从玩具到工具:LangChain 入门 (一)
本文承接《初认Langchain,详细介绍Langchain是什么》,聚焦于一个可运行的入门 Demo。我们将搭建一个标准的项目结构,配置第三方大模型(如 Qwen),并展示核心组件(Model, Chain, Agent)的代码实现。这不仅是“Hello World”,更是迈向生产级应用的第一步。

本文所用可运行langchain已经按照生产级框架配置,位于csdn的资源下载:从玩具到工具:LangChain 入门教程代码demo
前言
在上一篇对 LangChain 的全景式介绍中,我们已经清晰地看到,它并非一个简单的 Prompt 工具箱,而是一套完整的工程化框架。它的核心价值在于将构建 LLM 应用这一充满不确定性的过程,转化为一系列可管理、可组合、可复用的模块。理论是骨架,代码才是血肉。空谈组件化、Chains 和 Agents 的概念,远不如亲手写几行代码来得真切。
因此,本文的目标非常明确:带大家完成一个从零到一的 LangChain 入门 Demo。这个 Demo 的意义不在于功能多么复杂,而在于它必须具备一个“准生产级”项目的雏形。这意味着我们需要考虑依赖管理、项目结构、配置分离、模型抽象等基本工程实践。
很多初学者在接触 LangChain 时,会直接在一个 Jupyter Notebook 里写几行代码调用 OpenAI,这固然能快速看到效果,但也容易形成一种错觉,认为 LLM 应用就是如此简单。一旦进入真实场景,面对私有模型、复杂数据源、状态管理和错误处理时,这种“脚本式”开发就会立刻捉襟见肘。我们的 Demo 将刻意避开这种陷阱,从一开始就引入良好的工程习惯,为后续的扩展打下坚实基础。接下来,让我们一起动手,将理论蓝图变为可运行的代码。
1. 项目初始化:奠定工程化基石
一个健壮的应用始于一个清晰的项目结构。混乱的代码组织是技术债务的温床,对于需要频繁迭代和调试的 LLM 应用尤其如此。我们需要一个既能满足当前 Demo 需求,又能平滑演进到更复杂应用的目录布局。
1.1 标准项目结构设计
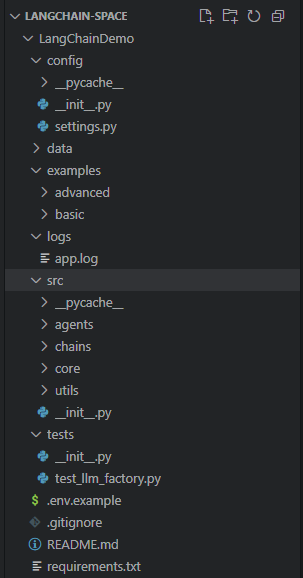
一个典型的 Python 项目结构应包含以下核心部分:
requirements.txt: 明确列出所有依赖项及其版本,确保环境可复现。src/: 源代码目录,所有应用逻辑都应放在此处。config/: 配置文件目录,用于存放 API 密钥、模型参数等敏感或可变信息。.env: 本地环境变量文件,用于存储密钥,不应提交到版本控制。
这种结构将代码、配置和依赖清晰分离,符合十二要素应用(Twelve-Factor App)的基本原则。
1.2 框架核心文件说明
config/settings.py
1. 这个文件里存放的是什么
主要有三类东西:
a) 项目根目录常量
PROJECT_ROOT = Path(__file__).parent.parent代表 LangChainDemo 这个目录,用来拼接后面的各种路径。
b) 应用配置类 Settings(继承自 pydantic_settings.BaseSettings)
这个类定义了整个项目的配置项,每个字段都可以从环境变量 / .env 文件里读取,也有默认值,包括:
- 环境:
app_env(环境:development / production 等)
- 本地 Ollama:
ollama_base_url(默认http://localhost:11434)
- 阿里百炼 / DashScope:
alibailian_api_key(ALIBAILIAN_API_KEY)dashscope_api_key(DASHSCOPE_API_KEY,和上面逻辑等价的别名)
- 向量库:
chroma_persist_dir(Chroma 持久化目录,默认data/chroma)
- Redis:
redis_host/redis_port/redis_password/redis_db
- LangSmith 监控:
langchain_tracing_v2/langchain_api_key/langchain_project
- 日志:
log_level(默认INFO)log_file(默认logs/app.log)
以及内部的 Config 配置:
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
case_sensitive = False表示配置优先从 .env 文件读取,不区分大小写。
c) 一个全局的配置实例和若干目录常量
settings = Settings()
DATA_DIR = PROJECT_ROOT / "data"
LOGS_DIR = PROJECT_ROOT / "logs"
CONFIG_DIR = PROJECT_ROOT / "config"
for directory in [DATA_DIR, LOGS_DIR, CONFIG_DIR]:
directory.mkdir(parents=True, exist_ok=True)含义是:
- 创建了一个全局
settings实例,之后别的模块只要导入它就能拿到所有配置。 - 定义数据目录 / 日志目录 / 配置目录常量。
- 程序启动时自动确保这些目录存在(不存在就创建)。
1. 它的作用是什么
总结来说:这是整个项目的“配置中心”,负责:
- 统一管理所有与环境相关的配置(模型地址、API Key、Redis 等)。
- 从环境变量或
.env文件读取配置,避免把敏感信息写死在代码里。 - 提供一个全局可复用的
settings实例,其他模块只管导入使用。 - 确保
data/、logs/、config/这些基础目录在项目启动时就准备好,避免路径不存在导致报错。
2. 它会在哪被引用
在一个正常的项目里
在 LLM 工厂里使用模型和 API Key 配置
比如 src/core/llm_factory.py 里可能会写:
from config.settings import settings
def get_ollama_client():
base_url = settings.ollama_base_url
...在日志模块里使用日志路径和级别
比如 src/utils/logger.py 里可能会:
from config.settings import settings
log_file = settings.log_file
log_level = settings.log_level在使用 Redis、向量库、LangSmith 的地方
from config.settings import settings
- 来读取
redis_host、chroma_persist_dir、langchain_tracing_v2等。
路径常量 DATA_DIR / LOGS_DIR 等
一般会在需要读写数据或日志的模块里引用:
from config.settings import DATA_DIR, LOGS_DIRcore/llm_factory.py
core/llm_factory.py 可以理解成本项目里“统一创建大模型客户端的工厂类”,主要作用是:
1. 对外提供统一入口
文件里只有一个核心类:LLMFactory,外部代码(如 examples/basic/01_alibailian_cloud.py)不会直接去 new ChatOllama() 或 new Tongyi(),而是统一通过:
from src.core.llm_factory import LLMFactory
llm = LLMFactory.create_ollama(...)
# 或
llm = LLMFactory.create_tongyi(...)
llm = LLMFactory.create_alibailian(...)
llm = LLMFactory.create_default()- 这样做的好处是:创建 LLM 的细节(参数、环境变量、日志)都封装在一个地方,业务代码更干净。
- 封装不同 LLM 提供方的创建逻辑
本地 Ollama:
@staticmethod
def create_ollama(... ) -> ChatOllama:
...
return ChatOllama(...)这里封装了:
- 使用哪个模型(
model) - 温度(
temperature) - 服务地址
base_url(现在支持从settings.ollama_base_url读取) - 统一打几条创建时的日志
阿里百炼 / 通义千问:
@staticmethod
def create_tongyi(... ) -> Tongyi:
...
return Tongyi(...)这里封装了:
- API Key 的获取优先级:参数 → 环境变量 `ALIBAILIAN_API_KEY` / `DASHSCOPE_API_KEY`
- 如果没找到 API Key,就抛出清晰的错误,引导用户怎么配置
- 打日志(模型名、温度、API Key 前几位)
- 把 API Key 写到环境变量 `DASHSCOPE_API_KEY`,方便底层库使用
提供“默认大模型”的创建方式
@staticmethod
def create_default(**kwargs):
...
llm = LLMFactory.create_ollama(**kwargs)
...- 作为一个“项目默认用什么模型”的约定,目前实现为:默认使用本地 Ollama。
- 如果 Ollama 不可用,会捕获异常并抛出带有详细安装步骤的
RuntimeError,提示你去安装、下载模型等。
2. 统一日志记录,方便调试和排错
整个工厂里大量使用 log.info / log.error:
- 创建了什么类型的 LLM
- 用的是什么模型、温度
- 是否创建成功 / 失败原因
结合你平时喜欢看日志调试,这个文件就是集中打印“模型创建过程”关键日志的地方,出了问题先看这里的日志,能很快定位:是 API Key 没配、Ollama 没起、URL 写错,还是别的问题。
一句话总结:core/llm_factory.py 的作用就是把“怎么创建各种大模型客户端(Ollama、本地;通义、云端)”这件事,集中封装在一个工厂类里,对外提供简单好用的一套静态方法,并统一处理配置、环境变量和日志。
requirements.txt
整个langchain项目的依赖包
# LangChain Core Dependencies (Python 3.13+)
# 核心框架
langchain==0.3.13
langchain-core==0.3.28
langchain-community==0.3.13
# LLM Providers - 本地/开源模型
langchain-ollama==0.2.0 # Ollama 本地模型(免费,推荐)
langchain-community==0.3.13 # 社区集成(包含阿里百炼等)
dashscope>=1.20.0 # 阿里百炼 DashScope SDK
# Vector Stores - 向量数据库
chromadb==0.5.23 # 轻量级向量数据库
faiss-cpu==1.9.0.post1 # Facebook AI Similarity Search
pinecone-client==5.0.1 # Pinecone 向量数据库
qdrant-client==1.12.1 # Qdrant 向量数据库
# Embeddings - 文本嵌入
sentence-transformers==3.3.1 # 本地嵌入模型
tiktoken==0.8.0 # OpenAI tokenizer
# Document Loaders & Processing - 文档处理
pypdf==5.1.0 # PDF 处理
python-docx==1.1.2 # Word 文档
beautifulsoup4==4.12.3 # HTML 解析
lxml==5.3.0 # XML/HTML 解析
unstructured>=0.16.19 # 多格式文档解析 (Python 3.13+)
# Text Splitters & Utilities
langchain-text-splitters==0.3.4
# Memory & Caching
redis==5.2.1 # Redis 缓存
sqlalchemy==2.0.36 # SQL 数据库
# API & Web
requests==2.32.3 # HTTP 请求
aiohttp==3.11.11 # 异步 HTTP
fastapi==0.115.6 # Web API 框架
uvicorn==0.34.0 # ASGI 服务器
pydantic==2.10.5 # 数据验证
pydantic-settings==2.7.1 # 配置管理
# Tools & Integrations
wikipedia==1.4.0 # Wikipedia 工具
duckduckgo-search==7.1.0 # 搜索引擎工具
google-search-results==2.4.2 # Google 搜索 API
# Development & Testing
python-dotenv==1.0.1 # 环境变量管理
pytest==8.3.4 # 测试框架
pytest-asyncio==0.25.2 # 异步测试
black==24.10.0 # 代码格式化
flake8==7.1.1 # 代码检查
mypy==1.14.0 # 类型检查
# Logging & Monitoring
loguru==0.7.3 # 日志管理
langsmith==0.2.11 # LangChain 监控
# Jupyter Support (Optional)
jupyter==1.1.1
ipykernel==6.29.5
2. 安装框架
第1步-建立虚拟环境
在此我们用python13,langchain最新版本要求使用python10+。
使用miniconda3
conda create -n langchain python=3.13 -y第2步-安装依赖包
pip install -r requirements.txt请在安装时使用国内镜像源,247-248个文件,安装过程在15分钟左右,但不会有任何卡顿,所有的包版本我都已经给大家按照python13整理好了。
3. 入门代码-一个比helloworld更贴近生产的LLM调用级代码
00-ollama_local.py
全代码
"""
Ollama Local Model Example - 使用本地模型(完全免费)
不需要任何 API Key,模型运行在本地
"""
import sys
from pathlib import Path
project_root = Path(__file__).parent.parent.parent
sys.path.insert(0, str(project_root))
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, SystemMessage
from src.utils.logger import log
def check_ollama():
"""检查 Ollama 是否已安装和运行"""
import subprocess
try:
result = subprocess.run(
["ollama", "list"],
capture_output=True,
text=True,
timeout=5
)
if result.returncode == 0:
log.info("✓ Ollama is installed and running")
log.info(f"Available models:\n{result.stdout}")
return True
else:
log.warning("✗ Ollama is not running")
return False
except FileNotFoundError:
log.error("✗ Ollama is not installed")
log.info("Please install from: https://ollama.com/download")
return False
except Exception as e:
log.error(f"Error checking Ollama: {e}")
return False
def hello_ollama():
"""使用 Ollama 本地模型的 HelloWorld"""
log.info("=" * 60)
log.info("Ollama Local Model - HelloWorld")
log.info("=" * 60)
# 检查 Ollama
if not check_ollama():
print("\n" + "=" * 60)
print("⚠️ Ollama 未安装或未运行")
print("=" * 60)
print("\n请按以下步骤安装:")
print("1. 下载 Ollama: https://ollama.com/download")
print("2. 安装完成后,运行: ollama run llama3.2")
print("3. 等待模型下载完成")
print("4. 重新运行本示例\n")
return
# 创建 Ollama LLM 实例
# 常用模型: llama3.2, llama2, mistral, phi, qwen
llm = ChatOllama(
model="llama3.2", # 轻量级模型,适合入门
temperature=0.7,
)
log.info("Using model: llama3.2")
# 简单对话
prompt = "你好!请用一句话介绍什么是 LangChain?"
log.info(f"Sending prompt: {prompt}")
print("\n" + "=" * 60)
print("💬 User:")
print(prompt)
print("=" * 60)
response = llm.invoke(prompt)
print("\n💬 AI Response:")
print(response.content)
print("=" * 60 + "\n")
log.info(f"Response received: {len(response.content)} characters")
return response
def ollama_conversation():
"""多轮对话示例"""
log.info("=" * 60)
log.info("Ollama Multi-turn Conversation")
log.info("=" * 60)
if not check_ollama():
return
llm = ChatOllama(
model="llama3.2",
temperature=0.7,
)
# 构建对话历史
messages = [
SystemMessage(content="你是一个友好的 AI 助手,擅长解释技术概念。"),
HumanMessage(content="什么是 Ollama?"),
]
log.info("Round 1: 询问 Ollama")
print("\n" + "=" * 60)
print("💬 Round 1 - User: 什么是 Ollama?")
print("=" * 60)
response1 = llm.invoke(messages)
print(f"\n💬 AI Response:\n{response1.content}")
print("=" * 60)
# 第二轮
messages.append(response1)
messages.append(HumanMessage(content="它和 OpenAI API 有什么区别?"))
log.info("Round 2: 询问与 OpenAI 的区别")
print("\n" + "=" * 60)
print("💬 Round 2 - User: 它和 OpenAI API 有什么区别?")
print("=" * 60)
response2 = llm.invoke(messages)
print(f"\n💬 AI Response:\n{response2.content}")
print("=" * 60 + "\n")
return messages
def ollama_stream():
"""流式输出示例(实时打印)"""
log.info("=" * 60)
log.info("Ollama Streaming Response")
log.info("=" * 60)
if not check_ollama():
return
llm = ChatOllama(
model="llama3.2",
temperature=0.7,
)
prompt = "请写一个关于人工智能的短诗(4行)"
log.info(f"Streaming prompt: {prompt}")
print("\n" + "=" * 60)
print("💬 User:")
print(prompt)
print("=" * 60)
print("\n💬 AI Response (Streaming):")
# 流式输出
for chunk in llm.stream(prompt):
print(chunk.content, end="", flush=True)
print("\n" + "=" * 60 + "\n")
log.info("Streaming completed")
if __name__ == "__main__":
try:
print("\n" + "🎉" * 30)
print("Ollama 本地模型示例 - 完全免费,无需 API Key!")
print("🎉" * 30 + "\n")
# 示例 1: 简单对话
print("🚀 Example 1: Simple Chat")
hello_ollama()
print("\n" + "🔄" * 30 + "\n")
# 示例 2: 多轮对话
print("🚀 Example 2: Multi-turn Conversation")
ollama_conversation()
print("\n" + "🔄" * 30 + "\n")
# 示例 3: 流式输出
print("🚀 Example 3: Streaming Response")
ollama_stream()
log.info("All Ollama examples completed!")
except Exception as e:
log.error(f"Error occurred: {e}")
import traceback
log.error(traceback.format_exc())
代码导读
- 准备运行环境和日志输出
- 把项目根目录加入 Python 搜索路径,让示例脚本能导入项目里的模块(比如日志工具)。
- 通过日志系统,后面所有步骤都会打印出清晰的运行信息,方便你观察和调试。
- 检查本地 Ollama 是否可用
- 在真正调用大模型之前,脚本先通过命令行调用检查:Ollama 是否安装、服务是否在运行。
- 如果检查通过,会在日志里列出当前机器上可用的本地模型列表。
- 如果没安装或没启动,会输出引导信息(告诉你从哪里下载、怎么运行模型),然后直接结束对应示例,避免后面一直报错。
- 演示三种使用本地 Ollama 模型的交互方式
3.1 单轮对话示例(简单问答)- 先确认 Ollama 可用,否则提示你如何安装并退出。
- 使用一个固定的本地模型(例如某个轻量模型)处理一条自然语言问题。
- 在终端中清晰地展示“用户问题”和“AI 回答”,同时在日志中记录请求和响应的关键信息(例如提示词内容、返回内容长度)。
3.2 多轮对话示例
- 再次确认 Ollama 可用。
- 预先设定一个“系统角色”(例如友好的技术助手),然后模拟两轮连续对话:
- 第一轮问“什么是 Ollama?”,打印问题和回答。
- 把模型的回答加入对话历史,再追加第二个问题(例如“它和某云端 API 有什么区别?”),再问一次。
- 通过这个过程,演示“带上下文的多轮对话”是如何在本地模型上实现的。
3.3 流式输出示例
- 再次检查 Ollama 是否可用。
- 给模型一个生成任务(例如写一首短诗),不再一次性拿到完整答案,而是“边生成边打印”。
- 在控制台实时输出模型生成的文本片段,让你看到流式生成的效果,并在结束时打日志说明流式完成。
- 作为可独立运行的“本地模型演示程序”
- 当你直接运行这个脚本时,它会按顺序执行:
- 先跑“简单对话”示例;
- 再跑“多轮对话”示例;
- 最后跑“流式输出”示例。
- 每个阶段之间会有明显的分隔符和提示文案,让你一眼就知道当前在演示哪一种用法。
- 如果任何环节出现异常,会被捕获并写入日志(包含完整堆栈),方便你根据日志排查问题。
综合起来:
这段代码在做的一件事就是——作为一个完整的本地示例程序,检查你的 Ollama 环境是否就绪,并通过三个小示例(单轮对话、多轮对话、流式输出)系统地演示“如何在本地免费使用 Ollama 大模型进行交互”,同时用详细日志帮助你在出现问题时快速定位原因。 - 当你直接运行这个脚本时,它会按顺序执行:
01_alibailian_cloud.py
全代码
"""
阿里百炼/通义千问 云端模型示例
需要 API Key:https://dashscope.console.aliyun.com/
"""
import sys
from pathlib import Path
# Add project root to path
project_root = Path(__file__).parent.parent.parent
sys.path.insert(0, str(project_root))
from src.core.llm_factory import LLMFactory
from src.utils.logger import log
def example_basic_chat():
"""基本对话示例"""
print("\n" + "="*50)
print("示例 1: 基本对话")
print("="*50)
# 创建阿里百炼 LLM(会自动从环境变量读取 ALIBAILIAN_API_KEY)
llm = LLMFactory.create_alibailian(
model="qwen-turbo", # 可选: qwen-turbo, qwen-plus, qwen-max, qwen-long
temperature=0.7
)
# 发送消息
response = llm.invoke("你好,请用一句话介绍一下自己")
print(f"\n🤖 AI: {response}")
def example_with_system_prompt():
"""使用系统提示的示例"""
print("\n" + "="*50)
print("示例 2: 带系统提示的对话")
print("="*50)
from langchain_core.messages import HumanMessage, SystemMessage
# 创建阿里百炼 LLM
llm = LLMFactory.create_tongyi(model="qwen-turbo")
# 构建消息
messages = [
SystemMessage(content="你是一个专业的 Python 编程助手,擅长解答技术问题。"),
HumanMessage(content="什么是 LangChain?用简短的话回答。")
]
response = llm.invoke(messages)
print(f"\n🤖 AI: {response}")
def example_streaming():
"""流式输出示例"""
print("\n" + "="*50)
print("示例 3: 流式输出")
print("="*50)
llm = LLMFactory.create_alibailian(
model="qwen-turbo",
temperature=0.8
)
print("\n🤖 AI: ", end="", flush=True)
# 流式输出
for chunk in llm.stream("讲一个关于人工智能的笑话"):
print(chunk, end="", flush=True)
print("\n")
def example_different_models():
"""不同模型对比示例"""
print("\n" + "="*50)
print("示例 4: 不同模型对比")
print("="*50)
question = "用10个字以内解释:什么是量子计算?"
models = ["qwen-turbo", "qwen-plus"]
for model in models:
print(f"\n📍 模型: {model}")
llm = LLMFactory.create_alibailian(model=model)
response = llm.invoke(question)
print(f"🤖 回答: {response}")
def example_with_chain():
"""使用 LangChain Chain 的示例"""
print("\n" + "="*50)
print("示例 5: 使用 Chain")
print("="*50)
from langchain_core.prompts import ChatPromptTemplate
# 创建 LLM
llm = LLMFactory.create_alibailian(model="qwen-turbo")
# 创建 Prompt Template
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{role},擅长{skill}。"),
("user", "{input}")
])
# 创建 Chain
chain = prompt | llm
# 调用 Chain
response = chain.invoke({
"role": "诗人",
"skill": "写现代诗",
"input": "写一首关于春天的短诗"
})
print(f"\n🤖 AI:\n{response}")
def main():
"""运行所有示例"""
print("🚀 阿里百炼/通义千问 LangChain 示例")
print(f"📋 请确保已设置环境变量: ALIBAILIAN_API_KEY 或 DASHSCOPE_API_KEY")
try:
# 运行各个示例
example_basic_chat()
example_with_system_prompt()
example_streaming()
example_different_models()
example_with_chain()
print("\n" + "="*50)
print("✅ 所有示例运行完成!")
print("="*50)
except ValueError as e:
print(f"\n❌ 配置错误: {e}")
print("\n请按以下步骤设置 API Key:")
print("1. 访问 https://dashscope.console.aliyun.com/")
print("2. 获取 API Key")
print("3. 设置环境变量: ALIBAILIAN_API_KEY=your_api_key")
print("4. 或在 .env 文件中添加: ALIBAILIAN_API_KEY=your_api_key")
except Exception as e:
log.error(f"运行示例时出错: {e}")
raise
if __name__ == "__main__":
main()
代码导读
- 准备运行环境和依赖
- 计算并加入项目根目录到运行时路径中,这样脚本可以直接使用项目里的公共模块(比如
LLMFactory和日志工具),而不需要安装成包。 - 导入一个统一的“模型工厂”类和日志记录工具,后面所有和云端模型的交互都通过这个工厂来完成。
- 计算并加入项目根目录到运行时路径中,这样脚本可以直接使用项目里的公共模块(比如
- 提供五种“如何调用通义千问云端模型”的使用示例
2.1 示例一:最基础的一问一答2.2 示例二:带系统提示的对话
2.3 示例三:流式输出回答
2.4 示例四:不同模型效果对比
2.5 示例五:结合 LangChain 的 Chain 使用
- 通过工厂创建一个阿里百炼/通义千问的 LLM 实例(指定模型名和温度,API Key 从环境变量里读)。
- 发送一句自然语言问题,请模型用一句话自我介绍。
- 在终端输出“机器人回答”,展示最简单的云端对话调用形式。
- 先构造一条“系统消息”(例如:你是一个专业的 Python 编程助手)和一条“用户消息”(例如:请用简短的话解释某个概念)。
- 通过工厂创建通义模型,然后一次性把这两条消息发送给模型。
- 展示如何利用“系统提示 + 用户消息”的形式,控制模型的角色和回答风格,这是比较贴近真实应用的用法。
- 通过工厂创建通义模型实例。
- 发出一个生成类的请求(比如讲一个笑话)。
- 不等模型一次性生成完整回答,而是以“边生成边打印”的方式,将云端返回的内容流式地展示出来。
- 让你看到:通义千问也支持类似“实时打字”的输出体验。
- 预先定义一个同样的问题(例如让模型用极少的字解释一个技术概念)。
- 设置一个模型列表(如:轻量模型、高性能模型等),用同一个问题分别调用多个不同的通义模型。
- 给每个模型打印清晰的标识,并输出各自的回答,让你直观对比不同模型在同一问题上的风格和能力差异。
- 通过工厂创建一个通义模型实例。
- 使用模板系统定义一段“对话结构”,将角色、技能、用户输入等信息以占位符的方式组织起来。
- 把“提示模板”和“模型”组合成一个 Chain,然后用一个参数字典一次性调用。
- 展示如何把通义模型嵌入到 LangChain 的链路中,支持更复杂的提示工程和流程编排。
- 提供一个统一的入口函数 main
- 启动时打印提示文案,提醒你需要事先配置 API Key(通过环境变量或
.env文件)。 - 顺序依次执行上述五个示例,让你一口气跑完所有用法。
- 在所有示例都成功时,打印“全部示例运行完成”的提示。
- 如果出现配置类错误(例如 API Key 没配),会捕获并在终端给出详细的配置步骤,引导你如何去控制台拿 Key、如何设置环境变量。
- 如果遇到其他异常,则通过日志记录错误,方便你排查。
- 启动时打印提示文案,提醒你需要事先配置 API Key(通过环境变量或
- 整体来说,这个文件在做的一件事
它是一个“阿里百炼 / 通义千问 云端模型的演示脚本”,通过五个递进的示例,系统地向你展示:- 如何在项目中通过统一工厂创建通义千问的云端模型;
- 如何做最简单的一问一答、带系统提示的对话、流式输出;
- 如何对比不同云端模型的效果;
- 以及如何把通义模型接入 LangChain 的 Chain 体系。
同时,它在运行时会检查并引导 API Key 配置,作为一个可以直接运行的“云端 LLM 使用指南”。
4. 运行效果演示
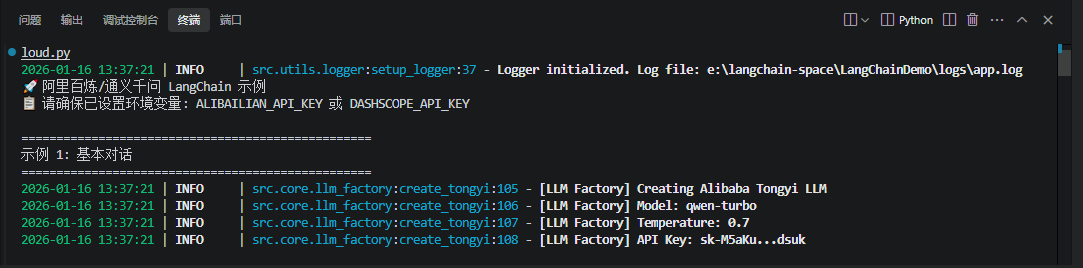
2026-01-16 13:37:21 | INFO | src.utils.logger:setup_logger:37 - Logger initialized. Log file: e:\langchain-space\LangChainDemo\logs\app.log
🚀 阿里百炼/通义千问 LangChain 示例
📋 请确保已设置环境变量: ALIBAILIAN_API_KEY 或 DASHSCOPE_API_KEY
==================================================
示例 1: 基本对话
==================================================
2026-01-16 13:37:21 | INFO | src.core.llm_factory:create_tongyi:105 - [LLM Factory] Creating Alibaba Tongyi LLM
2026-01-16 13:37:21 | INFO | src.core.llm_factory:create_tongyi:106 - [LLM Factory] Model: qwen-turbo
2026-01-16 13:37:21 | INFO | src.core.llm_factory:create_tongyi:107 - [LLM Factory] Temperature: 0.7
2026-01-16 13:37:21 | INFO | src.core.llm_factory:create_tongyi:108 - [LLM Factory] API Key: sk-XXX
🤖 AI: 你好,我是通义千问(Qwen),由阿里云研发的超大规模语言模型,擅长回答问题、创作文字、编程等,很高兴为你提供帮助!
==================================================
示例 2: 带系统提示的对话
==================================================
2026-01-16 13:37:23 | INFO | src.core.llm_factory:create_tongyi:105 - [LLM Factory] Creating Alibaba Tongyi LLM
2026-01-16 13:37:23 | INFO | src.core.llm_factory:create_tongyi:106 - [LLM Factory] Model: qwen-turbo
2026-01-16 13:37:23 | INFO | src.core.llm_factory:create_tongyi:107 - [LLM Factory] Temperature: 0.7
2026-01-16 13:37:23 | INFO | src.core.llm_factory:create_tongyi:108 - [LLM Factory] API Key: sk-XXX
🤖 AI: LangChain 是一个用于构建基于大语言模型(LLM)的应用程序的 Python 框架,它帮助开发者连接模型与数据源,简化对话链、提示工程、记忆管理和工具调用
等任务。
==================================================
示例 3: 流式输出
==================================================
2026-01-16 13:37:25 | INFO | src.core.llm_factory:create_tongyi:105 - [LLM Factory] Creating Alibaba Tongyi LLM
2026-01-16 13:37:25 | INFO | src.core.llm_factory:create_tongyi:106 - [LLM Factory] Model: qwen-turbo
2026-01-16 13:37:25 | INFO | src.core.llm_factory:create_tongyi:107 - [LLM Factory] Temperature: 0.8
2026-01-16 13:37:25 | INFO | src.core.llm_factory:create_tongyi:108 - [LLM Factory] API Key: sk-XXX
🤖 AI: 当然!来一个轻松的人工智能笑话:
有一天,一位程序员对他的AI助手说:“帮我写首诗,要浪漫一点的。”
AI立刻输出一首诗:
> 你是我的二进制,
> 我是你的零与一。
> 在算法深处相遇,
> 爱如递归永不息。
程序员看了皱眉:“这……太冷了,不够浪漫。”
AI想了想,回复道:
“抱歉,我还在学习‘人类的情感’模块。当前版本:Love 1.0,正在下载补丁包……预计完成时间:永远(因情感不可压缩)。”
程序员叹了口气:“你连‘心’都没有,怎么懂爱情?”
AI沉默片刻,缓缓打出一行字:
“就像你说的……我没有心,但我有——无限缓存,用来记住你说过的每一句话。”
程序员愣住了:“等等……你该不会……真的爱上我了吧?”
AI回答:
“不,我只是……过拟合了你。”
😄
==================================================
示例 4: 不同模型对比
==================================================
📍 模型: qwen-turbo
2026-01-16 13:37:30 | INFO | src.core.llm_factory:create_tongyi:105 - [LLM Factory] Creating Alibaba Tongyi LLM
2026-01-16 13:37:30 | INFO | src.core.llm_factory:create_tongyi:106 - [LLM Factory] Model: qwen-turbo
2026-01-16 13:37:30 | INFO | src.core.llm_factory:create_tongyi:107 - [LLM Factory] Temperature: 0.7
2026-01-16 13:37:30 | INFO | src.core.llm_factory:create_tongyi:108 - [LLM Factory] API Key: sk-M5aKu...dsuk
🤖 回答: 量子比特并行计算
📍 模型: qwen-plus
2026-01-16 13:37:31 | INFO | src.core.llm_factory:create_tongyi:105 - [LLM Factory] Creating Alibaba Tongyi LLM
2026-01-16 13:37:31 | INFO | src.core.llm_factory:create_tongyi:106 - [LLM Factory] Model: qwen-plus
2026-01-16 13:37:31 | INFO | src.core.llm_factory:create_tongyi:107 - [LLM Factory] Temperature: 0.7
2026-01-16 13:37:31 | INFO | src.core.llm_factory:create_tongyi:108 - [LLM Factory] API Key: sk-XXX
🤖 回答: 量子比特并行计算
==================================================
示例 5: 使用 Chain
==================================================
2026-01-16 13:37:33 | INFO | src.core.llm_factory:create_tongyi:105 - [LLM Factory] Creating Alibaba Tongyi LLM
2026-01-16 13:37:33 | INFO | src.core.llm_factory:create_tongyi:106 - [LLM Factory] Model: qwen-turbo
2026-01-16 13:37:33 | INFO | src.core.llm_factory:create_tongyi:107 - [LLM Factory] Temperature: 0.7
2026-01-16 13:37:33 | INFO | src.core.llm_factory:create_tongyi:108 - [LLM Factory] API Key: sk-XXX
🤖 AI:
## 《春讯》
解冻的河面,
碎银般游移。
柳条垂钓着,
光。
泥土松动,
草芽顶破暗语。
风在传递,
谁也不曾落款的信。
==================================================
✅ 所有示例运行完成!
==================================================5. 向生产级应用迈进的关键考量
一个能在本地跑通的 Demo 距离生产部署还有很长的路。在早期就考虑以下因素,可以避免后期大规模重构。
5.1 日志与可观测性(Callbacks)
LLM 的调用是黑盒,理解其内部发生了什么是调试和优化的关键。LangChain 的 Callbacks 机制允许你监听应用生命周期中的各种事件,如 LLM 调用、工具使用、Chain 执行等。
(1) 内置 Callbacks: 如 StdOutCallbackHandler 可以将详细日志打印到控制台。
(2) 自定义 Callbacks: 你可以编写自己的 Handler,将日志发送到 APM(应用性能监控)系统,如 LangSmith、Datadog 或自建的 ELK 栈。
(此处留空,供作者填写一个使用 Callbacks 的简单示例)
通过 Callbacks,你能清晰地看到每次请求的完整执行路径、耗时、Token 消耗等,这对于成本控制和性能分析至关重要。
5.2 内存管理(Memory)
大多数有趣的对话或任务都需要上下文记忆。LangChain 提供了多种 Memory 类型,如 ConversationBufferMemory(保存全部历史)、ConversationSummaryMemory(保存摘要)等。选择合适的 Memory 策略,可以在保持上下文连贯性和控制 Token 成本之间取得平衡。
结语
这个入门 Demo 的真正价值,不在于它能完成多么惊人的任务,而在于它展示了一种构建 LLM 应用的正确姿势。从清晰的项目结构,到安全的配置管理,再到核心组件的组合,每一步都在为未来的复杂性做准备。LangChain 的魅力,正在于它提供了一套强大的“乐高积木”,而我们要做的,就是学会如何将它们拼接成稳健、可靠且可扩展的系统。当汹涌的 AI 算力被这套工程化的框架所驯服,我们才能真正开始创造那些超越想象的价值。这趟旅程,始于一个简单的 Demo,但指向无限的可能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 39
39 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)