AI基础概念之十一:CNN算法的基本原理
(如 28×28→784×1),完全破坏了像素的空间位置关系 —— 它无法区分 “左上角的像素和相邻像素” 与 “左上角的像素和右下角的像素” 的差异,只能学习到无结构的特征。每个卷积核对应一个可学习的偏置值,在步骤 2 的点积结果上加上偏置,公式:output=点积结果+b偏置的作用是调整特征图的整体数值范围,提升模型的拟合能力。计算:0×1+0×0+0×(−1)+0×1+1×0+2×(−1)+
一、 多层感知机的缺陷
多层感知机(MLP)的层与层之间采用全连接(每个神经元与上一层所有神经元相连),这种结构在处理图像、语音等二维 / 一维网格数据时,存在三个致命问题。
参数爆炸,计算效率极低
-
以一张 28×28 的手写数字图片为例,输入层有 784 个神经元,若隐藏层设 1000 个神经元,仅这一层的权重参数就有 784×1000=784000 个;
-
若处理 224×224×3 的彩色图像,输入层有 150528 个神经元,隐藏层设 2048 个神经元,权重参数会达到 150528×2048≈3.1×108 个 —— 参数过多会导致训练慢、过拟合风险高、需要海量数据支撑。
丢失空间结构信息,无法利用数据局部相关性
-
图像、语音等数据的核心特征是局部相关的:比如图像的边缘、纹理是由相邻像素组成的,语音的声调是由连续帧组成的;
-
MLP 会将输入的二维图像展平为一维向量(如 28×28→784×1),完全破坏了像素的空间位置关系 —— 它无法区分 “左上角的像素和相邻像素” 与 “左上角的像素和右下角的像素” 的差异,只能学习到无结构的特征。
缺乏平移不变性,泛化能力差
-
平移不变性:图像中的物体(如猫)无论在左、中、右位置,模型都应该识别出来;
-
MLP 不具备这种能力:若训练数据中猫在图像左侧,当测试数据中猫在右侧时,MLP 会因为输入向量的元素顺序改变而无法识别;
二、 CNN 算法的诞生
-
1989 年:CNN 的雏形LeNet-1。杨立昆(Yann LeCun)团队受生物视觉系统 “局部感受野” 的启发,提出卷积神经网络的早期模型,首次引入卷积层、池化层的核心结构:卷积层:用共享权重的卷积核提取图像局部特征(边缘、角点),大幅减少参数;池化层:下采样降维,保留关键特征的同时降低计算量。
-
1998 年:LeNet-5 模型。杨立昆团队正式提出LeNet-5,这是第一个完整的卷积神经网络模型,专为手写数字识别设计(MNIST 数据集)。它包含 3 层卷积 + 2 层池化 + 2 层全连接,能以 99% 以上的准确率识别手写数字,是 CNN 的里程碑。但受限于计算能力不足、数据集规模小,LeNet-5 仅用于实验室场景,未大规模落地,神经网络再次进入低谷(此时支持向量机 SVM 等传统机器学习算法更受青睐)。
-
2006 年:深度学习的起点。杰弗里・辛顿(Geoffrey Hinton)在《Science》发表论文,提出两个关键技术:预训练 + 微调:用受限玻尔兹曼机(RBM)对深层网络逐层预训练,再用 BP 算法微调,解决深层网络训练时的 “梯度消失” 问题;首次明确深度神经网络(Deep Neural Network, DNN)的概念:指层数 ≥ 5 层的神经网络(区别于传统 2-3 层的浅层网络)。这一突破让学术界意识到 “深层网络” 的潜力,深度学习时代正式开启。
-
2012 年:AlexNet 引爆深度学习革命。辛顿的学生亚历克斯・克里泽夫斯基(Alex Krizhevsky)提出AlexNet,一个 8 层的深度卷积神经网络,在 ImageNet 图像分类大赛中以15.3% 的错误率碾压第二名(传统方法错误率 26.2%),震惊学界。AlexNet 的成功关键是在算力、数据和算法上同时进行了大幅度的改进。 这一事件标志着卷积神经网络(CNN)成为计算机视觉的核心模型,深度学习从实验室走向工业界。
-
利用GPU 并行计算:大幅提升训练速度(当时用 2 块 GTX580 GPU)。AlexNet 的参数达到 6000 万,是 LeNet-5 的 1000 倍,足够支撑复杂图像的特征提取
-
AlexNet 的训练数据是 ImageNet-2012,包含 120 万张标注图像、1000 个类别,覆盖了真实世界的复杂场景
-
算法创新:解决深层网络训练难题,提升模型鲁棒性
AlexNet 在 LeNet-5 的基础上,做了 4 个关键改进,让深层 CNN 的训练变得稳定且高效:
创新点 解决的问题 商用价值 ReLU 激活函数 替代 Sigmoid,解决深层网络的梯度消失问题 让网络可以堆叠到 8 层,且训练收敛速度提升 10 倍 Dropout 正则化 随机丢弃部分神经元,防止过拟合 让模型在大规模数据上的泛化能力更强,商用场景下准确率更稳定 重叠池化(Overlapping Pooling) 池化核 3×3、步长 2,避免特征混叠 提升特征提取的精度,减少商用场景的误判(如安防识别错人) LRN 层(局部响应归一化) 增强特征的区分度 提升分类任务的准确率,
如今CNN已经在全领域落地应用,CNN 和深度神经网络彻底改变了多个行业:计算机视觉:车牌识别、人脸识别、自动驾驶图像检测、医疗影像诊断;语音识别:智能音箱、语音转文字;自然语言处理:机器翻译、聊天机器人。
Geoffrey Hinton 与 Yoshua Bengio、Yann LeCun(深度学习三巨头)因对深度神经网络的奠基性贡献,共同荣获2018 年 ACM 图灵奖。在CNN的发展中,Hinton和Yann LeCun都有着及其重要的奠基性作用。
三、 CNN 算法的核心模块:卷积层(Convolutional Layer)
这是 CNN 的灵魂模块,核心作用是提取图像的局部特征(如边缘、纹理、形状)。用一组可学习的卷积核(Filter/Kernel) 滑过输入图像,卷积核与图像的局部区域做点积运算,输出特征图(Feature Map)。卷积核的大小决定局部感受野(如 3×3、5×5),即每次关注图像的一小块区域。其关键特性包括:权值共享:同一个卷积核在整张图像上重复使用,大幅减少参数数量(相比全连接层,参数量可降低几个数量级)。空间不变性:无论特征在图像的哪个位置,卷积核都能识别,让模型具备平移不变性。
卷积中常用到的几个基础概念:
| 术语 | 含义 | 示例 |
|---|---|---|
| 输入(Input) | 卷积层的输入,可为原始图像或上层特征图 | 28×28 的灰度图(单通道)、32×32×3 的彩色图(3 通道) |
| 卷积核(Kernel/Filter) | 可学习的权重矩阵,用于提取局部特征 | 3×3×3(高 × 宽 × 输入通道数) |
| 步长(Stride) | 卷积核每次滑动的像素数 | Stride=1(逐像素滑动)、Stride=2(隔 1 像素滑动) |
| 填充(Padding) | 在输入边缘补 0,用于保持输出尺寸 | Padding=1(3×3 卷积核补 1 圈 0,输出尺寸与输入一致) |
| 输出(Feature Map) | 卷积运算后的结果,即提取的特征 | 输入 28×28、3×3 核、Stride=1、Padding=1 → 输出 28×28 |
卷积层的分步实现(以 2D 卷积为例)我们以单通道输入 + 单卷积核的最简场景为例,拆解每一步计算过程:
步骤 1:输入预处理(可选 Padding)
目的:避免卷积后特征图尺寸缩小(尤其是多层卷积时,尺寸会持续收缩)。
-
规则:若输入尺寸为 H×W,卷积核尺寸为 K×K,步长 S,填充 P,则输出尺寸为:
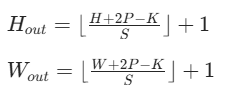
-
示例:输入 5×5,3×3 卷积核,Stride=1,Padding=1,输出 5×5;无 Padding 则输出 3×3。
步骤 2:卷积核滑动与局部点积(核心步骤)
这是卷积层的核心运算,本质是卷积核与输入局部区域的加权求和:
-
将卷积核覆盖到输入的第一个局部区域(左上角);
-
对卷积核的每个权重与输入对应位置的像素值做点积(相乘后求和);
-
将结果作为输出特征图对应位置的像素值;
-
按步长滑动卷积核,重复 1-3 步,直到遍历输入的所有区域。
直观示例(有Padding、Stride=1):
Padding 的核心作用是补 0 保持输出尺寸与输入一致,以下是 5×5 输入 + Padding=1+3×3 卷积核的完整过程:
补 0 后的输入(7×7):
[[0, 0, 0, 0, 0, 0, 0],
[0, 1, 2, 3, 4, 5, 0],
[0, 6, 7, 8, 9, 10, 0],
[0, 11,12,13,14,15, 0],
[0, 16,17,18,19,20, 0],
[0, 21,22,23,24,25, 0],
[0, 0, 0, 0, 0, 0, 0]]
Hout=(5+2×1−3)/1+1=5,Wout=5,输出为 5×5 矩阵(与原输入尺寸一致)。
计算输出 [0,0]
[[0, 0, 0],
[0, 1, 2],
[0, 6, 7]]
计算:0×1+0×0+0×(−1)+0×1+1×0+2×(−1)+0×1+6×0+7×(−1)=0−2−7=−9,输出 [0,0] = -9。
最终输出
[[-9, -6, -8, -10, -7],
[-3, -6, -8, -10, -13],
[-3, -6, -8, -10, -13],
[-3, -6, -8, -10, -13],
[-15, -6, -8, -10, -19]]
Padding=1 后,输出尺寸从 3×3 恢复为 5×5,边缘像素的特征也能被提取(无 Padding 时边缘信息会丢失)。
步骤 3:加偏置(Bias)
每个卷积核对应一个可学习的偏置值,在步骤 2 的点积结果上加上偏置,公式:output=点积结果+b偏置的作用是调整特征图的整体数值范围,提升模型的拟合能力。
获得输出后,同样可以采用反向传播 + 梯度下降的方式来实现参数的更新。
四、 CNN 算法的核心模块:池化层(Pooling Layer)
也叫下采样层,核心作用是压缩特征图尺寸、保留关键特征、提升模型鲁棒性。对卷积层输出的特征图进行局部聚合操作,用局部区域的统计值(最大值 / 平均值)替代该区域的所有值。两种主流类型:最大池化(Max Pooling):取局部区域的最大值,能有效保留边缘、纹理等强特征,是最常用的池化方式。平均池化(Average Pooling):取局部区域的平均值,能保留背景等平滑特征,常用于模型的最后几层
池化层的关键作用包括:
-
降低特征图的宽和高,减少后续计算量;
-
增强平移不变性(特征位置轻微变化不影响池化结果);
-
一定程度上防止过拟合。
一、 明确池化层输入,已刚才卷积层的输出作为池化层输入举例
回顾之前 Padding=1 后的卷积输出(5×5):
input_pool = np.array([
[-9, -6, -8, -10, -7],
[-3, -6, -8, -10, -13],
[-3, -6, -8, -10, -13],
[-3, -6, -8, -10, -13],
[-15, -6, -8, -10, -19]
])
二、 池化层核心参数(通用配置)
-
池化核大小 K=2×2
-
步长 S=2
-
填充 P=0(池化层一般不填充,除非需要严格保持尺寸)
三、 计算输出尺寸
池化输出尺寸公式与卷积一致:
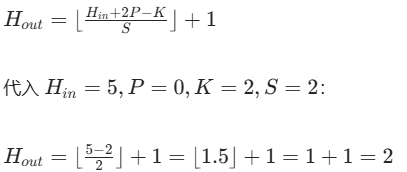
同理 Wout=2,最终池化输出为 2×2 矩阵(输入边缘不足 2×2 的区域会被舍弃)。
四、 2×2 最大池化(Max Pooling):取局部区域最大值
核心逻辑:滑动 2×2 池化核,取每个区域的最大值作为输出像素。最终输出(2×2)
[[-3, -8],
[-3, -8]]五、 2×2 平均池化(Average Pooling):取局部区域平均值
最终输出(2×2)
[[-6.0, -9.0],
[-4.5, -9.0]]池化层处理的核心结论
-
输入尺寸影响:5×5 输入经 2×2 步长 2 池化后,输出压缩为 2×2,实现降维;
-
无学习参数:池化的 “取最大 / 平均” 规则固定,训练中无需更新参数;
-
特征鲁棒性:最大池化保留局部最强特征(如本例的 -3),平均池化保留局部整体趋势(如本例的 -6);
-
边缘舍弃:步长 = 2 时,输入最后一行 / 列的剩余 1 个像素会被舍弃,若需保留可设置 Padding=1。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)