Kimi新架构训练效率提升25%!马斯克夸赞
月之暗面刚刚发布了新模型架构𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔。在不同模型尺寸上,训练效率均提升了25%。有人声称这一创新,将注意力旋转了90°。马斯克也对这一创新表示惊叹。AI大神Karpathy直言,我们对Transformer开山之作《Attention is All You Need》这篇论文的理解还是不够。月之暗面团队提出注意力残差机制,巧妙化解了
月之暗面刚刚发布了新模型架构𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔。

在不同模型尺寸上,训练效率均提升了25%。
有人声称这一创新,将注意力旋转了90°。
马斯克也对这一创新表示惊叹。
AI大神Karpathy直言,我们对Transformer开山之作《Attention is All You Need》这篇论文的理解还是不够。

月之暗面团队提出注意力残差机制,巧妙化解了深层网络中的信息稀释难题。这是基础架构的一次前沿突破。
揭开深度网络的记忆瓶颈
深度神经网络是驱动现代人工智能的核心引擎,信息在其中逐层流动并完成复杂的特征提取。
在现代大型语言模型(LLM)中,残差连接(Residual connections)与前置归一化(PreNorm)构成了标准的骨架组合。
每一层在对输入进行加工后,都会将新生成的特征与原始输入直接相加,随后再传递给下一层。
这种设计曾经是解决深层网络梯度消失问题的关键钥匙。
通过展开网络结构的数学表达,每一层实际上都在接收前面所有层输出结果的均匀累加和。
从浅层到深层,每一层都在以固定的单位权重进行累加,信息流的汇聚方式显得十分机械。
随着网络深度的不断增加,隐藏层的数值规模会呈线性增长。前期网络层输出的信息在经过数十次的累加后,其相对占比会被严重稀释。
早期层包含的原始输入细节被逐渐掩盖,深层网络无法根据当前任务的需要,精准回溯并提取特定浅层的信息。
为了在庞大的累加和中维持自身的影响力,越靠后的网络层往往被迫输出更大规模的数值,整个训练过程的稳定性因此受到挑战。
一些研究尝试引入缩放残差路径或是多流循环机制,但大多依然受限于固定的加法累加模式。让网络在不同层之间实现有选择性的信息交互,成为进一步释放模型潜力的核心诉求。
序列建模领域的发展历程为深度维度的优化提供了灵感。
早期的循环神经网络(RNN)在处理长文本序列时,同样面临着将历史信息压缩到单一隐藏状态的瓶颈。
Transformer架构通过引入注意力机制,允许模型在处理当前Token时,自主分配权重去关注序列中的任何一个历史位置,从而彻底改变了自然语言处理的格局。
时间维度与深度维度在信息传播上展现出奇妙的对偶性,沿着深度维度引入类似的注意力选择机制,显得自然且充满前景。
让每一层拥有独立选择权
月之暗面团队提出了一套被称为注意力残差(Attention Residuals)的全新机制。
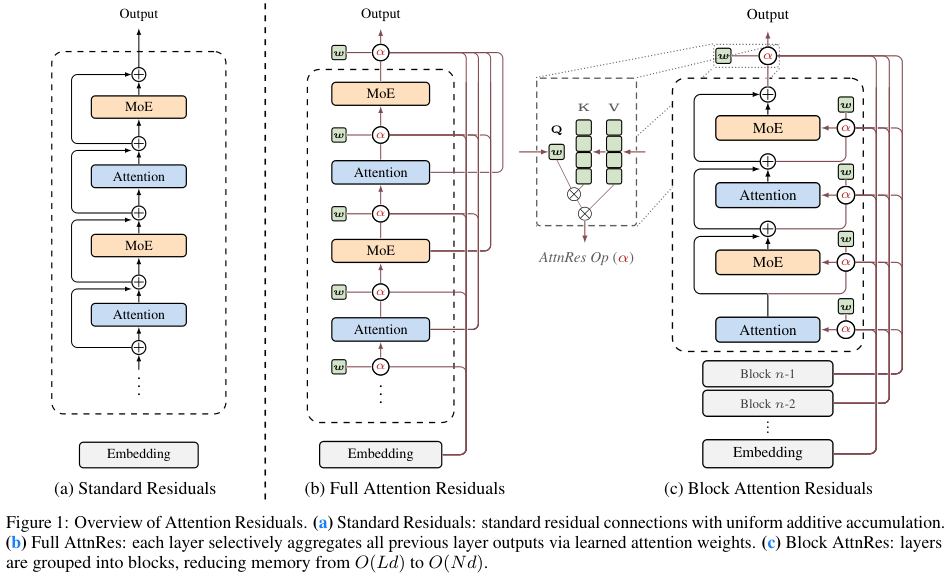
该机制舍弃了传统残差连接中僵化的均匀累加,转而采用一种基于Softmax函数的深度注意力聚合方式。
每一层不再被动接受一个混合了所有历史信息的臃肿状态,而是主动出击,通过学习得到的专属查询向量(Query vector),对所有前置层的输出结果进行动态打分和加权融合。
在完全注意力残差(Full AttnRes)的设定中,每一层都配备了一个独立可学习的伪查询向量。
当信息传递到特定层时,该层会利用自己的查询向量,计算与前面所有层输出结果的匹配度。为了防止某些数值过大的层在注意力分配中占据绝对主导,机制内部融合了均方根归一化(RMSNorm)操作。
网络层可以根据输入数据的具体内容,灵活决定是更多地参考刚经过处理的上一层特征,还是直接跨越数十层去调取非常早期的Token嵌入信息。
每一个Token在进行完全注意力残差计算时,计算量相较于常规模型仅有小幅增加。
由于网络深度远远小于序列长度,这部分额外的算力消耗在整体计算框架下显得微乎其微。
面对工业界动辄数十亿乃至上百亿参数的大规模分布式训练场景,流水线并行(Pipeline parallelism)与激活值重计算是标准配置。流水线并行会将庞大的模型切分并部署在不同的计算节点上。
完全注意力残差要求保留每一个前置层的输出,并在不同的物理节点之间进行全量传输。
巨大的通信开销与内存占用构成了严峻的工程挑战,迫切需要一种既能保留注意力机制优势,又能兼顾分布式系统效率的折中方案。
团队随即推出了块状注意力残差(Block AttnRes)作为高效的替代架构。网络包含的所有层被划分为若干个固定大小的区块。
在每一个区块内部,信息的流转依然遵循传统的残差累加模式,各个层的输出被汇总成一个单一的区块级表示。跨越区块边界时,网络则运用完整的注意力机制,专门针对有限的几个区块级表示以及初始的Token嵌入进行加权融合。
区块划分大幅度削减了需要存储和通信的特征数量。不仅单层节点的内存输入输出压力显著降低,跨节点通信的数据量也成比例缩小。
区块级表示有效浓缩了局部网络层的特征精华,注意力机制依然能够在宏观的深度尺度上进行灵活的信息调度,实现了计算效率与模型表达能力的绝佳平衡。
化整为零的工程智慧
大规模训练与推理需要极为精密的系统优化来支撑。在交错式的流水线并行调度中,每一个物理节点通常会负责执行多个虚拟阶段的计算任务。
传统的通信方式在每次虚拟阶段切换时,都会机械地将所有累积的区块表示发送给下一个节点,造成了大量的冗余数据传输。
团队引入了跨阶段缓存技术。
由于物理节点会连续处理多个虚拟阶段,早期阶段接收到的区块数据可以被直接缓存在本地内存中。当进入后续的虚拟阶段时,节点间只需传输那些全新计算完成的增量区块即可。
通信开销实现了大幅度缩减,数据传输过程完全可以被常规的计算任务所掩盖,整个分布式集群的运转效率得到了极大的保障。
推理阶段同样面临着延迟与内存管理的双重考验。传统的自回归解码过程如果在每一层都执行遍历历史区块的注意力计算,极易引发内存访问瓶颈。长文本预填充阶段更是需要保存海量的区块状态,对设备的显存容量提出了苛刻要求。
双阶段计算策略(Two-phase computation strategy)应运而生。
第一阶段聚焦于区块间的并行注意力计算。由于伪查询向量是预先学习好的独立参数,它们与当前层的动态前向计算过程解耦。同一个区块内所有层的查询向量可以被拼接起来,通过一次批量的矩阵乘法,统一完成对历史区块特征的读取与匹配。内存访问次数被大幅度摊销,读取效率得到质的飞跃。
第二阶段则专注于区块内部的序列化计算与结果合并。每一层在处理区块内部的局部累加信息后,会利用在线Softmax(Online softmax)算法,将局部结果与第一阶段获得的历史全局特征进行元素级别的合并。
合并操作非常轻量,自然支持与周围的归一化算子进行算子融合,极大降低了显存读写延迟。对于长上下文输入,预填充阶段产生的历史特征会被切分并分布在各个张量并行(Tensor-parallel)设备上,结合分块预填充技术,每张显卡上的额外显存占用被压缩至极低水平。
详尽的算力与内存读写统计进一步验证了优化方案的卓越性。常规残差连接在每一层需要进行少量的读写操作。块状注意力残差在引入区块化与双阶段调度后,平均每一层的读写成本仅仅微幅增加。推理过程的端到端延迟增加不足2%,完全具备成为下一代大规模模型标准组件的工程基础。
以下表格详细记录了不同残差机制下,针对每一个Token的单层内存读写成本:
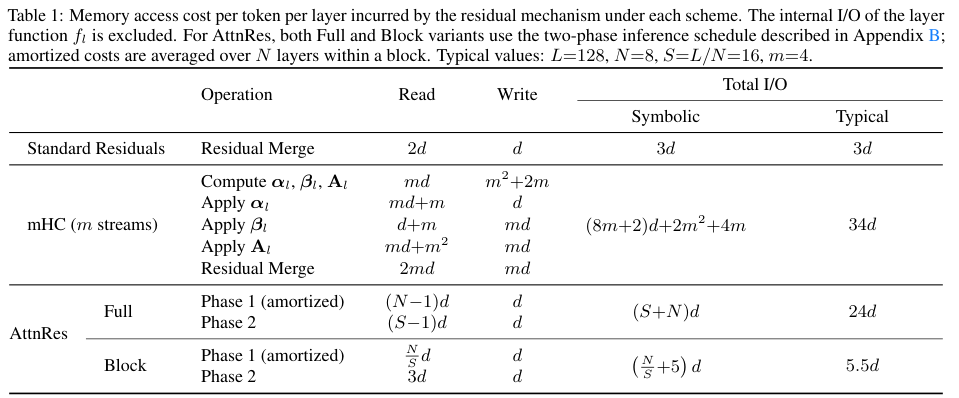
规模扩展与能力跃升
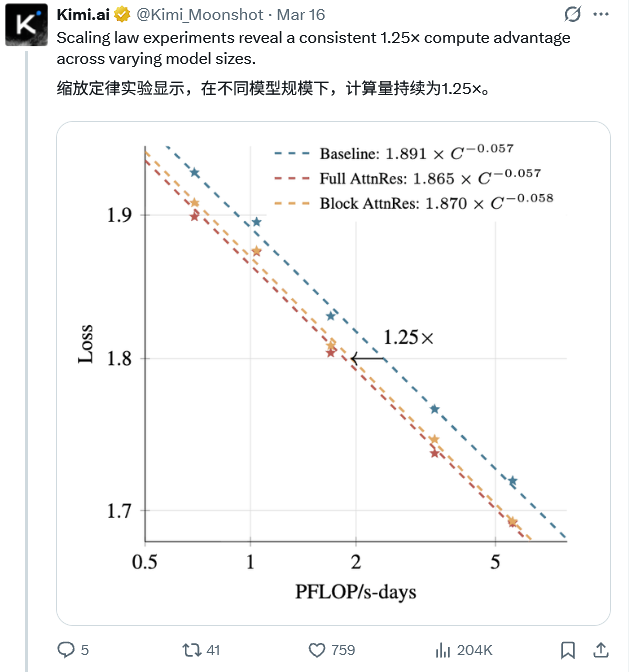
为了全面验证注意力残差机制的泛化能力与性能收益,研究人员设计了跨越不同参数规模的缩放定律(Scaling laws)实验。
所有参测模型均基于包含混合专家(MoE)结构的Transformer架构,支持8192 Token的上下文窗口,并采用余弦学习率调度策略。
在相同的计算预算下,块状注意力残差与完全注意力残差始终展现出更优的验证损失,并且随着模型规模的放大,性能优势保持着高度的一致性。
在给定的算力消耗下,块状注意力残差可以达到基础模型使用1.25倍算力才能实现的损失水平。
当网络规模进一步扩展时,块状版本与完全版本的性能差距逐渐弥合,用极低的工程代价换取了几乎完整的机制红利。
以下表格展示了不同规模下的模型配置及验证损失对比:
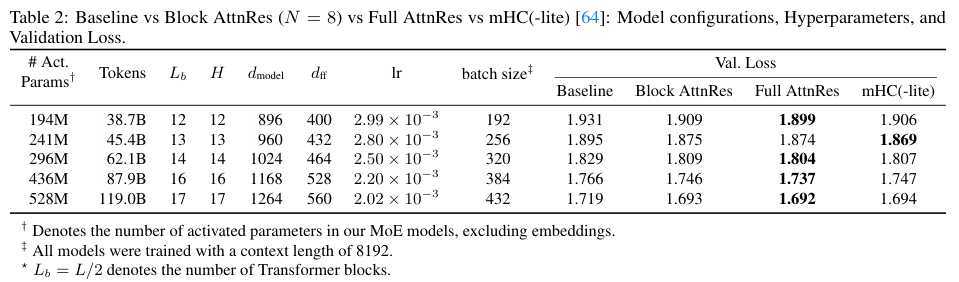
团队随后将块状注意力残差集成到总参数量达480亿、激活参数量为30亿的大型架构中,并进行了高达1.4万亿Token的深度预训练。
训练动态日志清晰地反映了该机制对隐藏层状态的重塑效果。传统架构中,每一层的输出数值会随着网络深度的增加而不可阻挡地膨胀,早期的梯度分布也极为不均。
引入新机制后,输出数值在每一个区块内部缓慢增长,并在区块边界处通过注意力机制被重新归一化,呈现出极具规律的有界周期性波动。梯度分布也变得更加均匀,不同深度的网络层在模型更新中发挥着更为均衡的作用。
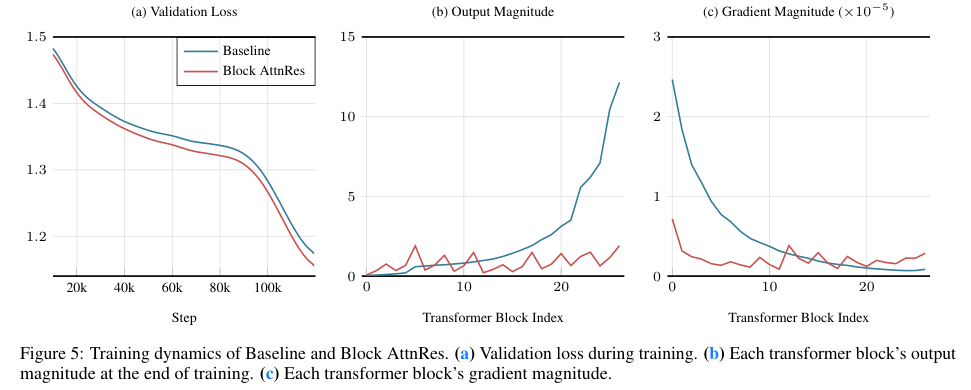
经过充分预训练与长上下文扩展,搭载新架构的模型在多项主流自然语言处理评估基准上均实现了对基础架构的全面超越。
尤其在需要多步逻辑推理和信息整合的复杂任务中,提升幅度格外亮眼。能够随时调取早期特征的能力,赋予了模型更深厚的上下文理解底蕴。
下表详细汇总了480亿参数模型在不同维度上的性能测试成绩:
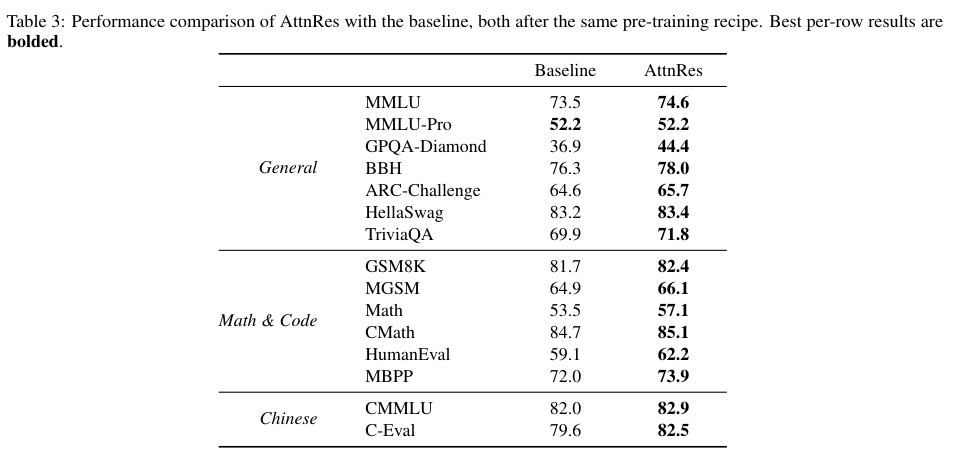
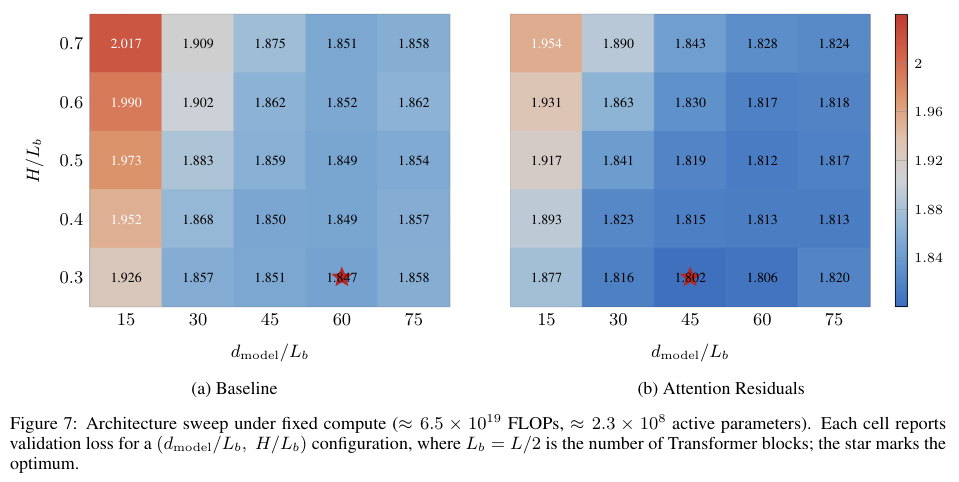
消融实验进一步验证了机制设计中每一个微小选择的必要性。
将查询向量改为动态依赖输入的形式,虽然能带来微小的性能增益,却会引入额外的线性投影层并破坏推理阶段的内存访问效率。移除用于控制数值规模的均方根归一化模块,或是将Softmax激活函数替换为Sigmoid,都会导致性能的明显回落。
Softmax特有的竞争性归一化特性,迫使模型在众多历史层中做出更为锋利、明确的选择,从而最大化了信息提取的信噪比。
各类核心组件的消融验证数据如下表所示:
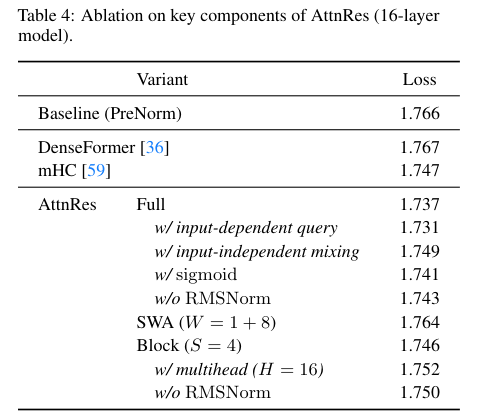
为了探究新机制对网络宏观拓扑结构的影响,研究人员在固定的算力与参数总量下,遍历了数十种不同的深度与宽度组合。
热力图扫参结果呈现出明确的指向:传统的残差网络在中间层维度与深度比例达到60左右时取得最佳表现;而注意力残差机制将最优比例拉低至45附近。
全新的信息流转通道赋予了模型更为强大的深层驾驭能力,使得模型倾向于采用更深、更窄的骨干结构来获取更优的泛化表现。
在提取模型实际学习到的注意力权重分布时,对角线主导的特征依然清晰可见。
每一层最关注的依旧是紧邻的前置层,局部特征的连续处理依然是信息加工的主轴。在特定深度的网络层中,偶尔会出现偏离对角线的集中高亮区域,模型自主学会了建立跨越多个区块的跳跃连接。
最底层的Token嵌入信息在预注意力阶段持续保持着不可忽视的权重,宛如网络深入运算时随身携带的原始坐标尺。块状设计完美继承了完全版本的这种权重分布模式,将结构化的信息筛选路径妥善保留了下来。
深度维度的残差机制演进呈现出百花齐放的态势,下表系统梳理了现有各种代表性残差方案的更新规则及其核心特征:

网络结构的每一次底层优化,都在不断突破参数规模与智能表现的转换天花板。
通过巧妙借鉴序列建模中的注意力思想,月之暗面团队成功在模型深度维度上搭建起更加智能的信息高速公路,彻底解放了前置层数据的沉睡价值。
参考资料:
https://github.com/MoonshotAI/Attention-Residuals
https://arxiv.org/pdf/2603.15031

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献276条内容
已为社区贡献276条内容

所有评论(0)