给 Agent 加一个可靠的知识检索层:从向量引擎到 RAG 工作流的实践笔记
第一个问题:为什么检索到了内容,答案还是错?可能是召回内容相似但不适用,也可能是旧文档没有过滤,还可能是模型误解了上下文。第二个问题:为什么文档越多,效果反而越差?可能是重复资料、过期资料、低质量资料太多。数据量增加前,应该先建立评估和治理机制。第三个问题:为什么模型上下文很长,仍然需要检索?因为上下文长度不等于资料选择能力。先筛选再阅读更稳定。第四个问题:为什么答案必须有来源?因为没有来源就很难
给 Agent 加一个可靠的知识检索层:从向量引擎到 RAG 工作流的实践笔记

最近做 AI 应用时,越来越容易遇到一个问题:模型本身很强,但一进入真实业务场景,就开始“不知道”。
它能解释代码,也能写总结,还能把一段接口文档改写成很自然的说明。但如果问它:
“这个接口现在还能不能用?”
“这条业务规则是不是最新版?”
“这个问题之前有没有处理过?”
“这个 Agent 调工具前应该先查哪些资料?”
模型往往不能直接回答。原因很简单:模型并不知道项目里的内部文档、历史变更、业务规则、客户记录、代码仓库和团队约定。
这也是很多 Agent 项目从 Demo 到落地时会卡住的地方。
Demo 阶段,只要模型能回答、能调用工具、能生成内容,就已经很有演示效果。但落地阶段,真正麻烦的是上下文。Agent 不是只会聊天,它可能要读取资料、调用接口、生成报告、写代码、创建工单,甚至执行多步骤任务。如果它在没有查资料的情况下直接行动,就很容易出现“看起来很智能,实际上很冒险”的情况。
所以,本文不讨论哪个模型更强,也不讨论模型价格,而是从工程角度梳理一个更基础的问题:
如何给 Agent 加一层可用的向量检索能力,让它在回答和执行前先找到可靠上下文。
这个问题看起来朴素,但它是很多 AI 应用能不能稳定落地的关键。
1. 为什么模型调用不是完整的 AI 应用

很多 AI 应用的第一步,都是从调用模型开始。
一个最简单的请求大概是这样:
const response = await client.chat.completions.create({
model: "some-model",
messages: [
{ role: "system", content: "你是一个技术助手" },
{ role: "user", content: "解释一下 RAG 是什么" }
]
})
这段代码可以跑通,也可以很快做出一个聊天页面。
但问题是,这只是模型调用,不是完整的业务系统。
如果用户问的是通用问题,模型可以基于已有知识回答。但如果用户问的是内部业务问题,模型就需要额外资料。
比如:
“订单接口的 item_id 字段还能不能用?”
“新同事为什么进组后看不到项目?”
“客户投诉两次后是否需要升级处理?”
“这个服务上线前需要跑哪些测试?”
这些问题都不是模型凭通用知识就能稳定回答的。它需要知道内部文档、版本变化、权限规则、工单流程和历史记录。
如果直接把问题丢给模型,模型可能会生成一段很流畅的回答。但流畅不等于可靠。很多时候,模型最危险的地方不是不会说,而是把不确定的内容说得像真的。
因此,一个稍微严肃一点的 AI 应用,不能只做“问题 -> 模型 -> 答案”这条链路。它至少还需要一层知识检索:
用户问题 -> 检索相关资料 -> 过滤与排序 -> 模型基于资料回答 -> 返回答案和来源。
这就是 RAG 的基本思路。
2. Agent 为什么更需要检索层

普通问答系统答错了,用户可能重新问一次。
Agent 答错了,可能会继续执行。
这就是 Agent 与普通聊天机器人的区别。
Agent 可能会:
读取文件。
调用接口。
生成代码。
修改配置。
创建工单。
总结会议。
生成客户回复。
调用内部工具。
执行多步骤流程。
一旦 AI 从“回答”变成“行动”,上下文的重要性就会上升。
比如一个代码 Agent,在修改某个模块前,如果没有检索 README、设计文档、历史 PR 和测试规范,就可能改掉一个兼容逻辑。
比如一个客服 Agent,在回复客户前,如果没有查最新售后政策和历史工单,就可能给出错误承诺。
比如一个数据 Agent,在生成分析报告前,如果没有查指标口径,就可能用错字段。
这些问题不是靠一句“请谨慎回答”就能解决的。需要系统设计让 Agent 形成一套固定流程:
先判断是否需要资料。
需要资料时调用检索工具。
检索结果不足时继续查或提示不确定。
资料存在冲突时不要强行下结论。
涉及操作时先给出计划并等待确认。
执行结果要可追踪。
这套流程里,向量引擎就是关键的一层。
它不负责替模型思考,但负责给模型提供可用上下文。
3. 向量引擎在系统里做什么

向量引擎的核心作用,是把非结构化资料变成可以语义检索的知识片段。
企业或项目里的资料通常很分散:
接口文档。
产品说明。
FAQ。
Markdown 文档。
PDF。
代码注释。
提交记录。
历史 PR。
客服工单。
会议纪要。
运营复盘。
内部规范。
这些内容如果只放在文件夹里,模型是不会自动知道的。需要先把它们解析、切分、向量化,再建立索引。
当用户提问时,系统把问题也转换成向量,然后在向量引擎里查找语义相近的片段。
比如文档里写的是“权限继承策略”,用户问的是“为什么新同事看不到项目?”
关键词可能不完全一致,但语义上是相关的。
这就是向量检索相比普通关键词搜索的价值。
不过,只做向量召回还不够。
因为“相似”不等于“正确”。
一段旧文档可能和问题很相似,但已经过期。
一段会议纪要可能提到了某个规则,但不是正式文档。
一段内部资料可能很相关,但当前用户没有权限查看。
所以,向量引擎往往要配合 metadata、权限过滤、版本控制、重排和引用来源一起使用。
一个可用的检索层,不只是返回相似文本,而是返回“当前场景下可以使用的资料”。
4. 文档切分不要只按字数

很多 RAG 系统效果不好,第一步就出在文档切分。
最简单的切分方式是按固定长度,比如每 800 字切一段。
这种方式容易实现,但不一定适合业务文档。
比如一段接口文档:
## 创建订单接口
POST /api/orders
### 请求参数
- user_id:用户 ID
- sku_id:商品 ID
- count:数量
### 注意事项
旧字段 item_id 已不再推荐使用。新版本请使用 sku_id。
如果切分时把“接口名”和“注意事项”切开,用户问“item_id 还能不能用”时,系统可能召回不到接口背景。
更合理的方式是尽量保留语义结构。
一个片段里最好包含:
当前标题。
上级标题。
正文内容。
来源路径。
更新时间。
文档类型。
这样模型拿到片段时,不只是看到一句话,还知道这句话属于哪份资料、哪个章节、哪个版本。
对于代码文档,还可以按函数、类、模块切分。
对于 FAQ,可以把问题和答案放在同一个片段里。
对于规范文档,可以按章节切分。
对于会议纪要,可以按议题切分。
切分策略没有唯一标准,关键是让召回结果保持完整语义。
5. metadata 是知识片段的身份证

如果只存文本和向量,系统很快会遇到问题。
比如用户问“退款规则”,系统召回了一段三年前的旧政策,因为语义很相似。
用户问“接口字段”,系统召回了一段废弃版本说明。
用户问“客户处理流程”,系统召回了一段当前用户无权查看的内部资料。
这些问题都需要 metadata 参与处理。
一个知识片段可以长这样:
{
"id": "chunk_001",
"text": "旧字段 item_id 已不再推荐使用。新版本请使用 sku_id。",
"metadata": {
"source": "docs/api/order.md",
"title": "创建订单接口",
"doc_type": "api_doc",
"version": "v3",
"updated_at": "2026-05-12",
"status": "active",
"permission": "internal",
"owner": "backend-team"
}
}
这些字段的作用很直接。
source 用于引用来源。
doc_type 用于限定资料类型。
version 用于判断版本。
updated_at 用于处理新旧资料。
status 用于过滤废弃文档。
permission 用于权限控制。
owner 用于后续追踪维护责任。
metadata 不一定一开始就设计得很复杂,但不能完全没有。
没有 metadata 的知识库,就像没有目录和标签的资料室。东西确实都在,但很难保证每次拿出来的都是对的。
6. 检索之后还需要过滤和重排
很多 Demo 会这样写:
const results = await vectorSearch(query, { topK: 5 })
const answer = await llmGenerate(query, results)
这能跑,但在真实场景里不够稳。
检索结果通常需要经过几层处理。
第一层是权限过滤。
当前用户没有权限看的内容,不应该进入模型上下文。
第二层是状态过滤。
已经废弃或过期的内容,不应该作为最终依据。
第三层是去重。
同一段内容可能在多个文档里重复出现,需要合并或去掉重复片段。
第四层是重排。
向量相似度最高的片段,不一定是最适合回答问题的片段。可以使用 rerank 或规则重新排序。
第五层是置信度判断。
如果召回结果都不够相关,系统应该提示资料不足,而不是强行回答。
这些步骤看起来会增加复杂度,但它们是生产系统必须考虑的。
很多 RAG 系统答错,不是因为没有搜到东西,而是搜到了一堆相似但不能用的东西。
7. 答案必须尽量带来源

在个人使用 AI 时,很多人只看答案是否顺眼。
但在工程场景里,来源非常重要。
用户不仅想知道“答案是什么”,还想知道“答案来自哪里”。
例如:
旧字段 item_id 已不再推荐使用。当前建议使用 sku_id 作为商品标识。
来源:
- docs/api/order.md
- 章节:创建订单接口
- 更新时间:2026-05-12
这样的回答更容易被信任,也更容易排查问题。
如果答案错了,可以回查:
是文档错了?
是检索错了?
是重排错了?
还是模型理解错了?
如果答案没有来源,排查会非常困难。
所以,在设计 RAG 系统时,不要只追求回答自然,也要考虑可追踪性。
可追踪性是从 Demo 走向生产的重要标志。
8. 一个最小可用流程

下面是一个简化版流程,适合用来理解整体结构。
type Chunk = {
id: string
text: string
metadata: {
source: string
title: string
updatedAt: string
permission: string
status: "active" | "deprecated"
}
}
async function retrieve(query: string, userRole: string) {
const rawResults = await vectorSearch(query, { topK: 20 })
const filtered = rawResults
.filter(item => item.metadata.status === "active")
.filter(item => canAccess(userRole, item.metadata.permission))
const reranked = await rerank(query, filtered)
return reranked.slice(0, 5)
}
async function answer(query: string, userRole: string) {
const chunks = await retrieve(query, userRole)
if (chunks.length === 0) {
return {
answer: "当前资料不足,无法给出可靠结论。",
sources: []
}
}
const context = chunks
.map((c, i) => `[${i + 1}] ${c.text}\n来源:${c.metadata.source}`)
.join("\n\n")
const prompt = `
请只基于给定资料回答。
如果资料不足,请明确说明不确定。
回答后列出来源。
用户问题:
${query}
资料:
${context}
`
return llmGenerate(prompt)
}
这段代码只是示意,真实项目里还会有更多细节,比如查询改写、多路召回、缓存、日志、错误处理、用户反馈等。
但核心思想不变:
先检索。
再过滤。
再生成。
再引用。
9. Agent 如何使用检索工具
Agent 使用检索工具时,不应该每次都无脑调用,也不应该完全不调用。
可以按照问题类型判断。
如果用户只是让它改写一句话,可能不需要检索。
如果用户问业务规则、接口状态、历史处理、客户情况,就应该检索。
如果用户要求执行操作,比如发送消息、修改状态、提交代码,就应该先检索相关规则,再给出操作计划。
一个简化流程如下:
用户输入
↓
判断任务类型
↓
是否需要外部知识
↓
需要:调用检索工具
↓
检查资料是否足够
↓
足够:生成答案或计划
↓
不足:继续检索或提示不确定
↓
涉及执行:等待确认
这样 Agent 的行为会更像一个谨慎的工程助手。
它不是拿到任务就开始动手,而是先查资料。
这很朴素,但很重要。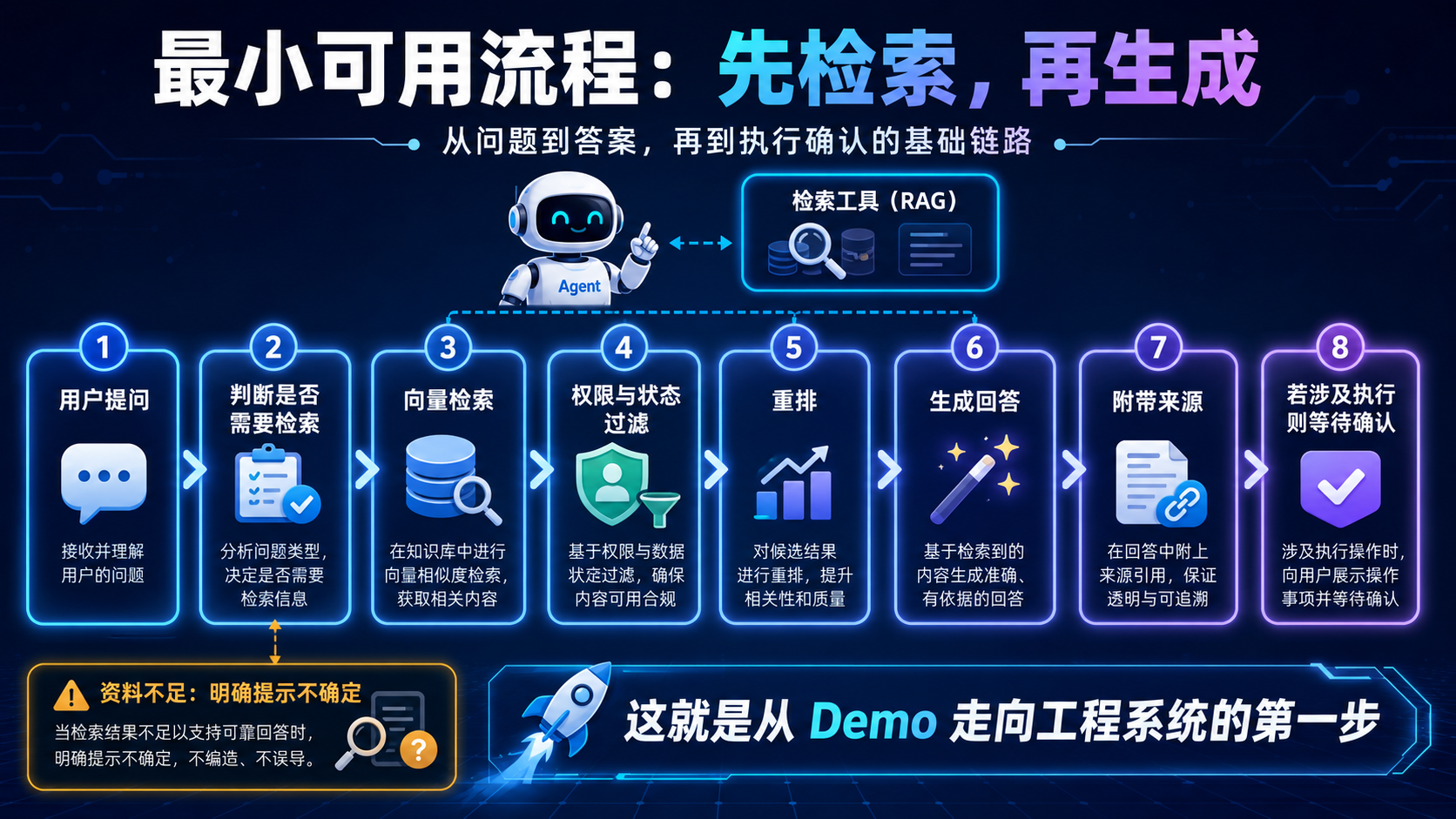
10. 先用小场景验证,不要一上来导入所有资料
很多团队做知识库时,一开始就想把所有文档都导进去。
这通常不是好主意。
资料越多,问题越复杂。
旧文档更多。
重复内容更多。
权限更乱。
评估更困难。
如果前期链路还没跑通,大规模导入只会把问题放大。
更稳的方式是先选一个小场景。
比如:
接口文档问答。
内部 FAQ 检索。
项目 README 检索。
售后政策问答。
运营复盘查询。
准备几十份低敏资料,设计二十个真实问题,先验证检索和引用是否稳定。
如果需要一个在线环境做小范围复现实验,可以使用这个地址:
https://178.nz/awa
第一轮建议只验证三件事:
能否召回正确资料。
能否引用来源。
资料不足时是否会停止编造。
如果这三件事不稳定,就不要急着扩大数据量。
11. 如何评估检索效果
不要只靠感觉。
“感觉答得不错”是最容易误导人的。
可以准备一个小型评估集。
例如:
问题:item_id 字段还能不能用?
理想来源:docs/api/order.md
问题:新同事为什么看不到项目?
理想来源:docs/auth/permission.md
问题:客户投诉两次后是否需要升级?
理想来源:docs/support/escalation.md
然后观察:
正确来源是否被召回。
正确来源是否排在前面。
答案是否真的基于来源。
是否引用了过期文档。
是否在资料不足时拒答。
不同权限用户是否看到不同结果。
这些指标比单纯看模型回答更有意义。
因为 RAG 系统的问题可能出现在多个环节:
文档解析。
文本切分。
向量化。
检索。
过滤。
重排。
生成。
引用。
如果没有评估集,就只能靠猜。
今天改 topK,明天改 chunk size,后天换 embedding 模型,最后到底有没有变好,很难判断。
工程系统不应该靠玄学调参。
12. 长上下文不能完全替代向量引擎
现在很多模型上下文越来越长,于是有人会问:既然模型能读很多内容,还需要向量引擎吗?
需要。
因为长上下文解决的是“能放多少”,向量引擎解决的是“该放什么”。
把所有资料都塞进模型,不一定是好方法。
不同用户权限不同。
不同任务需要不同资料。
旧文档和新文档需要区分。
无关内容太多会干扰模型。
长上下文也会带来成本和延迟。
更合理的方式是先检索,再阅读。
向量引擎负责从大量资料里筛出最相关、最可信、最适合当前用户的片段。
模型负责理解这些片段并生成答案。
两者是配合关系,不是替代关系。
模型上下文越长,前置筛选反而越重要。
13. 多模态场景也需要知识检索

向量引擎不只适合文本问答。
多模态场景同样需要知识检索。
比如图像生成。
如果只是生成一张好看的图片,模型能力很重要。
但如果要生成符合业务要求的图片,就需要上下文。
品牌色是什么?
字体规范是什么?
产品卖点是什么?
哪些元素不能出现?
历史素材是什么风格?
投放平台有什么要求?
目标用户是谁?
这些信息如果不提供给模型,生成结果可能看起来很好,但业务上不能用。
未来的多模态工作流,很可能是:
先检索品牌资料。
再检索历史素材。
再读取产品说明。
再生成图像方案。
再根据反馈调整。
这依然需要向量引擎参与。
所以,越是复杂的 AI 应用,越不能只依赖模型本身。
14. 模型接入层和知识层要分开
很多系统会把模型接入和知识检索混在一起看。
其实它们是两个层级。
模型接入层解决的是:
怎么调用模型。
怎么管理 key。
怎么切换模型。
怎么统计成本。
怎么记录调用日志。
知识检索层解决的是:
模型回答前应该看什么资料。
哪些资料能被当前用户看到。
哪些资料已经过期。
答案来自哪里。
检索结果是否足够可靠。
这两个层级都重要,但不能互相替代。
有模型接入层,不代表有知识能力。
有向量引擎,也不代表不需要模型调用。
更合理的架构是:
模型层可以替换。
知识层持续沉淀。
今天使用这个模型,明天换另一个模型,但文档、索引、metadata、评估集和权限规则应该继续复用。
这才是长期建设 AI 应用的方式。
15. Agent 记忆不能等于聊天记录
很多人做 Agent memory,会把所有聊天记录都存下来。
这不叫长期记忆。
这叫日志。
日志有用,但不能直接当记忆。
真正有价值的记忆,是未来任务可复用的信息。
比如:
用户偏好先看结论。
某个接口已经废弃。
某个模块修改后必须跑集成测试。
某个客户需要特殊审批。
某个指标口径在 2026 年调整过。
某类问题需要人工确认。
这些信息可以沉淀成长期记忆。
但一次临时对话、一次中间推理、一次工具返回,不一定都应该进入长期记忆。
如果什么都记,Agent 会越来越混乱。
如果记错了,错误会被长期放大。
如果旧记忆不失效,系统会一直引用过期经验。
所以 Agent memory 也需要治理。
什么该记?
谁能看?
什么时候用?
什么时候过期?
如何纠错?
这些问题都需要设计。
向量引擎可以帮助存储和召回记忆,但不能替代记忆策略。
16. 普通开发者应该补哪些能力
如果想做 AI 应用,不建议只学 prompt。
prompt 有用,但它只是入口。
更值得补的是这些工程能力:
文档解析。
文本切分。
向量检索。
metadata 设计。
权限过滤。
答案引用。
检索评估。
Agent 工具调用。
key 管理。
日志审计。
上下文压缩。
长期记忆治理。
这些能力看起来没有“神级提示词”那么吸引眼球,但更接近真实项目。
未来 AI 应用不只需要会用模型的人,更需要能让模型稳定进入业务的人。
会调用模型的人很多。
会让模型基于正确资料回答的人少。
会让 Agent 调工具的人很多。
会让 Agent 调工具前先查资料的人少。
机会往往就在这些不那么热闹的基础能力里。
17. 一个可执行的学习路线
如果从零开始,可以按这个顺序练习:
第一步,选一个小场景。
比如接口文档问答。
第二步,准备资料。
选 20 到 50 份低敏文档。
第三步,做切分。
保留标题、来源、更新时间。
第四步,写入向量引擎。
每个片段带 metadata。
第五步,实现检索。
先做 topK,再做过滤和重排。
第六步,接模型生成。
要求只基于资料回答,并附来源。
第七步,做评估集。
准备 20 个真实问题,标注理想来源。
第八步,引入 Agent。
让 Agent 判断是否需要检索,资料不足时停止回答。
第九步,加入权限。
不同用户看到不同范围的资料。
第十步,加入更新机制。
旧文档失效,新文档生效。
这条路线不复杂,但很扎实。
做完一遍后,会比只看概念文章更理解 RAG 和 Agent 的真实问题。
18. 常见问题总结
第一个问题:为什么检索到了内容,答案还是错?
可能是召回内容相似但不适用,也可能是旧文档没有过滤,还可能是模型误解了上下文。
第二个问题:为什么文档越多,效果反而越差?
可能是重复资料、过期资料、低质量资料太多。数据量增加前,应该先建立评估和治理机制。
第三个问题:为什么模型上下文很长,仍然需要检索?
因为上下文长度不等于资料选择能力。先筛选再阅读更稳定。
第四个问题:为什么答案必须有来源?
因为没有来源就很难排查,也很难建立用户信任。
第五个问题:为什么 Agent 要先查资料?
因为 Agent 可能会行动。行动前没有依据,风险比普通问答更高。
19. 写在最后
AI 应用正在从“模型调用”进入“上下文工程”。
模型越来越强,Agent 越来越能干,多模态能力也越来越成熟。
但越是这样,越不能忽视底层问题:
模型根据什么回答?
Agent 根据什么行动?
答案来自哪里?
资料是否最新?
用户是否有权限?
系统能否评估和追踪?
向量引擎的价值,就在这些问题里。
它不是为了让架构看起来复杂,而是为了让 AI 应用更可控。
一个可用的 AI 系统,不应该只是模型直连。
它应该能检索资料,能过滤权限,能引用来源,能处理旧文档,能在资料不足时停止编造,能让 Agent 行动前先查清楚。
模型负责生成。
Agent 负责执行。
向量引擎负责提供可靠上下文。
当 AI 从聊天框走向真实工作流,这层上下文底座会越来越重要。
AI 应用的下半场,拼的不是谁的 prompt 更长,而是谁的上下文更可靠。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)