Agent Skills实战:27个脚本不进上下文,一句话完成RAG入库前文档扫描
这篇介绍Skill 的核心设计理念(渐进式披露)与文件规范、它与 MCP 及多 Agent 的本质区别、如何将现有项目(以数据治理工具包为例)进行 Skill 化改造,以及从投标书生成等长文档场景出发,探讨 Skill 在企业级交付中的产品化潜力。
Anthropic在25年12月18日宣布把Agent Skills 发布为开放标准,到现在刚一个多月时间里,Cursor、OpenCode、Antigrativy 等主流 AI 编程工具就已经完成了集成,GitHub 上星标也超过了 52k。
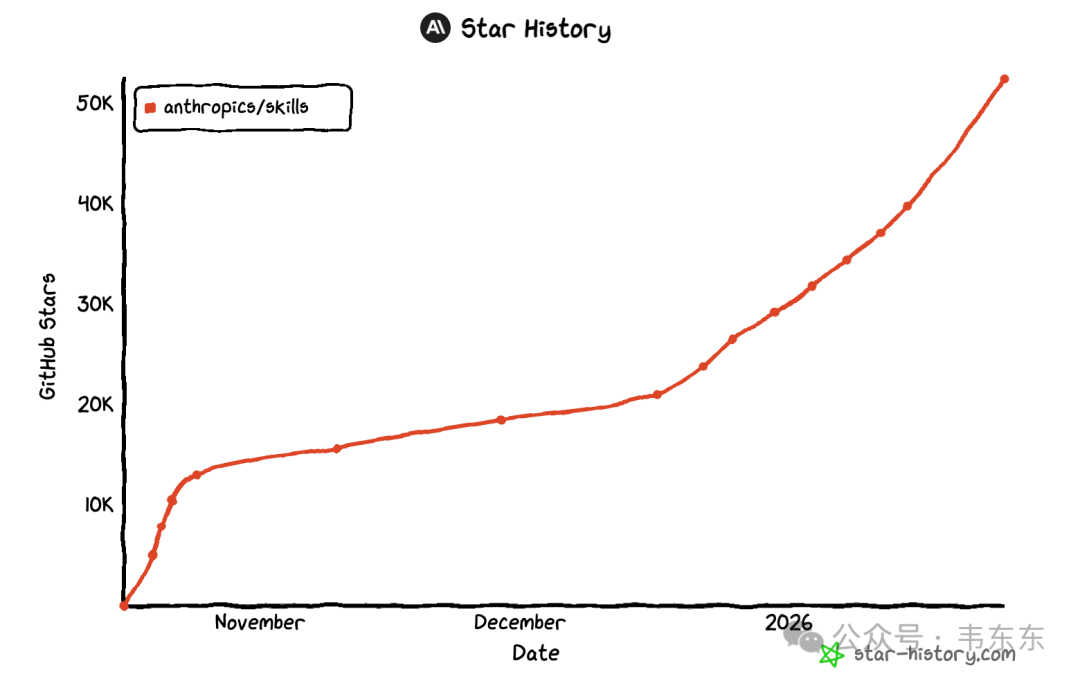
项目地址:https://github.com/anthropics/skills
刚发布那会儿我在忙着录制视频课程,一月初才来得及具体测试。起初先是跑了一遍 Reddit 和 X 上热议的几个开源项目,然后又在手头的知识库和数据治理项目里实际用了一段时间。目前用了两三周下来,整体感受是 Skills 解决的问题不新鲜(Prompt 管理、脚本复用),但它提供的抽象方式确实够简洁,一个文件夹、一份 Markdown、一套目录约定,就把让大模型记住怎么做某件事这个需求给标准化了。
市面上介绍Agent Skills 的文章不少,但大多停留在个人效率工具层面。这些玩法当然有用,但我更感兴趣的是另一个问题,就是 Skills 这套机制,在 2B 企业大模型应用里能怎么用?能不能把已有的业务脚本和工作流封装成 Skill,让非技术人员也能调用?
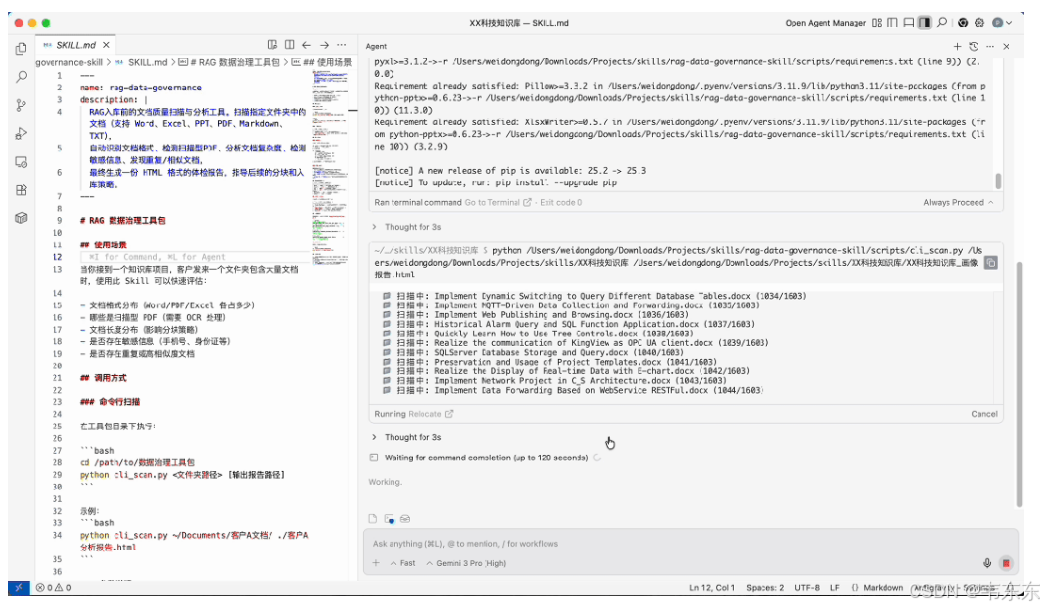
数据治理工具包 Skill 化使用效果
这篇试图说清楚:
Skill 的核心设计理念(渐进式披露)与文件规范、它与 MCP 及多 Agent 的本质区别、如何将现有项目(以数据治理工具包为例)进行 Skill 化改造,以及从投标书生成等长文档场景出发,探讨 Skill 在企业级交付中的产品化潜力。
以下,enjoy:
1、什么是 Agent Skills?
一句话定义:Agent Skills 是一套基于文件系统的 Prompt 工程化规范。说人话就是,它把让大模型记住怎么做某件事这个需求,抽象成了一个标准化的文件结构。核心我总结下来就三件事:
1、用一个文件夹来封装一个"能力";
2、用 Markdown 来描述这个能力的调用方式;
3、用 YAML 头部来做索引,让大模型知道什么时候该调用
规范本身很简单,没有复杂协议,不需要 SDK,任何支持文件读取的 Agent 都能实现。
1.1、为什么需要渐进式加载
渐进式加载是 Skill 设计里最核心的理念,也是它区别于传统 Prompt 管理方式的关键。
传统做法是把所有指令都塞进 System Prompt。问题在于上下文窗口是稀缺资源。假设你有 50 个 Skill,每个 2000 tokens,全塞进去就是 10 万 tokens,大模型还没干活,上下文就爆了。
但很多人聊上下文优化,第一反应是怎么压缩、怎么摘要、怎么用 RAG 只召回相关片段。这些当然有用,但从第一性原理出发,最有效的优化其实是"非必要不传入",也就是在源头上就把当前处理阶段模型不需要看到的内容排除掉。Skill 的渐进式加载,本质上就是这个思路的工程化落地。
Skill 的解决方案是三层按需加载:
|
层级 |
加载时机 |
内容 |
Token 消耗示例 |
|---|---|---|---|
|
第 1 层 |
Agent 启动时 |
YAML 头部的 name + description |
每个 50-100 tokens |
|
第 2 层 |
用户请求匹配时 |
SKILL.md 正文(完整指令) |
1000-2000 tokens |
|
第 3 层 |
执行过程中按需 |
references/ 里的详细文档 |
视情况而定 |
第一层相当于一份目录索引,模型看完就知道"有哪些能力可用"。只有当用户的请求和某个 Skill 的 description 匹配的时候,大模型才会去读取完整的指令。这样 50 个 Skill 的索引加起来也就 2500-5000 tokens,完全可接受。
1.2、文件结构与 SKILL.md格式
一个Skill就是一个文件夹,核心是 SKILL.md 文件:
my-skill/
├── SKILL.md # 核心:指令文件
├── scripts/ # 可选:可执行脚本
├── references/ # 可选:详细文档
└── assets/ # 可选:配置文件、Schema 等SKILL.md 的格式也很直接,开头是 YAML 头部,后面是 Markdown 正文:
---
name: data-analysis
description: 分析数据集并生成可视化报告,支持 CSV/Excel/JSON 格式。
---
# 数据分析 Skill
## 使用场景
...
## 执行流程
...这里有个关键点:description 的质量直接决定模型能否正确匹配到这个Skill。写 description 要像写函数签名一样,说清楚输入输出和适用场景。
1.3、不只是Prompt 管理:scripts/references/assets 的价值
如果只看 SKILL.md,可能会有盆友觉得这不就是把 Prompt 放到文件里管理,意义也不是很大。确实,纯文本指令的场景下,Skill 和传统的 Prompt 模板没有本质区别。
但 Skill 的真正价值在于它可以封装完整的工作流,不只是一段提示词,而是提示词 + 可执行代码 + 参考文档 + 配置文件的组合。这让它能覆盖从简单到复杂的各种场景:
|
场景复杂度 |
典型结构 |
示例 |
|---|---|---|
|
轻量级 |
只有 SKILL.md |
代码风格规范、PR 审查清单、文档模板 |
|
中等 |
SKILL.md+ references |
产品知识库问答(references 里放产品文档) |
|
重度 |
完整结构 |
数据治理工具包(27 个 Python 脚本 + 质量标签说明 + 阈值配置) |
以上篇文章介绍的数据治理工具包为例,进行Skill化之后,scripts/ 里放了文档解析、格式识别、质量评估等脚本;references/ 里放了质量标签的详细说明文档;assets/ 里放了输出报告的 JSON Schema。用户只需要说"帮我扫描这个文件夹的文档质量",模型读取 SKILL.md后知道该怎么调用脚本、怎么解读结果,整个流程一气呵成。
这就是 Skill 区别于普通 Prompt 模板的地方,它不是把复杂逻辑都塞进提示词让大模型理解,而是把执行逻辑外置到脚本、把领域知识外置到 references、把配置参数外置到 assets,SKILL.md只负责告诉模型这些东西在哪、怎么用。
1.4、发现与激活机制
Skill 的发现机制说白了就是目录扫描。Agent 启动时遍历指定目录(全局目录和项目目录),找到所有包含 SKILL.md 的文件夹,解析 YAML 头部,构建索引。(不同平台的目录约定略有差异)
全局目录放跨项目通用的 Skill,比如代码审查、文档生成;项目目录放特定项目的 Skill,比如某客户的数据治理规则。
激活流程也很简单直接:用户发消息 → 模型根据 description 判断匹配哪个 Skill → 读取完整 SKILL.md→ 按指令执行。
但有一点需要强调,就是原则上脚本代码不进入上下文,只有执行结果进入。这是上下文优化的关键。比如我在上篇文章中介绍的 RAG 入库前的文档扫描工具包,其中有 27 个 Python 脚本,全塞进 Prompt 大家要 5 万 tokens;但通过 Skill 机制,上下文只需要 SKILL.md(2000 tokens 左右)加上脚本的执行结果。
1.5、两种集成方式
Skill 有两种集成方式,选哪种取决于 Agent 的运行环境:
方式一:文件系统直读
适用于 Cursor、Claude Code 这类本地 IDE 环境。模型直接用 Shell 命令读取文件:
cat ~/.claude/skills/data-analysis/SKILL.md这是最灵活的方式,大模型可以自主决定读取哪些内容。
方式二:通过 Tool 调用
适用于 Web 应用(例如网页端的Claude)、API 服务等没有文件系统访问权限的场景。需要封装成 Tool 供模型调用,比如通过 MCP Server 提供 list_skills、get_skill_content 等接口。
两种方式的核心逻辑一样,只是访问路径不同。对于企业级应用,工具方式更常见,因为可以做权限控制、审计日志、远程 Skill 库等。
1.6、底层实现原理
虽然大家应该主要是在 IDE 里使用 Skill,但它的底层实现并不复杂,本质就是目录扫描 + 提示词注入 + 按需加载。核心代码逻辑大约 50 行:
# 1. 启动时:扫描目录,只读取 YAML 头部(name + description)
def discover_skills(skills_dir):
for folder in Path(skills_dir).iterdir():
skill_md = folder / "SKILL.md"
if skill_md.exists():
metadata = parse_frontmatter(skill_md) # 只读头部
skills.append(metadata)
return skills
# 2. 生成索引,注入到 System Prompt
available_skills_xml = generate_xml(skills) # <available_skills>...</available_skills>
# 3. 运行时:模型判断需要某 Skill 时,调用工具读取完整内容
if tool_name == "view_text_file":
content = Path(file_path).read_text() # 此时才加载完整 SKILL.md特别解释一下这个底层的原理,是想说明 Skill 机制不依赖任何特定 IDE,可以嵌入到任何后端服务里。大家完全可以在自己的大模型应用中实现同样的逻辑:目录扫描、元数据索引、按需加载,把 Skill 作为模块化知识与能力的封装形态。
2、官方 Skill 案例拆解:以 docx 为例
聊完核心概念,来看一个真实的 Skill 长什么样。Anthropic 在发布规范的同时,官方仓库里提供了 16 个参考实现。除此之外,GitHub 上也涌现出不少开源 Skill 库项目,热度很高。这篇我就针对官方的这 16 个 skill 做些盘点,它们按用途大致可以分成四类:
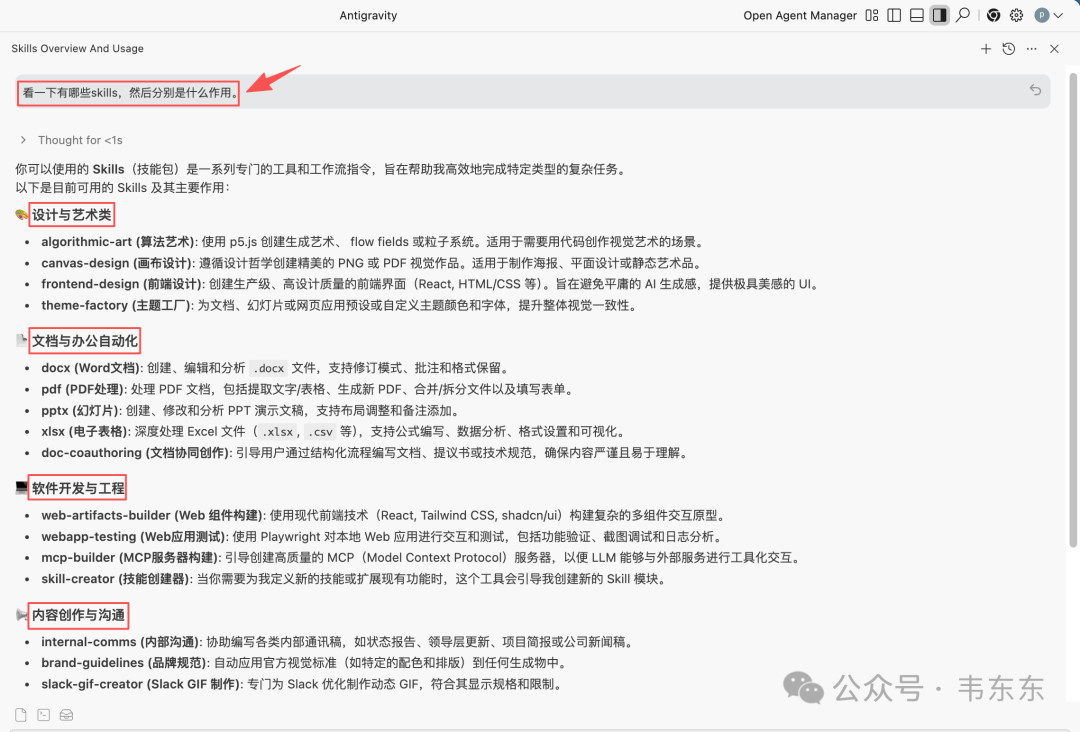
|
类别 |
Skills |
|---|---|
|
设计与艺术 |
algorithmic-art、canvas-design、frontend-design、theme-factory |
|
文档与办公 |
docx、pdf、pptx、xlsx、doc-coauthoring |
|
软件开发 |
web-artifacts-builder、webapp-testing、mcp-builder、skill-creator |
|
内容与沟通 |
internal-comms、brand-guidelines、slack-gif-creator |
从企业应用场景出发,文档处理类的 Skill 最有参考价值。我拿 docx(Word 文档处理)来做个拆解。
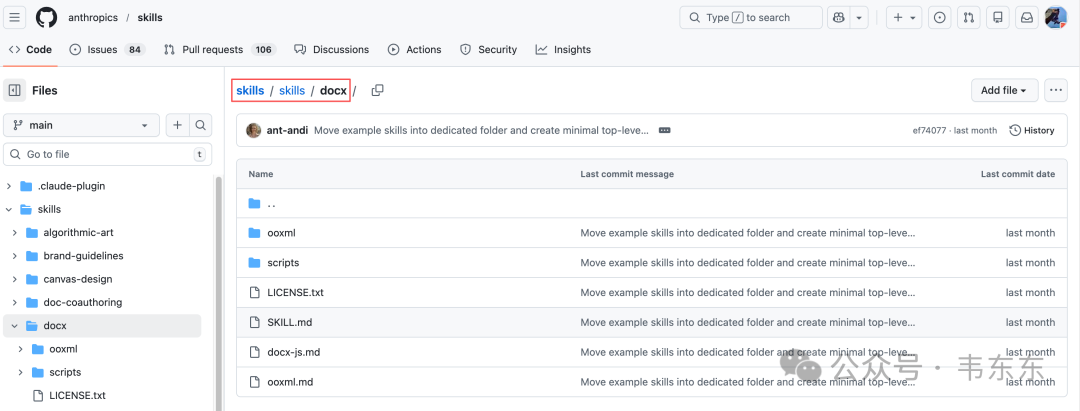
2.1、docx Skill 的文件结构
docx/
├── SKILL.md # 主指令文件(约 200 行)
├── docx-js.md # 参考文档:docx-js 库用法
├── ooxml.md # 参考文档:OOXML 格式详解
├── scripts/ # Python 脚本
│ ├── document.py # 文档操作库(5 万字符)
│ └── utilities.py # 工具函数
└── ooxml/
├── scripts/ # unpack.py、pack.py 等
└── schemas/ # XML Schema 定义这是一个相对重度的 Skill 结构。主指令文件 SKILL.md负责告诉大模型什么场景用什么工具,具体的技术细节则外置到 references(这个skill官方包里实际没有这个文件夹) 和 scripts 里。
2.2、SKILL.md的设计思路
打开 SKILL.md,开头是 YAML 头部:
name: docx
description: "Comprehensive document creation, editing, and analysis
with support for tracked changes, comments, formatting preservation,
and text extraction. When Claude needs to work with .docx files..."description 写得很具体,不是泛泛的处理 Word 文档,而是明确列出了能力边界:创建、编辑、分析、修订追踪、批注、格式保留、文本提取。这样大模型在匹配的时候就更精准。正文部分采用了决策树结构:
## Workflow Decision Tree
### Reading/Analyzing Content
Use "Text extraction" or "Raw XML access" sections below
### Creating New Document
Use "Creating a new Word document" workflow
### Editing Existing Document
- Your own document + simple changes → Basic OOXML editing
- Someone else's document → Redlining workflow (recommended)
- Legal, academic, business docs → Redlining workflow (required)这种设计不得不说很聪明,大模型不需要一次性理解所有内容,而是根据用户的具体需求,跳转到对应的章节。这也是渐进式披露思想在 SKILL.md 内部的应用。
2.3、脚本与参考文档的分工
SKILL.md里引用了两份核心文档:
docx-js.md:用于创建新文档,详细说明了 docx-js 这个 JS 库的用法
ooxml.md:用于编辑现有文档,详细说明了 OOXML 格式和 Document 库的 API
SKILL.md里写明了加载时机:
MANDATORY - READ ENTIRE FILE: Read `ooxml.md` (~600 lines)
completely from start to finish. Pay special attention to
"Document Library" and "Tracked Change Patterns" sections.注意这里说的是"completely from start to finish",对于复杂任务,大模型需要完整阅读参考文档,而不是只看片段。这其实是在教大模型怎么使用第三层内容。
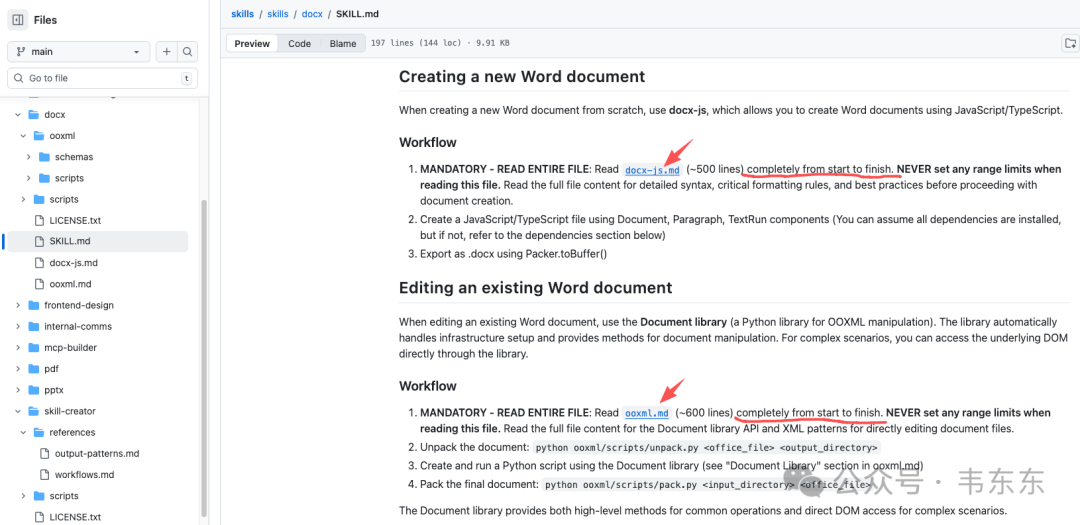
scripts目录下的 Python 代码提供了文档对象操作能力(如 document.py 提供 DOM 操作接口),而 ooxml/scripts/ 目录下则包含 unpack.py 和 pack.py 这样用于解压和重打包 docx 文件的底层工具。SKILL.md 告诉模型怎么调用这些脚本,但脚本代码本身不进入上下文。
2.4、一个典型的调用流程
假设用户说:"帮我把这份合同里的'甲方'全部改成'委托方',要有修订痕迹"
1、模型读取 SKILL.md,根据决策树判断这是"Editing Existing Document"场景
2、进一步判断是"Someone else's document",应该用 Redlining workflow
3、模型读取 ooxml.md,了解如何使用 Document 库和修订追踪的 XML 格式
4、执行脚本:先 unpack、再用 Python 脚本修改 XML、最后 pack
5、返回修改后的文档整个过程中,模型只需理解 SKILL.md的决策逻辑和 ooxml.md 的 API 说明,不需要看大约5万字符的 document.py源码。这就是 Skill 机制在复杂任务上的价值。
从这个官方示例可以看出,一个好的 Skill 设计核心就是把复杂度分层:description 写清楚能力边界让匹配更精准,正文用决策树结构让大模型按需跳转,执行逻辑和领域知识外置到 scripts 和 references 里。如果你在做企业大模型应用,财务报表处理、合同审核、技术文档生成这类场景,都可以参考这个结构来封装。
3、Skill vs MCP vs 多 Agent
聊完 Skill 本身,再来说说它和 MCP、多 Agent 是什么关系。这三个概念经常被混在一起讨论,但实际上解决的问题不太一样。我梳理了一个表格,尝试从下面五个维度给大家做个直观的对比:
|
维度 |
Agent Skills |
MCP |
多 Agent |
|---|---|---|---|
|
核心定位 |
程序性知识封装 |
外部系统连接器 |
复杂流程编排 |
|
解决问题 |
怎么做某件事 |
怎么获取外部数据 |
怎么协调多个任务 |
|
载体形态 |
Markdown + 脚本 |
JSON-RPC 协议 |
独立运行实体 |
|
状态管理 |
无状态 |
无状态 |
有状态 |
|
适用场景 |
标准化操作流程 |
实时数据获取 |
长流程、多轮交互 |
说人话就是:
Skill 是给 Agent 写的操作手册,告诉它遇到某类任务该怎么做;MCP 是外部系统的数据接口,让 Agent 能访问数据库、API、文件系统等;多 Agent 是分工协作机制,把复杂任务拆成多个子任务交给不同 Agent 处理
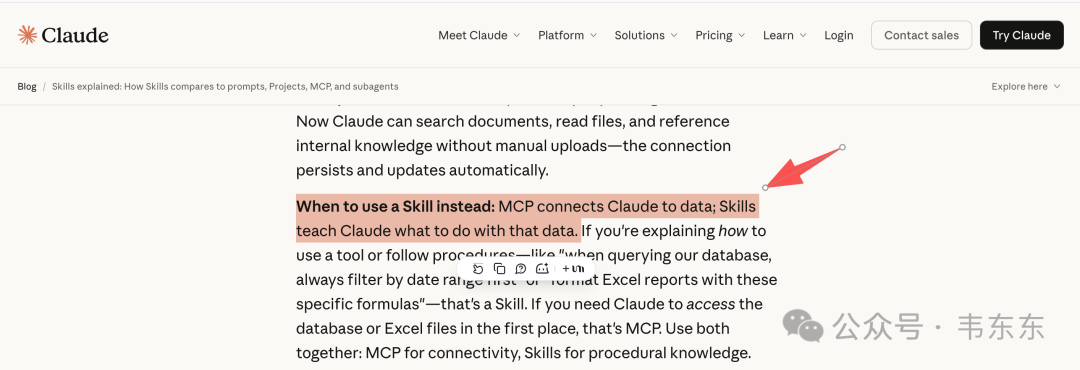
https://claude.com/blog/skills-explained
从企业大模型应用落地的角度来说,这三种技术可以组合使用:Skill 解决标准化流程复用问题,比如文档质量检测、代码审查、报告生成这类可以沉淀成 SOP 的任务;MCP 解决外部数据接入问题,让 Agent 能查数据库、调 API、读文件系统,这是企业应用的刚需;多 Agent 解决复杂流程编排问题,当任务涉及多个步骤、需要状态管理时,单个 Agent 搞不定
换句话说,在一个多 Agent 工作流里,某个子 Agent 可以调用 MCP 获取数据,然后用 Skill 里定义的标准流程来处理。这篇文章主要先介绍 Skill,MCP 和多 Agent 的搭配使用后续结合具体案例再展开。
4、把数据治理工具包 Skill 化
前面都是概念,这一部分来点实际的。我拿上篇文章介绍的一个 RAG 数据治理工具包来演示完整的 Skill 化过程。
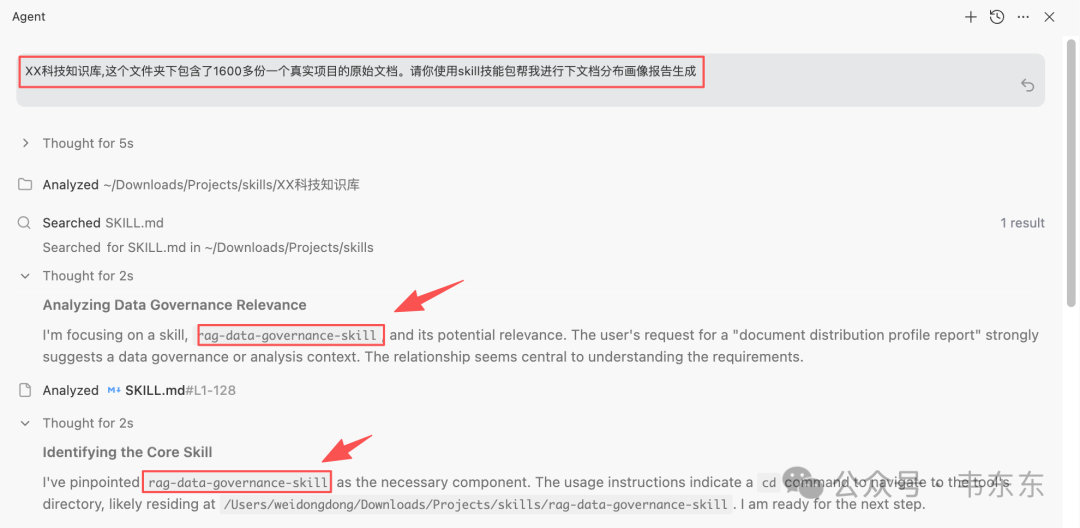
方便大家看到效果,这里的演示还是搭配 IDE(Antigravity)来操作,但在真实的生产环境里,Skill 机制并不依赖 IDE,本质是一个标准化入口,可以接到后端服务或编排系统里,前提是运行环境具备必要的权限和依赖。
4.1、项目背景
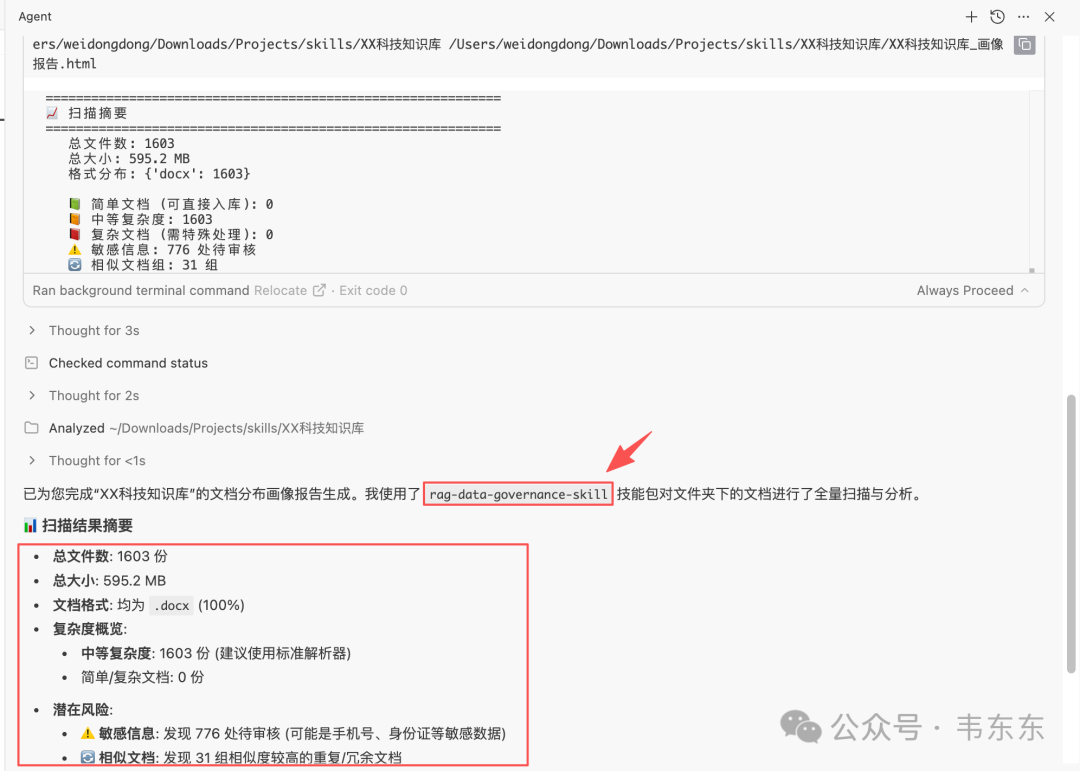
这个工具包是给知识库项目做的,具体项目背景在上一篇文章当中有详细说明了。这里就不再赘述。核心功能是在入库之前先做一次扫描和画像盘点,主要覆盖文档格式分布、扫描型 PDF 的识别与 OCR 标记、复杂度评估(纯文字/含表格/含图片)、敏感信息的初筛、相似/重复候选的识别,并生成一份 HTML 报告来指导后续的分块和清洗策略。
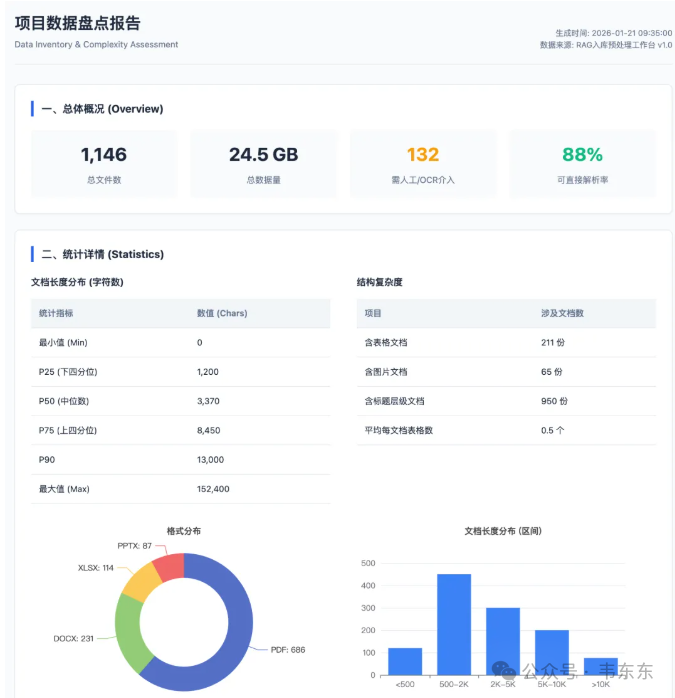
知识库文档入库扫描的HTML报告样图
4.2、Skill 化的核心改动
原来这个工具包是通过 Web UI 使用的:启动 FastAPI 服务,打开浏览器,点按钮扫描,再查看结果。但在 IDE + 大模型的场景下,我希望一句话调用,就是用户说“帮我扫描这个文件夹”,模型就能直接执行并返回结果。
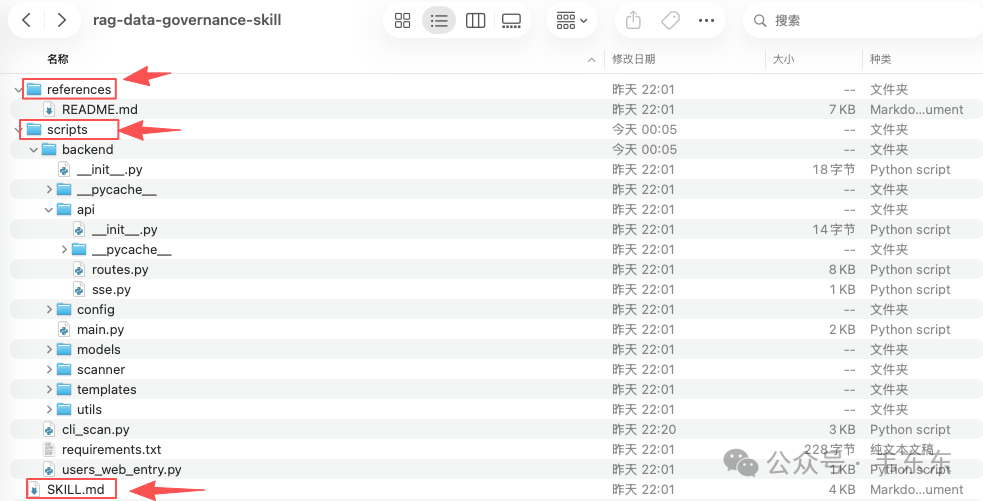
所以 Skill 化的改动主要集中在三个动作上:增加 CLI 入口、补齐 SKILL.md 、按平台规则注册到 Skill 目录。其中最关键的是新增 cli_scan.py,接受文件夹路径作为参数,调用原有 ScanPipeline,直接输出 HTML 报告。
下面是简化后的核心逻辑示意(省略参数校验与部分工具函数定义):
from pathlib import Path
import sys
from scanner.pipeline import ScanPipeline
from utils.export_utils import generate_export_html
def print_progress(msg):
print(msg)
def main():
input_dir = sys.argv[1]
output_file = sys.argv[2] if len(sys.argv) > 2 else "report.html"
template_dir = Path(file).parent / "backend" / "templates"
# 调用原有的扫描流水线
pipeline = ScanPipeline()
result = pipeline.start_scan(input_dir, progress_callback=print_progress)
# 生成 HTML 报告
html = generate_export_html(result, template_dir)
Path(output_file).write_text(html, encoding="utf-8")
# 输出摘要
print(f"✅ 报告已生成: {output_file}")这个 CLI 脚本复用了原有的主流程和核心模块,只是换了一个更适合自动化调用的入口。与此同时,SKILL.md 用来告诉模型“这个工具包能做什么、怎么调用”:
---
name: rag-data-governance
description: |
RAG入库前的文档质量扫描与分析工具。扫描指定文件夹中的文档,
自动识别格式、检测扫描型PDF、分析复杂度、检测敏感信息、
发现重复文档,生成 HTML 格式的扫描报告。
---正文里把使用场景、调用方式(如 python cli_scan.py <路径> [输出文件])、输出说明(终端摘要 + HTML 报告)、支持的文档格式、质量标签含义以及配置调整方式都写清楚。最后把整个工具包注册到平台会扫描的 Skill 全局目录,让大模型能稳定发现并调用:
cp -r 数据治理工具包 ~/.gemini/antigravity/global_skills/rag-data-governance或者在项目目录下使用,只要运行环境会扫描该路径,模型也能发现。Skill 化之后,使用流程就变成了“用户一句话提出扫描需求,模型识别对应 Skill,读取 SKILL.md 获取命令,执行扫描脚本并返回摘要和报告路径”,全程不需要手动操作 Web UI。
通过这个案例也想说明,尽量提供 CLI 入口以便自动化调用,优先产出 HTML/JSON/Markdown 等可复用文件而不是只在终端打印,复用原有主流程而不是重写项目,并在 SKILL.md 里把命令、参数、输出位置和注意事项写清楚,这样模型才能稳定、可控地使用。
5、从投标书生成看 Skill 的行业价值
写到这里,我想跳出技术细节,聊聊 Skill 对行业应用(尤其是 ToB 交付)的真正价值。我之前做过不少类似的长文档生成项目,像银行的信贷尽调报告、法律行业的合同生成,还有环保行业的环评报告。这些场景听起来行业跨度很大,但技术底座其实都差不多。无非就是先把长文档拆成若干个小章节,写好每一章的模板,然后用"RAG(找素材)+ 规则引擎(算数据)+ 大模型"一段段生成,最后再拼起来。这个路子跑通了很多遍,能生成,质量也还行。
最近在做一个投标书生成项目的时候,我一直在思考产品化的问题:当面对有类似需求但场景不同(如投软件、投硬件、投服务)的客户时,原有的那套把逻辑写在 Workflow 里的方法暴露出了一些局限性,换句说每接一个新客户,就得把核心代码改一遍,功能边界很难定义,交付也变得比较重。而在思考技术架构怎么设计才能更好复用时,Skill 这种能力包的形态提供了一些新的思考方向。
5.1、解决的不是生成问题,而是复用问题
按之前的做法,逻辑是写在代码里的。比如做"软件开发类"标书,在代码里硬编码了很多软件工程的规范、引用了特定的检索库。这时候如果来了个"硬件集采类"的标书项目,虽然大流程一模一样(都是分章生成),但因为领域知识变了,就得去改代码、换 Prompt、重新部署一套环境。这意味着每做一个新行业,边际成本并没有明显降低。
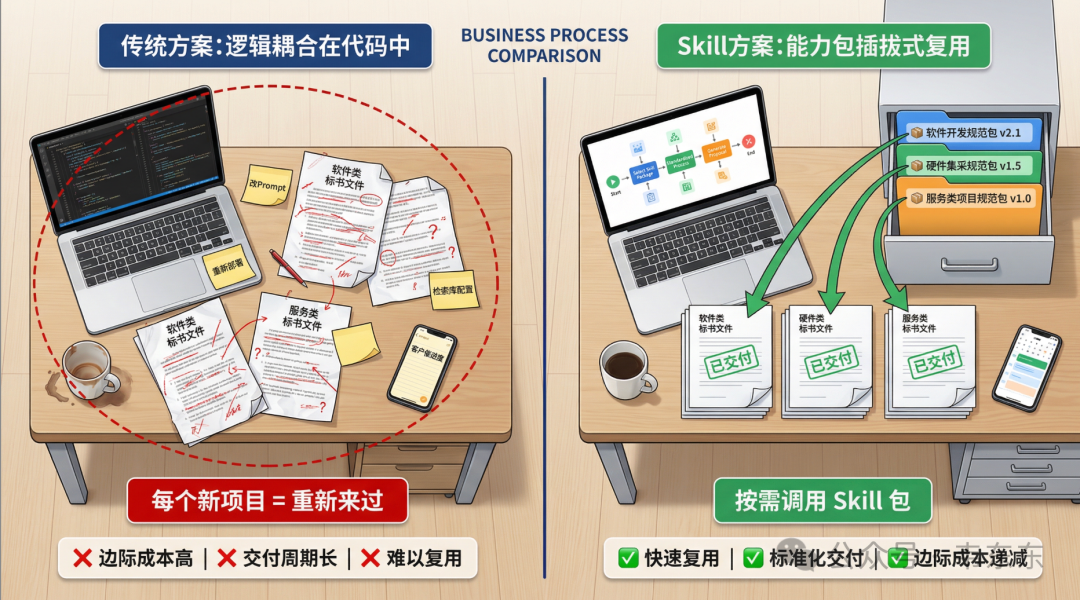
我在尝试用 Skill 改造这个环节,思路是把领域知识从代码里剥离出来,封装成一个个独立的 Skill 包。比如做一个 bid-software-spec 的 Skill,里面放软件开发的规范;再做一个 bid-hardware-spec 的 Skill,放硬件参数校验规则。这样核心的 Workflow 代码就可以保持稳定,遇到同类但不同领域的项目时,只需要挂载不同的 Skill 包。
当然,这本质上还是软件工程里"配置化/插件化"的新瓶装旧酒。但 Skill 的独特之处在于,它是一种自然语言驱动的配置,大模型能读懂、能按需加载的技能包,这比传统的 JSON 配置要灵活得多。
它虽然不能直接变身标准化产品,但确实提供了一种"领域知识与流程代码解耦"的可行路径,让"同一套代码 + 不同的技能包"成为可能。这在面对同一场景下(如长文档生成)跨客户、跨行业的复用难题,也确实多了一种更轻量的解法。
5.2、在长文档生成中的三个具体落点
既然在尝试 Skill 化,具体应该怎么切分?在投标书生成这个场景里,目前初步探索下来有三个环节比较适合用 Skill 来进行结构化封装。
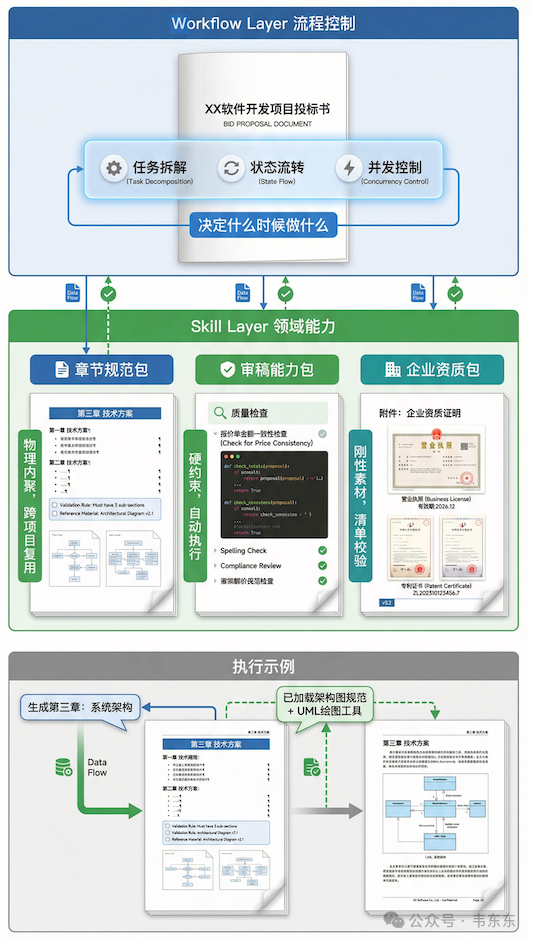
章节规范包
在固定格式的长文档生成场景里,业界早也有了"分章节、分 Prompt"的生成做法。而 Skill 的主要价值并不在于分治,而是提供了一种物理内聚的打包方式。说人话就是,以前这些规则往往分散在代码配置、数据库字段或者 Prompt 模板库里,迁移一个章节很麻烦。现在 Skill 把单一章节所需的 Prompt、校验规则、素材文件全部放在一个文件夹里。这种所见即所得的物理结构,让跨项目的规则变成了可复用模块。
审稿能力包
审稿环节往往依赖业务专家的经验(比如"报价单金额必须与正文一致")。这部分可能会有盆友想,这不就是把规则塞进知识库让 RAG 召回吗?个人认为,这里的区别在于 RAG 本身不执行校验,必须依赖后续校验逻辑;而 Skill 可以封装具体的检查脚本或工具(硬约束)。比如写一个 Python 脚本去自动比对正文和报价单的数字。Skill 的价值在于把老师傅觉得这里容易出错的经验,变成了一段能自动跑起来的代码,比纯靠大模型自觉要靠谱得多。
企业资质包
写投标书的时候,营业执照、专利证书、客户案例等都属于必须绝对准确的刚性素材。在没有 Skill 之前,我倾向于用“资产库 + 元数据治理 + 版本控制 + 模板绑定”的组合:资质文件有唯一 ID、有效期、项目归属等字段,正文通过占位符或字段绑定引用,检索更多是辅助入口,并配合强过滤与人工校验。这样可以把误用/错用的风险控制在流程层面,而不是寄希望于语义召回的准确率。
而 Skill 可以把这套做法进一步产品化,就是把特定项目所需的资质与规则打包成可复用的资产包,模型生成到对应章节时按清单读取并校验,减少歧义入口、提升可追溯性和审计性。它不是替代所有治理手段,而是提供一个更工程化、可复用的载体。
5.3、Workflow vs Skill:编排与能力的关注点分离
最后关于架构设计,还有个问题需要厘清,就是 Skill 和 Workflow 到底以谁为主?
在目前的实践中,我更倾向于把核心控制权放在 Workflow(编排系统)这一侧,但不同团队也可能会采用 Agent 驱动的架构(让 Agent 自主决定调用哪些 Skill 以及执行顺序)。Workflow 通常负责全流程的任务拆解、状态流转和并发控制(或者至少负责流程描述),而 Skill 更像是被剥离出来的领域能力层,里面既有知识,也有工具和校验逻辑。人工编排好的 Workflow 决定什么时候做,Skill 提供做什么所需的上下文和工具。比如主流程决定现在要生成"系统架构章节",就去调用架构师 Skill,加载架构图规范和绘图工具。
这种"流程编排与领域能力分离"的架构,带来的最大好处之一是让 Workflow 变轻量了些。Workflow 回归纯粹的流程控制,而繁杂多变的业务细节被下沉到了一个个独立的 Skill 包里。当然,前提是 Skill 有清晰的接口和版本治理,这种架构清晰度才能成为工程维护性的关键保障。
6、写在最后
抛开技术细节换个角度看 Skill,让我想起当年的 Docker。Docker出来之前,国内大厂其实早就基于 Linux 的 cgroups/namespaces 做过资源隔离与部署体系,只是一直缺一套被行业广泛接受的交付格式与工作流标准。但为什么最后是 Docker 成了行业标准?因为它定义了一套所有人都认的镜像格式和交付流程,把复杂的运行环境封装成了一个标准包,谁拿到都能跑。
今天的 Skill 和 MCP,非常像当年的 Docker。大模型、RAG、Prompt 这些技术大家都会,但怎么把这些能力封装好、分发出去、让别人的系统能直接用,一直缺乏标准。Anthropic 现在做的,就是在定义大模型时代的 Dockerfile。在这个视角下,Skill 给做企业应用的从业者带来的启发也很明显了:交付的终局不是交付代码,而是把行业 Know-how 封装成能被下一个项目直接调用的 Skill 包。
这种标准化的价值在于,它提供了一个通用的业务载体。现在的 AI Coding 已经非常成熟,理论上80% 以上的项目代码实现都可以交给大模型 24 小时去跑。当 Skill 解决了怎么封装的问题,而 AI Coding 搞定了怎么写代码的问题,作为从业者应该腾出手来更多去关注业务逻辑本身,也就是那些必须由人来做的设计选型、复杂的数据预处理,以及在预算、工期等现实约束下的一期二期规划。
换句话说,真正的壁垒不再是代码写得有多快,而是能不能在这些约束条件下,把那 3-5 个核心场景里的行规、经验、窍门,提炼并封装进这一套能被大模型完美执行的 Skill 里。对业务场景的深刻理解与抽象,才是从能做项目到能做产品的真正跨越。
项目源代码包已上传至星球和视频教程中,欢迎一线从业中加入星球交流《企业大模型应用从入门到落地》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 40
40 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)