【详细步骤】大模型基础知识(3)---ollama简介和环境变量设置
本文介绍了Ollama的各类详细的知识点。文章详细说明了Ollama的特点、下载安装方法、常用命令以及如何设置模型下载路径。同时对比了Ollama(适合个人开发)和vLLM(适合企业生产环境)的不同应用场景,并解释了私有化部署对企业数据安全的重要性。最后提供了从官网下载模型和通过命令行操作的具体指导。Ollama是一款开源软件,可简化大型语言模型(LLM)的本地部署和管理,适合个人开发者体验。
前言
今天教大家利用Ollama简单本地部署一下模型,第一步,我们肯定要先了解ollama,并设置环境。小伙伴们都可以体验一下,首先,我需要给大家说明一下:
一般在企业里面私有化本地部署多数都会选择vllm,因为Ollama 主打极致易用性,是个人开发者本地体验大模型的首选;vLLM 追求性能极限,专为企业级高并发生产环境而生。当然一般也会结合使用,比如用Ollama进行调试,在生产环境使用vllm。接下来我们先来下载一下ollama,亲自体验一下,vllm后面都会进行讲解。
一、私有部署是指
随着 AI 技术普及也暴露出系列问题,其中最严重的是安全问题。
比如企业数据隐私与安全的问题,在金融、医疗、政府等行业,企业数据隐私与安全至关重要。使用公共大模型存敏感数据泄露风险,因其训练可能接触不同来源敏感数据。于是,私有大模型有了市场需求,它让企业或机构用自有数据训练模型,结果供内部或伙伴使用,保障数据隐私安全。此外,内部提效、开发投入等因素,也推动私有大模型成为未来 AI 新方向。
私有化部署是将软件、系统或服务部署在企业自有可控的物理服务器、自建机房或专属云环境,而非依赖第三方公共云平台的部署方式,核心是实现数据存储与系统运行的完全自主管控。
就是把模型部署在本地,保护数据安全。
二、Ollama的简介
1. 什么是Ollama
是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
中文名:羊驼(就是我的头像了)
网址:https://ollama.com
Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。
Ollama的主要功能:包括快速部署和运行各种大语言模型,它还支持从GGUF、PyTorch或Safetensors格式导入自定义模型,并提供了丰富的API和CLI命令行工具,方便开发者进行高级定制和应用开发。
下面就是具体的页面:
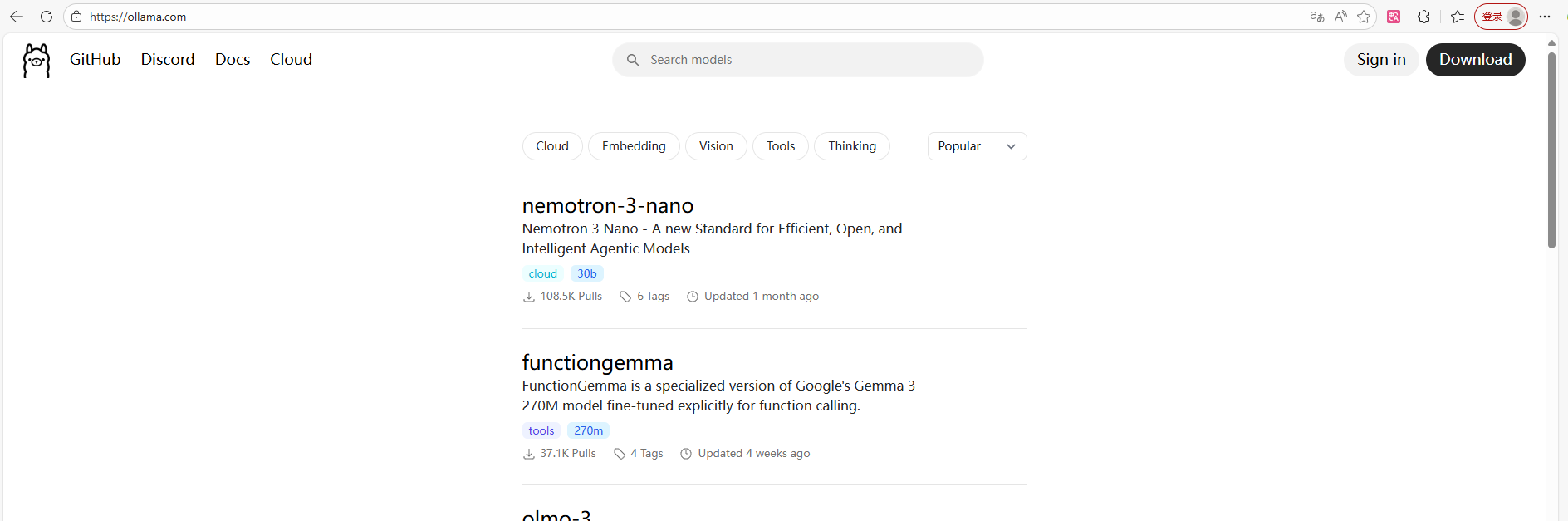
2. Ollama的特点
一站式管理
通过Modelfile将模型权重、配置参数与硬件适配逻辑封装为统一可分发包,自动优化 GPU 显存分配等底层细节,支持自定义系统提示词、工具调用能力等高级配置,无需手动调试复杂环境变量。
热加载模型文件
支持运行中动态切换模型,无需重启服务,配合会话保持机制,切换过程不中断当前交互,可通过/switch <模型名>命令快速在不同能力模型间切换,提升多任务处理效率。
丰富的模型库
内置模型检索系统,涵盖对话、代码、嵌入、OCR、多模态等多种类型,2025-2026 年新增 Llama 3、Qwen 3、Mistral 3、DeepSeek 等前沿模型,支持一键下载运行,无需手动管理权重文件。
多平台支持
全面兼容 Windows、macOS(14+)及 Linux 系统,适配 Intel、NVIDIA、Apple Silicon 等硬件架构,新增 Vulkan GPU 加速支持,确保跨设备一致的运行体验。
无复杂依赖
优化推理引擎大幅减少第三方库依赖,支持纯 CPU 推理与 Apple Silicon 原生加速,安装仅需单条命令完成,无需预装 PyTorch、CUDA 等复杂环境。
资源占用少
采用轻量化代码设计与模型量化技术(4-bit/8-bit),16GB 内存即可流畅运行 8B 参数模型,显存占用较同类工具降低约 30%,适配消费级设备与边缘计算场景。
3.下载方式
- Window:https://ollama.com/download/OllamaSetup.exe
- Mac:https://ollama.com/download/Ollama-darwin.zip
- Linux:https://ollama.com/download/ollama-linux-amd64
复制或者打开链接直接下载,也可以前往官网下载,注意根据自己的系统选择,ollama无法选择安装位置,默认C盘(C:\Users\<你的用户名>\AppData\Local\Ollama),但是可以手动迁移到其他盘。
双击文件即可安装
检查安装是否完成:
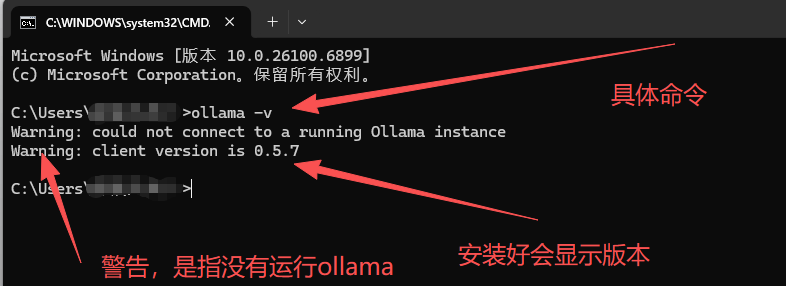
win+R快捷键打开cmd---输入以下命令查看Ollama版本(win就是键盘上的 Windows 徽标键图标,四个白色方块组成的 Windows 标志)
点击确定,进入cmd页面,也可以直接左下角搜索cmd进入
4. 部署大模型
有两种方式下载模型:
1.直接在ollama里面下载,因为现在的版本有了一个UI界面,进入之后可以选择下载模型和在线模型的使用,刚开始进去的时候可能页面无法输入和选择模型,只需要稍等一会就行,因为在联网加载模型信息。
2.直接进入官网下载,模型更多,还可以按照类型选择
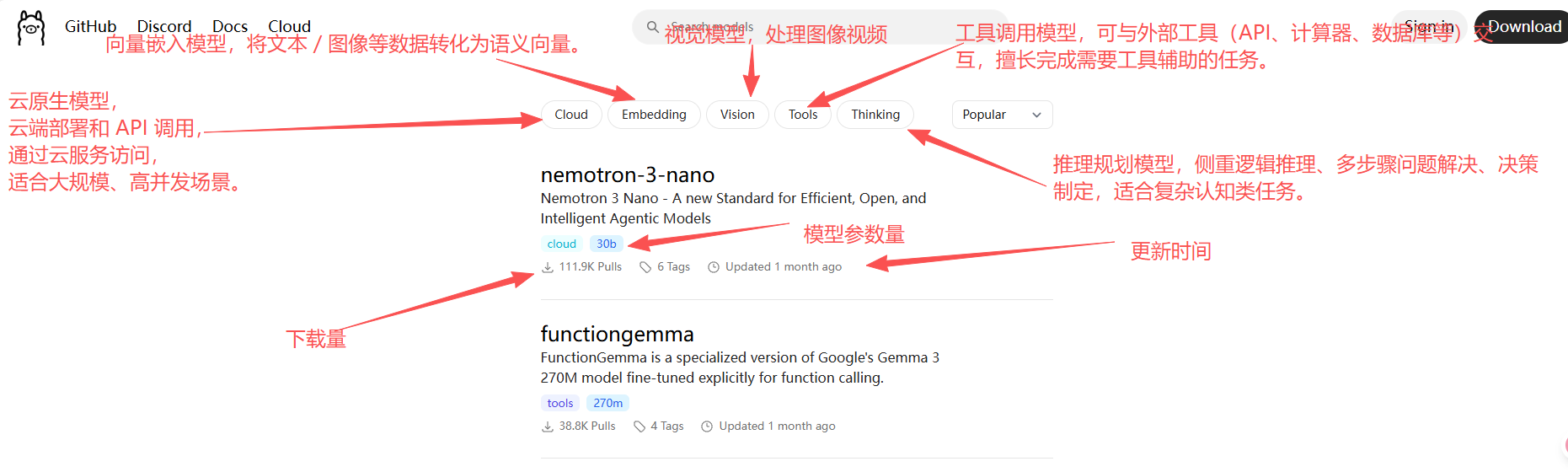
我们以千问为例,进行下载,可以自己选择,参数量越大效果越好,需要的存储空间越大。
直接搜索,选择自己想要下载的版本,进入具体页面
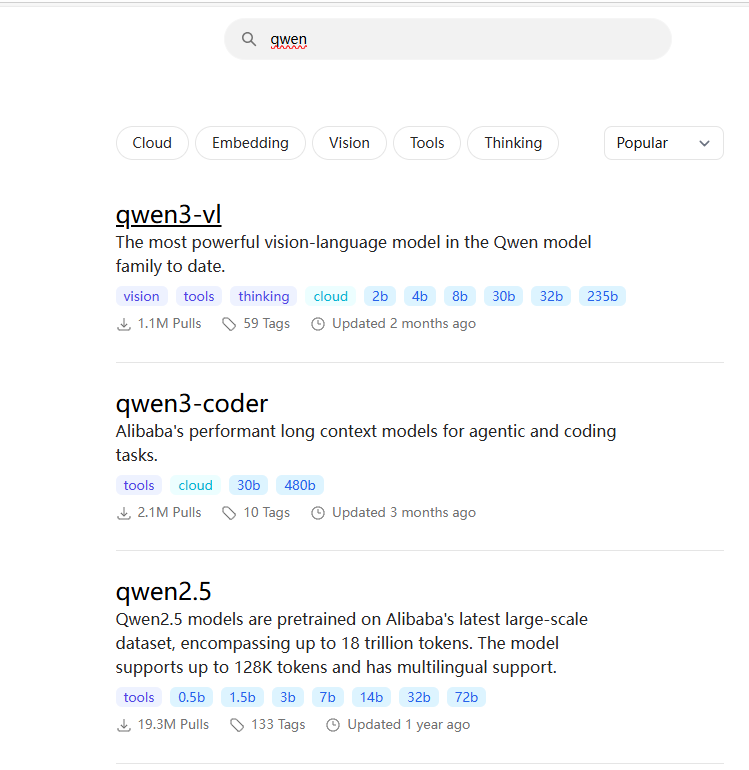
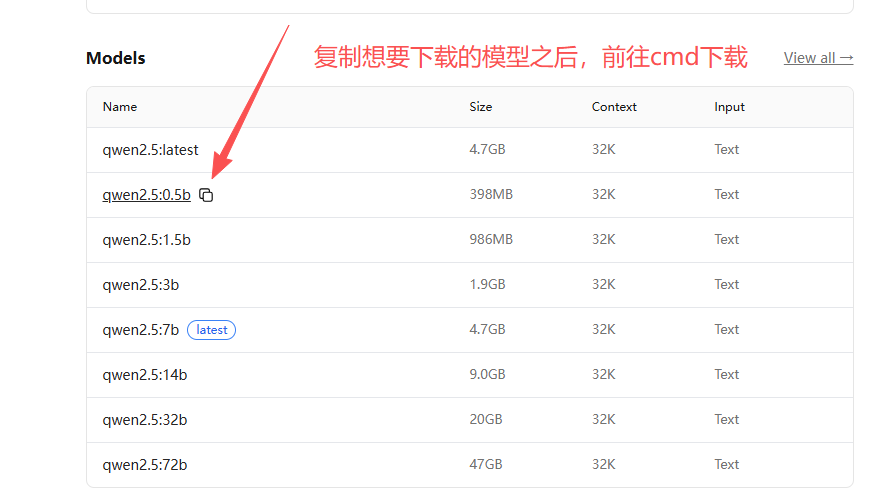
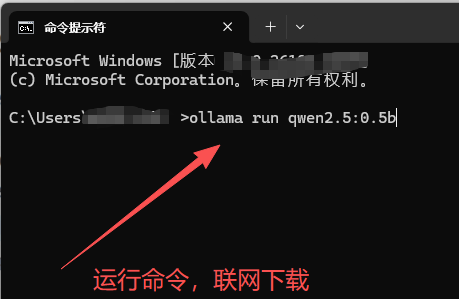
运行命令,下载模型
5. Ollama的常用命令
ollama run <模型名>:启动指定模型并进入交互式对话(如 ollama run llama3),本地无该模型时自动下载。
ollama serve:启动Ollama本地服务器,默认后台自动运行,手动执行多用于调试或配置端口。
ollama pull <模型名>:从 Ollama Hub 下载模型到本地(如 ollama pull qwen2),不启动对话。
ollama list:列出本地已下载的所有模型,展示模型名、ID、大小和修改时间。
ollama show <模型名>:查看指定模型的详细信息,包括参数规模、文件大小、描述及Modelfile内容。
ollama rm <模型名>:删除本地指定模型(如 ollama rm phi3),释放磁盘空间。
ollama cp <原模型名> <新模型名>:复制并重命名模型(如 ollama cp llama3 my-llama3-finetune),适合保存微调后版本。
ollama stop <模型名>:停止后台运行的指定模型进程,释放内存资源。
ollama create <模型名> -f Modelfile:通过Modelfile文件构建自定义模型(支持微调、添加系统提示、组合模型等)。
ollama push <模型名>:将本地自定义模型推送到Ollama Hub,供他人拉取使用。
ollama export <模型名> <文件路径>:将指定模型导出为本地文件(如 `ollama export llama3 ./llama3.gguf`),用于备份/迁移。
ollama import <模型名> <文件路径>:从本地文件导入模型到Ollama(如 `ollama import my-model ./my-model.gguf`),恢复或迁移模型。
常用的也就前六个,其他了解就行,就算忘记了直接大模型搜索就行,很方便。
三、ollama的环境设置步骤
3.1 模型安装位置
Windows 10/11:C:\Users\<你的用户名>\.ollama\models
macOS:/Users/<你的用户名>/.ollama/models
3.2 如何更换模型下载路径
如果所有模型都下载在了C盘,对于我们来说很占硬盘空间,建议下载在其他盘,我们来看看如何操作。
1. 在除C盘外的地方创建一个用于存储模型的目录

2. window配置环境变量OLLAMA_MODELS,指定具体路径
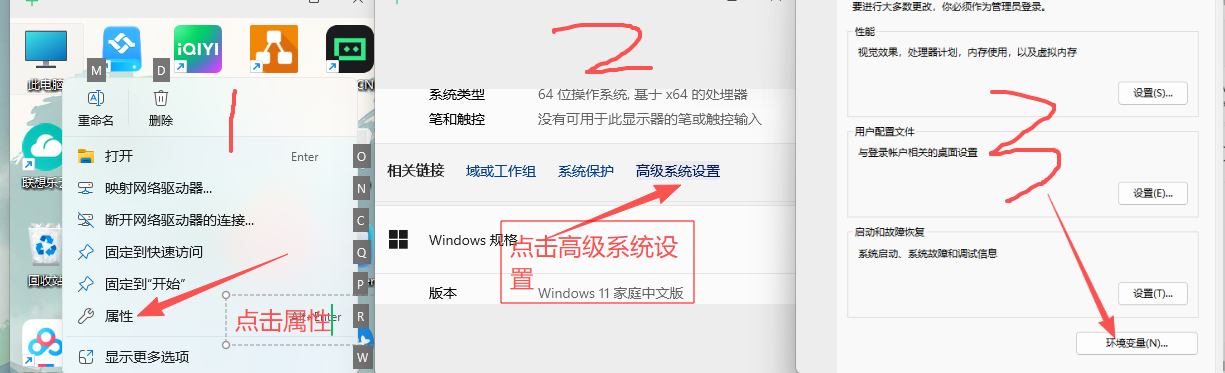
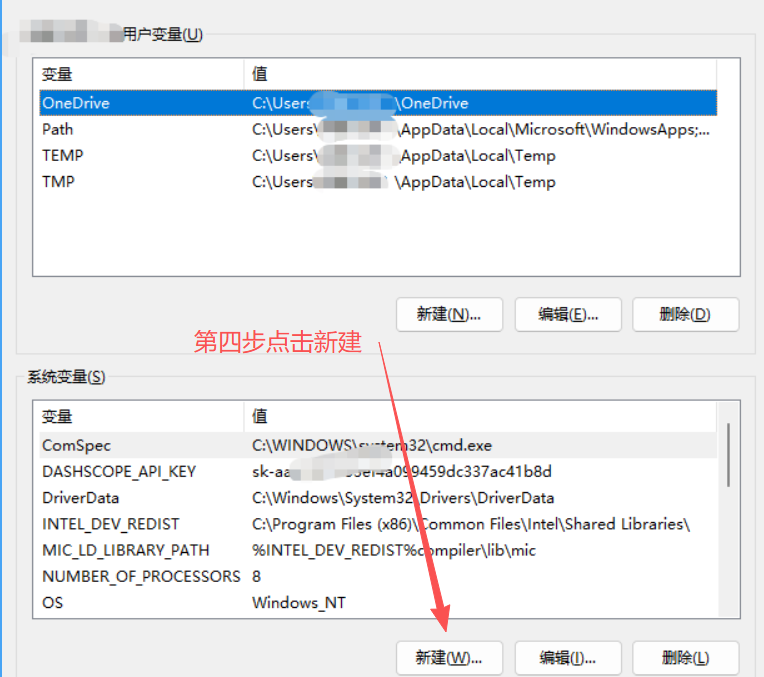
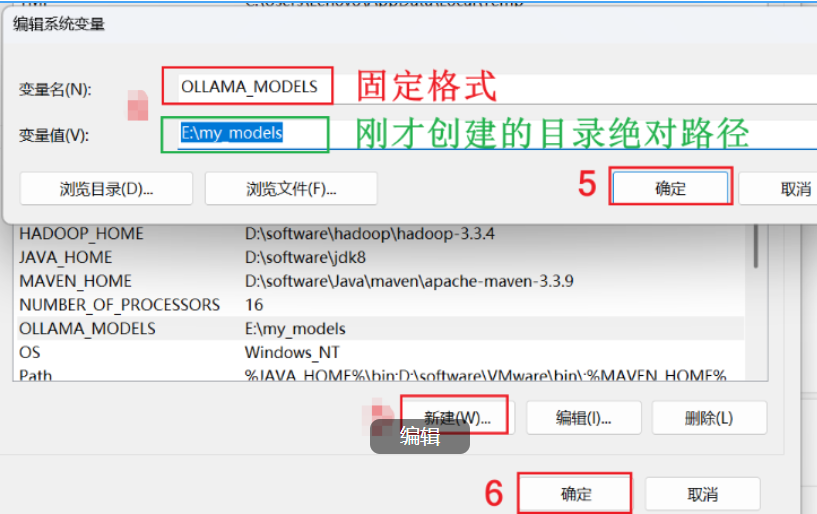
变量名是固定值:OLLAMA_MODELS(复制)
如何复制绝对路径

注意:设置好环境变量之后,一定要重启ollama。在右下角退出Ollama。
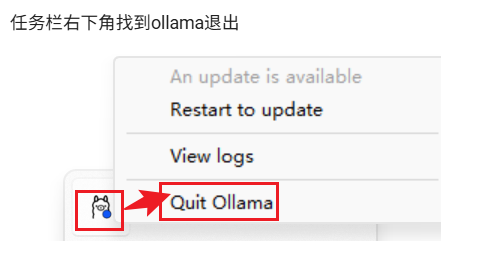

之后下载的模型就会下载在自己设置的文件夹里面。
四、总结
今天的内容就分享结束了,希望小伙伴们能对ollama有一定的了解,进行下载并熟悉命令及环境变量的设置,一定要更换模型下载的路径,因为模型下载的话都很大,一般都是几G大小,甚至更大。
后续就要给大家分享一下,如何使用具体的命令和搭建具体的聊天机器人来体验一下。
上述内容会根据大家的评论和实际情况进行实时更新和改进。
麻烦小伙伴们动一动发财的小手,给小弟点个赞和收藏,如果能获得小伙伴的关注将是我无上的荣耀和前进的动力。
小伙伴们,我是AI大佬的小弟,希望大家喜欢!!!
晚安,兄弟们。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)