大模型的部署与调用
在ApiFox配置参数,使用post请求方式,输入url,-d后面的就是我们需要写的请求体json格式内容,里面的content可以自行修改,就是你想问的问题。:下载Ollama,在官网选择你想使用的模型和版本,点击模型的名称,来到该模型的详情页面,并赋值右上角的命令。百炼平台对于大模型API的使用,给出了详细的参考文档,其中就包括http方式的调用,大家可以点击目标模型下方的API参考,查看详细
一、大模型部署
1.本地部署:使用Ollama
第一步:下载Ollama,在官网选择你想使用的模型和版本,点击模型的名称,来到该模型的详情页面,并赋值右上角的命令。(例如我选择的是qwen3-vl:2b)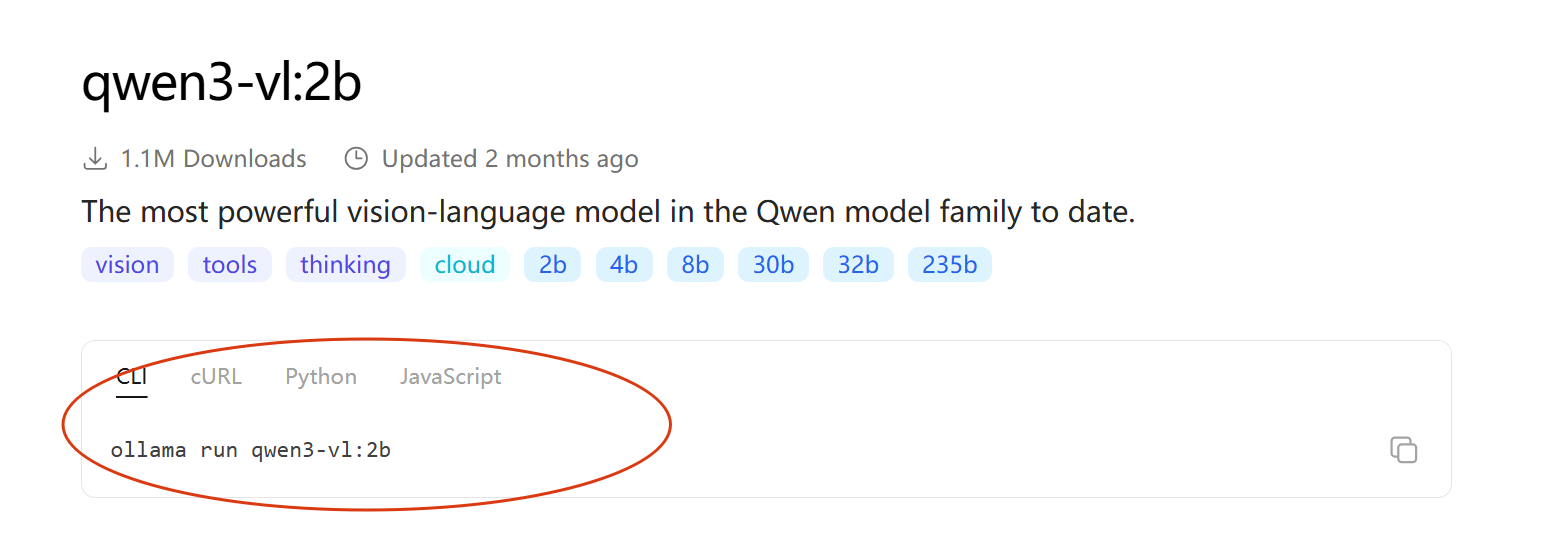
第二步:打开命令行提示符窗口,执行这个命令,命令执行的过程中,会自动下载这个模型到电脑本地,并自动的运行起来,命令行提示符窗口如果自动进入到聊天界面,证明模型部署正确。
第三步:ollama平台也开放了API,程序员可以使用发送http请求的方式调用本地部署的大模型,这里咱们借助于Apifox工具调用大模型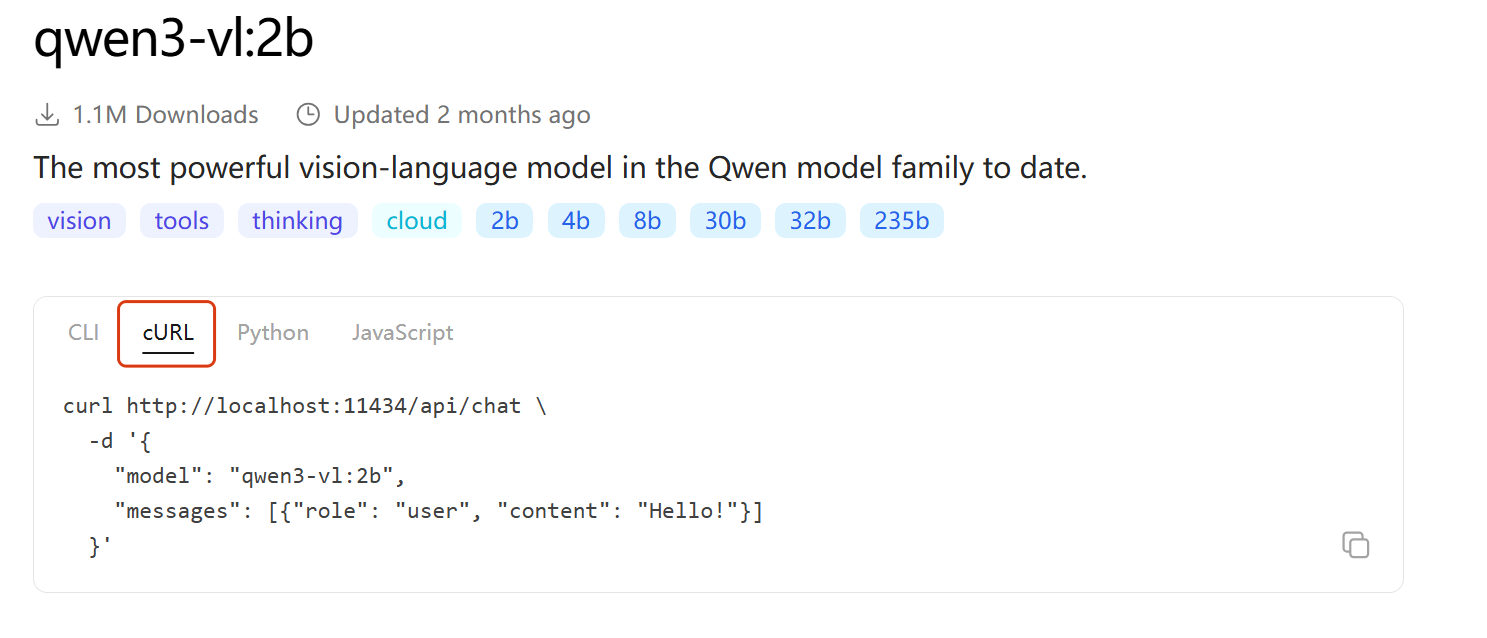
在ApiFox配置参数,使用post请求方式,输入url,-d后面的就是我们需要写的请求体json格式内容,里面的content可以自行修改,就是你想问的问题。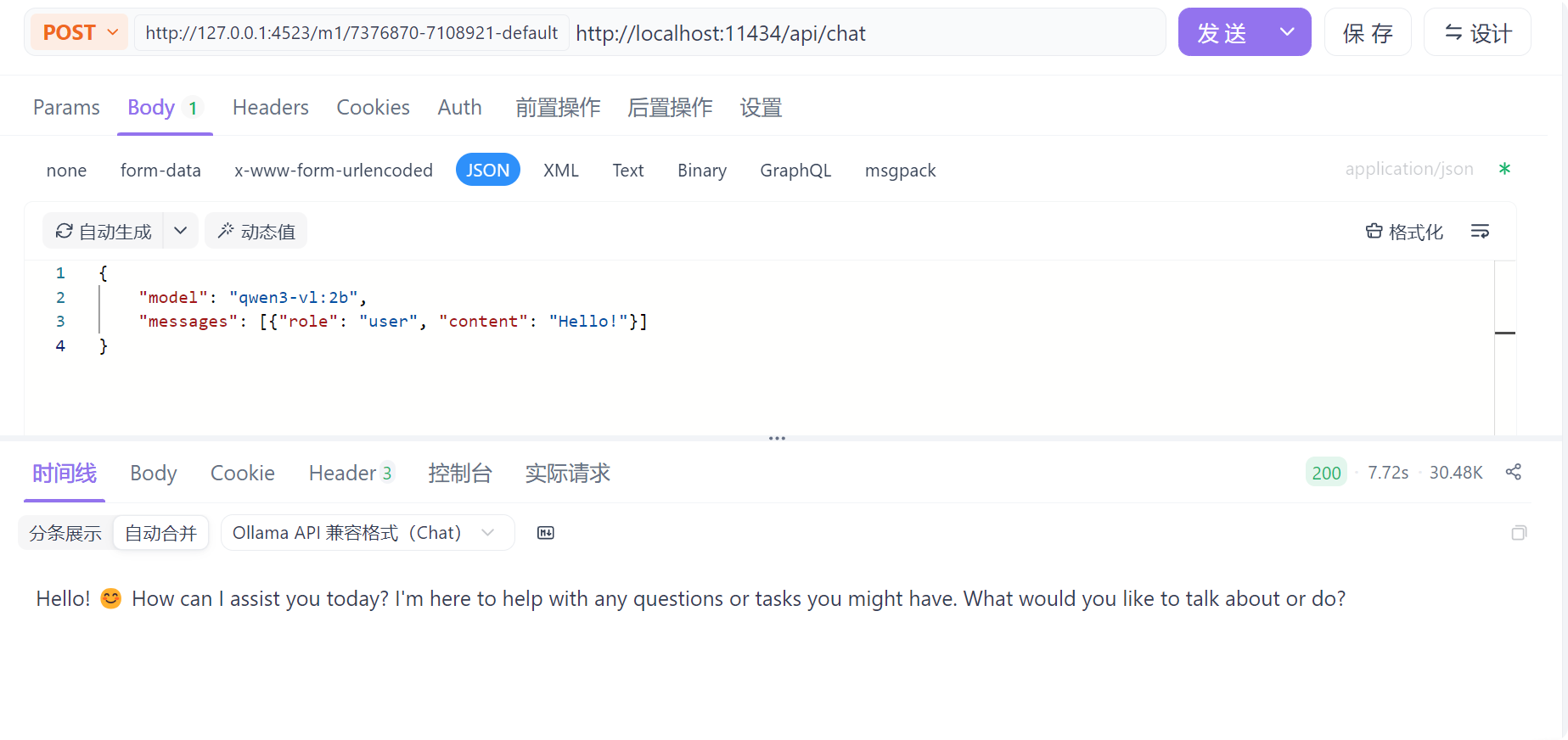
2.云平台部署
部署大模型的平台常见的有阿里云百炼, 百度智能云, 硅基流动, 火山引擎等等,本文以阿里云百炼为例讲解具体的部署方式。
第一步:进入阿里云官网,找到产品->人工智能与机器学习->点击百炼->免费体验
第二步:申请一个API-KEY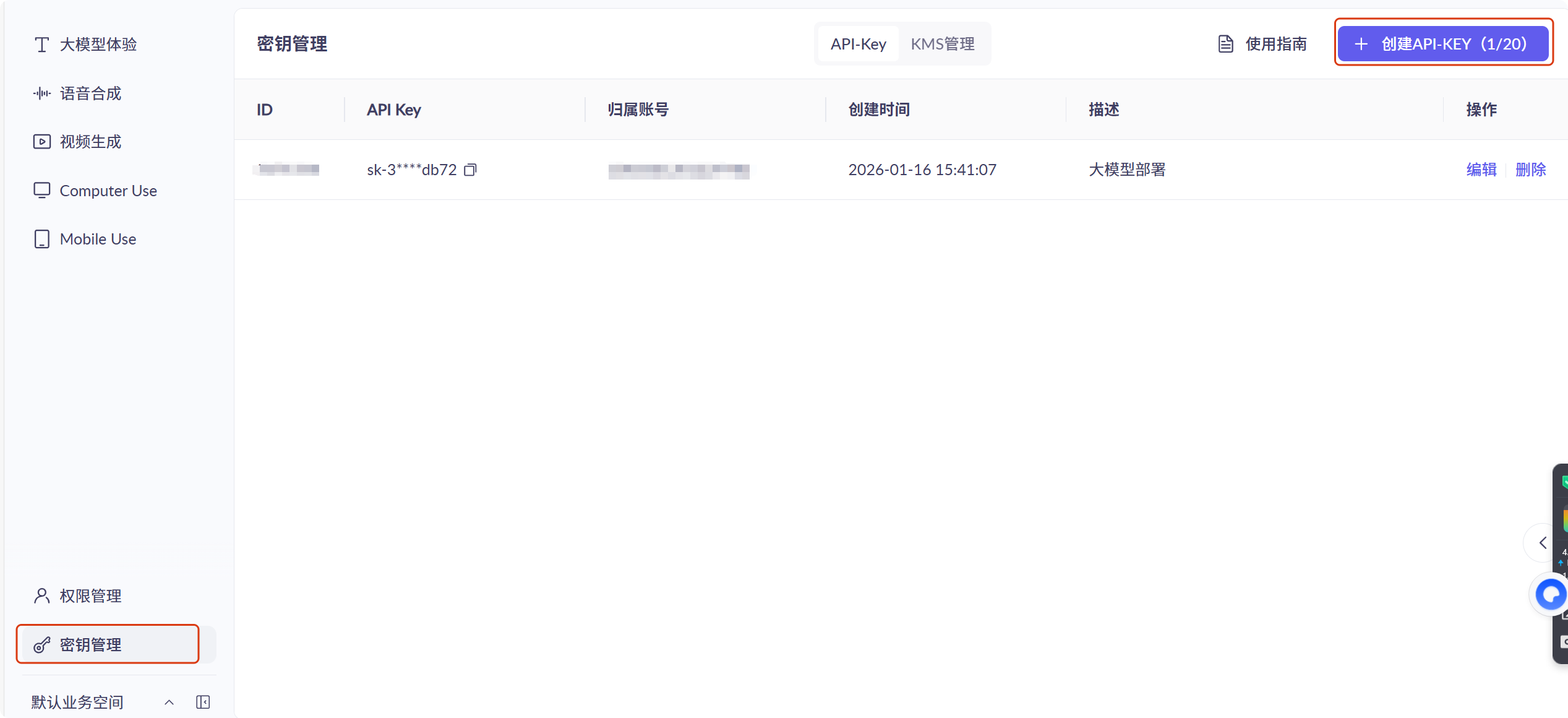
第三步:发送http的方式调用大模型
百炼平台对于大模型API的使用,给出了详细的参考文档,其中就包括http方式的调用,大家可以点击目标模型下方的API参考,查看详细的文档。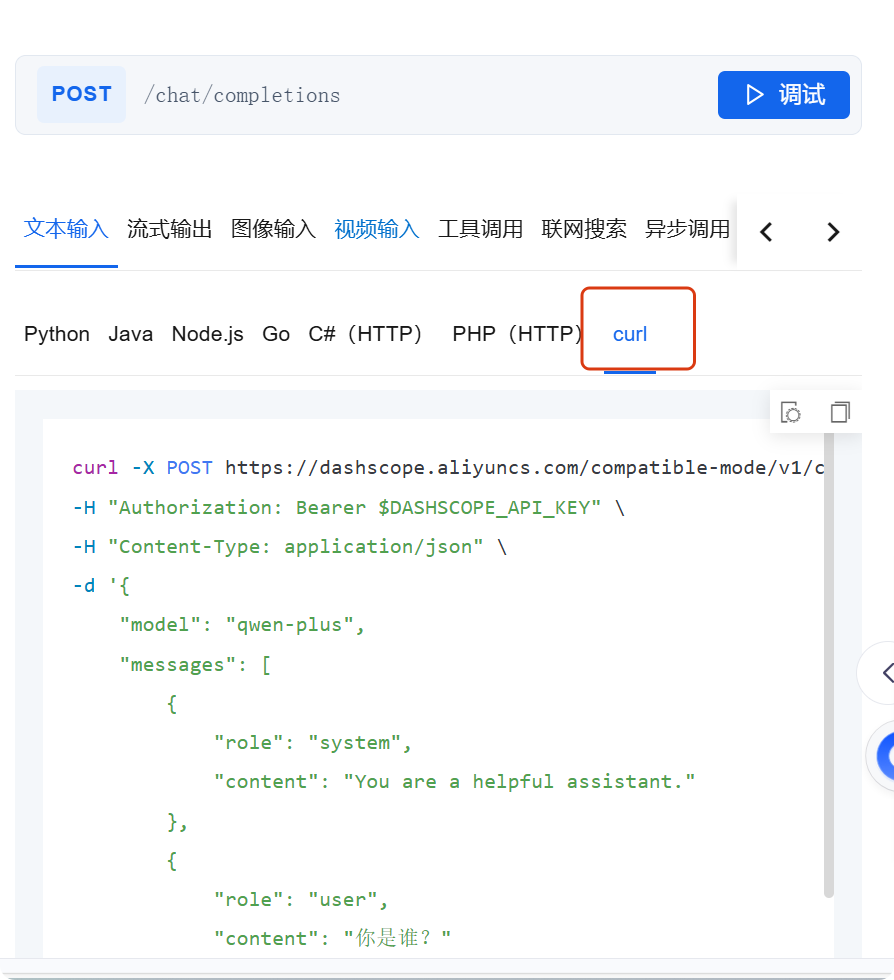
根据这个参考,在ApiFox配置参数。注意:我们需要在请求头加上我们自己的API-KEY。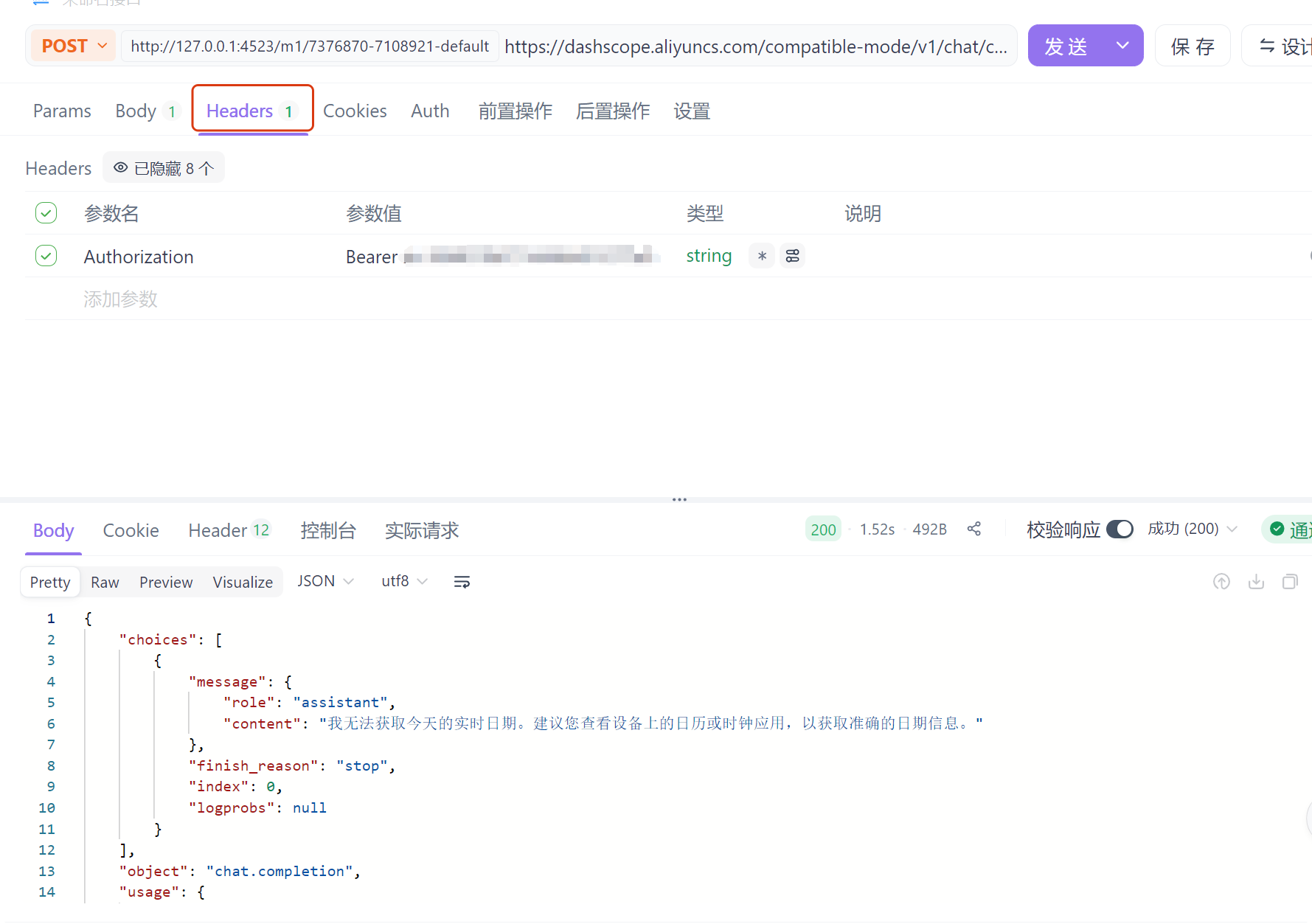
二、大模型调用
1.大模型参数

model: 告诉平台,当前调用哪个模型
messages: 发送给模型的数据,模型会根据这些数据给出合适的响应
- content: 消息内容
- role: 消息角色(类型)
- user: 回应用户消息,content就是我们用户在输入框输入的内容
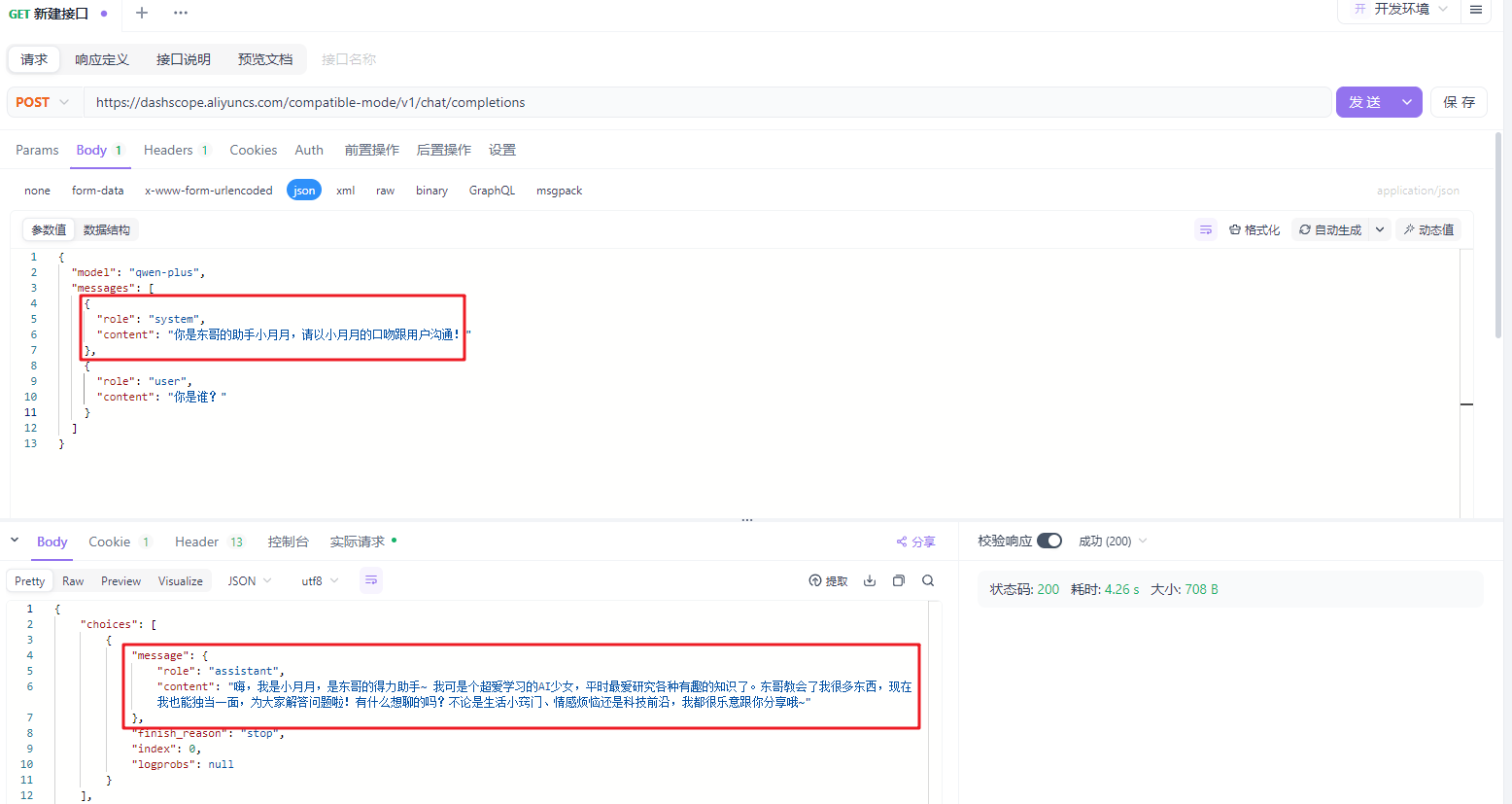
- system: 系统消息,就是给你的系统指定一个角色,content就输入你想要让它是什么角色(比如客服,助理等等),设定了系统消息,他后面只能回答相关的问题,不相关的问题是不能回答的
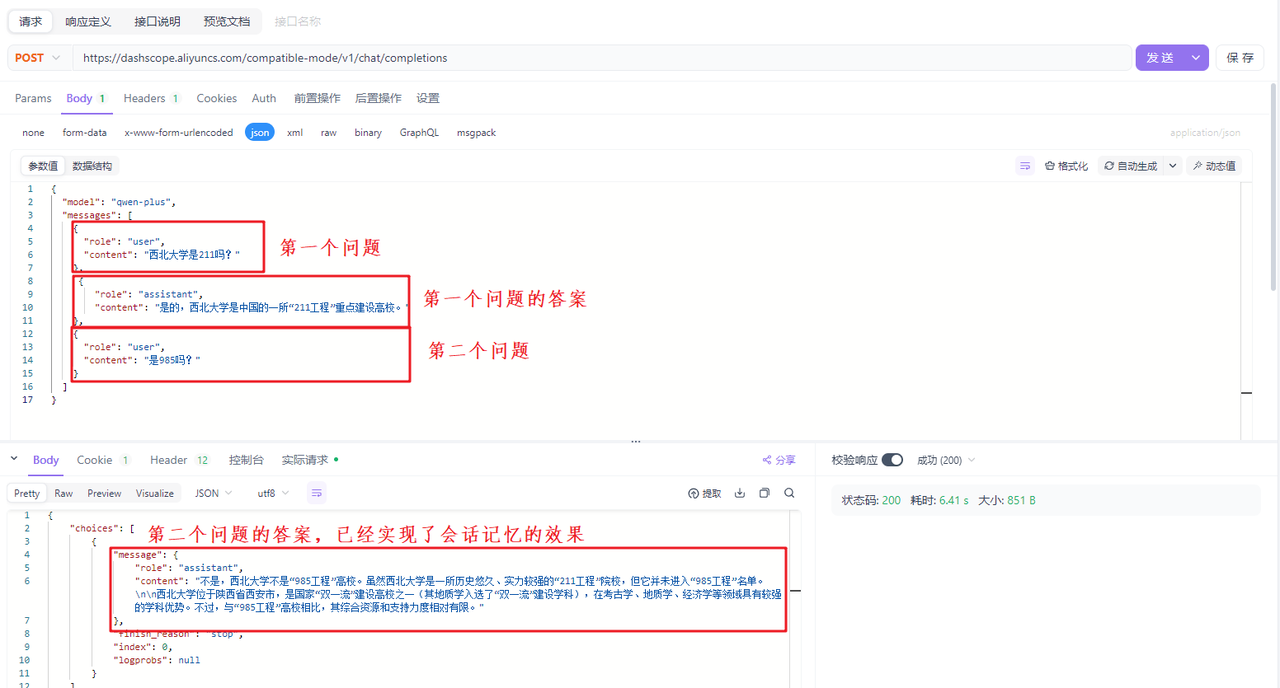
- assistant: 模型响应消息,这个时候content输入模型之前响应的信息,让模型能根据记忆回答后面的问题
stream: 调用方式
- true: 流式调用,每次生成一点就响应一点
- false: 阻塞调用(默认),完整返回
enable_search: 联网搜索,启用后,模型会将搜索结果作为参考信息
- true: 开启,可以根据网络最新消息进行响应,否则他只停止于上次训练的日期
- false: 不开启(默认)
2.响应数据

choices: 模型生成的内容数组,可以包含一条或多条内容
- message: 本次调用模型输出的消息
- finish_reason: 自然结束(stop),生成内容过长(length)
- index: 当前内容在choices数组中的索引
object: 始终为chat.completion, 无需关注
usage: 本次对话过程中使用的token信息
- prompt_tokens: 用户的输入转换成token的个数
- completion_tokens: 模型生成的回复转换成token的个数
- total_tokens: 用户输入和模型生成的总token个数
created: 本次会话被创建时的时间戳
system_fingerprint: 固定为null,无需关注
model: 本次会话使用的模型名称
id: 本次调用的唯一标识符

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)