Agent Memory(上):记忆的形态、功能与代表性路径
在本篇中,我们从宏观结构到具体机制,对 Agent Memory 的基础框架进行了系统化梳理。如何在有限上下文中维持有效的短期状态表示;如何在跨会话场景中构建可检索、可复用的长期知识链路。从这些方案中可以看到,Agent Memory 的关键不在于“存得更多”,而在于选择性保留、结构化组织、面向任务的可复用性。REFERENCE[1] [2](2025|NUS&人大&复旦&北大,Agent,L
转载自:知乎【浦算DeepLink】Agent Memory(上):记忆的形态、功能与代表性路径
作者:SPC from AISYS-Group@Shanghai AI Lab
TL;DR
随着 AI Agent 在复杂任务、长期交互和多步推理场景中的应用不断扩大,传统大语言模型无状态(Stateless) 的设计逐渐显露出局限性:它们无法跨会话积累经验,无法基于历史行为调整策略。
于是,一个核心能力被反复提到:智能体记忆(Agent Memory)。
Agent Memory通过将历史交互、环境反馈和任务进展等组织成可检索的内部表征,使智能体能够进行经验驱动的推理、持续优化策略和更深层次的语境理解。这种记忆不仅支持跨会话信息的保留,还能在后续交互中用于更准确的状态估计与预测性决策,体现出真正的有状态智能行为,而不是简单的上下文拼接。简单来说,Memory 让 Agent 不只是“即时反应”,而是基于过去的行动和结果持续改进决策。一个具备 Memory 的 Agent ≈ Prompt + 当前输入 + 历史可用信息。
本系列文章将分两步展开:
- 本篇系统性综述出发,梳理 Agent Memory 的形式、功能与生命周期。在明确整体框架之后,我们选取两个具有代表性的技术路径进行深入分析:QwenLong-L1.5 如何通过“工作记忆压缩”突破上下文长度限制;M3-Agent 如何形成和使用长期记忆。
- 下篇将围绕长期一致性与多轮任务保持,介绍当智能体需要持续执行任务、跨会话调度工具并在复杂环境中不断积累经验时,记忆系统如何才能既高效又稳健的有关工作。
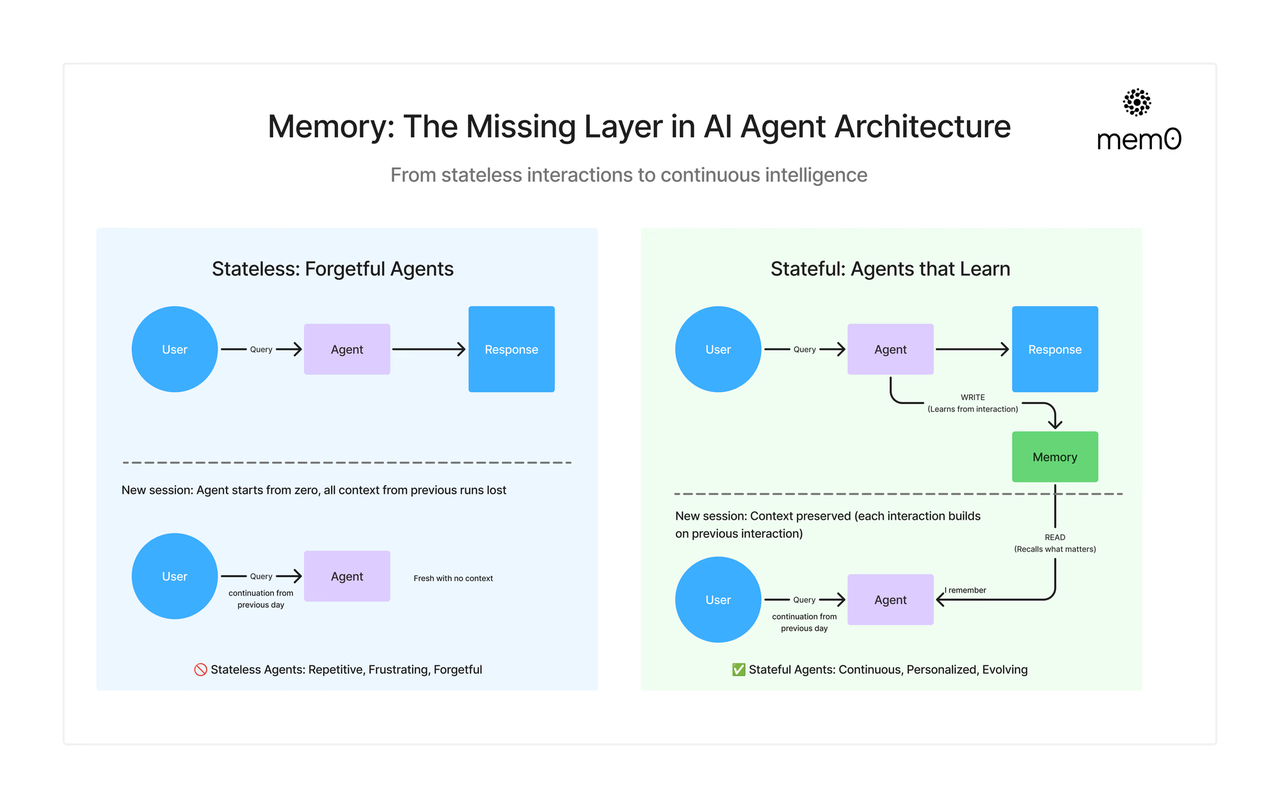
注:图片来源:https://mem0.ai/blog/memory-in-agents-what-why-and-how
一、Agent Memory的形式、功能和动态生命周期
新加坡国立大学、中国人民大学等机构在综述《Memory in the Age of AI Agents: A Survey》中,对 Agent Memory 给出了一个清晰的统一视角,回答了四个核心问题:
Agent Memory是什么?存在哪里?为什么需要?如何形成、演化和使用?
1. Agent Memory是什么
当基于大语言模型的智能体(LLM-based agent)与环境交互时,其瞬时观察 $$o_i^t$$ 往往不足以支持有效的决策。为了弥补这一点,智能体需要依赖来自以往交互的信息,这些信息既包括当前任务的历史,也包括先前完成任务中的经验。论文通过构建一个统一的智能体记忆系统(Agent memory system)来形式化这一能力,该系统以一个随时间演化的记忆状态表示智能体的累积信息。
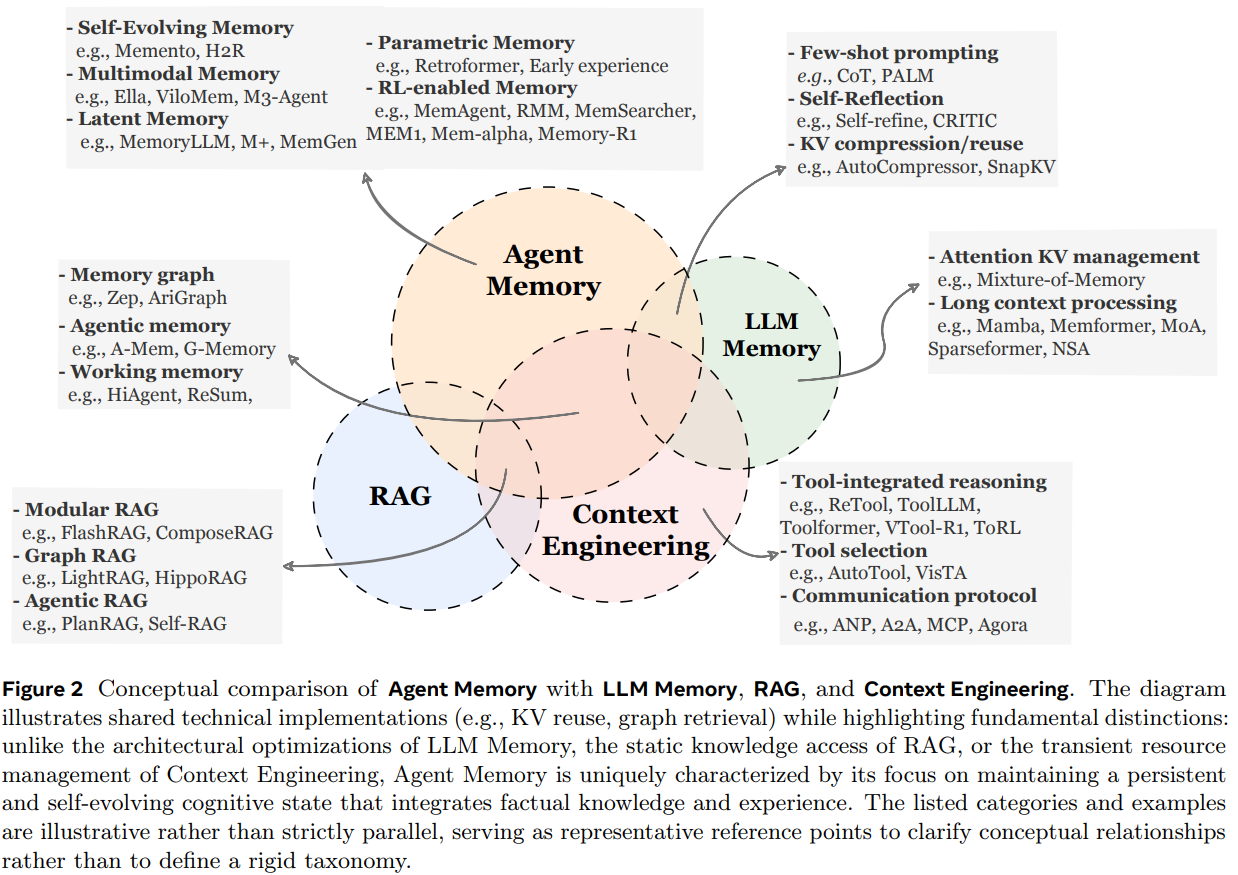
2. Memory的载体是什么?
在不同的智能体系统中,记忆并非通过单一的结构来实现。相反,针对不同的任务场景需要不同的存储形式,每种形式都有其自身的结构属性,从而使智能体在交互过程中积累信息并保持行为一致性。根据记忆的存储位置及其表征形式,Agent memory 通常有三种形式:
- Token级别的记忆:记忆以自然语言(文本)或离散符号的形式存储在外部数据库中。这是最常见、最易解释的形式。
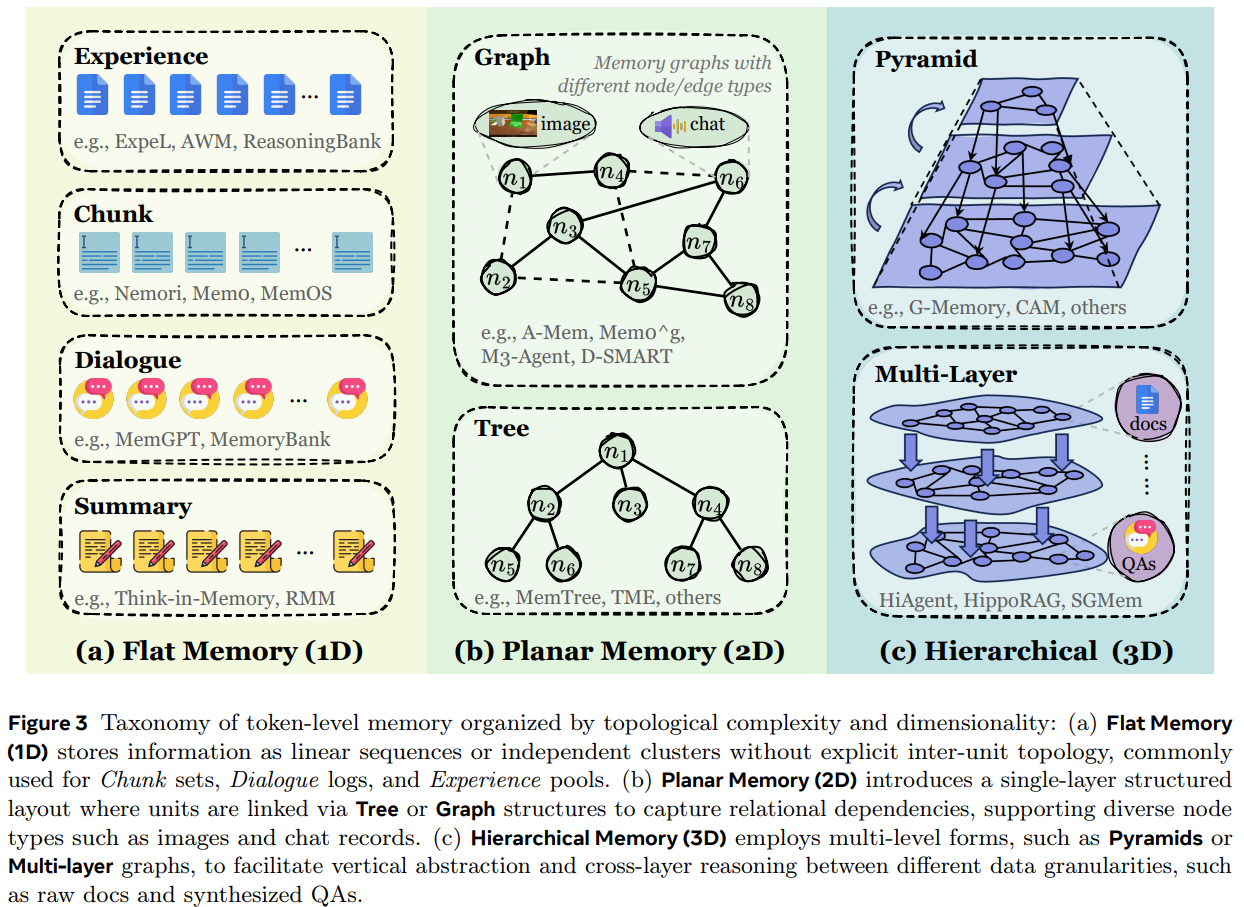
- 参数化记忆:将信息直接编码进模型参数中。例如:通过预训练、SFT、后训练修改模型参数,向模型注入知识;通过适配器、LoRA将知识存储在额外的参数模块。
- 潜在记忆:以隐式形式承载在模型内部表示中,例如 KV cache、激活值、隐藏状态(hidden states)以及latent embeddings等。
3. Agent有Memory后可以实现什么功能?
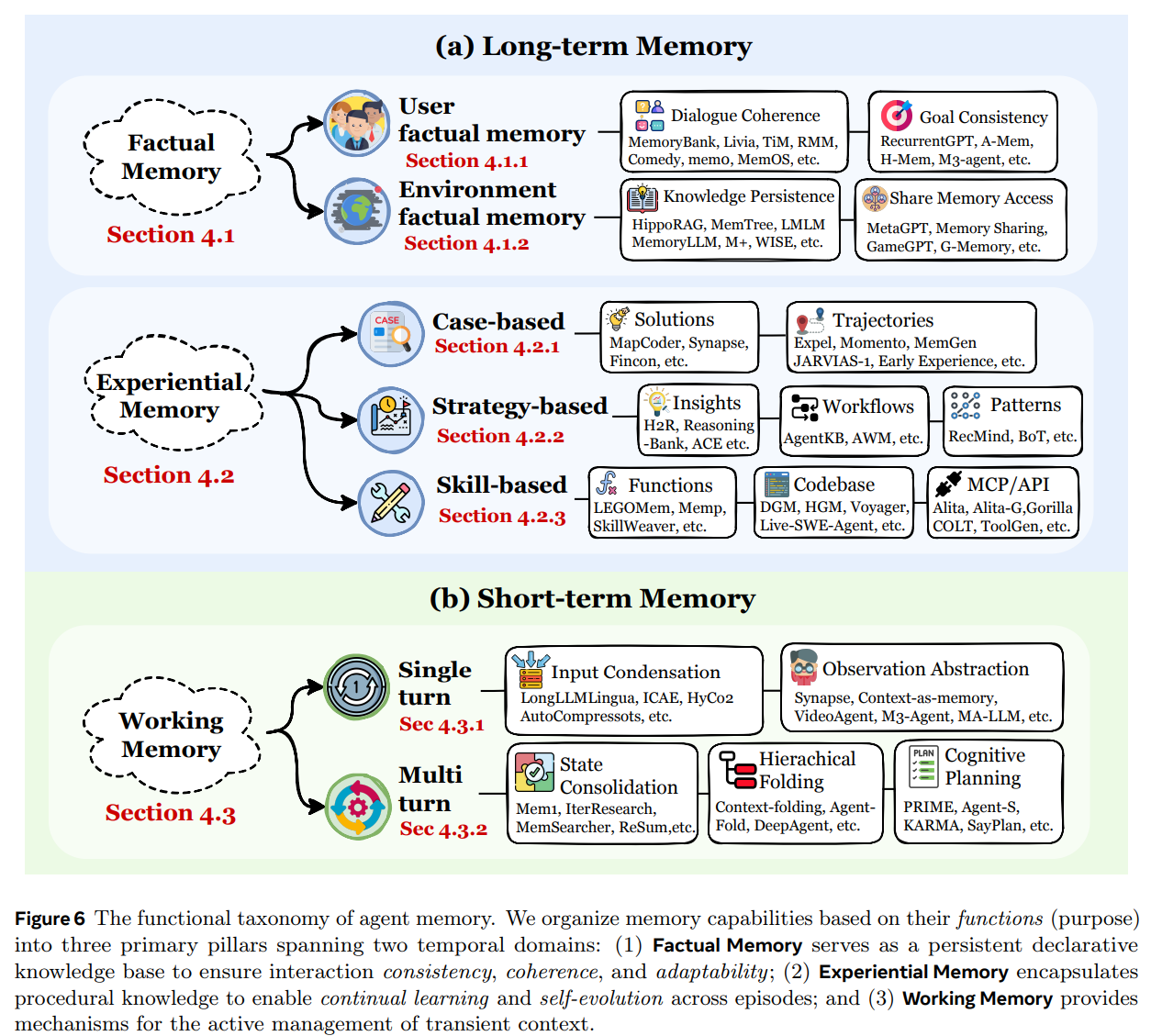
记忆的功能远不止 “记住过去”。在时间层面,论文将记忆分为两个时间类别:(1)长期记忆(Long-term Memory)为跨会话(cross-session)的持久存储,用于积累和保存知识。例如,记忆用户偏好,记忆任务的完成进度等。(2)短期记忆(Short-term Memory)作为会话内(in-session)的临时工作空间,用于支持当前的推理过程。会话结束后,短期记忆就会丢失。
这种划分进一步细化为三个主要的功能支柱,构成了分析的框架。论文根据记忆功能(目的)将其分为三大支柱:
- 事实记忆(Factual Memory)
智能体的陈述性知识库,通过回忆显式事实、用户偏好以及环境状态来确保行为的一致性、连贯性与适应性。该记忆系统回答的问题是:“智能体知道什么?”
- 经验记忆(Experiential Memory)
智能体的过程性与策略性知识,通过对过往的行为轨迹、失败与成功进行抽象与总结而不断积累,以支持持续学习与自我演化。该记忆系统回答的问题是:“智能体如何改进自身?”
- 工作记忆(Working Memory)
智能体在单个任务或会话期间用于主动上下文管理的、容量受限且可动态控制的临时思考空间。该记忆系统回答的问题是:“智能体当前正在思考什么?”
4. Memory如何运作并演化?
动态机制关注记忆系统的动态生命周期,即记忆如何形成、更新(演化)和被使用(检索)。这是 Agent 记忆区别于静态数据库的核心。记忆的生命周期包括三个过程:
- 记忆形成(Memory Formation)
该过程将原始经验转化为信息密集型知识。记忆系统并非被动地记录全部交互历史,而是有选择地识别具有长期价值的信息,例如成功的推理模式或环境约束条件。这一部分回答的问题是:“如何抽取记忆”
- 记忆演化(Memory Evolution)
该过程描述了记忆系统的动态演进机制,重点在于将新形成的记忆与已有记忆库进行整合。通过诸如相关记忆的整合、冲突消解以及自适应裁剪等机制,系统能够在不断变化的环境中保持记忆的泛化性、连贯性与高效性。这一部分回答的问题是:“如何优化记忆”
- 记忆检索(Memory Retrieval)
该过程决定了记忆被取用的质量。在给定上下文条件下,系统会构建面向任务的查询(task-aware query),并通过检索策略来访问合适的记忆。检索得到的记忆在语义上与任务相关,且在功能上对推理至关重要。这一部分回答的问题是:“如何使用记忆”
二、QwenLong-L1.5 —— 工作记忆的压缩
QwenLong-L1.5 通过后训练阶段的系统性优化,提供了一套完整的长上下文推理解决方案,并且从数据、算法和架构三侧入手,详细介绍了如何从“能读长文”进化到“能基于长文进行复杂推理”的工程细节。该方案旨在解决的问题是:当前长文本模型在后训练阶段缺乏高质量数据、RL 训练不稳定以及物理上下文窗口限制(没数据、训不稳、无限长)等。
1. [数据侧] 长上下文数据的合成
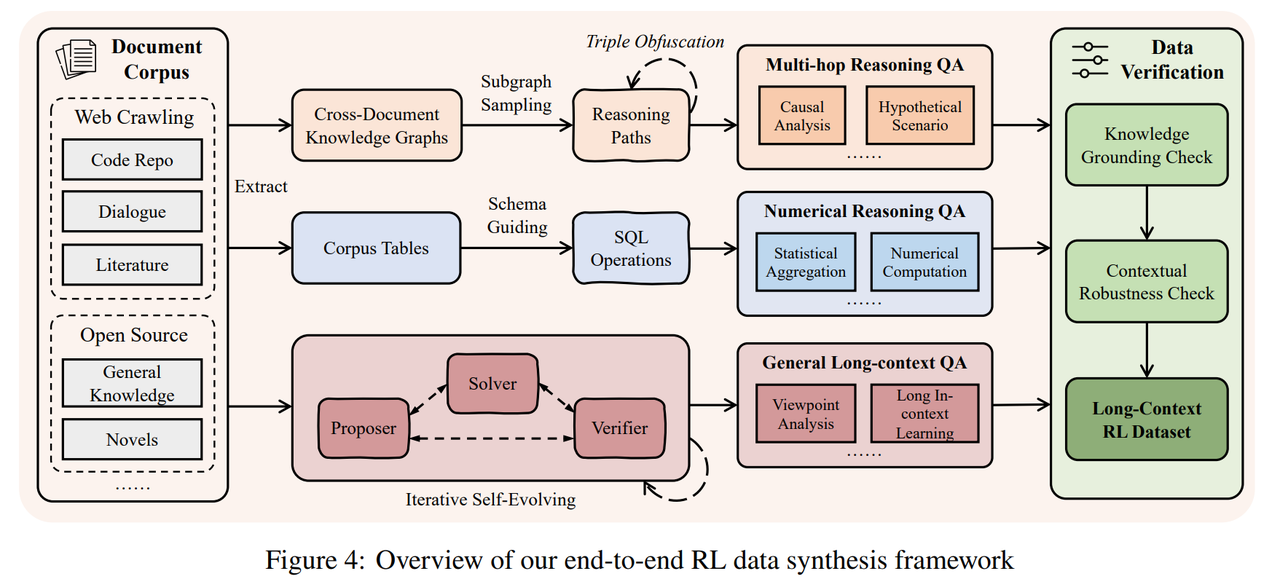
QwenLong-L1.5 提供了一套能够合成需要多跳推理和全局信息聚合的高质量合成数据流水线。合成数据包括以下三种:
- 多跳推理问答(In-depth Multi-hop Reasoning QA)
这一方法先把文档中的信息抽取成知识图谱,再从图中采样跨多个文档的复杂推理路径。通过刻意拉开信息分布、模糊实体表述,让问题必须“多步推理”才能回答。最后基于这些路径生成多跳问题,并严格控制难度与质量。
2. 跨文档数值推理问答(Corpus-level Numerical Reasoning QA)
该方法把多个文档中的表格和统计信息统一整理成结构化大表。再用大模型把自然语言问题转成 SQL,对表格执行计算得到标准答案。最终生成需要跨文档统计、计算和时间推理的长上下文数值问答。
3. 通用长上下文推理(General Long-Context Reasoning)
这里使用一个多智能体协作框架自动生成难度逐步提升的问题。一个智能体出题,一个解题,一个负责验证对错,通过反复迭代不断提高问题复杂度。最终得到高质量、难度递进的长上下文推理数据。
2. [算法侧] 长上下文的稳定强化学习算法
将短文 RL 方法应用到长文上会导致训练极不稳定,为了解决长上下文强化学习过程中普遍存在的训练不稳定性问题,QwenLong-L1.5 使用 GRPO 作为基础算法,进行了一些改进。
引入了任务均衡采样与特定任务优势估计,以缓解奖励偏置;同时提出了自适应熵控制策略优化(Adaptive Entropy-Controlled Policy Optimization,AEPO),用于动态调节探索—利用之间的权衡。这些创新使模型能够在序列长度逐步增长的情况下实现稳定训练。
相较于PPO算法,GRPO 省去了 Value Network,直接通过 Group 内的相对优势来优化,目标是最大化期望奖励。GRPO 对于每个输入 采样一组
个候选回答
,并通过组内奖励的标准化来估计优势。简化的目标函数为:
2.1 算法改进1: 任务均衡采样 与 任务感知优势估计
2.1.1 任务均衡采样
长上下文数据类型多、分布差异大,如果随机采样,容易导致每个 batch 中任务分布不均,训练不稳定。在训练前先按模型表现(pass@k)对不同来源数据分桶并均衡抽样;训练中则强制每个 batch 从不同任务类型(选择题、多跳推理、阅读理解、对话记忆、数值计算)中等量采样,以保持训练分布稳定。
2.1.2 任务特定优势估计Task-Specific Advantage Estimation:
由于不同任务的奖励分布差异很大,直接用 batch 级或 group 级归一化会引入噪声和偏差。作者改为按任务分别计算奖励的标准差来估计优势函数,从而避免高密度奖励任务(奖励分数在0-1之间连续变化)和稀疏奖励(奖励分数在0-1之间是离散的)任务相互干扰,对各类任务给出更为精确的估计。计算优势时,分母的标准差不再基于整个 Group,而是基于当前 Batch 内同一任务类型的所有样本计算
2.2 算法改进2: 基于熵负梯度裁剪
在强化学习中,熵(Entropy)是用于度量策略随机性与不确定性的核心概念,主要用于控制探索(exploration)与利用(exploitation)之间的平衡。高熵:策略更随机;低熵:策略更确定。
长上下文任务需要先在大量文本中定位关键信息再进行推理,这使得正确和错误答案往往共享大量相同的推理步骤,二者在文本上高度相似。结果是:错误答案中包含了很多“看起来正确”的步骤,导致强化学习中奖励归因困难,训练容易不稳定。
在训练时,高熵(不确定性高)的 token 往往产生更大的梯度,这些梯度主要来自错误回答,会显著放大更新噪声。同时,高熵 token 也代表模型在探索推理路径,若惩罚过重会抑制模型自我纠错能力。
QwenLong-L1.5提出一种熵感知的负梯度裁剪策略:只对高熵的错误响应(或其中的高熵 token)屏蔽其梯度贡献,而保留低熵或正确部分的学习信号。该方法既能减少噪声、稳定训练,又能保留模型的探索与修正能力。在目标函数中添加了指示函数:
指示函数的作用是过滤梯度,当优势
(说明是负样本), 且token级高熵
或 序列级高熵
时,将梯度置零,否则为 1。选择不惩罚这些token,以保护探索能力。
2.3 算法改进3: 自适应熵控制策略优化AEPO
QwenLong-L1.5 发现“高熵 + 负优势”是长上下文强化学习训练不稳定的主要根源,于是提出了 AEPO。该方法在训练过程中实时监控策略的整体熵水平,并据此动态决定是否屏蔽负样本的梯度,AEPO 算法定义了 batch 级熵,设定目标熵范围:
当熵过高时,只保留正样本进行更新,以降低随机性;当熵过低时,再重新引入负样本,防止探索能力塌缩。通过这种自适应的熵调控机制,AEPO在保持探索与利用平衡的同时显著提升了训练稳定性和最终性能。
3. [工作记忆压缩] 面向超长上下文的记忆增强架构
即便扩展上下文窗口也无法容纳任意长度的序列,QwenLong-L1.5 设计了记忆管理框架,并结合多阶段融合的强化学习训练,将单次推理与基于记忆的迭代处理无缝整合,从而支持超过 400 万 token 的超长任务。通过多阶段融合训练,使模型能够处理超过 4M token 的超长任务。
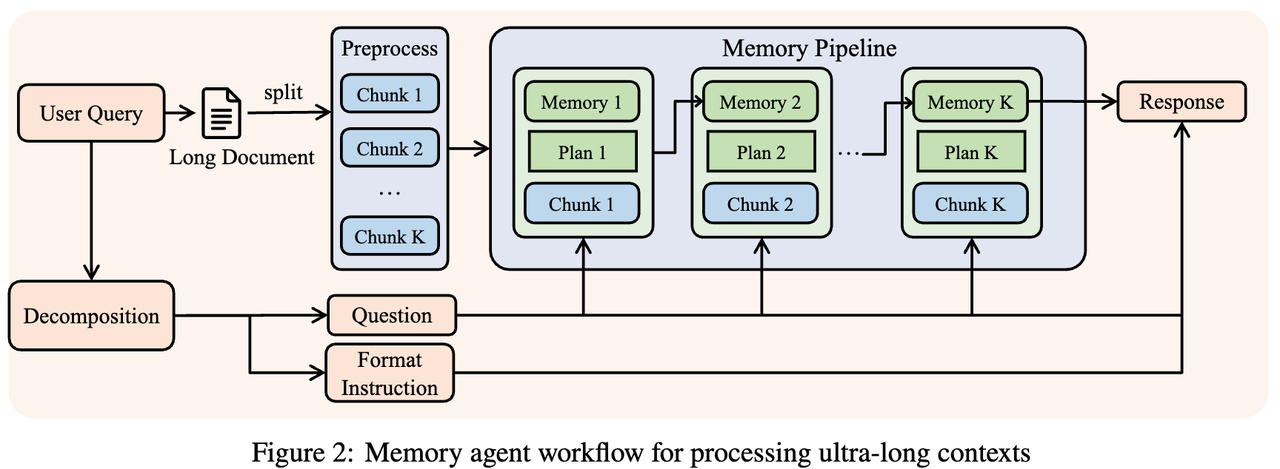
给定一个长上下文和一个query,Memory Agent的工作流程为:
三、M3-Agent —— 长期记忆的形成与检索
研究提出的M3-Agent 是一个多模态智能体框架,尝试解决Agent 如何真正拥有可用的长期记忆的问题。M3-Agent 的核心架构由一个多模态大语言模型(MLLM)和一个外部的长期记忆模块构成。其运作通过两个并行且持续进行的过程实现:记忆化 (Memorization) 和控制 (Control) 。
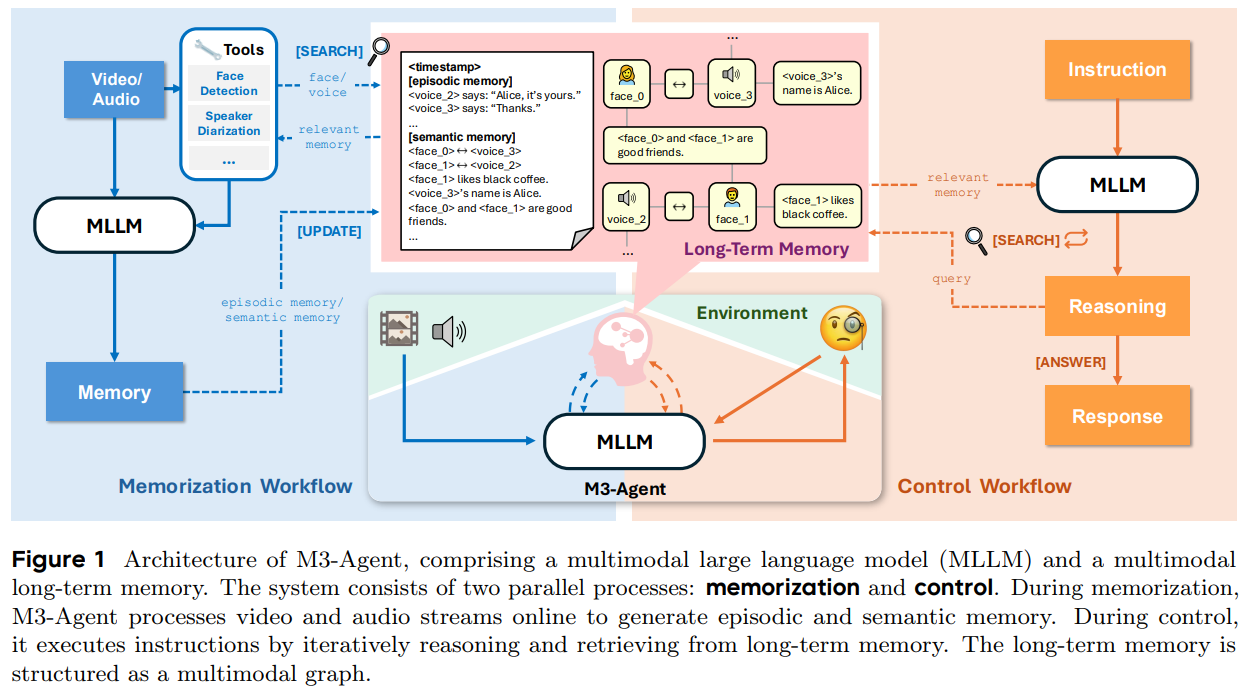
1. 记忆化过程 : 长期记忆的形成
记忆化过程是将智能体感知到的多模态信息转化为结构化的长期记忆。M3-Agent将记忆分为两种类型:
- 情景记忆 (Episodic Memory) :记录在特定时间、特定场景下发生的具体事件。它关注「What happened?」,包含了丰富的上下文细节,如人物的动作、外貌、对话内容以及环境描述。
- 语义记忆 (Semantic Memory) :从一个或多个情景中提炼出的、不依赖于特定上下文的通用知识、事实或规律。它关注「What does it mean?」。
以实体为中心的多模态记忆图谱 (Entity-centric Multimodal Memory Graph) 是 M3-Agent 解决实体一致性的方法,每个节点代表一个记忆项。所谓实体一致性,是指智能体在处理无限长的多模态数据流时,能够稳定地识别、追踪并关联同一个核心实体(人、物等),无论其在不同时间、不同模态(视觉、听觉)下如何呈现。
- 实体ID的建立:系统利用外部工具,如人脸识别和声纹识别模型,从视频流中提取出关键实体(主要是人)的生物特征。每个被识别的独立实体都会被分配一个 ID,例如
<face_1> 或 <voice_2>。 - 记忆的组织:无论是情景记忆还是语义记忆都会与相关的实体 ID 进行关联。例如,关于 Alice 的所有信息,包括她的外貌描述(与
<face_1> 关联)、她说的话(与 <voice_2> 关联)、她的行为、以及推断出的偏好,都会被链接到代表她的实体节点上。 - 跨模态关联:语义记忆的一个重要功能是建立跨模态实体间的等价关系。
M3-Agent 构建了一个可动态增长、内部一致、且支持多模态信息融合的知识图谱。论文选用 Qwen2.5-Omni-7b,一个支持视觉和音频输入的开源多模态模型,通过监督微调让模型学会生成高质量的情景记忆和语义记忆。
2. 控制过程:长期记忆的检索
当接收到外部指令时,控制过程被激活。该过程负责利用已有的长期记忆进行推理,并最终完成任务,它旨在解决推理动态性。推理动态性是指让智能体摆脱「一问一答」模式,学会动态的、多轮的推理策略,能够根据具体任务需求自主地、迭代地探索记忆库,逐步逼近最终答案。
智能体的两种核心行动:
-
[Search]:如果信息不足,模型会决定继续搜索。它会生成一个具体的查询语句(query),调用记忆库的搜索工具来获取更多相关信息。 -
[Answer]:如果模型认为信息已经充分,它会终止搜索循环,并生成最终的答案。
控制模型选用 Qwen3-32b作为基础模型,采用 DAPO 算法进行强化学习训练。RL 环境设置如下:
- 状态 (State) :当前的对话轨迹,包含问题和已经检索到的记忆。
- 行动 (Action) :生成包含
[Search] 或 [Answer] 指令的文本。 
DAPO 算法通过对比一组(group) rollout 轨迹的奖励,计算每个行动的优势(Advantage),并据此更新模型。
四、总结
在本篇中,我们从宏观结构到具体机制,对 Agent Memory 的基础框架进行了系统化梳理。无论是 QwenLong-L1.5 对工作记忆压缩,还是 M3-Agent 的长期记忆形成与检索,它们所代表的并非孤立技术,而是两类核心能力的集中体现:
- 如何在有限上下文中维持有效的短期状态表示;
- 如何在跨会话场景中构建可检索、可复用的长期知识链路。
从这些方案中可以看到,Agent Memory 的关键不在于“存得更多”,而在于选择性保留、结构化组织、面向任务的可复用性。
REFERENCE
[1] Memory in the Age of AI Agents: A Survey[2](2025|NUS&人大&复旦&北大,Agent,LLM,RAG,上下文,记忆形式/功能/动态)AI Agent时代的记忆:综述
[3] QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
[4] QwenLong-L1.5:长上下文推理的后训练优化
[5] QwenLong-L1.5:长上下文推理与记忆管理的后训练方案
[6] Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
[7] M3-Agent:为 AI 智能体构建「长期记忆」
如果你对 Agent Memory 有更多理解,或者在实际项目中有过相关实践和踩坑经验,欢迎在评论区交流,也欢迎补充你认为更合理的实现思路,共同讨论。
此外,DeepLink团队在小红书上新建了【DeepLink】账号,我们将会为大家分享核心技术的深度解析、AI 开放计算领域的行业动态研判,以及落地案例的细节拆解、技术踩坑经验。欢迎大家移步关注!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)