YOLO模型检测性能提升(无人机空中检测横幅)
(负样本+参数调整+预处理模型-缩放+引入新的模块机制)
(目前我只会这几种方法,后续学到了新的方法会更新博客)
1.数据集的好坏程度决定模型性能的上限,即使参数调整的再好,数据集质量太低,也会导致训练结果出现偏差。所以我们在选择数据集或者自己标注数据集时一定要注意:
标注准确性:确保边界框紧贴目标边缘
标签一致性:同一目标在不同图像中标注方式一致
剔除错误标注:删除明显的错误标注样本
数据增强要适当
2.可以适当添加负样本,降低误检率。
这里解释一下什么是负样本:负样本 = 没有目标的图片,负样本就是告诉模型:"这些地方没有横幅,别瞎猜!"
我们在没添加负样本时:
模型学习:横幅 → 横幅特征
结果:容易把相似的纹理/形状误判为横幅
添加负样本后:
模型学习:
1. 横幅 → 横幅特征
2. 非横幅 → 这不是横幅!
结果:减少误判,提高精确率
知道什么是负样本之后,该怎么收集负样本呢?
从这些地方找:
- 你的数据集环境:同一场景但没有横幅的图片
- 容易误检的区域:模型之前误检过的地方截图
- 相似纹理:与横幅颜色/纹理相似的背景(墙壁、海报栏、窗户)
- 负样本来源:
- 从视频中截取无横幅的帧
- 从网上找类似场景图片
负样本数量不宜过多,一千张图片有个最多100张的负样本就差不多了,太多了的话会让模型"畏手畏脚",连真正的目标也不敢检测。
找到图片之后,对负样本进行标注!!!,负样本也是需要标注的!我们在训练模型时每个图片都需要有对应的标签,只是负样本的标签是空白,但是也要有一个.txt的文件和图片对应。
然后分别将负样本图片和标注加入images-trian和labels-train中
(为了避免后续不想要负样本了,可以提前将没加入负样本的数据集备份一个)
添加负样本后,训练脚本不需要额外设置
下面是我在生成横幅检测模型时遇到的问题:
这是模型正在检测视频时的截图,可以看到目前还算正常
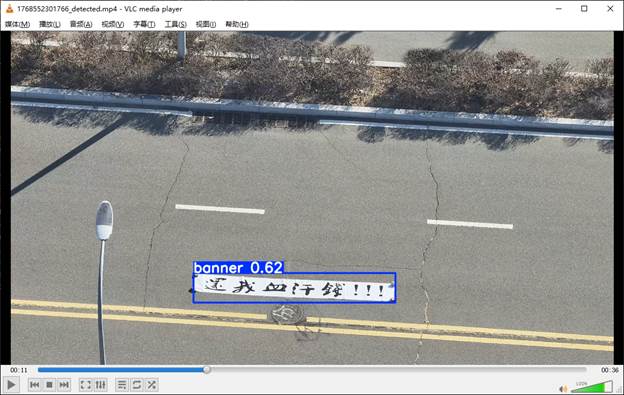
下面是无人机飞离横幅之后拍摄到跑道后,模型把红色的跑道误检成横幅
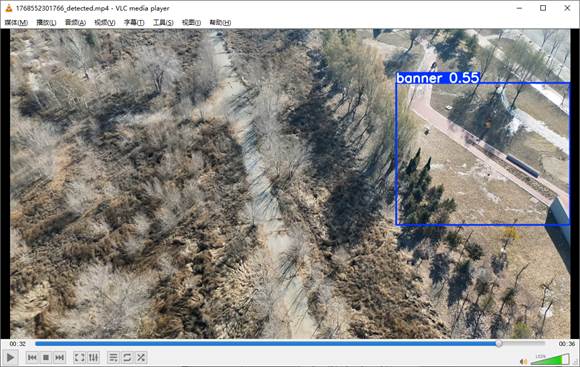
因为,数据集中的横幅大部分符合红色的长方形,所以导致模型误检,现在我们加入负样本,看看模型性能能不能得到提升。
在images中的train中加入自己找的不包含目标的照片。

因为数据集中的横幅多是红色且长条的形状,所以这里的负样本我找了很多类似横幅特征的图片。
再让AI写一个基于图片名字创建空白.txt文档的脚本。
全是0字节的。
下面是没添加负样本和添加了负样本的训练结果:
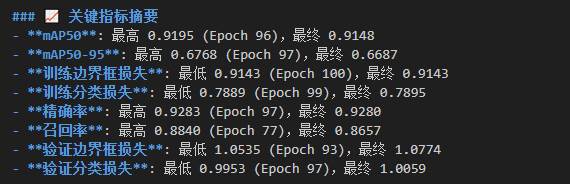
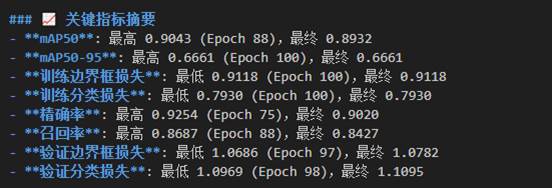
可以看到添加了负样本的模型的map50,精确率,召回率都有所降低,但是都不多(可能是我添加的负样本不是很多的原因),其实按理来说应该只有召回率降低一些,map50和精确率应该上升一点,不过没关系,零点零几的改变并没有什么太大差距,我们更应该关注模型在预测时的实际变化,将模型导入预测脚本,
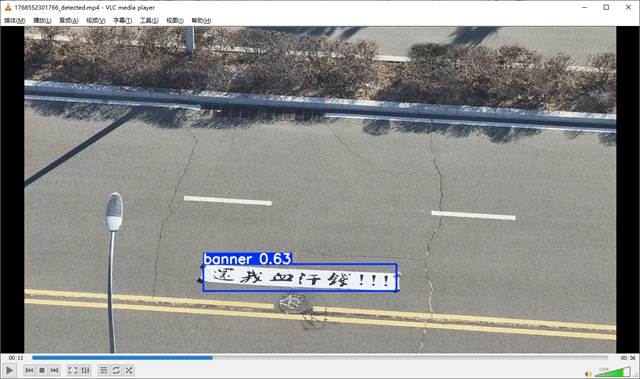
可以看到,在观察真正的横幅时,模型还是可以正常预测的:
我们再继续播放,无人机已经飞到之前的红色跑道的地方:
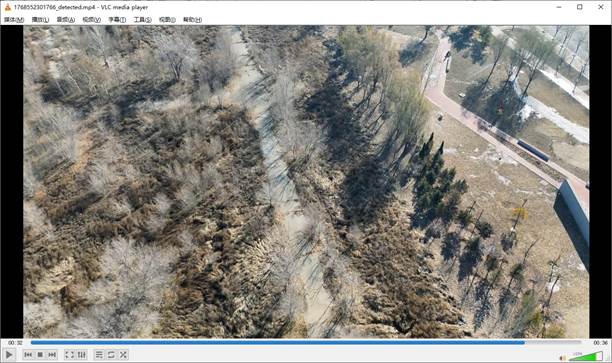
此时模型并没有和之前一样误检,说明添加负样本还是很有用的。
3.一些训练参数的设置
损失函数的优化:可以根据自己的目的进行侧重
权重调整:
增加 box_loss 权重 → 提升定位精度
调整 cls_loss 权重 → 改善分类能力
优化 dfl_loss → 改善边界框回归
Focal Loss:关注难分类样本,减少易分类样本影响
还有就是我们在训练时的评估参数:
其中注意我们的conf和iou参数的设置,
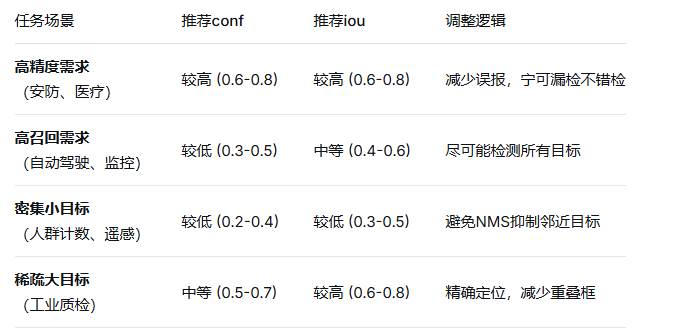
我在进行横幅检测时,由于训练脚本是让AI帮忙配置的,而且没有细看,他给我的conf设置为0.001,这导致我的模型的精确率和召回率虚高,下面的图片是我用视频对模型进行预测时出现的情况,可以看到除了真正的横幅,模型还把路沿认成了横幅。

除了训练脚本中的conf我们需要设置,我们在对视频进行预测时还需要设置conf,
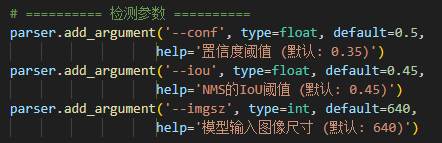
适当提高我们对视频进行预测的conf也可以提高检测结果,但是瑕不掩瑜,认真调整训练脚本的参数才是关键,在这个AI盛行的年代,确实方便了我们的学习,不过最重要的是要有甄别的能力,AI肯定可以用,但是不能完全依赖它,这么简单的错误,训练了一上午最后预测结果这么差,真是血的教训。
4.预处理数据集-缩放
因为我现在需要做的是通过无人机在空中检测横幅,但是在网上搜索的很多资料都是正面且怼脸拍摄的横幅,所以必须要无人机在空中放大之后模型才能检测到横幅,但是有因为条件有限,主要是因为没钱,没有无人机俯拍横幅的数据集,有也很少,肯定不够支持训练模型,用来验证都够呛,只能通过缩放图片大小来尽量模拟无人机俯拍的情况。
第一步:我们让AI写一个图片缩放可视化的脚本,可以自己设置缩放scale参数,观察生成的图片的大小,选择符合自己项目要求的scale。
可视化缩放脚本:
######################################################
#该脚本用来可视化数据集的增强效果,模拟无人机俯拍时的视角
######################################################
import cv2
import numpy as np
import random
import os
from pathlib import Path
import matplotlib.pyplot as plt
# ====== 配置参数(修改这里) ======
IMAGE_PATH = r"C:\Users\JAMES HARDEN\Desktop\横幅数据集\横幅数据集\images\train"
OUTPUT_DIR = r"D:\yoloV12\yolov12-main\yolov12-main\OutPut\overhead_simulation"
IMGSZ = 640 # 输出图像大小
SAMPLE_COUNT = 5 # 随机抽取的图片数量
# 固定三个缩放值
FIXED_SCALES = [0.08, 0.09, 0.10] # 修改这三个值即可
# ===============================
def resize_image(img, scale):
"""按指定比例缩放图片"""
h, w = img.shape[:2]
new_w = int(w * scale)
new_h = int(h * scale)
# 确保最小尺寸
new_w = max(10, new_w)
new_h = max(10, new_h)
# 缩放图片
img_resized = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
return img_resized, scale
def add_text_to_image(img, text, position=(10, 30), font_scale=0.6, thickness=2):
"""在图像上添加文字"""
img_with_text = img.copy()
font = cv2.FONT_HERSHEY_SIMPLEX
color = (0, 255, 0) # 绿色文字
# 添加文字
cv2.putText(img_with_text, text, position, font, font_scale, color, thickness)
return img_with_text
def visualize_augmentations():
"""可视化无人机俯拍效果"""
# 创建输出目录
os.makedirs(OUTPUT_DIR, exist_ok=True)
# 获取所有图片文件
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp']
image_files = []
if os.path.isfile(IMAGE_PATH):
image_files = [IMAGE_PATH]
elif os.path.isdir(IMAGE_PATH):
for ext in image_extensions:
image_files.extend([str(p) for p in Path(IMAGE_PATH).glob(f'*{ext}')])
if not image_files:
print(f"未找到图片文件: {IMAGE_PATH}")
return
print(f"找到 {len(image_files)} 张图片")
print(f"固定缩放值: {FIXED_SCALES}")
# 随机抽取指定数量的图片
if len(image_files) > SAMPLE_COUNT:
selected_images = random.sample(image_files, SAMPLE_COUNT)
else:
selected_images = image_files
# 处理随机抽取的图片
for i, img_path in enumerate(selected_images):
print(f"处理图片 {i+1}: {os.path.basename(img_path)}")
try:
# 读取图片
with open(img_path, 'rb') as f:
img_array = np.frombuffer(f.read(), np.uint8)
img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
if img is None:
print(f" 无法读取图片: {img_path}")
continue
original_h, original_w = img.shape[:2]
# 创建空白画布
result_height = IMGSZ
result_width = IMGSZ * 4 # 原始图片 + 3种缩放效果
result_canvas = np.zeros((result_height, result_width, 3), dtype=np.uint8)
# 1. 原始图片
original_aspect = original_w / original_h
original_height = int(result_height * 0.9)
original_width = int(original_height * original_aspect)
if original_width > IMGSZ:
original_width = IMGSZ
original_height = int(original_width / original_aspect)
original_resized = cv2.resize(img, (original_width, original_height), interpolation=cv2.INTER_LINEAR)
x_offset = (IMGSZ - original_width) // 2
y_offset = (result_height - original_height) // 2
result_canvas[y_offset:y_offset+original_height, x_offset:x_offset+original_width] = original_resized
result_canvas = add_text_to_image(result_canvas, f"Original: {original_w}x{original_h}", (10, 30))
# 2. 三种固定缩放效果
for j, scale in enumerate(FIXED_SCALES):
# 应用缩放
resized_img, actual_scale = resize_image(img.copy(), scale)
# 在画布上定位
canvas_x = IMGSZ * (j + 1)
# 获取缩放后尺寸
h_resized, w_resized = resized_img.shape[:2]
# 居中放置
x_offset_canvas = canvas_x + (IMGSZ - w_resized) // 2
y_offset_canvas = (result_height - h_resized) // 2
x_end = min(x_offset_canvas + w_resized, canvas_x + IMGSZ)
y_end = min(y_offset_canvas + h_resized, result_height)
if x_end > x_offset_canvas and y_end > y_offset_canvas:
result_canvas[y_offset_canvas:y_end, x_offset_canvas:x_end] = resized_img[:y_end-y_offset_canvas, :x_end-x_offset_canvas]
# 添加文字
text_y = result_height - 60
result_canvas = add_text_to_image(result_canvas, f"Scale: {actual_scale:.4f}", (canvas_x + 10, text_y))
result_canvas = add_text_to_image(result_canvas, f"Size: {w_resized}x{h_resized}", (canvas_x + 10, text_y + 30))
# 添加分隔线
for j in range(1, 4):
line_x = IMGSZ * j
cv2.line(result_canvas, (line_x, 0), (line_x, result_height), (255, 255, 255), 2)
# 保存结果
output_path = os.path.join(OUTPUT_DIR, f'drone_view_{i+1}.jpg')
cv2.imwrite(output_path, result_canvas)
print(f" 已保存: {output_path}")
# 显示图片
plt.figure(figsize=(16, 6))
plt.imshow(cv2.cvtColor(result_canvas, cv2.COLOR_BGR2RGB))
plt.title(f'无人机俯拍模拟 - 图片 {i+1}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 单独保存每种缩放效果
for j, scale in enumerate(FIXED_SCALES):
resized_img, actual_scale = resize_image(img.copy(), scale)
h_resized, w_resized = resized_img.shape[:2]
canvas = np.zeros((IMGSZ, IMGSZ, 3), dtype=np.uint8)
# 随机位置放置
x_offset = random.randint(0, max(0, IMGSZ - w_resized))
y_offset = random.randint(0, max(0, IMGSZ - h_resized))
x_end = min(x_offset + w_resized, IMGSZ)
y_end = min(y_offset + h_resized, IMGSZ)
if x_end > x_offset and y_end > y_offset:
canvas[y_offset:y_end, x_offset:x_end] = resized_img[:y_end-y_offset, :x_end-x_offset]
# 添加文字
canvas = add_text_to_image(canvas, f"Scale: {actual_scale:.4f}", (10, 30))
canvas = add_text_to_image(canvas, f"Size: {w_resized}x{h_resized}", (10, 60))
cv2.imwrite(os.path.join(OUTPUT_DIR, f'scale_{i+1}_{j+1}.jpg'), canvas)
except Exception as e:
print(f" 处理图片时出错: {e}")
continue
print(f"\n完成! 结果已保存到: {OUTPUT_DIR}")
print(f"随机抽取了 {len(selected_images)} 张图片进行可视化")
if __name__ == "__main__":
print("无人机俯拍模拟可视化")
print(f"图片路径: {IMAGE_PATH}")
print(f"输出目录: {OUTPUT_DIR}")
print(f"随机抽取 {SAMPLE_COUNT} 张图片\n")
visualize_augmentations()例:下面就是我生成的可视化的图片结果
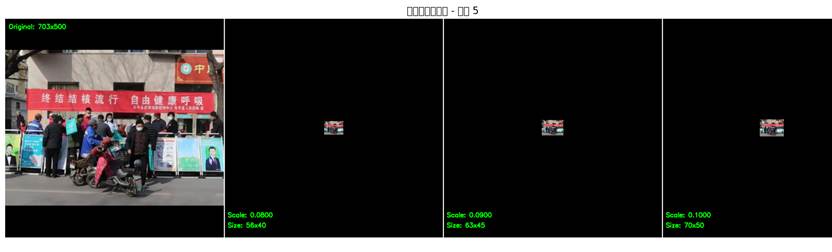
经过观察,我发现scale在0.15和0.25时比较符合我的项目需求,所以我的数据增强-缩放范围就选择0.15-0.25,但是我们在训练脚本中的数据增强的scale并不支持0.15-0.25这样的缩放范围,我们可以在
Ultralytics-data-augment.py-randomperspective-affine_transform中看到,YOLOv12-main框架中的缩放规则如下:
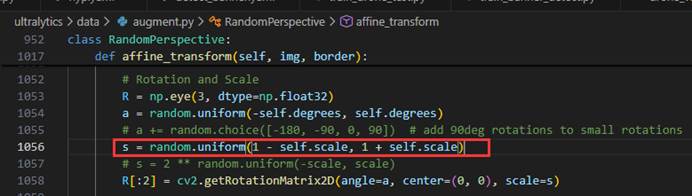
如果我们只是在训练脚本中将scale设置为0.15,
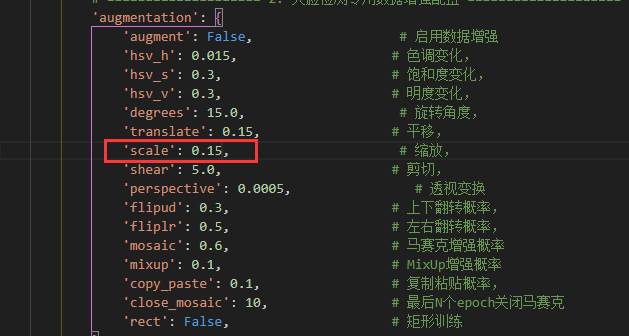
他执行的是[1-0.15,1+0.15],并不是我们要求的范围,所以我们只有通过对数据集进行预处理,此时只有再劳驾我们的AI帮忙写一个将图片进行缩放的脚本,此时缩放范围就可以自定义了,注意!!图片缩放之后,标签也要跟着一起进行相应变换,这不能忘。
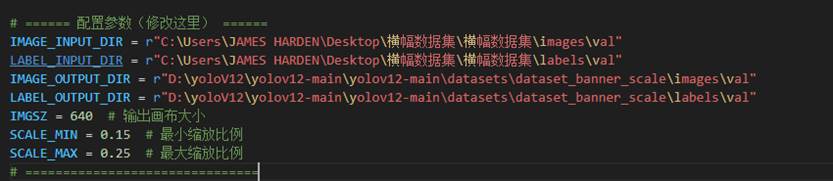
预处理-缩放脚本:
import cv2
import numpy as np
import os
import random
from pathlib import Path
import sys
#################################################
#功能:对数据集进行预处理,进行缩放
##################################################
# ====== 配置参数(修改这里) ======
IMAGE_INPUT_DIR = r"C:\Users\JAMES HARDEN\Desktop\横幅数据集\横幅数据集\images\val"
LABEL_INPUT_DIR = r"C:\Users\JAMES HARDEN\Desktop\横幅数据集\横幅数据集\labels\val"
IMAGE_OUTPUT_DIR = r"D:\yoloV12\yolov12-main\yolov12-main\datasets\dataset_banner_scale\images\val"
LABEL_OUTPUT_DIR = r"D:\yoloV12\yolov12-main\yolov12-main\datasets\dataset_banner_scale\labels\val"
IMGSZ = 640 # 输出画布大小
SCALE_MIN = 0.07 # 最小缩放比例
SCALE_MAX = 0.09 # 最大缩放比例
# ===============================
def main():
print(f"输入图片目录: {IMAGE_INPUT_DIR}")
print(f"输入标签目录: {LABEL_INPUT_DIR}")
print(f"输出图片目录: {IMAGE_OUTPUT_DIR}")
print(f"输出标签目录: {LABEL_OUTPUT_DIR}")
# 检查输入目录是否存在
if not os.path.exists(IMAGE_INPUT_DIR):
print(f"错误: 输入图片目录不存在: {IMAGE_INPUT_DIR}")
sys.exit(1)
if not os.path.exists(LABEL_INPUT_DIR):
print(f"警告: 输入标签目录不存在: {LABEL_INPUT_DIR}")
# 创建输出目录
try:
os.makedirs(IMAGE_OUTPUT_DIR, exist_ok=True)
os.makedirs(LABEL_OUTPUT_DIR, exist_ok=True)
print(f"已创建输出目录")
except Exception as e:
print(f"错误: 无法创建输出目录: {e}")
sys.exit(1)
# 获取图片文件
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp']
image_files = []
for ext in image_extensions:
# 只找小写扩展名
files = list(Path(IMAGE_INPUT_DIR).glob(f'*{ext}'))
image_files.extend([str(p) for p in files])
# 去重
image_files = list(set(image_files))
if not image_files:
print(f"错误: 在 {IMAGE_INPUT_DIR} 中没有找到图片文件")
print(f"支持的扩展名: {image_extensions}")
# 列出目录内容
print(f"\n目录内容:")
try:
for item in os.listdir(IMAGE_INPUT_DIR)[:10]:
print(f" {item}")
except:
pass
sys.exit(1)
print(f"找到 {len(image_files)} 张图片")
# 处理每张图片
success_count = 0
for i, img_path in enumerate(image_files):
img_name = Path(img_path).stem
try:
# 1. 读取图片
img = cv2.imread(img_path)
if img is None:
# 尝试用另一种方式读取
with open(img_path, 'rb') as f:
img_data = np.frombuffer(f.read(), np.uint8)
img = cv2.imdecode(img_data, cv2.IMREAD_COLOR)
if img is None:
print(f" 图片 {i+1}: 无法读取 {os.path.basename(img_path)}")
continue
original_h, original_w = img.shape[:2]
# 2. 随机缩放
scale = random.uniform(SCALE_MIN, SCALE_MAX)
new_w = int(original_w * scale)
new_h = int(original_h * scale)
# 确保最小尺寸
new_w = max(10, new_w)
new_h = max(10, new_h)
# 3. 缩放图片
img_resized = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
# 4. 创建画布并放置图片
canvas = np.zeros((IMGSZ, IMGSZ, 3), dtype=np.uint8)
# 计算放置位置
max_x_offset = max(0, IMGSZ - new_w)
max_y_offset = max(0, IMGSZ - new_h)
if max_x_offset > 0:
x_offset = random.randint(0, max_x_offset)
else:
x_offset = 0
if max_y_offset > 0:
y_offset = random.randint(0, max_y_offset)
else:
y_offset = 0
# 放置图片
end_x = min(x_offset + new_w, IMGSZ)
end_y = min(y_offset + new_h, IMGSZ)
if end_y - y_offset > 0 and end_x - x_offset > 0:
canvas[y_offset:end_y, x_offset:end_x] = img_resized[:end_y-y_offset, :end_x-x_offset]
# 5. 保存图片
output_img_path = os.path.join(IMAGE_OUTPUT_DIR, f"{img_name}_drone.jpg")
success = cv2.imwrite(output_img_path, canvas)
if not success:
print(f" 图片 {i+1}: 保存失败 {os.path.basename(output_img_path)}")
continue
# 6. 处理标签
output_label_path = os.path.join(LABEL_OUTPUT_DIR, f"{img_name}_drone.txt")
label_path = os.path.join(LABEL_INPUT_DIR, f"{img_name}.txt")
if os.path.exists(label_path):
with open(label_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
new_lines = []
for line in lines:
parts = line.strip().split()
if len(parts) >= 5:
cls_id = parts[0]
x_center = float(parts[1])
y_center = float(parts[2])
bbox_w = float(parts[3])
bbox_h = float(parts[4])
# 转换坐标
x_center_new = (x_center * new_w + x_offset) / IMGSZ
y_center_new = (y_center * new_h + y_offset) / IMGSZ
bbox_w_new = bbox_w * new_w / IMGSZ
bbox_h_new = bbox_h * new_h / IMGSZ
# 检查边界框是否在画布内
if (0 <= x_center_new - bbox_w_new/2 and
x_center_new + bbox_w_new/2 <= 1 and
0 <= y_center_new - bbox_h_new/2 and
y_center_new + bbox_h_new/2 <= 1):
new_lines.append(f"{cls_id} {x_center_new:.6f} {y_center_new:.6f} {bbox_w_new:.6f} {bbox_h_new:.6f}")
# 保存标签
if new_lines:
with open(output_label_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(new_lines))
else:
# 保存空文件
with open(output_label_path, 'w', encoding='utf-8') as f:
pass
else:
# 如果原始标签不存在,创建空标签文件
with open(output_label_path, 'w', encoding='utf-8') as f:
pass
success_count += 1
# 显示进度
if (i + 1) % 100 == 0:
print(f"已处理 {i + 1}/{len(image_files)} 张图片")
except Exception as e:
print(f" 图片 {i+1}: 处理 {os.path.basename(img_path)} 时出错: {e}")
continue
print(f"\n处理完成!")
print(f"总图片数: {len(image_files)}")
print(f"成功处理: {success_count}")
print(f"失败: {len(image_files) - success_count}")
# 验证输出
print(f"\n验证输出:")
# 检查输出目录
output_images = list(Path(IMAGE_OUTPUT_DIR).glob('*.jpg'))
output_labels = list(Path(LABEL_OUTPUT_DIR).glob('*.txt'))
print(f"输出图片数量: {len(output_images)}")
print(f"输出标签数量: {len(output_labels)}")
if output_images:
print(f"输出目录中的图片示例:")
for img in output_images[:3]:
print(f" - {img.name} ({os.path.getsize(img)} 字节)")
else:
print(f"错误: 输出目录中没有图片!")
print(f"请检查: {IMAGE_OUTPUT_DIR}")
if __name__ == "__main__":
main()生成的图片如下:
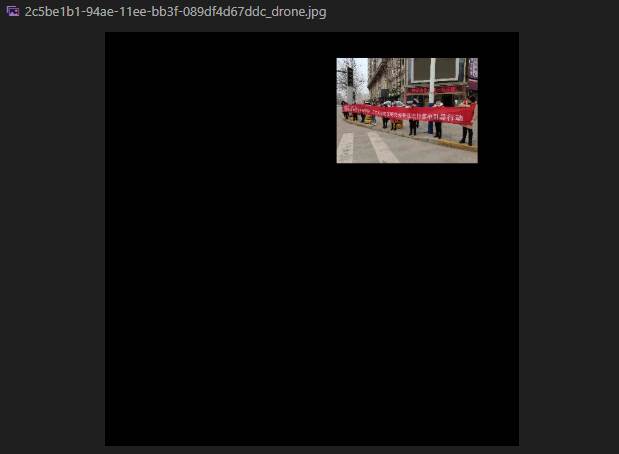
简直是low到爆,不过我使用的是已经用正常大小的横幅训练了的模型,对这个模型再次用我们进行了预处理-缩放的数据集进行训练。
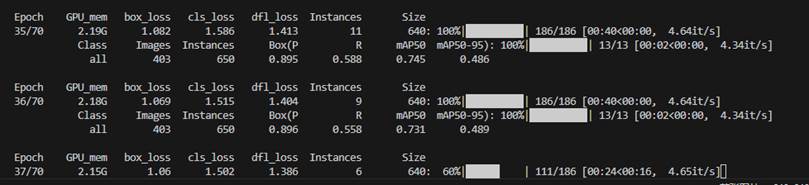
再次训练我是关闭了数据增强模块,就专注于对缩放大小的检测,训练轮次不宜太高,因为比较是同一数据集,只是进行了缩放变换,轮次过高的话容易有过拟合风险且容易导致泛化能力下降。
微调的目标是让模型适应新数据,而不是从头学习。轮次过高会导致过拟合,轮次过低则效果不明显。
可以看到相较之前,召回率明显降低了,不过没关系,什么都无法舍弃的话什么都得不到。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)