厦门大学曹刘娟团队FastVGGT:四倍速度提升,打破VGGT推理瓶颈并降低累积误差!
文章标题:FastVGGT: Training-Free Acceleration of Visual Geometry Transformer项目链接:https://mystorm16.github.io/fastvggt/文章链接:https://arxiv.org/abs/2509.02560代码链接:https://github.com/mystorm16/FastVGGT。
文章标题:FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
项目链接:https://mystorm16.github.io/fastvggt/
文章链接:https://arxiv.org/abs/2509.02560
代码链接:https://github.com/mystorm16/FastVGGT
一、主要贡献
- 系统分析了 VGGT 推理速度的瓶颈。
- 观察到 VGGT 全局注意力机制的冗余特性,首次将 token merging 引入前向3D模型。
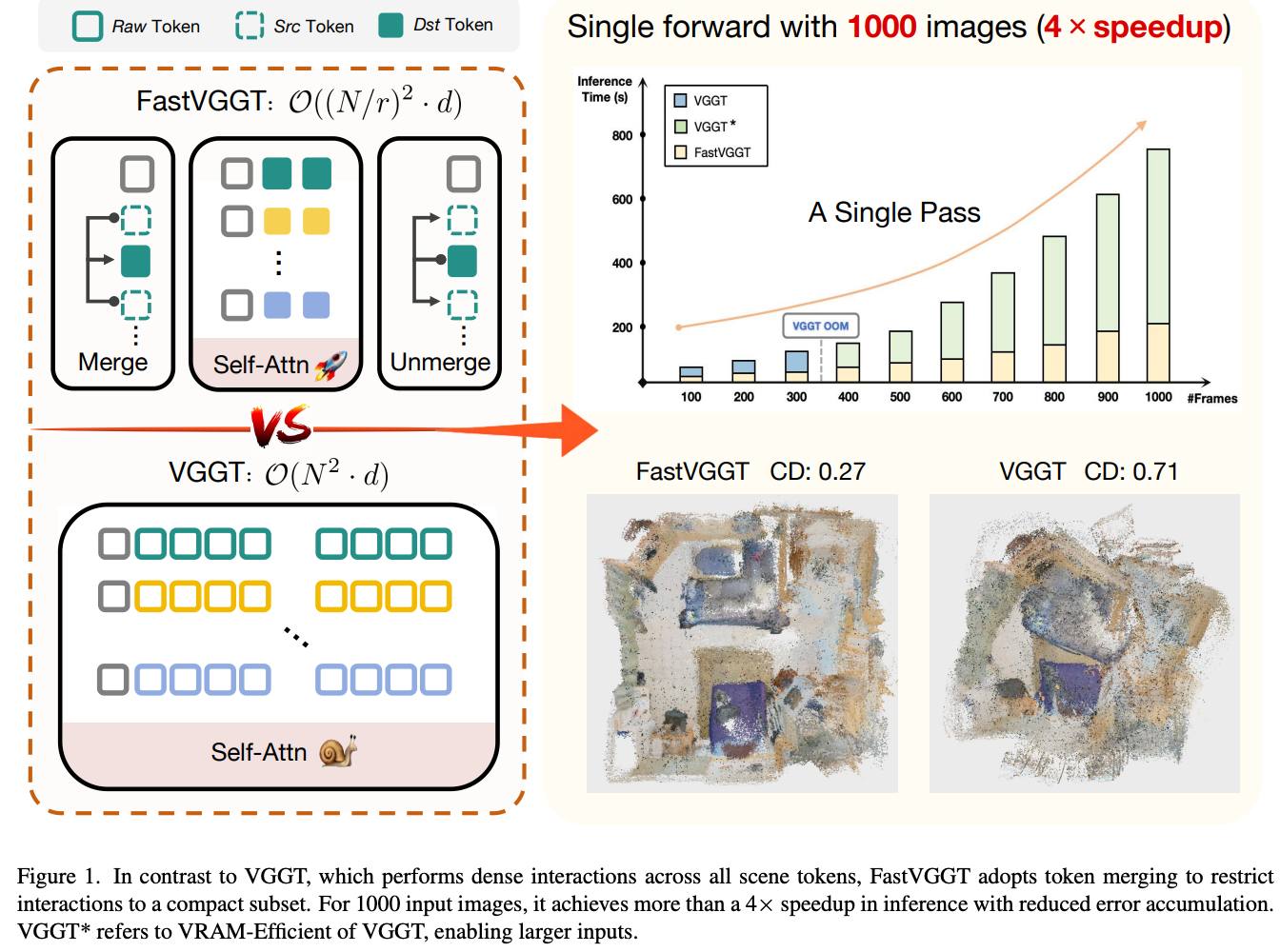
- 基于VGGT的工程优化,使得VGGT可以在单GPU(80G VRAM)一次前向处理1000张输入图像(优化前为300张输入)。
- 提出FastVGGT,在 1000 张图像推理任务中实现 4× 加速,并有效降低了 VGGT 的累积误差。
二、瓶颈分析
2.1 推理效率问题:
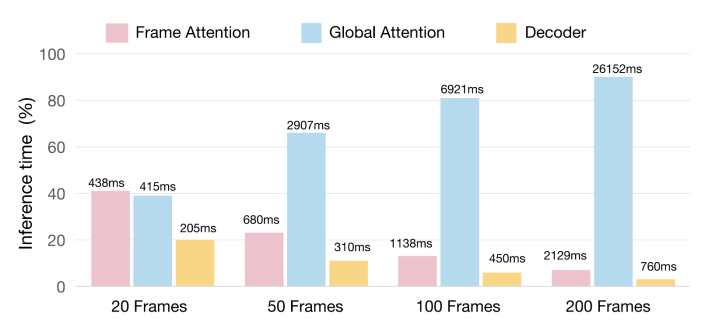
- Frame Attention(帧内交互) 与 Global Attention(跨帧交互)在短序列时,两者开销相当;但随着帧数增加,Global Attention 的计算量占据主要时间消耗。
- 时间复杂度:即便VGGT使用 Flash-Attention 将内存复杂度降到 O(nd),时间复杂度仍然是O(n²d)。
2.2 累积误差问题:
- VGGT 的 全局注意力机制会在跨帧关联时逐渐放大细微错误。
- 随着序列延长,token 空间不断扩展,误差被累积和放大,导致预测结果漂移,影响重建稳定性。
三、观察:全局注意力存在大量冗余
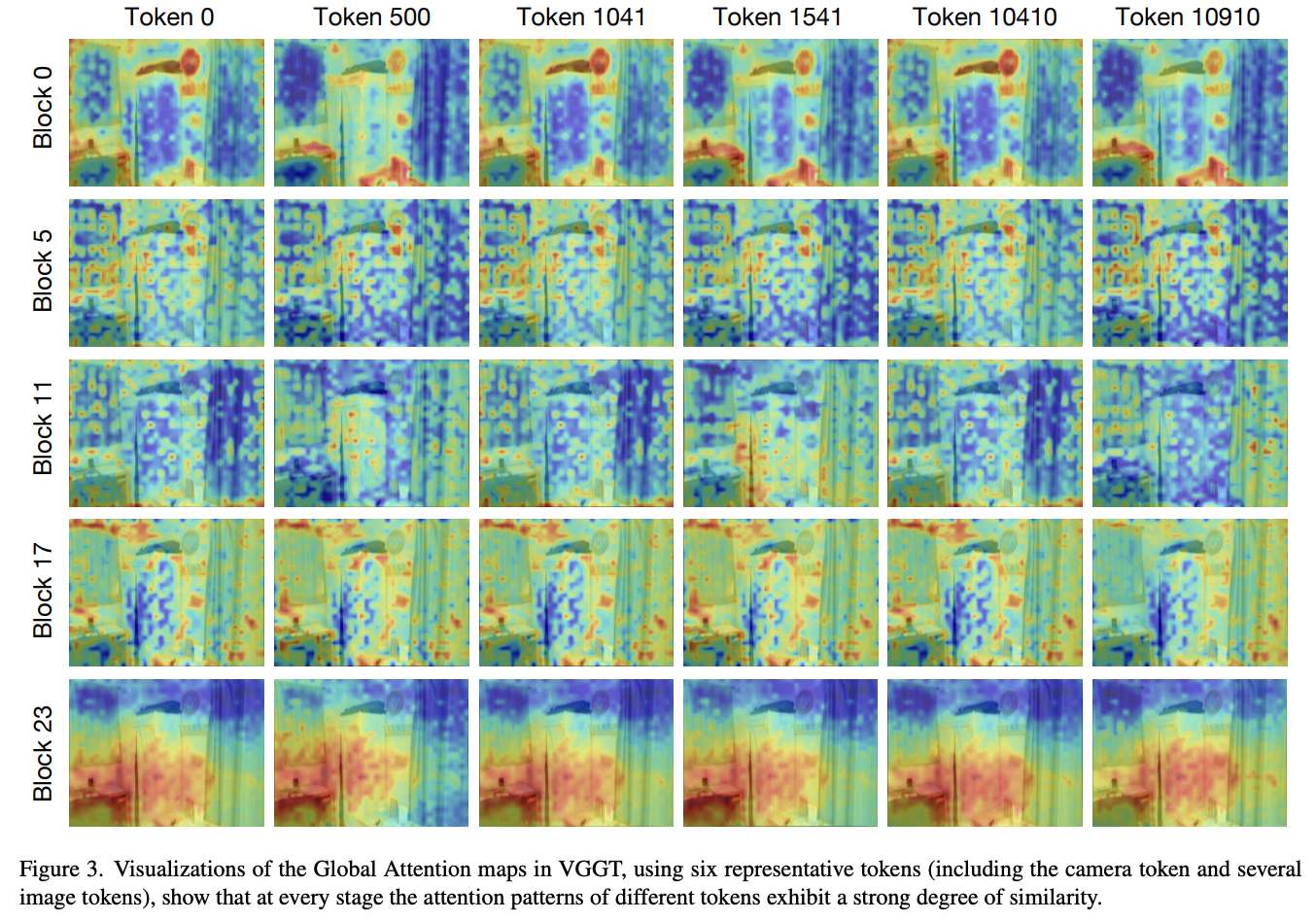
- 在 VGGT 的 Global Attention 中,同一 Block 下不同 token 的注意力图几乎重合,说明大量 token 之间的信息存在冗余,许多计算并未引入新的信息。
- 这种全局层面的差异性丧失(token collapse)现象在 DINO 系列中也曾出现。不同的是,在 DINO 中,这种退化会削弱密集预测任务的效果;而在 VGGT 中,由于采用了 Global + Frame Attention 的混合模式,全局退化反而在一定程度上反映了场景一致性。然而,这种相似性也带来了计算冗余,为后续优化提供了空间。
四、方法
4.1 Token划分:
我们探索了 training-free 的 token merging 方法来优化 VGGT 中的冗余注意力。Token merging 在 2D 视觉任务中已有较为成熟的应用,但在 3D 架构中的探索仍然十分有限。针对 visual geometry 模型的特点,我们提出了三种简洁而高效的 token merging 策略:
- 参考系约束:第一帧作为全局的参考系,别的token都对第一帧的token有非常强的注意力,因此全部作为destination token,
- 关键token保留:为保持全局连续性并避免破坏匹配所需的重要信息,我们在场景中保留 特异性最高的 token 作为 salient token。这些 token 不作为 merging 的目标,也不被合并,而是仅参与注意力计算。
- 基于区域的采样:受 ToMeSD 启发,我们在帧内对 token 进行 region-based sampling,分别采样 destination token 与 source token,以确保采样均匀性,避免过度丢失局部信息。
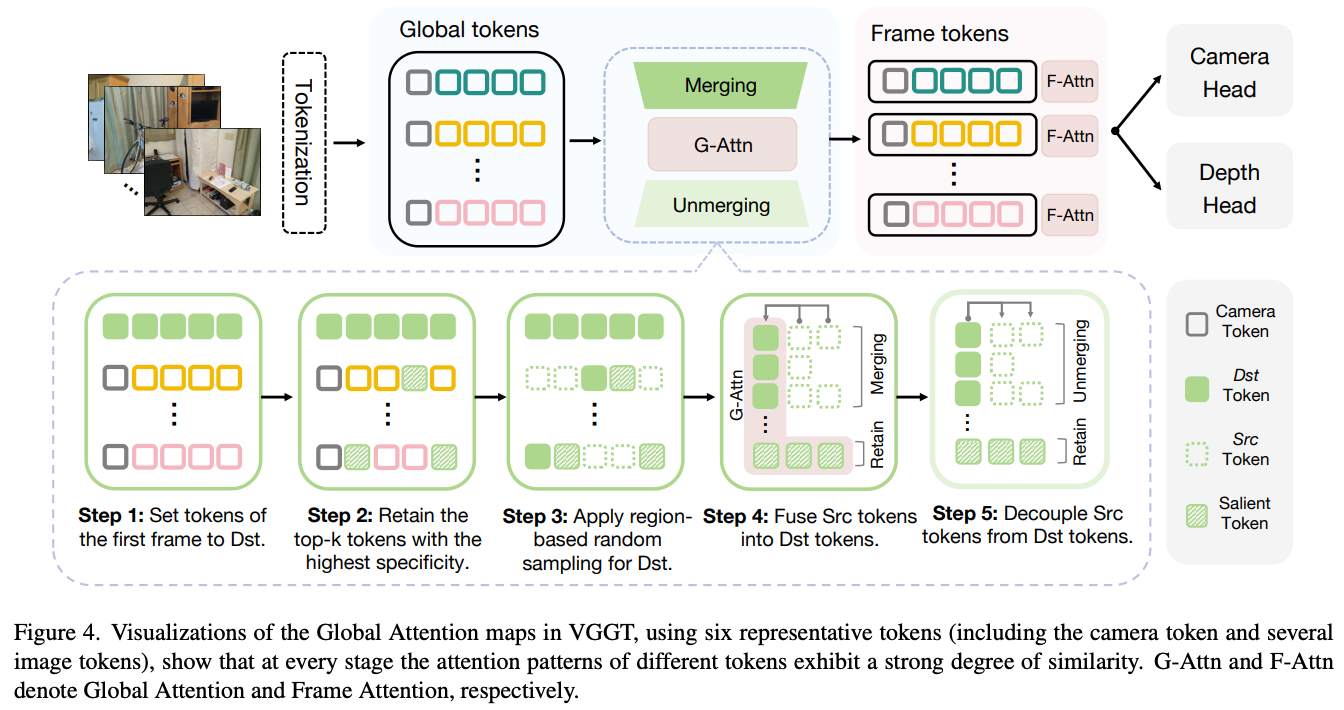
4.2 Token Merging:
我们计算每个 source token (src) 与所有 destination token (dst)的余弦相似度
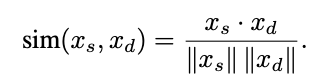
将每个src token 合并到最相似的 dst token 中
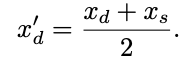
合并完成后,source token 将被丢弃,从而显著减少参与注意力计算的 token 数量。
4.3 Token Unmerging:
在 3D 重建任务中,模型需要逐 token 地生成密集输出(例如深度图或点云)。这意味着每个输入 patch/token 在解码器阶段都必须对应一个输出。为此,我们引入 Token Unmerging 机制:将合并后的 token 复制回其原始位置,从而恢复输入 token 的数量。这一过程既保证了密集 3D 重建输出的完整性,又保持了与 VGGT 的完全兼容性。
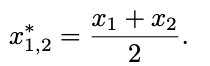
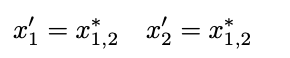
五、实验
5.1 数据集
- ScanNet-50:从 1500 个场景中均匀均匀抽样 50 个,作为主要测试集。
- 7Scenes、NRGBD:用于进一步验证模型的泛化能力。
5.2 任务
- 点云重建(Point Map Reconstruction)
- 相机位姿估计(Camera Pose Estimation)
5.3 模型配置
- VGGT* 作为 baseline(显存优化版本的VGGT,在前向过程中手动清理VGGT encoder产生的中间变量,使得A800可以塞入1000张image)
- GPU:NVIDIA A800 GPU (80GB VRAM)。
- 所有实验均采用FlashAttention-V2,未采用xFormers。
5.4 点云重建实验
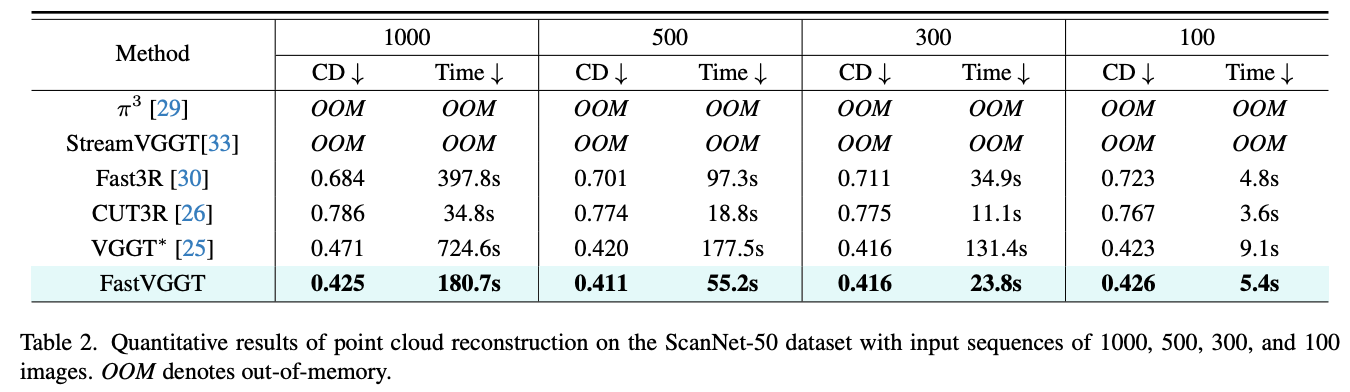
(a) ScanNet-50
- 输入帧数:100、300、500、1000。
- 评价指标:Chamfer Distance (CD)、推理时间。
- 结果:FastVGGT 相比 VGGT*,在 1000 帧输入下加速 4倍(724.6s → 180.7s),并具有更好的重建质量(0.471 → 0.425)。
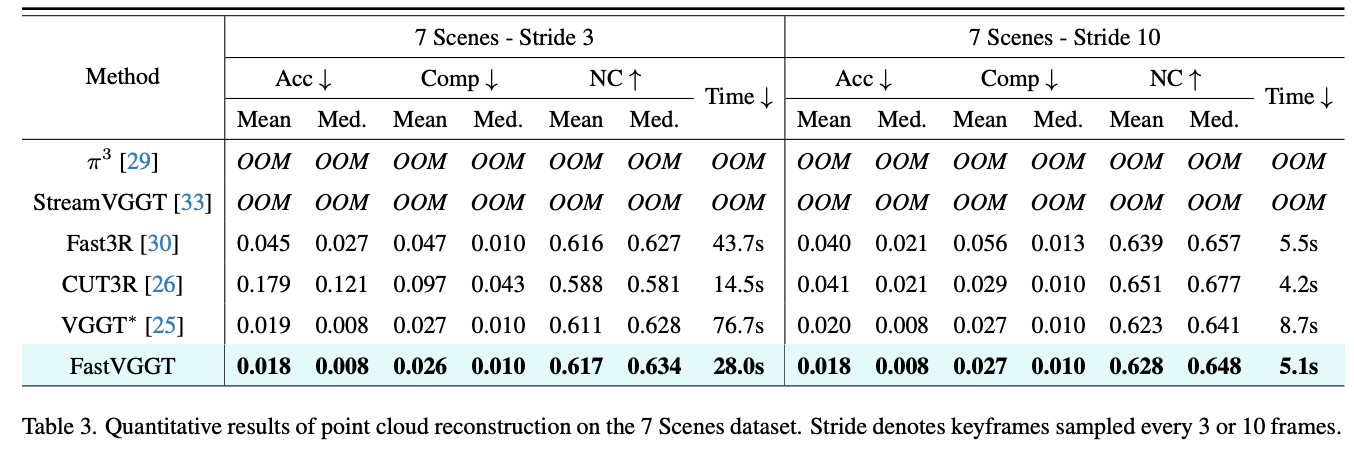
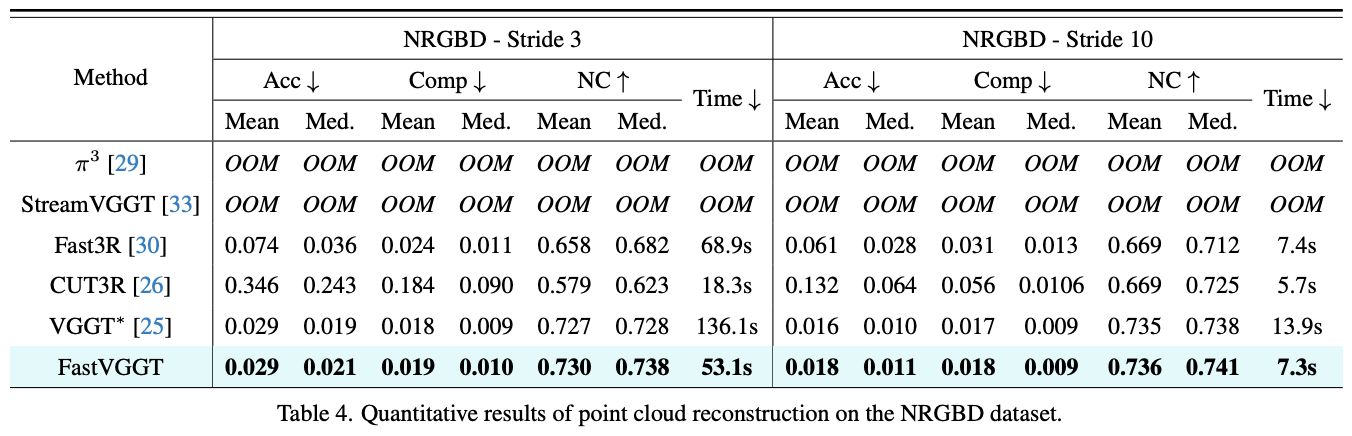
(b) 7 Scenes & NRGBD
- 输入设置:每隔 3 帧或 10 帧采样 keyframe 作为输入。
- 评价指标:Accuracy (Acc)、Completeness (Comp)、Normal Consistency (NC)、推理时间。
- 结果:FastVGGT 在 7Scenes 与 NRGBD 上延续了 ScanNet 实验的结论:在显著缩短推理时间的同时,仍保持了 VGGT 的强大重建性能。
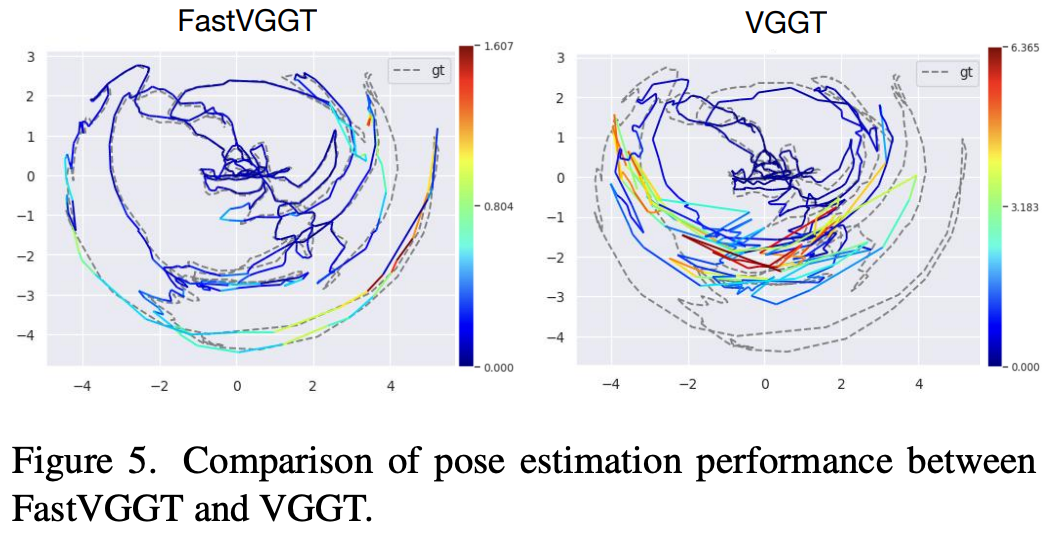
5.5 点云重建实验
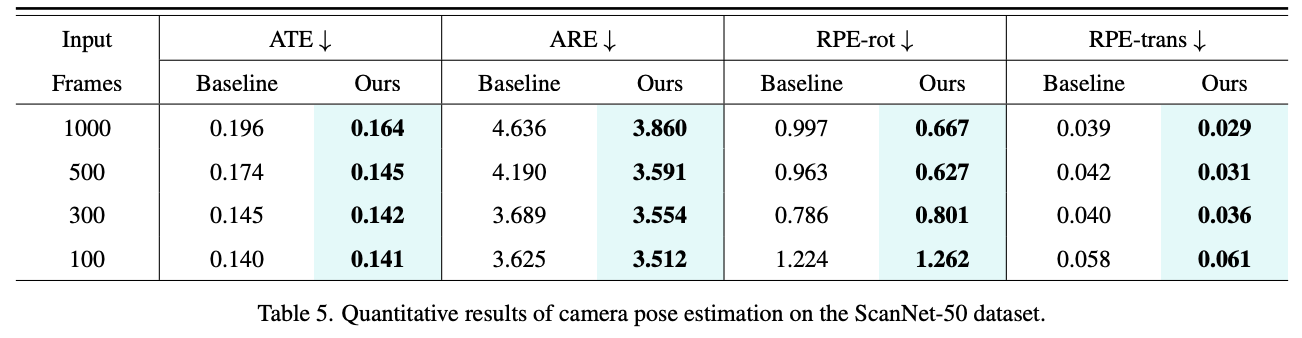
- 输入帧数:100、300、500、1000。
- 评价指标:
- ATE (Absolute Trajectory Error)
- ARE (Absolute Rotation Error)
- RPE-rot (Relative Pose Error, 旋转)
- RPE-trans (Relative Pose Error, 平移)
- 结果:在1000 帧输入的情况下,FastVGGT 将 ATE 从 0.196 (VGGT*) 降低至 0.164。同时,旋转与平移的相对误差也均显著降低。FastVGGT 不仅实现了更快的推理速度,还有效缓解了长序列推理过程中的误差累积问题。
六、结论
本文提出 FastVGGT,一种 training-free 的加速方法。基于对 VGGT 全局注意力冗余性的观察,FastVGGT 引入 token merging,在有效减少冗余计算的同时保持重建精度。在 ScanNet-50、7Scenes、NRGBD 等数据集上,FastVGGT 实现了 最高 4 倍的推理加速,并在 3D 重建与相机位姿估计任务中保持了VGGT的精确度,同时有效缓解了 VGGT 的误差累积问题,证明了FastVGGT 在大规模 3D 视觉系统中的实用性。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)