SQL 的执行过程你了解吗?从客户端到磁盘,一条 SQL 到底经历了什么?
摘要:本文详细解析了MySQL中SQL语句的完整执行流程,包含8个核心阶段:连接器→解析器→预处理器→优化器→执行器→存储引擎→返回结果。重点分析了优化器的索引选择、执行器的数据过滤机制,以及存储引擎的磁盘IO问题。文章提供了SpringBoot中的优化建议,包括使用EXPLAIN分析执行计划、监控BufferPool命中率等,并对比了无索引和有索引查询的性能差异,指出90%的SQL性能问题源于优
视频看了几百小时还迷糊?关注我,几分钟让你秒懂!
在 Spring Boot 开发中,你是不是经常这样写代码:
User user = userMapper.selectById(1001);
然后数据库就“神奇地”返回了结果。
但你有没有想过:
这条 SQL 从 Java 应用发出,到最终拿到数据,中间到底经历了哪些步骤?
为什么有时候快如闪电,有时候慢如蜗牛?
今天我们就深入 MySQL 内部,手把手拆解 SQL 的完整执行流程,并告诉你:
- 哪些环节最容易出性能问题?
- 如何针对性优化?
- 为什么
EXPLAIN能帮你“透视”执行过程?
一、整体流程图(先看全景)
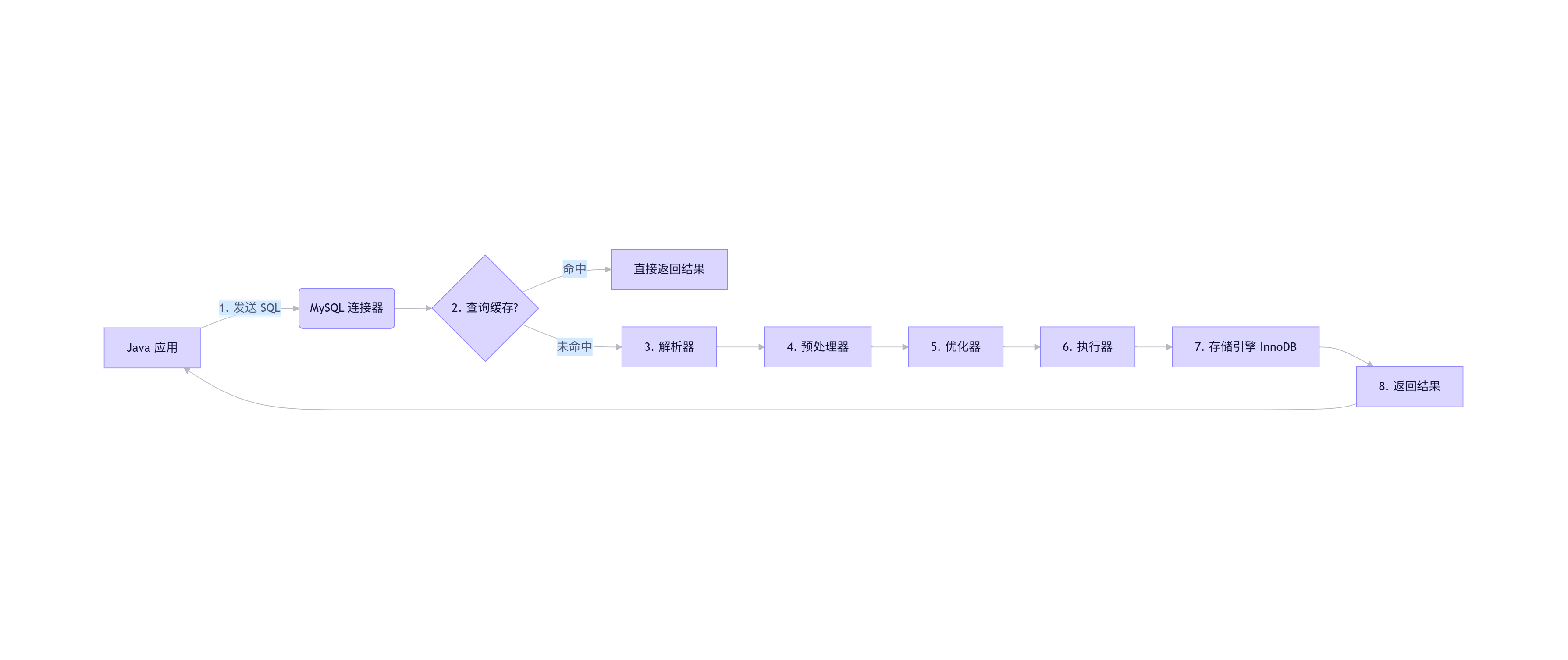
⚠️ 注意:MySQL 8.0 已移除查询缓存!所以第 2 步在新版本中不存在。
二、详细拆解:8 大核心阶段
阶段 1️⃣:连接器(Connector)
- 作用:建立连接、校验账号密码、管理权限
- 关键点:
- 连接会保持(即使 idle),直到超时(
wait_timeout默认 8 小时) - 权限在连接时确定,中途修改权限需重连才生效
- 连接会保持(即使 idle),直到超时(
- 常见问题:
Too many connections→ 连接池过大或未释放- 权限变更不生效 → 忘记重连
✅ Spring Boot 建议:使用 HikariCP 等连接池,避免频繁创建连接。
阶段 2️⃣:查询缓存(Query Cache)【MySQL 8.0+ 已废弃】
- 作用:缓存
SQL语句 -> 结果的映射 - 为什么被废弃?
- 表只要一更新,所有相关缓存全部失效
- 高并发下锁竞争严重
- 结论:不要依赖查询缓存!用 Redis 等外部缓存替代。
阶段 3️⃣:解析器(Parser)
- 作用:将 SQL 字符串转为解析树(Parse Tree)
- 做两件事:
- 词法分析:识别关键字、表名、字段等(如
SELECT、user、id) - 语法分析:检查 SQL 是否符合语法规则
- 词法分析:识别关键字、表名、字段等(如
- 报错示例:
SELECT * FORM user; -- 词法错误(FORM 不是关键字) SELECT * FROM user WHERE; -- 语法错误(WHERE 后缺条件)
💡 这就是为什么你写错 SQL 会立刻报错,还没到执行阶段!
阶段 4️⃣:预处理器(Preprocessor)
- 作用:进一步语义检查
- 检查内容:
- 表和字段是否存在?
- 用户是否有权限访问?
- 别名是否重复?
- 举例:
SELECT name FROM users; -- 如果 users 表不存在,这里报错
✅ 注意:权限检查在连接时 + 预处理时各做一次!
阶段 5️⃣:优化器(Optimizer)—— 性能关键!
- 作用:决定“怎么执行”这条 SQL(不是“是否执行”)
- 核心任务:
- 选择索引(
idx_user还是idx_time?) - 决定 JOIN 顺序(先查 A 表还是 B 表?)
- 是否使用临时表、文件排序?
- 选择索引(
- 输出:执行计划(Execution Plan)
🔍 举个例子:
SELECT * FROM orders o
JOIN users u ON o.user_id = u.id
WHERE u.city = '北京' AND o.status = 1;
优化器要决定:
- 先查
users(过滤 city='北京')再 JOINorders? - 还是先查
orders(过滤 status=1)再 JOINusers? - 用哪个索引更快?
✅ 这就是
EXPLAIN展示的内容!
阶段 6️⃣:执行器(Executor)
- 作用:调用存储引擎接口,真正执行查询
- 流程:
- 根据优化器的计划,调用 InnoDB API
- 逐行读取数据(可能走索引,可能全表扫描)
- 应用
WHERE条件过滤(Server 层过滤) - 组装结果集
- 关键点:
- 执行器工作在 MySQL Server 层
- 存储引擎(如 InnoDB)只负责数据存取
🌰 举例:
SELECT name FROM users WHERE age > 18;
- 如果
age有索引:执行器调用 InnoDB 的索引扫描 - 如果没索引:执行器让 InnoDB 全表扫描,每行返回给 Server 层判断
age > 18
💥 这就是为什么“没索引会慢”——因为要回表 + Server 层过滤!
阶段 7️⃣:存储引擎(Storage Engine)—— InnoDB
- 作用:真正读写磁盘数据
- InnoDB 特性:
- 支持事务、行锁、MVCC
- 数据按 聚簇索引(主键) 组织
- 使用 Buffer Pool 缓存数据页
- 关键流程:
- 先查 Buffer Pool(内存)
- 没命中 → 从磁盘加载数据页到 Buffer Pool
- 返回记录给执行器
✅ Buffer Pool 命中率越高,查询越快!
阶段 8️⃣:返回结果
- 执行器把结果集通过连接器返回给客户端
- 客户端(如 JDBC)解析成 Java 对象
三、Spring Boot 中如何观察这个过程?
1. 用 EXPLAIN 看优化器决策
@Select("EXPLAIN SELECT * FROM users WHERE age > 18")
List<Map<String, Object>> explainQuery();
重点关注:
type:是否全表扫描?key:用了哪个索引?Extra:有没有Using filesort?
2. 开启慢查询日志(定位性能瓶颈)
-- 查看是否开启
SHOW VARIABLES LIKE 'slow_query_log';
-- 开启(临时)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 超过 1 秒记录
日志会记录:
- 实际执行时间
- 扫描行数
- 是否使用临时表
3. 监控 Buffer Pool 命中率
SHOW ENGINE INNODB STATUS;
-- 或
SELECT
(1 - (Innodb_buffer_pool_reads / Innodb_buffer_pool_read_requests)) AS hit_rate
FROM information_schema.GLOBAL_STATUS
WHERE Variable_name IN ('Innodb_buffer_pool_reads', 'Innodb_buffer_pool_read_requests');
✅ 命中率应 > 99%,否则需增大 innodb_buffer_pool_size。
四、反例 vs 正例:优化前后对比
❌ 反例:无索引 + 全表扫描
-- users 表 100 万行,age 无索引
SELECT * FROM users WHERE age = 25;
执行过程:
- 优化器:没索引可用 → 选择全表扫描
- 执行器:让 InnoDB 逐行读 100 万行
- Server 层:每行判断
age=25 - 结果:耗时 2 秒,CPU 飙升
✅ 正例:加索引后
CREATE INDEX idx_age ON users(age);
执行过程:
- 优化器:选择
idx_age索引 - 执行器:调用 InnoDB 索引查找,只读 100 行
- 结果:耗时 10 毫秒
五、总结:SQL 执行流程速记口诀
连 → 解 → 预 → 优 → 执 → 引 → 返
(连接器 → 解析器 → 预处理器 → 优化器 → 执行器 → 存储引擎 → 返回)
| 阶段 | 关键问题 | 优化方向 |
|---|---|---|
| 连接器 | 连接数过多 | 用连接池 |
| 优化器 | 没走索引 | 建合适索引 |
| 执行器 | 回表太多 | 用覆盖索引 |
| 存储引擎 | 磁盘 IO 高 | 增大 Buffer Pool |
记住:90% 的 SQL 性能问题,都出在“优化器选错计划”或“存储引擎 IO 太高”!
视频看了几百小时还迷糊?关注我,几分钟让你秒懂!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 33
33 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)