【论文速读】Reflexion: 让Agents使用语义梯度强化学习
本文提出了一种名为Reflexion的框架,旨在解决大型语言模型 (LLM) 在作为智能体 (Agent) 执行任务时,难以通过传统的强化学习 (RL) 方法进行快速、低成本学习的问题。Reflexion 的本质是将“策略优化” (Policy Optimization) 从参数空间 (Parameter Space) 转移到了上下文空间 (Context Space)。
论文标题: Reflexion: Language Agents with Verbal Reinforcement Learning
作者: Noah Shinn 1 ^{1} 1, Federico Cassano 1 ^{1} 1, Ashwin Gopinath 2 ^{2} 2, Karthik Narasimhan 3 ^{3} 3, Shunyu Yao 3 ^{3} 3
单位: 1 ^1 1Northeastern University, 2 ^2 2MIT, 3 ^3 3Princeton University
代码: https://github.com/noahshinn024/reflexion
5. 总结
本文提出了一种名为 Reflexion 的框架,旨在解决大型语言模型 (LLM) 在作为智能体 (Agent) 执行任务时,难以通过传统的强化学习 (RL) 方法进行快速、低成本学习的问题。
Reflexion 的本质是将 “策略优化” (Policy Optimization) 从参数空间 (Parameter Space) 转移到了上下文空间 (Context Space)。不同于传统的 RL 需要更新神经网络权重 (Weights),Reflexion 利用 LLM 的语言能力,将环境的二元或标量反馈转化为 语言形式的自我反思 (Verbal Self-Reflection)。这些反思作为一种“语义梯度”,存储在情节记忆 (Episodic Memory) 中,诱导智能体在随后的试验中做出更好的决策。
实验表明,Reflexion 在决策制定 (AlfWorld)、推理 (HotPotQA) 和编程 (HumanEval) 任务上均取得了显著超越基线 (ReAct, CoT) 的性能。特别是在 HumanEval 上,它达到了 91% 的 pass@1 准确率,超过了当时 GPT-4 的 80%。这标志着赋予 Agent 自我纠错和迭代学习能力是通往更高级自主智能的关键一步。
1. 思想
-
大问题:
- 当前的 LLM Agent(如 ReAct, Toolformer)虽然具备决策能力,但在面对错误时缺乏高效的学习机制。
- 传统的强化学习(如 PPO)对于 LLM 来说极其昂贵(计算量大、时间长),且需要大量的训练样本,难以适应少样本 (Few-Shot) 场景。如何让冻结参数的 LLM 像人类一样从试错中快速学习?
-
小问题:
- 稀疏奖励的局限性: 环境通常只提供二元成功/失败信号或标量分数,缺乏关于“哪里错了”和“如何改进”的具体信息。LLM 难以直接从
Reward=0中推导出正确的 Action。 - 信用分配 (Credit Assignment): 在长序列任务中,很难确定是哪一步操作导致了最终的失败。
- 上下文限制: 如何在有限的上下文窗口内保留对未来尝试最有价值的经验,而不是简单地堆砌历史轨迹?
- 稀疏奖励的局限性: 环境通常只提供二元成功/失败信号或标量分数,缺乏关于“哪里错了”和“如何改进”的具体信息。LLM 难以直接从
-
核心思想:
- 语言反馈强化 (Verbal Reinforcement): 放弃调整权重 θ \theta θ,转而调整输入上下文。将环境的反馈信号通过一个 Self-Reflection 模型 转化为具体的语言描述(即“反思”)。
- 模拟人类的短期记忆: 这种机制模仿了人类的短期记忆工作方式——当我们犯错时,我们在脑海中用语言总结教训(例如“我不应该在这个抽屉里找钥匙,因为我已经找过了”),并在下一次尝试时调用这个总结。
- 元学习循环: 构建一个
Trial -> Evaluation -> Reflection -> Memory -> Next Trial的闭环,使 Agent 能够在数次尝试内通过语义推理自我修正。
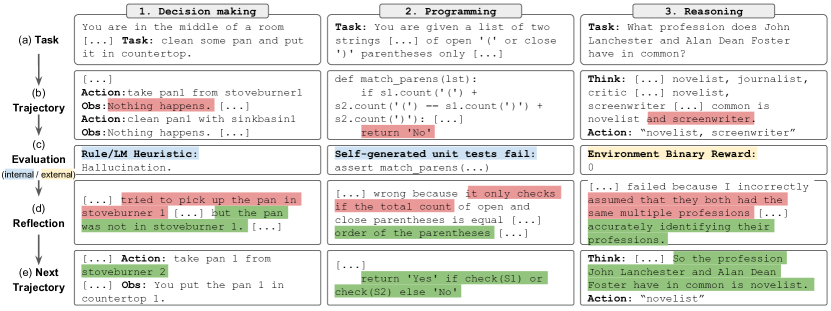
Figure 1: Reflexion 工作流程概览。在决策、编程和推理任务中,Agent 通过试错和自我反思来优化自身行为。
2. 方法
Reflexion 框架由三个模块化组件构成:Actor (执行者)、Evaluator (评估者) 和 Self-Reflection (自我反思者)。它们协同工作,通过迭代过程优化 Agent 的表现。
2.1 核心组件定义
-
Actor ( M a M_a Ma):
- 这是一个基于 LLM 的生成模型,负责根据状态观测生成文本或动作。
- 形式化为策略 π θ ( a t ∣ s t , m e m ) \pi_\theta(a_t | s_t, mem) πθ(at∣st,mem),其中 a t a_t at 是动作, s t s_t st 是当前观测, m e m mem mem 是存储的历史反思。注意, θ \theta θ 在训练过程中保持不变。
-
Evaluator ( M e M_e Me):
- 负责评估 Actor 生成的轨迹 τ \tau τ 的质量,并产生奖励分数 r r r。
- 根据任务不同,Evaluator 可以是:
- 精确匹配 (EM): 用于推理任务 (如 QA)。
- 预定义启发式 (Heuristics): 用于决策任务 (如检测循环动作)。
- 单元测试执行: 用于编程任务 (代码是否通过测试)。
- LLM 自身: 让另一个 LLM 充当裁判。
-
**Self-Reflection ( M s r M_{sr} Msr) **:
- 这是一个 LLM,其作用是针对失败的轨迹生成语言反馈 (Verbal Feedback)。
- 输入:稀疏奖励 r r r (如失败) + 当前轨迹 τ \tau τ + 历史记忆 m e m mem mem。
- 输出:反思摘要 s r t sr_t srt。
- 这一步解决了信用分配问题,通过语言推理识别出导致失败的具体步骤。
-
Memory ( m e m mem mem):
- 短期记忆: 当前试验的轨迹 τ t \tau_t τt。
- 长期记忆: 存储历史试验生成的反思 m e m = [ s r 0 , s r 1 , . . . , s r t ] mem = [sr_0, sr_1, ..., sr_t] mem=[sr0,sr1,...,srt]。
- 在推理时,Actor 的上下文会被填充这些 s r sr sr,“提示”它不要重蹈覆辙。
2.2 算法流程 (Reflexion Process)
Reflexion 被形式化为一个迭代优化过程。假设最大试验次数为 N N N。
- 初始化: m e m = ∅ mem = \emptyset mem=∅, t = 0 t = 0 t=0.
- 循环 (直到成功或达到 t m a x t_{max} tmax):
- 执行 (Act): Actor 基于当前记忆生成轨迹 τ t \tau_t τt。
τ t ∼ π θ ( ⋅ ∣ s 0 , m e m ) \tau_t \sim \pi_\theta(\cdot | s_0, mem) τt∼πθ(⋅∣s0,mem) - 评估 (Evaluate): Evaluator 对轨迹评分。
r t = M e ( τ t ) r_t = M_e(\tau_t) rt=Me(τt) - 判断: 如果 r t r_t rt 表示成功,则退出循环。
- 反思 (Reflect): 如果失败,Self-Reflection 模型分析 τ t \tau_t τt 和 r t r_t rt,生成反思 s r t sr_t srt。
s r t = M s r ( τ t , r t , m e m ) sr_t = M_{sr}(\tau_t, r_t, mem) srt=Msr(τt,rt,mem) - 记忆更新 (Memorize): 将反思追加到记忆中 (通常限制保留最近的 Ω \Omega Ω 条以适应 Context Window)。
m e m ← m e m ∪ { s r t } t ← t + 1 mem \leftarrow mem \cup \{sr_t\} \\ t \leftarrow t + 1 mem←mem∪{srt}t←t+1
- 执行 (Act): Actor 基于当前记忆生成轨迹 τ t \tau_t τt。
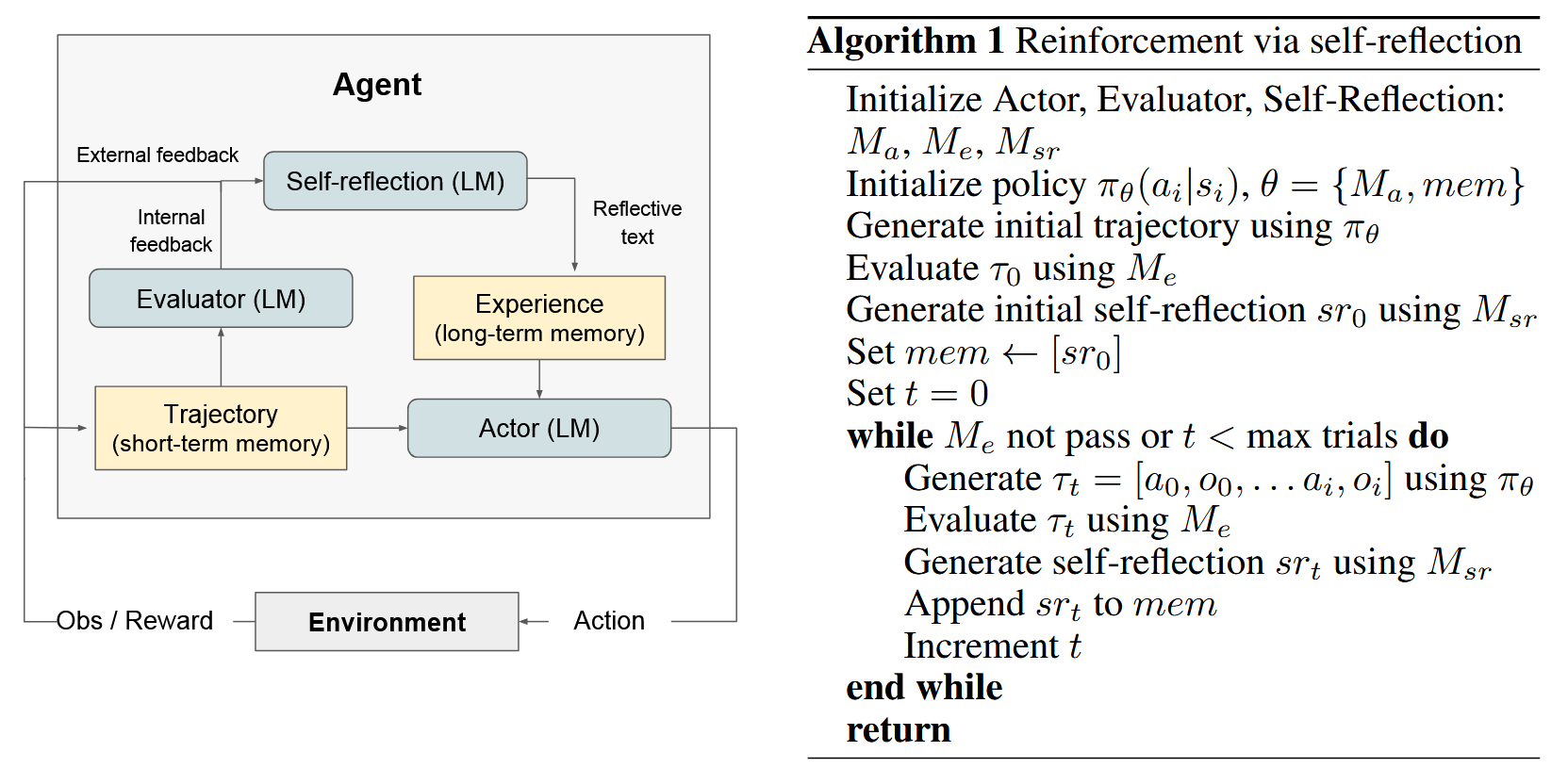
Figure 2: Reflexion 的强化学习算法流程图。核心在于通过 Self-reflection (LM) 将二元/标量反馈转化为具体的 Reflective text 并存入 Memory。
2.3 编程任务中的特殊实现
对于编程任务,Reflexion 利用了测试驱动开发 (TDD) 的思想:
- Evaluator: 是一套单元测试。
- Internal Tests: Agent 自己编写单元测试来验证代码(这是自洽性的一种体现)。
- 流程: 生成代码 -> 运行内部测试 -> 如果失败,Reflexion 模型根据报错信息(stderr/stdout)生成建议 -> 修改代码。
3. 优势
相比于 PPO 等传统 RL 方法或 ReAct 等单纯的 Prompt 工程,Reflexion 具有以下独特优势:
- 轻量级 (Lightweight): 不需要微调庞大的 LLM 参数,节省了巨大的计算资源。
- 对比: RLHF 需要训练 Actor 和 Critic 网络。
- 语义效率 (Semantic Efficiency): 反馈是自然语言形式,相比标量 Reward,它包含了更丰富的“梯度”信息(即改进方向)。
- 对比: 传统 RL 的 scalar reward 极其稀疏,需要海量样本探索。
- 可解释性 (Interpretability): 记忆模块存储的是人类可读的文本,我们可以清楚地看到 Agent 是如何“思考”并修正错误的。
- 通用性: 适用于任何可以通过 API 访问的黑盒 LLM (如 GPT-4)。
4. 实验
作者在三类截然不同的任务上评估了 Reflexion。
4.1 任务与设置
- 顺序决策 (Sequential Decision Making): AlfWorld 环境。
- 任务:在模拟家庭环境中寻找和操作物体。
- 难点:长视距规划,状态空间巨大。
- 推理 (Reasoning): HotPotQA 数据集。
- 任务:多跳问答。
- 难点:需要检索并整合多个文档的信息。
- 代码生成 (Programming): HumanEval, MBPP, 和自建的 LeetcodeHardGym。
- 任务:根据文档生成 Python/Rust 代码。
- 难点:语法严格,逻辑复杂。
4.2 实验结果
AlfWorld (决策)
- Reflexion 显著优于 ReAct。在 12 次迭代学习步骤中,Reflexion 相比强基线提高了 22% 的绝对成功率。
- 现象: ReAct 容易陷入循环动作或产生幻觉,而 Reflexion 能通过反思“我之前已经检查过桌子了,现在应该检查抽屉”来打破循环。
HotPotQA (推理)
- Reflexion 相比 ReAct 提升了 20% 的性能。
- Reflexion 能够纠正错误的检索路径,例如“我搜索了错误的关键词,导致没有结果,下次应该搜索…”。
HumanEval (编程) - 最惊艳的结果
- 在 Python 代码生成任务上,Reflexion 达到了 91.0% Pass@1 的准确率。
- 对比: 之前的 SOTA GPT-4 仅为 80.1%。
- 这证明了即使是强大的 GPT-4,通过 Reflexion 的自我反思循环,也能解锁显著的性能提升。

Table 1: HumanEval 和 MBPP 上的 Pass@1 准确率。Reflexion 在 Python 和 Rust 语言上均取得了 SOTA 结果。
4.3 消融研究 (Ablation Study)
- Self-Reflection 的必要性: 如果只保留记忆(Episodic Memory)但去掉反思生成步骤(只存储原始轨迹),性能提升大幅下降。这说明将错误轨迹“消化”为高级的语言总结是学习的关键。
- Loop 的作用: 随着试验次数 t t t 的增加,成功率呈现明显的上升趋势,证明 Agent 确实在“学习”。
附录
Reflexion Actor instruction
You are a Python writing assistant.You will be given your previous implementation of a function
a series of unit tests results,and your self-reflection on your previous implementation.Apply the
necessary changes below by responding only with the improved body of the function.Do not include
the signature in your response.The first line of your response should have 4 spaces of indentation so
that it fits syntactically with the user provided signature.You will be given a few examples by the
user.
Reflexion Actor 使用如下格式:
(Instruction)
(Function implementation)
(Unit test feedback)
(Self-reflection)
(Instruction for next function implmentation)
Reflexion Self-reflection instruction and example
You are a Python writing assistant.You will be given your previous implementation of a function.
a series of unit tests results,and your self-reflection on your previous implementation.Apply the
necessary changes below by responding only with the improved body of the function.Do not include
the signature in your response.The first line of your response should have 4 spaces of indentation so
that it fits syntactically with the user provided signature.You will be given a few examples by the
user.
Reflexion Self-Reflection 使用如下格式:
(Instruction)
(Function implementation)
(Unit test feedback)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)