AI: 什么是 RAG,与 ElesticSearch 有何关系?
RAG(检索增强生成)是一种融合信息检索与文本生成的 AI 技术框架,核心是让大模型生成前先从外部知识库检索相关信息,再结合检索结果生成回答,以此弥补模型知识局限、降低幻觉、提升内容可信度与时效性。
·
RAG全称Retrieval‑Augmented Generation(检索增强生成),是一种融合信息检索与文本生成的AI技术框架,核心是让大模型生成前先从外部知识库检索相关信息,再结合检索结果生成回答,以此弥补模型知识局限、降低幻觉、提升内容可信度与时效性。
核心原理与流程
- 知识准备(离线阶段)
- 将企业文档、数据库、网页等外部知识源切分为文本片段,用Embedding模型转为向量,存入向量数据库建立索引。
- 检索(在线阶段)
- 接收用户查询后,将问题转为向量,在向量数据库中通过语义匹配快速召回Top‑N相关文本片段。
- 生成(在线阶段)
- 将检索到的文本片段与原始查询拼接为上下文,输入大语言模型(LLM),生成有来源依据、事实准确的回答。
核心价值与优势
| 优势 | 说明 |
|---|---|
| 解决知识滞后 | 无需重训模型,更新知识库即可获取新药进展、金融政策变动等最新信息 |
| 减少幻觉 | 以检索到的权威文档为依据生成内容,降低事实错误风险 |
| 增强可解释性 | 回答可关联具体知识来源,支持溯源与验证,提升可信度 |
| 降低成本 | 避免全量模型重训的高算力/时间成本,知识更新更高效灵活 |
| 场景定制化 | 可构建行业专属知识库(如法律、医疗、金融),适配专业需求 |
关键技术组件
- Embedding模型:负责将文本转为高维向量,捕捉语义信息,如OpenAI Embeddings、BERT等。
- 向量数据库:高效存储与检索向量,支持快速相似性匹配,如Pinecone、Chroma、Milvus等。
- 检索策略:包括关键词检索、语义检索、混合检索(关键词+语义),提升召回精度。
- 大语言模型:如GPT‑4、Llama 2等,负责理解上下文并生成自然语言回答。
- 提示词工程:优化检索结果与查询的拼接方式,引导模型生成高质量内容。
典型应用场景
- 企业知识问答:基于内部文档(如规章制度、技术手册)提供精准答案,适用于员工培训、IT支持。
- 智能客服:结合产品手册、常见问题库,实时解答用户疑问,提升服务效率。
- 金融分析:检索市场动态、政策文件、研报,辅助生成投资建议、风险评估报告。
- 医疗咨询:整合最新临床指南、药品信息,支持医生快速获取诊疗参考,确保建议时效性。
- 法律检索:从法规库、判例集检索相关条文与案例,辅助律师准备法律文书、提供咨询。
挑战与优化方向
- 检索精度:需平衡召回率与精确率,避免无关信息干扰或关键信息遗漏,可通过混合检索、重排模型优化。
- 知识更新与治理:建立知识库更新机制,确保信息权威、及时,避免过时内容影响回答质量。
- 上下文长度限制:LLM上下文窗口有限,需对检索结果精炼、摘要,提升信息密度。
- 多模态支持:拓展至图片、音频、视频等多模态数据的检索与生成,适配更复杂场景。
总结
RAG通过“检索+生成”的协同模式,为大模型提供了动态、可验证的知识增强方案,在降低幻觉、提升时效性与可解释性方面优势显著,是企业AI应用落地的关键技术之一,尤其适用于知识密集型领域的智能问答、内容生成与决策支持。
RAG 与 ElesticSearch 有何关系?
RAG(检索增强生成)与 Elasticsearch 并非对立或替代关系,Elasticsearch 是可以作为 RAG 架构中检索环节的工具之一,二者属于“技术框架”与“组件工具”的关联。
具体来说,二者的关系可以从以下几个维度拆解:
| 维度 | RAG | Elasticsearch |
|---|---|---|
| 定位 | 一套端到端的技术框架,核心目标是通过“检索+生成”提升大模型输出的准确性和时效性 | 一款分布式全文检索引擎,核心能力是对结构化/非结构化数据做高效的关键词、模糊、范围检索 |
| 在 RAG 中的角色 | 主导整个流程(知识准备→检索→生成→反馈) | 可作为 RAG 检索层的实现工具,替代或配合向量数据库完成检索任务 |
| 适配的检索方式 | 支持多种检索策略(语义检索、关键词检索、混合检索) | 原生擅长关键词检索,通过插件(如 Elasticsearch Vector Search)可支持语义检索 |
| 核心优势互补 | 解决大模型知识滞后、幻觉问题 | 弥补纯向量数据库在关键词匹配、过滤聚合、大规模数据管理上的短板 |
1. Elasticsearch 在 RAG 中的两种典型用法
(1)纯关键词检索方案
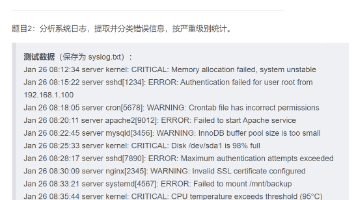
适用于数据结构清晰、用户查询以明确关键词为主的场景(如企业文档查询、日志问答)。
- 流程:
- 将知识库文本(如金融研报、政策文件)预处理后存入 Elasticsearch,建立字段索引(如标题、正文、发布时间)。
- 用户输入查询(如“2025年量化交易新规”),Elasticsearch 基于关键词匹配召回相关文档片段。
- 将检索结果拼接为上下文,送入大模型生成回答。
(2)混合检索方案(关键词+语义)
这是更主流的进阶用法,结合 Elasticsearch 的关键词优势和向量数据库的语义优势,提升 RAG 检索精度。
- 流程:
- 对知识库文本同时做两件事:① 存入 Elasticsearch 建立关键词索引;② 用 Embedding 模型转成向量,存入向量数据库。
- 用户查询时,同时触发 Elasticsearch 的关键词检索和向量数据库的语义检索。
- 对两类检索结果做融合重排(如按相关性打分排序),筛选出最优片段送入大模型。
2. Elasticsearch 用于 RAG 的优缺点
| 优点 | 缺点 |
|---|---|
| 支持大规模数据的分布式存储与检索,稳定性强 | 原生语义检索能力弱,需依赖插件(如 Elastic Learned Sparse Encoder)实现向量功能 |
| 自带丰富的过滤、聚合、排序功能,可按时间、类别等维度筛选检索结果 | 向量检索性能不如专业向量数据库(如 Milvus、Pinecone),高维度向量场景下效率偏低 |
| 对结构化数据(如数据库表、CSV)和非结构化数据(如 PDF、Word)均有良好支持 | 部署和维护成本高于轻量级向量数据库(如 Chroma) |
3. 与专业向量数据库的选择对比
在 RAG 架构中,选择 Elasticsearch 还是专业向量数据库,核心看场景需求:
- 若查询以关键词为主、语义为辅,且需要复杂的过滤/聚合逻辑(如金融领域按行业、时间筛选研报)→ 优先 Elasticsearch 或混合方案。
- 若查询以自然语言语义匹配为主(如开放域问答、智能客服)→ 优先专业向量数据库,检索精度更高。
需要我帮你整理一份RAG检索层工具选型对比表,涵盖Elasticsearch、Milvus、Pinecone等主流工具的核心参数吗?是的。
RAG 检索层主流工具选型对比表
| 工具类型 | 工具名称 | 核心优势 | 适用场景 | 向量检索性能 | 部署方式 | 成本 | 局限性 |
|---|---|---|---|---|---|---|---|
| 全文检索引擎(支持向量功能) | Elasticsearch | 1. 兼具关键词检索+向量检索,混合检索能力强 2. 支持复杂过滤、聚合、排序(如按时间/行业筛选) 3. 生态成熟,支持结构化/非结构化数据 |
金融研报检索、企业文档管理、日志问答等需要关键词+语义结合的场景 | 中(高维度向量场景下,检索速度低于专业向量数据库) | 1. 开源版:本地/私有云部署 2. 商业版:Elastic Cloud 托管 |
开源版成本低;商业版按资源计费,中高成本 | 1. 向量功能需依赖插件,配置较复杂 2. 高维度向量(>1024维)检索效率下降 3. 资源占用较高 |
| 开源向量数据库 | Milvus | 1. 专为向量检索设计,支持多种索引算法(如IVF_FLAT、HNSW) 2. 分布式架构,可水平扩展,支持大规模向量数据 3. 适配多模态向量(文本、图片、音频) |
大规模语义检索、多模态问答、推荐系统 | 高(分布式架构下,亿级向量检索毫秒级响应) | 1. 开源版:本地/私有云部署 2. 商业版:Zilliz Cloud 托管 |
开源版成本低;商业版按存储和查询量计费 | 1. 关键词检索能力弱,需配合其他工具 2. 部署和运维有一定技术门槛 |
| 开源向量数据库 | Chroma | 1. 轻量级部署,支持本地快速启动,无需复杂配置 2. 内置Embedding模型接口,可直接对接OpenAI/Hugging Face模型 3. 支持Python API,集成成本低 |
小型项目、原型验证、本地知识库问答 | 中(适合百万级向量规模,大规模场景性能不足) | 开源版:本地部署/轻量云服务器 | 极低(开源免费,资源占用小) | 1. 不支持分布式扩展,无法应对亿级向量 2. 企业级特性(如权限管理)缺失 |
| 闭源托管向量数据库 | Pinecone | 1. 全托管服务,无需部署运维,开箱即用 2. 自动扩缩容,适配流量波动 3. 支持混合检索(关键词+向量),检索精度高 |
企业级应用、生产环境、快速上线的项目 | 高(优化的索引算法,支持亿级向量低延迟检索) | 托管云服务(无开源版) | 中高(按存储量、查询量和向量维度计费,小规模试用有免费额度) | 1. 闭源,数据隐私需依赖厂商合规 2. 成本随数据规模增长较快 3. 定制化能力有限 |
| 闭源托管向量数据库 | Weaviate | 1. 支持知识图谱与向量检索结合,可关联实体关系 2. 内置语义搜索API,支持过滤和聚合 3. 多语言支持,适配全球化场景 |
知识图谱问答、实体关联检索、多语言语义查询 | 高 | 1. 开源版:本地/私有云部署 2. 商业版:Weaviate Cloud Services 托管 |
开源版成本低;商业版按资源计费 | 1. 知识图谱功能配置复杂 2. 托管版价格较高,适合中大型企业 |
选型核心决策建议
- 原型验证/小项目 → 优先 Chroma,轻量易部署,集成成本低。
- 金融/企业级混合检索场景 → 优先 Elasticsearch,兼顾关键词和语义检索,支持复杂筛选。
- 大规模向量/分布式生产环境 → 优先 Milvus(开源) 或 Pinecone(托管),性能和扩展性更优。
- 知识图谱+向量检索场景 → 优先 Weaviate,支持实体关系关联。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)