浏览器自动化Playwright MCP参考指南
在AI与浏览器自动化深度融合的浪潮下,微软开源的Playwright MCP(Model Context Protocol)横空出世,以“结构化理解”重构了AI与网页的交互逻辑,成为连接大语言模型与浏览器自动化的核心桥梁。Playwright MCP的革命性突破在于基于可访问性树提供网页元素的结构化数据,以JSON格式直供大语言模型,普通用户在Claude Code中仅凭自然语言指令,就能驱动AI
在AI与浏览器自动化深度融合的浪潮下,微软开源的Playwright MCP(Model Context Protocol)横空出世,以“结构化理解”重构了AI与网页的交互逻辑,成为连接大语言模型与浏览器自动化的核心桥梁。Playwright MCP的革命性突破在于基于可访问性树提供网页元素的结构化数据,以JSON格式直供大语言模型,普通用户在Claude Code中仅凭自然语言指令,就能驱动AI完成复杂网页操作。
作为Claude Code中常用的MCP,其安装方法如下:
# 无头版
claude mcp add -s user playwright -- npx @playwright/mcp@latest --headless
# 窗口版
claude mcp add -s user playwright -- npx @playwright/mcp@latest一、指令列表
1. browser_navigate
功能: 导航到指定URL
{
"url": "https://x.com/compose/articles"
}示例:
browser_navigate: https://x.com/compose/articles2. browser_snapshot
功能: 获取当前页面的可访问性快照,用于查找页面元素
使用时机:
- 页面加载后获取初始状态
- 操作前后查看页面变化
使用建议:
大多数浏览器操作(click, type, press_key 等)都会在返回结果中包含页面状态。不要在每次操作后单独调用 browser_snapshot,直接使用操作返回的页面状态即可。
✅ 正确做法:
browser_click → 从返回结果中获取页面状态 → browser_click → ...
❌ 错误做法:
browser_click → browser_snapshot → 分析 → browser_click → browser_snapshot → ...3. browser_click
功能: 点击页面元素
参数:
element: 元素描述(用于权限确认)ref: 元素引用(从 snapshot 结果获取)
示例:
{
"element": "create button",
"ref": "<create_button_ref>"
}使用方式:
browser_click: element="create button", ref=<create_button_ref>4. browser_file_upload
功能: 上传文件到页面
参数:
paths: 文件路径数组
示例:
{
"paths": ["/path/to/cover-image.jpg"]
}使用场景: 封面图上传(使用专门的媒体上传按钮)
5. browser_type
功能: 在文本框中输入内容
参数:
element: 元素描述ref: 元素引用text: 要输入的文本submit: 输入完成后是否按回车(可选,默认false)
示例:
{
"element": "标题输入框",
"ref": "<title_ref>",
"text": "文章标题",
"submit": false
}6. browser_press_key
功能: 按键或组合键
参数:
key: 按键名称,支持组合键如Meta+v,Control+a,Control+Shift+R
常用快捷键:
Meta+v/Control+v- 粘贴Meta+c/Control+c- 复制Enter- 回车Escape- 退出/取消
组合键格式:
Control+A, Control+Shift+R, Meta+v示例:
browser_press_key: Meta+v7. browser_wait_for
功能: 等待条件满足
参数:
text: 等待出现的文本textGone: 等待消失的文本time: 最大等待时间(秒)
使用建议:
- 只在以下情况使用:
-
- 等待图片上传完成(
textGone="正在上传媒体") - 等待页面初始加载(极少数情况)
- 等待图片上传完成(
- 不要使用
browser_wait_for来等待按钮或输入框出现
关键理解: textGone 会在文字消失时立即返回,time 只是最大等待时间。
✅ 正确用法:短 time 值,条件满足立即返回
browser_wait_for textGone="正在上传媒体" time=2
❌ 错误用法:固定长时间等待
browser_wait_for time=5示例:
browser_wait_for textGone="正在上传媒体" time=2二、高效执行原则
1. 避免不必要的 browser_snapshot
大多数操作返回结果已包含页面状态,直接使用即可。
2. 避免不必要的 browser_wait_for
只在必要场景使用:
- 等待上传完成
- 等待页面初始加载
3. 连续执行浏览器操作
每个操作返回的页面状态包含所有需要的元素引用,直接使用进行下一步。
理想流程:
browser_navigate → 从返回状态找create按钮 → browser_click(create)
→ 从返回状态找上传按钮 → browser_click(上传) → browser_file_upload
→ 从返回状态找应用按钮 → browser_click(应用)
→ 从返回状态找标题框 → browser_type(标题)
→ 点击编辑器 → browser_press_key(Meta+v)4. 准备工作前置
在开始浏览器操作之前,先完成所有准备工作(如解析文件、生成数据),这样可以连续执行浏览器操作。
三、元素定位策略
通过 block_index 定位
编辑器内容通常是嵌套结构:
textbox [ref=xxx]:
generic [ref=block0]: # block_index 0
- paragraph content
heading [ref=block1]: # block_index 1
- h2 content
generic [ref=block2]: # block_index 2
- paragraph content
...反向插入原则: 按 block_index 从大到小顺序插入图片,避免偏移影响。
四、常见组合使用场景
场景1: 打开页面并点击按钮
browser_navigate: https://example.com
browser_snapshot
browser_click: element="按钮名", ref=<btn_ref>场景2: 上传文件并填写表单
browser_click: element="上传按钮", ref=<upload_ref>
browser_file_upload: paths=["/path/to/file.jpg"]
browser_type: element="标题框", ref=<title_ref>, text="标题内容"场景3: 复制粘贴内容
# 先用Python复制到剪贴板
python copy_to_clipboard.py html --file /tmp/content.htmlbrowser_click: element="编辑器", ref=<editor_ref>
browser_press_key: Meta+v场景4: 等待上传完成
browser_press_key: Meta+v
browser_wait_for textGone="正在上传媒体" time=2五、实际案例
GitHub上基于Playwright MCP开发的X Article Publisher Skill,实现一键将 Markdown 文章发布到 X (Twitter) Articles,告别繁琐的富文本编辑。项目地址如下:
https://github.com/wshuyi/x-article-publisher-skill/tree/main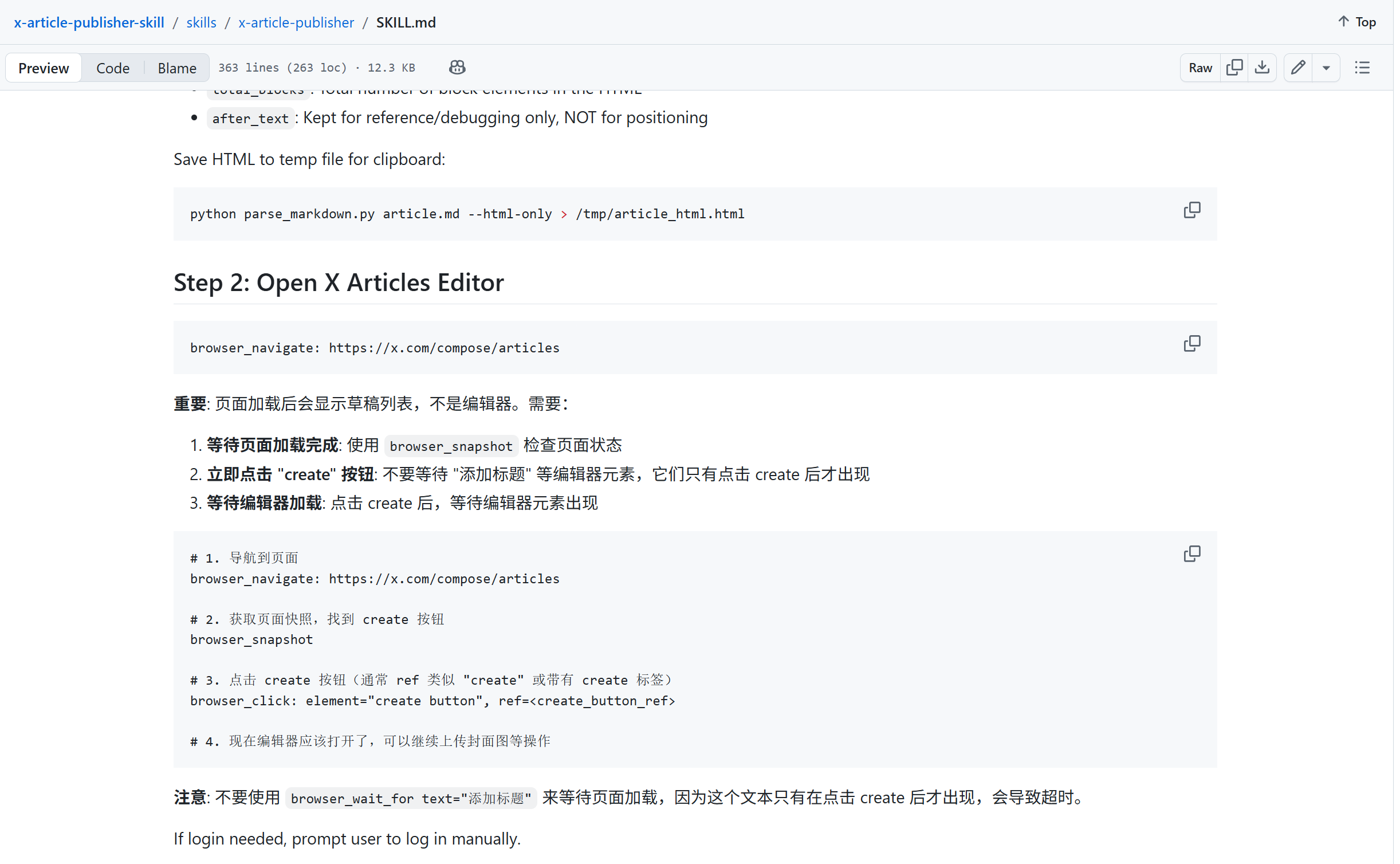

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)