory Online】。它提供了开箱即用的可视化界面和算力,让你能像搭积木一样配置PPO实验,大幅降低入门门槛,是初学者体验和快速原型验证的利器。
第三部分:效果评估 —— 你的模型真的变“聪明”了吗?
训练结束,如何检验成果?需要定量与定性相结合。
1. 定量评估:看数据说话
- 奖励得分:在一组未参与训练的指令上,分别让微调前(SFT)和微调后(PPO)的模型生成回复,并用同一个奖励模型打分。PPO模型的平均奖励应有显著提升。
- KL散度:检查PPO模型与Reference模型在验证集上的平均KL散度。它应在可控范围内,证明模型没有“忘本”。
- 基础能力基准测试:跑一下MMLU、GSM8K等通用评测集,确保数学、常识等基础能力没有严重退化。
2. 定性评估(黄金标准):人工评测
这是最可靠的方法。请你自己或邀请他人进行盲测对比。
- 示例对比:
- 指令:“用生动有趣的方式,向一个10岁孩子解释黑洞。”
- SFT模型回复:“黑洞是时空曲率大到光都无法逃脱的天体。其边界称为事件视界...”
- PPO微调后回复:“想象一下,太空里有一块超级超级重的‘橡皮泥’,它把周围的‘太空布’压出了一个深不见底的洞,连跑得最快的光娃娃掉进去都爬不出来,这个神秘的洞就是黑洞!”
- 评测维度:哪个回复更有用、更易懂、更生动、更安全?PPO的目标正是在这些主观但关键的维度上胜出。
总结与展望
让我们回顾一下核心要点:
- PPO微调的本质:是一个带约束的优化过程。它用奖励模型作为“指挥棒”,用KL散度作为“安全带”,引导大模型朝着符合人类偏好的方向进化。
- 成功的标志:模型在获得更高奖励(更符合偏好)的同时,其输出分布与原始可靠模型(Reference)不过度偏离。
- 核心价值:它解决了SFT无法处理的复杂、多目标权衡问题(如“有用”vs“无害”),是打造“善解人意”AI的关键步骤。
当前挑战与未来方向
尽管PPO成就斐然,但挑战依旧:
- 奖励模型的瓶颈:“裁判”的水平决定了“演员”的上限。如何训练出更精准、更全面的奖励模型仍是核心难题。
- 高成本与不稳定:同时加载和训练多个大模型,对算力要求极高,且超参数敏感,调试不易。
- 价值观的“单一化”风险:一个奖励模型可能只代表一种群体偏好,如何实现包容性、可定制的对齐是未来重点。
社区正在探索更优方案,例如DPO等直接偏好优化算法,试图绕过复杂的强化学习过程。但无论如何,PPO作为大模型对齐技术的开拓者和现阶段事实上的标准,其思想将持续影响未来。
希望这篇文章能帮你拨开PPO的迷雾,不仅理解ChatGPT何以智能,更能亲手开启你的大模型“调教”之旅。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)