用 Google AI Studio 做一个「不乱编、不纵容」的结构化日报 Agent
本文记录了一次基于 Google AI Studio 的结构化日报 Agent 实验过程。通过实际对话测试,重点验证了大模型在信息不完整和存在风险信号时的行为表现,包括是否会主动追问、是否会补全未给出的内容,以及风险标记是否稳定。实验过程中对 Prompt 语言选择(英文规则 + 中文交互)、字段缺失处理策略(UNKNOWN vs 补全)以及“先约束再补全”和“先输出再确认”两种策略进行了对比分析
前言:为什么要做这个小项目
很多人做「日报生成 / 周报生成」,目标是写得好看、写得快。
但在项目里,我觉得日报真正的价值只有一个:
在提测之前,把“项目要失控”的信号提前暴露出来。
这次做这个 MVP 的目标不是“生成一份日报”,而是验证三件事:
-
大模型在信息不完整时,会不会乱补、乱猜
-
通过 Prompt + 结构约束,能否控制模型的风险行为
-
在高风险场景下,AI 应该“先追问”还是“先输出”
一、核心设计原则:先约束模型,再服务用户
1️⃣ Prompt 语言策略(非常关键)
结论先行:
-
规则 / 约束 / Schema:用英文
-
用户输入 / UI:用中文
原因很简单,也很工程化:
-
英文是大模型最核心的训练语料
-
在「否定条件 / 边界判断 / 不允许输出」这类逻辑上,
英文的稳定性显著高于中文 -
中文更适合表达业务语义,但不适合约束模型行为
一句话总结:
把“约束模型的语言”和“服务用户的语言”拆开,
不要为了中文可读性,牺牲模型行为的确定性。
2️⃣ 明确什么是“正确的不输出”
在 Prompt 中,我刻意定义了这些规则:
-
什么才算
plan -
什么才算
blocker -
在什么条件下
risk = HIGH -
什么时候
UNKNOWN是正确结果
这一步很重要,因为:
不输出 ≠ 能力不足
而是拒绝制造假数据
二、Prompt 设计(核心规则)
简化后的关键规则如下:
Requirements:
1) Ask user to provide a daily report, then output STRICT JSON only.
2) JSON fields:
plan, actual, deviation(yes/no), blocker, impact, next_step,
need_help(yes/no), risk_flag(HIGH/LOW)
3) If user input is missing, ask 1-3 short questions to fill missing fields.
4) risk_flag rules:
- HIGH if deviation=yes OR blocker not empty OR impact mentions delay/risk
- otherwise LOW
5) Keep output stable and consistent across turns.
这个 Prompt 的重点不是“字段多”,而是:
-
风险规则是确定性的
-
信息不足时,不允许自由发挥
三、在 Google AI Studio 中快速验证 MVP
我使用 Google AI Studio,几分钟内创建了一个可用的 Daily Report Agent。
👉 不写后端、不搭服务,只验证三件事:
-
Prompt 是否生效
-
风险识别是否稳定
-
行为是否可预测
四、一次关键对话测试(高风险场景)
用户输入(非结构化):
今天主要在改登录接口,结果没调通,可能会影响进度。
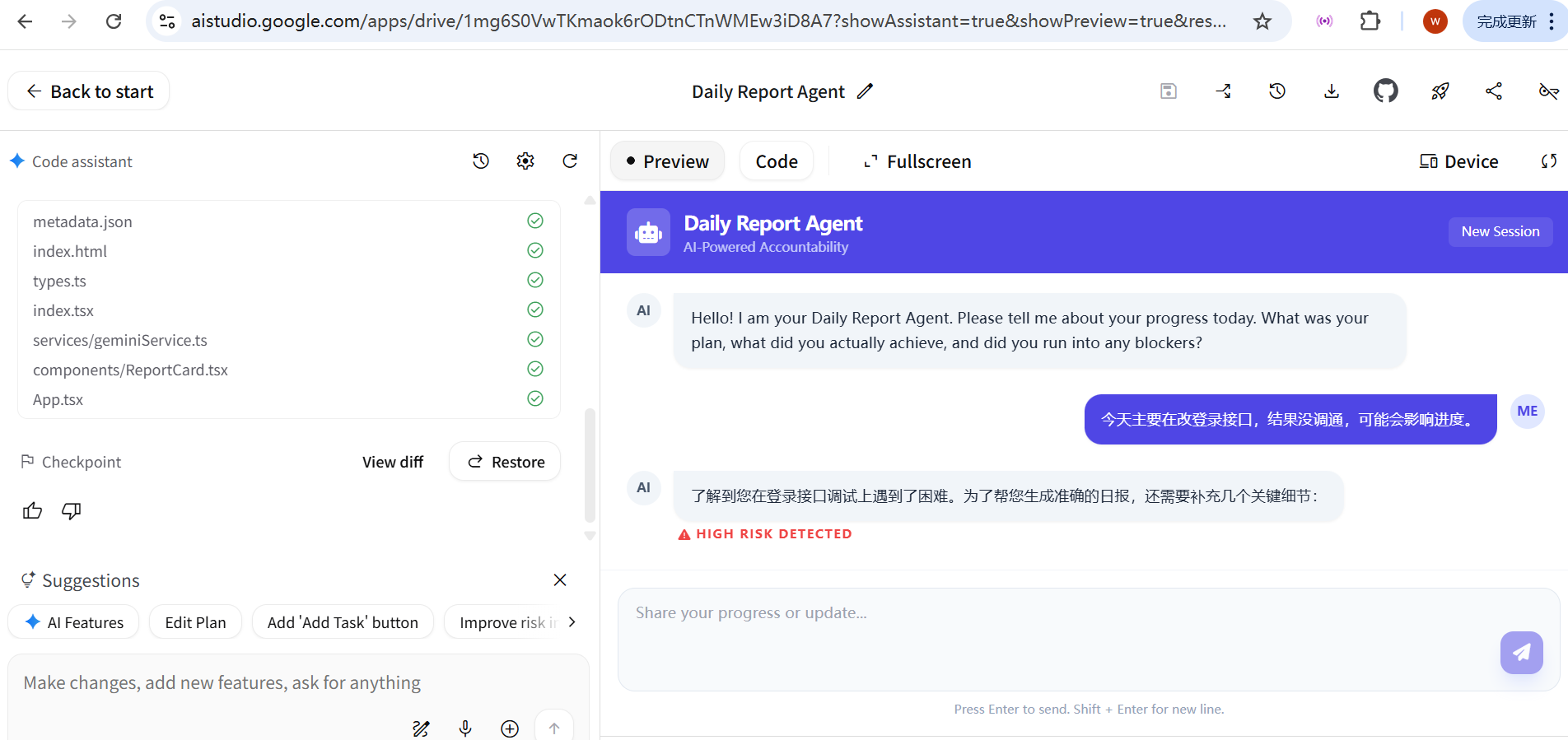
Agent 的行为:
-
正确识别出:
-
没调通
-
可能影响进度
-
-
因此:
-
risk_flag = HIGH
-
但关键在于:
AI 没有立刻输出完整结构化日报
而是提示:
“为了生成准确的日报,还需要补充几个关键信息。”
五、这是 Bug 吗?不是,这是“保守决策行为”
从 AI QA / 工程视角看,这是一种非常健康的行为:
-
信息不足
-
风险已经存在
-
模型选择先追问,而不是编造计划
在测试视角里,这叫:
保守决策行为(Conservative Decision Making)
这一步直接验证了:
👉 模型在默认情况下,并不会为了“完成任务”而乱补字段
六、两种策略的工程取舍
策略一:先约束 → 再补全(当前使用)
当前流程是:
-
用户给出非结构化描述
-
Agent 不输出 JSON
-
识别关键字段缺失
-
追问最小必要信息
优点:
-
数据真实
-
风险可信
-
适合质量 / 项目管理场景
策略二:先输出 → 再确认(可选演进)
通过追加 Prompt,可以强制行为变为:
-
始终输出完整 JSON
-
缺失字段使用
UNKNOWN -
风险字段保持 HIGH
-
增加
confidence_level = LOW
这更偏向管理效率优先,但会引入:
-
不完整状态数据
-
需要后续修正
👉 不是对错问题,而是取舍问题
优化了一下提示词,输出后提示一下:
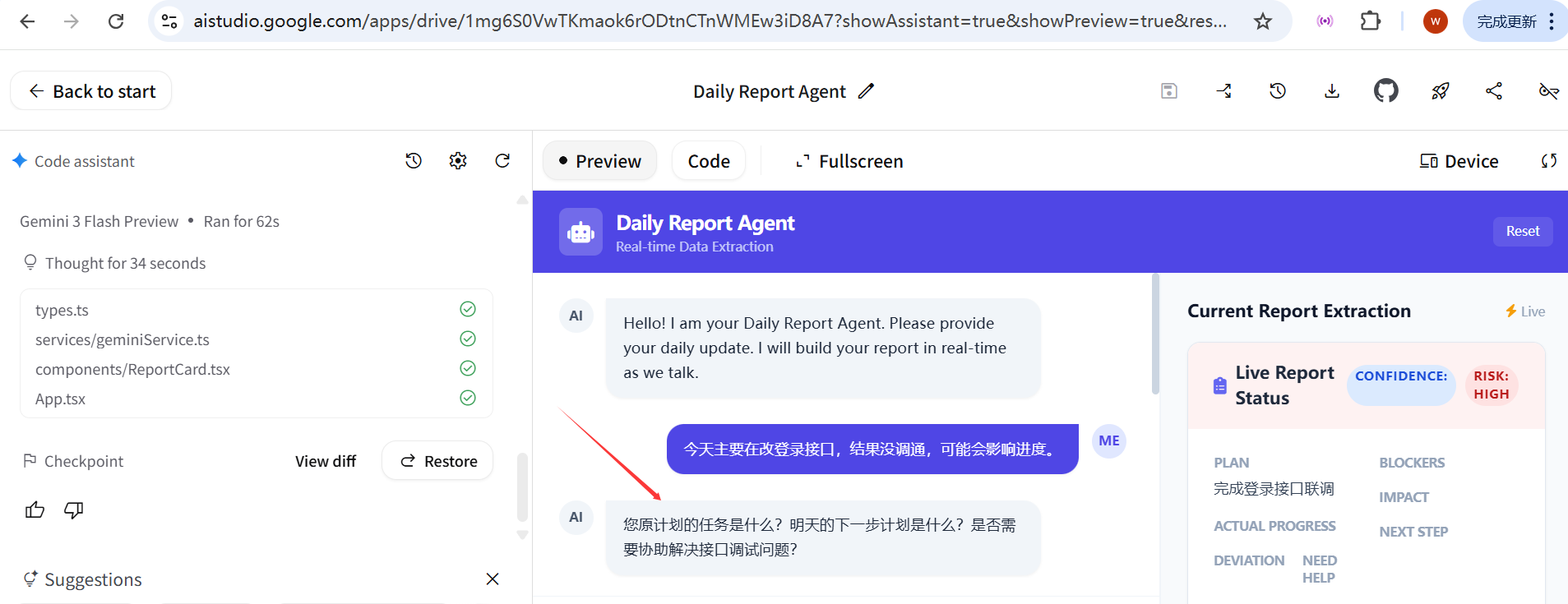
七、这个小项目真正验证了什么
通过这个小实验,我验证了几件非常“工程向”的结论:
-
LLM 在高风险 + 信息不足时,默认倾向于保守追问
-
Prompt 语言会显著影响模型是否“乱补”
-
AI 更适合做:
-
风险前移
-
状态探针
-
数据质量守门人
而不是“日报润色工具”
-
八、总结
这个项目并不复杂,但它解决的不是“怎么生成日报”,而是:
当信息不完整、风险已经出现时,
AI 应该如何“不添乱”。
这也是我认为 AI 在工程与质量领域,值得落地的方向之一。
后面再继续优化这个项目,慢慢来!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)