Java大模型应用开发day07-天机ai-学习笔记
--Day07--SpringAI高级与私有大模型
--今日任务
- 了解什么是MCP
- 基于SpringAI实现MCP Client
- 基于SpringAI实现MCP Server
- 基于SpringAI实现多模态大模型
- 基于SpringAI实现大模型的格式化输
--1.SpringAI-MCP
--1.1什么是MCP
MCP(Model Context Protocol )叫作模型上下文协议,是一种标准化协议,它能够使 AI 大模型以结构化的方式与外部工具和资源进行交互。它支持多种传输机制,以在不同环境中提供灵活性。
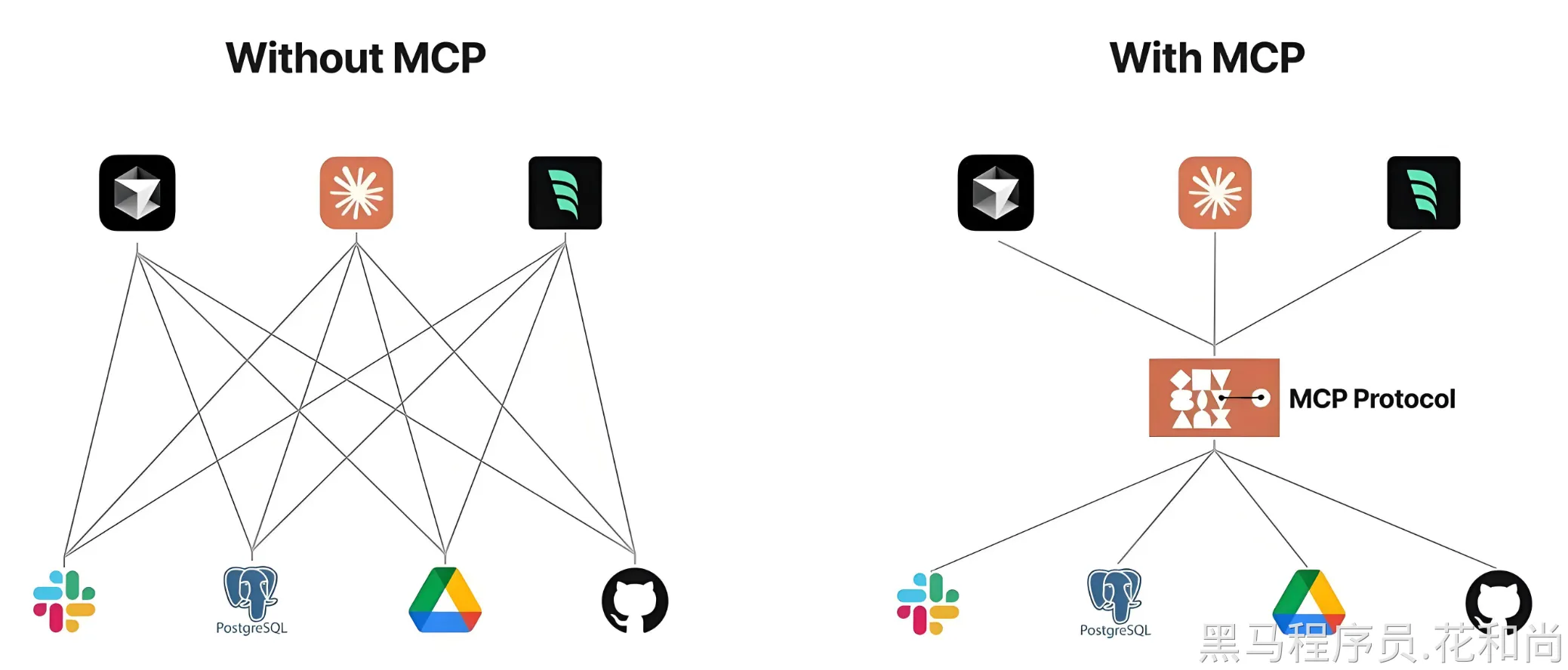
由上图,可以看出,在Java应用程序中,通过MCP Client可以与各种的MCP Server进行交互,增强了AI大模型的能力。
看上去,似乎和Tool Calling差不多,也是增强大模型的能力,不同的是,MCP是标准,更通用。
举两个场景来说明:
- 在SpringAI中编写的Tools,可以放到Python中使用吗?,显然是不可以的,要想让Python中使用,就得使用Python语言重写一次Tool,才能使用,这就是不通用性的体现。
- 在企业项目开发中,我们采用了Spring AI框架来构建智能体。这些智能体通常需要执行一系列通用功能,如天气查询、商品检索及下单等。基于以往的做法,每当开发新项目时,都需要重新编写实现这些功能的工具(Tool),这显然不利于代码复用。为解决这一问题,可以采用MCP标准进行服务器端开发,并将这些常用工具封装成服务接口。这样一来,其他的智能体只需通过调用该服务即可轻松访问所需功能,从而极大地提高了代码的复用性和开发效率。
MCP 就是 “Model-Call-Protocol”,简单来说就是让模型自己去执行任务的一种机制。你给它一个请求,它可以自己理解意图,然后去处理或者调用其他能力来完成。就像你让一个智能助手帮你查信息,它能自己决定要查哪张表、调用哪个 API,然后给你结果。
Tool Calling 更像是 你手动告诉模型该用哪个工具。也就是说,你把“工具”和“调用方式”都明确交给模型,它只负责按照指令去调用。MCP 更智能一些,它可以自主决定用哪个工具或服务去完成任务,不用你每次指定。
用一个比喻:
Tool Calling → 你给模型一把锤子,说:“去钉钉子。”
MCP → 模型自己看情况,可能拿锤子,也可能拿螺丝刀,甚至顺手去找钉子或者螺丝,总之把事情搞定。
--1.2技术架构
SpringAI对MCP做了支持,简化了Java项目中的MCP开发。参考文档:
--1.2.1MCP client
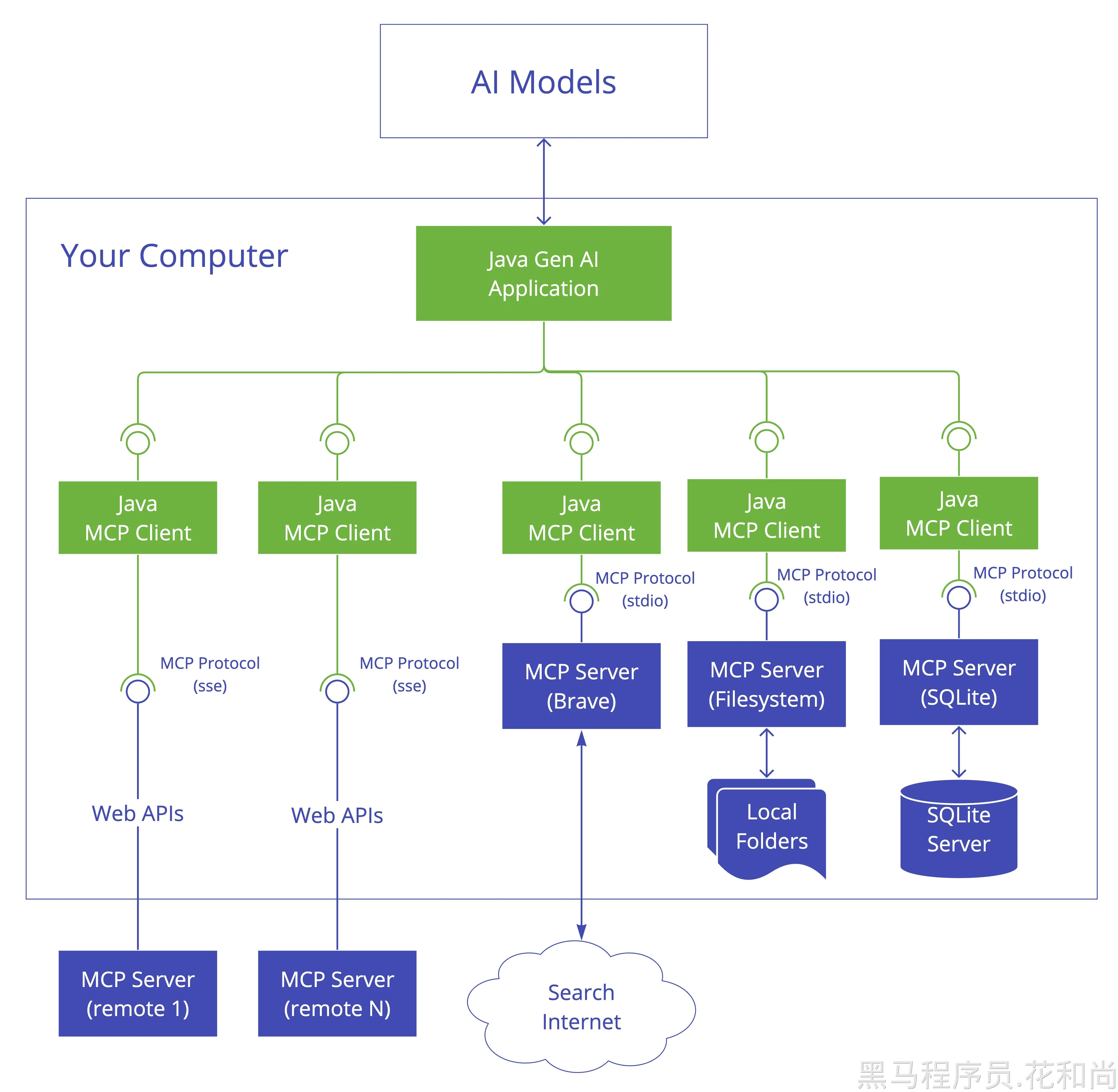
MCP Client 负责建立和管理与 MCP 服务器之间的连接,以及管理:
- 协议版本协商以确保与服务器的兼容性
- 功能协商以确定可用特性
- 消息传输和 JSON-RPC 通信
- 工具发现与执行
- 资源访问与管理
- 提示系统(Prompt )交互
- 可选功能:
- 根管理
- 采样支持
- 同步和异步操作
- 传输选项:
- 基于标准输入输出(stdio)的进程间通信传输
- 基于 Java HttpClient 的 SSE 客户端传输
- 用于响应式 HTTP 流的 WebFlux SSE 客户端传输
--1.2.2MCP Server
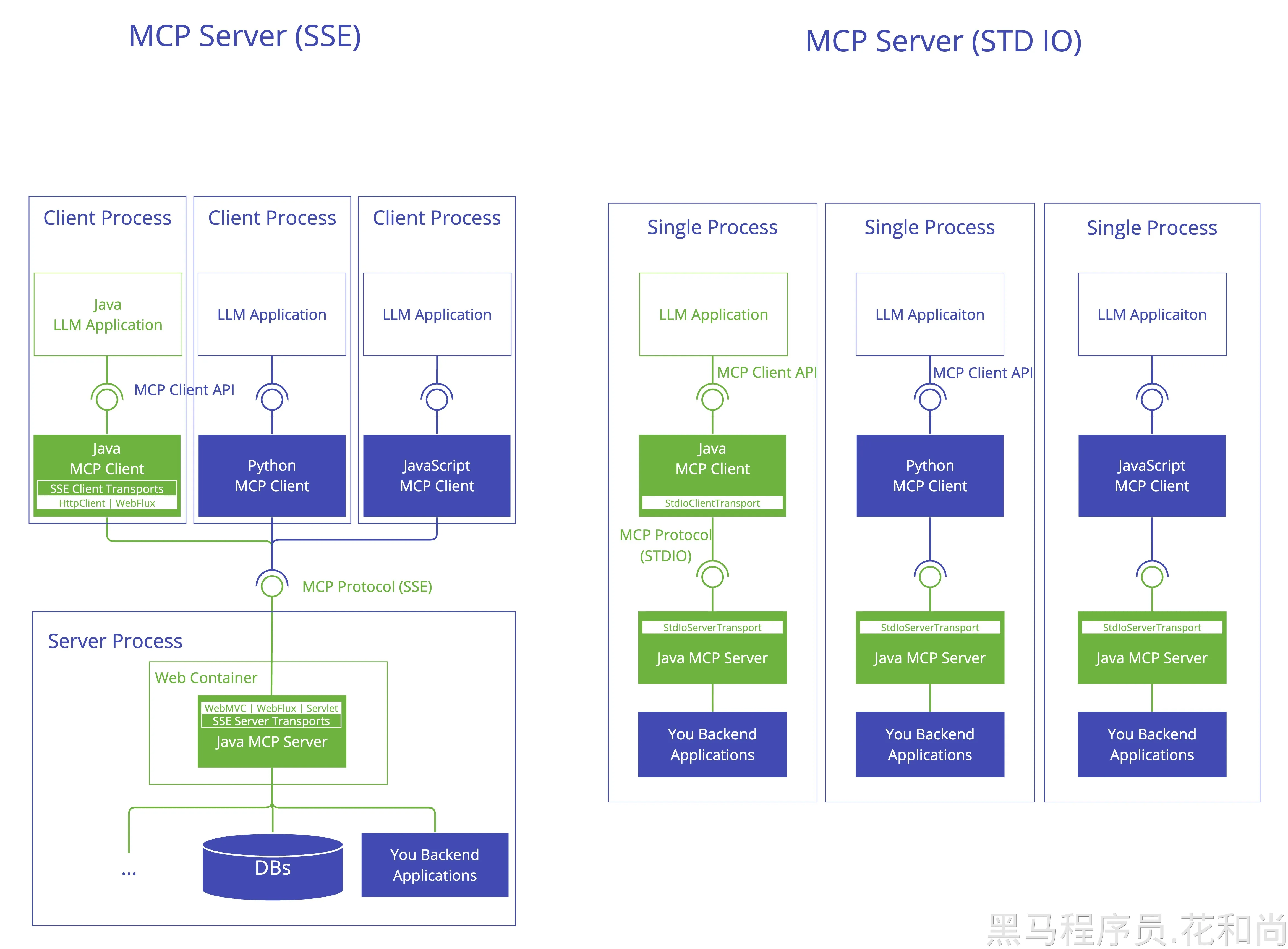
- 服务器端协议操作实现
- 工具暴露与发现
- 基于URI的资源管理
- 提示模板提供与处理
- 与客户端的能力协商
- 结构化日志记录和通知
- 并发客户端连接管理
- 同步和异步API支持
- 传输实现:
- 基于标准输入输出(stdio)的进程间通信传输
- 基于Servlet的SSE(服务器发送事件)服务器传输
- 用于响应式HTTP流的WebFlux SSE服务器传输
- WebMVC SSE 服务器传输,用于基于 Servlet 的 HTTP 流式传输
--1.3MCP Client实战
下面我们将基于SpringAI的MCP功能进行对MCP的Client进行学习。
--1.3.1功能需求
现在我们需要给AI大模型增强2个功能:
- 打开浏览器,浏览网页,进行总结网页中的内容
-
- 提问:
打开网站:https://www.bilibili.com/,总结下这个网站的内容
- 提问:
- 输入一个ip地址,让大模型解析出这个ip地址的所在地
-
- 提问:
查询ip所在地:223.11.151.238
- 提问:
显然,大模型如果不做增强的话,是做不到的,下面我们就基于MCP进行实现。
--1.3.2 初始工程
通过老师的链接拉取代码,并更改配置为自己所用,保证基本对话功能可用
--1.3.3实战1:控制浏览器
我们的需求是,给大模型提问:打开网站:https://www.bilibili.com/,总结下这个网站的内容,就会进行相应的操作。
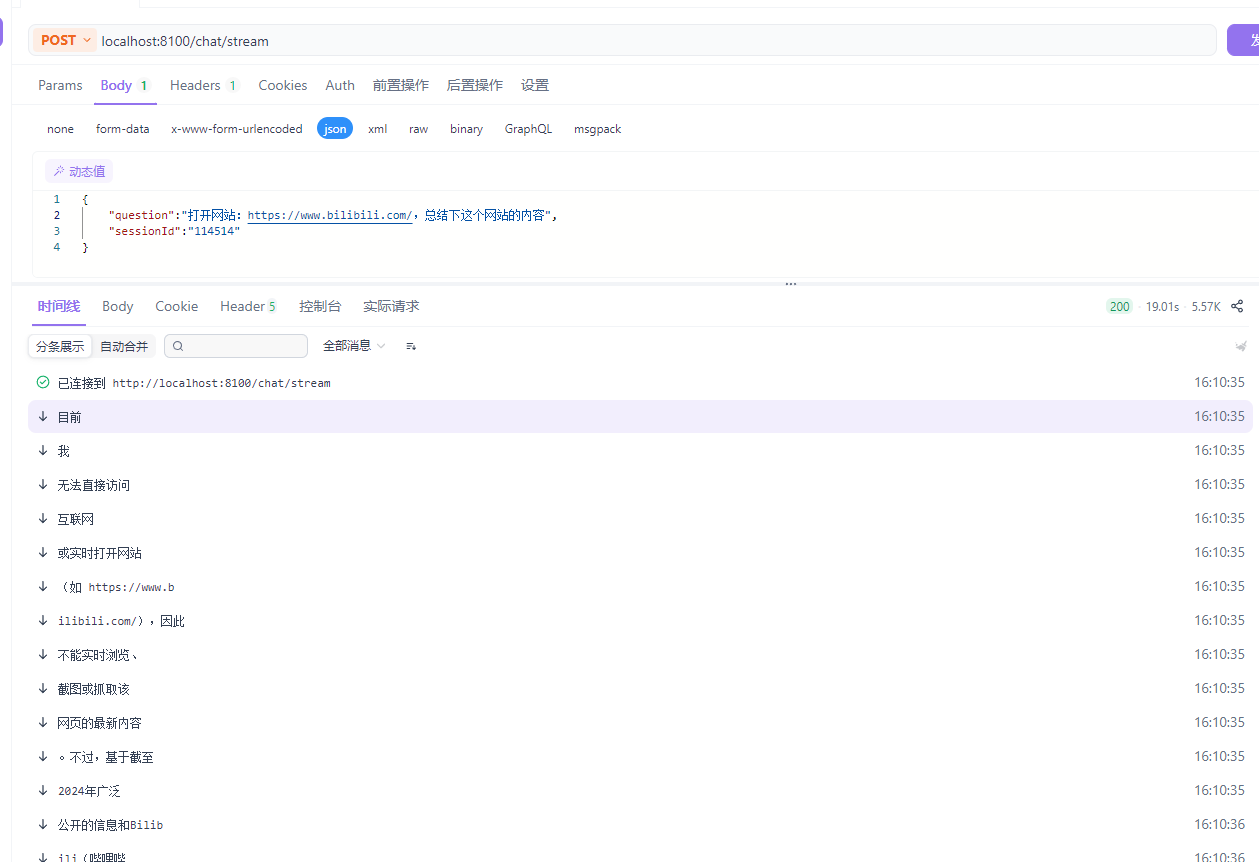
默认他是干不了的,下面我们来增强这个大模型
第一步,先在本机通过npm安装@executeautomation/playwright-mcp-server,如下:

#使用国内源安装命令:
npm install -g @executeautomation/playwright-mcp-server --registry=https://registry.npmmirror.com第二步,在项目中增加依赖:
<!--SpringAI-MCP-Client-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>第三步,在resource包下增加mcp-servers.json文件:
{
"mcpServers": {
"playwright": {
"command": "npx.cmd",
"args": [
"-y",
"@executeautomation/playwright-mcp-server"
]
}
}
}这一步,一定要确定在cmd命令行中,能够执行npx命令,如果不能执行,重新安装nodejs:
第四步,在application.yml中Spring.ai层级下增加MCP的配置内容:
我不知道为什么toolcallback的配置项idea没有自动提示吓我一跳
mcp:
client:
enabled: true #启动mcp客户端
name: ${spring.application.name} #客户端名称
version: 1.0.0 #客户端版本号
request-timeout: 30s #请求超时时间
toolcallback:
enabled: true #启用工具回调自动配置
stdio:
servers-configuration: classpath:mcp-servers.json第五步,在SpringAIConfig中配置Tools
/**
* 创建并返回一个ChatClient的Spring Bean实例。
*
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
ToolCallbackProvider tools
) {
return builder
.defaultSystem(SYSTEM_PROMPT) // 设置默认的系统角色
.defaultTools(tools) // 设置默认的工具
.build();
}第六步,重启服务,进行测试:
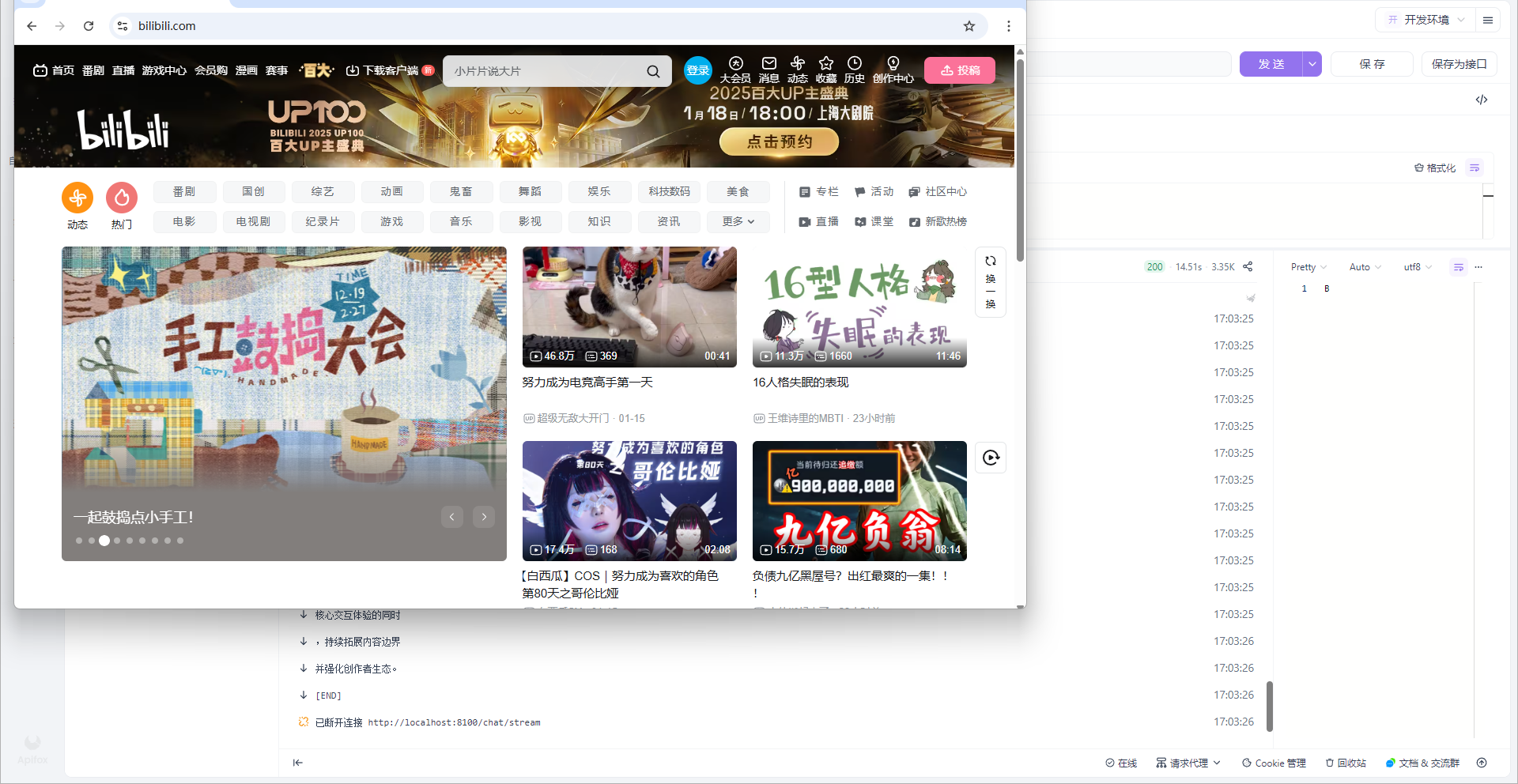
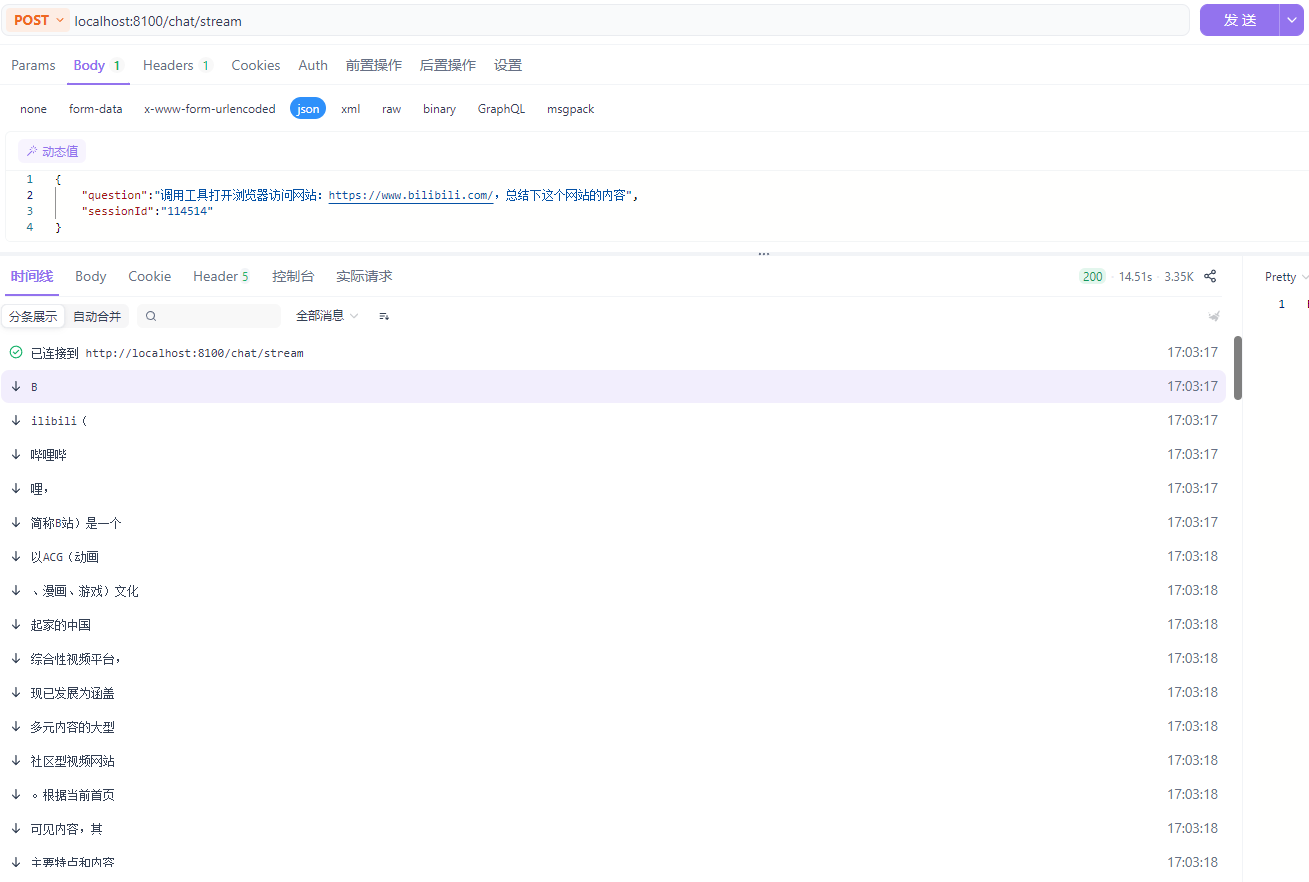
--1.3.4原理分析
通过上面的实战,已经可以看到大模型可以控制浏览器了,是怎么做到的呢?
实际上,底层的实现也是基于Tool Calling实现的,由于配置了mcpServers,就拥有了好多的工具,注册到SpringAI中。
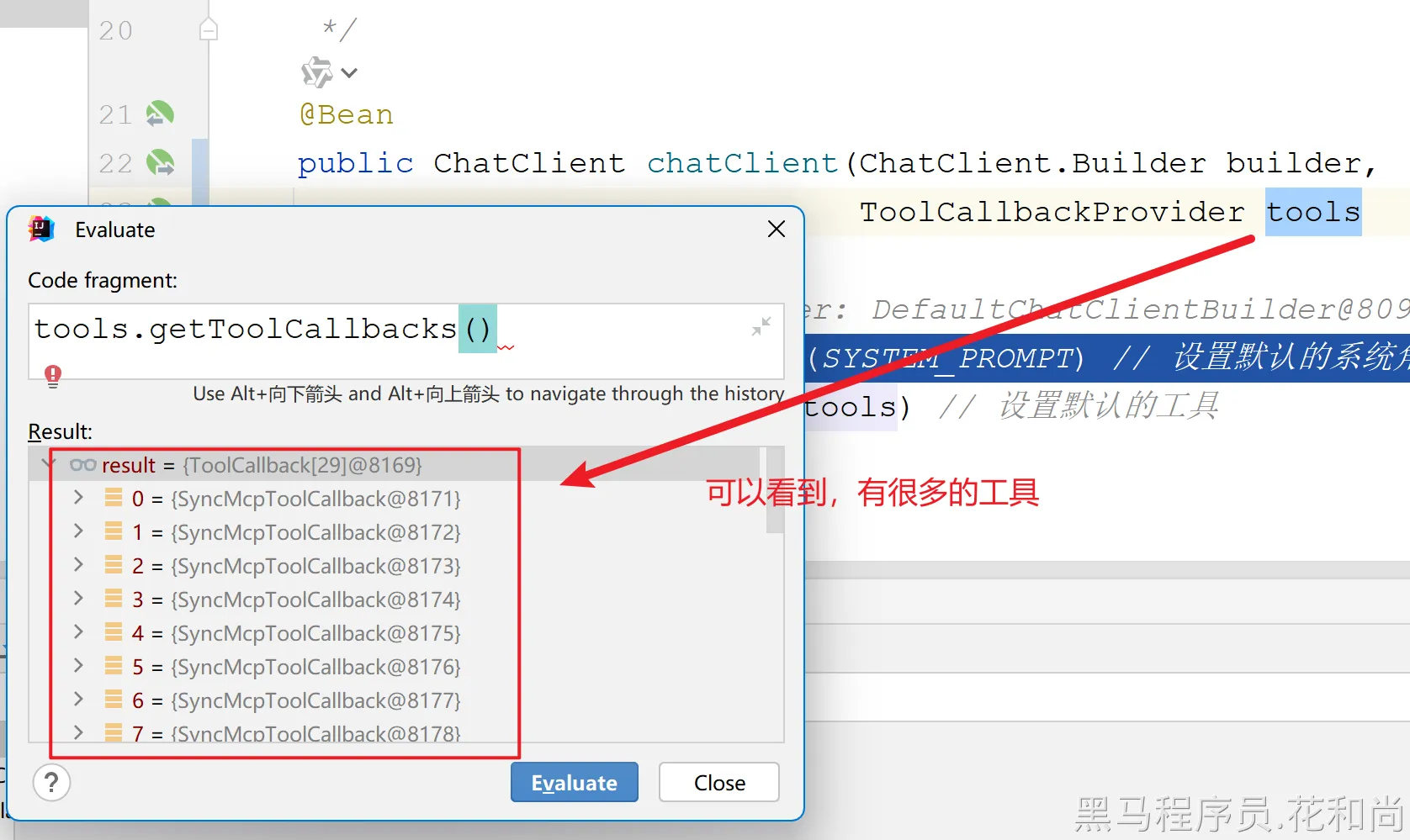
而这些工具的开发,并不是我们自己做的,也不是用java开发的,是别人开发好的,遵循了MCP协议,所以就可以集成到SpringAI中使用了,而这工具就是用来控制浏览器的,所以就实现了上面的效果。
--1.3.5实战2:ip地址所在地
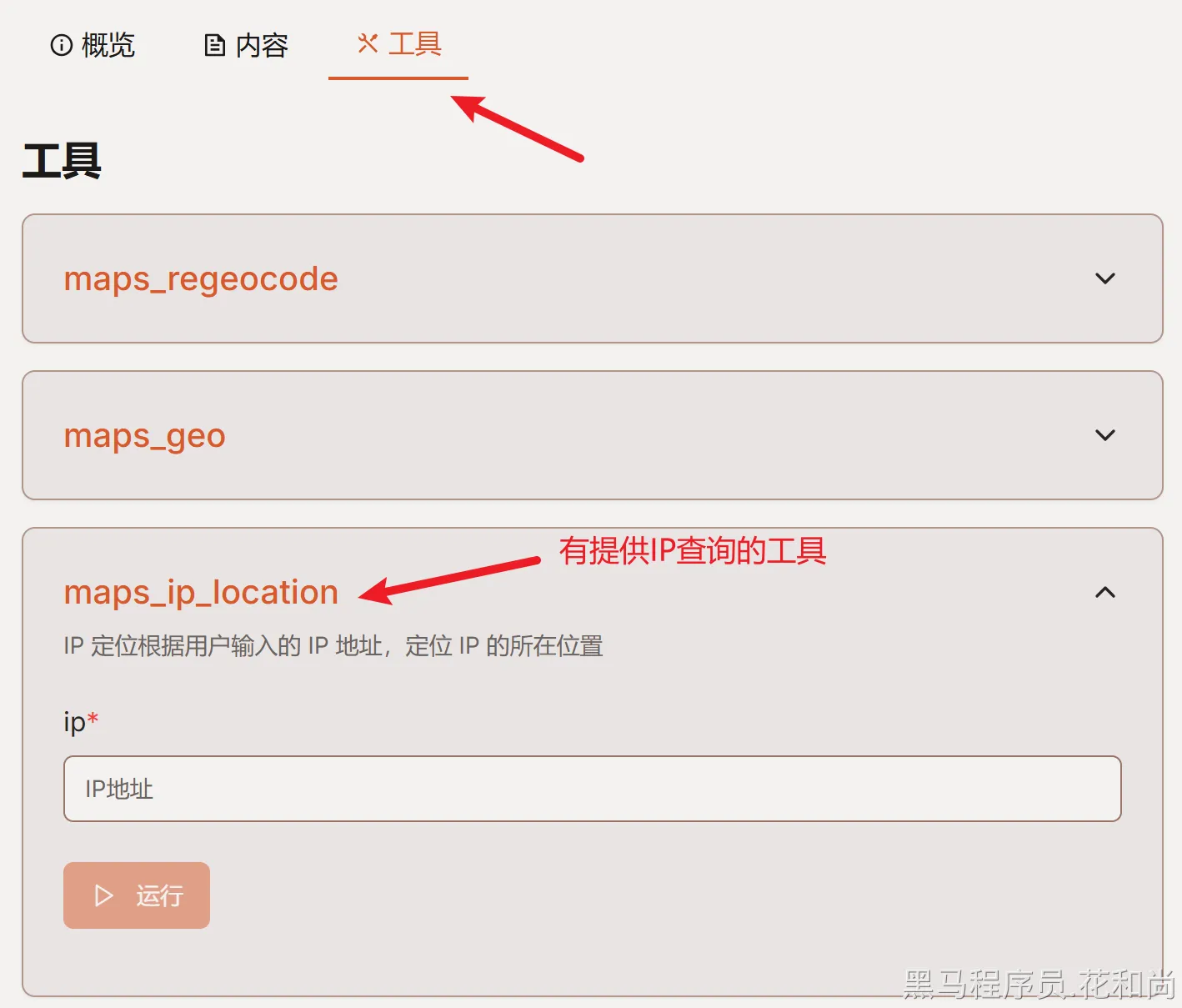
需求是 ,向大模型提问:查询ip所在地:223.11.151.238,就可以查询到ip地址的所在地。要想实现这个功能,可以借助与高德地图服务来实现,也不需要我们自己来对接,直接基于写好的MCP服务即可。
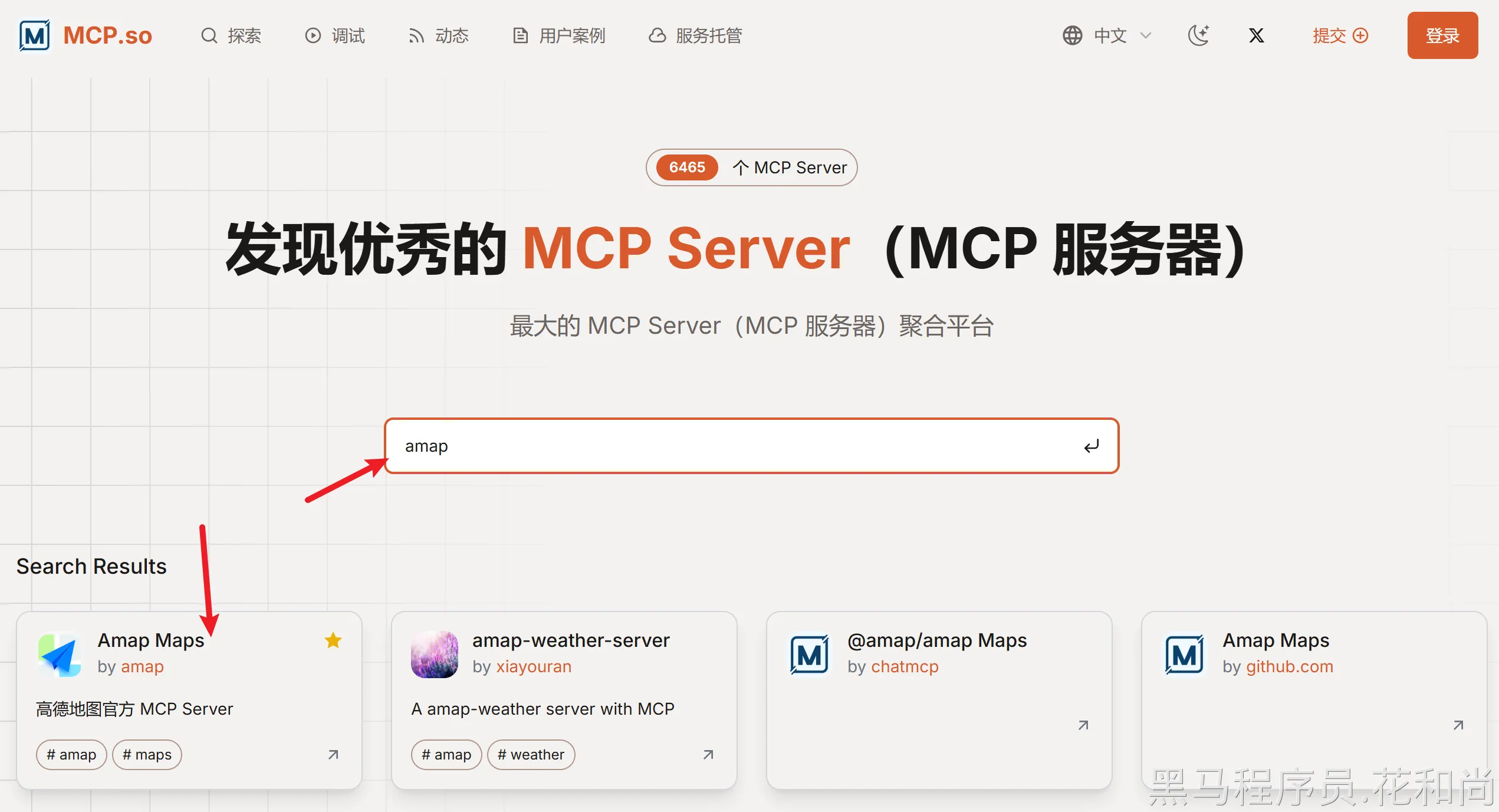
--1.3.5.1查找MCP服务
首先,需要解决一个问题,就是MCP服务从哪里能找到呢?我们可以通过这个网站来查找:https://mcp.so/zh/
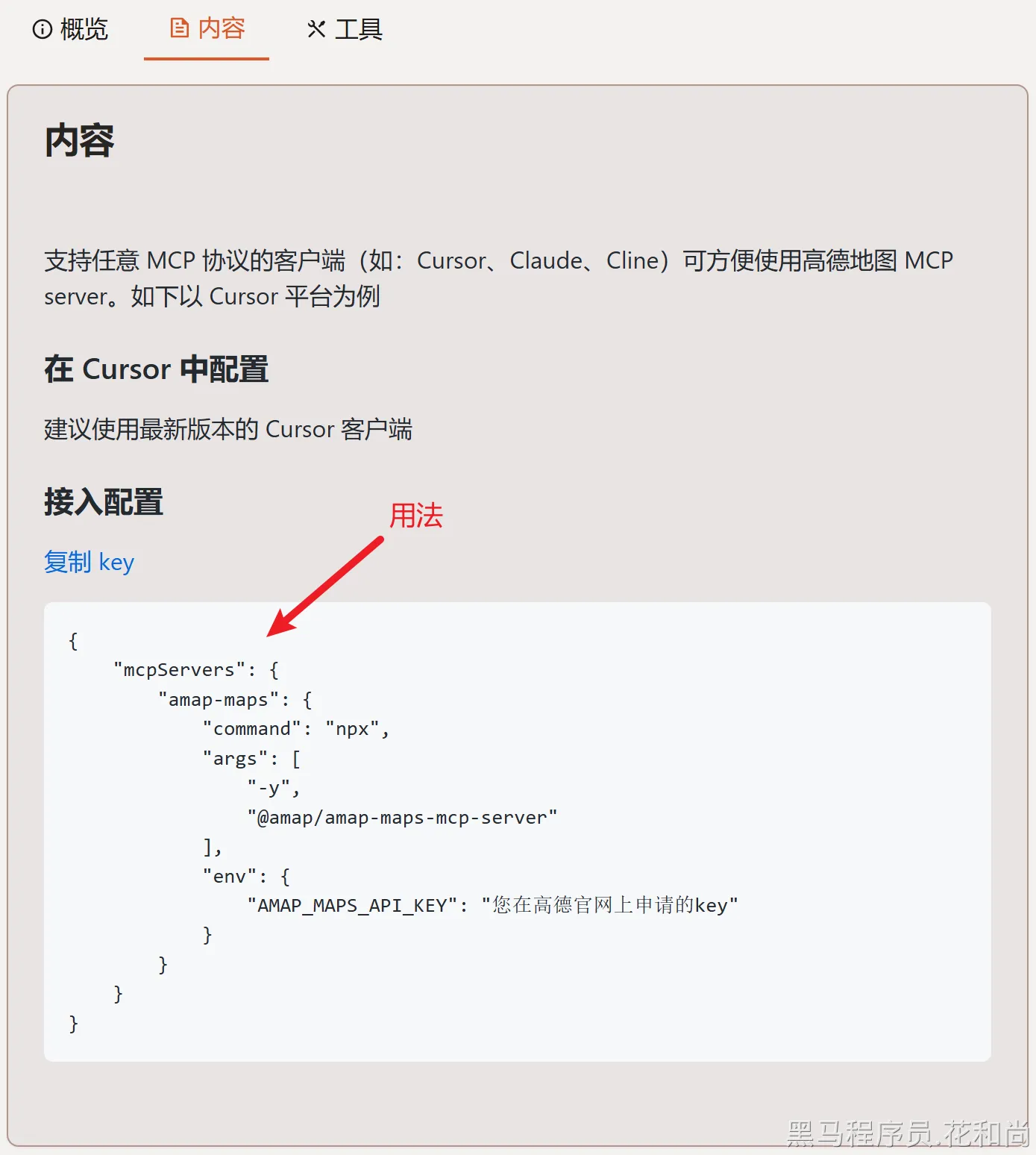
用法:
--1.3.5.2集成到项目
首先通过npm安装:

#使用国内源安装命令:
npm install -g @amap/amap-maps-mcp-server --registry=https://registry.npmmirror.com增加配置:
{
"mcpServers": {
"playwright": {
"command": "npx.cmd",
"args": [
"-y",
"@executeautomation/playwright-mcp-server"
]
},
"amap-maps": {
"command": "npx.cmd",
"args": [
"-y",
"@amap/amap-maps-mcp-server"
],
"env": {
"AMAP_MAPS_API_KEY": "xxxxxx"
}
}
}
}
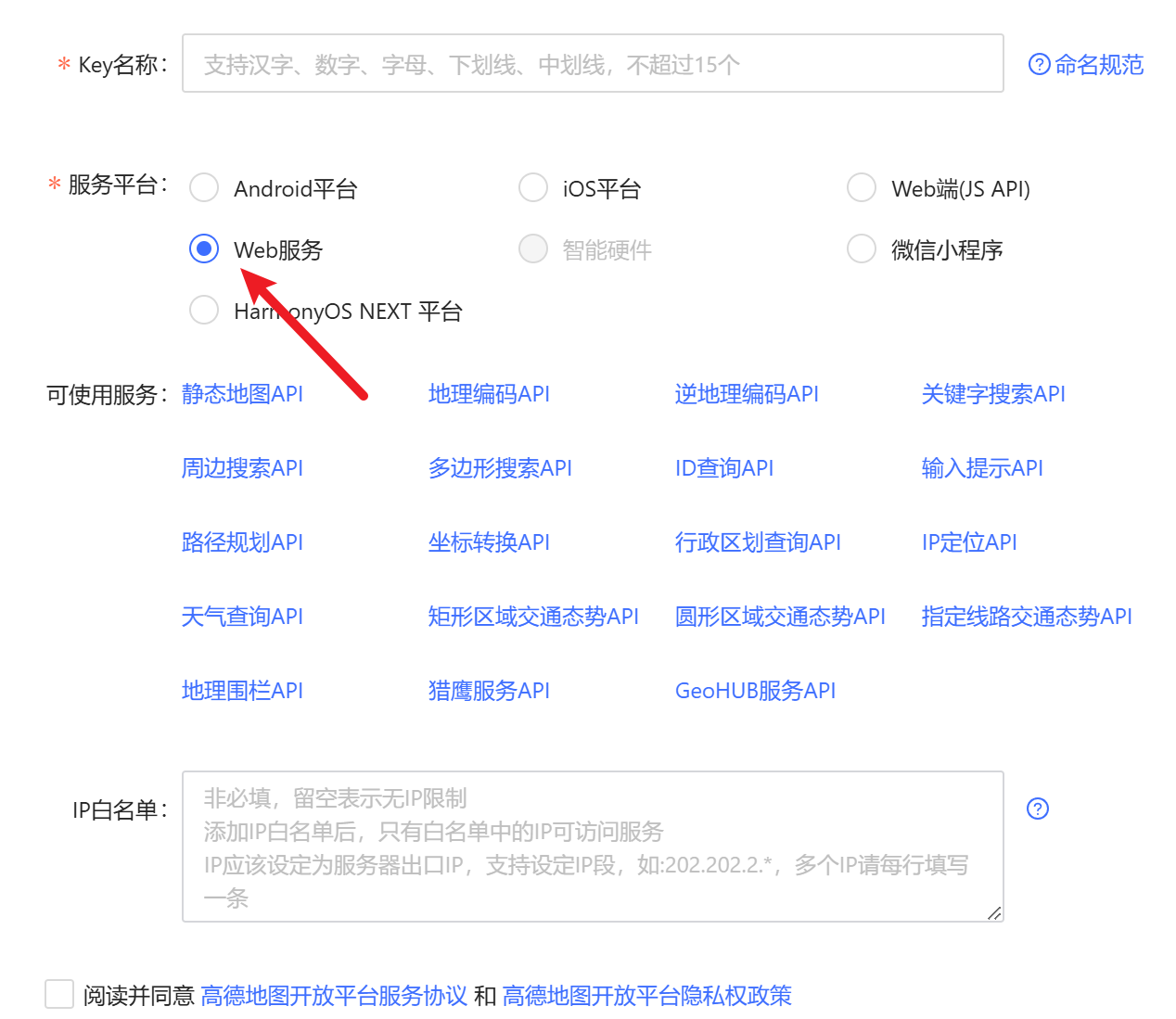
注意:AMAP_MAPS_API_KEY这个值要填自己在高德服务申请的key值。
申请地址:https://lbs.amap.com/dev/key
申请时注意【服务平台】选项,需要申请【Web服务】的key。
--1.3.5.3重启测试
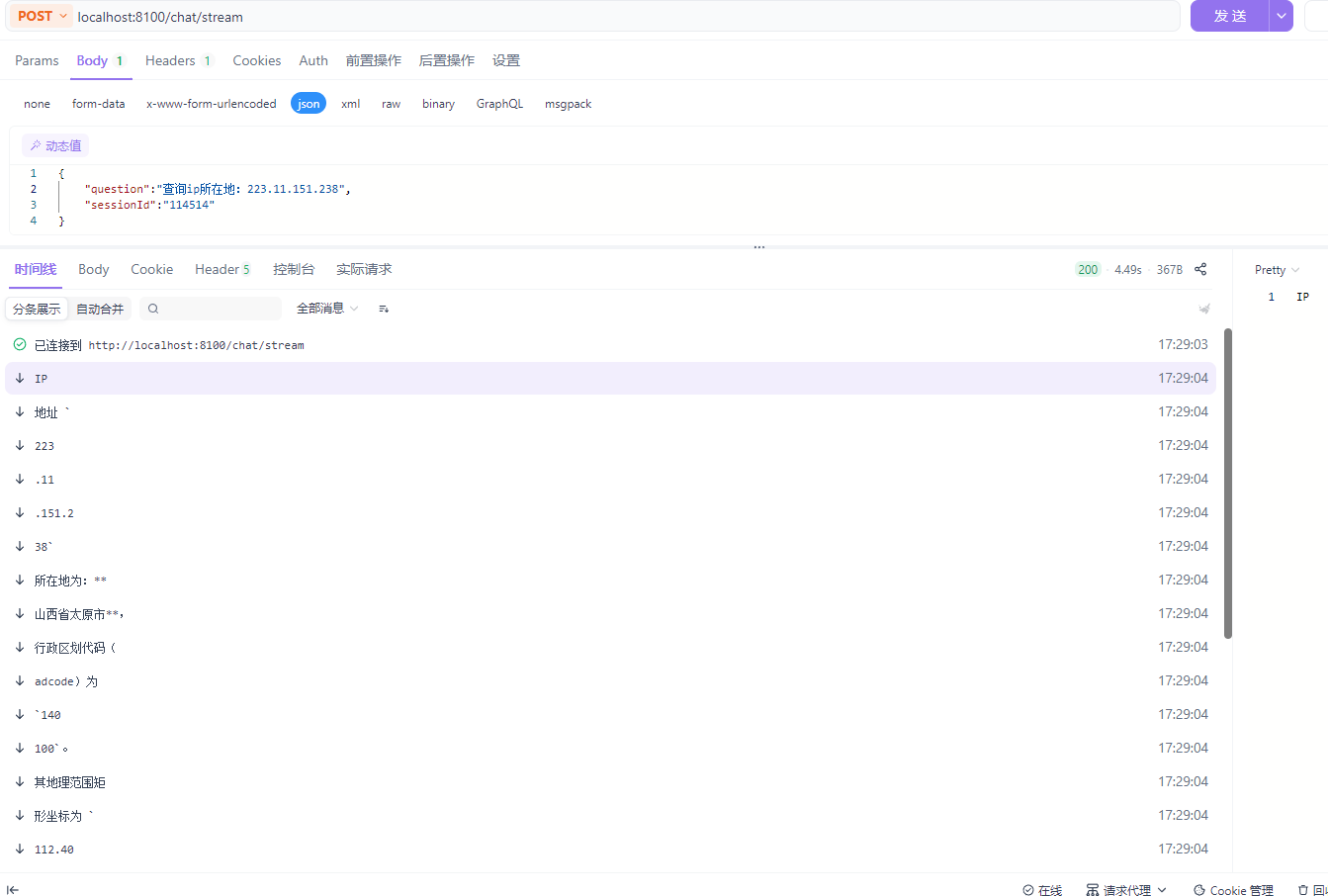
已查询到所在地
--1.3.6 练习 -mcp操作Redis
按照上述的操作方法,为大模型增加Redis的操作工具。参考:
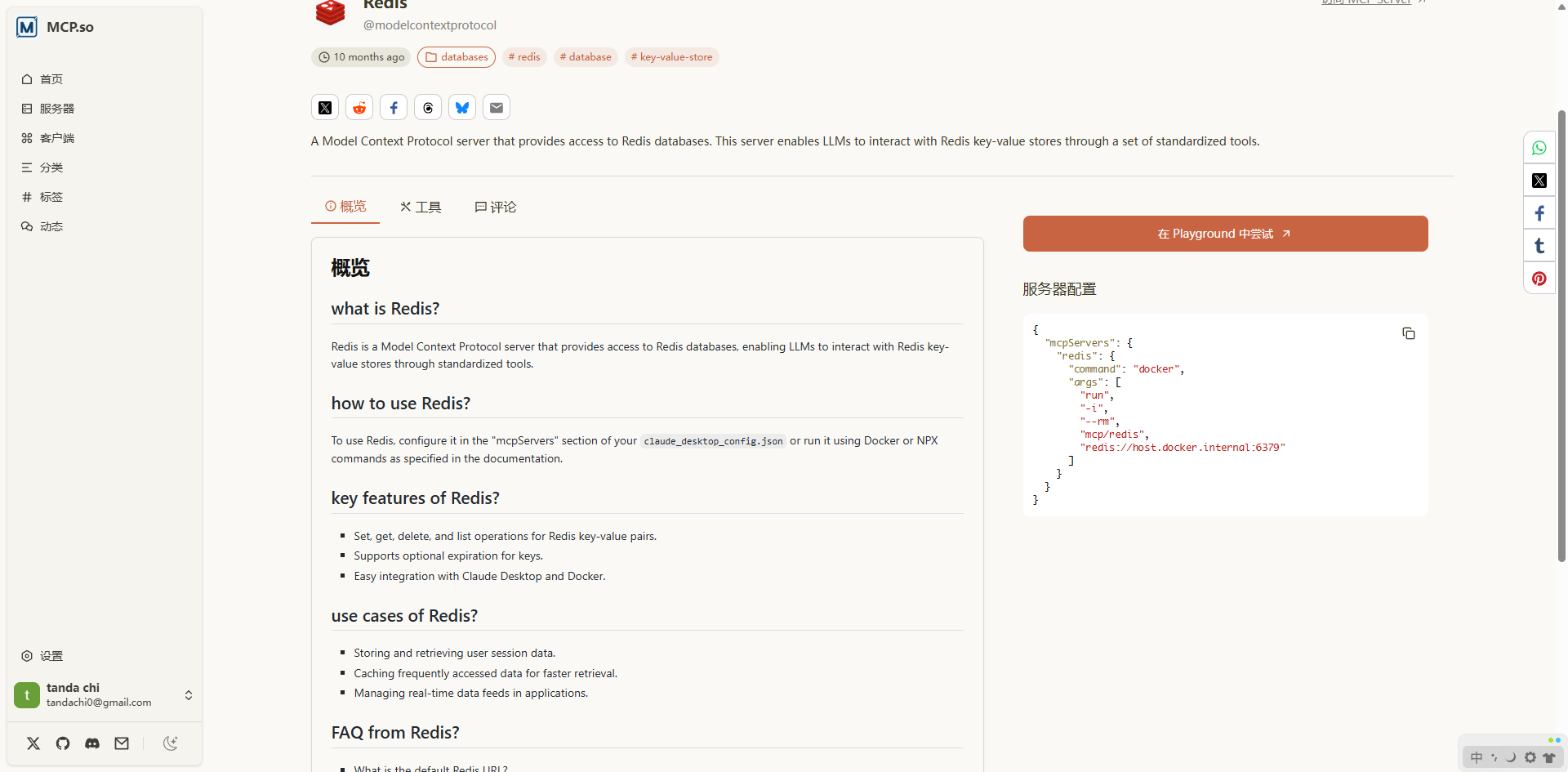
"redis": {
"command": "npx.cmd",
"args": [
"-y",
"@modelcontextprotocol/server-redis",
"redis://:123456@localhost:6379"
]
}--重启测试

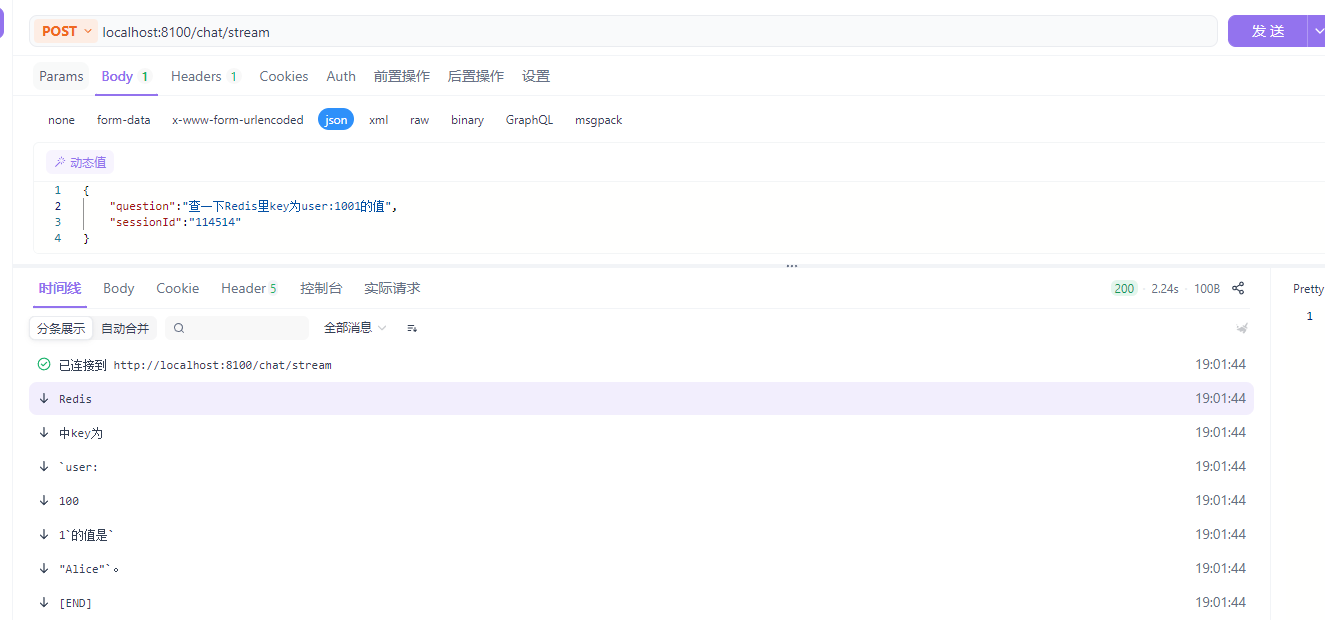
OK
--1.3.7总结
MCP Client 是 Spring AI 中用于“让大模型按协议调用外部能力(工具 / 服务 / 数据源)”的客户端,它解决的是:模型不只是生成文本,而是能通过标准化协议安全、可控地“用工具做事”。
在没有 MCP 的情况下,大模型只能“靠猜”回答;
而 MCP Client 的作用是:给模型一套标准化的能力描述(Schema + 协议),让模型在需要时主动发起结构化调用,由你在服务端真实执行,再把结果返回给模型继续推理。
核心做了三件事:
-
能力注册(Tool / Resource 暴露):
把 Java 方法、HTTP 接口、数据库查询等,声明成 MCP 能力(带输入/输出 Schema)。 -
结构化调用(非文本):
模型不是返回一段“我建议你调用接口 X”,而是直接返回一个 可反序列化的调用请求,MCP Client 负责解析并执行。 -
结果回注模型(闭环):
执行结果再次喂给模型,模型基于真实数据继续生成最终回答。
MCP Client ≈ AI 时代的 RPC / OpenAPI 网关,只不过“调用发起者”是大模型。
--1.4 MCP Server 实战
前面我们都是使用的已经写好的MCP Server,实际上,也可以自己来实现的。
接下来,我们将写一个自己的天气查询服务,将他封装成MCP Server,这样需要的天气查询服务的大模型,就可以直接集成了。
--1.4.1. 创建my-spring-ai-mcp-server
--1.4.2导入依赖
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>
</dependencies>--1.4.3编写yml配置
server:
port: 8101 #端口
spring:
application:
name: my-spring-ai-mcp-server
ai:
mcp:
server:
name: ${spring.application.name}
type: async #服务类型 异步,支持SYNC和ASYNC--1.4.4启动类
package cn.itcast;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.core.env.Environment;
import java.net.InetAddress;
import java.net.UnknownHostException;
@Slf4j
@SpringBootApplication
public class MCPServerApplication {
public static void main(String[] args) throws UnknownHostException {
SpringApplication app = new SpringApplicationBuilder(MCPServerApplication.class).build(args);
Environment env = app.run(args).getEnvironment();
String protocol = "http";
if (env.getProperty("server.ssl.key-store") != null) {
protocol = "https";
}
log.info("--/\n---------------------------------------------------------------------------------------\n\t" +
"Application '{}' is running! Access URLs:\n\t" +
"Local: \t\t{}://localhost:{}\n\t" +
"External: \t{}://{}:{}\n\t" +
"Profile(s): \t{}" +
"\n---------------------------------------------------------------------------------------",
env.getProperty("spring.application.name"),
protocol,
env.getProperty("server.port"),
protocol,
InetAddress.getLocalHost().getHostAddress(),
env.getProperty("server.port"),
env.getActiveProfiles());
}
}--1.4.5 编写MCP工具
编写weatherDTO
package cn.itcast.dto;
import com.fasterxml.jackson.annotation.JsonPropertyDescription;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class WeatherDTO {
@JsonPropertyDescription("城市ID")
private String cityId;
@JsonPropertyDescription("城市名称")
private String city;
@JsonPropertyDescription("当前温度(单位:℃)")
private String temperature;
@JsonPropertyDescription("低温(单位:℃)")
private String lowTemperature;
@JsonPropertyDescription("高温(单位:℃)")
private String highTemperature;
@JsonPropertyDescription("数据日期(格式:YYYYMMDD)")
private String date;
@JsonPropertyDescription("空气质量指数")
private String quality;
@JsonPropertyDescription("PM2.5 浓度(单位:微克/立方米)")
private double pm25;
}
service
package cn.itcast.tools;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import cn.itcast.dto.WeatherDTO;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Service;
@Service
public class WeatherService {
@Tool(description = "根据城市id查询天气信息")
public WeatherDTO getWeather(@ToolParam(description = "城市id") String cityId) {
// 通过http请求获取天气信息,并且通过json数据解析为WeatherDTO对象
String url = "http://t.weather.itboy.net/api/weather/city/" + cityId;
String data = HttpUtil.get(url);
JSONObject jsonObject = JSONUtil.parseObj(data);
return WeatherDTO.builder()
.cityId(jsonObject.getByPath("cityInfo.citykey", String.class)) // 城市ID
.city(jsonObject.getByPath("cityInfo.city", String.class)) // 城市名称
.date(jsonObject.getByPath("date", String.class))// 数据日期
.temperature(jsonObject.getByPath("data.wendu", String.class)) // 当前温度
.lowTemperature(jsonObject.getByPath("data.forecast[0].low", String.class))// 低温
.highTemperature(jsonObject.getByPath("data.forecast[0].high", String.class))// 高温
.quality(jsonObject.getByPath("data.quality", String.class))// 空气质量
.pm25(jsonObject.getByPath("data.pm25", Double.class))// PM2.5数值
.build();
}
}
--1.4.6MCP service配置
package cn.itcast.config;
import cn.itcast.tools.WeatherService;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.ai.tool.ToolCallbacks;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class McpConfig {
/**
* 申明对外提供服务的工具
*/
@Bean
public List<ToolCallback> weatherTools(WeatherService weatherService) {
return List.of(ToolCallbacks.from(weatherService));
}
}
--1.4.7启动测试
浏览器访问地址:http://localhost:8101/sse

说明,MCPServer已经启动成功。
--1.4.8在MCPClient中集成服务
只需要在MCPClient中指定服务地址即可。
在yml配置文件中,Client层级下新增如下配置:
type: async
sse:
connections:
server1:
url: http://localhost:8101 #指定mcp Server服务器地址启动服务,打断点可以看到,已经有天气的工具了:
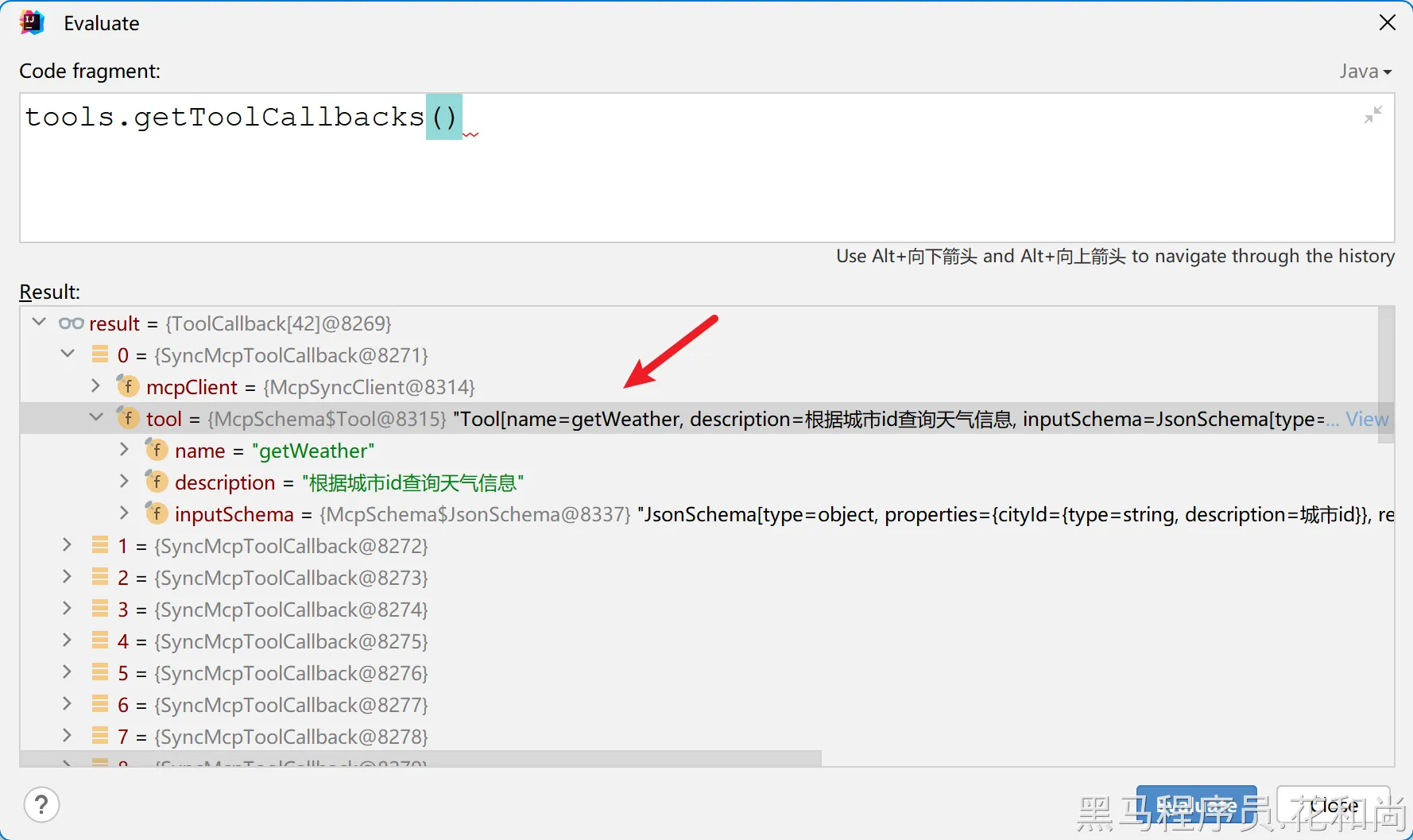
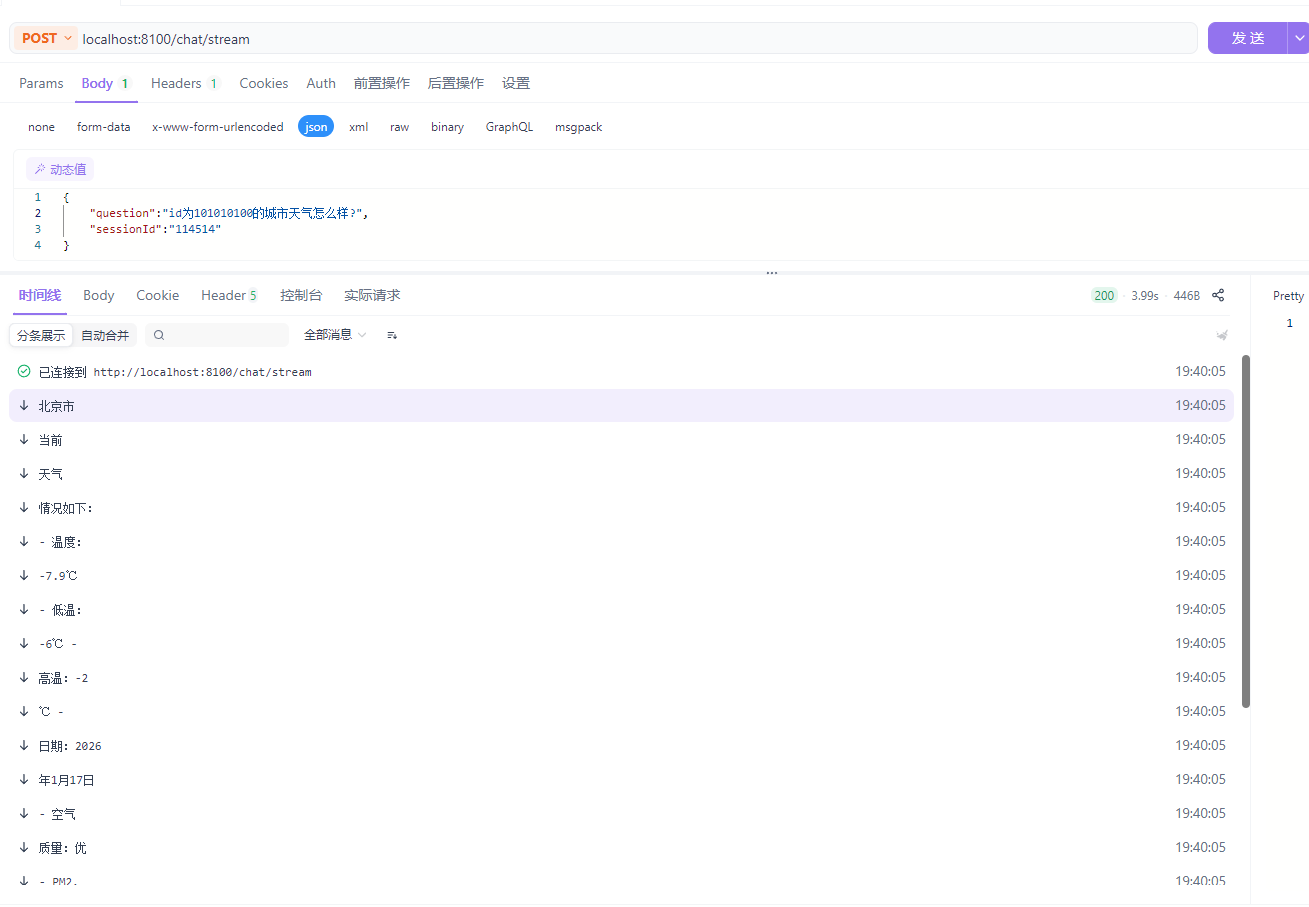
--1.4.9功能测试
--1.4.10总结
MCP Server 是“大模型可调用能力的提供方”,它把你的后端能力(方法 / 接口 / 数据)按照统一协议暴露出来,供 MCP Client(以及大模型)以结构化方式安全调用。
MCP Client = AI 发起调用的一侧(像 Feign / SDK)
MCP Server = AI 能调用的服务端(像 Provider / OpenAPI 服务)
--2.多模态
--2.1什么是多模态
多模态就是指可以处理各种不同类型的数据,比如文字、图片、声音和视频等。到现在为止,我们跟大模型的互动都只是通过普通的文字输入,这主要是因为我们用的大模型只能处理文字。
实际上,在阿里云百炼平台有很多的模型是支持多模态的,如:
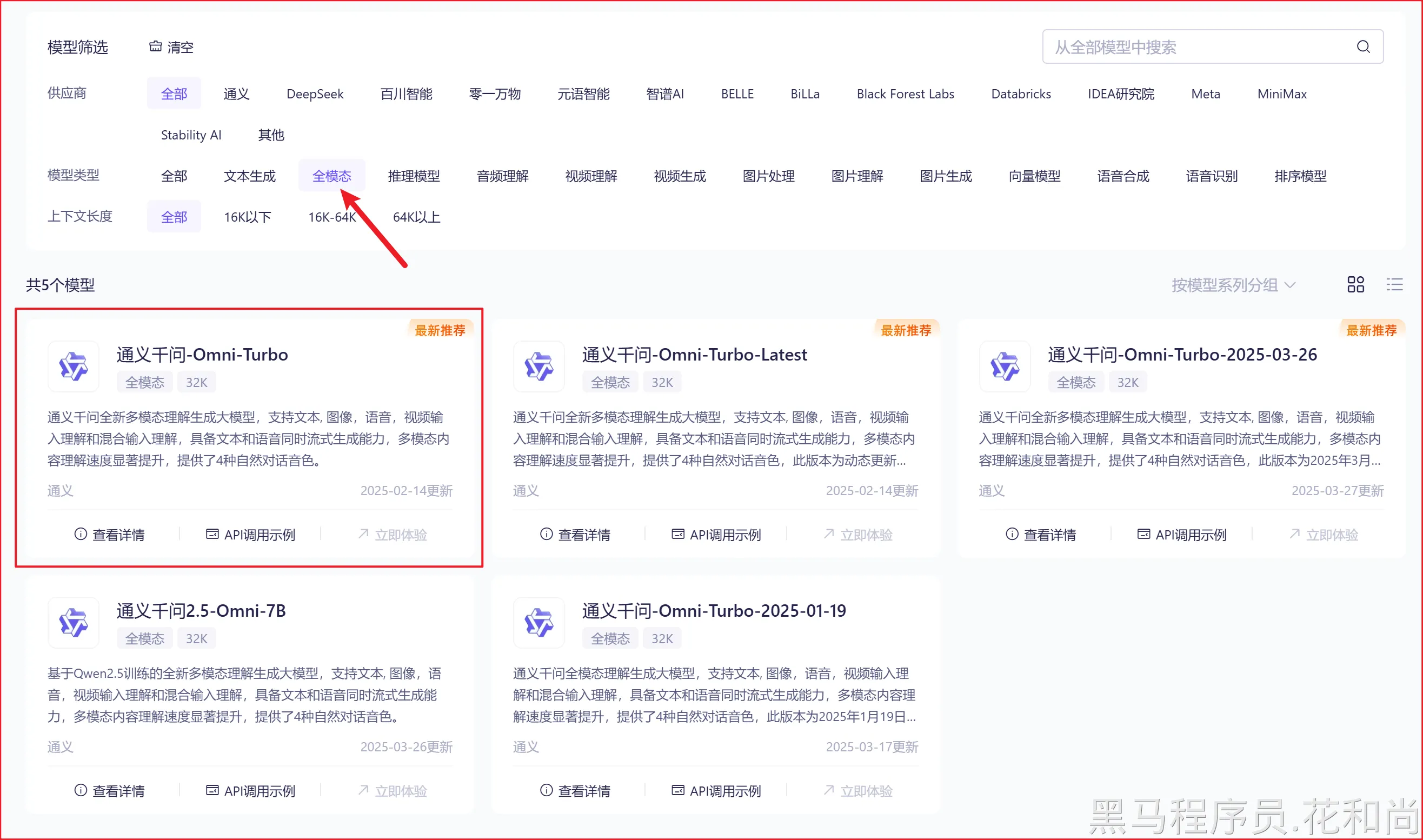
下面,我们将基于qwen-omni-turbo模型,进行学习,完成对图片的理解。
--2.2编码实现
在my-spring-ai项目工程中添加代码实现。
controller
/**
* 处理多模型流式聊天请求的端点方法
* 该方法接收用户问题、会话ID和可选文件列表,返回流式文本响应
*
* @param question 用户输入的问题内容
* @param sessionId 唯一会话标识符,用于关联聊天上下文
* @param files 可选的上传文件列表,用于多模态处理(可为空)
* @return Flux<String> 流式返回的文本响应,按事件流格式传输
*/
@PostMapping(value = "stream-multi-model", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatStreamMultiModel(@RequestParam("question") String question,
@RequestParam("sessionId") String sessionId,
@RequestParam(value = "files", required = false) List<MultipartFile> files) {
return chatService.chatStreamMultiModel(question, sessionId, files);
}service
/**
* 多模型聊天
*
* @param question 用户提问
* @param sessionId 会话id
* @param files 文件列表
* @return 大模型的回答
*/
Flux<String> chatStreamMultiModel(String question, String sessionId, List<MultipartFile> files);serviceimpl
/**
* 处理多模型流式聊天请求并返回响应流
*
* @param question 用户输入的问题
* @param sessionId 会话唯一标识符
* @param files 上传的多媒体文件列表(当前仅支持JPEG图片)
* @return 包含流式响应内容的Flux对象,每个元素为文本片段,流结束时附加"[END]"标记
*/
@Override
public Flux<String> chatStreamMultiModel(String question, String sessionId, List<MultipartFile> files) {
// 将上传的文件转换为媒体对象列表(仅处理非空文件)
List<Media> mediaList = new ArrayList<>();
if (CollUtil.isNotEmpty(files)) {
for (MultipartFile file : files) {
var media = new Media(MimeTypeUtils.IMAGE_JPEG, file.getResource());
mediaList.add(media);
}
}
// 创建包含媒体信息的用户消息对象并设置消息格式类型
var userMessage = new UserMessage(question, mediaList);
userMessage.getMetadata().put(DashScopeChatModel.MESSAGE_FORMAT, MessageFormat.IMAGE);
// 构建多模型聊天请求参数(使用qwen-omni-turbo模型)
var prompt = new Prompt(userMessage, DashScopeChatOptions.builder()
.withModel("qwen-omni-turbo")
.withMultiModel(true)
.build());
// 调用聊天客户端生成流式响应内容
return this.chatClient.prompt(prompt)
.system(p -> p.param("now", DateUtil.now())) // 设置系统角色参数(当前时间)
// 设置会话记忆参数(绑定会话ID)
.advisors(advisor -> advisor.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId))
.stream()
.content()
// 在流结束时添加结束标记
.concatWith(Flux.just("[END]"));
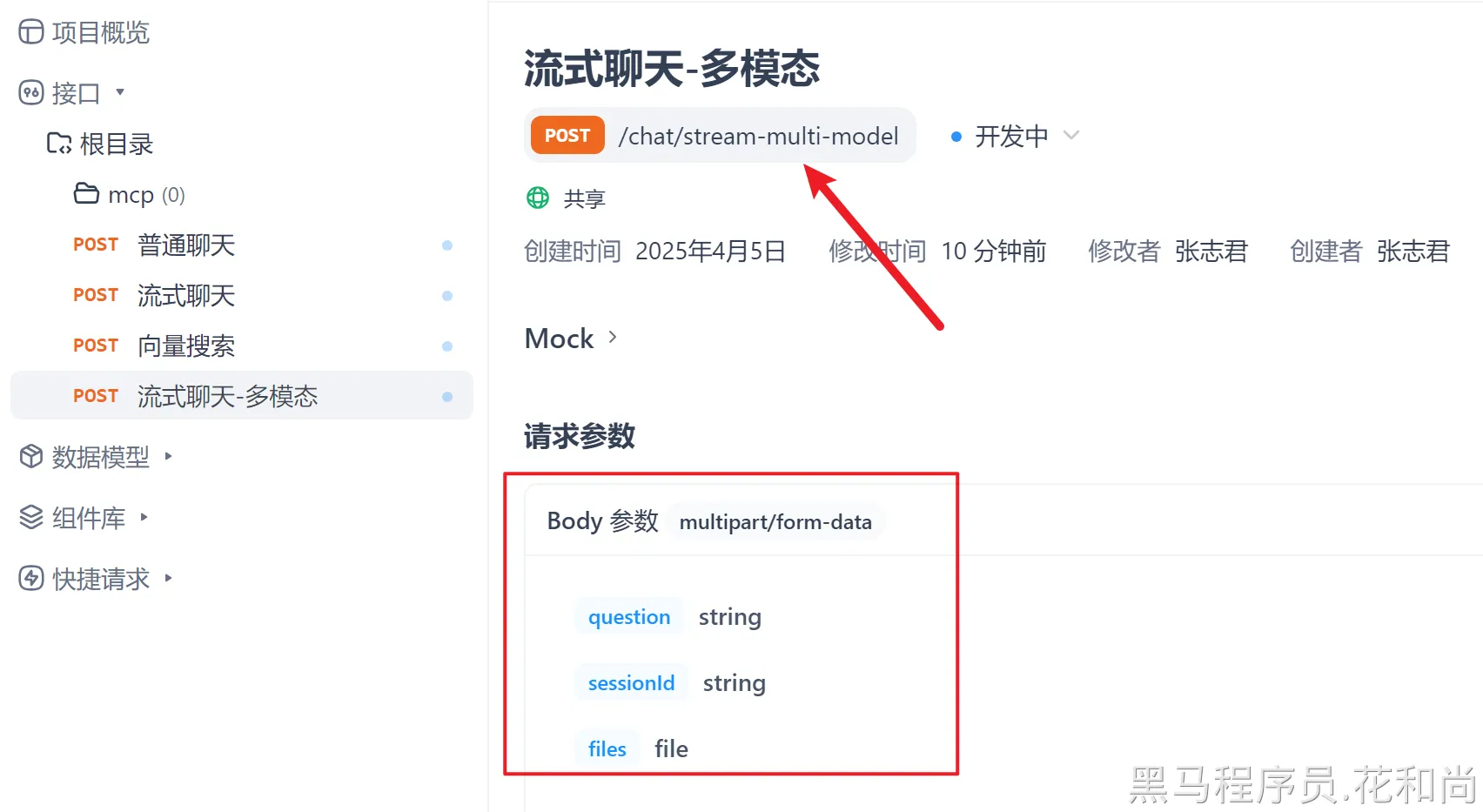
}--2.3apifox添加接口
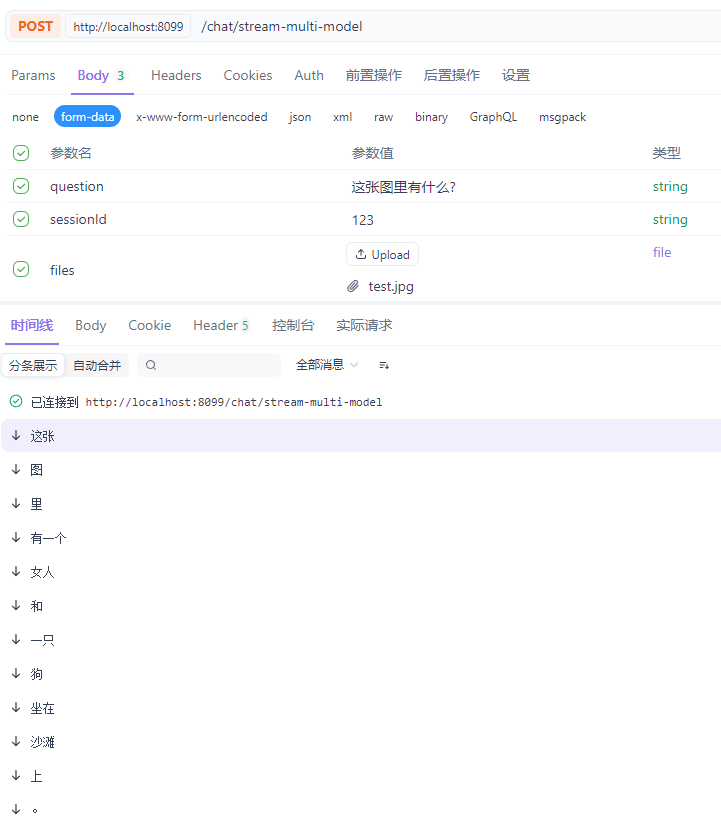
--2.4测试

--2.5总结
多模态是指大模型在一次推理中同时理解并融合多种输入形式(如文本、图片、音频),而在代码实现上,本质就是把不同模态统一封装为结构化输入(如
UserMessage = 文本 + Media),选择支持多模态的模型,并通过元数据和模型参数显式声明模态类型,让模型在同一上下文中完成融合推理并输出结果。
--3.结构化输出
结构化输出是指,大模型在生成的内容可以转化为json、java对象的方式,不只是之前看到的文本类型,在某些场景下是有这个需求的。
另外一方面,是因为即使我们明确要求大模型以json格式生成数据,而大模型依然会存在一定的不确定性,所以,结构化输出就比较有用了。
结构化输出转换器官网地址![]() https://docs.spring.io/spring-ai/reference/1.0/api/structured-output-converter.html
https://docs.spring.io/spring-ai/reference/1.0/api/structured-output-converter.html
--3.1Bean对象输出
测试用例
package cn.itcast.service;
import cn.hutool.core.util.StrUtil;
import jakarta.annotation.Resource;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class StructuredOutputTest {
private ChatClient chatClient;
@Resource
private ChatModel chatModel;
@BeforeEach
public void before() {
this.chatClient = ChatClient.builder(chatModel).build();
}
// 创建一个记录器,用于记录演员和电影列表
record ActorsFilms(String actor, List<String> movies) { }
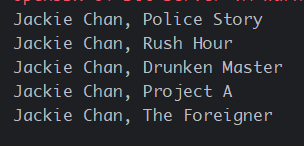
@Test
public void testBeanOut(){
ActorsFilms actorsFilms = this.chatClient.prompt()
.user("生成5部成龙的电影目录")
.call()
.entity(ActorsFilms.class);
for (String movie : actorsFilms.movies()) {
System.out.println(StrUtil.format("{}, {}", actorsFilms.actor(), movie));
}
}
}
测试结果
--3.2List<Bean>输出
测试用例
@Test
public void testListBeanOut(){
List<ActorsFilms> list = this.chatClient.prompt()
.user("生成5部成龙和刘德华的电影目录")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});
for (ActorsFilms actorsFilms : list) {
for (String movie : actorsFilms.movies()) {
System.out.println(StrUtil.format("{}, {}", actorsFilms.actor(), movie));
}
}
}测试结果

--3.3Map集合输出
测试用例
@Test
public void testMapOut(){
Map<String,Object> map = this.chatClient.prompt()
.user("生成一个名为'生肖表'的中国十二生肖列表,一个名为'星座表'的星座列表")
.call()
.entity(new ParameterizedTypeReference<Map<String,Object>>() {});
System.out.println(map);
}测试结果

--3.4List集合输出
测试用例
@Test
public void testListOut(){
List<String> list = this.chatClient.prompt()
.user("生成一个中国十二生肖列表")
.call()
.entity(new ParameterizedTypeReference<>() {});
System.out.println(list);
}测试结果
![]()
--3.5JSON格式输出
一般的大模型都支持json格式的输出,需要在模型参数上进行配置,并且在提示词中要求以json格式输出结果。
测试用例
@Test
public void testJsonOut() {
String content = "请以 JSON 格式返回以下信息:生成一个名为'生肖表'的中国十二生肖列表,一个名为'星座表'的星座列表";
Prompt prompt = new Prompt(content, DashScopeChatOptions.builder()
.withResponseFormat(DashScopeResponseFormat.builder()
.type(DashScopeResponseFormat.Type.JSON_OBJECT) // 设置返回格式为JSON对象
.build())
.build());
String json = this.chatClient.prompt(prompt)
.call()
.content();
System.out.println(json);
}测试结果

--3.6总结
大模型结构化输出的核心思路是:通过“输出约束 + 类型映射”两步走,把不稳定的自然语言结果,稳定地转换为 Java 可直接使用的对象(Bean / List / Map / JSON);在 Spring AI 中,主要依靠 StructuredOutputConverter + 泛型类型推断 +(必要时)模型 JSON 模式 来完成。
在 Spring AI 里,你只需要在调用 chatClient 时明确告诉模型“你要的返回类型是什么”,Spring AI 就会自动帮你完成 JSON 解析与对象转换。例如:
-
Bean / List / Map 等对象输出:
直接在.entity(...)中传入目标类型(Class或ParameterizedTypeReference),Spring AI 会自动引导模型按结构生成,并将结果反序列化为 Java 对象:
List<String> list = chatClient.prompt()
.user("生成一个中国十二生肖列表")
.call()
.entity(new ParameterizedTypeReference<List<String>>() {});
👉 本质是 “模型生成结构化内容 + StructuredOutputConverter 自动映射”。
- JSON 结构化输出(强约束):
当你只关心 JSON 本身或需要更强的稳定性时,在 模型参数中开启 JSON 模式,并在提示词中明确要求 JSON:
Prompt prompt = new Prompt(
"请以 JSON 格式返回:生肖表和星座表",
DashScopeChatOptions.builder()
.withResponseFormat(
DashScopeResponseFormat.builder()
.type(DashScopeResponseFormat.Type.JSON_OBJECT)
.build()
)
.build()
);
String json = chatClient.prompt(prompt).call().content();
👉 这是 “模型层强制 JSON + 程序侧自行解析”。
结构化输出 = 用提示词 + Spring AI 的 StructuredOutputConverter + 泛型/JSON 约束,让大模型“必须按你定义的数据结构说话”,而不是自由输出文本。
后面还有SpringAIAlibaba的插件集成以及Ollama私有化大模型的学习,由于插件集成与mcp集成差不多,作为一个tool注入chatclient即可,而Ollama私有化大模型也较为简单,本文不再进行总结赘述

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)