YOLO深度学习(计算机视觉)一毕设笔记4(YOLO_OBB遥感影像旋转目标体检测实战)
本文介绍了基于DOTA遥感影像数据集进行旋转目标检测的实战项目。首先讲解了YOLO_OBB旋转框检测与普通目标检测的区别,强调其在处理倾斜目标时的优势。然后详细说明了DOTA数据集的下载、解压和组织方法,包括将图片和标签文件按train/test/val分类存放。重点介绍了使用DOTA_devkit工具箱进行图片分割的步骤,以及将原始标签格式转换为YOLO_OBB格式的Python脚本实现。最后指
一、介绍实战项目
前面学了这么多大家已经完全掌握YOLO11的基本训练预测的流程了,那么现在用一个稍微正的项目来实战一下:《基于DOTA遥感影像数据集进行旋转目标体检测》
1、旋转体目标检测
ultralytics官网对OBB的介绍文档:https://docs.ultralytics.com/tasks/obb/
我们之前学得YOLO11普通目标检测任务只需要水平、垂直方向的检测框框住大概的物体就行;但是YOLO_OBB是专门用旋转框检测带角度倾斜的目标的,遥感影像特征模糊而且很多都是斜的,就要用这个任务模型
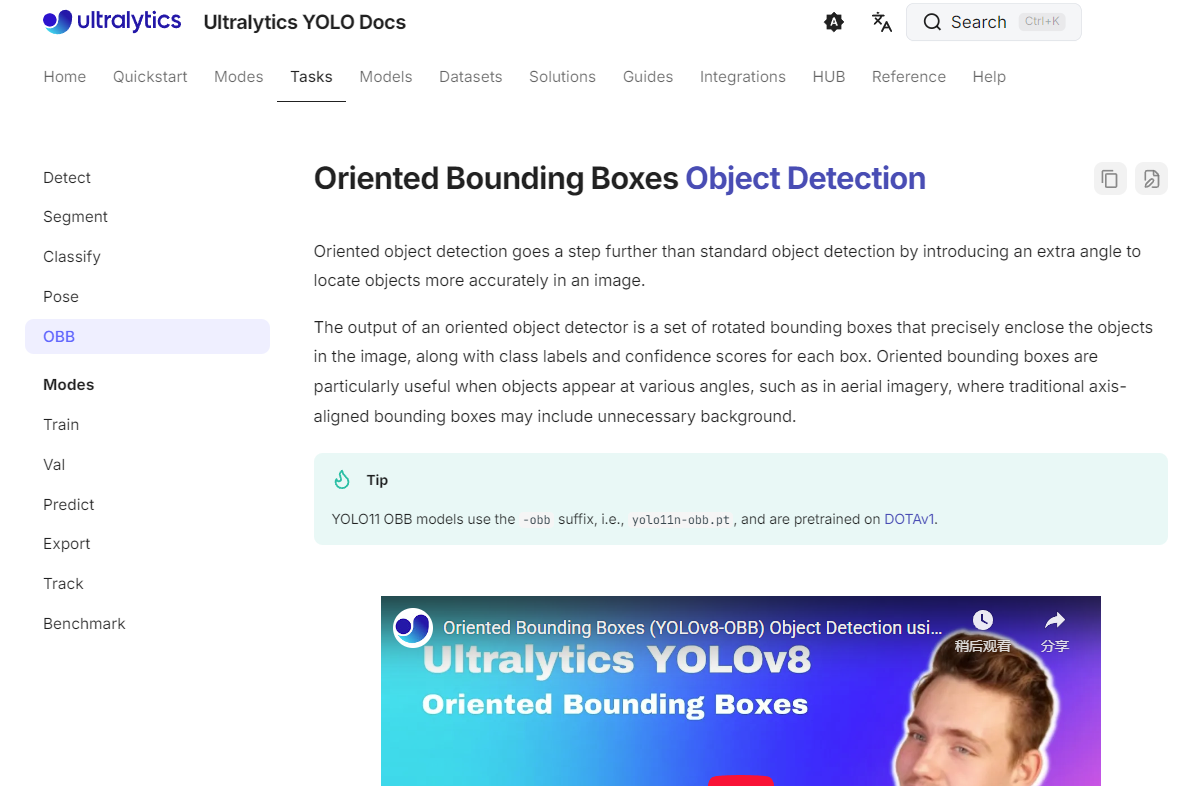
2、DOTA遥感影像数据集
数据集官网:https://captain-whu.github.io/DOTA/dataset.html
我们知道模型学习本身就要海量数据集,而且遥感数据的目标很小,特征比较模糊,更是需要海量数据,而DOTA数据集由武汉大学遥感国家重点实验室的夏桂松老师和华中科技大学电信学院的白翔老师联合整理并标注。正好这个数据集包含2806张高分辨率遥感图像和188282个标注物体,是目前最大、最全的遥感图像数据集之一,拿他练手一点毛病没有。
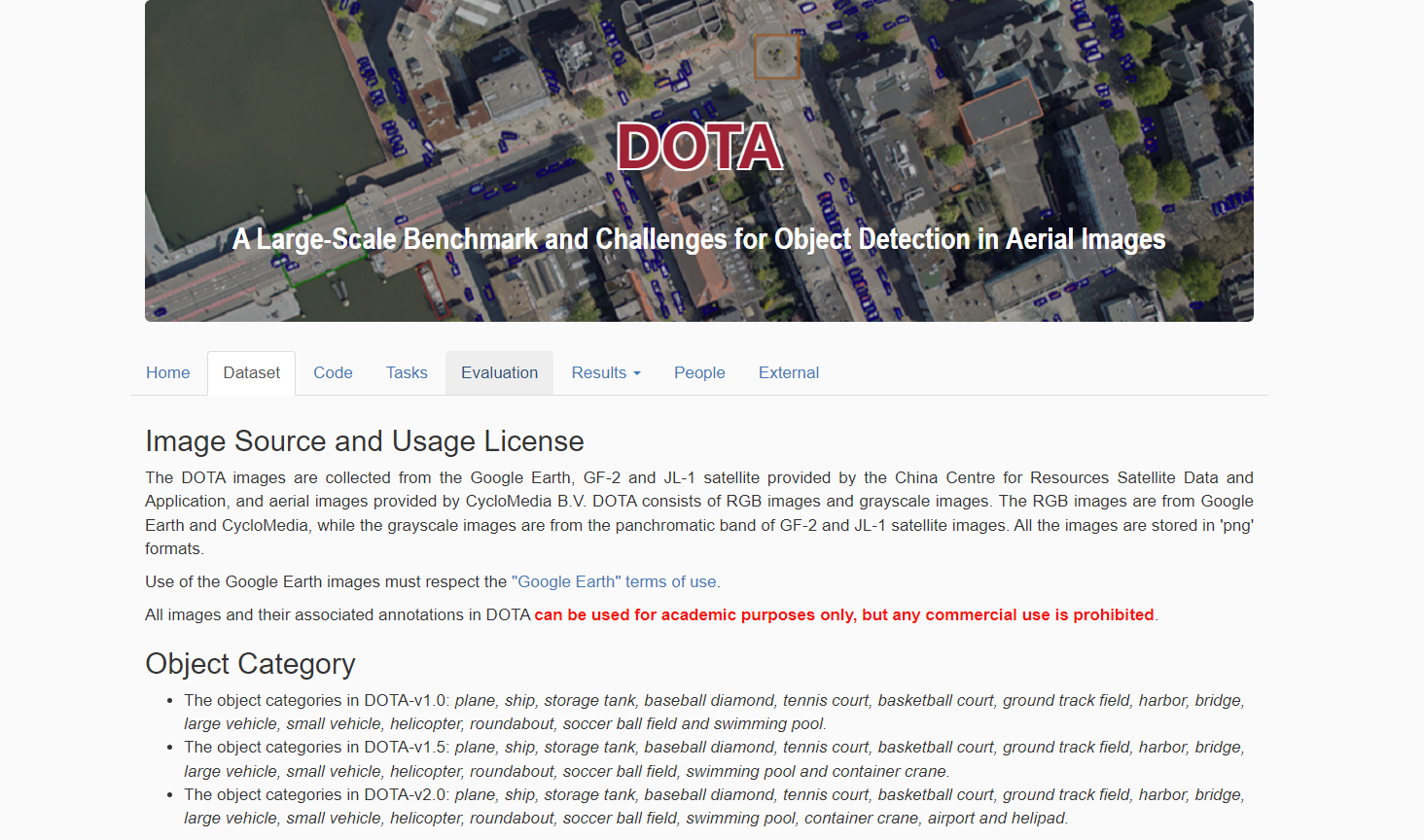
二、数据准备
1、官网下载数据
去到DOTA数据集官网拉到底,对于我们小白简单的练手,就下载那个1.0版本就行,第一行是百度云方式下载,第二行是谷歌网盘下载(要把train set \ test set \ validation set 3个都下载了)
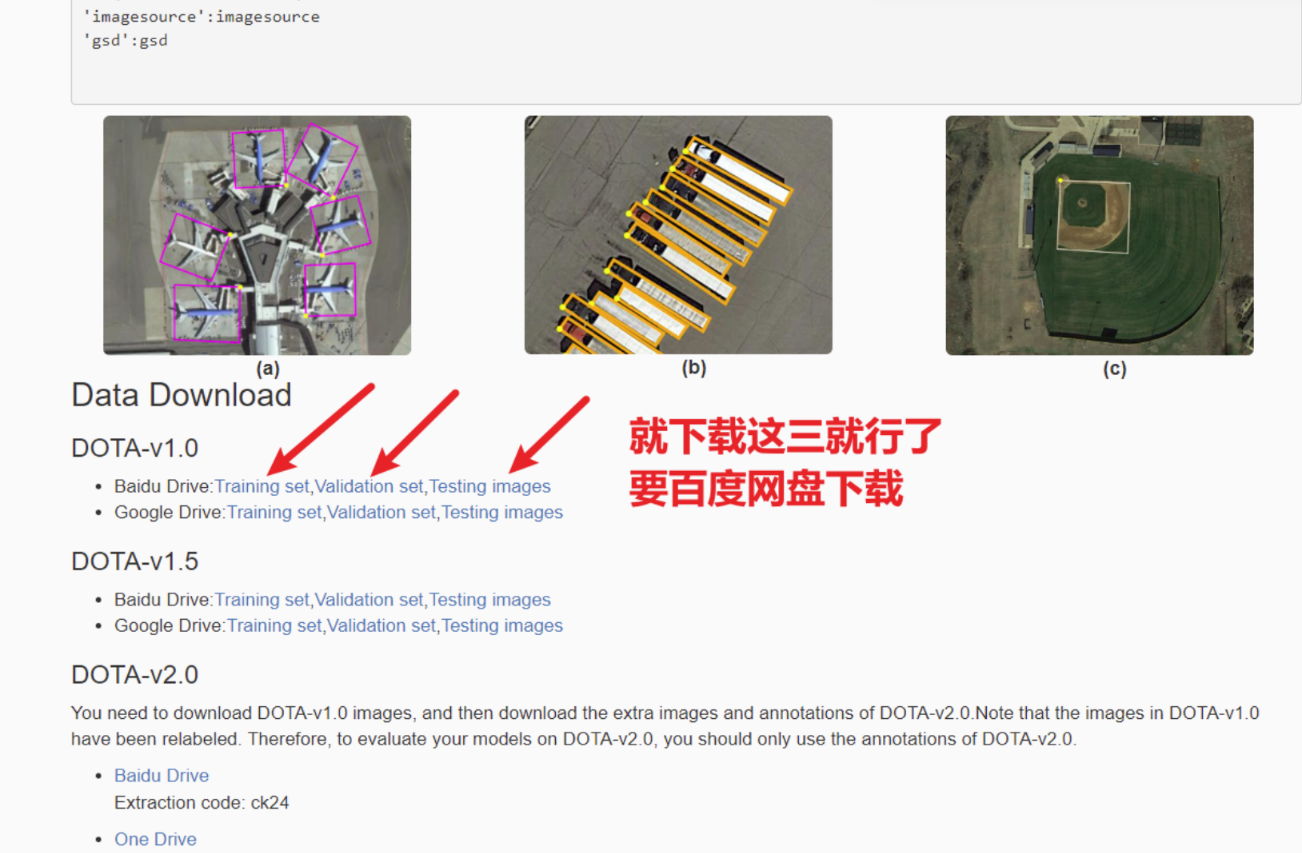
2、下载后提取文件
然后记住我的步骤,提取我们要用的数据整理
- 1、这里注意:“
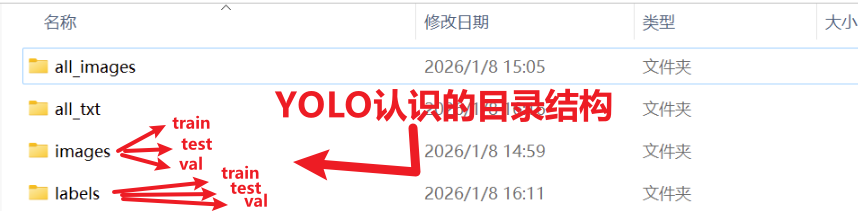
- 在YOLO训练时,我依旧采用我习惯的文件目录结构
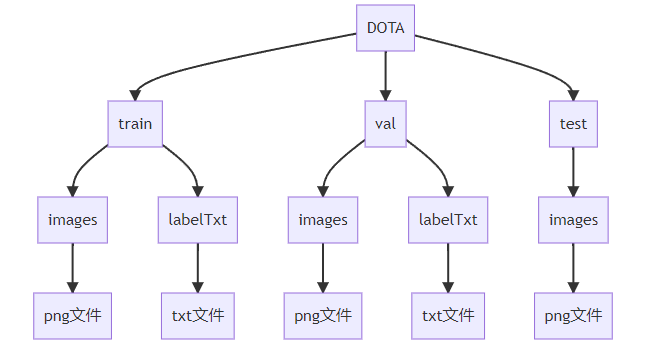
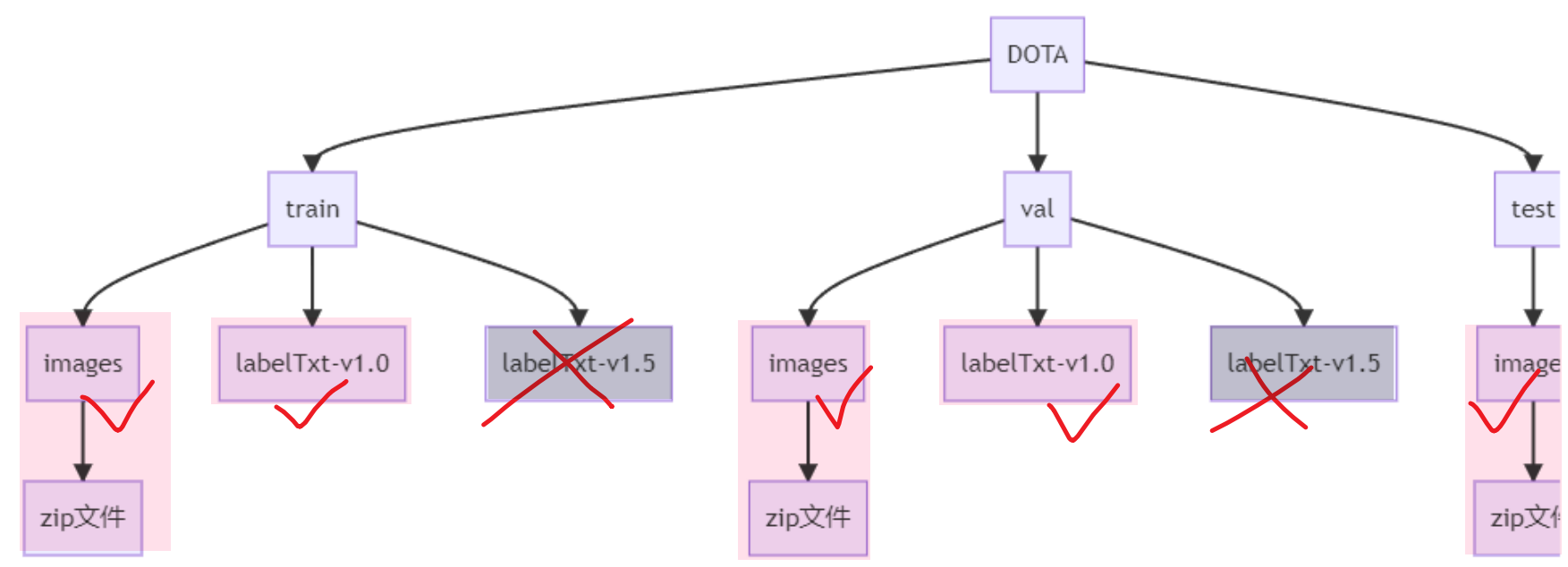
- 但是在训练之前我们还需要用脚本对图片进行一些操作,这需要我们先设置成下图这样的目录结构,注意文件夹名也要一样,因为等会讲到的这个工具的代码已经写好了,所以没办法,我一开始弄成了上面的结构结果还是改了
- 2、然后我们解压、打开下载的数据集文件
- 应该跟我这个结构一样,那么所有图片images的数据我们都要!
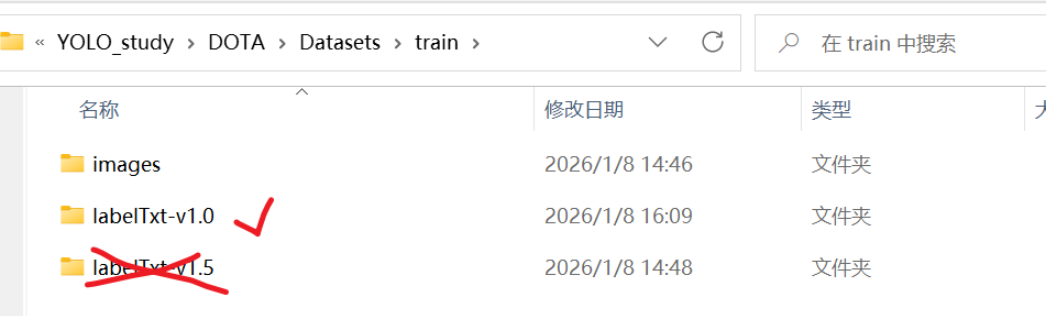
- 然后标签文件,我们只要labelTxt-v1.0,别的都不要!
- 3、images里的文件全部解压放一起
- 里面的part1、part2、part3.....是因为一个图片文件夹整个压缩还是很大,作者就把每个文件夹又分割几份来压缩,所以我们解压完放一起就行了。但是注意train、test、val还是要区分开放的
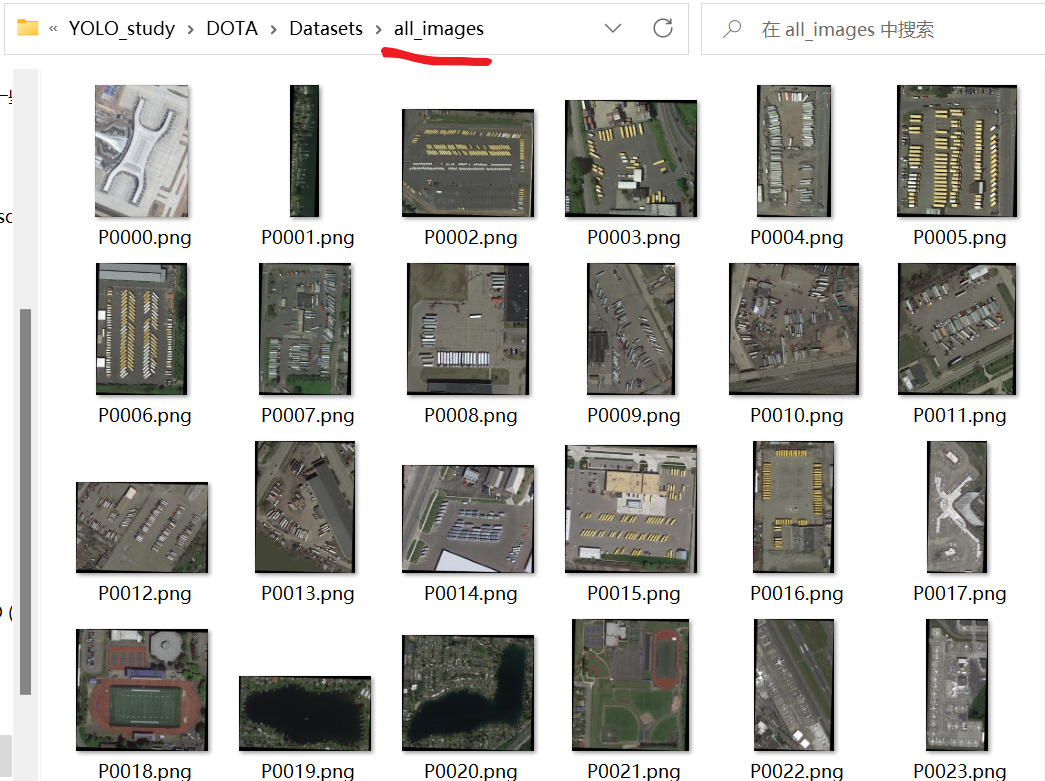
- 【all_images】:可以把train、test、val的图片全部放一起,一共2806张
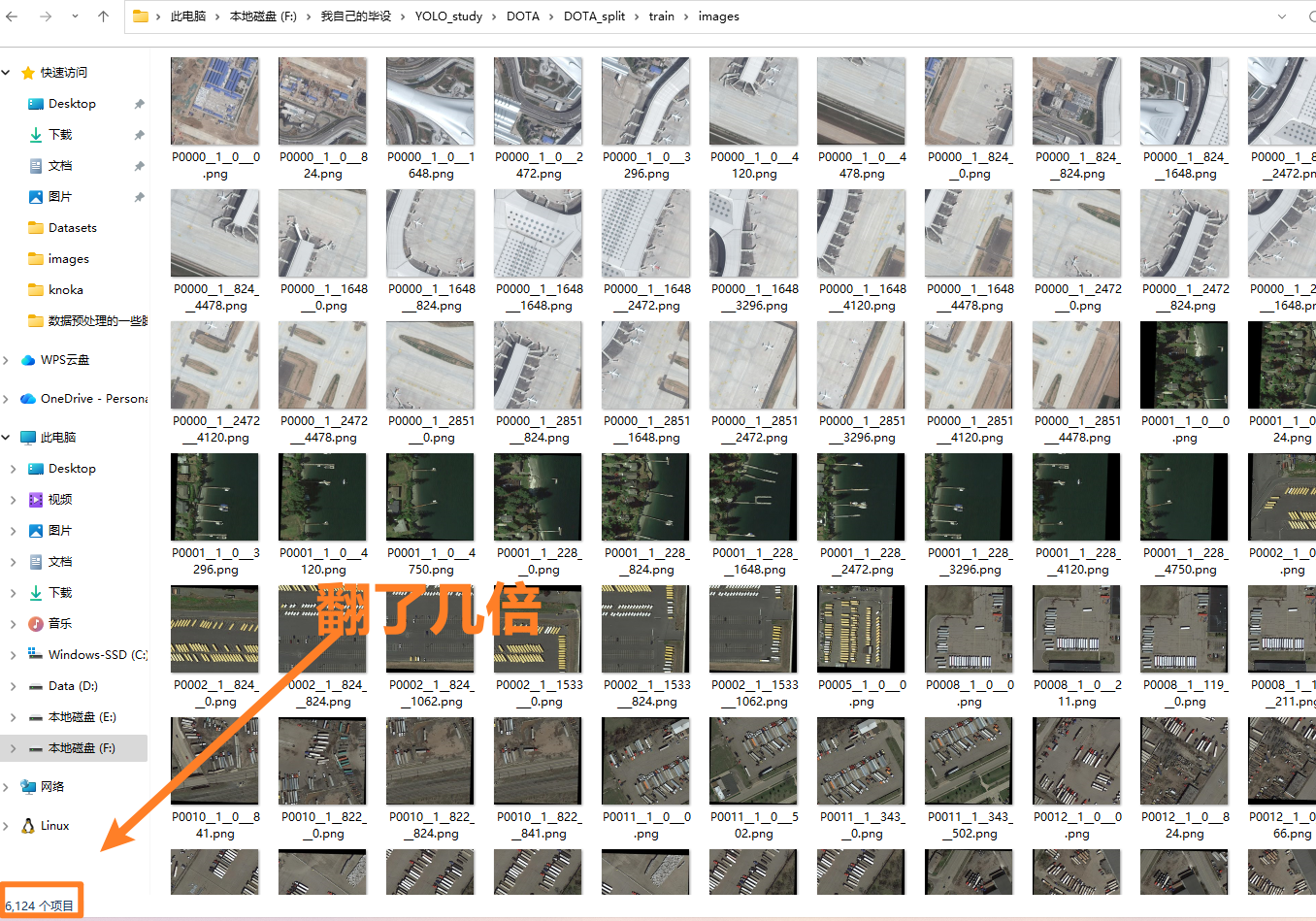
3、分割图片
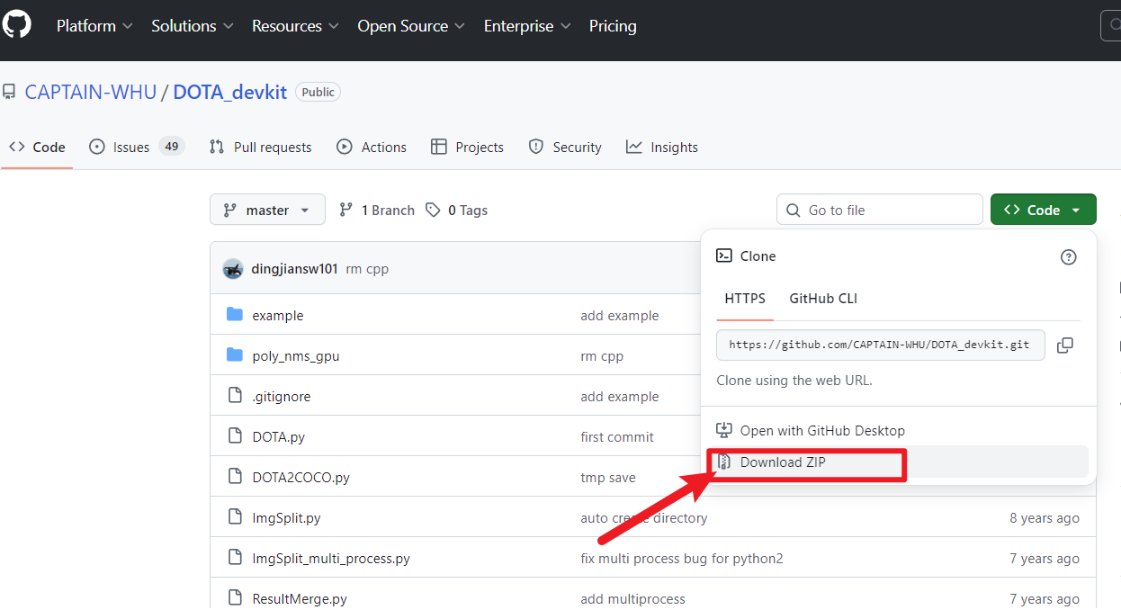
DOTA图片分割工具地址:https://github.com/CAPTAIN-WHU/DOTA_devkit
如果你点开一些DOTA数据集中的图像,你会发现,图片尺寸都是不一样大的,并且分辨率极高,这样的图像不适合直接用来训练,因此需要我们先做切割,然后再用于训练和检验。我们首先需要去上面链接下载DOTA数据集的工具箱下载下来
(为什么不做直接数据增强、归一化.....因为这些遥感影像本来拍物体就很小了,我们希望尽可能让图片清晰,宁愿分割成多张局部的图)
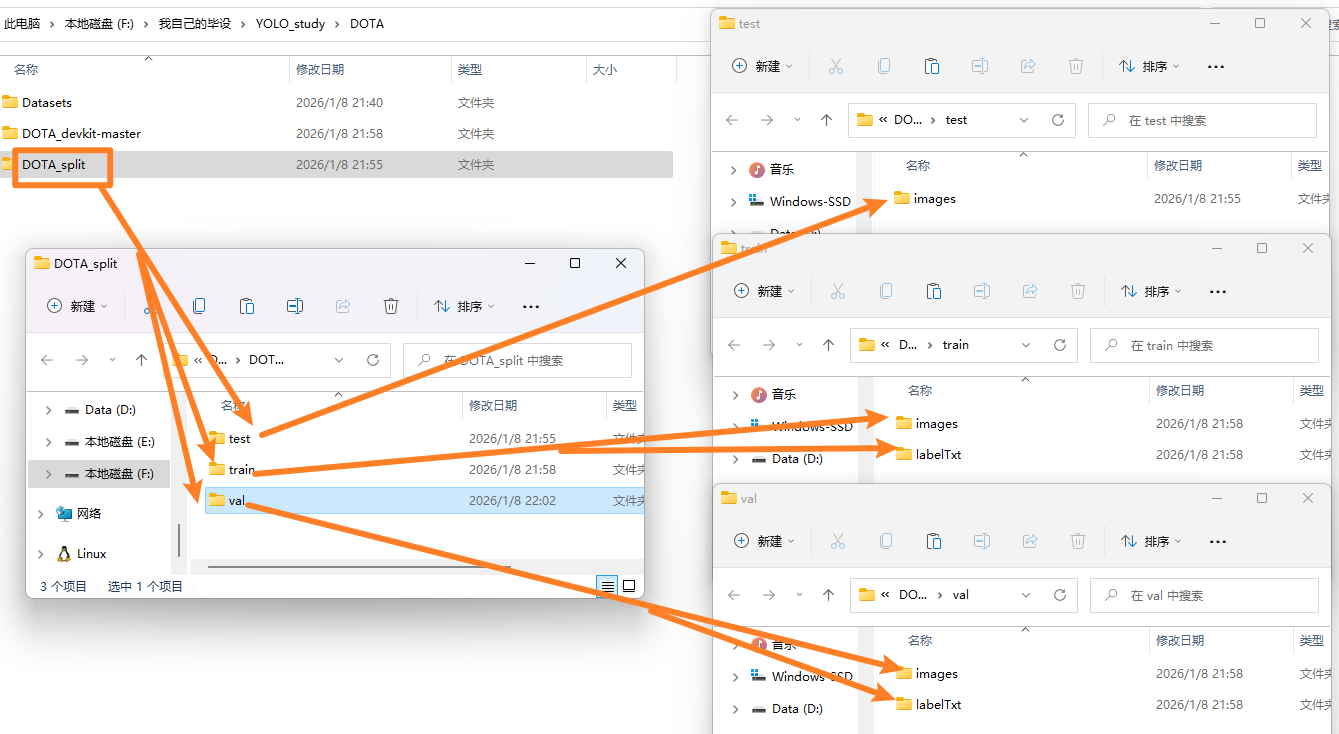
然后强调,用这个工具脚本之前,确保你的结构是这样,【all_images】和【all_txt】没有没关系,train、test、val这三个文件及以及里面的层级目录一定跟下图要一样
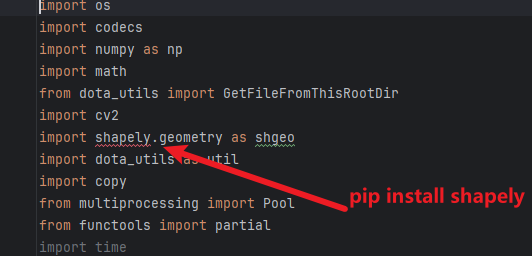
下载后,pip下载一下【shapely】这个工具包,用于分割重组图片的
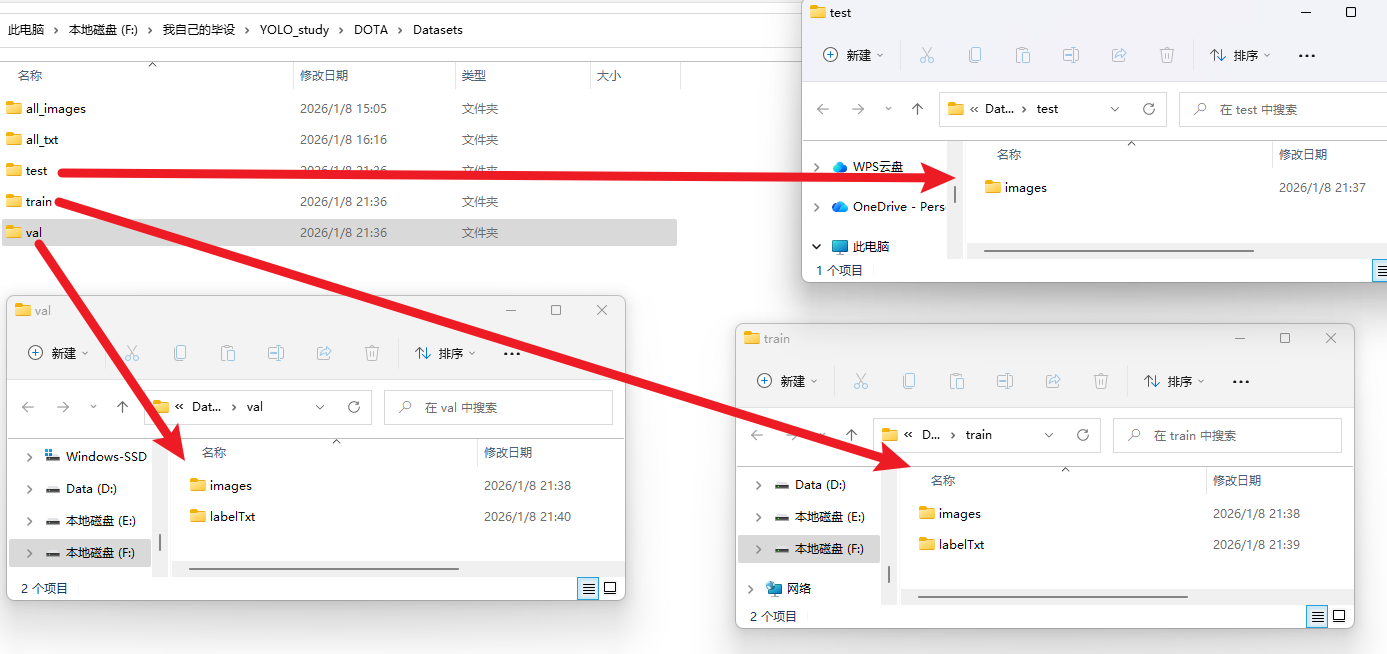
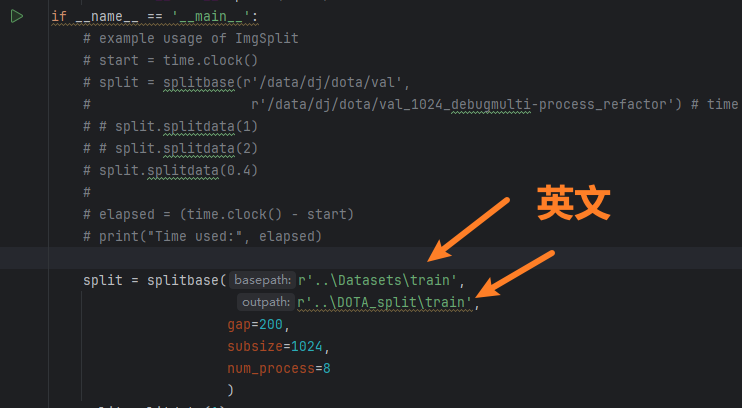
然后我们创建一个【DOTA_split】目录和【DOTA】一样,用于接收保存分割后的图片和标签文件
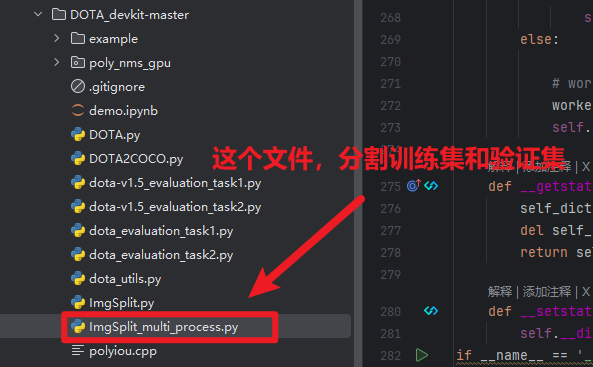
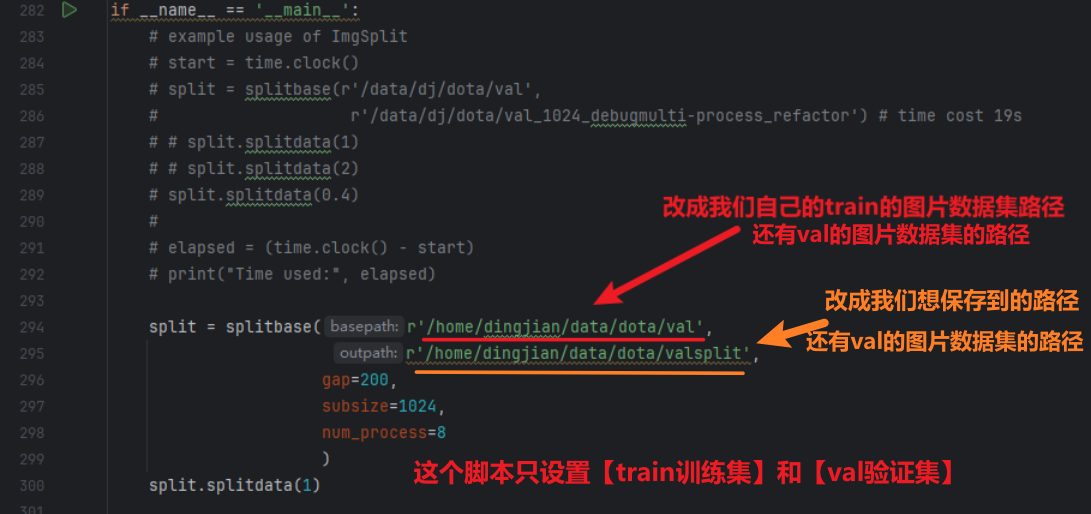
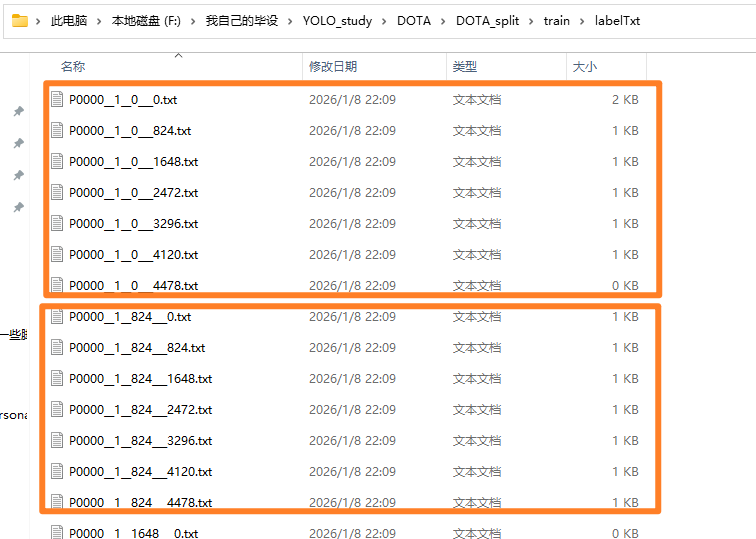
然后注意【ImgSplit_multi_process.py】这个脚本用来分割【train训练集】和【val验证集】,因为他两是有labelTxt标签文件的,所以这个脚本会自动根据【train】、【val】路径,读取到里面的【images】和【labelTxt】两个文件夹(不需要你指定)来对照着一起分割
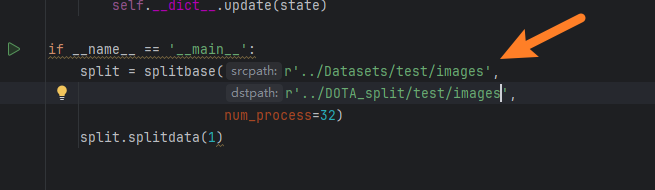
然后注意【SplitOnlyImage_multi_process.py】这个脚本专门用来分割【test训练集】,因为训练集下面没有【labelTxt标签文件】,只用分割图片。(但是这个脚本我们要专门指定【test】下的【images】文件夹,不然会找不到图片,而且输出保存的路径也要提前手动创建)
;
还有几个提示:
- 1、路径不要有中文,可以用相对路径,test的输入输出记得指定到images
- 2、这个不是报错,只是一些没用的警告,不影响
4、转换txt里的格式
现在我们还要改txt的文件格式:
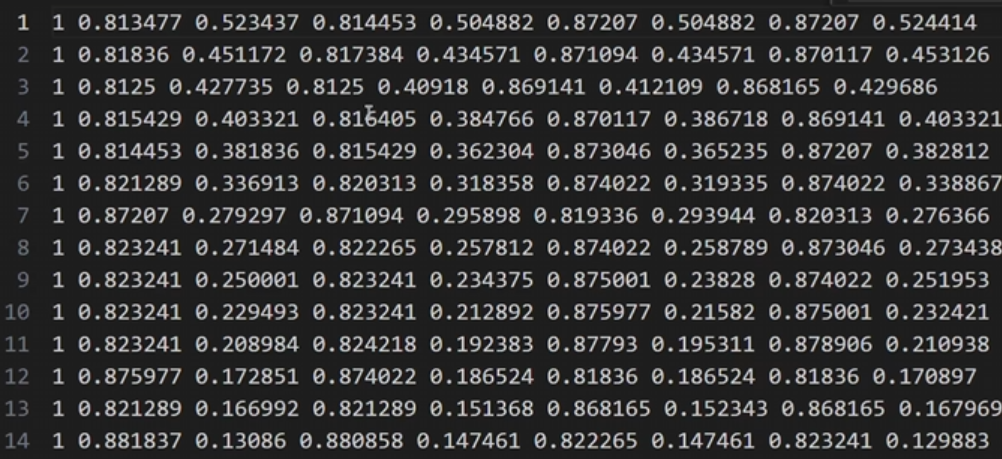
- 1、YOLO11的OBB要求的标签数据格式是:
- 【object_id x1 y1 x2 y2 x3 y3 x4 y4】:物体类别的id、和4个点的xy坐标
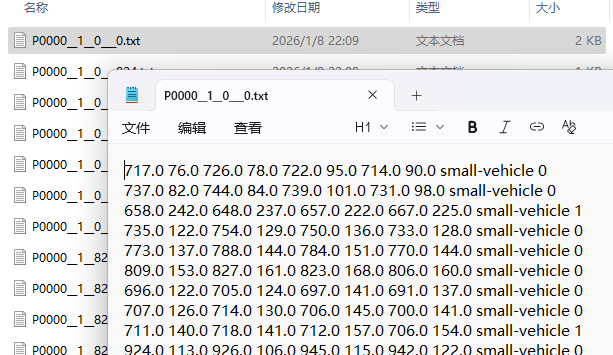
- 2、而DOTA的原始txt标签数据格式是:
- 【x1 y1 x2 y2 x3 y3 x4 y4 object_name hard_level】:4个点的xy坐标、物体类别的id、被检测到的困难程度
- 很明显像object_name就不符合yolo格式,yolo认物体类别只认0、1、2这样的数字,不认英文单词,所以要改
这里我写好2个脚本:
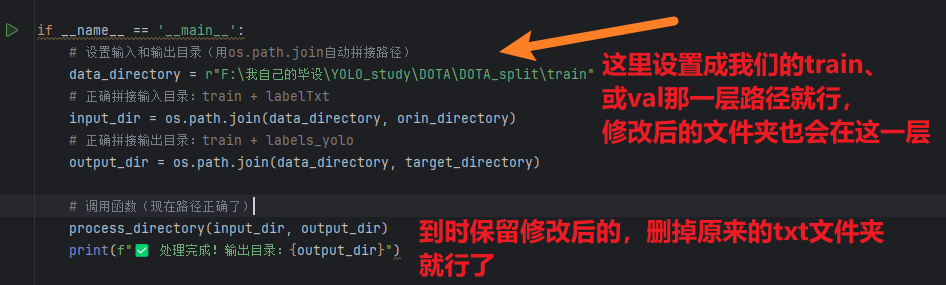
这个是稳妥版,修改完yolo格式的标签后,自动存放到同级目录下
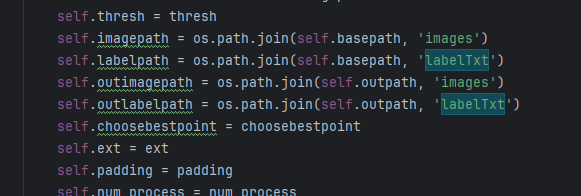
你需要手动创建保留这个新文件夹而删除原来的txt文件夹
import os # 定义 object_name 和 object_id 的映射关系 object_mapping = { "plane": 0, "ship": 1, "storage-tank": 2, "baseball-diamond": 3, "tennis-court": 4, "basketball-court": 5, "ground-track-field": 6, "harbor": 7, "bridge": 8, "large-vehicle": 9, "small-vehicle": 10, "helicopter": 11, "roundabout": 12, "soccer-ball-field": 13, "swimming-pool": 14, } orin_directory = "labelTxt" # 注意:你的原标签文件夹名是labelTxt,不是labels! target_directory = "labels_yolo" # 定义函数:处理单个文件 def process_file(input_path, output_path): with open(input_path, 'r', encoding='utf-8') as infile, open(output_path, 'w', encoding='utf-8') as outfile: for line in infile: data = line.strip().split() if len(data) != 10: continue # 如果数据格式不符合要求,跳过该行 # 提取 x1, y1, ..., x4, y4, object_name coords = [str(float(i)/1024.0) for i in data[:8]] object_name = data[8] # 获取 object_id object_id = object_mapping.get(object_name) if object_id is None: continue # 如果 object_name 不在映射表中,跳过该行 # 生成新格式:object_id x1 y1 x2 y2 x3 y3 x4 y4 new_line = f"{object_id} " + " ".join(coords) + "\n" outfile.write(new_line) # 定义函数:遍历目录,处理所有 txt 文件 def process_directory(input_dir, output_dir): for root, _, files in os.walk(input_dir): for file in files: if file.endswith('.txt'): input_file_path = os.path.join(root, file) relative_path = os.path.relpath(input_file_path, input_dir) output_file_path = os.path.join(output_dir, relative_path) os.makedirs(os.path.dirname(output_file_path), exist_ok=True) process_file(input_file_path, output_file_path) if __name__ == '__main__': # 设置输入和输出目录(用os.path.join自动拼接路径) data_directory = r"F:\我自己的毕设\YOLO_study\DOTA\DOTA_split\train" # 正确拼接输入目录:train + labelTxt input_dir = os.path.join(data_directory, orin_directory) # 正确拼接输出目录:train + labels_yolo output_dir = os.path.join(data_directory, target_directory) # 调用函数(现在路径正确了) process_directory(input_dir, output_dir) print(f"✅ 处理完成!输出目录:{output_dir}")这个是方便版,不用创建新文件夹,直接在原文件内容更改
不过建议还是拿一两个文件副本试一下,因为生怕出点什么问题直接把你原txt的内容给毁了
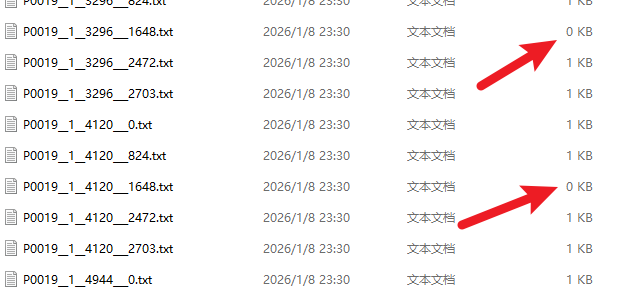
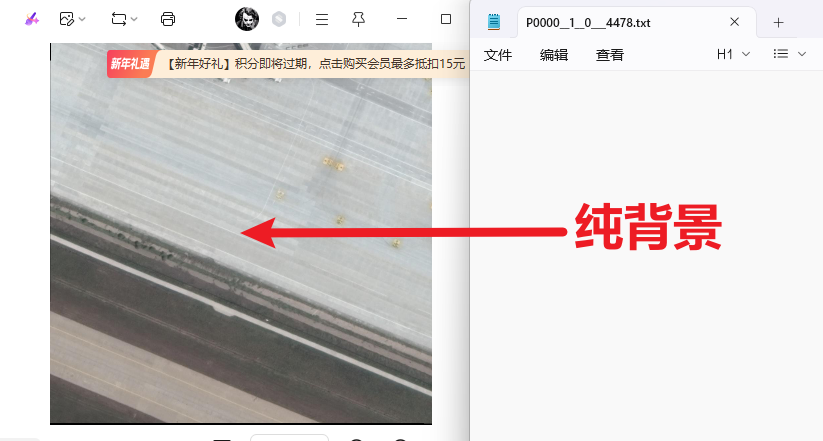
import os # -------------------------- 核心配置(确认和你的情况匹配) -------------------------- # 1. 类别映射(连字符格式,和你的DOTA标签一致) object_mapping = { "plane": 0, "ship": 1, "storage-tank": 2, "baseball-diamond": 3, "tennis-court": 4, "basketball-court": 5, "ground-track-field": 6, "harbor": 7, "bridge": 8, "large-vehicle": 9, "small-vehicle": 10, "helicopter": 11, "roundabout": 12, "soccer-ball-field": 13, "swimming-pool": 14, } # 2. 你的原标签文件夹路径(直接改这个!) label_dir = r"F:\我自己的毕设\YOLO_study\DOTA\DOTA_split\train\labelTxt" # 3. 分块尺寸(和你分割图片的尺寸一致,默认1024) split_size = 1024 # ----------------------------------------------------------------------------- def process_single_file(file_path): """处理单个txt文件,直接修改原文件内容""" # 读取原文件内容 with open(file_path, 'r', encoding='utf-8') as f: lines = f.readlines() # 处理每一行,筛选有效内容并转换格式 new_lines = [] for line in lines: line = line.strip() # 跳过空行、元数据行(imagesource/gsd) if not line or line.startswith(("imagesource", "gsd")): continue data = line.split() # 过滤格式错误的行(DOTA标签必须是10个部分) if len(data) != 10: print(f"⚠️ {os.path.basename(file_path)}:跳过格式错误行 → {line}") continue # 1. 坐标归一化(像素值→0~1的相对值) coords = [str(float(coord) / split_size) for coord in data[:8]] # 2. 类别名转ID object_name = data[8] object_id = object_mapping.get(object_name) if object_id is None: print(f"⚠️ {os.path.basename(file_path)}:跳过未知类别 → {object_name}") continue # 3. 构造YOLO OBB格式行 new_line = f"{object_id} " + " ".join(coords) + "\n" new_lines.append(new_line) # 直接写回原文件(覆盖原有内容) with open(file_path, 'w', encoding='utf-8') as f: f.writelines(new_lines) # 打印处理结果(区分有内容/空文件) if len(new_lines) > 0: print(f"✅ {os.path.basename(file_path)}:转换完成,有效标签数={len(new_lines)}") else: print(f"ℹ️ {os.path.basename(file_path)}:无有效标签,文件为空(0KB)") def process_all_files(label_dir): """遍历目录下所有txt文件,批量处理""" # 先检查目录是否存在 if not os.path.exists(label_dir): print(f"❌ 错误:标签目录不存在 → {label_dir}") return # 遍历所有txt文件 for root, _, files in os.walk(label_dir): for file in files: if file.endswith('.txt'): file_path = os.path.join(root, file) process_single_file(file_path) if __name__ == '__main__': # 安全提醒(必须先备份!) input("⚠️ 请确认已备份原labelTxt文件夹,按回车键继续(取消按Ctrl+C)...") # 执行批量处理 print("\n开始转换标签格式(直接修改原文件)...") process_all_files(label_dir) print("\n🎉 所有文件处理完成!")另外,改好后的txt文件有的是0KB没内容的不要慌,不是脚本出问题帮你删了,而是原数据本来就没内容,因为我们前面分割了图片,有的图片可能只是单纯的一个背景,没有目标检测体,那就没有东西需要记录啊
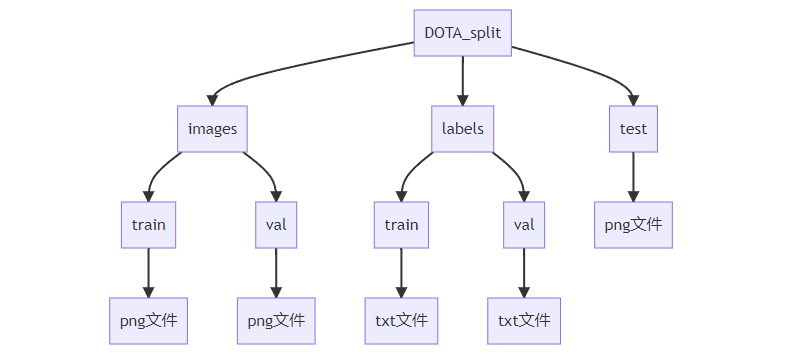
5、最后,文件目录结构换成YOLO标准
现在一切准备完毕,可以把文件结构整理成YOLO标准了
至于我加的all_images、all_txt你想加也可以加,我的想法是这两个文件夹后续我再添加别的图和标签到这,然后经过处理之后我再分别放到images和labels,可有可无
6、改写yaml文件
写过很多次了,这里就不多说了
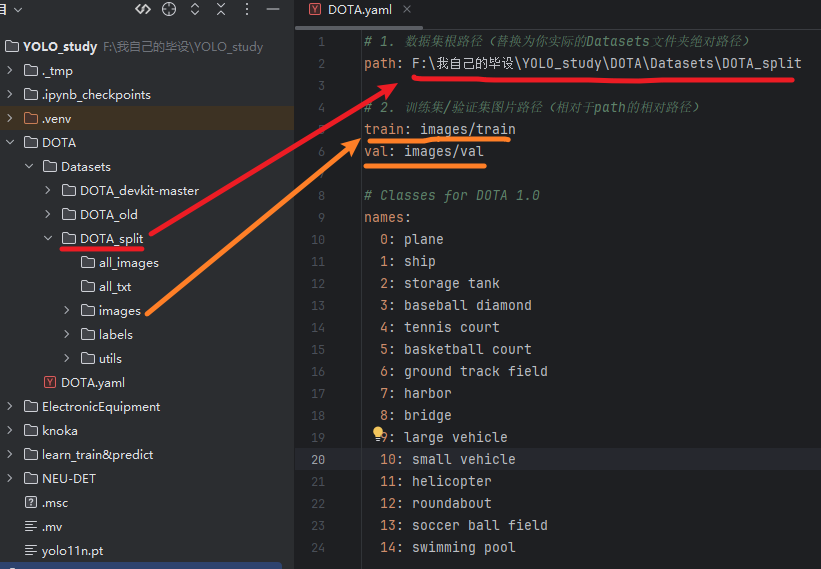
另外我把前面的【原DOTA数据】、【新DOTA数据】、【DOTA分割工具】都装到DOTA文件夹下的一个Datasets文件夹下,因为都归属于数据集,这样看着顺眼,然后我们的yaml文件、训练代码都可以直接放DOTA这一层总目录了
# 1. 数据集根路径(替换为你实际的Datasets文件夹绝对路径) path: F:\我自己的毕设\YOLO_study\DOTA\Datasets\DOTA_split # 2. 训练集/验证集图片路径(相对于path的相对路径) train: images/train val: images/val # Classes for DOTA 1.0 names: 0: plane 1: ship 2: storage tank 3: baseball diamond 4: tennis court 5: basketball court 6: ground track field 7: harbor 8: bridge 9: large vehicle 10: small vehicle 11: helicopter 12: roundabout 13: soccer ball field 14: swimming pool

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)