AI基础1-人工智能的数学基础
https://www.bilibili.com/video/BV1cz421B7NY
参考代码:https://github.com/GenTang/regression2chatgpt/tree/zh/
学习一下这套课
数学基础
矩阵
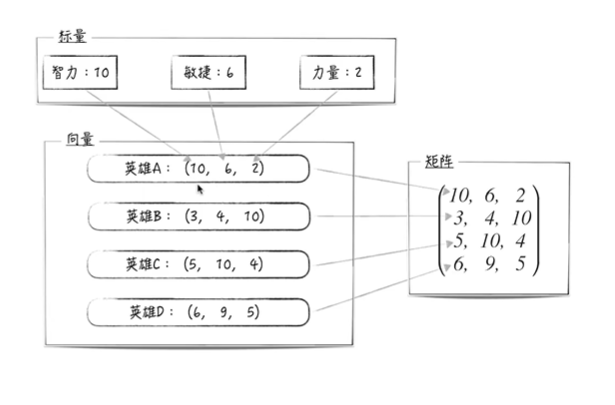
这部分主要需要注意一下的就是特征值和特征向量了,单看定义肯定是十分不利于理解的,但是从几何角度就很好理解了
矩阵可以看作是对向量空间进行线性变换的工具。特征值和特征向量揭示了在这种变换下某些向量的特殊性质。在矩阵变换中,特征向量是指那些在变换后方向保持不变的向量(可能反向)。这些向量仅被拉伸或压缩,而不会被旋转。
假设 v 是矩阵 A 的特征向量,则变换后 Av 与 v 共线。
特征值 λ 表示特征向量在变换中被拉伸或压缩的比例因子。若 λ > 1,向量被拉长;若 0 < λ < 1,向量被压缩;若 λ < 0,向量方向反转。
假设说明:
矩阵的特征值分解 A = PDP⁻¹(其中 P 是特征向量矩阵,D 是对角特征值矩阵)揭示了变换的几何本质:
P⁻¹ 将向量转换到由特征向量定义的坐标系。
D 在新坐标系中对每个基向量进行缩放(特征值决定缩放比例)。
P 将缩放后的向量转换回标准坐标系。
这种分解表明,任何线性变换都可以看作是在特征向量方向上的纯缩放变换的组合。
应用示例:二维变换
考虑二维空间中的矩阵变换:
特征值:λ₁ = 3, λ₂ = 1
对应特征向量:v₁ = [1, 1]ᵀ, v₂ = [-1, 1]ᵀ
变换的几何意义:
沿 v₁ 方向拉伸3倍。
沿 v₂ 方向保持不变。
其他向量会被拉伸并旋转,最终方向由这两个作用的组合决定。
特殊情况的几何表现:
当特征值为复数时,变换包含旋转成分;多重特征值可能对应不完全的特征向量集,此时变换包含剪切成分;零特征值对应的特征向量被压缩到原点(变换的核空间)。
概率
这部分王木头的课挺好;
https://www.bilibili.com/video/BV1vv4y1B71
假设性检验
假设性检验的一般步骤包括确定假设、选择检验统计量、计算统计量、做出决策等。
一般步骤 提出假设:
原假设( H 0 ): 通常表示无效应或无差异的假设,例如“实验组和对照组没有显著差异”。
备择假设( H 1 ): 研究者希望证实的假设,例如“实验组和对照组有显著差异” 。
确定显著性水平: 通常选择 α = 0.05 或 0.01 ,表示犯第一类错误(拒真错误)的最大允许概率 。
选择检验统计量: 根据数据类型和检验目的选择适当的统计量,如 z 统计量(总体方差已知时)或 t 统计量(小样本且方差未知时) 。
计算样本统计量: 将实际观测数据代入统计量计算公式 。
确定临界值: 根据显著性水平和统计量的抽样分布(如标准正态分布、 t 分布)确定拒绝域的边界值 。
做出决策: 比较计算得到的统计量与临界值。如果统计量落在拒绝域内,则拒绝原假设 H 0 ;
极大似然估计
用极大似然估计设计损失函数要比其他损失使用的频次更多,理解也复杂一些;
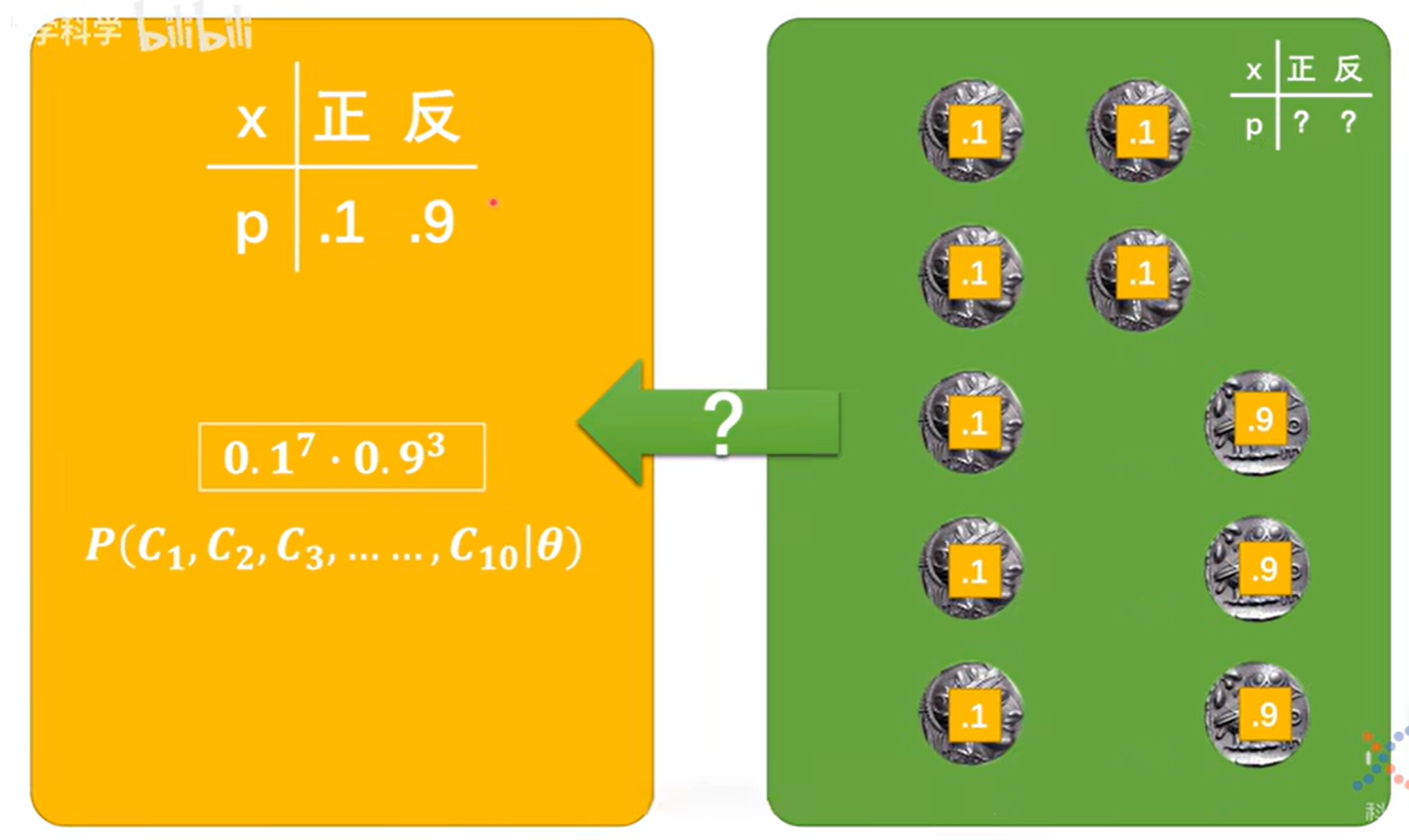
假定抛硬币十次结果为3/7开,那么我们可以回过头来假定抛硬币正反的概率p,在这个概率下计算发生3-7这个结果的发生概率,就可以得到一个计算结果,用来衡量在假定p下事实发生的概率;
即我们假定抛硬币正的概率为p,那么发生这个3/7结果的概率就可以归纳成一个十个概率相乘(十次抛硬币为图中对应既定结果)的公式;
进一步,对于任意1次抛正面概率为p硬币,在抛出前,结果为x=1(即正面)的概率可表示为[p],结果为x=0(反面)的概率为[(1-p)];
落地后为x面,这件事发生的概率是[p^x]*[(1-p)^(1-x)];
抛n次,落地后为x1,x2,x3...的概率就是累乘[p^x]*[(1-p)^(1-x)];
那么同样地,对于任意一次模型的判断,在和标签答案对照前,其判断输入对应的输出结果x=1的概率为y,x=0的概率为1-y;
对照标签答案后为x,这件事发生的概率是[y^x]*[(1-y)^(1-x)];
测试模型n次,输出结果为正确答案x1,x2,x3...的概率就是:L=累乘[y^x]*[(1-y)^(1-x)];
那么L越大,模型输出结果正确的概率就越大,那么L就可以作为模型的损失函数,在优化一下方便计算,这便是极大似然估计对应的损失函数:
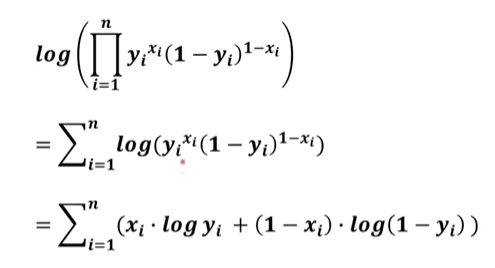
微积分
公修课不说了
贝叶斯定理
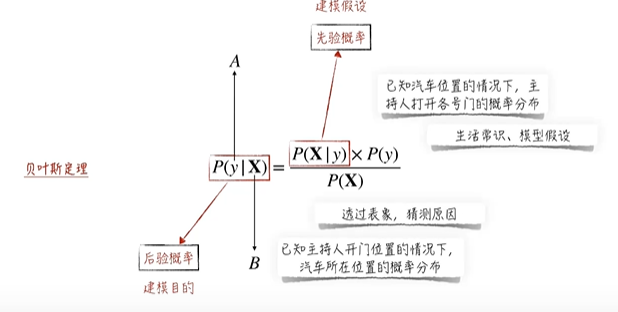
通俗说就是通过已知的y发生条件下x发生的条件概率计算x发生的情况下y发生的条件概率
即,在比赛场次和爆典次数明确的情况下,通过各场比赛我们可以轻松计算出edg赢下比赛的场次中康康爆典的概率,那么已知赛中康康再次爆典,就可以大胆猜测这场比赛赢下的概率,从而决定和朋友父子赌注。
简单代码
https://www.bilibili.com/video/BV1Y64y1Q7hi
数据读取
最简单的数据生成与读取
import numpy as np
np.random.seed(1531)
x = list(range(10, 29))
#生成[10,29)这个左开右闭区间中的19整数的随机序列
x = np.array(x)
#转换成numpy格式的数组
print(x)
e=np.random.randn(19)
#在标准正态分布随机19个浮点数,默认返回格式为numpy数组
print(e)
y=e+x
#奇怪的是,浮点数和整数可以直接相加
print(y)
#数组之间可以直接相加,默认为对应位置依次相加模块化一下:
def generate_data():
"""
随机生成数据
"""
# 规定随机数生成的种子
np.random.seed(4889)
# Python2和Python3的range并不兼容,所以使用list(range(10, 29))
x = np.array([10] + list(range(10, 29)))
error = np.round(np.random.randn(20), 2)
#np.round( ,2)表示保留小数点后两位
y = x + error
return pd.DataFrame({"x": x, "y": y})
#dataFrame用于返回一个类数据库或者说类excel格式的数据列表,引号里为索引名,后为数据列
myData=generate_data()
print(myData)
x=myData["x"]
y=myData["y"]
print(y)
#也可以通过索引名称取出数据可视化与保存
def visualize_data(data):
"""
数据可视化
"""
# 创建一个图形框,在里面只画一幅图
fig = plt.figure(figsize=(6, 6), dpi=80)
ax = fig.add_subplot(111)
#111表示展示框内一行一列画1幅图
# 设置坐标轴
ax.set_xlabel("$x$")
ax.set_xticks(range(10, 31, 5))
#设置刻度:10开始31结束,间隔为5
ax.set_ylabel("$y$")
ax.set_yticks(range(10, 31, 5))
# 画点图,点的颜色为b,blue蓝色
ax.scatter(data.x, data.y, color="b",
label="$y = x + \epsilon$")
plt.legend(shadow=True)
# 展示上面所画的图片。图片将阻断程序的运行,直至所有的图片被关闭
# 在Python shell里面,可以设置参数"block=False",使阻断失效。
plt.show()
visualize_data(myData)
myData.to_csv("./test",index=False)两个回归想跳过记录代码了,练练就跳过吧
回归
scikit-learn用着更简单呀,但是输出可能没state库那么专业
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.005
Model: OLS Adj. R-squared: -0.050
Method: Least Squares F-statistic: 0.09171
Date: Fri, 08 Dec 2023 Prob (F-statistic): 0.765
Time: 10:39:38 Log-Likelihood: -27.982
No. Observations: 20 AIC: 59.96
Df Residuals: 18 BIC: 61.96
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
x -0.0243 0.080 -0.303 0.765 -0.193 0.144
z 0.7873 0.445 1.768 0.094 -0.148 1.723
==============================================================================
Omnibus: 0.939 Durbin-Watson: 2.375
Prob(Omnibus): 0.625 Jarque-Bera (JB): 0.886
Skew: 0.338 Prob(JB): 0.642
Kurtosis: 2.221 Cond. No. 11.0
==============================================================================

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)