Qwen2.5VL-72B模型128K长序列性能优化方法
近期,我们在NPU集群上开展了Qwen2.5VL-72B模型的128K长序列训练任务。针对多模态大模型在长序列场景下面临的显存压力和计算效率挑战,本文记录了FSDP2框架适配、显存异常管理、Ring/Ulysses/Hybrid混合序列并行、ViT-DP异构并行、重计算优化、模型加载优化(meta-device、cpu-init、dcp使能)等一系列关键技术攻关工作。需求背景。
作者:昇腾实战派 x 3号小金鱼
摘要
近期,我们在NPU集群上开展了Qwen2.5VL-72B模型的128K长序列训练任务。针对多模态大模型在长序列场景下面临的显存压力和计算效率挑战,本文记录了FSDP2框架适配、显存异常管理、Ring/Ulysses/Hybrid混合序列并行、ViT-DP异构并行、重计算优化、模型加载优化(meta-device、cpu-init、dcp使能)等一系列关键技术攻关工作。
一、概述与优化目标
需求背景
随着Qwen VL系列模型的发布以及下游任务的亮眼表现,为构建多模态理解标杆模型,我们选用了Qwen2.5VL-72B模型进行深度优化。
优化目标
MindSpeed-MM仓Qwen2.5VL-72B模型支持128K长序列训练,在8机Atlas 800T A3服务器资源下,拉起模型128K长序列训练,提升MFU。
二、Qwen2.5VL MFU优化
该模型开箱采用Megatron-LM ring-attention CP切分,同时采用PTD切分,有两个主要因素导致性能不理想:
- 其一是多模态模型的异构性导致存算失衡,以VLM模型为例,模型同时存在ViT和LLM两种异构的结构,ViT的计算量较大但通常冻结参数不参与训练,其显存占用较小;LLM在不开启重计算的场景下显存占用通常较大,导致传统的Megatron PTD切分无法使得两者同时存算均衡。 分析该模型开箱性能数据的PP流水,除了第一个pp stage具有较高的计算负载,其它的stage都产生了较大的PP空泡,导致硬件利用率低下、整体性能较差。为了解决该问题,通常可以采用FSDP2这种无Pipeline Parallel的切分框架,此外也可以采用DistTrain(DistTrain: Addressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models)这种异构的并行策略框架。本文采用FSDP2方案,该章节后续会依次介绍(NPU、GPU)开箱性能数据、基础性能优化、Megatron-FSDP2(后续简称FSDP2)介绍及适配流程等。
- 其二是开箱长序列采用ring attention算法,ViT模块序列长度是LLM的4倍,当时mindspeed ring_attention不支持TND格式输入,需要转为SBND格式,构建atten mask会占用很大的显存,另外FA的耗时也远大于LLM FA,会在2.2章节补充介绍。
2.1 VLM模型异构MFU优化
2.1.2 Megatron-FSDP2框架适配
本项目选择使用FSDP2替换Megatron PTD,以消除Pipeline parallel,解决pp空泡带的问题。
PyTorch的完全分片数据并行(FSDP)旨在提供一个高性能的即时执行模式实现,对模型参数、梯度、优化器状态进行切分,包含通信分桶和通信/计算掩盖功能。进一步,FSDP2移除了FlatParameter,采用沿0维分片的DTensor表示分片参数,支持对单个参数的便捷操作、免通信的分片状态字典,以及更简化的初始化流程。FSDP示意图:
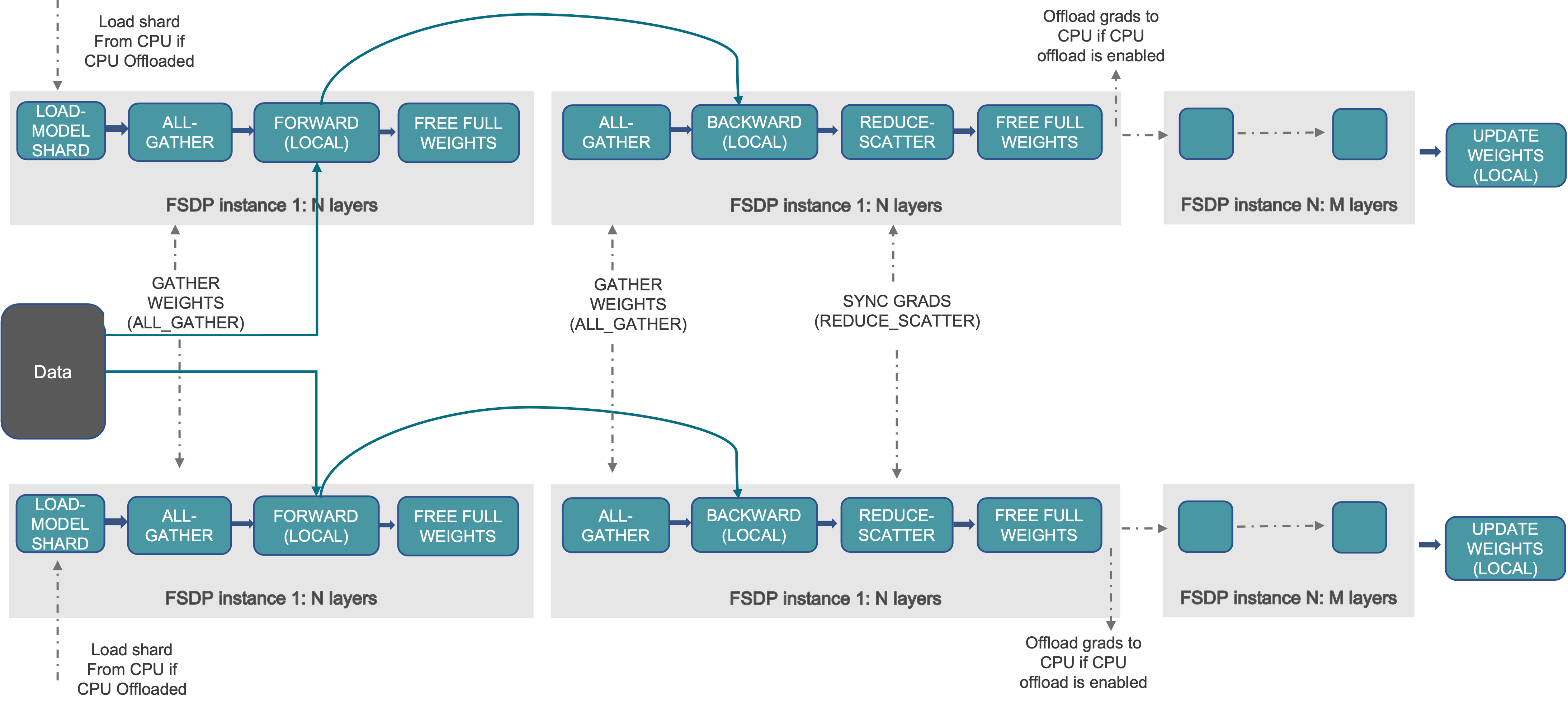
mindspeed fsdp2_config.yaml的配置项如下:MindSpeed/FSDP2介绍
sharding_size: int # 分片组大小,表示每个参数分片组的NPU数量
sub_modules_to_wrap: Optional[Iterable[torch.nn.Module]] = None # 需要进行FSDP包装的模块类列表,需要通过绝对路径引入:例如:mindspeed_mm.models.predictor.dits.sat_dit.VideoDiTBlock
reshard_after_forward: Union[bool, int] = True # 前向计算后立即重新分片参数
param_dtype: bf16 # 参数存储精度
reduce_dtype: fp32 # 梯度通信精度
cast_forward_inputs: bool = True # 自动转换前向输入到计算精度
ignored_modules AEModel, TextEncoder: Optional[Iterable[torch.nn.Module]] = None # 排除FSDP管理的模块列表, 需要通过绝对路径引入:例如:mindspeed_mm.models.ae.base.AEModel
num_to_forward_prefetch: int # 指定前向计算预取(forward prefetch)的层数,默认值为0
MindSpeed上使用Megatron-FSDP2,
脚本修改:
export CUDA_DEVICE_MAX_CONNECTIONS=2 # fsdp设置不能为1
--untie-embeddings-and-output-weights
--use-torch-fsdp2 \ # fsdp2使能方法
--fsdp2-config-path ./examples/qwen2.5vl/fsdp2_config.yaml \ # fsdp2配置文件
--ckpt-format torch_dist \ # PyTorch (FSDP2)分布式检查点格式
--use-cpu-initialization \ # 模型较大时NPU初始化会oom,需要使用cpu初始化
--init-model-with-meta-device \ #模型尺寸较大时需要使能meta-device参数初始化
# fdsp2需要关闭分布式优化器
fsdp2_config.yaml配置文件如下:
# sharding_size: 2 # device_mesh("replicate", "shard"),该配置源至其中的shard(可以不指定,默认为all ranks shard)
sub_modules_to_wrap: # 需要进行FSDP切分的模块(此处置对LLM的emb和transformer_layer进行FSDP切分,llm_head以及vit暂未切分)
- megatron.core.transformer.transformer_layer.TransformerLayer
- megatron.core.models.common.embeddings.language_model_embedding.LanguageModelEmbedding
- megatron.core.models.common.embeddings.rotary_pos_embedding.RotaryEmbedding
param_dtype: "bf16"
reduce_dtype: "fp32" # 梯度在fp32高精度下聚合
cast_forward_inputs: True # 前向过程中自动将输入数据转为混合精度策略中指定的数据类型(可以通过MixedPrecisionPolicy精细化控制)
ignored_modules: # 不需要进行FSDP切分的模块
- mindspeed_mm.models.vision.vision_model.VisionModel
recompute_modules: # 重计算模块
- megatron.core.transformer.transformer_layer.TransformerLayer
2.2 128K长序列MFU优化
该章节后续主要会依次介绍USP方案适配、ViT-DP长序列优化等内容。MindSpeed-MM中CP算法(Ulysses、Ring Attention、USP等)的适配过程在本文中不多做介绍,感兴趣可以参考MindSpeed-MM相关适配代码:Ring-Attention核心适配代码、Ulysses核心适配代码。
2.2.1 USP CP方案介绍
在本章节开始的性能优化明细中,有两个提升值得关注,分别是在FSDP2场景下,第一个ring16—>ring4uly4存在提升效果,第二个是在vit-dp是从ring16—>ring2uly8也存在性能提升。
为了探究这个性能收益来源,我们在Qwen2.5VL 72B模型减层场景下进行了ring和uly性能对比。ring和uly主要性能差异在于FA算子,且FAG算子性能区别较小。因为ulysses进入FA时没有切序列长度(完整序列长度),相对ring而言具有更高的FA效率,因此ulysses cp方案性能优化ring cp方案,(head头数、序列长度等)条件允许的情况下应该尽可能使用ulysses或者usp。
以CP16(ulysses_dregree=4为例),usp序列切分算法原理示意图如下所示:
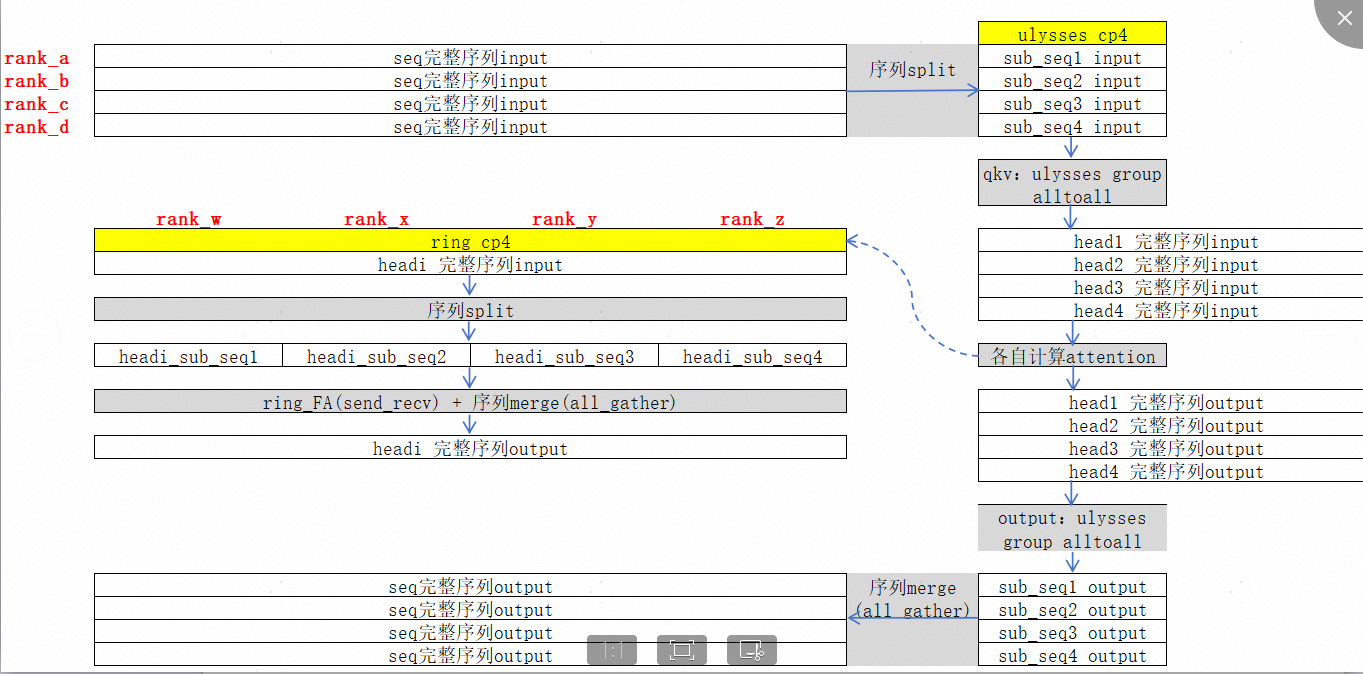
算法流程如下: usp-paper

数据类型为BNSD,CP GROUP被分为两个维度(ring cp_group和ulysses cp_group),可以看做一个二维列表(ulysses对应列,ring对应行),例如cp_size8可以看做2×4,则ulysses cp_size为2,ring cp_size为4。 上表中alltoall可以表示为在特性维度上进行gather,在特定维度上进行scatter,例如ulysses前向过程会对seq维度进行gather、对应hc维度进行scatter(对应scatter_idx=1,gather_idx=2),反向过程则相反。
为什么要使用USP:ulysses和ringattention两种算法对比如下表:

另外,以Qwen2.5VL 72B模型为例:各模块heads数量和GQA数量如下表:

默认情况下,Megatron parallel rank order为tp-cp-ep-dp-pp,因此在使用FSDP2场景时(无TP),CP rank分配具有最高优先级。在该Qwen2.5VL 72B模型中,CP_SIZE最大取值8.(受限于GQA),按照上表分析,CP通信在单机中时,通常ulysses性能优化ring,因此对该模型我们会优先选择ulysses algo。但是对于128k序列长度,cp_size8切分之后序列仍然较大(oom无法支持训练)。因此自然会引出USP,ulysses无法进一步切分的序列长度,使用ring进一步切分。因此,在无法全部使用Ulysses进行CP切分的场景下,使用USP混合序列切分就是更合适的选择。
2.2.2 USP_ViT-DP方案介绍
ViT-DP原理,在qwen2.5vl 72b模型vit模块中存在windows_attention和full attention两种类型Attention计算,其中full attention表示对完整的视频帧/图像数据进行self-attention计算,windows attention则表示将视频帧/图像数据按照patch_size(14)以及spatial_merge_size(2)等参数进行分割后合并,将帧数据分割成一个个小块,然后进行独立的self-attention计算。
基于上述情况,有个直观的想法就是,可以沿着帧的维度(对应full attention)或者patch的维度(对应windows attention)将数据沿着序列维度在cp_group中进行分割,每个cp_rank可以进行独立的Attention计算,并不需要交互,计算完成后再沿着序列维度进行汇聚。Qwen2.5VL模型结构示意图如下:
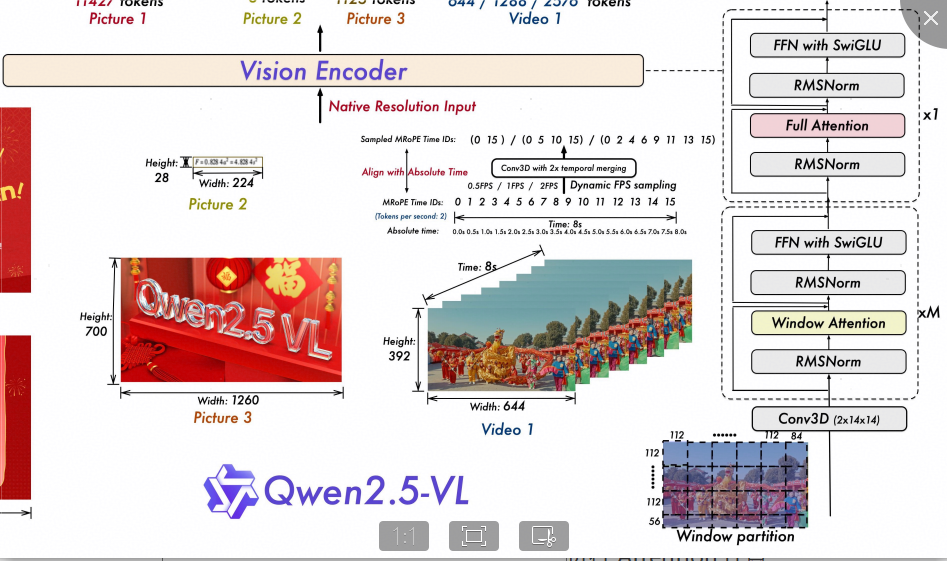
ViT中两种类型Attention在ViT DP中切分示意图如下,
| Windows Attention中多个patch组成一个windows,单个windows内部独立进行Attention计算: | Full Attention中单个Frame内部独立进行Attention计算: |
|---|---|
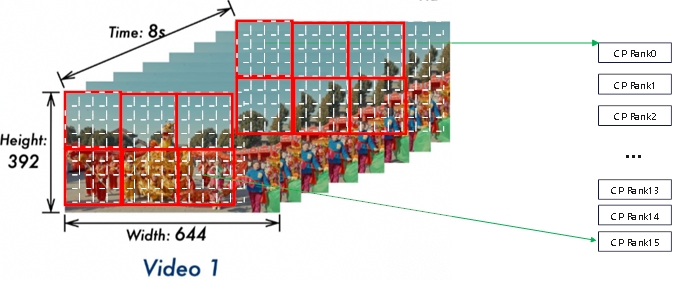 |
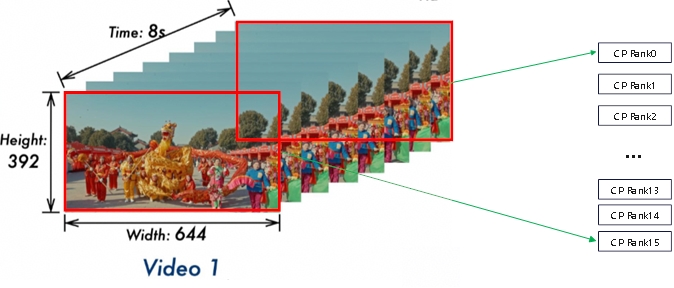 |
不管是Frame还是Windows,换一个角度都可以看做是dp视角的输入,将它们均匀划分到不同rank上独立运算,以实现并行提速。MindSpeed-MM仓中针对Qwen2.5VL ViT-DP的核心适配代码如下:
ViT-DP场景下,定义ViT独立的FA调用函数: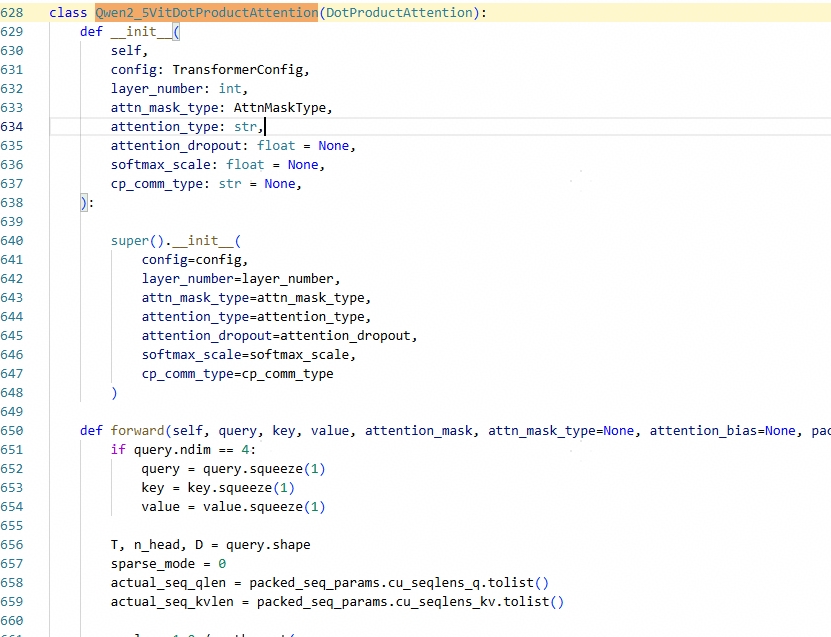 | Qwen2_5VitDotProductAttention替换DotProductAttention,实现ViT和LLM CP隔离:
| Qwen2_5VitDotProductAttention替换DotProductAttention,实现ViT和LLM CP隔离: 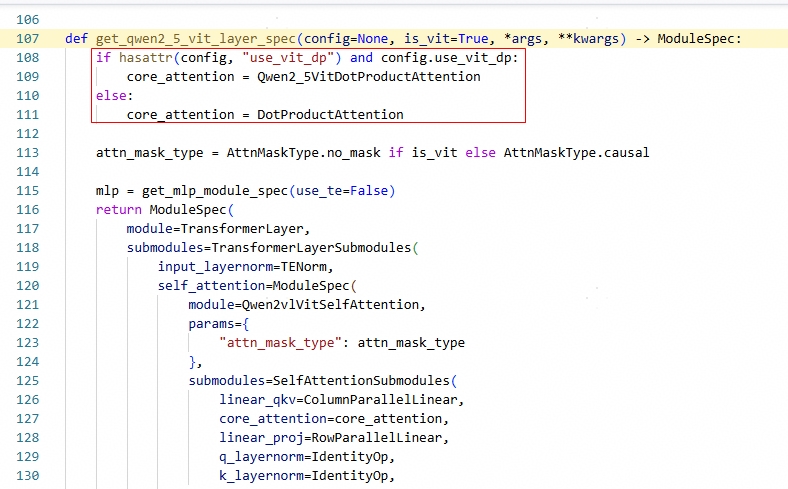 隔离LLM USP中ulysses对Attention基类wrapper,实现对ViT core_attention去wrapper:
隔离LLM USP中ulysses对Attention基类wrapper,实现对ViT core_attention去wrapper: 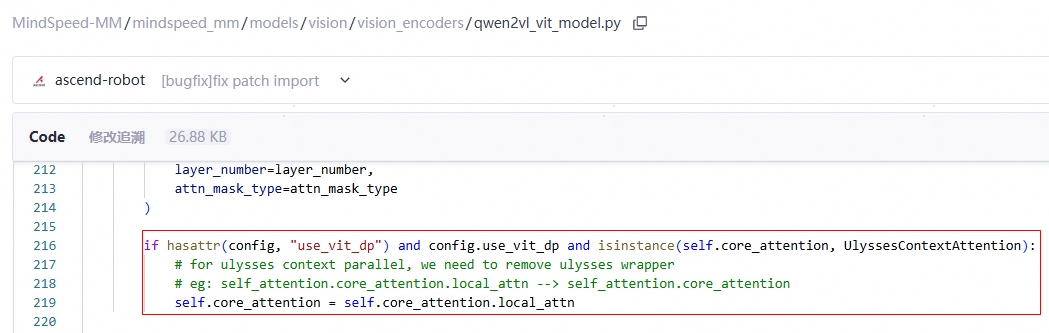
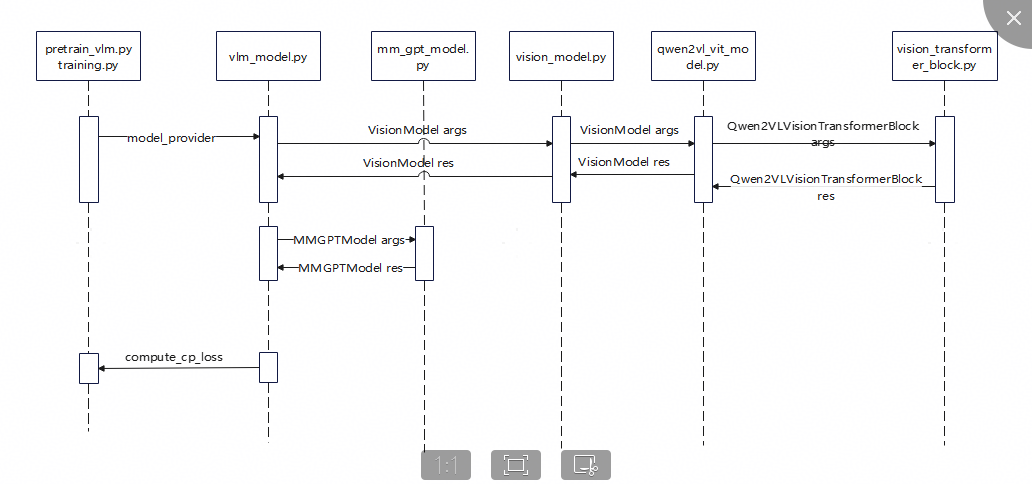
MindSpeed-MM VLM模型代码调用逻辑图如下所示,vlm_model.py文件中定义了模型主体结构(依次调用ViT、LLM,然后计算Loss):
本次适配的USP_ViT-DP CP长序列流程图如下所示:
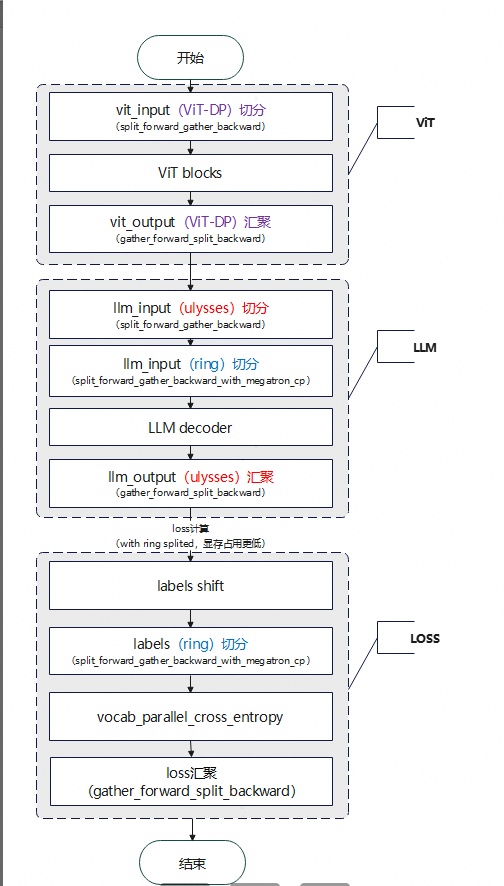
优势分析:
Qwen2.5VL 128K序列长度需要开启CP16,由于LLM GQA限制,CP可配置为ring16 或者 usp(例如:r8u2),并且ViT和LLM共用CP配置(cp size/group/algo等),不管哪种情况ViT模块长序列都需要ring attention的参与。 对于qwen2.5vl vit中windows attention而言,使用变长FA(TND格式)能有效提升FA效率,当时mindspeed ring attention不支持TND格式,需要转为形如SBND格式,相对TND格式,FA的计算效率明显降低。
进一步,通过Vit-DP的方式将ViT的cp_algo和LLM进行解耦,以实现ViT独立的CP序列并行配置,考虑ViT中Full/Windows两种类型Self Attention都是在Frame帧或者Patch块中独立进行,Frame/Patch之间并不需要进行CP通信,因此不需要使用传统uly/ring/usp CP算法,可直接复用LLM的CP Group,将Frame/Patch的数据(平均)分发给LLM CP Group中的Ranks,进行独立的Attention计算,然后进行结果汇聚,最终实现零通信序列并行。
三、 小结与展望
目前Qwen2.5VL ViT-DP主要针对视频训练数据,对于图片训练数据在full-attention中,图片的数量可能无法达到cp_size,导致存在部分cp_rank无法分配到计算数据,导致Device闲置,通常会拉低MFU,不符合设计预期。此外ViT-DP实现方法上,进行了一定程度的侵入式、定制化修改,由于其核心思想是模型不同模块(ViT vs LLM)CP配置存在差异,其中配置包括:cp_size、cp_group、cp_algo等,这一定程度上和DistTrain并行单元内部独立设置model parallel配置思想类似,也是为了解决VLM等多模态模型异构挑战,DistTrain提出了一种解耦化(Disaggregated)的多模态LLM训练方案,主要包含两方面的创新:
- 将计算量、参数量迥异的不同模块分离开,从而使得各模块可以用各自最优的并行策略运行,比较理想地解决了模型异构性带来的问题
- 针对多模态场景存在的数据异构性,设计了分离式的数据预处理模块,较大程度上解决了数据异构对DP、PP不均衡性带来的问题
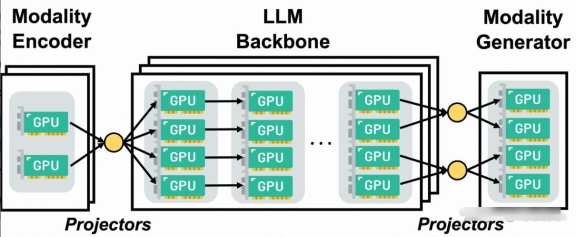
目前MindSpeed-MM版本已经构建DistTrain能力,已构建异构TP|DP|CP|PP方案,针对上述ViT-DP的需求场景,后续MindSpeed-MM可能会提供更加优雅的解决方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)