训练一个垂直领域大模型,真正训练一个模型,不是只做 RAG,到底要做哪些步骤
摘要:大模型训练与知识库的核心区别在于:训练是通过海量数据调整模型参数使其具备通用能力,而知识库是模型可查询的外部信息库。训练垂直领域大模型的流程包括:1)明确目标范围;2)数据准备(占70%重要性);3)选择基础模型(通常基于已有模型微调);4)训练阶段(继续预训练或指令微调);5)对齐优化(RLHF等);6)专业评估;7)部署监控。整个过程强调数据质量、专业评估和持续更新,训练与知识库相互补充
目录
(2)指令微调(SFT, Supervised Fine-tuning)
一、大模型训练与知识库的区别
1. 训练(Training)是什么?
训练是 “让模型学会语言、知识和能力” 的过程。就像小孩上学,从大量书本和经验中学习规律。
训练的特点:
-
使用海量原始数据(网页、书籍、对话等)
-
调整模型内部的参数
-
训练一次成本极高(时间、算力)
-
训练后模型具备 “通用能力”(理解、生成、推理等)
2. 知识库(Knowledge Base)是什么?
知识库是 “模型在回答问题时可以查阅的外部信息库”。就像你做题时可以翻的参考书。
知识库的特点:
-
是外部数据,不改变模型参数
-
可以随时更新
-
用于补充模型训练时没学到或已经过时的知识
-
常见方式:RAG(检索增强生成)
3. 两者的关系
-
训练 = 让模型 “脑子里有东西”
-
知识库 = 让模型 “能查资料”
-
训练是基础,知识库是增强
-
知识库不能替代训练,训练也不能替代知识库
4. 简单比喻
训练 = 把书背进脑子里
知识库 = 桌上放着一本可以随时翻的百科全书
二、训练垂直领域大模型的完整流程
可以把它理解成:准备数据 → 训练底座 → 做领域适配 → 评估 → 部署
下面分步骤讲。
1. 明确目标与范围(非常关键)
你必须先确定:
-
模型要解决什么任务?(问答?文档生成?代码?客服?)
-
领域是什么?(医疗、法律、金融、教育、制造…)
-
模型规模多大?(7B、13B、70B…)
-
是要从头训练,还是基于现有大模型做微调?
这一步决定后面所有成本。
2. 数据准备(决定模型上限)
垂直领域模型的成败 70% 取决于数据。
主要包括:
-
公开领域数据(论文、文档、网页)
-
私有数据(企业内部文档、历史对话、专家知识)
-
高质量标注数据(用于指令微调)
数据处理步骤:
-
数据收集
-
清洗(去重、去噪、过滤低质内容)
-
结构化(尤其是文档类)
-
划分训练集 / 验证集 / 测试集
如果是企业场景,通常需要:
-
文档解析(PDF、Word、PPT)
-
长文档分段
-
自动抽取知识(如术语、FAQ、流程)
3. 选择基础模型(通常不会从零训练)
从零训练一个大模型成本极高(上亿级别)。大多数企业会选择:
-
基于已有大模型做微调(LoRA、QLoRA、全参数微调)
-
或基于开源底座(如 Llama、Qwen、Mistral)做继续预训练
选择底座时看:
-
模型能力
-
许可证是否允许商用
-
推理成本
-
社区生态
4. 训练阶段(核心部分)
训练一般分为两类:
(1)继续预训练(Pre-training)
适用场景:
-
领域知识非常专业(如医疗、法律)
-
通用模型缺乏相关术语和知识
目标:让模型 “学会领域语言”。
做法:
-
使用大量领域文档
-
训练方式类似原始预训练
-
成本较高,但效果强
(2)指令微调(SFT, Supervised Fine-tuning)
适用场景:
-
让模型学会 “按指令做事”
-
让输出更符合行业格式、风格、规则
数据形式:
-
指令 → 输出
-
多轮对话
方法:
-
LoRA(最常用,成本低)
-
QLoRA(更省显存)
-
全参数微调(效果最好但最贵)
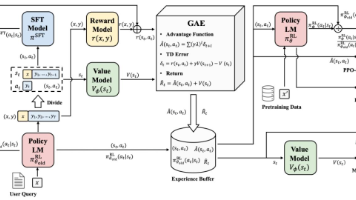
5. 对齐与优化(可选但推荐)
包括:
-
RLHF(基于人类反馈的强化学习)
-
奖励模型训练(RM)
-
对齐到行业规范(如医疗不能胡说、法律不能给虚假建议)
这一步让模型 “听话、安全、可靠”。
6. 评估(非常重要)
垂直领域模型必须做专业评估。
评估内容:
-
知识准确性(是否胡说)
-
任务完成度(是否按要求输出)
-
格式规范性(如医疗文书、法律合同)
-
速度与成本
-
安全风险(敏感信息泄露、幻觉)
评估方式:
-
自动评估(用另一个大模型打分)
-
人工评估(行业专家)
-
测试集评估(Perplexity、EM、F1 等)
7. 部署与推理(上线)
包括:
-
模型量化(4bit、8bit)
-
推理框架(vLLM、TensorRT-LLM、DeepSpeed)
-
API 服务化
-
监控(幻觉、延迟、错误率)
-
持续更新(增量微调、RAG 补充)
三、简化版总结
训练垂直领域大模型的步骤:
-
明确任务与范围
-
数据收集与清洗
-
选择基础模型
-
继续预训练(可选)
-
指令微调(SFT)
-
RLHF / 对齐(可选)
-
评估
-
部署与监控

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)